Kubernetes使用Prometheus + Grafana添加监控
为 Kubernetes 添加监控是一个系统性的工程,通常被称为 "Kubernetes 可观测性"。一个完整的监控体系主要包括指标收集、日志聚合和链路追踪。这里我们将重点放在最核心的指标监控上
最经典和流行的组合是 Prometheus + Grafana。
核心监控架构:Prometheus + Grafana
text
+-------------+ Pull Metrics +--------------+ Query +----------+
| K8S Cluster |------------------>| Prometheus |<-----------| Grafana |
| & Workloads | | (TSDB) | | (UI) |
+-------------+ +--------------+ +----------+
^
| Store Rules/Alerts
+--------------+
| Alertmanager |
+--------------+-
Prometheus: 负责指标数据的采集、存储和告警规则的判断。
-
Grafana: 负责将 Prometheus 中的数据可视化,制作成精美的监控仪表盘。
-
Alertmanager: (与 Prometheus 协同工作) 负责对 Prometheus 产生的告警进行去重、分组、静默,并通过邮件、Slack、Webhook 等方式发送告警通知。
前提条件
- 一个正在运行的 Kubernetes 集群。
参考: k8s入门
- 已安装
kubectl并配置好对集群的访问
- 已安装
Helm。
参考: k8s使用helm简化安装
部署步骤
1. 添加 Helm 仓库
Prometheus 社区维护了一个官方的 Helm Chart,我们首先添加这个仓库。
sh
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update2:创建独立的监控命名空间
为了保持集群的整洁,我们创建一个专门的命名空间 monitoring。
sh
kubectl create namespace monitoring3. 安装 kube-prometheus-stack
这个 Chart 是一个"全家桶",它包含了 Prometheus、Grafana、Alertmanager 以及一系列为 Kubernetes 定制的监控规则和 Grafana 仪表盘。
sh
helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring这个命令会部署以下组件:
prometheus-prometheus-oper-prometheus: Prometheus Server
prometheus-grafana: Grafana 服务器
prometheus-prometheus-oper-alertmanager: Alertmanager
prometheus-kube-state-metrics: 用于监控 Kubernetes 资源对象(如 Deployment、Pod)的状态。
prometheus-prometheus-node-exporter: 用于收集集群每个节点的硬件和操作系统指标(DaemonSet)。
4. 验证安装
sh
# 检查 Pod 是否都正常运行
kubectl get pods -n monitoring输出应该类似如下,所有 Pod 的状态都应为 Running 或 Completed。
text
NAME READY STATUS RESTARTS AGE
prometheus-grafana-5f64b8c8c4-2q2vw 2/2 Running 0 5m
prometheus-kube-state-metrics-7c6484dd96-d2n2p 1/1 Running 0 5m
prometheus-prometheus-node-exporter-8xv2k 1/1 Running 0 5m
prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 5m
prometheus-prometheus-oper-operator-5dccf8d4d7-2v2v2 1/1 Running 0 5m
prometheus-prometheus-oper-prometheus-0 2/2 Running 0 5m检查 Service:
sh
kubectl get svc -n monitoring输出应该类似如下, 这是为 Grafana、Prometheus 等创建的 Service
text
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 118s
prometheus-grafana ClusterIP 10.43.161.227 <none> 80/TCP 2m7s
prometheus-kube-prometheus-alertmanager ClusterIP 10.43.176.15 <none> 9093/TCP,8080/TCP 2m7s
prometheus-kube-prometheus-operator ClusterIP 10.43.212.195 <none> 443/TCP 2m7s
prometheus-kube-prometheus-prometheus ClusterIP 10.43.102.79 <none> 9090/TCP,8080/TCP 2m7s
prometheus-kube-state-metrics ClusterIP 10.43.240.205 <none> 8080/TCP 2m7s
prometheus-operated ClusterIP None <none> 9090/TCP 118s
prometheus-prometheus-node-exporter ClusterIP 10.43.187.42 <none> 9100/TCP 2m7s访问监控界面
方式一:端口转发 (快速测试,不适用于生产)
访问 Grafana
sh
kubectl port-forward -n monitoring svc/prometheus-grafana 8080:80然后浏览器打开 http://localhost:8080
- 用户名:admin
- 密码:通过以下命令获取
sh
kubectl get secret -n monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decode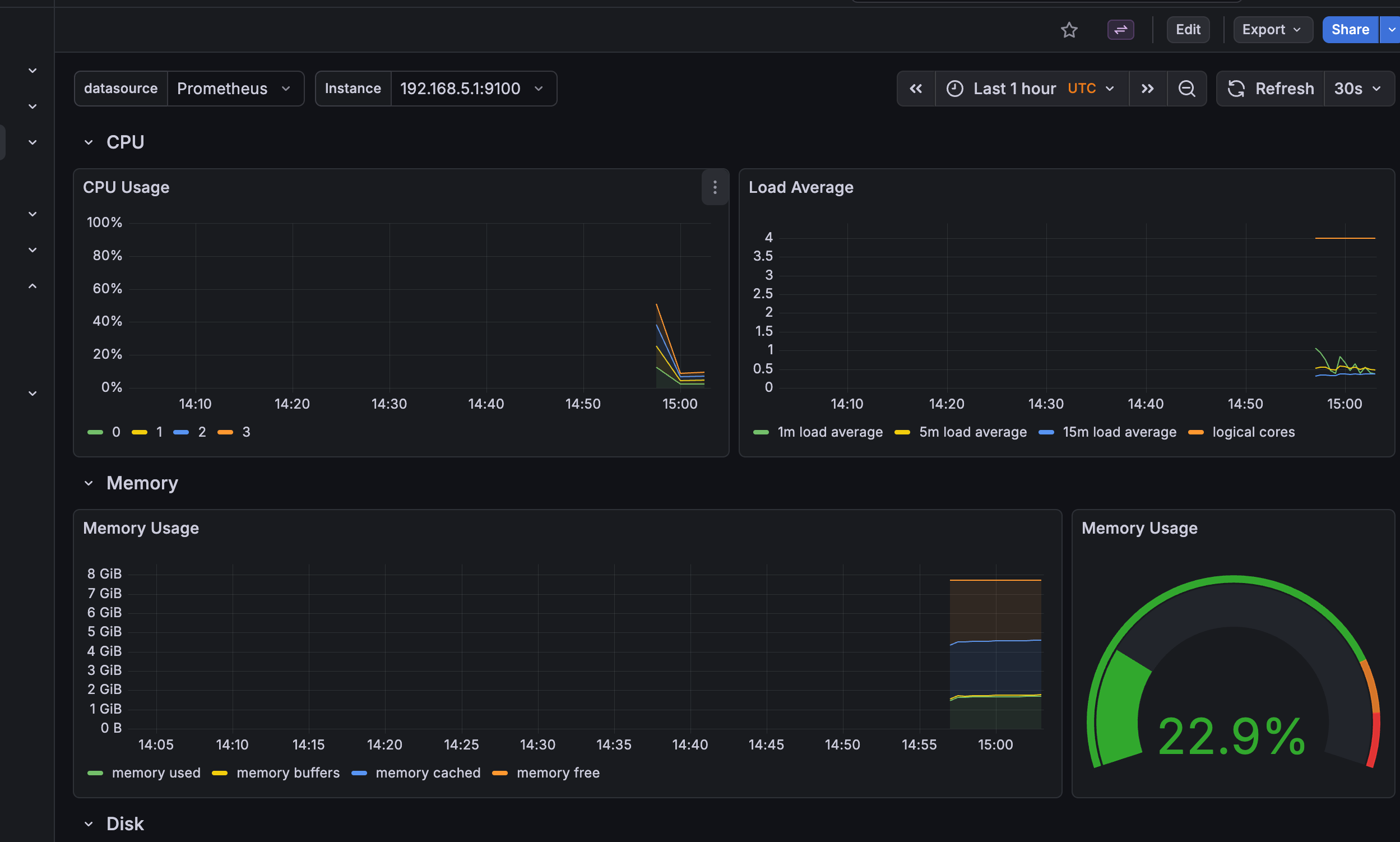
访问 Prometheus
sh
kubectl port-forward -n monitoring svc/prometheus-kube-prometheus-prometheus 9090:9090然后浏览器打开 http://localhost:9090。
访问 Alertmanager:
sh
kubectl port-forward -n monitoring svc/alertmanager-operated 9093:9093然后浏览器打开 http://localhost:9093。
方式二:配置 Ingress / LoadBalancer (生产环境)
你需要修改 Helm Chart 的 Values 来暴露服务。例如,为 Grafana 配置 Ingress:
- 创建一个名为
custom-values.yaml的文件:
yaml
grafana:
adminPassword: "your-strong-password" # 设置一个明确的密码
ingress:
enabled: true
hosts:
- grafana.your-domain.com
alertmanager:
ingress:
enabled: true
hosts:
- alertmanager.your-domain.com
prometheus:
ingress:
enabled: true
hosts:
- prometheus.your-domain.com- 使用自定义 Values 文件升级安装
sh
helm upgrade --install prometheus prometheus-community/kube-prometheus-stack -n monitoring -f custom-values.yaml监控内容解读
安装完成后,Grafana 中已经预置了许多有用的仪表盘:
Kubernetes / Compute Resources / Cluster: 集群级别的 CPU、内存、磁盘使用情况。
Kubernetes / Compute Resources / Namespace (Pods): 查看特定命名空间下所有 Pod 的资源使用情况。
Kubernetes / Compute Resources / Pod: 深入查看单个 Pod 的详细资源消耗。
Node Exporter Dashboard: 监控节点的硬件指标,如 CPU 温度、负载、磁盘 IO、网络流量等。
通过这些仪表盘,你可以清晰地了解:
集群健康度:节点是否就绪,资源是否充足。
应用性能:Pod 的 CPU/内存使用率是否异常,是否触发了 HPA。
业务洞察:通过为应用暴露的自定义指标,监控 QPS、错误率等。
监控你自己的应用
要让 Prometheus 自动发现并监控你的应用,你需要:
- 暴露指标端点 :你的应用程序需要提供一个 HTTP 端点(如
/metrics),以Prometheus格式输出指标。 - 配置 ServiceMonitor/PodMonitor :这是
Prometheus Operator引入的 CRD,用于告诉Prometheus如何发现和抓取你的应用指标
我们来为这个Spring应用加上监控
- 添加依赖
xml
<!-- Spring Boot Actuator - 必须 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Micrometer Prometheus Registry - 必须 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<version>1.11.5</version>
</dependency>- 应用配置
application.properties
text
spring.application.name=spring-k8s-demo
management.endpoints.web.exposure.include=health,metrics,prometheus
management.endpoint.health.show-details=always
management.endpoint.health.enabled=true
management.endpoint.prometheus.enabled=true- 部署文件增加监控部分
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: spring-app
labels:
app: spring-app
spec:
replicas: 2
selector:
matchLabels:
app: spring-app
template:
metadata:
labels:
app: spring-app
monitor-group: spring-apps
annotations:
prometheus.io/scrape: "true" ## 增加监控
prometheus.io/path: "/actuator/prometheus" ## 增加监控
prometheus.io/port: "8080" ## 增加监控
prometheus.io/scheme: "http" ## 增加监控
spec:
containers:
- name: spring-app
image: spring-k8s-demo:latest
imagePullPolicy: IfNotPresent
ports:
- name: metrics
containerPort: 8080
env:
- name: MANAGEMENT_ENDPOINTS_WEB_EXPOSURE_INCLUDE
value: "health,metrics,prometheus,info"
- name: MANAGEMENT_ENDPOINT_PROMETHEUS_ENABLED
value: "true"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 12
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 12
periodSeconds: 10
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"- service文件更新
yaml
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: sprint-service
namespace: default
labels:
app: spring-app
monitor-group: spring-apps
spec:
selector:
app: spring-app # 只使用这一个选择器,确保与 Pod 标签匹配
ports:
- name: metrics
port: 8080
targetPort: 8080
type: NodePort
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: spring-app-monitor
namespace: monitoring # 必须与 Prometheus 同 namespace
labels:
release: prometheus # 必须匹配 Prometheus 配置
app: spring-app-monitor
spec:
selector:
matchLabels:
monitor-group: spring-apps # 匹配 Service 的标签
endpoints:
- port: metrics # 必须匹配 Service 中端口的 name
path: /actuator/prometheus
interval: 30s
scrapeTimeout: 10s
namespaceSelector:
any: true # 从所有 namespace 发现服务重新编译,生成镜像,部署到k8s集群中,部署完成后,Java应用就具备了基础的监控能力,可以在Prometheus和Grafana中查看应用运行状态。

总结
通过以上步骤,你已经成功为你的 Kubernetes 集群搭建了一套强大、开源且功能完整的监控系统。这套系统不仅能监控集群本身和核心组件的健康状况,还能通过简单的配置轻松扩展,监控你部署在集群上的所有业务应用。
引用
例子: https://github.com/WilsonPan/java-developer/k8s/monitoring