大家好,今天是紧跟时事的韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少"避坑"经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批"好上手且有亮点"的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

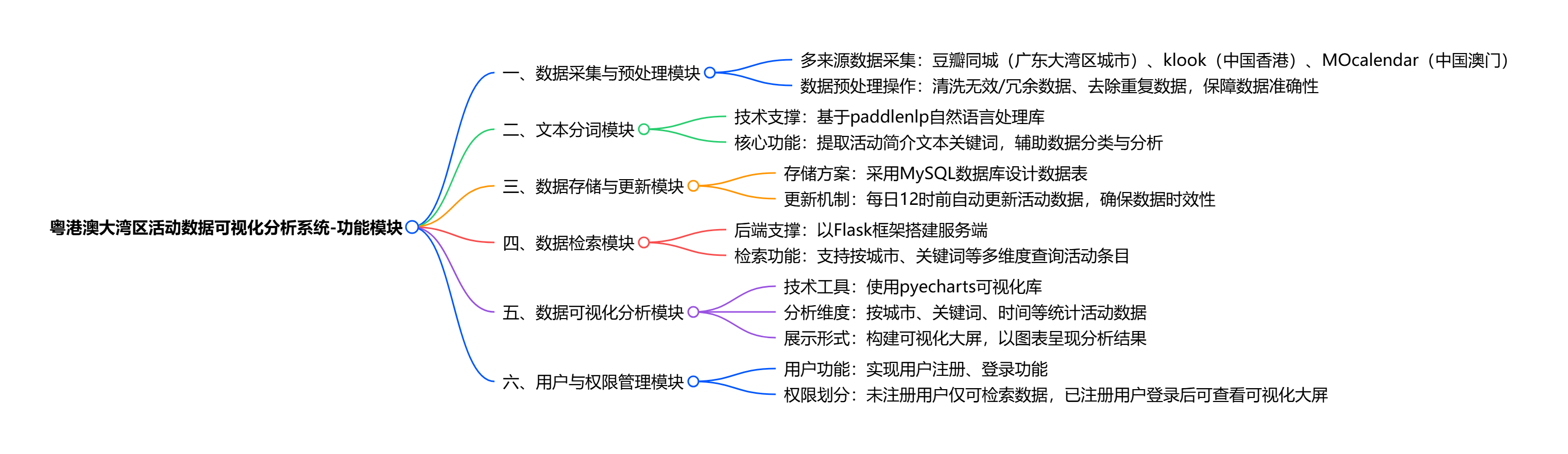
粤港澳大湾区活动数据可视化分析系统核心功能可概括为:
从指定网站采集大湾区三地活动数据,经清洗去重预处理后存入 MySQL 数据库并每日更新;
通过 paddlenlp 对活动文本分词提取关键词,以 Flask 搭建后端支持按城市、关键词等检索数据;
借助 pyecharts 构建可视化大屏,支持多维度统计分析展示;
同时设用户权限管理,未注册用户仅能检索数据,已注册用户登录可查看可视化大屏,为相关决策提供数据支持。
开题陈述
各位老师好,我的毕业设计题目是《粤港澳大湾区活动数据可视化分析系统的设计与实现》。该系统旨在通过自动化数据采集与智能分析技术,为湾区活动运营提供决策支持。
系统主要分为六大功能模块:1)数据采集层,针对粤港澳三地不同特性,分别爬取豆瓣同城(广东)、Klook(香港)及Mocalendar(澳门)的活动数据;
2)数据预处理层,完成清洗、去重与标准化;
3)智能分析层,基于PaddleNLP对活动描述文本进行关键词提取与分类;
4)数据存储层,采用MySQL数据库并设计定时更新机制;
5)可视化展示层,利用PyEcharts构建多维度分析大屏;
6)用户权限层,实现注册登录与分级访问。技术栈以Python为骨干,整合Flask后端框架、MySQL数据库及前端可视化组件,形成完整的数据闭环。
答辩开始
评委老师: 你的系统涉及爬取三个不同平台的数据,这些平台的页面结构和反爬策略差异较大。你在技术方案中计划如何应对香港Klook和澳门Mocalendar可能存在的IP限制和动态加载问题?
答辩学生: 针对IP限制,我考虑在爬虫程序中集成代理IP池轮换机制,并设置合理的请求间隔时间(如3-5秒),模拟正常用户访问行为。
对于动态加载内容,我会采用Selenium或Playwright等自动化工具模拟浏览器操作,等待JavaScript渲染完成后再提取数据。
同时,我会为每个平台编写独立的解析策略,通过分析网页DOM结构差异制定相应的XPath或CSS Selector规则,并在代码中加入异常重试机制,确保数据采集的稳定性。
评委老师: 你提到使用PaddleNLP进行文本分词,但粤港澳大湾区活动描述可能涉及粤语、繁体中文及英文混合的情况。你的NLP模型如何处理这种多语言混杂的场景?是否考虑过繁简体转换和方言识别的准确性问题?
答辩学生: 您提出的这个问题我确实考虑到了。对于多语言混杂的情况,我的处理思路是:首先通过语言检测库(如langdetect)识别文本主体语言,针对不同语言选择不同的分词策略。
对于繁体中文,我会使用OpenCC进行繁简体转换后再进行分词;
对于粤语,PaddleNLP的LAC模型对粤语有一定识别能力,同时我会补充构建一个粤语活动领域的自定义词典来提升准确率;
英文部分则采用Jieba的英文分词模式。
不过老师提醒得对,方言识别的准确性确实需要进一步验证,我计划在后续通过人工抽样标注100条数据进行准确率测试,如果低于85%会考虑采用更专业的多语言预训练模型。
评委老师: 你的系统设置每天12点前更新数据,但活动信息具有时效性强的特点。如果某个热门活动在上午10点发布,用户却要等到第二天才能看到,这显然会影响数据价值。你如何平衡数据实时性与系统性能开销?
答辩学生: 我的折中方案是设计分级更新机制:对于常规活动维持每日批量更新,但对于高关注度类别(如演唱会、展会)设置触发式增量更新------当检测到该类活动页面数量变化超过阈值时,立即启动补充爬取。同时,我会为用户搜索功能集成实时爬取接口,当用户搜索无结果时,系统可临时触发针对该关键词的即时采集,将结果缓存2小时后失效。这样既保证了日常性能,又满足了对时效性要求高的场景。
评委老师: 可视化大屏通常需要秒级响应,但当数据量累积到百万级时,直接查询数据库渲染图表会导致严重延迟。你在系统架构上是否考虑过数据预聚合或缓存策略?具体如何实现?
答辩学生: 我的解决方案是在数据库层面设计预聚合表,按城市、类别、日期等维度提前计算好统计结果,大屏直接查询这些聚合数据而非原始数据。同时引入Redis缓存机制,将高频访问的图表数据(如今日活动概览)缓存15分钟,用户查询时优先读取缓存。对于复杂的多维分析,我会采用ClickHouse列式存储作为分析型数据库,与业务数据库MySQL分离,形成OLTP与OLAP的混合架构,确保前端响应时间在2秒以内。
评委老师: 你的数据采集涉及用户发布的活动信息,其中可能包含个人隐私或企业商业机密。在法律合规性方面,你是否研究过《网络安全法》《个人信息保护法》以及香港《个人资料(私隐)条例》的相关规定?系统如何确保数据使用的合法性?
答辩学生: 目前我的方案只采集公开的活动信息(标题、时间、地点等),明确避开报名名单、联系方式等个人敏感信息。技术上,我会设置数据过滤规则,自动剔除包含手机号、身份证号等敏感字段的内容。但老师您的提问让我意识到仍可能存在合规风险,特别是香港和澳门有不同的数据保护法规。我需要补充研究三地法律差异,在系统中增加数据来源声明和使用条款提示,并对采集的数据进行匿名化处理。如果涉及商业活动详情,我会考虑加入robots.txt协议检查机制,尊重网站的数据使用政策。
评委老师: 你的系统本质上是对已有活动信息的聚合展示,创新点略显不足。你是否考虑过在此基础上增加预测性分析功能?比如基于历史活动数据预测未来某个区域某类活动的热度趋势,或者通过时间序列分析给出活动举办的最佳时机建议?如果要做,技术路线是什么?
答辩学生: 老师您说得很对,这确实能显著提升系统的价值。
我初步设想可以构建两个预测模块:一是活动热度预测,采用LSTM时间序列模型,输入历史报名人数、搜索指数、节假日等特征,预测未来7天各类别的热度趋势;
二是区域活动饱和度分析,通过计算各区域活动数量与人口密度、场地容量的比值,给出新活动选址建议。
技术路线上,我会先完成基础功能,在数据采集满3个月形成时间序列后,使用Prophet或LSTM进行建模,准确率目标设定在75%以上。不过老师您也指出了我的不足,这部分我会作为系统的扩展功能在论文中详细阐述可行性方案,并在主功能稳定后尝试实现原型。
评委评价与总结
H同学的开题答辩整体表现良好,陈述清晰完整,技术路线明确,对系统架构有较为全面的思考。在问题回答环节能够结合技术细节阐述解决方案,特别是对多语言处理、性能优化等难点问题有提前预案,显示出较好的工程思维能力。
需要加强的方面:一是法律合规意识需进一步强化,建议补充粤港澳三地数据法规的对比研究章节;二是创新性如老师提问所言尚有提升空间,建议在后续工作中将预测性分析模块落地,而非仅停留在设想阶段;三是论文撰写需更注重数据质量评估体系的构建,建议在系统中增加数据可信度指标。
总体而言,该课题具备可行性,同意开题。希望在后期的设计与实现中,能够重点关注数据合规性与算法创新,争取形成更具学术价值和应用前景的成果。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告可参考。