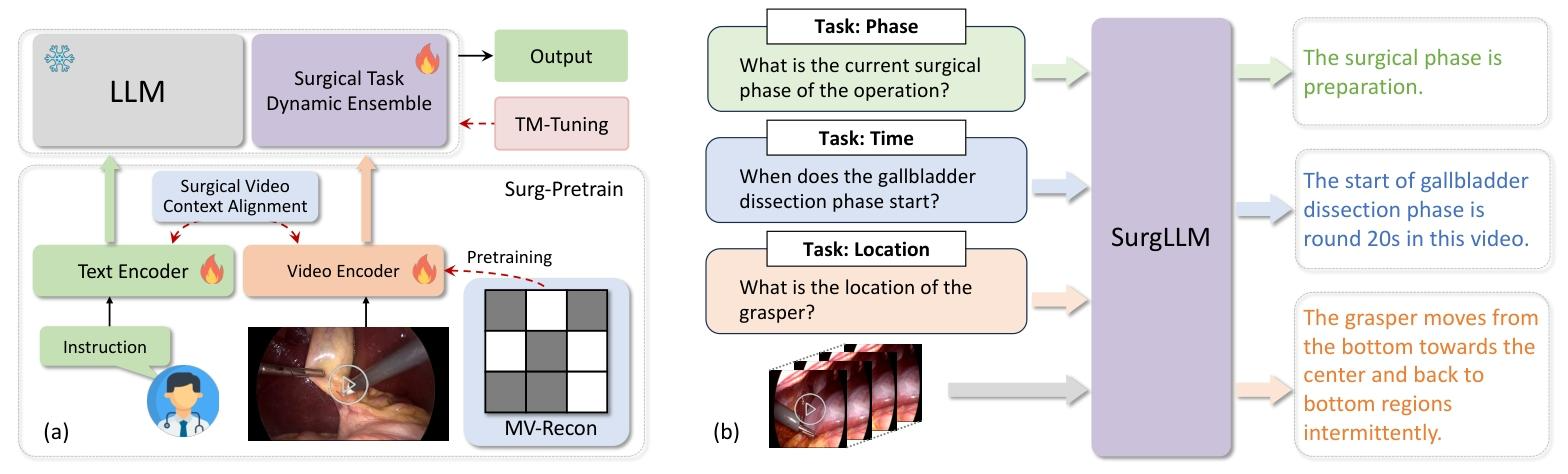
SurgLLM: A Versatile Large Multimodal Model with Spatial Focus and Temporal Awareness for Surgical Video Understanding
(1)优先对含手术器械的区域进行掩码,不同时间长度(2、4、8、16 帧)的mask,让AE重建mask的部分,练一下encoder
(2)对比学习:视频 - 文本对比学习(VTC)、视频 - 文本匹配(VTM)和掩码语言建模(MLM)三个互补目标
(3)对切片的手术片段打上 "这是一个从 i×t 秒到 (i+1)×t 秒的视频片段"的时间描述S,与对应视觉特征H交错排列
,q是查询的问题
(4)Surgical Task Dynamic Ensemble:先对输入查询进行任务类型判定,用多任务Q-Former把视觉映射到不同任务空间,并激活不同任务对应的Lora参数
其中,Q-Former中,每个任务对应一组可学习向量,激活到具体任务时,用可学习向量和video encoder的向量做交叉注意力
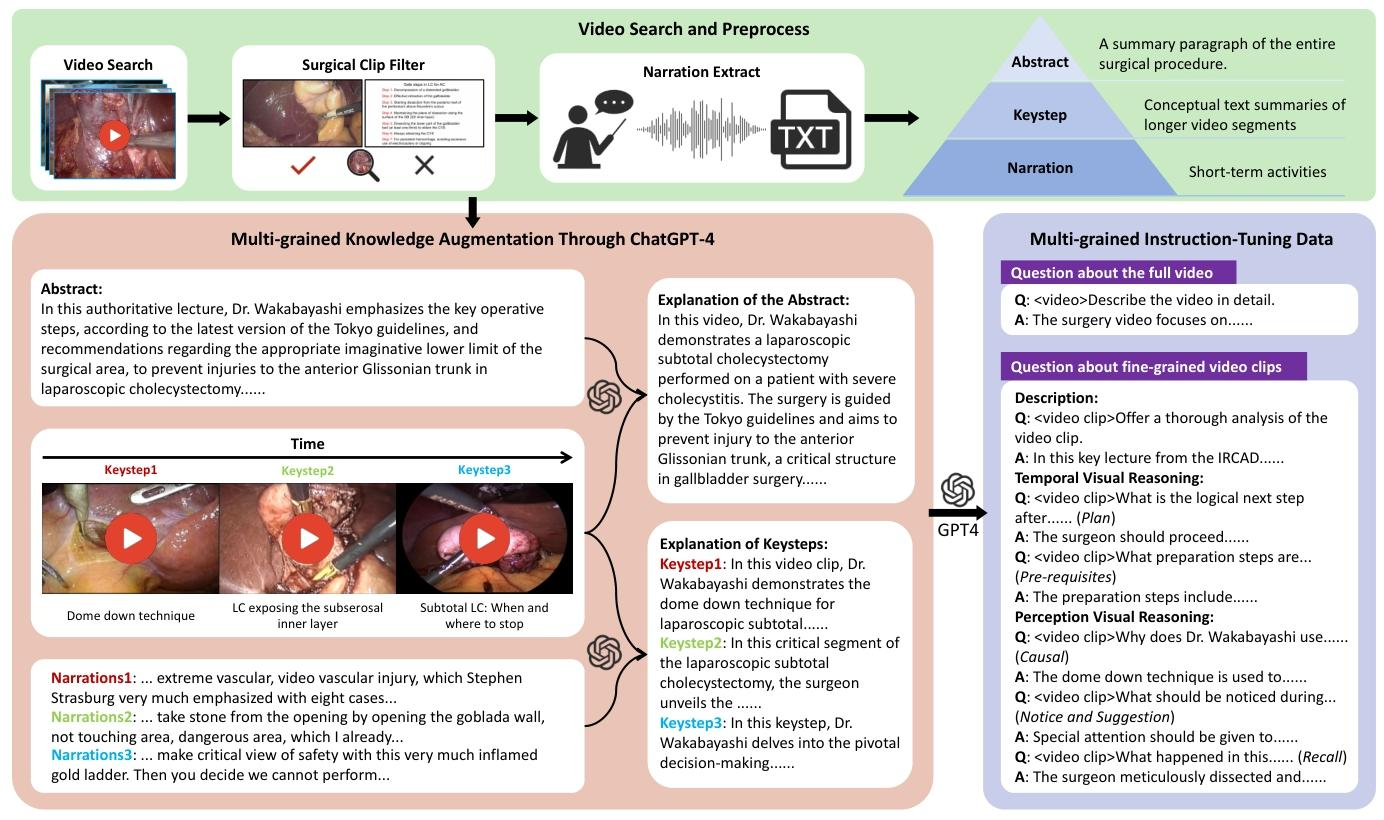
SurgVidLM: Towards Multi-grained Surgical Video Understanding with Large Language Model
(1)构建数据集是拿ResNet50过滤非手术片段,有全局QA和局部QA
(2)训练:第一阶段低频采样(1fps)全局视频,Lora微调
第二阶段输入时间码,对时间码对应的片段高频采样(2fps),将第一阶段的低频特征作为kv,采样出的特征作为q,做注意力融合
(3)推理:第一阶段生成全局理解结果(如 "该视频为腹腔镜直肠癌根治术,包含探查、游离、吻合等 5 个关键阶段")
第二阶段模型先定位问题对应的视频片段(通过时间码),再推理
Procedure-Aware Surgical Video-language Pretraining with Hierarchical Knowledge Augmentation
想解决的问题是外科领域文本质量低、专业知识缺失的痛点,而不是练一个手术视频理解模型
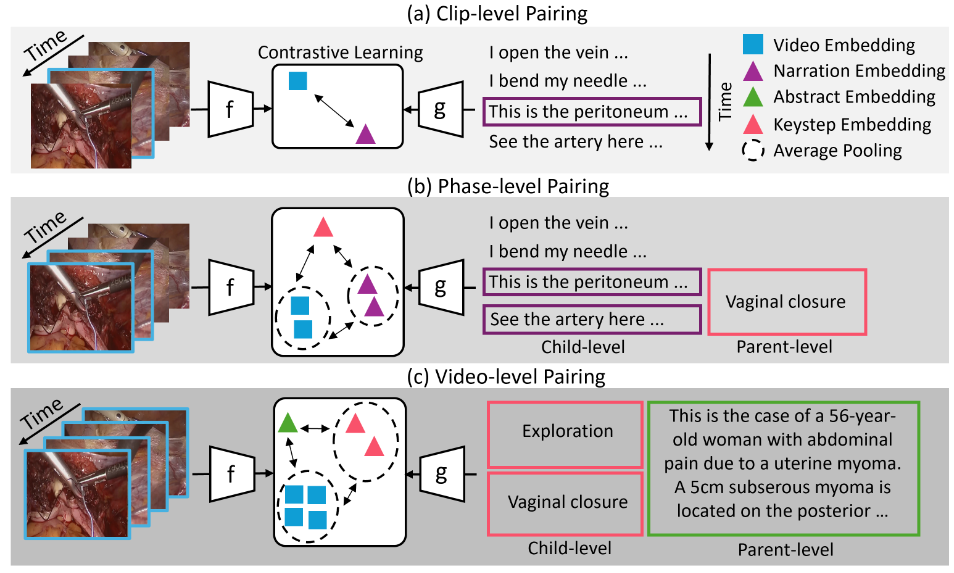
多层对比学习,红色是手术流程中不同阶段的核心操作描述,绿色是对整个手术视频的摘要文本(病例总结)
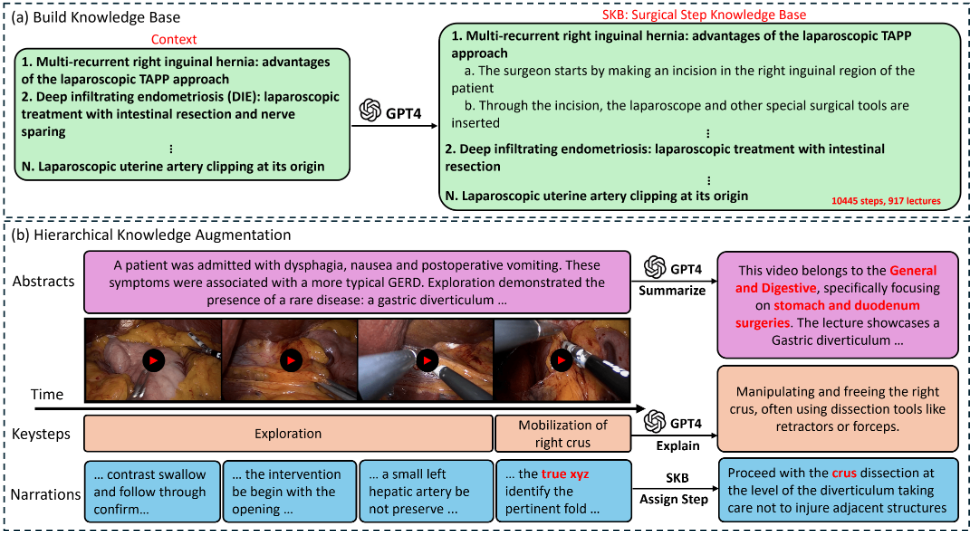
(a)根据病例扩充可能发生的结构化的手术步骤描述
(b)红色部分对应 Video-Level Pairing,根据临床症状描述Context,生成视频级摘要
橙色部分对应Phase-Level Pairing,根据手术视频的片段,生成阶段级关键步骤描述
蓝色部分,将手术过程中碎片化的语音转录文本,将转录文本与流程 (a) 构建的 结构化手术步骤描述 进行语义匹配,生成标准化的片段级叙事文本