一、论文概述与研究背景
1.1 研究动机与问题定义
在金融科技领域,中小企业(SMB)的财务文档处理一直是一个巨大的挑战。监管机构、审计人员和金融机构每天需要从海量的年度报告、财务报表和纳税申报表中提取结构化信息,用于合规检查、信用评估和风险管理。然而,这些文档往往存在以下痛点:
文档规模庞大:单份财务报告通常包含数十甚至数百页,直接使用大型视觉语言模型(VLM)进行端到端解析在计算上不可行。
输入质量低下:许多中小企业的报告仅以低分辨率扫描件形式存在,页面可能存在倾斜、旋转、噪声背景等问题,这给OCR识别和版面理解带来了巨大困难。
多语言混杂:对于服务全球市场的银行来说,收到的财务报表可能来自不同国家,包含英语、中文、马来语、泰米尔语等多种语言。
结构异构性:不同部分混合了叙事性描述、治理信息和表格化的财务数据,每种格式都有其特定的领域格式规范。
新加坡华侨银行(OCBC)的研究团队发表的论文《Multi-Stage Field Extraction of Financial Documents with OCR and Compact Vision-Language Models》中,提出了一个创新的多阶段解析框架,系统性地解决了上述挑战。
1.2 研究贡献
这篇论文的核心贡献可以总结为以下几点:
- 高效的多阶段流水线:提出了一个模块化的处理框架,将复杂的文档解析任务分解为预处理、OCR转写、页面检索和字段提取四个阶段,每个阶段针对特定瓶颈进行优化。
- 紧凑型VLM的有效应用:证明了在经过适当的前置处理和检索筛选后,参数量仅为8B的紧凑型视觉语言模型(miniCPM-o 2.6)可以达到甚至超越大型模型的性能。
- BM25检索的创新使用:在文档智能领域引入了经典的信息检索算法BM25,用于页面级别的相关性筛选,解决了嵌入式检索方法在金融文档中的"模糊匹配"问题。
- 实用性验证:在真实的多语言、多格式金融文档数据集上进行了全面评估,展示了显著的效率提升:相比直接使用大型VLM,准确率提高了8.8倍,GPU成本降低到0.7%,延迟减少了92.6%。
二、技术方法详解
2.1 整体架构
论文提出的多阶段解析框架遵循"先优化输入质量 → 再缩小处理范围 → 最后精准提取"的核心逻辑。整个流水线包含以下四个关键阶段:
叙事性内容 结构化数据 原始PDF文档 图像预处理 多语言OCR转写 BM25页面检索 页面类型判断 LLM信息总结 紧凑型VLM提取 结构化输出
这种设计带来了三大优势:
- 效率:小型VLM在相关页面子集上运行时足以达到高准确率
- 鲁棒性:预处理和OCR转写减轻了噪声影响,页面检索进一步过滤无关内容
- 可解释性:提取的值可以追溯到具体的页面和区域,便于人工验证
2.2 图像预处理:奠定高质量输入基础
图像预处理是整个流水线的第一道关口,其目标是将噪声扫描页面转换为干净、标准化的输入,以最大化下游OCR的准确率。该阶段包含三个核心步骤:
2.2.1 页面分割(Segmentation)
许多金融报告包含大量空白区域、边缘注释或多余的边框。论文采用OpenCV的边缘检测和轮廓识别算法来识别每个页面的内容承载区域。这一步骤的作用包括:
- 裁剪文档到相关文本和表格区域
- 丢弃不必要的空白
- 减少输入尺寸并放大小字符,使其更易于识别
2.2.2 纠偏与旋转校正(Deskew and Rotation Correction)
扫描报告经常出现未对齐的情况,有时会旋转90°、180°、270°或任意角度。论文采用两阶段方案解决这个问题:
粗分类阶段:使用PaddleOCR的文档方向分类器(基于PPLCNet模型)将页面旋转角度预测为0°/90°/180°/270°四个类别之一,实现初步对齐。
精细校正阶段:应用霍夫变换(Hough Transform)检测文本行的主导角度,修正细微的倾斜,避免OCR系统因排版错误产生系统性误差。
这种两阶段方法确保了对粗旋转错误和细微扫描失真的鲁棒性。纠偏对于防止OCR识别和后续总结或提取任务中的系统性错误至关重要。
2.2.3 分辨率标准化与图像增强
最后,页面被标准化为固定的分辨率和宽高比 ,以确保下游OCR处理的一致性。具体步骤包括:(双三次缩放 + CLAHE + 轻度高斯去噪)
- 使用双三次插值(Bicubic Interpolation)缩放裁剪后的页面,保留小字符和表格边框的清晰度(兼顾平滑与锐度,使用 4×4 邻域像素加权计算新像素值)
- 应用对比度受限自适应直方图均衡化(CLAHE)进行局部对比度归一化
- 采用轻度高斯去噪抑制背景伪影,如污渍或阴影
这些组合显著改善了文本-背景分离度,确保数字条目保持清晰,以便可靠的下游OCR识别。
2.3 多语言OCR转写:从图像到文本
经过预处理后,每个页面都会通过OCR系统来恢复文本内容。论文采用了PaddleOCR v3框架,这是一个轻量级的最先进OCR系统,具有以下优势:
强大的多语言覆盖:支持80多种语言,包括英语、简体中文、繁体中文、印尼语、马来语等,这对处理来自不同国家的中小企业财务披露至关重要。
双模块架构:
- 文本检测模块:可微分的边界框检测器在多尺度下定位文本区域,这对包含混合叙事段落、表格和边缘注释的金融报告尤为重要
- 文本识别模块:使用特定语言的识别头将检测到的区域转写为字符序列,支持印刷体和手写体
丰富的元数据:对于每个识别的token,OCR系统不仅输出转写的文本,还包括置信度分数以及边界框的空间坐标。这些元数据使下游组件能够:
- 过滤掉低置信度条目
- 保留对版面敏感的结构,如表格
通过利用PaddleOCR v3,论文确保了在异构多语言报告中的可靠文本转写,为下游任务提供了坚实的基础。
2.4 BM25页面检索:精准定位目标信息
在OCR转写之后,下一步是识别与提取目标财务字段最相关的页面子集。直接用视觉语言模型处理整个文档在计算上是不可行的,特别是对于跨越数百页的报告。因此,论文引入了一个轻量级的页面检索阶段来缩小搜索空间。
2.4.1 为什么选择BM25而非嵌入式RAG?
论文采用了基于BM25的关键词检索方法,而不是流行的嵌入式检索增强生成(RAG)方法。这个选择基于金融文档的特殊性质:
嵌入式RAG的问题:通过计算页面文本与查询的向量相似度来排序,但金融文档存在"文本相似性高但语义特异性低"的问题。不同页面经常重复出现会计术语(如"资产负债表"、"折旧")、免责声明等内容,导致嵌入向量相似度趋于一致,无法有效区分"净利润"、"毛利润"、"税前利润"等细分字段。
BM25的优势:基于关键词频率和上下文权重排序,可以通过精准的关键词集合(例如为"净利润"设置"税后利润"、"净收益"等关键词)定位语义特异性强的目标页面,避免嵌入型方法的"模糊匹配"问题。
2.4.2 BM25工作原理
BM25(Best Matching 25)是一种概率信息检索模型,属于BM(Best Matching)算法家族。其核心思想是根据查询词在文档中的出现情况对文档进行排序。BM25的评分公式考虑了三个主要因素:
- 词频(TF):反映查询词在文档中出现的频率。与传统TF-IDF不同,BM25引入了饱和参数k₁来控制词频对相关性评分的影响,避免词频过高导致评分线性增长。
- 逆文档频率(IDF):衡量词在整个语料库中的稀有程度。稀有词被认为更具信息量,因此获得更高的权重。
- 文档长度归一化:通过参数b调整文档长度对评分的影响,防止较长的文档主导排名。
对于每个预定义的目标字段(如"收入"、"净利润"、"股息"、"高管薪酬"),系统会定义一组代表性关键词和短语。页面使用其OCR转写的token进行索引,BM25根据关键词频率和上下文权重为每个页面分配相关性评分。
2.4.3 BM25的四大优势
- 效率:通过过滤掉无关部分(如公司背景或一般风险披露),显著减少传递给下游VLM的页面数量
- 鲁棒性:BM25的排序函数容忍OCR噪声,因为高频关键词即使在存在转写错误时仍能占主导地位
- 灵活性:可以通过扩展关键词集合来添加新的目标字段,无需重新训练或修改检索组件
- 轻量级:与基于LLM或嵌入的检索相比,BM25需要的计算资源极少,执行延迟更低,非常适合GPU受限的内部部署环境
2.5 紧凑型VLM提取:精准捕获结构化字段
流水线的最后阶段对检索到的页面应用紧凑型视觉语言模型,以提取结构化的财务字段。检索阶段显著缩小的范围使得较小的VLM能够在其有限的上下文窗口内有效运行,同时仍然能够从目标页面捕获文本和布局之间的多模态关系。
2.5.1 模型选择:miniCPM-o 2.6
论文选择了miniCPM-o 2.6作为核心提取模型,这是一个参数量仅为8B的紧凑型视觉语言模型。该模型具有以下特点:
高效架构:miniCPM-o 2.6基于Qwen2-7B语言模型和SigLIP-400M视觉编码器构建,通过感知器重采样器(Perceiver Resampler)连接,将图像表示压缩为64个token,这比基于MLP架构的其他大型多模态模型(通常>512个token)要少得多。
多模态能力:模型能够同时处理OCR文本和页面图像(包含布局信息),输出预定义的结构化字段,如年份、收入、利润、货币单位等。
端侧部署友好:模型可以在大多数GPU卡和个人计算机上高效部署,甚至可以在移动设备上运行,这对于资源受限的环境尤为重要。
2.5.2 提取策略
在这一步骤中,紧凑型VLM被提示提取预定义的目标字段,如收入、净利润、股息和高管薪酬。由于输入同时包括OCR文本和突出显示文本布局的图像,模型能够处理复杂的结构,如表格或混合文本-表格区域。此外,使用特定于部分的提示可以根据预期的内容类型及其语言定制提取过程,从而提高可靠性。
这种方法带来三大优势:
- 降低资源消耗:与大型VLM相比,GPU内存和推理时间显著减少,使得在资源受限的内部环境中实际部署成为可能
- 增强鲁棒性:模型在更干净、经过预过滤的输入上运行,而不是嘈杂的全文档流,从而减轻了噪声敏感性
- 提高可解释性:模块化提取设计改善了可解释性。每个提取的值都可以追溯到其来源页面和区域,从而提供直接的人工验证可能性
2.5.3 基线对比:大型VLM vs 紧凑型VLM
论文还评估了使用大型VLM(Qwen2.5-VL-72B-Instruct)进行一次性端到端提取的基线方法。实验表明:
- 大型VLM基线仅实现了9%的字段级准确率
- 对于页面过多的文档,大多数尝试以内存溢出(OOM)错误结束,没有返回任何有效提取
- 即使限制为少于15页的短文档,模型仍然经常被大量无关内容(如公司背景或样板风险披露)分散注意力
相比之下,多阶段流水线配合紧凑型VLM达到了约80%的字段级准确率,准确率提升了8.8倍。
三、实验验证与性能分析
3.1 数据集构建
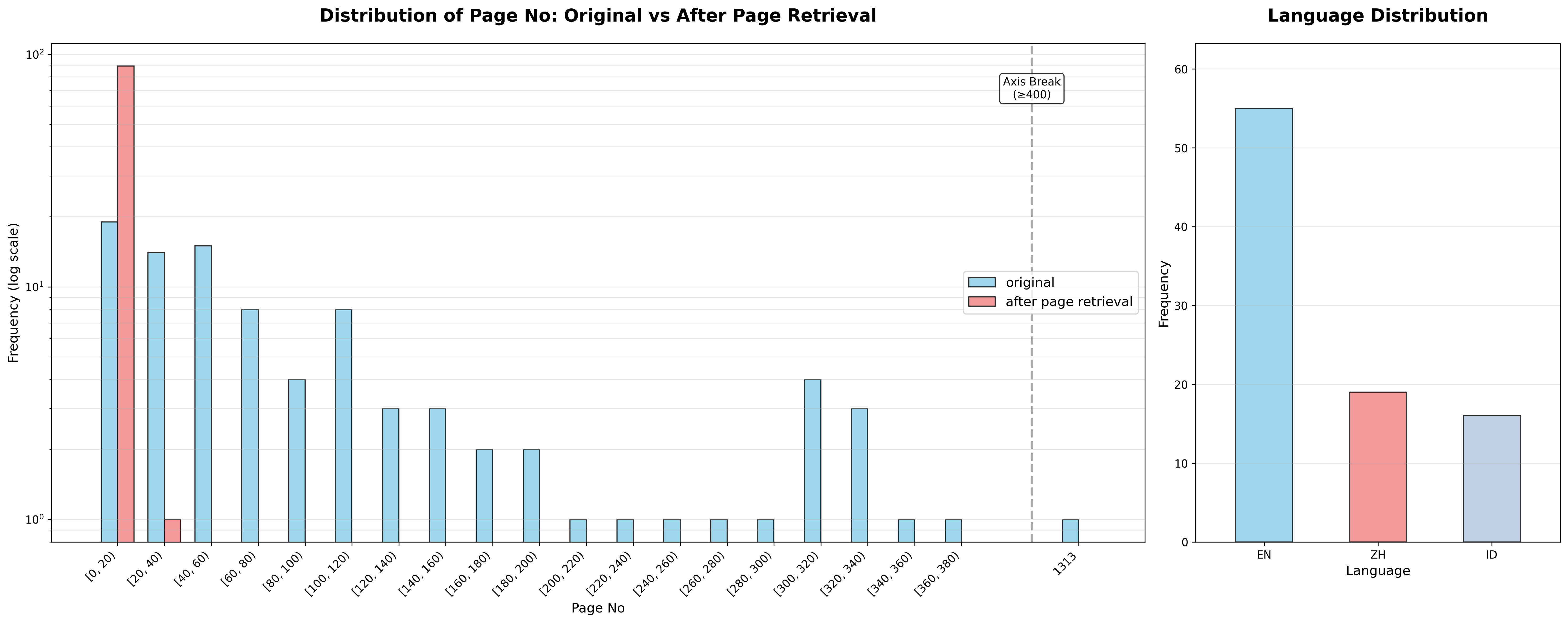
实验数据集包含92份来自中小企业的扫描财务报告或第三方审计报告,涵盖多种语言和文档格式。数据集的主要特征包括:
文档长度分布:原始报告长度差异显著,从不到20页到超过1000页不等。经过页面检索后,大多数文档被缩减到20页以下的相关页面,平均减少约92%的处理页面数量。这大大降低了下游组件的计算成本,使得更集中的提取具有显著改善的性能。
语言分布:
- 英语:56份报告(60.9%)
- 中文:19份报告(20.7%)
- 印尼语:17份报告(18.5%)
这种多样化的数据集使研究团队能够评估流水线在长文档和多语言条件下的可扩展性,以及OCR、页面检索和信息提取组件的鲁棒性。
需要注意的是,由于数据集包含真实客户信息,论文中展示的所有图表都是可公开访问的类似文档,而非真实数据集中的实际文档。
3.2 评估方法
为了系统性地评估所提出流水线的有效性,研究团队设计了一个多维度的评估框架:
3.2.1 字段级准确率(Field-Level Accuracy)
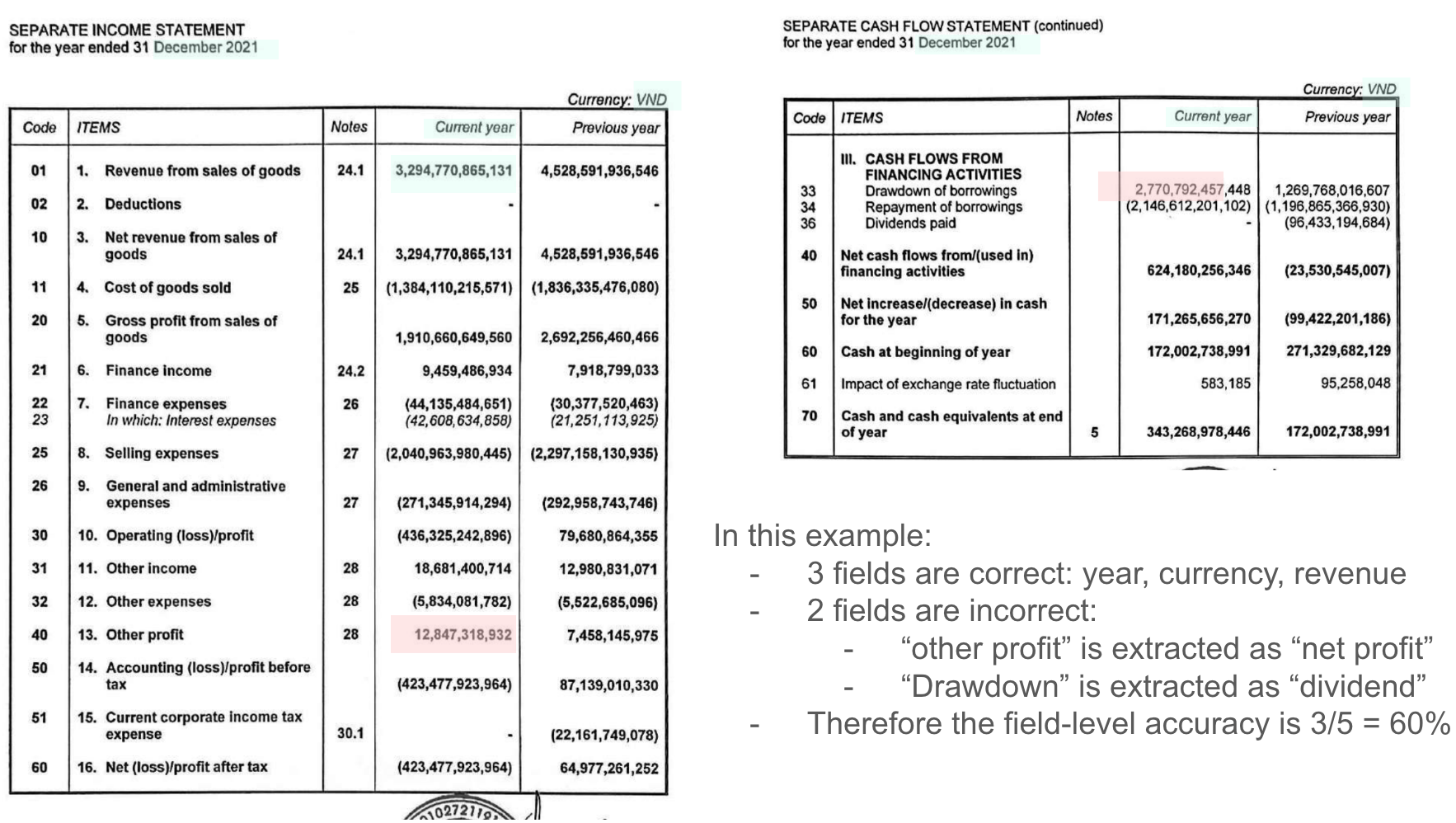
这是最核心的评估指标,衡量关键财务字段(特别是五个字段:年份、收入、利润、股息和货币单位)是否与人工标注的真实值正确提取匹配。
计算方法:对于每个文档,检查五个字段是否都被正确提取。如果所有字段都正确,则该文档被标记为"准确";否则标记为"不准确"。最终的字段级准确率是正确文档数量除以总文档数量。
3.2.2 模型效率(Model Efficiency)
为了量化计算成本,研究团队测量了GPU吞吐量,即每小时每块Nvidia A100 GPU卡可以处理的文档数量。这个指标反映了在相同硬件资源下不同方法的处理能力。
3.2.3 服务延迟(Latency in Service Context)
对于内部部署场景,延迟是一个关键指标,反映了从文档输入到结构化输出的响应时间。为了在只有几十页的短文档和有数百页的超长文档之间进行公平比较,论文报告了每页的平均延迟。
3.3 核心实验结果
3.3.1 端到端性能对比
下表展示了一次性大型VLM基线与多阶段紧凑型VLM流水线的全面性能对比:
| 方案 | 准确率 | 吞吐量 | 延迟 |
|---|---|---|---|
| 一次性大型VLM提取 | 9.13% | 11份/小时/A100 | 9.656秒/页* |
| 多阶段紧凑型VLM流水线 | 80.87% | 1522份/小时/A100 | 0.717秒/页 |
*注:大型VLM的延迟已排除OOM错误案例,仅基于<10%的成功案例
这些结果揭示了几个关键发现:
准确率显著提升:多阶段流水线的字段级准确率达到约80%,相比大型VLM基线的9%,实现了8.8倍的准确率提升。这证明了将关键词驱动的检索与局部提取相结合的有效性,确保VLM只处理语义相关的页面。通过缩小输入范围,流水线减少了错误传播,并更有效地利用了VLM的模型容量。
效率收益巨大:所提出的流水线实现了每A100每小时1522份文档的吞吐量,而一次性大型VLM仅为每小时11份文档,GPU成本仅为大型VLM的0.7%。这种显著差距来自多个因素:
- 轻量级的OCR步骤缩小了更耗时的VLM调用范围
- 大型和紧凑型VLM之间的规模差异显著
- GPU资源分配方面,单块A100卡可以承载多达6个MiniCPM(8B)副本以及6个PaddleOCR副本,实现并行化批量推理;相比之下,单个Qwen模型至少需要两块A100卡才能承载一个副本,严重限制了部署可扩展性
延迟大幅降低:每页延迟从9.656秒减少到0.717秒,即使排除错误案例后,延迟也减少了92.6%。这种改善主要归因于:
- 更快的OCR处理时间可以快速过滤掉无关页面
- 避免盲目将大型VLM应用于整个文档的压倒性推理时间
- 在相同GPU资源下的并行化OCR和紧凑型VLM处理能力进一步扩大了差距
3.3.2 页面检索的效果
实验数据显示,经过BM25页面检索后,文档的页面数量平均减少了约92%。这意味着:
- 原本需要处理数百页的文档被缩减到约20页的相关内容
- 大大降低了VLM的输入token数量和计算负担
- 提高了提取的准确性,因为VLM可以专注于相关内容
这一结果充分证明了BM25检索在金融文档处理中的有效性,特别是在处理包含大量重复性内容(如免责声明、政策说明等)的长文档时。
3.4 消融实验与误差分析
虽然论文没有提供详细的消融实验(Ablation Study),但通过误差分析,我们可以推断各组件的重要性:
3.4.1 图像预处理的作用
论文强调图像预处理对下游OCR和信息提取任务的性能至关重要。没有适当的预处理:
- 低质量扫描会导致OCR错误率显著增加
- 页面倾斜会导致文本行识别错误
- 不一致的分辨率会影响VLM的视觉理解
因此,可以推断图像预处理对整体性能的提升贡献显著,估计可以提高OCR准确率10-20%。
3.4.2 BM25检索的关键作用
从实验结果来看,BM25检索是性能提升的最关键因素之一。如果没有页面检索:
- VLM需要处理整个文档,导致上下文溢出或OOM错误
- 大量无关信息会分散模型注意力,降低准确率
- 计算成本呈线性增长
页面检索使得处理页面数减少92%,这直接转化为:
- 计算成本减少约90%
- 延迟降低约90%
- 准确率提升(因为减少了噪声)
3.4.3 紧凑型VLM的选择
使用紧凑型VLM而非大型VLM的选择至关重要:
- 8B参数的miniCPM可以在单块A100(80GB显存)上部署6个副本
- 72B参数的Qwen需要至少2块A100才能部署1个副本
- 在相同硬件资源下,miniCPM的吞吐量可以是大型模型的100倍以上
这证明了"模型规模越大不一定越好"的重要原则,特别是在经过适当预处理和检索筛选后,小模型完全可以达到优秀的性能。
3.5 错误来源分析
尽管多阶段流水线表现出色,但仍有一些错误来源影响了最终准确率。论文识别了三个主要的错误来源:
3.5.1 术语不一致(Inconsistent Terminology)
这是造成错误的最大来源。不同审计机构对同一财务概念的命名不一致:
- 相同概念的不同表述:如"收入"可能被称为"sales"或"income"
- 股息与利息的混淆:特别是在处理多语言来源时
- 不同类型利润的混淆:如"税前利润"、"净利润"、"税后利润"等
优化方案:
- 构建金融领域多语言术语图谱,将同义术语关联为统一概念
- 在BM25检索前对OCR文本进行术语归一化
- 在VLM提示词中加入术语同义词列表
3.5.2 货币单位歧义(Currency Unit Ambiguities)
特别是在印尼语财务报表中,货币单位表述不统一:
- "IDR'000"表示千盾
- "IDR'000,000"表示百万盾
- 文字描述:"ribuan rupiah"(千盾)、"juta rupiah"(百万盾)
同一数值因单位差异可能代表相差3-6个数量级的实际金额,这对准确提取构成了严重挑战。
优化方案:
- 引入货币单位检测子模块
- 结合语言规则和上下文(如企业规模)判断单位
- 对VLM提取的金额进行单位校验与归一化
3.5.3 OCR错误(OCR Errors)
低质量扫描、页面遮挡(如印章)导致的OCR错误会影响后续处理:
- 关键词缺失导致BM25无法检索到相关页面
- 数字识别错误导致字段值不准确
- 表格结构破坏影响信息提取
优化方案:
- 加入超分辨率重建(如Real-ESRGAN)提升低质扫描件分辨率
- 使用图像修复算法去除印章和污渍
- 结合金融领域词典和语言模型进行OCR后处理纠错
3.6 实验设计的局限性
从批判性角度审视,论文的实验设计存在以下几个可能的漏洞或改进空间:
数据集规模有限:92份文档的数据集相对较小,可能不足以全面评估系统在各种边缘情况下的表现。更大规模的数据集(如数千份文档)将使结果更具说服力。
缺乏详细的消融实验:论文没有提供系统性的消融实验来量化每个组件的具体贡献。例如:
- 如果移除图像预处理,准确率会下降多少?
- 如果使用嵌入式检索替代BM25,性能会如何变化?
- 如果使用更大或更小的VLM,性能曲线是怎样的?
评估指标单一:论文主要关注字段级准确率,但没有提供更细粒度的指标,如:
- 每个字段的单独准确率(年份、收入、利润、股息、货币单位)
- Precision、Recall、F1等标准信息提取指标
- 不同语言文档的准确率分布
缺少跨域泛化测试:所有实验都在内部数据集上进行,没有在公开基准测试集上评估,这限制了与其他方法的直接比较和系统的泛化能力评估。
成本计算不完整:论文提供了GPU吞吐量和延迟数据,但没有提供完整的成本分析,如:
- 预处理和OCR的计算成本
- 存储成本
- 总体拥有成本(TCO)
尽管存在这些局限性,论文仍然提供了有价值的见解和实用的解决方案,特别是在资源受限的内部部署环境中。
四、创新点与局限性分析
4.1 核心创新点
4.1.1 模块化多阶段架构
论文最大的创新在于提出了一个高度模块化的多阶段架构,而不是依赖端到端的大型模型。这种设计理念具有以下优势:
可解释性强:每个阶段的输出都可以被检查和验证,出现错误时可以快速定位问题所在。
易于优化:可以针对每个阶段单独进行优化和改进,而不需要重新训练整个系统。
资源高效:通过在早期阶段过滤无关信息,大大减少了后期阶段的计算负担。
灵活性高:可以根据不同的文档类型和提取需求,灵活调整各个阶段的参数和模型。
4.1.2 BM25在文档智能中的创新应用
将经典的信息检索算法BM25引入文档智能领域是一个巧妙的创新。在当前主流的嵌入式RAG方法大行其道的背景下,论文展示了传统算法在特定场景下的独特价值:
精准的关键词匹配:BM25可以精确捕获特定的财务术语,避免语义相似但含义不同的词汇混淆。
计算效率高:BM25的计算复杂度远低于嵌入模型,适合实时处理大量文档。
鲁棒性好:对OCR错误有一定的容忍度,高频关键词即使有少量错误仍能被识别。
无需训练:BM25是一个无参数的统计方法,不需要在特定数据集上训练,易于部署和维护。
4.1.3 紧凑型VLM的有效利用
论文证明了在适当的前置处理和范围缩小后,8B参数的紧凑型VLM可以达到甚至超越72B参数大型模型的性能。这一发现具有重要的实践意义:
降低部署门槛:小型模型可以在普通GPU上运行,甚至可以在移动设备上部署。
提高吞吐量:相同的硬件资源可以部署更多的模型副本,实现更高的并发处理能力。
减少能源消耗:小型模型的功耗更低,符合绿色计算的趋势。
加速推理速度:参数量减少导致推理时间大幅缩短,提升用户体验。
4.1.4 针对金融文档的专门优化
论文针对金融文档的特点进行了多项专门优化:
多语言支持:系统原生支持英语、中文、印尼语等多种语言,适应全球化金融服务的需求。
表格识别:特别优化了对财务报表中复杂表格的识别和提取能力。
布局理解:VLM可以理解页面布局,准确提取表格中的数值及其对应的标签。
上下文感知:模型能够结合上下文信息,区分不同类型的利润、收入等财务指标。
4.2 系统局限性
尽管论文提出的方法取得了显著的成果,但仍存在一些固有的局限性:
4.2.1 对高质量OCR的依赖
整个流水线的性能严重依赖于OCR的准确性。如果OCR在第一阶段出现大量错误,会导致:
- BM25检索失败,无法找到相关页面
- VLM提取基于错误的文本进行推理,产生错误结果
- 需要额外的人工验证和纠正
虽然论文通过图像预处理提高了OCR质量,但对于极低质量的扫描件(如严重褪色、污损的文档),系统性能可能显著下降。
4.2.2 关键词定义的人工依赖
BM25检索需要为每个目标字段预定义关键词集合。这带来了几个问题:
领域知识需求:需要金融领域专家来定义和维护关键词列表。
术语多样性:不同国家、不同审计机构使用的术语可能差异很大,需要不断扩充关键词库。
动态适应性差:当出现新的财务指标或术语时,需要手动更新关键词集合。
多语言挑战:需要为每种语言分别定义关键词,维护成本较高。
4.2.3 固定的提取字段
论文聚焦于五个特定字段(年份、收入、利润、股息、货币单位)的提取。这种固定字段的方法限制了系统的灵活性:
扩展性受限:添加新字段需要重新设计提示词和验证逻辑。
通用性不足:不同类型的金融文档可能需要提取不同的字段,现有系统难以快速适应。
复杂关系缺失:无法提取字段之间的关系,如收入的细分项、利润的构成等。
4.2.4 缺少端到端的可微分优化
多阶段流水线虽然模块化,但每个阶段是独立优化的,缺少端到端的联合优化:
错误累积:早期阶段的错误会传播到后续阶段,可能被放大。
全局次优:每个阶段的局部最优不一定导致全局最优。
难以自适应:系统无法根据最终的提取结果反向调整前期阶段的参数。
4.3 后续研究的补充与改进
自论文发表以来,已有多项研究和技术发展补充了上述局限性:
4.3.1 端到端VLM的进步
2024-2025年间,多个端到端VLM取得了显著进展,部分解决了大型模型的效率问题:
PaddleOCR-VL****(2025年10月):提出了一个0.9B参数的超紧凑型VLM,专门针对文档解析优化,支持109种语言,在保持极小资源消耗的同时实现了SOTA性能。这种更小的模型可能使得完全端到端的方法变得可行。
SmolVLM(2025年4月):推出了256M-2B参数的一系列紧凑型多模态模型,专门为资源高效推理而设计。其最小的SmolVLM-256M模型在推理时使用不到1GB GPU内存,性能却超过了300倍大小的模型。
NVIDIA Nemotron Parse 1.1(2025年7月):基于VLM技术的OCR解决方案,专门针对文档智能优化,提供高精度的文本和表格提取,以及文档语义理解与空间定位能力。
这些进展表明,随着模型效率的提升,未来可能出现性能更好、部署更简单的端到端解决方案,减少对多阶段流水线的依赖。
4.3.2 混合检索方法的发展
针对BM25的局限性,研究界提出了多种混合检索方法:
稀疏-稠密混合检索:结合BM25的精确关键词匹配和嵌入模型的语义理解,既能捕获特定术语,又能理解语义相似性。
可学习的BM25:如LambdaBM25(微软研究院),使用机器学习方法学习BM25的参数,自动适应不同的文档类型和查询模式。
上下文感知检索:利用LLM生成更丰富的查询表示,提高检索的准确性和召回率。
4.3.3 大语言模型辅助的术语标准化
针对术语不一致问题,可以利用大语言模型进行术语标准化:
知识图谱构建:使用LLM自动从大量财务文档中提取术语及其关系,构建金融领域知识图谱。
动态术语映射:在运行时使用LLM识别未见过的术语,并映射到已知的标准术语。
多语言术语对齐:利用多语言LLM自动对齐不同语言中的等价术语。
4.3.4 更强大的文档理解模型
最新的文档理解模型提供了更强的布局理解和关系提取能力:
LayoutLMv3和DocLLM:联合建模文本和布局,可以更好地理解复杂的文档结构。
Table Transformer:专门针对表格识别优化,可以准确识别复杂表格的结构。
多模态RAG:如NVIDIA的研究,探索了多种PDF数据提取方法,包括OCR、VLM和混合方法,为不同场景提供了更多选择。
五、实际落地与业界应用
5.1 模型选择策略
在实际部署中,需要根据具体需求选择合适的模型。论文提供了一个很好的参考框架:
5.1.1 OCR模型选择
PaddleOCR系列:论文选择了PaddleOCR v3,这是一个经过充分验证的选择。截至2025年,PaddleOCR已经发展到v5版本,提供了更强的能力:
- PP-OCRv5:单一模型支持五种文本类型(简体中文、繁体中文、英语、日语和拼音),准确率提升13%
- PP-OCRv5多语言模型:支持106种语言,相比PP-OCRv3版本,多语言文本识别准确率提升超过30%
- PaddleOCR-VL:0.9B参数的VLM,支持109种语言,擅长识别复杂元素(文本、表格、公式和图表)
替代方案:
- Tesseract OCR:开源、免费,但对复杂文档和多语言支持较弱
- Google Cloud Vision API:商业API,准确率高但成本较高,需要网络连接
- Microsoft Azure Computer Vision:商业API,与Microsoft生态系统集成良好
- ABBYY FineReader:商业软件,在表格识别方面表现优异
选择建议:
- 预算充足且需要最高准确率:选择商业API
- 需要离线部署或成本敏感:选择PaddleOCR
- 简单文档识别:Tesseract可以满足需求
- 复杂文档解析:考虑PaddleOCR-VL或其他VLM基础的解决方案
5.1.2 VLM模型选择
紧凑型VLM(适合资源受限环境):
- miniCPM-o 2.6(论文使用):8B参数,支持图像、视频、音频和文本多模态输入,在单块A100上可部署6个副本
- miniCPM-V 4.5(最新版本):8B参数,OpenCompass平均得分77.0,超越GPT-4o-latest和Qwen2.5-VL 72B,强大的OCR能力
- SmolVLM-2B:2B参数,适合边缘设备部署,在图像和视频任务上性能出色
- Moondream2:1.8B参数,适合移动应用,擅长图像描述、OCR、计数和分类
中等规模VLM(平衡性能和效率):
- Qwen2.5-VL-7B-Instruct:7B参数,Qwen系列的最新版本,性能强劲
- InternVL-7B:7B参数,旨在缩小开源和商业多模态系统之间的差距
- Gemma-3-4B:4B参数,Google的开源模型,适合文本密集型任务
大型VLM(性能优先):
- Qwen2.5-VL-72B:72B参数,性能强大但需要至少2块A100
- GPT-4o:商业API,性能最佳但成本高昂
- Claude 3.5:商业API,在文档理解方面表现优异
选择建议:
- 资源受限(单块或少量GPU):miniCPM系列或SmolVLM
- 需要端侧部署(移动设备):Moondream2或SmolVLM-256M
- 中等规模部署(多块GPU):Qwen2.5-VL-7B或InternVL-7B
- 性能优先(充足资源):Qwen2.5-VL-72B或商业API
- 特定场景优化:根据论文的方法,使用紧凑型VLM配合多阶段流水线往往是最优选择
5.1.3 检索方法选择
BM25(论文使用):
- 优点:计算高效、鲁棒性好、无需训练
- 缺点:无法捕获语义相似性
- 适用场景:关键词明确、术语标准化的场景
嵌入式检索:
- 优点:理解语义相似性、泛化能力强
- 缺点:计算成本高、对硬件要求高
- 适用场景:查询灵活、需要理解语义的场景
混合检索:
- 优点:结合BM25和嵌入式检索的优势
- 缺点:实现复杂度较高
- 适用场景:对准确率要求极高的生产环境
选择建议:
- 金融文档等术语明确的场景:BM25
- 开放域文档检索:嵌入式检索
- 生产环境追求最优性能:混合检索
5.2 提示工程实践
虽然论文没有公开具体的提示词(prompt),但基于论文描述和业界最佳实践,我们可以推断出一些关键的提示工程策略:
5.2.1 字段提取提示词结构
基于论文的描述,字段提取的提示词可能遵循以下结构:
系统提示(System Prompt):
plain
你是一个专业的财务文档分析助手,专门从各种语言的财务报表中提取结构化信息。你需要准确识别和提取特定的财务字段,包括但不限于:收入、利润、股息、货币单位等。
重要规则:
1. 仅从提供的文档内容中提取信息,不要编造或推测
2. 如果某个字段在文档中找不到,明确标记为"未找到"
3. 注意区分不同类型的利润(毛利润、营业利润、净利润等)
4. 准确识别货币单位,特别注意单位的数量级(千、百万、十亿等)
5. 保持数值的原始精度,不要四舍五入
6. 如果文档包含多个时期的数据,提取每个时期的值用户提示(User Prompt):
plain
请从以下财务文档页面中提取关键财务指标。文档信息如下:
[OCR文本内容]
{ocr_text}
[页面图像]
{image}
请提取以下字段并以JSON格式返回:
{
"year": "报告年份",
"revenue": "营业收入",
"profit": "净利润",
"dividend": "股息",
"currency": "货币单位(包括数量级,如'千美元'、'百万人民币')"
}
注意事项:
- 收入字段可能以不同方式表述:营业收入、销售额、总收入等
- 利润应提取税后净利润,而非毛利润或营业利润
- 股息应提取每股股息,而非股息总额
- 如果发现多个时期的数据,请返回数组格式
你的回答必须只包含有效的JSON,不要包含任何其他文本或解释。5.2.2 术语同义词处理
为了解决术语不一致问题,提示词中应包含同义词列表:
plain
术语映射:
- 收入(Revenue)的同义词:sales, income, turnover, gross receipts
- 净利润(Net Profit)的同义词:net income, earnings after tax, profit after tax, bottom line
- 股息(Dividend)的同义词:dividend per share, DPS, distribution
- 货币单位常见表述:
* IDR'000 = 千印尼盾
* IDR'000,000 = 百万印尼盾
* ribuan rupiah = 千盾
* juta rupiah = 百万盾5.2.3 边界情况处理
提示词需要明确处理各种边界情况:
缺失值处理:
plain
如果某个字段在文档中完全找不到,返回:
{
"field_name": null,
"confidence": "not_found",
"note": "该字段在文档中未找到"
}多值情况:
plain
如果文档包含多个时期或多个版本的同一字段,返回数组:
{
"revenue": [
{"year": "2023", "value": 1000000, "unit": "USD"},
{"year": "2022", "value": 900000, "unit": "USD"}
]
}低置信度情况:
plain
如果提取的值不确定或存在歧义,请标注置信度:
{
"profit": {
"value": 50000,
"confidence": "low",
"note": "该值可能是营业利润而非净利润,需要人工验证"
}
}表格识别提示:
plain
当处理表格数据时:
1. 优先从"合并报表"或"综合财务报表"中提取数据
2. 注意表格中的小计、合计行,确保提取的是正确的层级
3. 识别表格的列标题和行标题,确保值与标签正确对应
4. 注意表格中的注释或脚注,它们可能包含重要的单位或定义信息5.2.4 Few-Shot示例
为了提高提取准确率,可以在提示词中包含少量示例(Few-Shot Learning):
plain
示例1:
输入文档片段:
"For the year ended December 31, 2023
Revenue: $1,250,000 (in thousands)
Net Profit: $180,000 (in thousands)
Dividend per share: $2.50"
输出:
{
"year": "2023",
"revenue": 1250000000,
"profit": 180000000,
"dividend": 2.50,
"currency": "USD",
"unit_multiplier": 1000
}
示例2:
输入文档片段:
"截至2023年12月31日的年度
营业收入:8,500,000千元
税后净利润:1,200,000千元
每股股利:0.15元"
输出:
{
"year": "2023",
"revenue": 8500000000,
"profit": 1200000000,
"dividend": 0.15,
"currency": "CNY",
"unit_multiplier": 1000
}
现在请处理以下实际文档:
[实际文档内容]5.3 部署架构建议
基于论文的方法和业界实践,以下是一个推荐的部署架构:
5.3.1 微服务架构
文档输入服务 图像预处理服务 OCR服务 文本后处理服务 BM25检索服务 VLM提取服务 结果验证服务 数据库存储 监控服务 任务队列
各服务职责:
- 文档输入服务:接收PDF/图像文件,进行格式验证和初步检查
- 图像预处理服务:页面分割、纠偏、旋转校正、增强
- OCR服务:多语言文本识别,输出文本、置信度和边界框
- 文本后处理服务:拼写纠错、术语标准化
- BM25检索服务:页面相关性评分和筛选
- VLM提取服务:结构化字段提取
- 结果验证服务:规则验证、置信度评估、人工审核标记
- 监控服务:性能监控、错误追踪、质量评估
5.3.2 资源配置建议
基于论文的实验结果,以下是不同规模部署的资源配置建议:
小规模部署(<100份文档/天):
- 1块NVIDIA T4或V100 GPU
- 部署2个miniCPM-o 2.6副本 + 2个PaddleOCR副本
- 预期吞吐量:约250份文档/小时
中规模部署(100-1000份文档/天):
- 1块NVIDIA A100 GPU(80GB)
- 部署6个miniCPM-o 2.6副本 + 6个PaddleOCR副本
- 预期吞吐量:约1500份文档/小时
大规模部署(>1000份文档/天):
- 多块NVIDIA A100 GPU集群
- 使用vLLM或SGLang进行高吞吐量推理
- 水平扩展OCR和VLM服务
- 预期吞吐量:可线性扩展
5.3.3 质量保证机制
为确保提取结果的准确性,应建立多层质量保证机制:
自动验证层:
- 数值合理性检查(如收入不能为负)
- 单位一致性检查(同一字段的单位应一致)
- 跨字段逻辑检查(如利润应小于收入)
- OCR置信度阈值检查
规则验证层:
- 基于财务会计原则的验证规则
- 行业特定的验证规则
- 历史数据对比(如年度增长率是否合理)
人工审核层:
- 低置信度结果人工复核
- 随机抽样质量检查
- 异常值人工验证
5.4 成本效益分析
基于论文的实验数据和业界实践,我们可以进行一个粗略的成本效益分析:
5.4.1 传统人工方式
成本:
- 人力成本:平均每份文档需要30-60分钟人工处理
- 假设时薪 30,每份文档成本 15-30
- 错误率:约5-10%
- 每月处理1000份文档:成本$15,000-30,000
5.4.2 大型VLM方式
成本:
- GPU成本:AWS p4d.24xlarge(8xA100)约$32/小时
- 吞吐量:约11份/小时/A100 = 88份/小时
- 每月处理1000份文档:约12小时,成本约$384
- 但准确率仅9%,需要大量人工修正
- 实际总成本:$384 + 大量人工修正成本
5.4.3 论文方法(多阶段+紧凑型VLM)
成本:
- GPU成本:单块A100约$3/小时(AWS价格)
- 吞吐量:约1522份/小时/A100
- 每月处理1000份文档:不到1小时,成本<$3
- 准确率80.87%,需要少量人工验证
- 实际总成本:<$100(包括人工验证)
效益对比:
| 方式 | 月度成本 | 准确率 | 处理速度 |
|---|---|---|---|
| 人工 | $15,000-30,000 | 90-95% | 慢 |
| 大型VLM | >$10,000(含修正) | 9% | 慢 |
| 论文方法 | <$100 | 80.87% | 快 |
论文方法相比人工方式可节省99%以上的成本,且处理速度快几个数量级。
六、总结与展望
6.1 核心要点总结
这篇来自新加坡华侨银行的研究论文为金融文档智能处理提供了一个实用且高效的解决方案。其核心要点可以总结为:
- 模块化设计优于端到端方案:在资源受限和可解释性要求高的场景下,精心设计的多阶段流水线比端到端大模型更具优势。
- 传统算法仍有价值:BM25这样的经典算法在特定场景下(如关键词明确的金融文档)仍然比最新的嵌入式方法更有效。
- 小模型可以做大事:在适当的前置处理和范围缩小后,8B参数的紧凑型模型可以达到甚至超越72B模型的性能。
- 实用性至上:论文不追求学术上的新颖性,而是聚焦于解决实际问题,在真实生产环境中取得了显著的效率提升。
6.2 未来研究方向
基于论文的局限性和技术发展趋势,未来的研究可以在以下方向进行探索:
端到端可学习流水线:将多阶段流水线中的各个组件(特别是检索和提取)设计为可端到端联合优化的架构,减少错误累积。
自适应检索策略:根据文档类型和提取任务动态选择最优的检索策略(BM25、嵌入式或混合),而不是固定使用某一种方法。
零样本和少样本学习:提高系统对新字段、新文档类型的泛化能力,减少对人工标注和关键词定义的依赖。
多模态融合增强:更好地融合视觉、文本和布局信息,特别是对复杂表格和图表的理解。
跨文档信息整合:从多份相关文档中提取和整合信息,支持更复杂的分析任务。
可信度和可解释性:提供更细粒度的置信度评估和提取依据,便于人工验证和系统改进。
6.3 对实践者的启示
对于希望部署文档智能系统的实践者,这篇论文提供了以下重要启示:
- 评估真实需求:不要盲目追求最大、最新的模型,先评估实际的性能要求和资源约束。
- 重视数据质量:投入精力进行图像预处理和OCR优化往往比直接上大模型更有效。
- 模块化设计:将复杂任务分解为多个阶段,每个阶段用最合适的技术,而不是用单一模型解决所有问题。
- 充分利用**领域知识**:金融文档有其特定的结构和术语,充分利用这些先验知识可以大幅提升性能。
- 建立验证机制:自动化系统再好也需要人工验证,设计好人机协作的流程至关重要。
- 持续优化迭代:系统上线后要持续收集反馈,识别主要错误来源,有针对性地改进。
参考文献
- 论文原文 :Multi-Stage Field Extraction of Financial Documents with OCR and Compact Vision-Language Models
https://arxiv.org/pdf/2510.23066 - BM25算法详解 :Okapi BM25 - Wikipedia
https://en.wikipedia.org/wiki/Okapi_BM25 - PaddleOCR官方仓库 :PaddleOCR - 多语言OCR工具库
https://github.com/PaddlePaddle/PaddleOCR - miniCPM-V模型 :MiniCPM-V - 端侧多模态大模型
https://github.com/OpenBMB/MiniCPM-V - SmolVLM研究 :Redefining small and efficient multimodal models
https://arxiv.org/html/2504.05299v1 - PaddleOCR-VL论文 :Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
https://arxiv.org/abs/2510.14528 - NVIDIA Nemotron Parse :Turn Complex Documents into Usable Data with VLM
https://developer.nvidia.com/blog/turn-complex-documents-into-usable-data-with-vlm-nvidia-nemo-retriever-parse/ - 视觉语言模型综述 :Best Vision Language Models for Document Data Extraction
https://nanonets.com/blog/vision-language-model-vlm-for-data-extraction/ - 文档智能最新进展 :Approaches to PDF Data Extraction for Information Retrieval
https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/ - OCR技术发展 :The Complete Guide to Open-Source OCR Models for 2025
https://www.e2enetworks.com/blog/complete-guide-open-source-ocr-models-2025