一、获取餐厅信息
1.1 目标
从官网获取餐厅的店名、地址和电话信息,涵盖所有页面的数据。
1.2 实现思路
通过分析网页结构,发现餐厅信息通过Ajax请求获取,请求地址为 www.bkchina.cn/restaurant/... 请求参数包括页码page、省份storeProvince和城市storeCity等。但部分请求参数是%E4%B8%8A%E6%B5%B7%E5%B8%82这种样式,这时可以去载荷里找到查询字符串参数,更改过来即可。通过循环改变页码参数,不断发送请求,直到获取不到数据为止。
1.3 代码实现
python
import requests
# 找到请求网址
url = 'https://www.bkchina.cn/restaurant/getMapsListAjax'
# 添加基础请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
# 设置页面为1
page = 1
# 条件为真无限循环,直到取到的数据为空,条件不成立终止循环
while True:
# 将请求参数给到params 方便查看 用f插值法将page变量放入字典中
params = {
'page': f'{page}',
'storeProvince': '上海市',
'storeCity': '上海市',
'localSelect': '',
'search': ''
}
# 页面中看到请求方式为get请求,所以用get请求传入网址获取响应结果给到变量res
res = requests.get(url, headers=headers, params=params)
# 获取到的数据类型为字符串,服务端返回的什么数据,text得到的就是什么数据
# print(res.text)
# 把字符串数据转为字典数据,编码自动解码
res_data = res.json()
# 如果没有数据可以继续获取,服务端返回的数据格式为{data: {data: none}}:
# print(res_data)
# 如果res_data['data']['data']结果为空,则终止循环
if res_data['data']['data'] == []:
break
# 还可以用try except方法 如果异常就终止循环
# 利用for循环遍历res_data['data']['data']每一个列表数据给到变量i
for i in res_data['data']['data']:
# 列表数据为字典类型 取相应的值即可 这里用到的get方法获取值:好处如果获取不到数据,给一个空数据
storeName = i.get('storeName', '')
storeAddress = i.get('storeAddress', '').replace('amp;', '').replace(' ', '')
storePhone = i.get('storePhone', '')
print(storeName, storeAddress, storePhone)
print(f'这是当前加载的第{page}页数据')
# 每循环一次 页面+1
page += 11.4 注意事项
- 响应内容中的中文字符是Unicode编码,Python会自动处理。
- 结束循环的条件是当获取到的数据列表为空时,表明已经获取完所有数据。
二、获取产品信息
2.1 目标
获取产品名称。
2.2实现思路
产品信息通过POST请求获取,请求地址www.bkchina.cn/product/pro... 请求参数type表示产品类型,不同的type值对应不同的产品分类。发送POST请求,获取并解析响应数据。
2.3 代码实现
python
# 获取单系列数据
import requests
url = 'https://www.bkchina.cn/product/productList'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
# 看控制页面载荷里面表单数据
# 通过字典保存表单数据
data = {
'type': 'ham'
}
# 因为是post请求方式,所以这里要用post请求获取网页数据的相应结果
res = requests.post(url, data=data)
res_data = res.json()
# 这种方法不灵活,只能获取季节新品这一个系列得数据
# 面对像汉堡这种有三种系列得数据就要去修改数据,不够灵活
# for i in res_data['季节新品']:
# FName = j.get('FName', '')
# FId = j.get('FId', '')
# print(FName, FId)
# 通过for循环遍历res_data字典中得每一个键
# 这里是默认取的字典里的每一个键名给到变量i
for i in res_data:
# 再通过for循环遍历字典内对应的键的值(这里的值是列表(嵌套字典))给到变量j
for j in res_data[i]:
# 用字典里的get查询方法 查看键为FName的值是什么,如果没有就返回空
FName = j.get('FName', '')
# 用字典里的get查询方法 查看键为FId的值是什么,如果没有就返回空
FId = j.get('FId', '')
print(FName, FId)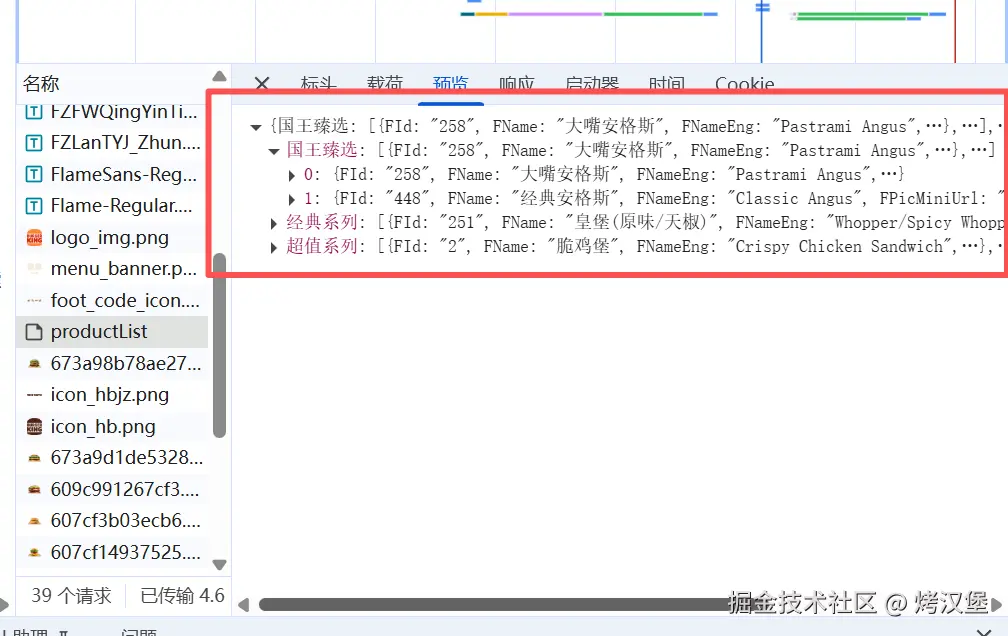
获取多系列数据
python
import requests
url = 'https://www.bkchina.cn/product/productList'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
# 将所有表单数据放在列表中
types = ['season', 'ham', 'snack', 'snack', 'dessert', 'breakfirst', 'meats', 'coffee', 'happy_meal']
# 遍历这个types列表将列表中的每一个值给到变量t
for t in types:
# 看控制页面载荷里面表单数据
# 通过字典保存表单数据
# 每经历一次for循环取一次列表里面types里面的值给到字典data
data = {
'type': t
}
# 因为是post请求方式,所以这里要用post请求获取网页数据的相应结果
res = requests.post(url, data=data)
res_data = res.json()
# 这种方法不灵活,只能获取季节新品这一个系列得数据
# 面对像汉堡这种有三种系列得数据就要去修改数据,不够灵活
# for i in res_data['季节新品']:
# FName = j.get('FName', '')
# FId = j.get('FId', '')
# print(FName, FId)
# 通过for循环遍历res_data字典中得每一个键
# 这里是默认取的字典里的每一个键名给到变量i
for i in res_data:
print(i)
# 输出结果时会报 'NoneType' object is not iterable的错误
# 很满足全餐这个列表为空,所以遍历的时候取不到值会报错
# 两种方法消除这个报错:
# 做个判断 如果这个列表为空则继续执行下面的程序
# if res_data[i] is None:
# continue
# 用try except抛出异常错误信息,看看具体报什么错误,或者也可以直接continue
try:
# 再通过for循环遍历字典内对应的键的值(这里的值是列表(嵌套字典))给到变量j
for j in res_data[i]:
# 用字典里的get查询方法 查看键为FName的值是什么,如果没有就返回空
FName = j.get('FName', '')
# 用字典里的get查询方法 查看键为FId的值是什么,如果没有就返回空
FId = j.get('FId', '')
print(FName, FId)
except Exception as e:
print('错误信息是:', e)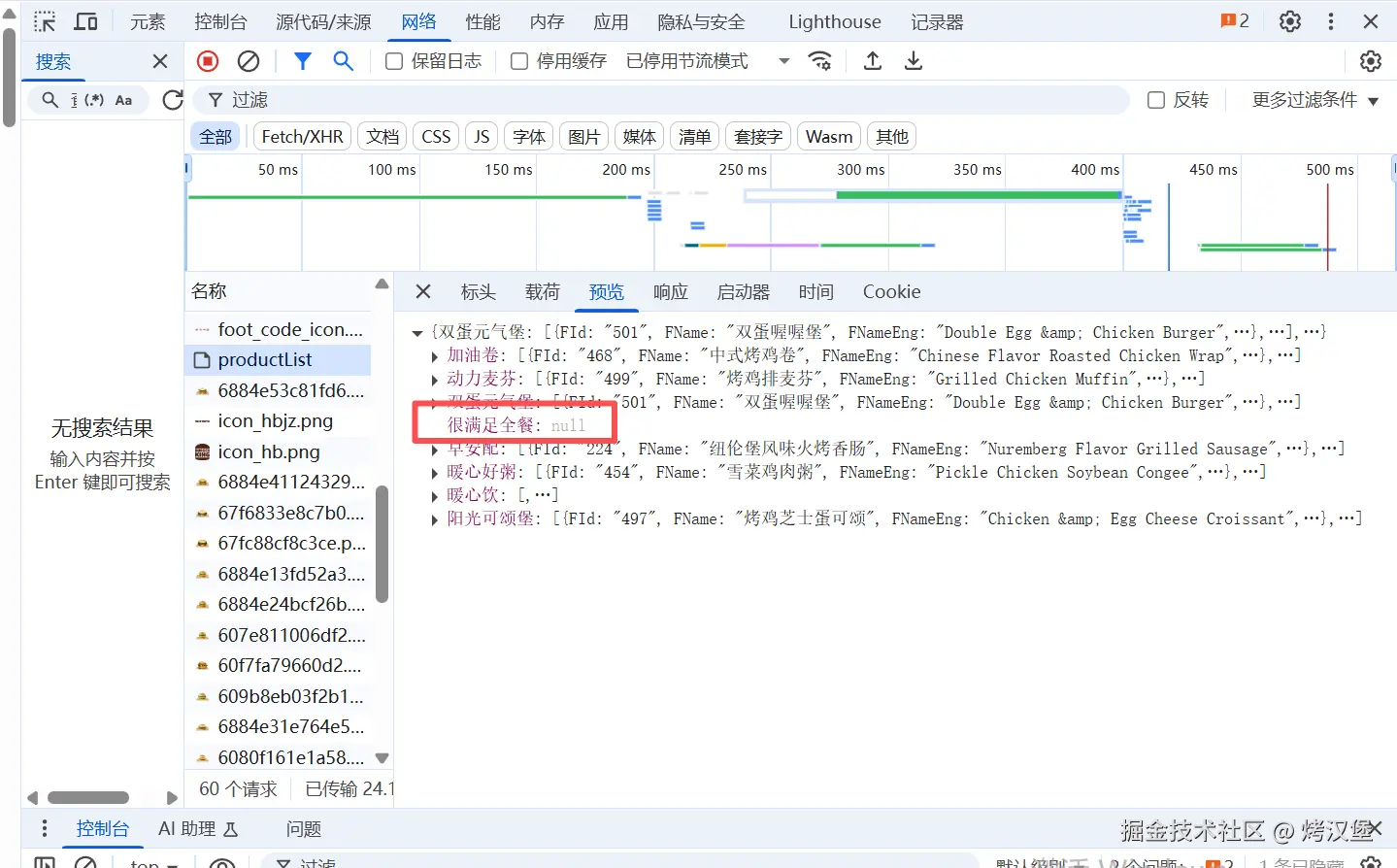
2.4 通过正则提取js代码中的系列参数
python
import requests
import re # 正则表达式模块
# 找到js所在的url
js_url = 'https://www.bkchina.cn/website/new/js/product.js'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
js_res = requests.get(js_url, headers=headers)
# 得到的响应结果调用text属性获取网页数据
js_str = js_res.text
# 用正则表达式获取到所有的符合表达式的结果放到列表中
# 贪婪模式:
# 基于当前表达式匹配到更多的数据
# 非贪婪模式:
# 基于当前表达式匹配到更少的数据
# type='(.*?)';
# 得到的列表前面有一个空值 用切片的方法切掉前面的空值
# ['', 'season', 'ham', 'snack', 'dessert', 'breakfirst', 'meats', 'coffee', 'happy_meal']
types = re.findall("type = '(.*?)';", js_str)[1:]
url = 'https://www.bkchina.cn/product/productList'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36'
}
# 遍历这个types列表将列表中的每一个值给到变量t
for t in types:
# 看控制页面载荷里面表单数据
# 通过字典保存表单数据
# 每经历一次for循环取一次列表里面types里面的值给到字典data
data = {
'type': t
}
# 因为是post请求方式,所以这里要用post请求获取网页数据的相应结果
res = requests.post(url, data=data)
res_data = res.json()
# 这种方法不灵活,只能获取季节新品这一个系列得数据
# 面对像汉堡这种有三种系列得数据就要去修改数据,不够灵活
# for i in res_data['季节新品']:
# FName = j.get('FName', '')
# FId = j.get('FId', '')
# print(FName, FId)
# 通过for循环遍历res_data字典中得每一个键
# 这里是默认取的字典里的每一个键名给到变量i
for i in res_data:
print(i)
# 输出结果时会报 'NoneType' object is not iterable的错误
# 很满足全餐这个列表为空,所以遍历的时候取不到值会报错
# 两种方法消除这个报错:
# 做个判断 如果这个列表为空则继续执行下面的程序
# if res_data[i] is None:
# continue
# 用try except抛出异常错误信息,看看具体报什么错误,或者也可以直接continue
try:
# 再通过for循环遍历字典内对应的键的值(这里的值是列表(嵌套字典))给到变量j
for j in res_data[i]:
# 用字典里的get查询方法 查看键为FName的值是什么,如果没有就返回空
FName = j.get('FName', '')
# 用字典里的get查询方法 查看键为FId的值是什么,如果没有就返回空
FId = j.get('FId', '')
print(FName, FId)
except:
continue2.5 注意事项
- POST请求的参数放在data中,以字典形式传递。
- 解析响应数据时,需要注意不同类型产品对应的键值对,确保正确获取产品名称。