1. 前言
本文旨在提供 征程 6E/M 计算平台的部署指南,将会从硬件、软件两部分进行介绍,本文整理了我们推荐的使用流程,和大家可能会用到的一些工具特性,以便于您更好地理解工具链。某个工具具体详细的使用说明,还请参考用户手册。
2. 征程 6EM 硬件配置

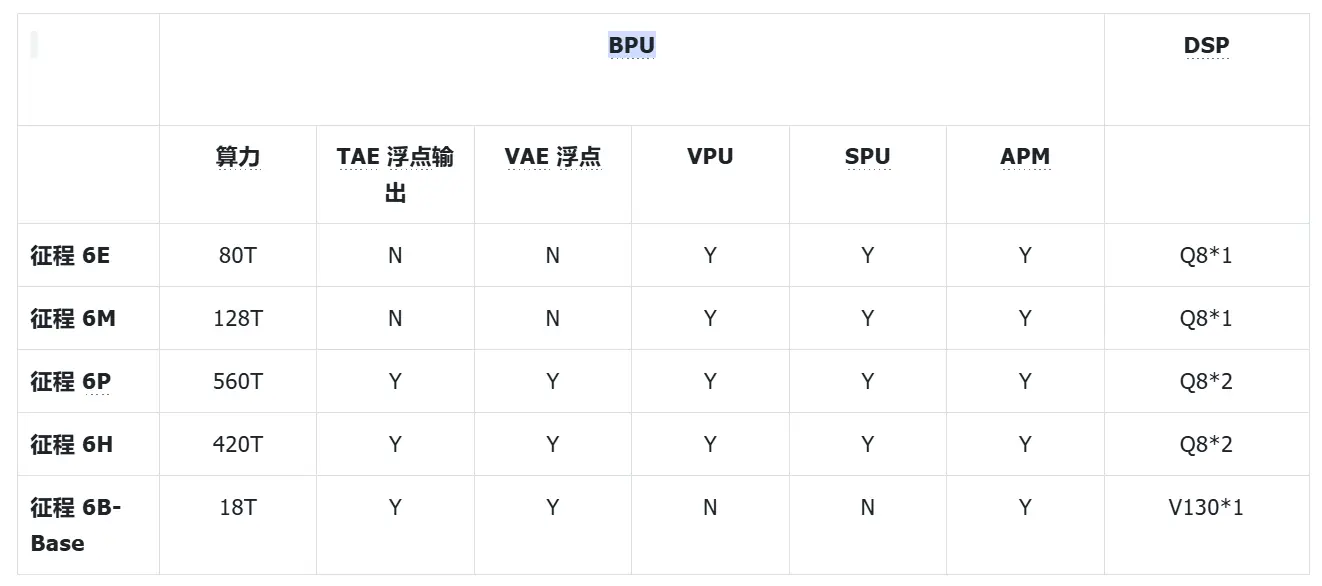
BPU 内部器件:
- TAE:BPU 内部的张量加速引擎,主要用于 Conv、MatMul、Linear 等 Gemm 类算子加速,支持 int8/int16 输入,int8/int16/int32 输出(仅模型输出层支持 int32 输出)
- AAE:Pooling、Resizer、Warping 等偏专用单元的集合,其中 Warping 可用于加速 Gridsample 等算子
- DTE:BPU 内部的数据排布变换引擎,支持各种维度的高效变换
- VAE:BPU 内部的 SIMD 向量加速引擎,可用于加速 Add、Mul、查表等 Vector 计算
- VPU:BPU 内部的 SIMT 向量加速单元,征程 6EM 可用于实现 Quantize、Dequantize 等算子
- SPU:BPU 内部的 RISC-V 标量加速单元,征程 6EM 可用于实现 TopK 等算子
- APM:BPU 内部另一块 RISC-V 标量加速单元,主要用于 BPU 任务调度等功能
3. 征程 6EM 工具链简介
3.1 模块架构图
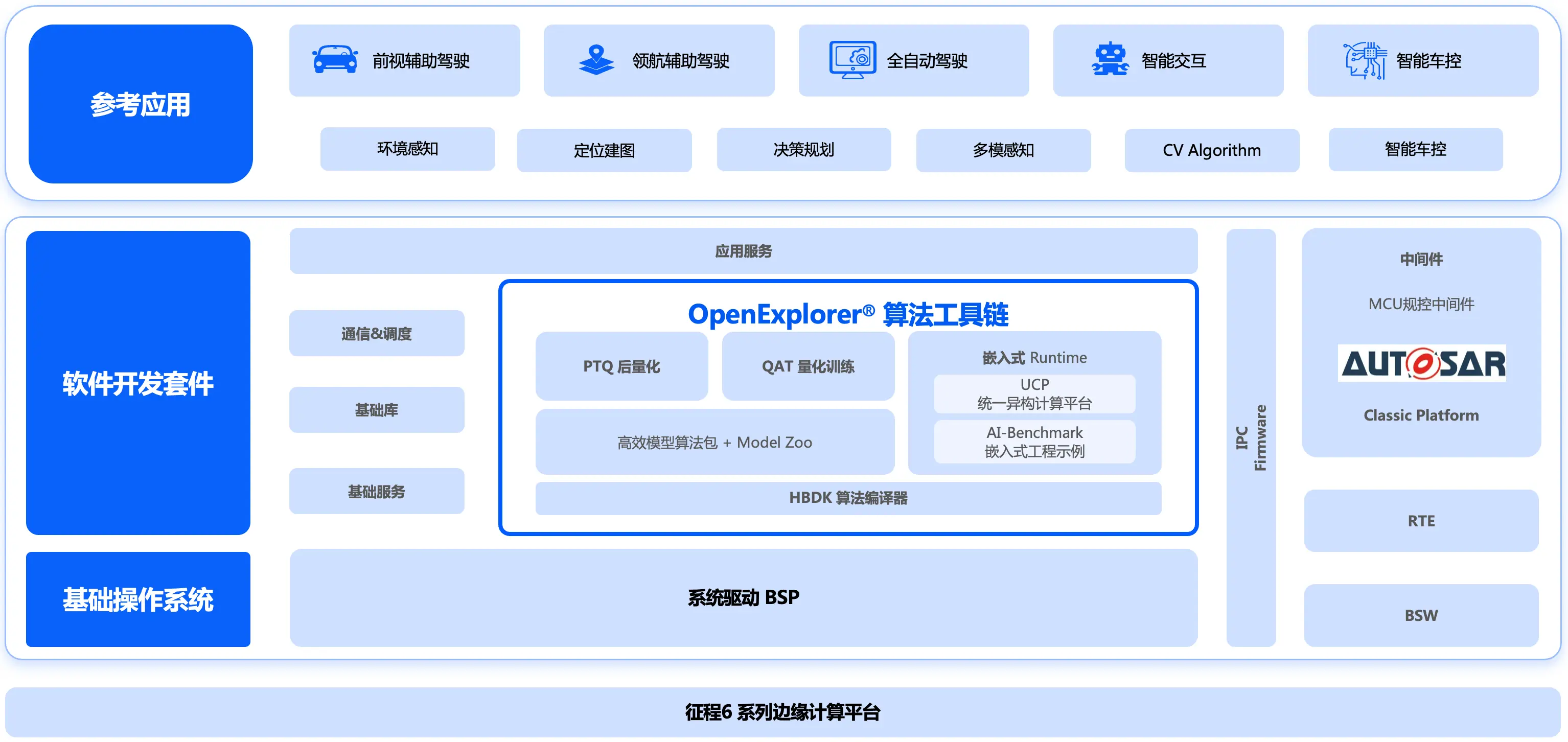
- PTQ :征程 6 工具链基于
horizon_tc_ui包封装的hb_compile命令行工具,提供 ONNX 模型 PTQ 全流程转换能力,其内部会先调用hmct包实现模型解析、图优化、校准功能,再调用hbdk4_compiler包实现模型的定点化和编译功能; - QAT :征程 6 工具链基于
horizon_plugin_pytorch包提供量化感知训练能力; - HBDK :征程 6 工具链编译器,基于
hbdk4_compiler包提供模型定点化、图修改、模型编译、静态 perf 等功能; - 高效模型算法包 :征程 6 工具链基于
horizon-torch-samples包,以源码开放形式提供了多场景参考算法,这些模型基于开源数据集训练,模型结构贴合地平线芯片进行了高效且用户友好的设计,并基于 QAT 链路实现了模型的量化转换; - UCP:征程 6 工具链统一计算平台,通过一套统一的异构编程接口实现了对 征程 6 计算平台相关计算资源的调用,提供视觉处理、模型推理、高性能计算库、自定义算子插件开发等功能;
- AI-Benchmark:征程 6 工具链基于预编译好模型提供的嵌入式工程示例,可实现模型的性能评测和精度评测。
3.2 两套模型转换链路
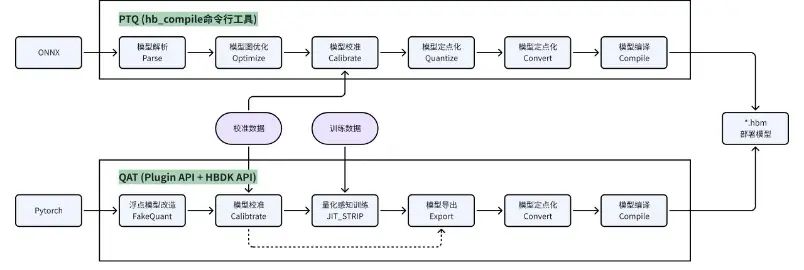
征程 6EM 工具链支持 PTQ(训练后量化)、QAT(量化感知训练)两套模型转换链路,其特性和优缺点如下:
- PTQ :基于
hb_compile命令行工具转换模型,配置好 yaml、校准数据集后,可一步实现模型的图优化、校准、量化、编译全流程。该量化方式快捷易用,但仅基于数学统计的方式量化不利于模型迭代,且可能会触发难以解决的 corner case,因此在量产项目中通常用于早期评测和简单模型的量化。 - QAT :在 PyTorch 开源框架上,基于
plugin插件的形式提供模型量化能力,并调用hbdk编译器的 API 实现模型的定点化和编译。该链路支持模型校准后进一步的 finetune 训练,虽然上手难度和训练成本都较高,但精度上限也更高,更利于模型迭代优化,是量产项目中的更优选择。
3.3 工具链推荐使用流程
鉴于两条量化链路的特性,我们建议的工具链使用流程如下:
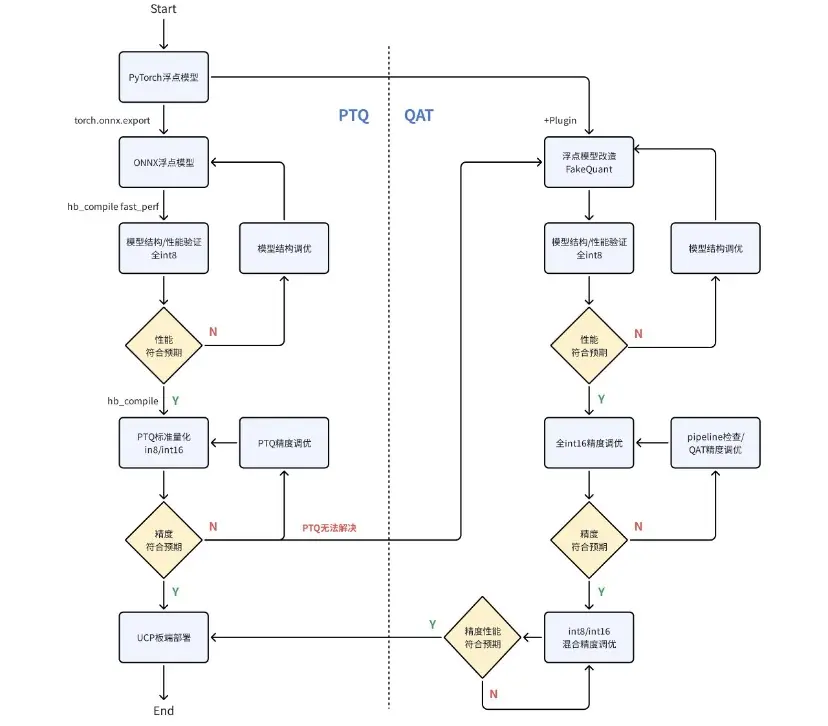
- Step1:先导出浮点 ONNX 模型(opset10~19),并基于 PTQ 链路进行快速的模型结构验证,全 int8 性能上限验证;若该性能符合预期,则可以精调 PTQ,若最终精度/精度都可同时满足预期,则可进行板端部署。
- Step2:如果遇到 PTQ 无法解决的精度 corner case,则需要转到 QAT 链路进行量化。依然建议先进行模型结构验证和全 int8 性能上限验证;若该性能符合预期,则优先在全 int16 配置下将精度训练至符合预期,然后再降低 int16 比例,实现 int8/int16 混合精度下的性能/精度调优,最终进行板端部署。
在以上推荐链路中:
- PTQ 链路的模型结构验证和标准量化,可在 X86 端参考本文 4.2 节使用
hb_compile命令行工具; - 模型性能分析和验证,可在 X86 端参考本文 6.4 节《静态 perf》使用
hbm_perf接口生成 html 分析文件,可在板端参考本文 8.2.1 节使用hrt_model_exec工具; - 模型推理,可在 X86 端参考用户手册《训练后量化-PTQ 转换工具-HBRuntime 推理库》,可在板端参考本文第 8 章《模型板端部署》使用 UCP 推理接口;
- 模型性能/精度调优,请见后续文章的详细介绍。
4. PTQ 链路
4.1 模型转换流程
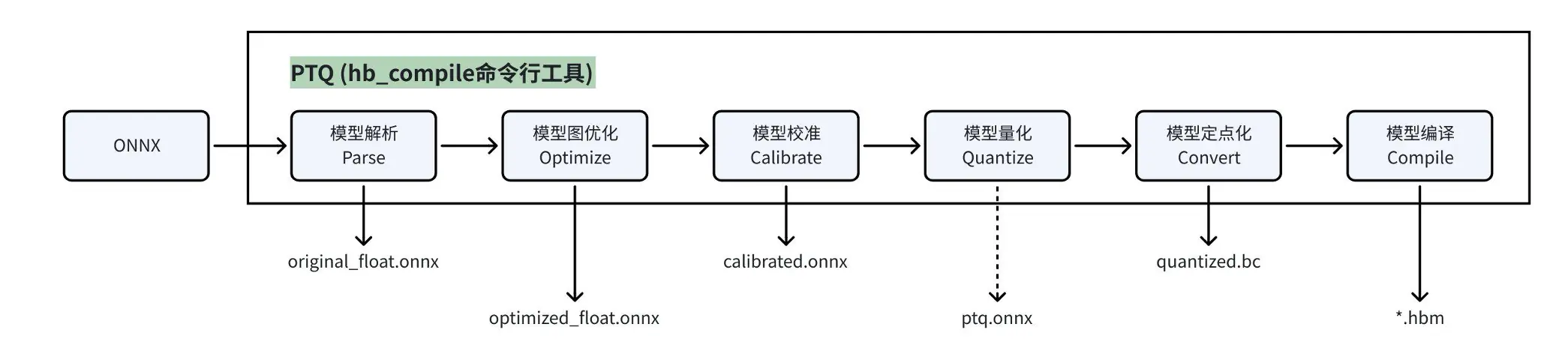
4.2 hb_compile 工具
hb_compile 为 PTQ 模型转换的命令行工具,支持以下 3 种使用方式:
| hb_compile**--marchnash-m-m**xxx.onnx | 模型检查,用于早期确认是否有 征程 6E/M 不支持的结构或算子 |
|---|---|
| hb_compile**--marchnash-m -mxxx.onnx--fast-perf** | |
| 快速性能评测,用于验证性能上限,工具会生成在板端运行性能最高的模型,工具内部主要会执行: | |
| 将 BPU 可执行算子算尽可能地运行在 BPU 上(int8) | |
| 删除模型首尾部可删除算子,如 Quantize/Dequantize、Cast、Transpose、、Reshape 等 | |
| 该功能执行后会在 。fast_perf 隐藏文件夹下生成一个 yaml 文件,您可以在其基础上做二次修改复用。 | |
| hb_compile**-c config.yaml** | 标准模型转换流程,精调模型性能/精度 |
4.3 PTQ 模型产出物
| original_float.onnx | 浮点 | 对 Caffe1.0 模型进行解析,转成 ONNX |
|---|---|---|
| optimized_float.onnx | 浮点 | 图优化,例如 BN 融合到 Conv |
| calibrated.onnx | 伪量化 | 插入校准节点,并基于校准数据计算统计到每个节点的量化参数 |
| ptq.onnx | 查表算子定点 + 其他算子伪量化 | 将查表算子定点化 |
| quantized.bc | 定点 | 整个模型定点化,并转换为地平线 hbir 中间表达 |
| hbm | 指令集 | 经过编译后的最终部署模型 |
4.4 PTQ 精度配置方法
在 config.yaml 中,支持通过 json 的方式配置 全局 、某类算子 、某个子图 、某个节点 的计算精度,可根据 BPU 算子支持约束进行配置。
Plain
# 校准参数组
calibration_parameters:
quant_config: './quant_config.json'4.5 PTQ 精度调优流程
请参考用户手册《训练后量化-PTQ 转换步骤-模型精度调优》和《训练后量化-PTQ 转换步骤-精度调优实战》章节。
5. QAT 链路
5.1 模型转换流程
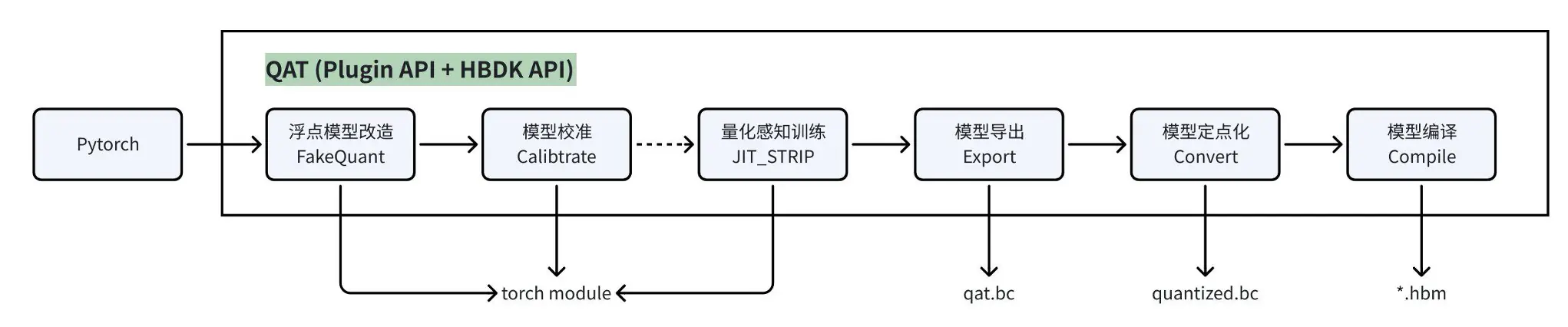
- 浮点模型改造:在模型前插入 QuantStub、在模型后插入 DequantStub,用于识别模型首尾部,剥离前后处理
- 模型校准 :通过在模型中插入 Observer 的方式,在 forward 过程中统计各处的数据分布,以计算出量化参数
- 部分模型仅通过 Calibration 便可满足精度要求,则无需进行 QAT,可直接编译模型用于部署
- 即使 Calibration 无法满足精度要求,也可降低后续 QAT 难度,缩短训练时间,提升最终训练精度
- 量化感知训练 :进一步通过训练的方式微调模型参数,如果 Calibration 精度较好,则推荐固定激活 scale
- JIT-STRIP:使用 hook 和 subclass tensor 的方式感知图结构,在原有 forward 上做算子替换/算子融合等操作,并且会根据模型中 QuantStub 和 DequantStub 的位置识别并跳过前后处理
- 优点:全自动,代码修改少,屏蔽了很多细节问题,便于 debug
- 缺点:动态代码块仍需要特殊处理
- JIT-STRIP:使用 hook 和 subclass tensor 的方式感知图结构,在原有 forward 上做算子替换/算子融合等操作,并且会根据模型中 QuantStub 和 DequantStub 的位置识别并跳过前后处理
5.2 QAT 精度配置方法
请见后续文章。
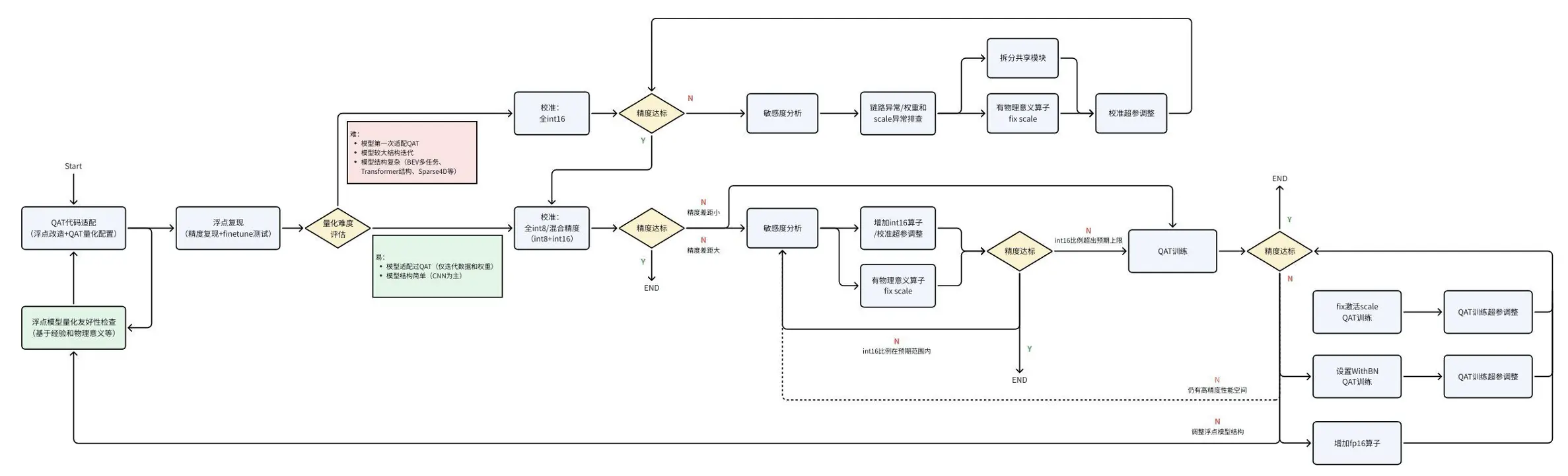
5.3 QAT 精度调优流程
6. 模型导出/定点化/编译
6.1 PTQ 链路
该流程封装在 hb_compile 中,相关参数通过 yaml 进行配置。若自行调用编译器接口执行,参考代码如下:
Plain
import onnx
from hbdk4.compiler.onnx import export
from hbdk4.compiler import convert, save, compile
# 经过PTQ校准得到的伪量化onnx模型,非线性的查表算子已定点
ptq_model = onnx.load("xxx_ptq_model.onnx")
# 导出查表算子定点+其他算子伪量化的hbir模型
qat_bc = export(ptq_model)
save(qat_bc, "qat.bc")
# 导出全定点hbir模型
quantized_bc = convert(qat_bc, "nash-b")
save(quantized_bc, "quantized.bc")
# 编译生成hbm模型
compile(
m=quantized_bc,
path="model.hbm",
opt=2,
march="nash-m",
progress_bar=True,
input_no_padding=True,
output_no_padding=True
)6.1.1 输入/输出去 padding
模型在 BPU 上推理时,其输入和输出节点的内存大小和数据存放规则需满足硬件对齐要求。
内存对齐:申请的内存大小需满足某个字节数的整数倍,
跨距对齐:跨距(Stride)是指数据存储在内存中时,每一行所占空间的实际大小,当对齐到某个字节数的整数倍后,硬件即可高效处理。该对齐的操作又叫 Padding,实际的对齐规则取决于具体的软硬件系统。假设一份 NHWC 为 1x20x30x1 的 int8 数据,若硬件要求跨距 W32 对齐,那么每一行 W 都将 Padding 2 个字节。
征程 6 工具链支持在 compile 接口中传入 input_no_padding、output_no_padding 参数来控制是否使用 BPU 自动完成 padding 对齐操作。开启后用户即可不关心 BPU 跨距对齐要求,无需手动 Padding,数据可连续存储在内存中。该特性可优化模型输入/输出的 IO 负载,但也有微小概率会引入性能的小幅下降,所以是否开启该功能请在您的模型上实际验证,并请在模型编译和板端部署环节统一跨距对齐的处理策略。
6.2 QAT 链路
QAT 链路的模型定点化和编译直接调用如上的编译器接口,模型导出额外封装了一层,参考代码如下:
Plain
from horizon_plugin_pytorch.quantization.hbdk4 import export
def export(
model: nn.Module,
example_inputs: Any,
name: str = "forward",
input_names: Optional[Any] = None, # 建议在模型导出时就配置好输入输出节点名称
output_names: Optional[Any] = None,
input_descs: Optional[Any] = None,
output_descs: Optional[Any] = None,
native_pytree: bool = True,
) -> Module6.3 模型修改
编译器支持在 hbir 上进行多 batch 拆分、插入数据前处理、算子删除、调整输入输出 layout 等修改操作,其主要应用场景如下:
多 batch 拆分:典型场景是 BEV 模型在部署时,多 V 输入来源于不同的摄像头,其数据在内存中独立存储,因此模型可将其多 V 输入沿 batch 维度做拆分;
数据前处理 :征程 6 工具链支持在模型前端插入一个前处理节点,以实现颜色空间转换(如 NV12---> BGR)、数据归一化((data-mean)/std),和 Resizer 功能(从大图上抠图 + Resize),并可由 BPU 进行加速;
算子删除:征程 6 工具链支持将模型首尾部的 Quantize、Dequantize、Cast、Reshape、Transpose 等算子删除,以适配更加灵活的部署方案;
调整输入输出 layout:模型首尾部除了支持删除 Reshape、Transpose 节点外,还支持插入 Transpose 节点,用户可灵活调整其 layout 排布。
以下参考代码对一个多输入模型实现了多 batch 输入拆分、图像输入的色彩空间转换、数据归一化、Resizer 功能:
Plain
from hbdk4.compiler import load, convert
qat_bc = load("qat.bc")
func = qat_bc[0]
batch_input = ["input_name1"] # 需要使用独立地址方式部署的输入节点名称列表
resizer_input = ["resize"] # 部署时数据来源于resizer的输入节点名称列表
pyramid_input = ["pym"] # 部署时数据来源于pyramid的输入节点名称列表
def channge_source(input, source):
node = input.insert_transpose(permutes=[0, 3, 1, 2])
node = node.insert_image_preprocess(mode="yuvbt601full2bgr", divisor=1, mean=[128, 128, 128], std=[128, 128, 128])
if source == "pyramid":
node.insert_image_convert("nv12")
elif source == "resizer":
node.insert_roi_resize("nv12")
for input in func.inputs[::-1]:
if input.name in batch_input:
origin_name = input.name
split_inputs = input.insert_split(dim=0)
for split_input in reversed(split_inputs):
if origin_name in pyramid_input:
channge_source(split_input, "pyramid")
elif origin_name in resizer_input:
channge_source(split_input, "resizer")6.4 静态 perf
对于编译好的 hbm,编译器支持在 X86 端对其 BPU 部分进行静态性能预估,执行以下命令即可生成一个 html 文件,包含模型预估性能、带宽、内存占用、BPU 内部单帧执行时序图等信息。
Plain
from hbdk4.compiler import hbm_perf
hbm_perf(model="xxx.hbm", output_dir="./")7. 浮点能力使用
7.1 硬件支持能力
征程 6EM BPU 中的 VPU 单元可提供一定的向量浮点计算能力,SPU 单元可提供一定的标量浮点计算能力。因此量化、反量化、TopK 等算子都可直接由 BPU 支持浮点计算,征程 6EM 详细的 BPU 浮点算子支持列表可参考用户手册《附录-工具链算子支持约束列表-算子 BPU 约束列表》。
在 OE-3.5.0 正式版本中,工具链已默认开启 BPU 已支持浮点算子的加速能力,用户仅需在 PTQ/QAT 链路中,将对应算子的量化精度配置为浮点即可使用。
7.2 量化/反量化处理
在 征程 6EM 平台,因为 VPU 浮点能力的加持,建议模型首尾部的量化/反量化算子可优先尝试将其保留在模型中。
编译器也同时支持使用以下接口将 quantized.bc 模型首尾部的量化/反量化节点移除,但移除后建议参考该篇文章(反量化节点的融合实现)将其融合进前后处理代码中,以减少一次数据遍历的冗余开销。
Plain
from hbdk4.compiler import load
quantized_bc = load("quantized.bc")
quantized_bc[0].remove_io_op(op_types=["Quantize", "Dequantize"])8. 模型板端部署
8.1 UCP 简介
UCP(Unify Compute Platform,统一计算平台)定义了一套统一的异构编程接口, 将 SOC 上的功能硬件抽象出来并进行封装,对外提供基于功能的 API 进行调用。UCP 提供的具体功能包括:视觉处理 (Vision Process)、神经网络模型推理 (Neural Network)、高性能计算库 (High Performance Library)、自定义算子插件开发。
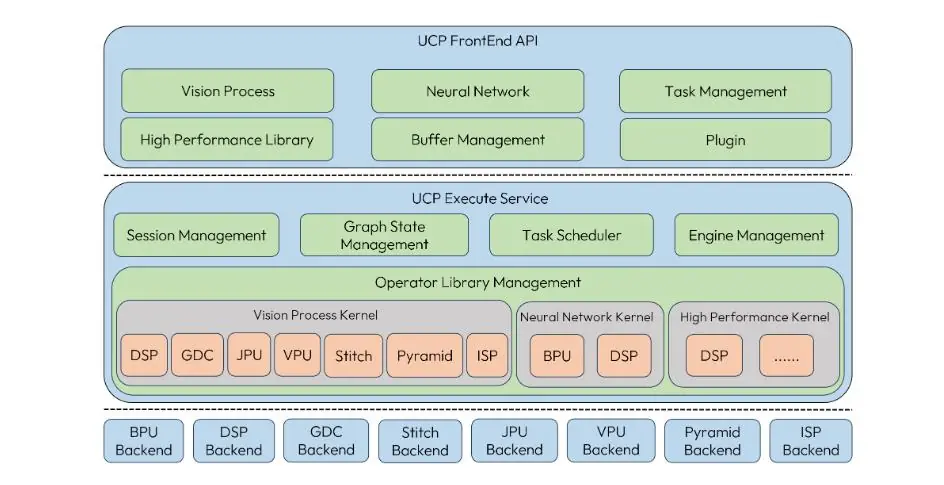
UCP 支持的 Backend 如下:

8.2 快速上手
使用 UCP 推理模型的基本代码参考如下,详细信息可参考用户手册《统一计算平台-模型推理开发》、《模型部署实践指导-模型部署实践指导实例》、《UCP 通用 API 介绍》等相关章节。
Plain
// 1. 加载模型并获取模型名称列表以及Handle
{
hbDNNInitializeFromFiles(&packed_dnn_handle, &modelFileName, 1);
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
}
// 2. 根据模型的输入输出信息准备张量
std::vector<hbDNNTensor> input_tensors;
std::vector<hbDNNTensor> output_tensors;
int input_count = 0;
int output_count = 0;
{
hbDNNGetInputCount(&input_count, dnn_handle);
hbDNNGetOutputCount(&output_count, dnn_handle);
input_tensors.resize(input_count);
output_tensors.resize(output_count);
prepare_tensor(input_tensors.data(), output_tensors.data(), dnn_handle);
}
// 3. 准备输入数据并填入对应的张量中
{
read_data_2_tensor(input_data, input_tensors);
// 确保更新输入后进行Flush操作以确保BPU使用正确的数据
for (int i = 0; i < input_count; i++) {
hbUCPMemFlush(&input_tensors[i].sysMem, HB_SYS_MEM_CACHE_CLEAN);
}
}
// 4. 创建任务并进行推理
{
// 创建任务
hbDNNInferV2(&task_handle, output_tensors.data(), input_tensors.data(), dnn_handle)
// 提交任务
hbUCPSchedParam sched_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sched_param);
sched_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &sched_param);
// 等待任务完成
hbUCPWaitTaskDone(task_handle, 0);
}
// 5. 处理输出数据
{
// 确保处理输出前进行Flush操作以确保读取的不是缓存中的脏数据
for (int i = 0; i < output_count; i++) {
hbUCPMemFlush(&output_tensors[i].sysMem, HB_SYS_MEM_CACHE_INVALIDATE);
}
// 对输出进行后处理操作
}
// 6. 释放资源
{
// 释放任务
hbUCPReleaseTask(task_handle);
// 释放输入内存
for (int i = 0; i < input_count; i++) {
hbUCPFree(&(input_tensors[i].sysMem));
}
// 释放输出内存
for (int i = 0; i < output_count; i++) {
hbUCPFree(&(output_tensors[i].sysMem));
}
// 释放模型
hbDNNRelease(packed_dnn_handle);
}8.2.1 hrt_model_exec 工具
为了方便用户快速查看 hbm 和 quantized.bc 的模型信息、进行模型单帧推理和性能评测,征程 6 工具链 UCP 提供了 hrt_model_exec 工具,并支持编译 X86、aarch64(aarch64 仅支持 hbm 推理)两个架构下的可执行程序。
hrt_model_exec 的三种使用方法如下:
Plain
# 设置环境变量
# arch代表架构类型,aarch64或x86
arch=aarch64
bin=../$arch/bin/hrt_model_exec
lib=../$arch/lib/
export LD_LIBRARY_PATH=${lib}:${LD_LIBRARY_PATH}
# 获取模型信息
${bin} model_info --model_file=xxx.hbm
# 模型单帧推理
${bin} infer --model_file=xxx.hbm --input_file=xxx.bin
# 模型性能评测-Latency(单线程)
${bin} perf --model_file=xxx.hbm --thread_num 1 --frame_count=1000
# 模型性能评测-FPS(多线程)
${bin} perf --model_file=xxx.hbm --thread_num 8 --frame_count=10008.3 图像输入动态 shape/stride
在 征程 6 芯片的视频通路上,有一块叫 Pyramid 的金字塔硬件处理模块,可提供 Camera 输入图像的缩放及 ROI 抠图能力,其输出为 nv12 类型的图像数据,并可基于共享内存机制直接给到 BPU 进行模型推理。因此在 征程 6 工具链中:
- Pyramid 模型指的是具有 nv12 图像输入的模型;
- Resizer 模型指的是具有 nv12 图像输入和 ROI 输入的模型,编译器支持通过 JIT 动态指令的方式,从 nv12 图像上完成 ROI 抠图 + Resize 的功能。
在 征程 6 工具链中,Pyramid 的输入 stride 为动态,Resizer 模型的 stride 和 shape 都是动态。如下为 mobilenetv1 编译后的模型信息:
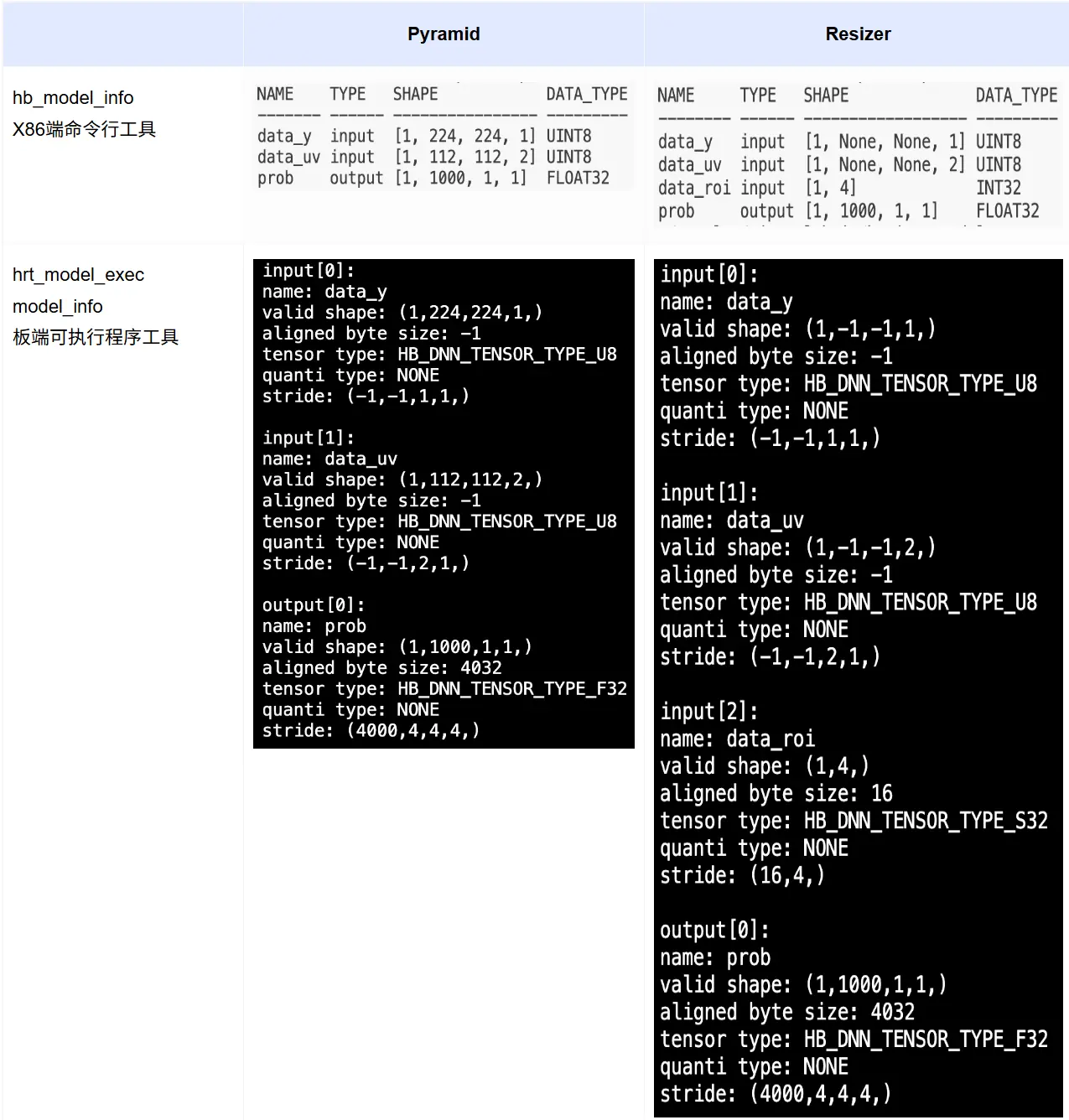
其中,-1 为占位符,表示为动态,Pyramid 输入的 stride 为动态;Resizer 输入的 H、W、stride 均为动态。
- Resizer 输入的 HW 动态,是因为原始输入的大小可以是任意的;
- Pyramid/Resizer 输入的 stride 动态 ,可以理解为是支持 Crop 功能 ,详细内容可参考用户手册《统一计算平台-模型推理开发-基础示例包使用说明-advanced_samples-crop》
8.4 非图像 tensor 内存对齐
对于非图像 tensor,征程 6EM 要求内存 64 对齐,征程 6B 要求 128 对齐,征程 6PH 要求 256 对齐。如上图所示,模型输出节点虽然 stride0 为 4000,但需要申请的 BPU 内存大小(aligned byte size)为 4032,即为 64 对齐的结果。
在模型实际部署中,非图像输入/输出节点所需申请的内存大小( aligned byte size)均可从模型节点属性的结构体中读取到(hbDNNTensorProperties),因此无需特别关注。
8.5 图像 tensor 跨距对齐
征程 6EMB 对于 Pyramid/Resizer 模型的图像输入,要求 W32 对齐,征程 6PH 要求 W64 对齐。若您有 征程 6 不同架构平台迁移的场景,请注意跨距对齐要求的差异。
部署代码建议您避免 hard code,推荐基于模型节点属性中的 validShape(张量有效内容尺寸)和 stride(张量各维度步长)进行解析和使用。
8.5.1 Pyramid 输入
Pyramid 输入 tensor 准备的参考代码如下:
Plain
hbDNNTensor *input = input_tensor;
for (int i = 0; i < input_count; i++) {
HB_CHECK_SUCCESS(
hbDNNGetInputTensorProperties(&input[i].properties, dnn_handle, i),
"hbDNNGetInputTensorProperties failed");
auto dim_len = input[i].properties.validShape.numDimensions; // 获取维度信息
for (int32_t dim_i = dim_len - 1; dim_i >= 0; --dim_i) {
if (input[i].properties.stride[dim_i] == -1) { // stride=-1即为动态
auto cur_stride = // 计算当前维度stride
input[i].properties.stride[dim_i + 1] *
input[i].properties.validShape.dimensionSize[dim_i + 1];
input[i].properties.stride[dim_i] = ALIGN_32(cur_stride); // 32对齐
}
}
int input_memSize = input[i].properties.stride[0] * // 计算内存大小
input[i].properties.validShape.dimensionSize[0];
HB_CHECK_SUCCESS(hbUCPMallocCached(&input[i].sysMem[0], input_memSize, 0),
"hbUCPMallocCached failed");
const char *input_name;
HB_CHECK_SUCCESS(hbDNNGetInputName(&input_name, dnn_handle, i), // 获取节点名称
"hbDNNGetInputName failed");
}示例:
Plain
ucp_tutorial/dnn/basic_samples/code/00_quick_start/resnet_nv12/src/main.cc注意:
视频通路上的金字塔硬件,其输出层支持配置 y、uv 的 stride,但仅要求 W16 对齐,若数据需要喂给 BPU 推理模型,建议直接按 BPU 的跨距对齐要求来配置。金字塔硬件的更多信息请参考系统软件用户手册。
8.5.2 Resizer 输入
Resizer 输入的 H、W 也是动态的,因此需要设置为原图尺寸,并计算好 W32 对齐的 Stride;ROI 作为模型输入节点,也需要对其进行赋值。以下为参考代码:
Plain
#define ALIGN(value, alignment) (((value) + ((alignment)-1)) & ~((alignment)-1))
#define ALIGN_32(value) ALIGN(value, 32)
int prepare_image_tensor(const std::vector<hbUCPSysMem> &image_mem, int input_h,
int input_w, hbDNNHandle_t dnn_handle,
std::vector<hbDNNTensor> &input_tensor) {
// 准备Y、UV输入tensor
for (int i = 0; i < 2; i++) {
HB_CHECK_SUCCESS(hbDNNGetInputTensorProperties(&input_tensor[i].properties,
dnn_handle, i),
"hbDNNGetInputTensorProperties failed");
// auto w_stride = ALIGN_32(input_w);
// int32_t y_mem_size = input_h * w_stride;
input_tensor[i].sysMem[0] = image_mem[i];
// 配置原图大小,NHWC
input_tensor[i].properties.validShape.dimensionSize[1] = input_h;
input_tensor[i].properties.validShape.dimensionSize[2] = input_w;
if (i == 1) {
// UV输入大小为Y的1/2
input_tensor[i].properties.validShape.dimensionSize[1] /= 2;
input_tensor[i].properties.validShape.dimensionSize[2] /= 2;
}
// stride满足32对齐
input_tensor[i].properties.stride[1] =
ALIGN_32(input_tensor[i].properties.stride[2] *
input_tensor[i].properties.validShape.dimensionSize[2]);
input_tensor[i].properties.stride[0] =
input_tensor[i].properties.stride[1] *
input_tensor[i].properties.validShape.dimensionSize[1];
}
return 0;
}
// 准备roi输入tensor
int prepare_roi_tensor(const hbUCPSysMem *roi_mem, hbDNNHandle_t dnn_handle,
int32_t roi_tensor_id, hbDNNTensor *roi_tensor) {
HB_CHECK_SUCCESS(hbDNNGetInputTensorProperties(&roi_tensor->properties,
dnn_handle, roi_tensor_id),
"hbDNNGetInputTensorProperties failed");
roi_tensor->sysMem[0] = *roi_mem;
return 0;
}
int prepare_roi_mem(const std::vector<hbDNNRoi> &rois,
std::vector<hbUCPSysMem> &roi_mem) {
auto roi_size = rois.size();
roi_mem.resize(roi_size);
for (auto i = 0; i < roi_size; ++i) {
int32_t mem_size = 4 * sizeof(int32_t);
HB_CHECK_SUCCESS(hbUCPMallocCached(&roi_mem[i], mem_size, 0),
"hbUCPMallocCached failed");
int32_t *roi_data = reinterpret_cast<int32_t *>(roi_mem[i].virAddr);
roi_data[0] = rois[i].left;
roi_data[1] = rois[i].top;
roi_data[2] = rois[i].right;
roi_data[3] = rois[i].bottom;
hbUCPMemFlush(&roi_mem[i], HB_SYS_MEM_CACHE_CLEAN);
}
return 0;
}示例:
Plain
ucp_tutorial/dnn/basic_samples/code/02_advanced_samples/roi_infer/src/roi_infer.cc8.6 小模型批量处理功能
由于 BPU 是资源独占式硬件,所以对于 Latency 很小的模型而言,其框架调度开销占比会相对较大。在 征程 6 平台,UCP 支持通过复用 task_handle 的方式,将多个小模型任务一次性下发,全部执行完成后再一次性返回,从而可将 N 次框架调度开销合并为 1 次,以下为参考代码:
Plain
// 获取模型指针并存储
std::vector<hbDNNHandle_t> model_handles;
// 准备各个模型的输入输出,准备过程省略
std::vector<std::vector<hbDNNTensor>> inputs;
std::vector<std::vector<hbDNNTensor>> outputs;
// 创建任务并进行推理
{
// 创建并添加任务,复用task_handle
hbUCPTaskHandle_t task_handle{nullptr};
for(size_t task_id{0U}; task_id < inputs.size(); task_id++){
hbDNNInferV2(&task_handle, outputs[task_id].data(), inputs[task_id].data(), model_handles[i]);
}
// 提交任务
hbUCPSchedParam sche_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sche_param);
sche_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &sche_param);
// 等待任务完成
hbUCPWaitTaskDone(task_handle, 0);
}8.7 优先级调度/抢占
UCP 支持任务优先级调度和抢占,可通过 hbUCPSchedParam 结构体进行配置,其中:
priority>customId> submit_time(任务提交时间)priority支持 0, 255,对于模型任务而言:- 0, 253 为普通优先级,不可抢占其他任务,但在未执行时支持按优先级进行排队
- 254 为 high 抢占任务,可支持抢占普通任务
- 255 为 urgent 抢占任务,可抢占普通任务和 high 抢占任务
- 可被中断抢占的低优任务,需要在模型编译阶段配置
max_time_per_fc参数拆分模型指令
- 其他 backend 任务,priority 支持 0, 255,但不支持抢占,可以认为都是普通优先级
8.8 直连/中继模式
UCP 框架还支持两种主要工作模式:直连模式、中继模式。系统默认运行在直连模式下,在中继模式下,UCP 将支持多进程任务的统一调度,即支持 priority 为 0, 253 的普通优先级任务的跨进程统一调度。
使用中继模式前,首先启动 ucp_service,service 文件位于 deps_aarch64/ucp/bin/service/ 路径下, 并通过环境变量 HB_UCP_ENABLE_RELAY_MODE=true 启用 Relay 模式,使得用户进程可以通过中继服务进行通信。 无论是直连模式还是中继模式,UCP 接口的调用方式保持一致,不会对编程逻辑产生影响。您可以根据实际需求灵活选择这两种模式,以满足系统在性能和灵活性方面的要求。
注意:
中继模式虽然可支持用户统一调度多进程间任务,但是也存在一些缺陷,包括:
- 需要做进程间通信和内存共享,整体的 CPU 负载更高;
- 模型任务底层资源的竞争都发送于 Service 进程内,相较于直连模式多个独立进程的竞争强度更高,任务的耗时可能受到影响。
8.9 X86 仿真
征程 6 工具链在 X86 端支持 hbm 指令仿真,但效率非常低,所以更推荐使用 quantized.bc 模型进行推理,其定点部分和 hbm 数值二进制一致,浮点部分可能存在架构本身差异,但通常对精度影响可忽略不计。
1. 推理 quantized.bc
Python 推理:
quantized.bc 在 X86 端的推理,可以使用 horizon_tc_ui 包封装的 HBRuntime 接口,具体可见用户手册《训练后量化-PTQ 转换工具-HBRuntime 推理库》,参考代码如下:
Plain
import numpy as np
from horizon_tc_ui.hb_runtime import HBRuntime
sess = HBRuntime("quantized.bc")
input_names = sess.input_names
output_names = sess.output_names
data1 = np.load("input1.npy")
data2 = np.load("input2.npy")
input_feed = {input_names[0]: data1, input_names[1]: data2}
output = sess.run(output_names, input_feed)quantized.bc 也可以直接调用其 func 的 feed 接口进行推理,其输入格式也为 dict,value 支持 torch.tensor 和 np.array 两种类型,输出格式与输入格式保持一致。参考代码如下:
Plain
import numpy as np
from hbdk4.compiler import load
hbir = load("quantized.bc")
func = hbir[0]
data1 = np.load("input1.npy")
data2 = np.load("input2.npy")
input_feed = {inputs[0].name: data1, inputs[1].name: data2}
hbir_outputs = func.feed(input_feed)C++ 推理:
quantized.bc 的 C++ 推理接口复用 hbm UCP 推理接口,仅 so 动态库需要替换成 X86 版本即可。 您也可以在 X86 端使用 hrt_model_exec 工具对 quantized.bc 进行模型信息查看和单帧推理。
2. 推理 hbm
由于 X86 端 hbm 推理为指令仿真,运行速度非常慢,因此工具链提供了 hbm_infer 工具以便用户在服务器端给直连的开发板下发推理任务。本文只介绍最简单的单进程使用方式,多进程、多阶段模型输入输出的传输优化,以及统计模型推理、网络传输耗时等功能请参考用户手册《hbm_infer 工具介绍》。
Plain
# hbm也可传入一个list,推理时通过指定model_name来选择推理哪个模型,推理所用的.so即可只传输一次
hbm_model = HbmRpcSession(
host="xx.xx.xx.xx",
local_hbm_path="xx.hbm",
)
# 打印模型输入输出信息
hbm_model.show_input_output_info()
# 准备输入数据
input_data = {
'img': torch.ones((1, 3, 224, 224), dtype=torch.int8)
}
# 执行推理并返回结果
# 若传入的是list,需要正确指定model_name
# output_data = hbm_model(input_data, model_name=model_name)
output_data = hbm_model(input_data)
print([output_data[k].shape for k in output_data])
# 关闭server
hbm_model.close_server()9. UCP 视觉处理/高性能算子
除模型推理外,UCP 还提供了视觉处理和高性能算子两大方向的多种算子接口,可支持诸如 Remap、Jpeg、H264/265、FFT/IFF 等功能,这些算子底层是基于地平线 SOC 上不同硬件 IP 进行的封装,并提供统一的调用接口。
更多信息可参考用户手册《统一计算平台》的相关章节。
注意:
板端实际部署时,ISP 到 Pyramid 的视频通路不建议使用 UCP,无法实现数据 Online,建议直接调用底软接口进行功能实现。
10. UCP 自定义算子(DSP)
为了简化用户开发,UCP 封装了一套基于 RPC 的开发框架,来实现 CPU 对 DSP 的功能调用,但具体 DSP 算子实现仍是调用 Cadence 接口去做开发。总体来说可分为三个步骤:
- 使用 Cadence 提供的工具及资料完成算子开发;
Plain
int test_custom_op(void *input, void *output, void *tm) {
// custom impl
return 0;
}- DSP 侧通过 UCP 提供的 API 注册算子,编译带自定义算子的镜像;
Plain
// dsp镜像中注册自定义算子
hb_dsp_register_fn(cmd, test_custom_op, latency)- ARM 侧通过 UCP 提供的算子调用接口,完成开发板上的部署使用。
Plain
// 将输入输出的hbUCPSysMem映射为DSP可访问的内存地址
hbUCPSysMem in;
hbUCPMalloc(&in, in_size, 0)
hbDSPAddrMap(&in, &in)
hbUCPSysMem out;
hbUCPMalloc(&out, out_size, 0)
hbDSPAddrMap(&out, &out)
// 创建并提交DSP任务
hbUCPTaskHandle_t taskHandle{nullptr};
hbDSPRpcV2(&taskHandle, &in, &out, cmd)
hbUCPSchedParam ctrl_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&ctrl_param);
ctrl_param.backend = HB_UCP_DSP_CORE_ANY;
hbUCPSubmitTask(task_handle, &ctrl_param);
// 等待任务完成
hbUCPWaitTaskDone(task_handle, 0);更多信息可见用户手册《统一计算平台-自定义算子-DSP 算子开发》。
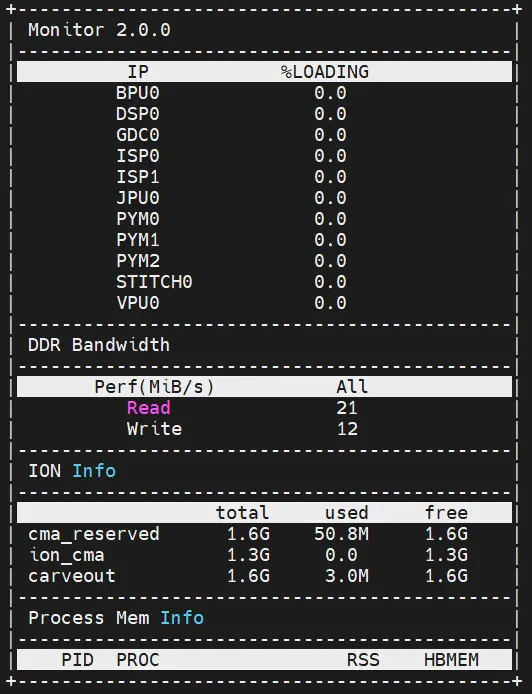
11. 性能监测工具
征程 6 平台 BPU、DSP 都是独占的硬件资源,任务一旦提交就会独占推理,UCP 侧仅能通过 hrt_ucp_monitor 工具去监测其硬件占用率(采样频率支持配置 10, 1000,默认 500),并且能查看到 DDR 内存占用情况。