【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
大多数深度学习的训练框架其实差异不大,都支持不同的激励函数,支持不同的layer定义,支持cuda训练,也支持自动求导、反向传播,更支持参数保存和onnx转换。不管怎么说,用公开的框架训练深度学习模型,要比自己写框架简单很多。下面,就看一下,怎么用pytorch训练第一个模型。
1、准备matplotlib
训练的时候经常需要看梯度和损失函数,所以需要安装一下matplotlib,
pip3.10.exe install matplotlib -i https://pypi.doubanio.com/simple2、准备好训练的数据
这里的数据是随机生成的,最终也是分成了两类。
# n_in - feature number
# n_h - hidden size
# n_out - two classification, 0 or 1
# batch_size - data number
n_in, n_h, n_out, batch_size=10,5,1,10
x=torch.randn(batch_size, n_in)
# target data
y=torch.tensor([[1.0], [0.0], [0.0],
[1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])3、构建网络模型
网络模型方面,除去输入输出,我们构建了一个四层网络,分别是全连接、ReLU、全连接和Sigmoid。直接用nn.Sequential添加即可。
model = nn.Sequential(
nn.Linear(n_in, n_h),
nn.ReLU(),
nn.Linear(n_h, n_out),
nn.Sigmoid()
)4、准备好残差方程和优化方法
深度学习主要就是靠梯度向量,来优化模型里面的参数,从而使得残差方程的数值最小。所以这里有必要选择好对应的残差方程和优化方法。
criterion=torch.nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(), lr=0.01)
losses=[]5、开始训练
训练的过程基本和我们之前自己写的框架是一样的,即预测、计算损失、反向传播得到梯度、更新参数。
for epoch in range(50):
y_pred = model(x) # predict was invoked here
loss=criterion(y_pred, y)
losses.append(loss.item())
print(f'Epoch [{epoch+1}/50], Loss: {loss.item():.4f}')
optimizer.zero_grad()
loss.backward()
optimizer.step()6、利用matplotlib打印损失
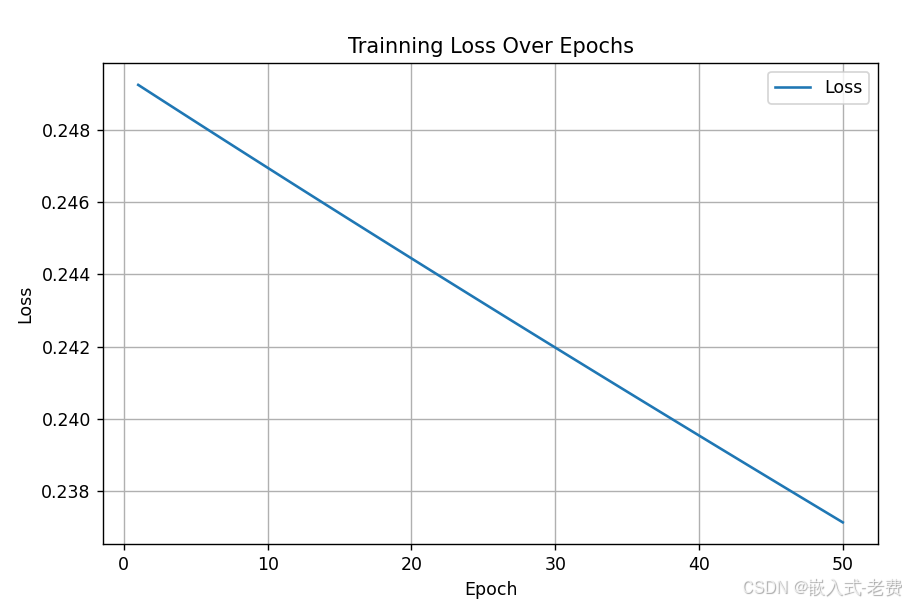
一般为了验证model的梯度是不是真的在下降,残差方程的损失是不是真的在减少,我们会用matplotlib对它们进行打印。如果下降比较慢,或者梯度消失,就要想想别的办法了。
plt.figure(figsize=(8,5))
plt.plot(range(1,51), losses, label='Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Trainning Loss Over Epochs')
plt.legend()
plt.grid()
plt.show()7、保存模型、安装onnxscript
训练的模型一般需要保存下来,方便下次继续训练或者直接使用,
torch.save(model, 'save.pt') # save
model = torch.load("save.pt") # load
model.eval()如果需要转换成onnx,那么首先需要安装onnxscript,
pip3.10.exe install onnxscript -i https://pypi.doubanio.com/simple接着直接调用torch.onnx.export即可,
dummy_input = torch.randn(1, n_in)
torch.onnx.export(
model,
dummy_input,
"model.onnx",
export_params=True,
opset_version=18,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)需要转成ncnn模型和参数的,可以参考这个链接,
https://github.com/Tencent/ncnn/wiki/use-ncnn-with-pytorch-or-onnx8、完整代码
最后给出完整代码,有兴趣的同学可以好好测试下,
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# n_in - feature number
# n_h - hidden size
# n_out - two classification, 0 or 1
# batch_size - data number
n_in, n_h, n_out, batch_size=10,5,1,10
x=torch.randn(batch_size, n_in)
# target data
y=torch.tensor([[1.0], [0.0], [0.0],
[1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])
# construct network model
model = nn.Sequential(
nn.Linear(n_in, n_h),
nn.ReLU(),
nn.Linear(n_h, n_out),
nn.Sigmoid()
)
# set loss and optimization function
criterion=torch.nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(), lr=0.01)
losses=[]
# trainig starts here
for epoch in range(50):
y_pred = model(x) # predict was invoked here
loss=criterion(y_pred, y)
losses.append(loss.item())
print(f'Epoch [{epoch+1}/50], Loss: {loss.item():.4f}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
# show loss here
plt.figure(figsize=(8,5))
plt.plot(range(1,51), losses, label='Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Trainning Loss Over Epochs')
plt.legend()
plt.grid()
plt.show()
# save model here
torch.save(model, 'save.pt')
dummy_input = torch.randn(1, n_in)
torch.onnx.export(
model,
dummy_input,
"model.onnx",
export_params=True,
opset_version=18,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)