FPGA教程系列-Vivado复数乘法的实现(IP核与非IP核)
复数乘法
大学知识,理工科必学,就不再赘述了。
在Vivado中,复数乘法的实现方式有很多种,可以用乘法器IP核,甚至可以直接用操作符*,还有复数乘法器的IP核,直接输出结果。先diy一个看看效果。
Top文件
verilog
`timescale 1ns / 1ps
module complex_multiplier_diy(
input wire i_clk,
input wire i_rst,
input wire signed [11:0] i_a, // Real part of first complex number
input wire signed [11:0] i_b, // Imaginary part of first complex number
input wire signed [11:0] i_c, // Real part of second complex number
input wire signed [11:0] i_d, // Imaginary part of second complex number
output reg signed [23:0] o_R, // Real part of the product
output reg signed [23:0] o_I // Imaginary part of the product
);
// --- Stage 1: Multiplication ---
// Intermediate wires for the first pipeline stage
wire signed [11:0] a_plus_b;
wire signed [11:0] c_plus_d;
wire signed [23:0] p_ac; // Product of A*C
wire signed [23:0] p_bd; // Product of B*D
wire signed [23:0] p_sum;// Product of (A+B)*(C+D)
// Combinational logic for additions before multiplication
assign a_plus_b = i_a + i_b;
assign c_plus_d = i_c + i_d;
// Infer 3 multipliers (DSP slices)
assign p_ac = i_a * i_c;
assign p_bd = i_b * i_d;
assign p_sum = a_plus_b * c_plus_d;
// Pipeline registers between Stage 1 and Stage 2
reg signed [23:0] p_ac_reg;
reg signed [23:0] p_bd_reg;
reg signed [23:0] p_sum_reg;
// --- Stage 2: Addition/Subtraction ---
// This always block performs the pipeline register update and the final calculation.
always @(posedge i_clk) begin
if (i_rst) begin
// Reset all pipeline registers and outputs
p_ac_reg <= 24'b0;
p_bd_reg <= 24'b0;
p_sum_reg <= 24'b0;
o_R <= 24'b0;
o_I <= 24'b0;
end else begin
// Stage 1 to Stage 2 pipeline registers
p_ac_reg <= p_ac;
p_bd_reg <= p_bd;
p_sum_reg <= p_sum;
// Stage 2: Perform additions/subtrictions using registered values
o_R <= p_ac_reg - p_bd_reg;
o_I <= p_sum_reg - p_ac_reg - p_bd_reg;
end
end
endmodule这个的优点是相对于4个乘法器,用了三个,资源占用少了一些。
Testbench
verilog
`timescale 1ns / 1ps
module complex_multiplier_diy_tb;
reg i_clk;
reg i_rst;
reg signed[11:0] i_a,i_b;
reg signed[11:0] i_c,i_d;
wire signed[23:0]o_R;
wire signed[23:0]o_I;
complex_multiplier_diy uut (
.i_clk(i_clk),
.i_rst(i_rst),
.i_a (i_a),
.i_b (i_b),
.i_c (i_c),
.i_d (i_d),
.o_R (o_R),
.o_I (o_I)
);
initial
begin
i_clk = 1'b1;
i_rst = 1'b1;
#100
i_rst = 1'b0;
end
initial
begin
i_a = 12'd10;
i_b = 12'd20;
i_c = 12'd30;
i_d = 12'd40;
end
always #5 i_clk = ~i_clk;
endmodule输入10+20i,30+40i,输出-500+1000i
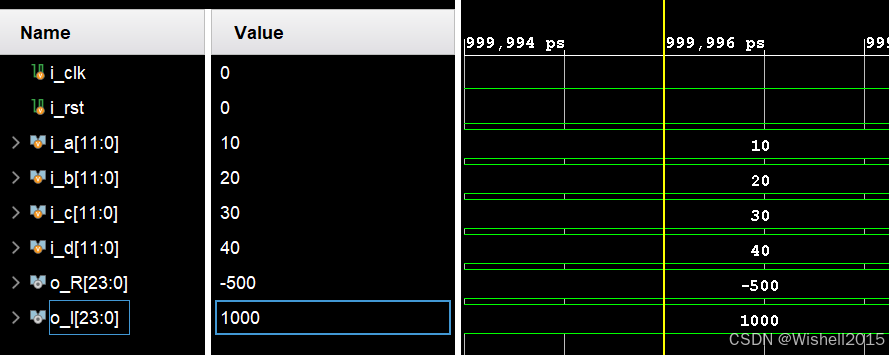
结果一致。
使用复数IP核
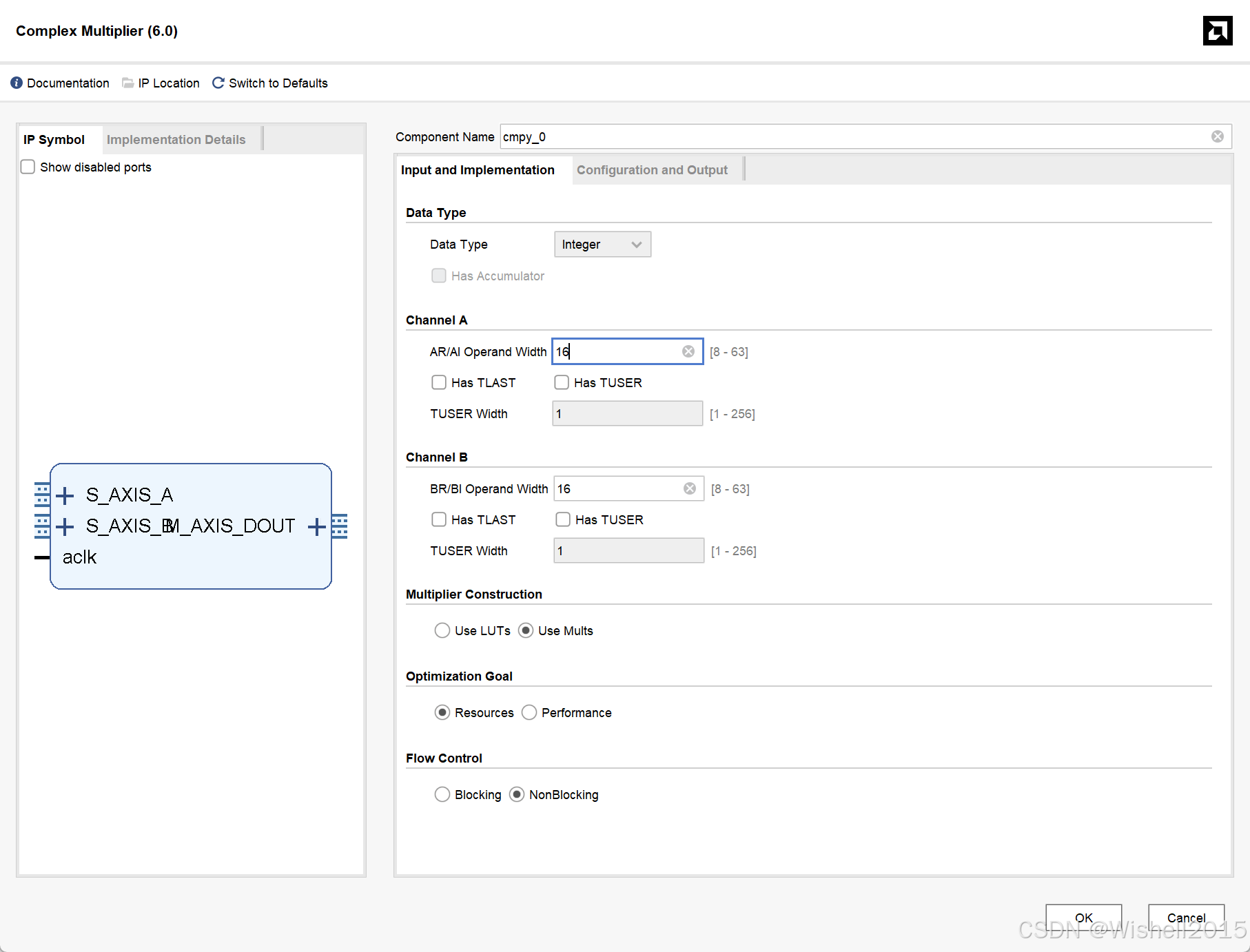
**数据类型(Data Type):**Integer(整数)或Float(浮点数)。定义操作数的数据类型。
通道配置(Channel A/B): AR/AI Operand Width(通道实部/虚部位宽),范围:8~63位。
- Has TLAST:启用TLAST信号(AXI Stream接口的数据包结束标志),用于多帧数据同步。
- Has TUSER:启用TUSER信号(用户自定义信号),传递额外控制信息(如数据帧号)。
- TUSER Width:设置TUSER信号的位宽(1~256位)。
乘法器构造(Multiplier Construction):Use LUTs 使用FPGA的查找表(LUT)实现乘法器。Use Mults使用FPGA的专用乘法器(DSP48E)实现。
优化目标(Optimization Goal):Resources 优先优化资源占用(减少DSP或LUT使用量)。Performance:优先优化性能(提高运算速度和时钟频率)。
流控制(Flow Control):Blocking :阻塞式流控制(接收端准备好后才发送数据)。NonBlocking:非阻塞式流控制(持续发送数据,忽略接收端状态)。
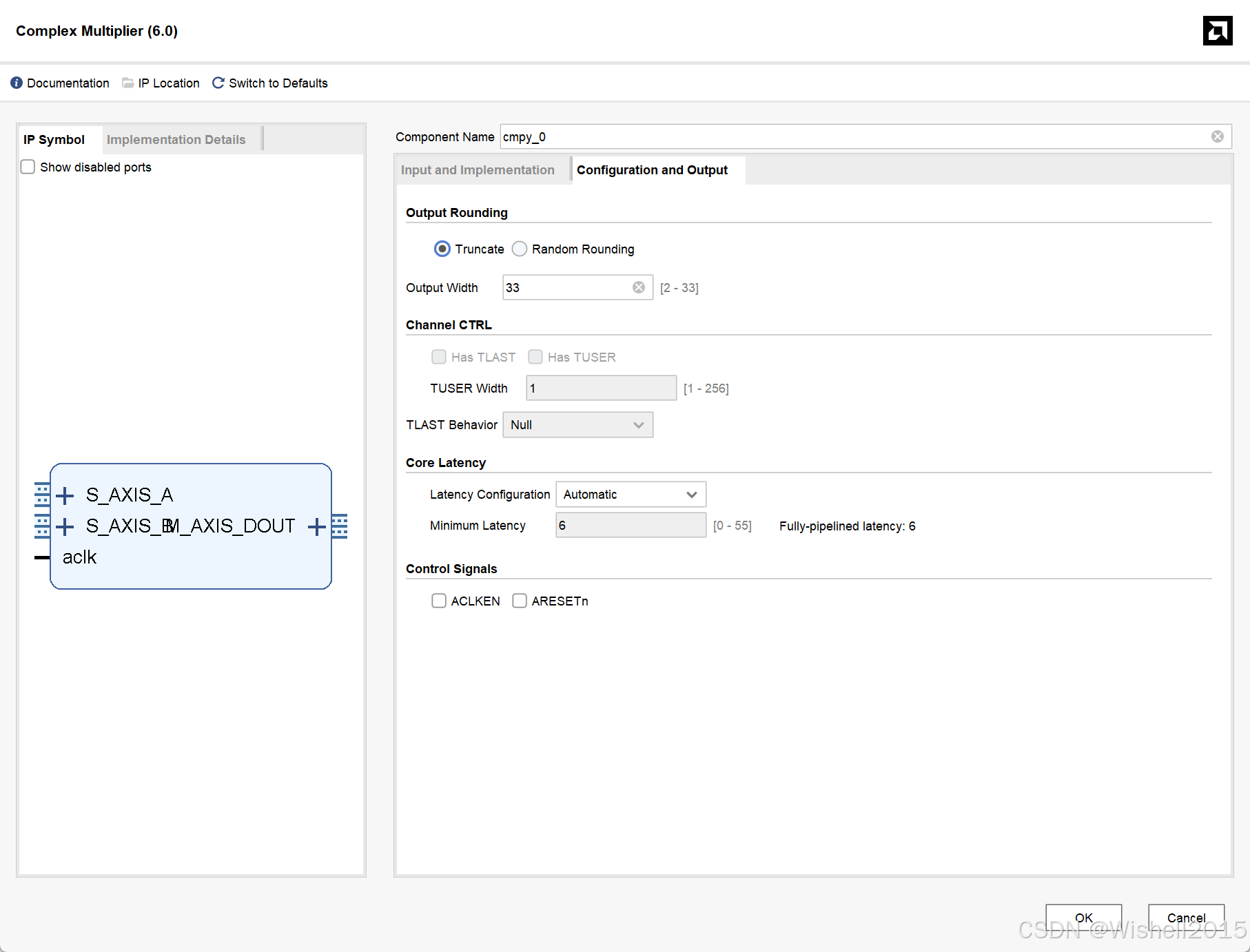
Output Rounding (输出舍入)
- Truncate (截断) :直接丢弃多余的低位。例如,一个33位的结果要存入32位宽的端口,直接砍掉最低的1位。
- Random Rounding (随机舍入) :一种更复杂的舍入算法,旨在减少系统性误差。
Output Width (输出位宽): 设置乘法器输出端口的位宽。
通道控制: 这部分选项用于配置AXI4-Stream数据流接口的辅助信号。
Has TLAST :是否启用 TLAST 信号。
Has TUSER :是否启用 TUSER 信号。
TUSER Width :设置 TUSER 信号的位宽。
TLAST Behavior :定义 TLAST 信号如何通过这个IP核。
核心延迟: 控制IP核的流水线深度。
Latency Configuration (延迟配置)
- Automatic (自动) ::让Vivado综合工具根据您的其他设置(如优化目标)自动选择最优的延迟。
- Manual (手动) :由用户手动指定一个固定的延迟值。
Minimum Latency (最小延迟) :设置希望IP核实现的最小延迟(时钟周期数)。
控制信号
-
ACLKEN:是否启用时钟使能信号。
-
ARESETn: :是否启用异步复位信号。
使用复数乘法器IP核仿真实现
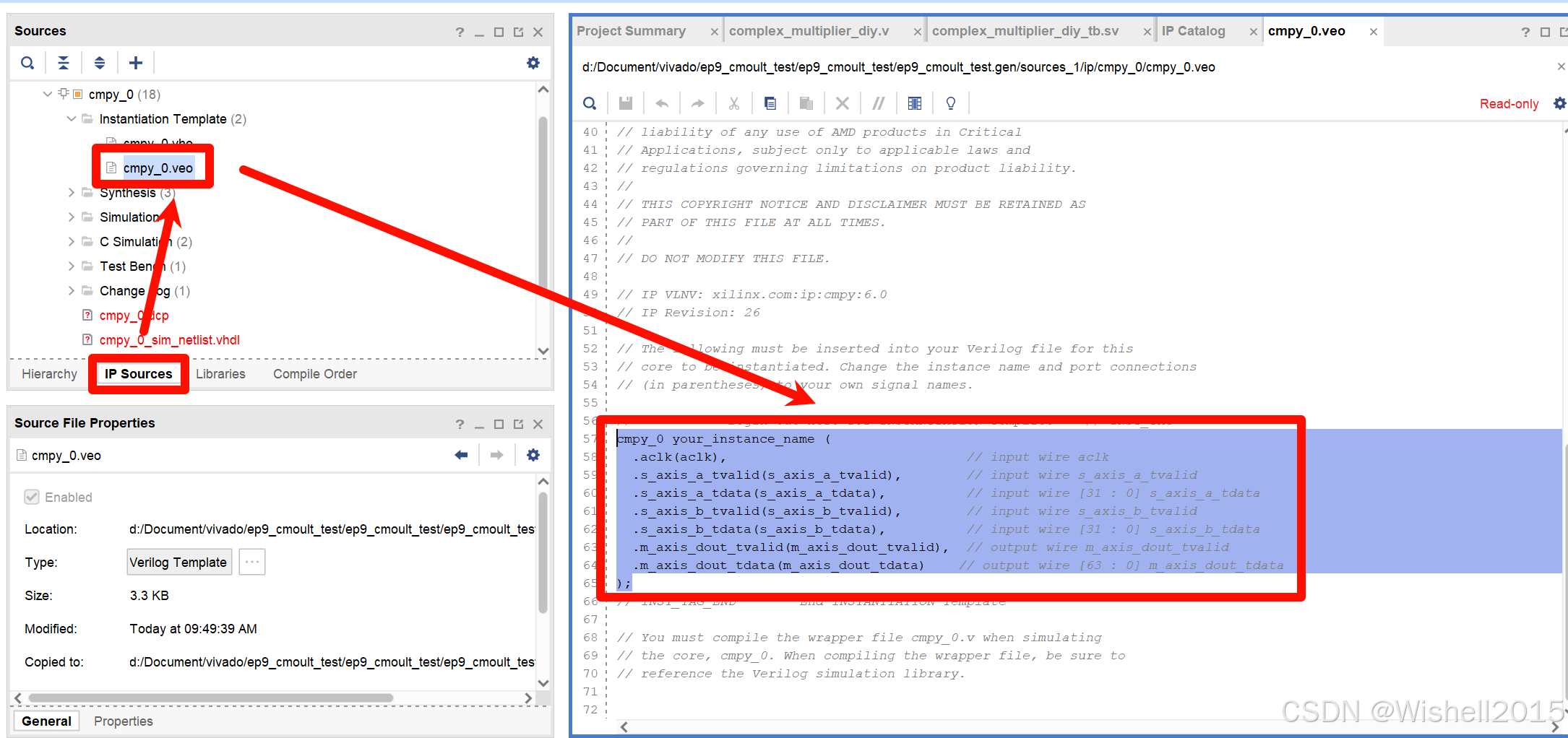
把例化的部分更换为生成的IP核:
需要注意的是位宽的不一致,应该是与AXI通信协议有关,所以只要满足例化需求就可以了。暂时不深究
verilog
wire [79:0]m_axis_dout_tdata;
cmpy_0 cmpy_u (
.aclk(i_clk), // input wire aclk
.s_axis_a_tvalid(1), // input wire s_axis_a_tvalid
.s_axis_a_tdata({4'b0000,i_b,4'b0000,i_a}), // input wire [31 : 0] s_axis_a_tdata
.s_axis_b_tvalid(1), // input wire s_axis_b_tvalid
.s_axis_b_tdata({4'b0000,i_d,4'b0000,i_c}), // input wire [31 : 0] s_axis_b_tdata
.m_axis_dout_tvalid(), // output wire m_axis_dout_tvalid
.m_axis_dout_tdata(m_axis_dout_tdata) // output wire [79 : 0] m_axis_dout_tdata
);
assign o_R=m_axis_dout_tdata[23:0];
assign o_I=m_axis_dout_tdata[63:40];仿真,观察输出,与diy的结果应该保持一致。