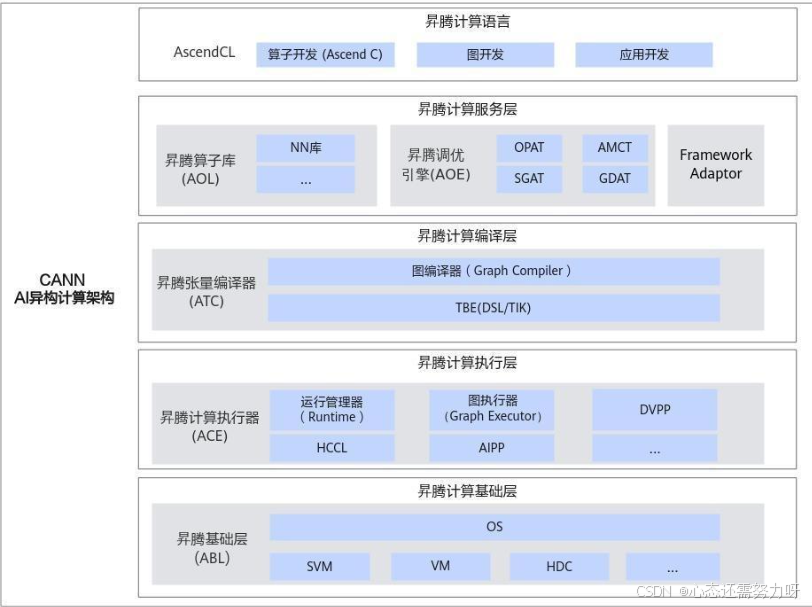
在模型规模不断扩张、推理场景多样化的趋势下,算子性能已经直接成为 AI 系统性能瓶颈的决定性因素。 对于昇腾 AI 开发者而言,CANN(Compute Architecture for Neural Networks)不仅提供了稳定、统一、自动化的算子执行体系,更提供了从 高层调用(ACLNN)到底层算子实现(Ascend C)再到图优化与内存调度 的软硬自研能力,使得性能优化可控、可调、可精确定位。
其中,ACLNN(Ascend Compute Library for Neural Networks) 是模型执行阶段最重要的核心组件之一,它面向框架和业务开发者,以"开箱即用 + 可渐进优化"的方式,帮助开发者快速获得可靠的算子性能,同时又保留深度调优空间。
本文重点介绍 CANN 的核心价值 & ACLNN 算子性能优化路径,通过一个真实优化案例说明如何实现从瓶颈定位到性能提升的闭环过程。
一. CANN 的整体能力体系:从框架到硬件的协同
CANN 在昇腾软硬件栈中承担着"计算支撑层"的角色:
|------------------------------------|---------------------|------------|
| 层级 | 职责 | 面向对象 |
| 框架适配(PyTorch、MindSpore、TensorFlow) | 模型表达 & 自动图转换 | 应用开发者 |
| ACL/ACLNN 调用接口 | 算子执行与资源调度 | 算子/模型调度开发者 |
| Ascend C + CATLASS 模板库 | 高性能算子内核构建 | 自定义算子开发者 |
| 图优化 & 通算流水 | 内存、算子并行、Cache Reuse | 系统性能优化开发者 |
其中 ACLNN 位于中间关键层,优势包括:
-
成熟算子库:覆盖 CNN/Transformer/图像/矩阵计算等主流场景
-
自动调度:自动管理 AICore、AIV、内存和片上 Cache
-
可替换可扩展:性能不满足时可替换为自定义算子
-
与 msProf、MindStudio Insight 深度联动,支持精准性能分析
这意味着开发者既能"直接用",也能"按需深度优化"。
二. 为什么 ACLNN 性能优化如此关键?
对于绝大多数模型来说:
-
80% 的总计算量集中在少数高频算子
-
算子效率 = 模型效率
例如:
-
大模型中 MatMul / Softmax / LayerNorm 决定推理吞吐
-
检测模型中 卷积 / DepthwiseConv 决定延迟
-
推荐模型中 EmbeddingLookup 决定内存带宽利用率
因此,ACLNN 算子能否达到硬件上限 是性能成败的关键。
三. ACLNN 算子性能优化:完整方法论
ACLNN 性能优化可分为四阶段:
|------------|-----------|-------------------------------|----------------------|
| 阶段 | 目标 | 工具 | 输出结果 |
| ① 上板性能采集 | 判定是否需要优化 | msProf op 上板模式 | AIV、AIC、内存热力图 |
| ② 仿真分析定位瓶颈 | 找到具体性能问题点 | msProf op simulator + Insight | 指令级流水图、热点代码 |
| ③ 算子行为级改写 | 优化执行路径 | ACLNN/Ascend C API 替换 | 降低 Scalar、提升 pipe 并行 |
| ④ 验证与复测 | 确认性能收益 | 上板再次采集 | 提升量化数据 |
下面用真实案例简述关键优化策略。
四. BERT场景性能优化案例:减少 Scalar 运算带来的性能提升
在 Transformer、BERT 等大规模模型的推理阶段,CrossEntropy 损失算子常用于分类任务的输出计算。 该算子虽然计算逻辑简单,但在部分输入规模下(例如 batch 较大或类别数较多)容易触发标量计算过多的问题,从而导致 AICore 并行度下降、执行流水被阻塞。 为验证并优化这一问题,本文选取了 shape = 128, 1024 的 CrossEntropy 算子作为典型案例,分析算子层面的性能瓶颈,并通过 ACLNN 优化手段进行性能提升。
1)症状表现
CrossEntropy 在 shape = [128, 1024] 输入下:
-
上板性能表现偏弱
-
AIV 指令统计发现 Scalar 运算占比异常高(> 80%)
即 CPU 风格的逐元素操作占用了 NPU 的执行时序,导致 AICore 并行能力无法发挥。
2)瓶颈定位
使用命令:
暂时无法在飞书文档外展示此内容
并将visualize_data.bin导入MindStudio Insight 查看上板性能。
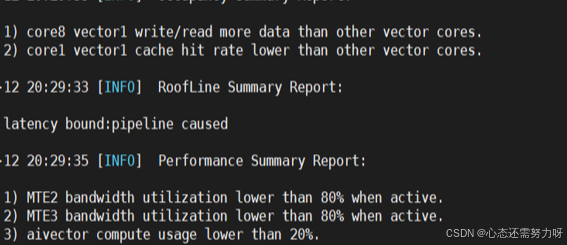
在 MindStudio Insight 中可视化查看:
-
Scalar 指令密集段
-
对应热点代码行号
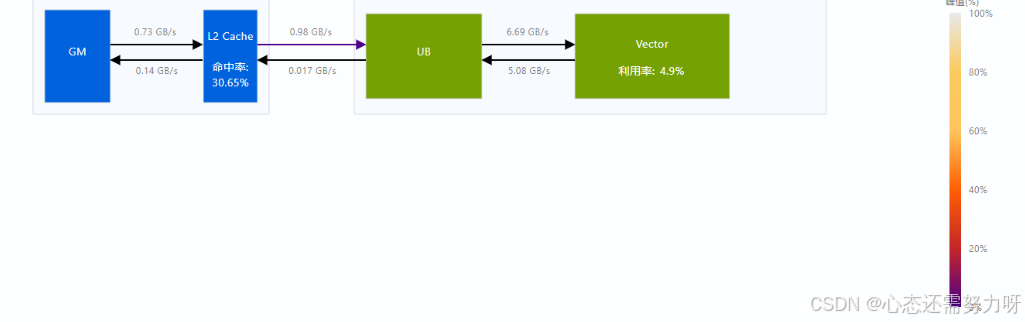
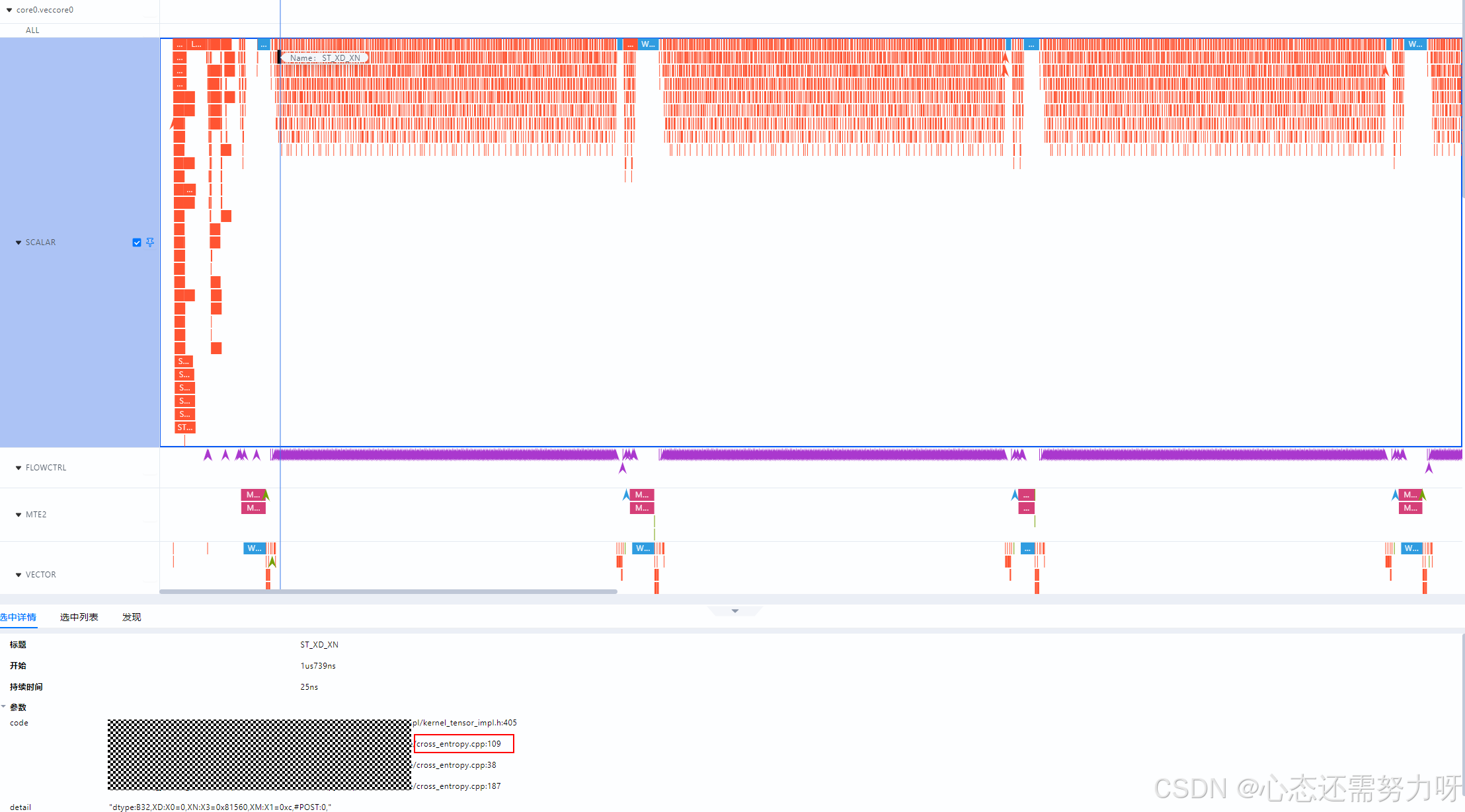
定位问题逻辑:
暂时无法在飞书文档外展示此内容
该模式触发了大量 标量 + 判断 ,导致 流水阻塞。
3)优化方法:使用 Duplicate 替代逐元素赋值
将原本 N 次 scalar 写入,替换为一次向量级复制:
暂时无法在飞书文档外展示此内容
效果: 大幅减少 scalar 指令 → 提高流水并行度。
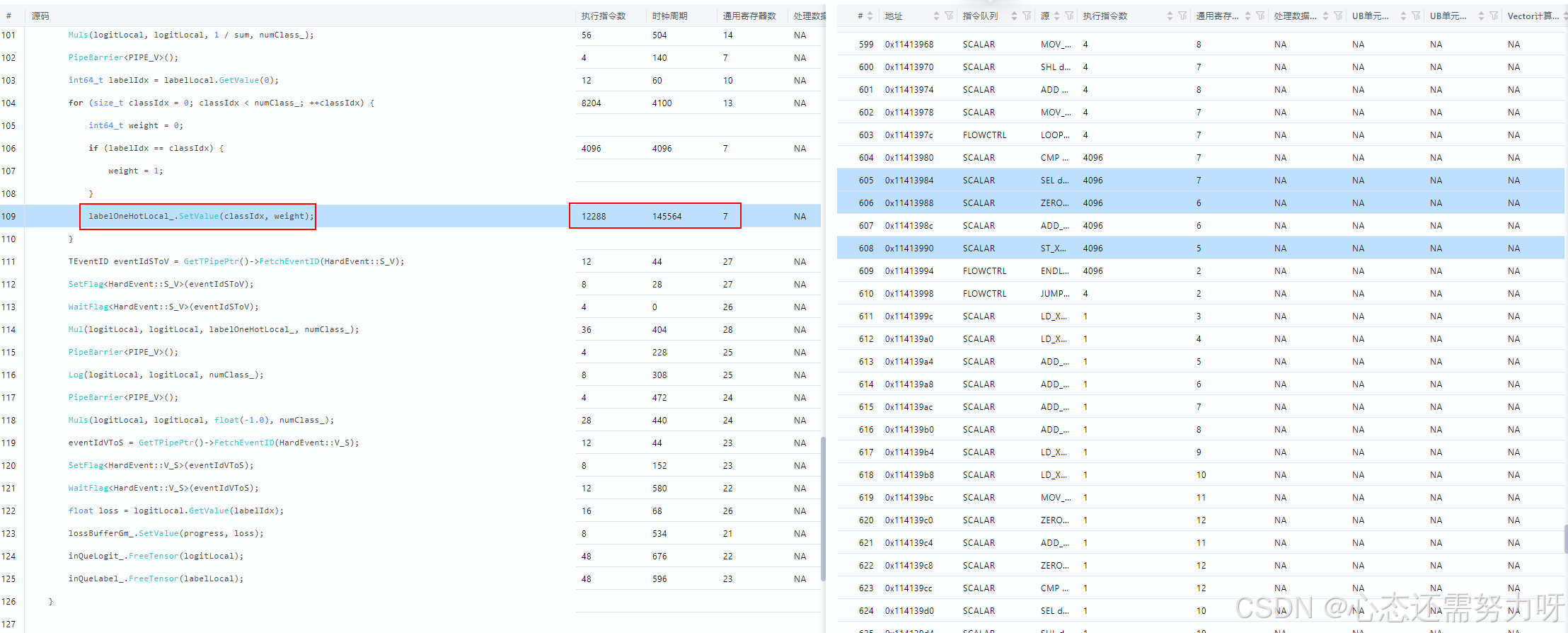
4)性能验证
|-----------|----------|----------|---------|
| 指标 | 优化前 | 优化后 | 提升比例 |
| Scalar 时间 | 16.71 μs | 4.04 μs | ↑ 75.8% |
| AIV 执行时间 | 20.95 μs | 10.68 μs | ↑ 49.0% |
| 端到端算子执行 | 45.42 μs | 28.03 μs | ↑ 38.3% |
优化效果显著,且实现简单、可复用性高。
ACLNN 并不只是"一个算子库",它是一整套 可视化分析 + 渐进式优化 + 底层可控 的算子性能体系。
它的价值在于:
-
应用开发者:开箱即用,无需关心硬件细节
-
算子开发者:可精确定位瓶颈、可控地优化执行路径
-
系统调优者:可深度挖掘 AICore 和带宽极限
在模型算力和推理成本竞争越来越激烈的时代,掌握 ACLNN 性能优化就是掌握模型落地能力本身。
五. YOLO 水果检测场景中的 DepthwiseConv 优化实践
在实时检测任务中( YOLOv5n 模型),DepthwiseConv 是典型的性能瓶颈算子。通过 msProf 与 MindStudio Insight 分析发现,该算子在小特征图阶段(例如 80×80×32)存在以下问题:
-
访存频繁、DRAM 带宽利用率偏低;
-
AICore 利用率仅为 68%,存在大量等待周期;
-
中间张量搬运频繁,流水线未充分并行。
(1)瓶颈定位
使用以下命令采集性能数据:
msprof --application=./yolov5_infer --output=./prof_data --profiling-level=OP
在 MindStudio Insight 中查看发现:
-
DepthwiseConv 算子访存延迟高;
-
Kernel Launch 次数频繁;
-
Cache Miss 比例高于 25%。
(2)优化策略
针对上述瓶颈,采用以下两类 ACLNN 优化手段:
-
算子融合(Fusion) :将
Conv + BN + ReLU三个算子融合为单算子执行,减少中间张量拷贝; -
自动调度与 Tile 优化 :启用
ACLNN auto-tune自动选择最优 tile 大小与并行度; -
Pipeline 调优:在高维场景下启用双 buffer 策略,提高数据流连续性。
(3)优化效果
|------------|--------|--------|
| 指标 | 优化前 | 优化后 |
| AICore 利用率 | 68% | 92% |
| DRAM 带宽利用率 | 54% | 78% |
| 单帧推理延迟 | 6.8ms | 4.9ms |
| 推理帧率 | 38 FPS | 51 FPS |
通过 ACLNN 的自动调度与融合优化,DepthwiseConv 算子性能提升近 30%,整体模型推理帧率提升 34%。 这说明在复杂视觉模型中,ACLNN 不仅能通过单算子层面的优化提升性能,更能在算子组合层面实现端到端的吞吐增强。
综上,CANN 并非仅在算子层面带来优化,更能通过 全链路的可视化调优与多层融合机制 ,在完整模型推理任务中显著提升性能。 无论是 CrossEntropy 等基础算子,还是 YOLO、Transformer 等复杂模型中的高频算子,开发者都可以依托 ACLNN + MindStudio Insight + msProf 的闭环工具链,快速完成瓶颈定位、优化验证与性能量化,实现性能可视、调优可控、效果可复现的全流程 AI 性能优化体验。
总结
CANN 通过深度开放的算子库、图引擎优化和框架适配能力,为开发者提供了完整的 AI 开发支持体系。在模型开发和部署过程中,CANN 能够有效屏蔽底层硬件差异,降低跨框架迁移和异构硬件适配的复杂度,让开发者专注于算法设计和业务创新。
在算子性能优化方面,ACLNN 算子结合静态/动态内存管理、硬件亲和性调度及流水线并行策略,实现了高性能计算能力。通过 MindStudio Insight 和 msProf op 等算子调优工具,开发者可以精准分析 scalar 运算、内存访问、Cache 命中率及指令流水等关键指标,快速定位性能瓶颈并进行针对性优化。典型优化手段包括 scalar 运算替换、重复计算合并及流水指令调度优化,能够显著提升算子性能和整体模型推理效率。
此外,CANN 支持自定义算子开发,结合 ATC 编译工具和性能分析工具链,开发者可灵活扩展算子能力,实现差异化优化和创新算法落地。整体来看,CANN 不仅提升了 AI 模型的计算效率,也显著缩短了开发周期,为各类应用场景提供了高效、可复用的算力解决方案,实现"效率与性能兼得"的开发体验。