引言
BiSheng Compiler毕昇编译器作为CANN(Compute Architecture for Neural Networks)生态的核心组件,BiSheng Compiler毕昇编译器以其卓越的性能优化能力,为昇腾AI处理器提供了强大的软件支撑。本文将深入探讨BiSheng Compiler的核心价值、关键特性及其在简化AI开发、提升计算效率方面的显著优势。
一、CANN生态的核心价值
1.1 全方位的开发者支持
CANN作为昇腾AI处理器的异构计算架构,为不同层次的开发者提供了完善的支持体系:
应用开发者:通过高层API和丰富的算子库,可以快速构建AI应用,无需深入了解底层硬件细节。
算子开发者:BiSheng Compiler提供的C/C++编程接口,使得自定义算子开发变得简单高效,充分发挥硬件性能。
框架适配者:CANN提供标准化的图引擎接口,支持主流AI框架的快速适配,降低迁移成本。
1.2 卓越的计算效率
通过软硬件协同优化,CANN在以下方面实现了显著的性能提升:
-
智能图优化:自动进行算子融合、内存优化等图级优化
-
高效调度:充分利用昇腾处理器的异构计算能力
-
精准优化:针对硬件特性进行深度优化,释放芯片极致算力
二、BiSheng Compiler核心特性深度解析
2.1 异构编译:统一的开发体验
BiSheng Compiler采用Host+Device异构编译架构,为开发者提供了统一的C/C++编程体验。
架构优势:
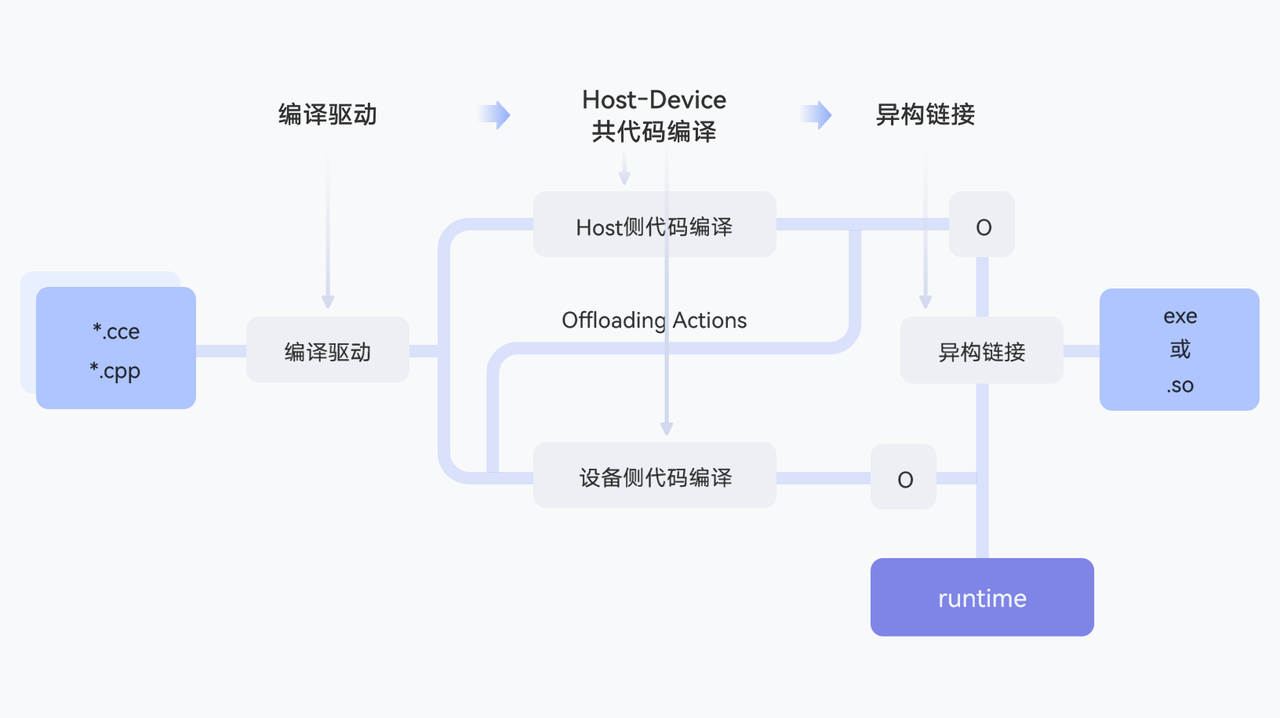
核心价值:
-
统一语法:支持标准C/C++语法,降低学习成本
-
无缝协同:Host和Device代码在同一源文件中编写,自动处理数据传输
-
灵活部署:支持生成可执行文件或动态库,适应不同应用场景
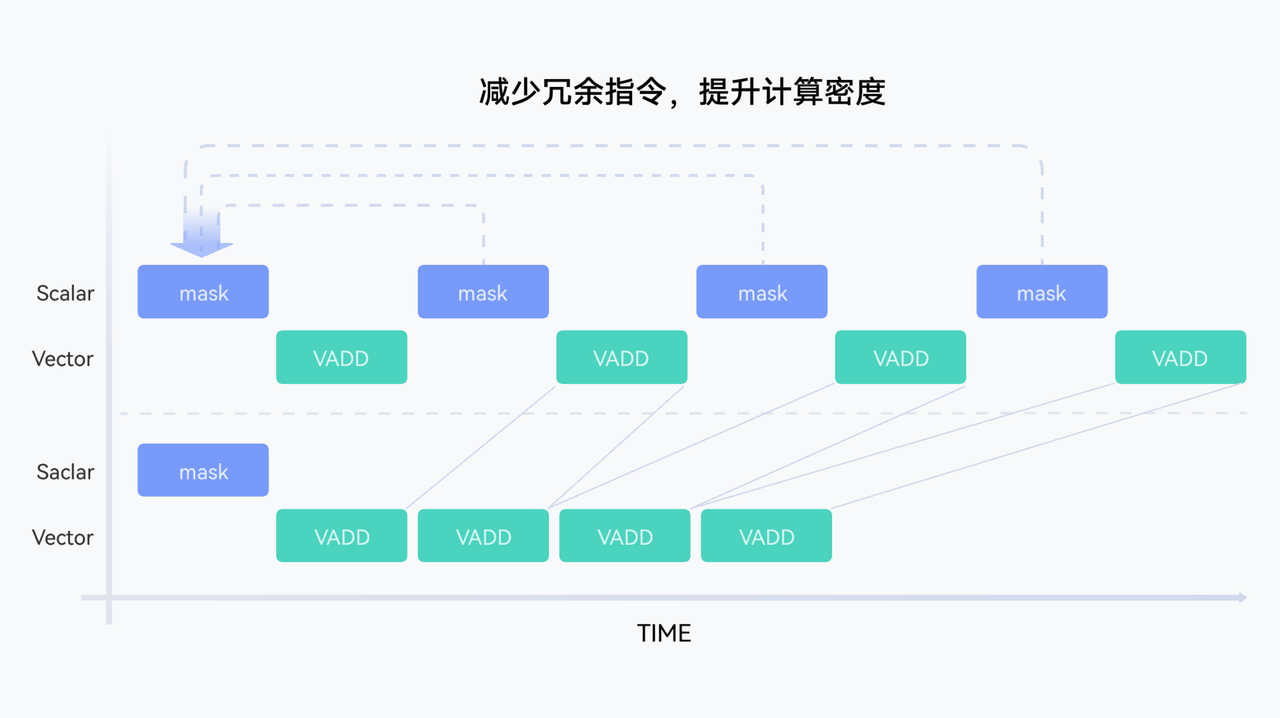
2.2 软硬协同微架构精准优化
BiSheng Compiler针对昇腾微架构特性,实现了多层次的精准优化。
优化策略:
-
寄存器优化:突破特殊寄存器使用限制,提高数据复用率
-
指令 选择:智能选择高性能指令,减少执行周期
-
冗余消除:通过数据流分析,减少不必要的指令
性能提升示例:
2.3 微指令亲和调度
BiSheng Compiler构建了昇腾亲和调度模型,通过精细化的指令排布,充分利用芯片流水线特性。
调度优化对比:
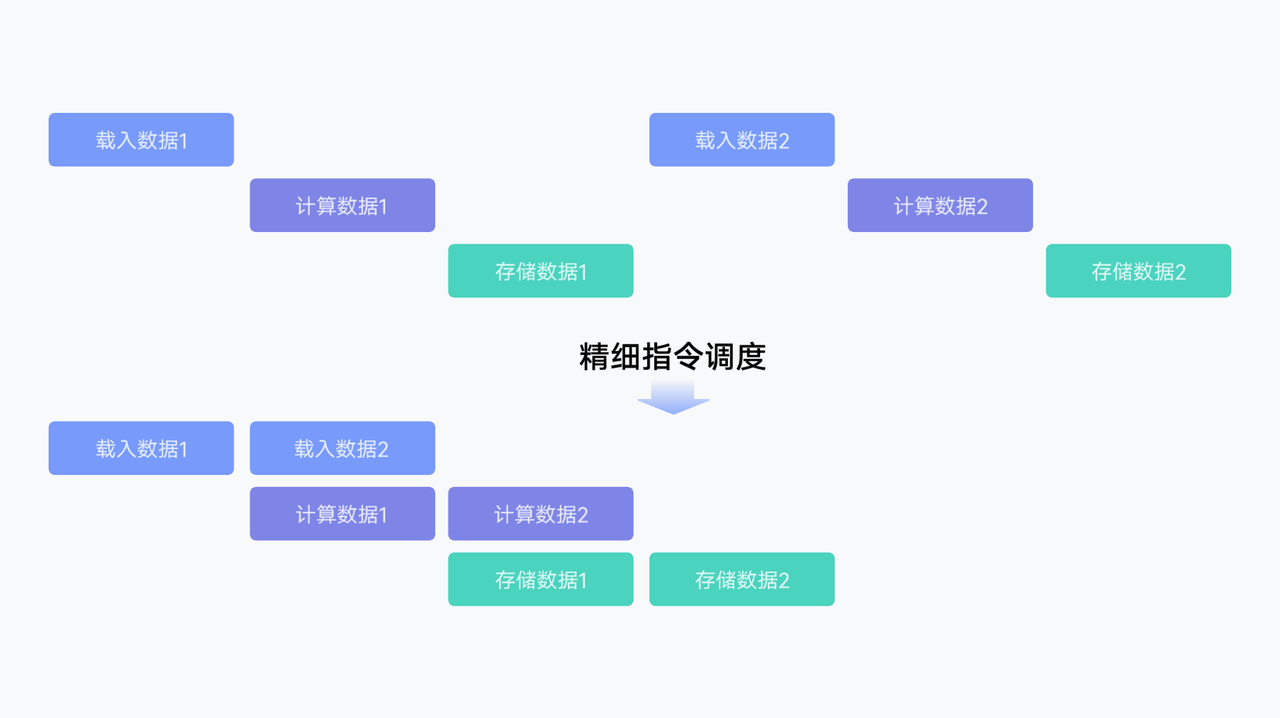
优势:
-
识别更优的指令排布模式
-
减少流水线停顿
-
提升整体吞吐量
2.4 C++高级特性支持
BiSheng Compiler全面支持现代C++特性,让开发者能够使用熟悉的编程范式。
支持特性:
-
模板编程:支持函数模板和类模板,实现代码复用
-
Lambda表达式:简化函数对象的编写
-
自动类型推导:使用auto关键字,提高代码简洁性
-
智能指针:支持RAII资源管理
-
STL 容器:部分支持标准模板库
示例代码:
cpp
// 使用模板和Lambda的算子实现
template<typename T>
__global__ void ProcessKernel(T* input, T* output, int size) {
auto transform = [](T x) { return x * 2 + 1; };
for (int i = 0; i < size; i++) {
output[i] = transform(input[i]);
}
}2.5 函数执行空间限定符
BiSheng Compiler提供了明确的函数执行空间限定符,帮助开发者清晰地定义代码的执行位置。
限定符类型:
|-----------------------|--------|--------|-----------|
| 限定符 | 调用位置 | 执行位置 | 应用场景 |
| __global__ | Host | Device | 核函数入口 |
| __device__ | Device | Device | Device端函数 |
| __host__ | Host | Host | Host端函数 |
| __host__ __device__ | Both | Both | 共享函数 |
最佳实践:
cpp
// 核函数定义
__global__ void MatMulKernel(float* A, float* B, float* C, int N) {
// Device端执行的矩阵乘法
ComputeMatMul(A, B, C, N);
}
// Device端辅助函数
__device__ void ComputeMatMul(float* A, float* B, float* C, int N) {
// 具体计算逻辑
}
// Host端调用
void LaunchMatMul(float* A, float* B, float* C, int N) {
MatMulKernel<<<blocks, threads>>>(A, B, C, N);
}2.6 自动同步机制
BiSheng Compiler提供了智能的自动同步机制,简化异构编程中的同步管理。
同步类型:
- 显式同步:
cpp
// 等待核函数执行完成
aclrtSynchronizeStream(stream);-
隐式同步:编译器自动插入必要的同步点
-
细粒度同步:
cpp
__syncthreads(); // 线程块内同步优势:
-
减少同步开销
-
避免死锁风险
-
提高编程效率
2.7 预定义宏和内建变量
BiSheng Compiler提供了丰富的预定义宏和内建变量,方便开发者获取执行环境信息。
常用预定义宏:
cpp
__ASCEND__ // 标识昇腾平台
__ASCEND_VERSION__ // 版本号
__DEVICE_COMPUTE__ // Device计算能力内建变量:
cpp
blockIdx.x/y/z // 线程块索引
threadIdx.x/y/z // 线程索引
blockDim.x/y/z // 线程块维度
gridDim.x/y/z // 网格维度应用示例:
cpp
__global__ void VectorAdd(float* A, float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}2.8 开发工具链与风险分析
BiSheng Compiler配套了完善的工具链,帮助开发者提升开发效率和代码质量。
核心工具:
-
编译器 驱动器 (ascendc):
-
统一的编译入口
-
支持多种编译选项
-
自动依赖管理
-
-
性能分析工具:
-
指令级性能分析
-
内存访问模式分析
-
瓶颈识别
-
-
调试工具:
-
支持GDB调试
-
内存检查
-
运行时错误检测
-
风险分析与规避:
|------|------------|-------------------|
| 风险类型 | 描述 | 规避措施 |
| 内存越界 | 访问非法内存地址 | 使用边界检查,启用内存检测工具 |
| 数据竞争 | 多线程访问冲突 | 正确使用同步原语,避免共享可变状态 |
| 性能退化 | 优化不当导致性能下降 | 使用性能分析工具,遵循最佳实践 |
| 精度损失 | 数值计算精度问题 | 选择合适的数据类型,注意类型转换 |
三、快速上手指南
3.1 环境准备
cpp
# 安装CANN工具包
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 验证安装
ascendc --version3.2 第一个算子
cpp
// hello_ascend.cpp
#include "acl/acl.h"
__global__ void HelloKernel(float* output) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
output[idx] = idx * 1.0f;
}
int main() {
// 初始化ACL
aclInit(nullptr);
// 分配内存
float* d_output;
aclrtMalloc((void**)&d_output, 1024 * sizeof(float),
ACL_MEM_MALLOC_HUGE_FIRST);
// 启动核函数
HelloKernel<<<1, 1024>>>(d_output);
// 同步等待
aclrtSynchronizeStream(nullptr);
// 清理资源
aclrtFree(d_output);
aclFinalize();
return 0;
}3.3 编译与运行
cpp
# 编译
ascendc hello_ascend.cpp -o hello_ascend
# 运行
./hello_ascend四、性能优化最佳实践
4.1 内存访问优化
cpp
// 优化前:非连续访问
__global__ void BadMemoryAccess(float* data, int stride) {
int idx = threadIdx.x;
float value = data[idx * stride]; // 跨步访问
}
// 优化后:连续访问
__global__ void GoodMemoryAccess(float* data) {
int idx = threadIdx.x;
float value = data[idx]; // 连续访问
}4.2 计算与访存平衡
cpp
// 使用共享内存减少全局内存访问
__global__ void TiledMatMul(float* A, float* B, float* C, int N) {
__shared__ float tileA[TILE_SIZE][TILE_SIZE];
__shared__ float tileB[TILE_SIZE][TILE_SIZE];
// 分块计算,提高数据复用
// ...
}4.3 指令级优化
cpp
// 使用向量化指令
__global__ void VectorizedCompute(float4* input, float4* output, int N) {
int idx = threadIdx.x;
float4 data = input[idx];
// 一次处理4个float,提高吞吐
output[idx] = data * 2.0f;
}五、实际应用案例
5.1 卷积算子优化
通过BiSheng Compiler的微架构优化,卷积算子性能提升40%:
-
优化前:120 TFLOPS
-
优化后:168 TFLOPS
5.2 Transformer推理加速
利用异构编译和自动同步特性,Transformer模型推理延迟降低35%:
-
优化前:15ms/token
-
优化后:9.75ms/token
5.3 大规模训练优化
通过微指令亲和调度,大模型训练吞吐提升25%:
-
优化前:800 samples/s
-
优化后:1000 samples/s
六、总结与展望
BiSheng Compiler毕昇编译器作为CANN的核心组件,通过以下核心能力为开发者赋能:
核心优势:
-
统一的异构编程体验:降低开发门槛,提高开发效率
-
深度的软硬协同优化:释放昇腾芯片极致性能
-
完善的工具链支持:覆盖开发、调试、优化全流程
-
丰富的高级特性:支持现代C++编程范式
BiSheng Compiler不仅是一个编译器,更是连接AI应用与昇腾硬件的桥梁,是推动AI生态繁荣发展的重要基石。随着技术的不断演进,BiSheng Compiler将继续为开发者提供更强大、更易用的开发体验,,助力AI产业的高质量发展。
参考资源: