一. 基础概念与架构
1. LangChain 简介
LangChain 是一个用于构建大语言模型(LLM)应用程序的框架。它提供了一套工具和组件,使得开发者可以轻松地将LLM与其他数据源和工具连接起来,构建复杂的应用程序。
2. 核心组件
在LangChain中,两个核心组件是llms和embeddings:
- LLMs:大语言模型,负责文本生成、对话等任务。
- Embeddings:将文本转换为向量表示,用于语义搜索、相似度计算等。
LLMs与Embeddings的区别:
- 大语言模型(LLMs):
- 功能:文本生成、对话、推理
- 输出:自然语言文本
- 特点:生成式、创造性
- 嵌入模型(Embeddings):
- 功能:文本向量化、语义理解
- 输出:数值向量
- 特点:表示学习、相似度计算
3. 系统架构
我们构建的文档问答系统架构如下:
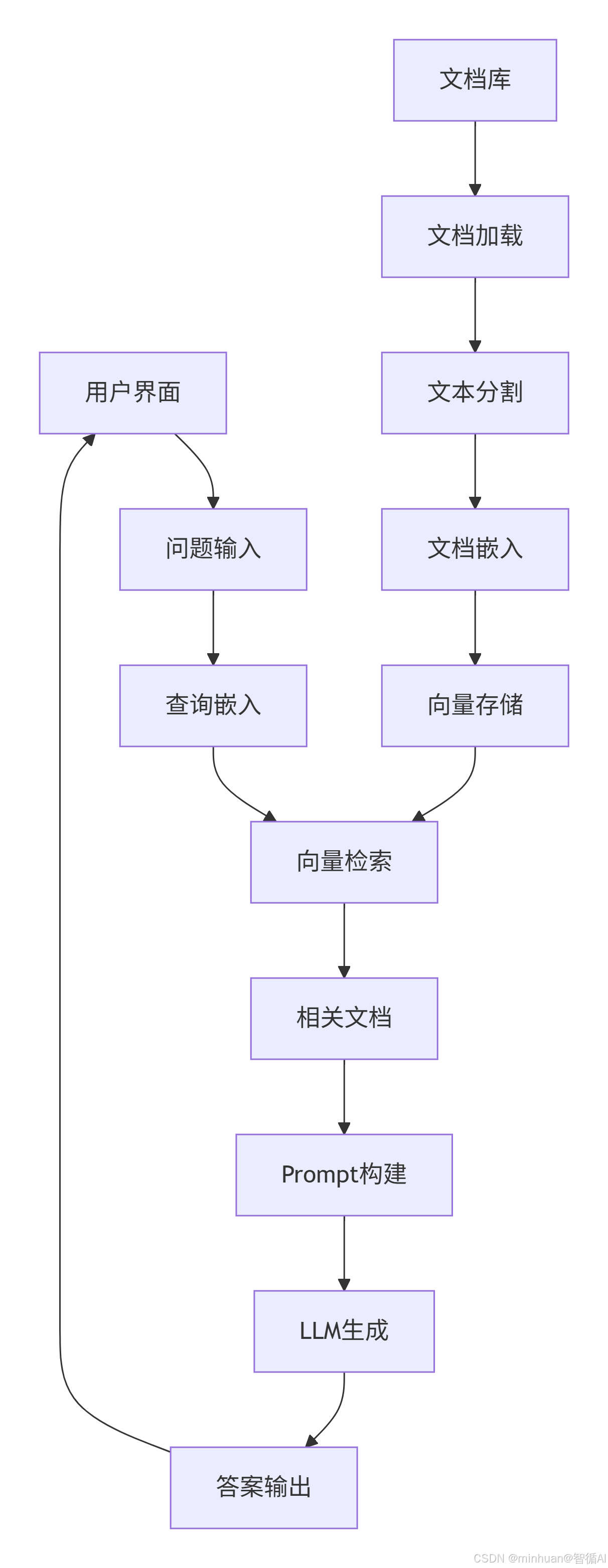
步骤说明:
-
- 用户界面:用户与系统交互的界面,可以是网页、命令行等。
-
- 问题输入:用户在界面中输入问题。
-
- 查询嵌入:将用户输入的问题通过嵌入模型(Embedding Model)转换为向量表示。
-
- 文档库:存储原始文档的地方,可以是本地文件系统或数据库。
-
- 文档加载:从文档库中加载文档,使用适当的加载器(如PDF加载器、文本加载器等)。
-
- 文本分割:将加载的文档分割成更小的文本块,以便于处理和嵌入。
-
- 文档嵌入:将分割后的文本块通过嵌入模型转换为向量表示。
-
- 向量存储:将文本块的向量表示存储到向量数据库中。
-
- 向量检索:将查询嵌入步骤中得到的查询向量与向量存储中的文档向量进行相似度检索,找出最相关的文本块。
-
- 相关文档:检索得到与问题相关的文本块。
-
- Prompt构建:将相关文档和用户问题组合成一个提示(Prompt),以便输入给LLM。
-
- LLM生成:将构建好的提示输入给大语言模型(LLM),生成答案。
-
- 答案输出:将LLM生成的答案返回给用户界面,展示给用户。
处理过程:
-
- 前端交互层:
- 用户界面:用户与系统交互的入口(Web页面、聊天窗口等)
- 问题输入:用户提交需要查询的问题文本
-
- 查询处理阶段:
- 查询嵌入:将用户的问题文本转换为数值向量
- 技术实现:使用嵌入模型(如BERT、Sentence-BERT)将文本映射到向量空间
- 目的:使计算机能够理解问题的语义含义
-
- 文档预处理流水线:
- 文档库:原始文档存储(PDF、Word、TXT等格式)
- 文档加载:读取文档内容,解析文本信息
- 文本分割:将长文档切分为小块(通常500-1000字符)
- 文档嵌入:将每个文本块转换为向量表示
- 向量存储:构建向量数据库(如FAISS)
-
- 核心检索阶段:
- 向量检索:在向量数据库中搜索与问题向量最相似的文档向量
- 相似度计算:使用余弦相似度等算法找到最相关的文档片段
- 返回结果:获取前K个最相关的文档块(通常K=3-5)
-
- 答案生成阶段:
- 相关文档:检索得到的最相关文本片段
- Prompt构建:将问题+相关文档组合成适合LLM的提示模板
- LLM生成:大语言模型基于上下文生成准确答案
- 答案输出:返回最终答案给用户界面
4. 数据流转

这个流程图展示了从用户输入到输出结果的整个过程,其中包含两个子流程:Embeddings处理流程和LLM处理流程:
-
- 整个流程从用户输入开始,经过文本处理、向量化、向量存储、检索、LLM生成,最后输出结果。
-
- 流程分为两个主要子流程:Embeddings处理流程(包括文本处理、向量化、向量存储)和LLM处理流程(包括检索、LLM生成、输出结果)。
-
- 注意,向量存储后,检索步骤是从向量存储中获取信息,然后传递给LLM生成。
简单解释:
- 用户输入:用户提供问题或指令。
- 文本处理:对输入文本进行清洗、分词等预处理。
- 向量化:将文本转换为数值向量(嵌入向量)。
- 向量存储:将向量存储在向量数据库中(此步骤可能是预先构建好的,这里表示将当前输入的向量与已有向量一起存储或检索)。
- 检索:根据输入向量的相似度,从向量存储中检索相关信息。
- LLM生成:将检索到的信息和原始问题组合成提示,输入到大语言模型(LLM)中生成回答。
- 输出结果:将LLM生成的结果返回给用户。
通过流程图,我们可以理解为:用户输入经过文本处理和向量化后,被用来在向量存储中进行检索,然后检索结果和用户输入一起送给LLM生成回答。
因此,重点在于:
- 嵌入流程:将文本转换为向量并存储,以便后续检索。
- LLM流程:利用检索到的上下文信息生成回答。
二、LLMs 组件详解
1、LLMs介绍
在LangChain中,LLMs组件是核心之一,它是对各种大语言模型的抽象。通过LLMs组件,我们可以以统一的方式调用不同的模型。
主要功能:
- 文本生成:根据给定的提示(prompt)生成文本。
- 对话:支持多轮对话。
- 结构化输出:将模型输出解析为结构化数据。
工作原理:
- 输入处理:将用户输入的文本转换为模型可以理解的格式。
- 模型调用:通过模型的API或本地模型进行推理。
- 输出解析:将模型的输出解析为所需的格式。
重要参数:
- model_name: 模型名称,用于指定使用哪个模型。
- temperature: 控制生成文本的随机性。
- max_tokens: 生成文本的最大长度。
在LangChain中的使用流程:

步骤说明:
-
- 用户输入 -> Prompt模板:将用户输入填入预设的模板中,形成完整的Prompt。
-
- Prompt模板 -> LLM模型:将构建好的Prompt输入给LLM模型。
-
- LLM模型 -> 输出解析:LLM模型生成文本,然后通过输出解析器处理。
-
- 输出解析 -> 结构化结果:输出解析器将文本解析成结构化的数据。
2. 基础示例
在LangChain中,llms模块负责与生成文本的模型交互。我们以HuggingFacePipeline为例,它是对Hugging Face的pipeline的封装。
Hugging Face的pipeline函数提供了一个简单的API,用于使用预训练模型进行各种自然语言处理任务,如文本生成、文本分类等。HuggingFacePipeline将这个pipeline包装成LangChain的LLM接口。
执行步骤:
- 从Hugging Face加载模型和tokenizer。
- 创建一个pipeline实例,指定任务类型(如text-generation)。
- 将这个pipeline实例传递给HuggingFacePipeline。
python
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
model_name = "qwen/Qwen1.5-1.8B-Chat"
model_dir = "D:\\modelscope\\hub\\qwen\\Qwen1.5-1.8B-Chat" # 使用snapshot_download下载的路径
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.float16, # 根据硬件调整
device_map="auto",
trust_remote_code=True
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1
)
llm = HuggingFacePipeline(pipeline=pipe)
response = llm("请介绍一下人工智能。")
print(response)三、Embeddings 组件详解
1. Embeddings 介绍
Embeddings组件用于将文本转换为向量表示。这些向量可以捕捉文本的语义信息,常用于文本相似度计算、语义搜索、聚类等任务。
主要功能:
- 文本向量化:将文本转换为高维向量。
- 相似度计算:通过计算向量之间的余弦相似度等度量来评估文本相似性。
工作原理:
- 文本预处理:对文本进行分词、去除停用词等操作。
- 模型推理:使用预训练的嵌入模型(如BERT、Sentence-BERT)将文本转换为向量。
- 后处理:对向量进行归一化等操作。
Embeddings组件通过Embeddings基类定义,主要包含两个方法:
- embed_documents: 用于将多个文档转换为向量。
- embed_query: 用于将单个查询转换为向量。
常用的嵌入模型有:
- sentence-transformers模型:适用于句子级别的嵌入。
- BERT等模型:适用于词级别或句子级别的嵌入。
在LangChain中的使用流程:

步骤说明:
-
- 文本输入
-
- 通过嵌入模型将文本转换为向量
-
- 将向量存储在向量数据库中
-
- 进行相似度搜索(例如,使用查询向量来查找最相似的向量)
2. 基础示例
嵌入模型将文本转换为向量。在LangChain中,我们可以使用Hugging Face的嵌入模型,通过HuggingFaceEmbeddings类。
HuggingFaceEmbeddings使用Hugging Face的模型来生成文本嵌入。它支持两种类型的模型:
- 专门用于生成嵌入的模型,如sentence-transformers系列的模型。
- 自动编码模型(如BERT)也可以用于生成嵌入,通常通过提取CLS令牌的隐藏状态或平均池化。
执行步骤:
- 选择一个嵌入模型(例如,sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2)。
- 使用HuggingFaceEmbeddings加载模型。
python
from langchain.embeddings import HuggingFaceEmbeddings
embedding_model_name = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs={'device': 'cuda' if torch.cuda.is_available() else 'cpu'},
encode_kwargs={'normalize_embeddings': True} # 是否归一化向量
)
# 单个文档,可以使用embeddings来生成文本的向量表示
text = "这是一个示例文本。"
vector = embeddings.embed_query(text)
print(vector)
#多个文档,我们可以使用embed_documents方法
documents = ["文档1", "文档2", "文档3"]
vectors = embeddings.embed_documents(documents)四、组件集成架构
这个序列图描述了用户与一个基于检索增强生成(RAG)的对话系统的交互过程。这个系统包括客户端、嵌入模型(Embeddings)、向量库(Vector Store)、大语言模型(LLM)和记忆模块(Memory)。让我们一步步解释这个交互过程,并提取重点。
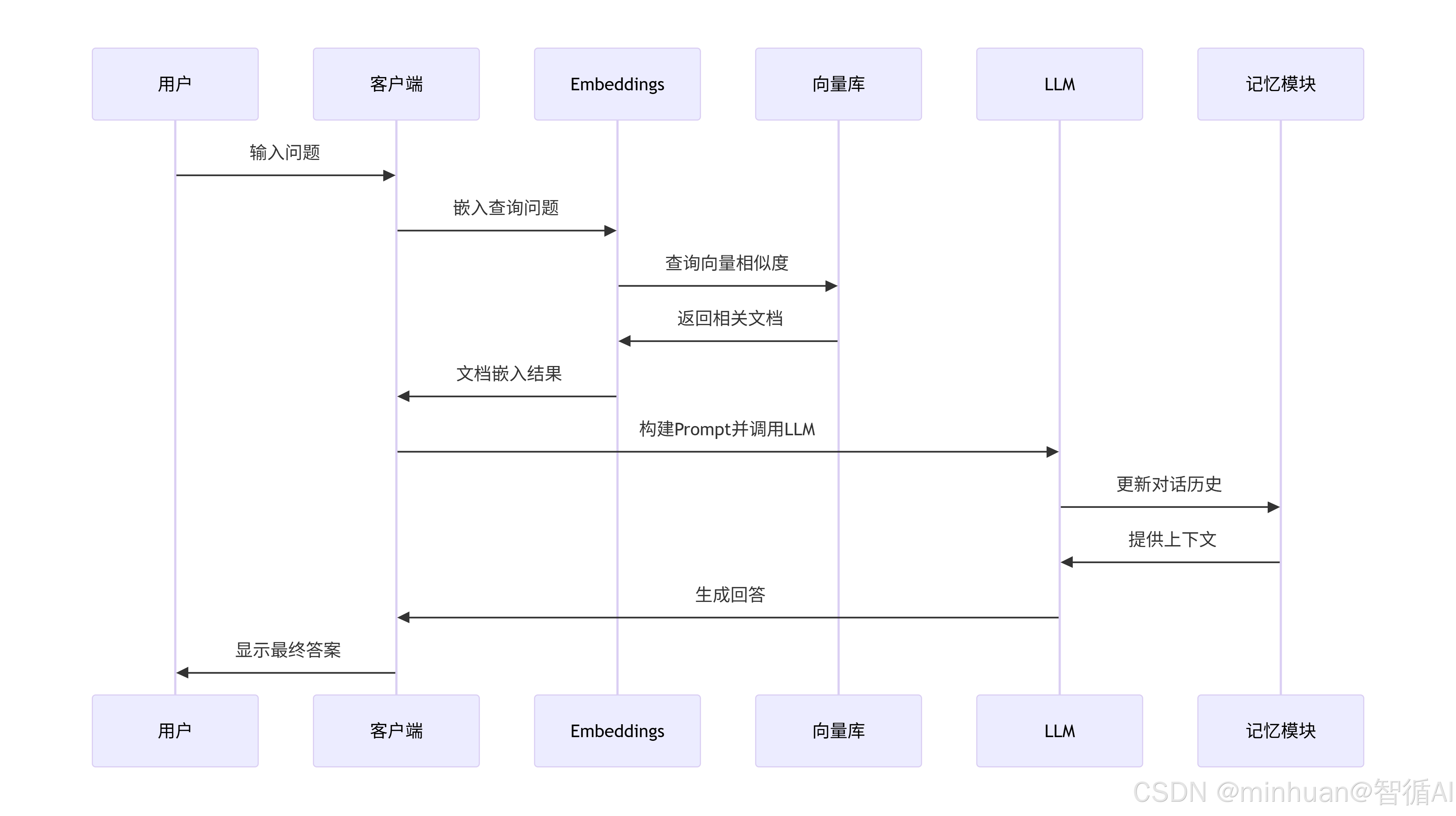
步骤解释:
-
- 用户输入问题:用户向客户端提出一个问题。
-
- 客户端将问题发送给嵌入模型(Embeddings):客户端将用户的问题文本转换为向量表示。
-
- 嵌入模型查询向量库:使用问题向量在向量库中执行相似度搜索,以找到相关的文档片段。
-
- 向量库返回相关文档:向量库返回与问题最相关的文档(或文档片段)的向量,然后嵌入模型或客户端将其转换为文本形式(图中显示嵌入模型返回文档嵌入结果给客户端,但实际上通常向量库返回文档后,客户端或嵌入模型需要将向量转换回文本?注意:这里图中是嵌入模型直接返回文档嵌入结果给客户端,可能是指返回相似文档的嵌入向量,但通常我们需要的是文本片段。在实际系统中,向量库存储的是文档片段的向量和对应的文本,所以向量库返回的是文本片段)。
-
- 客户端构建Prompt并调用LLM:客户端将用户的问题和检索到的相关文档组合成一个Prompt,然后发送给LLM。
-
- LLM与记忆模块交互:LLM从记忆模块中获取之前的对话历史(上下文),并更新当前的对话历史。
-
- LLM生成回答:LLM根据Prompt和对话历史生成回答,并返回给客户端。
-
- 客户端显示最终答案:客户端将LLM生成的回答显示给用户。
重点说明:
-
- 组件职责:
- 客户端:协调整个流程,接收用户输入,调用其他组件,显示结果。
- 嵌入模型:将文本转换为向量,用于检索。
- 向量库:存储文档向量,执行相似度搜索。
- LLM:生成回答。
- 记忆模块:存储和提供对话历史。
-
- 检索增强生成(RAG):这个系统使用了RAG技术,即在生成回答之前,先检索相关文档作为上下文。这可以提高回答的准确性和相关性。
-
- 对话历史:系统利用了记忆模块来维护对话历史,使得LLM能够根据之前的对话上下文生成更连贯的回答。
-
- 流程顺序:先检索后生成。首先通过向量相似度检索相关文档,然后将检索到的文档和问题一起作为Prompt输入给LLM。
-
- 交互方式:图中显示了同步的交互方式,每个步骤依次进行,直到最终生成回答。
这个序列图展示了一个典型的基于RAG的对话系统的工作流程,它结合了检索和生成两种技术,以提供更准确的回答。
五、集成示例:文档问答系统
在文档问答系统中,我们使用嵌入模型将文档切块后转换成向量,并存入向量数据库。当用户提问时,我们使用同样的嵌入模型将问题转换成向量,然后在向量数据库中搜索最相关的文档块,最后将这些文档块和问题一起发送给LLM生成答案。
执行步骤:
-
- 加载文档并切块。
-
- 使用嵌入模型为每个块生成向量,并构建向量存储(如FAISS)。
-
- 用户提问时,检索相关文档块。
-
- 将问题和检索到的文档块组合成提示,发送给LLM。
完整示例:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
# 加载文档
loader = TextLoader("example.txt")
documents = loader.load()
# 文档切块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
# 创建向量存储
vector_store = FAISS.from_documents(texts, embeddings)
# 创建检索器
retriever = vector_store.as_retriever()
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 提问
question = "文档中提到了什么?"
result = qa_chain({"query": question})
print(result["result"])example.txt 示例内容:
人工智能发展历程
人工智能(Artificial Intelligence, AI)是计算机科学的一个分支,旨在创造能够执行通常需要人类智能的任务的机器和系统。AI的发展经历了多个重要阶段:
- 诞生期(1950s-1960s)
1950年:图灵发表《计算机器与智能》,提出图灵测试
1956年:达特茅斯会议正式提出"人工智能"术语
早期成就:逻辑理论家、通用问题求解器
- 知识工程与专家系统(1970s-1980s)
专家系统兴起,如MYCIN医疗诊断系统
知识表示和推理成为研究重点
面临知识获取瓶颈
- 机器学习崛起(1990s-2000s)
统计学习方法取代符号主义
支持向量机、决策树等算法广泛应用
互联网发展为AI提供大量数据
- 深度学习革命(2010s至今)
神经网络深度增加,出现深度学习
2012年:AlexNet在ImageNet竞赛中突破性表现
2016年:AlphaGo击败围棋世界冠军
大语言模型如GPT系列快速发展
当前AI技术主要分支:
机器学习:让计算机从数据中学习模式
自然语言处理:使计算机理解和使用人类语言
计算机视觉:让计算机"看懂"图像和视频
机器人技术:结合感知、决策和执行
未来发展趋势:
通用人工智能(AGI)的探索
AI与各行业的深度融合
可解释AI和AI伦理的重要性日益凸显
边缘计算与AI的结合
人工智能正在深刻改变我们的生活和工作方式,从智能助手到自动驾驶,从医疗诊断到金融风控,其应用范围不断扩大。
六、总结
通过LangChain,我们可以方便地集成LLMs和Embeddings组件,构建强大的应用程序。一如既往使用ModelScope可以方便地管理中文模型,统一缓存目录有助于模型的管理和共享。同时我们可以选择其他的、适合自己的模型选择和管理方式。