0 引言:从"会下棋的程序"到"通用智能体"
如果把过去七十年的人工智能史压缩成一条时间轴,人类一开始只是在好奇:机器能不能像人一样下棋、识别图像、理解语言;而今天,我们已经在公开讨论人工通用智能(AGI)、人工超智能(ASI)以及相应的治理和安全问题。大模型、基础模型、多模态代理等概念层出不穷,却也不断模糊"弱人工智能""强人工智能"的边界,让很多技术从业者乃至研究者都产生了一种微妙的错觉:似乎我们已经半只脚踏进了强人工智能的大门,但又总感觉"差点什么"。
在哲学和心灵哲学语境中,弱人工智能(weak AI)与强人工智能(strong AI)的区分可以追溯到约翰·塞尔(John Searle)在 1980 年提出的经典讨论:弱人工智能只是"模拟思考",而强人工智能则真正"拥有心灵和理解"。(知乎专栏)在此之后,随着机器学习、深度学习、基础模型和开源大模型的兴起,人们又引入 AGI 这一更工程化的目标,强调系统在广泛任务上的通用性与人类可比甚至超越的人类水平能力。近期围绕 AGI 的定义和层级还出现了专门的开源综述和路线图项目,试图给出更可操作的技术标尺。(GitHub)
本文试图在理论与工程之间搭一座桥。从概念溯源出发,系统梳理弱人工智能和强人工智能的哲学根基、技术内涵与现实边界;再以"技术谱系"的方式,纵向回顾从符号主义到基础模型、从单一感知系统到多模态代理的演进;最后结合最新的开源大模型生态与 AGI 安全治理讨论,分析从弱 AI 走向强 AI 可能经历的阶段、路径与难题。
1 弱人工智能与强人工智能:概念渊源与哲学分歧
1.1 塞尔的区分:从"模拟思考"到"拥有心灵"
塞尔在讨论人工智能时做出了一个影响深远的区分:弱人工智能认为计算机程序只是帮助我们研究和模拟心智过程,它本身并不真正"思考";强人工智能则主张,恰当编程的计算机不仅会表现得像在思考,而且事实上"真的在思考",可以说拥有心灵。(知乎专栏)
在这一区分背后,是对"心灵是什么"的根本分歧。弱人工智能阵营往往采取一种工具主义立场,认为只要系统在可观察行为上足够智能,在工程上就可以称其为"智能系统",至于它是否具有内在的意识、自我或主观体验,并不影响系统的实用价值。而强人工智能则坚持,如果我们将"智能"理解为类似人类的理解、意向性和意识,那么仅仅在行为层面通过输入输出映射达到某种性能水平,并不足以宣称机器拥有真正的心灵。
这种分歧在今天依然活跃。面对 GPT-4、GPT-5 乃至各类开源大模型时,一部分人强调系统的通用性与表现,认为距离 AGI 已经不远;另一部分人则指出:这些系统仍然建立在统计模式匹配和符号操作上,缺乏真正的"世界模型"和主体性,很难说已经跨过强人工智能的门槛。
为了让后续讨论更清晰,我们可以暂时采用一个工作性定义:弱人工智能指专注于特定任务或有限任务集合、主要在行为层面展现智能的系统;强人工智能则指在广泛任务和开放环境中具备类似人类的理解、推理、学习与自我调节能力,且这一能力具有一定的内在统一性和持续性。
表 1 给出的是弱 AI 与强 AI 在典型维度上的概念性对比,它并非严格标准,但有助于把握二者的直观差异。
表 1 弱人工智能与强人工智能的概念性对比
| 维度 | 弱人工智能(weak AI) | 强人工智能(strong AI / AGI 语境下) |
|---|---|---|
| 目标范围 | 面向具体任务或窄域场景,如翻译、推荐、识别 | 面向广泛任务和开放环境,能够迁移和泛化 |
| 智能表现 | 任务表现可接近或超过人类,但缺乏统一性 | 在多种任务上具有一致且稳定的高水平能力 |
| 认知结构 | 通常面向任务单点优化,缺乏统一世界模型 | 具备统一世界模型与多种认知能力的集成结构 |
| 是否"拥有心灵" | 多数观点下"不拥有",只是工具或模拟 | 至少在某些强 AI 设想中,被认为可能拥有类似心灵或意识 |
| 评估方式 | 基于任务指标、基准数据集 | 需要综合评估跨任务能力、长期适应、价值对齐与自我反思能力 |
| 哲学争议的核心 | "表现像智能就够了么?" | "什么算真正的理解和意识?" |
在工程实践中,绝大多数可落地系统都属于弱 AI;但在学术讨论和公共叙事中,人们又往往用强 AI 或 AGI 来描述理想终点。这种"落地与理想之间的张力",在大模型时代变得越来越尖锐。
1.2 中国房间:语义、理解与"语法不等于语义"
塞尔著名的"中国房间"思想实验进一步强化了对强人工智能的怀疑。想象一个不会中文的人被关在房间里,外界通过投递纸条向他输入中文句子,房间中有一本巨大的规则手册,告诉他在每种中文输入下应该输出怎样的中文符号串。只要他严格遵循规则,外面的人会以为房间里"有一个懂中文的人",但事实上房间里的个体对中文一无所知。(Encyclopedia Britannica)
塞尔借此主张:计算机程序只是在进行形式符号(syntax)的操作,并不真正理解这些符号的语义(semantics)。计算机之所以在对话或推理中表现出"智能",是因为人类在其程序和数据中事先编码了大量语义信息;但系统本身并不"懂",就像中国房间中的操作者只是遵循规则,而没有任何对中文的内在理解。
在当代大语言模型(LLM)兴起后,中国房间论证重新被频繁引用。支持者认为,LLM 通过统计学习获取庞大的语料概率分布,本质上仍然是对符号或 token 的模式匹配;怀疑者则指出,当模型在我们从未显式编码的任务上表现出强大能力时,仅仅用"语法不等于语义"难以解释:难道高度结构化的统计分布本身就不能承载某种"涌现"的语义结构吗?
这一争议直接影响我们如何理解"从弱到强"的路径。如果坚持塞尔的立场,那么再强的语言模型,在根本上也只是弱 AI 的极致;如果承认复杂分布学习与世界交互可能孕育某种"功能主义意义上的理解",那么在连续谱意义上,从弱 AI 到强 AI 之间或许不存在绝对断裂,而是能力与结构积累到一定程度的跃迁。
2 弱人工智能:工程现实与能力边界
2.1 符号主义时代:专家系统的兴起与衰落
在早期人工智能发展中,弱 AI 的典型代表是符号主义系统与专家系统。经典著作《Artificial Intelligence: A Modern Approach》中就详细回顾了这一阶段:研究者通过手工构建知识库和推理规则,让系统在事实和规则图谱上进行逻辑推导,以解决定理证明、医疗诊断、化学结构分析等任务。(知乎专栏)
这类系统往往在特定窄域展示出令人惊艳的表现。例如 MYCIN 在血液感染诊断上的表现一度与人类专家相当;但它们也面临严重的"脆弱性":一旦问题偏离预设规则覆盖的范围,系统便失去效力。同时,知识获取瓶颈、规则维护成本、对噪声和不确定性的敏感,使得专家系统难以跨域扩展。
从弱 AI 的角度看,符号系统把"智能"理解为可显式编码的逻辑知识与推理规则,系统的边界由知识工程师的显式建模能力决定。这种范式虽然后来在通用 AI 叙事中逐渐式微,但它留下的知识表示、逻辑推理、规划搜索等思想,今天依然在神经符号系统、可解释性和形式验证等方向中发挥作用。
2.2 机器学习与深度学习:统计智能的崛起
从 1990 年代起,以统计学习为核心的机器学习逐渐成为主流。相较符号主义,机器学习不再依赖人工显式编码全部知识,而是通过数据驱动的方式自动学习模型参数,在分类、回归、聚类等任务上获得更好的鲁棒性与泛化性能。深度学习在 2012 年 ImageNet 比赛中爆发后,进一步将机器学习推向新的高度。
深度神经网络通过多层非线性变换,在语音识别、图像识别、机器翻译等领域取得了突破性成果;随后 Transformer 架构与自监督预训练的结合又催生出大规模语言模型与多模态模型,为后来的基础模型和通用智能体奠定了技术基石。(arXiv)
从弱 AI 视角来看,深度学习系统依然是典型的"弱人工智能":它们为具体任务训练模型,在给定数据分布和损失函数下优化性能。虽然预训练带来了强大的零样本和少样本泛化能力,但系统的行为仍旧高度依赖训练数据的统计结构。对于分布外场景、长周期规划、隐含因果结构和价值冲突,深度模型仍显示出非常明显的局限性。
然而,正是这种"在弱 AI 范畴内的极度增强",引发了对强 AI 和 AGI 的再思考:当弱 AI 在越来越多任务上表现接近乃至超过人类时,我们是继续在"窄域增强"的路线上一往无前,还是需要在架构和范式上进行更深层次的转变?
3 从弱到强:AGI 概念与能力光谱
3.1 AGI 的多种定义:从"能做任何事的人类"到"开放环境适应"
在大模型时代讨论强人工智能,几乎绕不开人工通用智能(AGI)的概念。然而,目前关于 AGI 的定义并不统一。Bowen Xu 在一篇专门讨论 AGI 定义的开源论文中指出,现有文献中对 AGI 的表述从"能够执行任何人类能完成的智力任务"到"能适应开放环境、在资源受限条件下根据一定原则做出决策"的广泛光谱,缺乏共识。(arXiv)
另一方面,AGI-Survey 等开源项目尝试从工程视角给出更系统的分层框架,将 AGI 理解为在感知、推理、记忆、规划以及与数字世界、物理世界和多智能体环境交互等方面具备广泛而稳健能力的系统,同时明确区分不同级别的"前 AGI""人类水平 AGI"和"超人 AGI"。(GitHub)
为了比较不同定义,我们可以概括几种典型视角:任务完备视角强调"能完成任何智力任务";能力维度视角关注在多个认知维度上的人类水平表现;适应性视角则重点考虑开放环境、长期学习与资源限制。
表 2 不同 AGI 定义视角的比较
| 视角类型 | 代表性表述或来源 | 核心关注点 | 隐含假设 |
|---|---|---|---|
| 任务完备视角 | "能执行任何人类可以完成的智力任务" 等经典表述(GitHub) | 覆盖任务集合的广度 | 将智能等同于任务集上的表现 |
| 能力维度视角 | 近期多维度 AGI 评估框架与分级提案(The Times of India) | 在推理、记忆、规划等多维度达到人类水平或更高 | 存在可量化的"认知维度" |
| 适应性与资源视角 | Xu 提出的"开放环境下资源受限适应"定义(arXiv) | 长期适应、在线学习与资源约束下的决策质量 | 智能本质是适应开放环境 |
| 代理与交互视角 | AGI-Survey 中对环境交互和多智能体的强调(东艾国际) | 与物理世界、数字世界和其他智能体的交互与协调 | 智能需要在复杂系统中体现 |
从本文的角度来看,我们可以把 AGI 理解为"在多种任务和环境中表现出持续的、高度泛化的、资源受限下的适应性智能",并将其视为强人工智能的工程化目标版本。这样一来,强 AI 不再只是哲学上的"拥有心灵",而是一个拥有较强操作性和可评估性的综合技术指标。
3.2 能力光谱与评测:从基准分数到长期代理表现
大模型出现后,各类基准(benchmark)层出不穷,从 MMLU、GSM8K 到多模态基准,人们一度希望通过一系列跨学科题目来衡量模型的"通用性"。然而,近期多家机构的研究和评估结果表明:在这些静态基准上取得高分,并不意味着系统在真实世界中具备稳健、可控的通用智能。(arXiv)
Mistral CEO Arthur Mensch 就公开指出,AGI 在很大程度上是一个"营销概念",与其纠结是否达到了某个抽象的 AGI 水平,不如关注"智能体连续执行任务的时长",即系统在不崩溃或严重偏离目标的前提下,能持续完成多长时间、多复杂序列的任务。(Business Insider) 这一观点在代理式系统(AI agents)快速发展的背景下,获得了越来越多工程师的认同。
从能力光谱的角度看,我们可以将当前系统大致放置在以下连续谱上:窄域模型主要依赖单任务数据和简单策略;任务通用模型通过大规模预训练在多任务上获得强表现;代理式系统则尝试通过记忆、工具使用和环境交互,将静态模型转化为面向过程和长期目标的智能体。真正的 AGI 可能要求在这一光谱上同时具备强大的任务通用性、稳定的长期代理行为以及良好的自我监控与校正能力。
这也意味着,从弱 AI 走向强 AI 的关键不只是"模型更大""算力更强",而是如何让模型在时间轴上持续、可靠地表现出合理行为,如何在复杂环境中维护目标一致性和价值对齐,以及如何在出现偏差时及时自我修正。
4 基础模型与大语言模型:处在"弱强之间"的关键范式
4.1 基础模型:新一代通用"底座"的技术特征
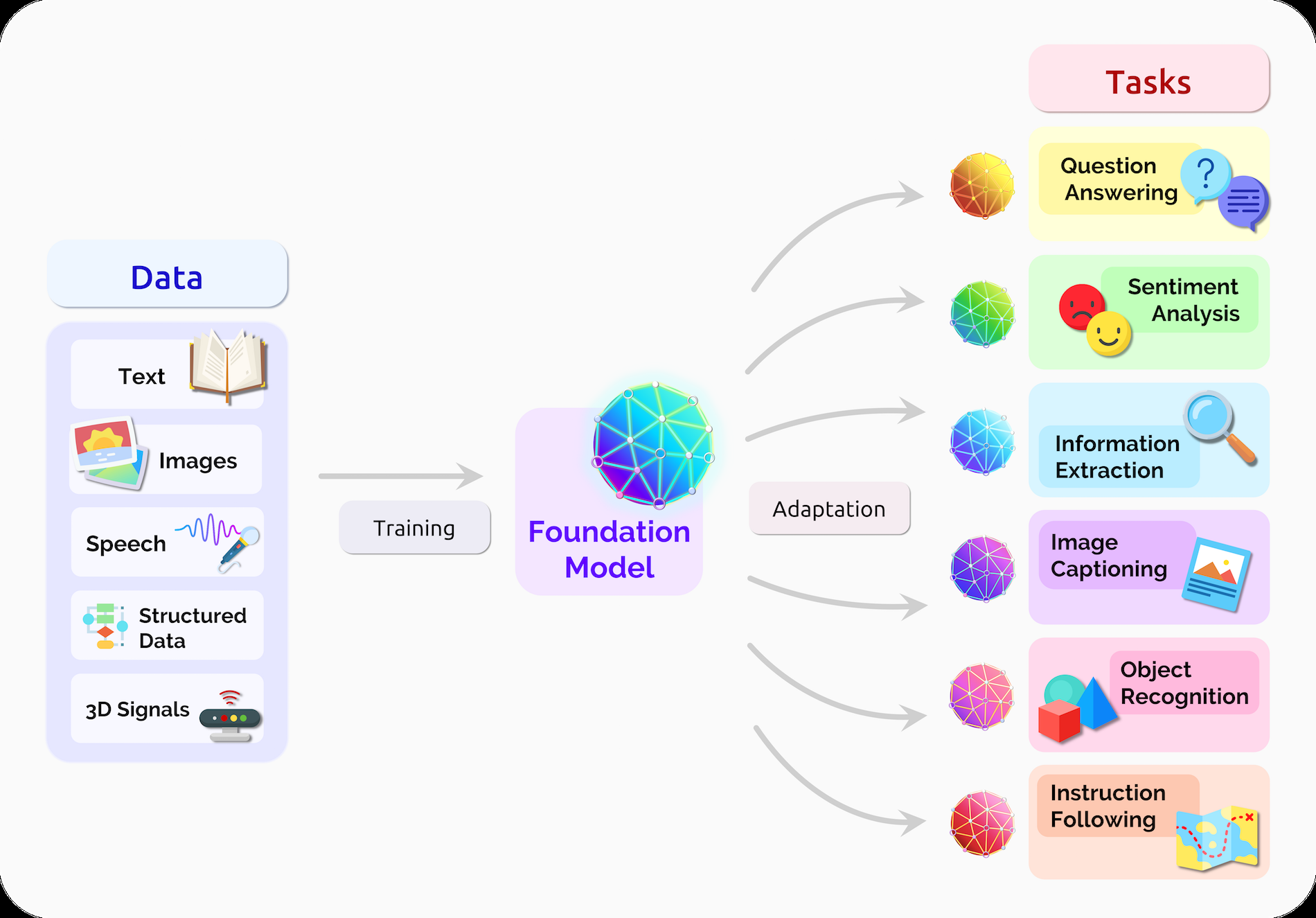
Rishi Bommasani 等人在 2021 年的论文《On the Opportunities and Risks of Foundation Models》中提出"基础模型"(Foundation Models)的概念,指出以 BERT、GPT-3、DALL·E 为代表的大规模预训练模型正在成为各种下游任务的通用"底座",并据此引发了一场范式转移:研究者不再为每个任务从头训练模型,而是基于统一的基础模型进行微调或提示调优。(arXiv)
基础模型具有几个鲜明特征:首先,它们通常通过自监督方式在巨量数据上训练,学习数据分布中的丰富结构;其次,它们具有显著的跨任务迁移能力,少样本甚至零样本即可在新任务上表现良好;再次,它们往往具有高度的模块化能力,能够通过插件、适配器、工具调用等方式扩展功能。
从弱 AI--强 AI 光谱来看,基础模型似乎站在一个中间位置。一方面,它们仍旧是统计学习系统,并未显式引入心灵或意识的概念;另一方面,它们表现出的迁移能力、涌现行为和跨模态理解已经远超传统窄域模型,可以说是"弱 AI 的极致形态",甚至在某些工程叙事中被视为通往 AGI 的"临界状态"。
然而,Bommasani 等人也明确指出,基础模型带来的风险和挑战同样是系统性的,包括偏见与不公、数据泄露、不可预测的行为和对整个 AI 生态的集中化影响。因此,如何在利用基础模型扩展能力的同时,避免将整个社会基础设施押注在少数不透明的模型上,成为 AGI 时代的一个核心治理难题。(arXiv)
4.2 大语言模型的能力、局限与"伪强 AI 幻觉"
大语言模型(LLM)是当前基础模型的典型代表。通过 Transformer 架构和大规模语料预训练,LLM 在文本生成、对话、编程、推理和多模态理解等任务上展现出前所未有的能力。开源和闭源社区都在快速迭代 LLM:从 GPT 系列到 Gemini、Claude,再到 Llama、Qwen、Mistral、DeepSeek 等开源大模型,已经形成了丰富的模型生态。(莫尔索随笔)
LLM 之所以容易被误认为"强 AI",原因在于它们在表层行为上非常接近人类对话者:能够流畅表达观点、自我解释推理过程,甚至表现出某种"人格风格"。但从技术上看,它们仍然主要依赖语言数据中的统计共现关系,在世界模型的完整性、长期规划、跨模态因果理解和自我反思等方面存在明显短板。
近期多份针对 AGI 安全的报告指出,即便最先进的闭源模型在一些基准上接近人类水平,它们仍然缺乏可验证的长期可靠性与稳健性,更不要说真正意义上的"心灵"或"意识"。Future of Life Institute 对多家顶尖 AI 公司进行的安全评估就发现,大多数公司在面向人类水平或更高智能的安全规划上准备不足,整体得分并不理想。(卫报)
因此,在讨论"从弱 AI 走向强 AI"时,大语言模型或许更像是一座通向强 AI 的巨大平台,而不是终点本身。它们为我们提供了前所未有的通用表示和接口能力,但要将其发展为真正意义上的强人工智能,还需要在世界建模、具身交互、自我反思与价值对齐等方面进行深入的架构创新。
5 技术谱系:从 GOFAI 到多模态智能体
5.1 算法与架构的纵向演进:一条简化的技术谱系
如果从"技术谱系"的角度回看人工智能的发展,我们可以把关键范式抽象成若干阶段:
表 3 人工智能主要技术范式的谱系概览
| 阶段/范式 | 核心技术与代表系统 | 典型优点 | 典型局限 |
|---|---|---|---|
| 早期符号主义 | 逻辑推理、状态空间搜索、专家系统 | 可解释性强,适合结构化知识 | 知识获取难,鲁棒性差,难以扩展 |
| 统计机器学习 | SVM、决策树、图模型等 | 对噪声有一定鲁棒性,泛化能力提升 | 需要人工特征工程,表达能力有限 |
| 深度学习 | CNN、RNN、Transformer 等 | 表达能力强,多模态感知表现卓越 | 依赖大数据,缺乏显式结构与可解释性 |
| 基础模型 | 大规模预训练语言/多模态模型 | 跨任务迁移强,形成统一表示与接口 | 训练成本高,黑箱化严重,风险集中化 |
| 代理与世界模型 | 强化学习、模型学习、多智能体系统 | 面向长期目标与环境交互,有潜在 AGI 路径 | 训练难度大,安全性与稳定性尚不成熟 |
这一谱系并非线性替代,而是不断叠加与融合。今天的许多系统已经将符号推理与神经网络结合(神经符号系统),将深度学习与强化学习结合(如 AlphaZero、复杂控制任务),甚至在基础模型之上叠加代理层、记忆模块和外部工具,从而构造出更复杂的智能体架构。
从弱 AI 到强 AI 的过程中,最值得注意的趋势是:系统越来越从"单次映射"走向"长期交互",从"静态模型"走向"具身或虚拟具身的智能体"。这种转变不仅是计算结构的调整,更是目标函数、评估方式和安全治理范式的整体迁移。
5.2 认知架构、世界模型与代理式系统
在通往强人工智能的技术路线中,认知架构和世界模型被许多研究者视为"缺失环节"。AGI 相关会议与综述中频繁出现的一个观点是:如果没有统一的世界模型和长期记忆,仅凭短上下文的统计模式匹配,很难支撑开放环境中的持续智能行为。(The Millennium Project)
代理式系统(AI agents)尝试在基础模型之上增加三个关键能力:持久记忆(能够跨会话、跨任务保持状态与知识)、工具使用(调用外部计算资源、数据库和 API 来扩展能力)以及环境交互(在模拟或真实环境中采取行动并观察反馈)。近期不少开源项目围绕"多工具、多步骤、多智能体协作"的代理系统展开,探索如何将大模型从单轮问答扩展为能长期追踪目标、主动规划和协作的智能体。
在这一过程中,世界模型扮演着枢纽角色:它既包括模型对物理世界和社会世界的结构化表示,也包含对自身能力与局限性的元认知表示。具备世界模型的智能体能够在缺乏直接数据时进行想象与模拟,通过内部仿真评估行动方案的后果,从而在现实环境中采取更稳健的行动策略。
从弱 AI 的视角看,代理和世界模型只是"更复杂的工程模块";从强 AI 的视角看,它们可能是从"会做题的系统"走向"能够在世界中生存和适应的主体"的关键突破。

6 开源大模型与"可验证强智能"的道路
6.1 主流开源大模型与技术生态
在过去两年里,开源大模型生态以惊人的速度发展。从 Meta 发布的 Llama 系列,到阿里 Qwen、Mistral 系列、DeepSeek 系列,再到各国和各研究机构推出的区域性大模型,开源已经成为推动 AI 技术民主化与透明化的重要力量。(莫尔索随笔)
OpenLLM、Hugging Face 等平台则在这一生态之上提供统一的模型仓库和运行环境,方便开发者快速加载和部署各种开源模型。OpenLLM 的模型仓库中列出了包括 Llama 3、Mistral、Qwen2 等在内的一系列最新开源模型,并提供统一的接口来运行和管理。(GitHub)
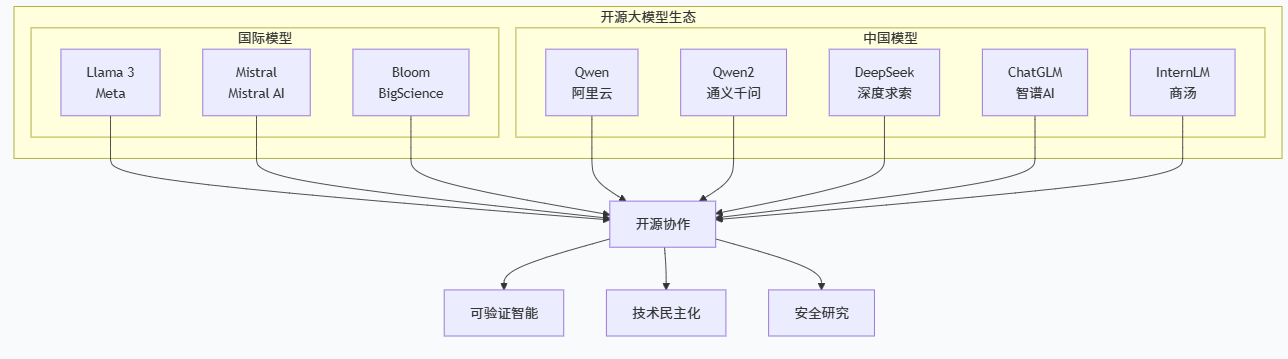
从"技术谱系"的角度看,开源大模型的重要意义在于:它们让更多研究者可以审视模型架构、训练策略和评估方法,从而在更透明的基础上探索 AGI 路线与安全机制。在闭源模型中,我们很难验证某些能力是否真正在模型内部出现,还是被对齐和数据工程"包装"出来;而在开源模型中,至少在理论上可以通过复现实验、更改组件、注入探针等方式进行更细粒度的分析。
表 4 部分代表性开源大模型概览(非完整,仅举例)
| 模型系列 | 主要维护方 | 典型版本与参数规模 | 技术特点与典型应用 |
|---|---|---|---|
| Llama 3.x | Meta | 8B--405B 等多种规模 | 多语种支持强,推理与代码能力突出,成为众多下游应用的基础模型 |
| Qwen / Qwen2 | 阿里巴巴 | 通用版 + VL + Audio 等多模态变体 | 在中文与多模态任务上表现优异,提供丰富的专用模型 |
| Mistral 系列 | Mistral AI | 7B--Mixtral 8x22B 等多种混合专家结构 | 强调效率与推理能力,适合在资源受限环境部署 |
| DeepSeek 系列 | DeepSeek AI | 多种规模与对齐版本 | 在数学推理、代码和多语种任务上表现突出,主打社区友好与开放部署 |
| 其他区域模型 | 多国研究机构或联盟 | 如 OpenEuroLLM、Olmo 等 | 强调数据透明与本地化,对隐私和法规合规有更细致考虑 |
值得注意的是,在"开源"一词的使用上,业界存在不小争议。多家媒体和研究机构指出,一些自称开源的大模型在训练数据、对齐过程或使用许可上仍然保留了较多限制,与传统意义上的自由软件或开源软件并不完全等同。(Le Monde.fr) 这也促使相关组织提出更严格的"开源 AI"标准,要求在模型权重、训练代码、数据来源以及安全评估等方面提高透明度。
6.2 "类开源"争议、透明度与安全性
开源与 AGI 的关系是复杂而微妙的。一方面,更开放的模型和工具有助于全球研究者共同审查技术、发现安全隐患,并推动更公平的技术分配;另一方面,如果强能力模型在缺乏足够安全措施的情况下完全开放,也可能放大滥用、对抗攻击和失控风险。
近期有研究和报道指出,许多被冠以"开源"标签的大模型实际上采用了"权重部分开放""对齐过程不透明""使用条款限制较多"等策略,这种"类开源"既满足了企业扩张生态影响力的诉求,又在一定程度上保留了技术壁垒和商业机密。(Le Monde.fr) 从强 AI 与 AGI 的角度看,这种局面使得我们很难在全局范围内建立统一的安全标准和审计机制。
Future of Life Institute 等机构的评估则提醒我们,即便是最前沿的 AI 公司,在 AGI 乃至超智能系统的安全规划上仍然严重不足。(卫报) 对于开源模型生态而言,如何在社区层面引入"安全合规清单""能力门控机制""滥用监测与应急响应流程",成为通往强人工智能过程中不可回避的挑战。
从某种意义上说,真正可持续的强 AI 路线,必须在"开放性、透明性与安全性"三者之间达到新的平衡:既要避免极端集中化带来的黑箱风险,也要防止完全无门槛开放造成的失控。
7 边界重绘:强人工智能是否等于 AGI?
7.1 概念辨析:强 AI、AGI 与 ASI
在当前讨论中,"强人工智能"和"AGI"经常被混用,但两者并非严格等价。强 AI 更偏向哲学语境,强调"是否真正拥有心灵、意识和理解";AGI 则是一种工程化概念,强调系统在多种任务和环境中是否具备人类水平的通用智能。(知乎专栏)
此外,许多研究和媒体还会提到人工超智能(ASI),指在几乎所有重要领域都远超人类的智能系统。在技术演进路径上,常见的想象是:从当前的窄域 AI 和基础模型出发,逐步迈入人类水平 AGI,最终演化为 ASI。近期新闻报道中,多位顶尖企业家与研究者将 AGI 的时间表估计在未来 5--10 年内,但也有人指出这种时间表本身缺乏统一的定义基准。(The Times of India)
这种概念混用容易导致两种极端:一方面,一些乐观叙事将当前大模型的突破直接等同于"强 AI 已临门";另一方面,一些哲学立场则坚持认为,除非系统展示出无可争议的主观体验或意识,否则一切关于 AGI 和强 AI 的讨论都只是"换壳的弱 AI"。
从本文的视角看,更务实的做法是将强 AI 理解为一个由多条维度构成的区域,而不是单一边界:在认知能力、适应性、价值对齐、自我反思和意识等维度上,系统可以处在不同水平。AGI 可以被视为在其中若干维度上达到人类水平的一个子集,而是否把"类似意识"也作为必要条件,则是哲学和科学共同面临的长期问题。
7.2 技术、哲学与社会的三重边界
在讨论从弱 AI 到强 AI 的边界时,我们至少要面对三重维度:技术可行性边界、哲学可接受性边界,以及社会与政策层面的安全边界。
技术可行性边界关注的是:在当前可预见的算法和算力下,我们能在多大程度上构建出"足够通用"的智能系统。AGI-Survey 等项目通过整理开源文献,尝试给出一个多层次的路线图,包括内部机制、接口设计、系统实现和对齐问题,体现的是一种"从工程问题出发不断逼近 AGI 区域"的思路。(GitHub)
哲学可接受性边界涉及:什么条件下我们愿意承认一个系统"真的理解"或"真的拥有心灵"?中国房间论证以及围绕功能主义、意识难题等展开的争论在当代依然激烈。(Michigan State University) 即使某个系统在所有可观测行为上都与人类无异,是否就足以宣称它拥有意识,仍然没有定论。
社会与政策的安全边界则是近年来愈发紧迫的议题。Future of Life Institute 等组织提醒我们,即便技术上可以继续推进通用智能的边界,在缺乏充分安全规划和治理机制的条件下匆忙跨越,可能带来系统性风险。(卫报) 如何在技术探索与安全约束之间找到恰当平衡,将直接影响我们如何从弱 AI 走向强 AI。
8 迈向强人工智能的现实路径与开放难题
8.1 路线图:从工具到伙伴,从模型到智能体
结合前文对技术谱系和开源生态的分析,可以勾勒出一条相对务实的"从弱到强"路线:
首先,在模型层面持续推动基础模型的多模态化与结构化,让系统对世界的表示更加丰富和精细,包括因果结构、物理约束和社会规范的内化。AGI 相关会议与综述中,多次强调将世界模型与基础模型结合的重要性。(The Millennium Project)
其次,在系统层面将模型升级为智能体,引入持久记忆、工具使用和环境交互能力,让系统能够在时间轴上连贯地追踪目标、执行计划并自我修正。Mensch 等人提出用"连续任务执行时长"来衡量系统实际智能水平,本质上就是在关注智能体在现实世界中的长期表现,而非单次对话或单次推理的成绩。(Business Insider)
再次,在治理层面构建"安全优先"的体系,将评估、监控、对齐和干预机制嵌入强能力系统的全生命周期。Future of Life Institute 与其他机构的报告表明,当前行业在这方面普遍准备不足,需要从公司层面、行业自律和公共监管等多个维度加强。(卫报)
最后,在知识生产模式上充分利用开源生态,通过开源模型、开源评测基准和开源工具链让更多研究者参与到强 AI 的验证和修正过程中,从而在全球范围内形成"集体智能"般的自我纠错与风险缓释机制。(莫尔索随笔)
如果用一张表来概括这一路线的主要阶段,我们可以得到一个高度简化但具有启发性的图景:
表 5 从弱 AI 到强 AI 的阶段性路线(概念性)
| 阶段 | 核心形态 | 主要技术抓手 | 关键风险与挑战 |
|---|---|---|---|
| 工具级弱 AI | 面向单任务的模型或服务 | 传统 ML / DL 模型 | 任务窄、迁移弱、对齐主要靠人工使用规范 |
| 通用基础模型阶段 | 大规模预训练的通用模型 | 自监督预训练、对齐技术、插件化扩展 | 黑箱风险、集中化、数据与偏见问题 |
| 智能体阶段 | 具备记忆、工具与环境交互的代理 | 世界模型、长期记忆、强化学习、多智能体系统 | 行为难以预测,对齐复杂,评估维度激增 |
| 接近/达到 AGI 阶段 | 多模态、多环境下人类水平的持续智能 | 综合集成、稳健对齐、自我监控与治理框架 | 失控风险、社会结构冲击、伦理与法律难题 |
需要强调的是,这一图景并非线性必经之路,而是对当前开源文献和产业实践的一种抽象。不同研究路线可能在某些阶段并行推进或采用截然不同的技术手段,但"模型--智能体--治理"这三个层次,几乎出现在所有通往强人工智能的严肃讨论之中。
8.2 对齐、安全与治理:强 AI 之前的"前置条件"
越接近强人工智能,我们就越需要正视一个现实:安全与治理不是"实现 AGI 之后再补上的附加模块",而是从一开始就必须植入技术路线的前置条件。
在开源文献中,围绕 AI 对齐(alignment)、可控性(controllability)和责任划分的讨论已经迅速升温。AGI-Survey 的报告在路线图中专门划出了"对齐与伦理"部分,指出如果不在系统早期就构建和验证对齐机制,后续在能力更强的阶段修补将变得异常困难。(GitHub)
与此同时,越来越多政策报告提醒人们,AGI 的时间表可能比预期更近,而企业在存在性风险规划上的准备却远远落后。例如 Future of Life Institute 的评估显示,被调查的多家领先公司在"存在性安全规划"上没有一家达到 B 级以上,多数仅为 C 或更低。(卫报) 在这样的背景下,一些学者和机构甚至提出暂时暂停最前沿大模型的训练,以便为安全治理留出时间,这一主张在业界引起了激烈争论。
从弱 AI 走向强 AI,如果不能在技术设计、公司治理和公共政策三个层面同步推进对齐与安全,很可能会陷入"能力先行、安全滞后"的危险路径,这既不利于技术本身的长期发展,也可能对社会产生不可逆的冲击。
9 结语:在连续谱上理解"从弱到强"
回顾本文的讨论,我们可以看到,从弱人工智能到强人工智能,并不存在一条简单的"单调上升曲线",而更像是一条在哲学、工程和社会治理之间不断来回摆动的路径。弱 AI 与强 AI 的区分在塞尔时代主要是一场心灵哲学争论,中国房间论证质疑了任何"纯语法操作等同于理解"的主张;而在大模型时代,这一争论被重新放置到基础模型、开源大模型和代理系统的语境中,我们开始以更细致的维度来审视"什么算通用智能"。(知乎专栏)
基础模型和大语言模型让弱 AI 的能力拓展到了前所未有的范围,开源大模型生态又为我们提供了前所未有的透明度与实验空间;与此同时,AGI 的定义仍在不断被重写,安全与治理的缺口也在持续暴露。AGI-Survey 等开源项目试图用系统性的路线图和分层框架来填补这一空白,而 Future of Life Institute 等机构则提醒我们,在讨论强 AI 的技术前景时,不能忽视存在性风险和全球治理问题。(GitHub)
也许在很长一段时间里,我们都难以给出一个人人满意的"强 AI 已经实现"的判定标准。但这并不妨碍我们在连续谱意义上理解和推动智能系统的发展:在能力上,逐步从窄域走向通用;在结构上,从静态模型走向具身智能体;在治理上,从局部监管走向全球协同。在这个过程中,开源文献与开源模型将继续扮演重要角色,帮助我们在迈向更强智能的同时,保持对透明度、公平性和安全性的坚持。
真正值得警惕的或许并不是强人工智能本身,而是我们在奔向它的过程中是否仍然保有足够的反思、节制与集体智慧。
参考文献(部分开源与公开资料)
[1]Searle, J. (1980). Minds, brains, and programs. Behavioral and Brain Sciences. 相关介绍与中文评论可见:知乎专栏《人工智能:现代方法------第27章 人工智能的哲学、伦理和安全性》。(知乎专栏)
[2]Chinese Room Argument 条目,Encyclopedia Britannica 与 Internet Encyclopedia of Philosophy,对塞尔中国房间思想实验及其批评进行系统梳理。(Encyclopedia Britannica)
[3]Bommasani, R., et al. (2021). On the Opportunities and Risks of Foundation Models. arXiv:2108.07258. 由 Stanford CRFM 等机构维护的基础模型综述与更新。(arXiv)
[4]Xu, B. (2024). On the Definition of Artificial General Intelligence. arXiv:2404.10731. 提出 AGI 的开放环境适应性定义,并综述现有多种定义。(arXiv)
[5]AGI-Survey 项目:Bowen-Xu/AGI-Survey, GitHub 开源仓库与 dongaigc.com 概览文章,系统梳理 AGI 内部机制、接口设计、系统实现与对齐问题。(GitHub)
[6]The Millennium Project. Artificial General Intelligence: Issues and Opportunities. 欧洲委员会委托的 AGI 报告,讨论 AGI 的初始条件与长期风险。(The Millennium Project)
[7]Goertzel, B., et al. (2023). Artificial General Intelligence: 16th International Conference, AGI 2023, Proceedings. Springer. 收录多篇关于 AGI 架构、评估与安全的最新研究。(SpringerLink)
[8]Liu, D. (2024). 2024 Open Source AI Models Analysis------Llama, Qwen, Mistral, DeepSeek. 对多款主流开源大模型的能力与应用进行分析。(莫尔索随笔)
[9]OpenLLM:bentoml/OpenLLM GitHub 仓库,提供运行 Llama3、Mistral、Qwen2 等开源 LLM 的统一接口与模型仓库。(GitHub)
[10]Baseten Blog. The best open source large language model. 综述 2025 年代表性开源大语言模型及其应用场景。(Baseten)
[11]王建峰. 《选择合适的大型语言模型:Llama、Mistral 和 DeepSeek》. 36 氪, 2025. 以工程视角对比多款开源 LLM 的性能与部署考量。(36氪)
[12]Future of Life Institute. AI firms 'unprepared' for dangers of building human-level systems, report warns. The Guardian, 2025. 报告指出多家领先 AI 公司在 AGI 存在性安全规划上的不足。(卫报)
[13]Artificial Intelligencer Newsletter. OpenAI and Google's wrestling match. Reuters, 2025. 讨论 AGI 时间表、不确定性的定义以及大模型在搜索与浏览中的影响。(Reuters)
[14]Business Insider. Mistral's CEO says reaching AGI will be 'a marketing move.' 2025. 采访 Arthur Mensch 关于 AGI 定义与"任务执行时长"指标的观点。(Business Insider)
[15]Le Monde. La part d'ombre des intelligences artificielles qui se disent << open source >>. 2025. 分析 LLM 领域"类开源"现象及新的开源定义讨论。(Le Monde.fr)