Alloc内存分配器
vector类
cpp
namespace std {
// T: 你要存什么类型的数据 (比如 int)
// Alloc: 你想用什么工具来管理内存 (默认送你一个 std::allocator<T>)
template < typename T, typename Alloc = std::allocator<T> >
class vector {
// ... vector 的内部实现 ...
};
}
cpp
// 模板类:如果你不传 Alloc,Alloc 默认就是 std::allocator<T>
std::vector<int> v;
// 等价于 ->
std::vector<int, std::allocator<int>> v;当我学会了内存池,
于是代码就会变成这样:
cpp
// 定义一个使用 MyPoolAllocator 的 vector 类型
std::vector<int, MyPoolAllocator<int>> v;内存碎片
内部碎片
已分配的内存块未被实际使用的部分
外部碎片
分配不出去的内存。
锁
自旋锁
- test_and_set()的作用是检测这个锁是false或true,然后再将锁置为true
- std::memory_order_acquire只是配合test_and_set()的一个参数,保证他是原子操作
cpp
#include <iostream>
#include <atomic> // 必须包含这个库
#include <thread>
#include <vector>
class SpinLock {
private:
// std::atomic_flag 是 C++ 中唯一保证"无锁"的原子类型
// ATOMIC_FLAG_INIT 初始化为"清除"状态 (也就是 false / 未上锁)
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
void lock() {
// test_and_set 做两件事:
// 1. 把 flag 设置为 true (上锁)。
// 2. 返回 flag **之前** 的值。
// 如果之前是 true (别人锁着),返回 true -> while 循环继续转 (Spin)。
// 如果之前是 false (没人锁),返回 false -> while 循环结束 -> 我拿到了锁!
// 这里用 acquire,保证我拿到锁之后,能看见别人改的数据
while (flag.test_and_set(std::memory_order_acquire)) {
// 这里通常放一个 CPU hint,告诉 CPU 我在空转 (可选,但推荐)
// std::this_thread::yield(); // 或者 _mm_pause();
}
}
void unlock() {
// 清除标志位 (设为 false)
// 这里用 release,保证我改完的数据,能被下一个拿锁的人看见
flag.clear(std::memory_order_release);
}
};
// --- 测试代码 ---
SpinLock mySpinLock;
int counter = 0; // 共享资源
void work() {
for (int i = 0; i < 100000; ++i) {
mySpinLock.lock(); // 1. 加锁 (忙等待)
counter++; // 2. 临界区 (很快的操作)
mySpinLock.unlock(); // 3. 解锁
}
}
int main() {
std::thread t1(work);
std::thread t2(work);
t1.join();
t2.join();
// 如果没有锁,结果肯定小于 200000
std::cout << "Final counter: " << counter << std::endl;
return 0;
}原子操作无锁
- CAS(比较并交换)
举一个简单的CAS例子,就是先检查a是否=b,然后交换(a,c)或(b,c)
cpp
a.CAS(b,c);
if(a==b) a=c;
if(a!=b) b=c (下一轮)==> a.CAS(c,c)这样只要a没有被别人改变,这轮就会出去。
这就有点乐观锁的样子。没人动a我就动了,有人动a我就一直循环。把代码中的互斥锁改进一点
我往freeList中前插一个【结点X】
freeList_ (头指针) -> 节点 A
freeList_ -> 节点 X -> 节点 A
- 在 C++ 中,它长这样: `现在的值.compare_exchange_weak(预料值, 渴望指)
cpp
bool MemoryPool::pushFreeList(Slot* X) {
while(true){
x->next=A;
//如果不用CAS,没有互斥要求
//代码只是简单的一局freeList_=X;
//有了互斥操作 就是if(FreeList_=A) freeList_=X
// if(freeList_!=A) A=X,再执行下一轮
if (freeList_.compare_exchange_weak(A, X)
{return true;}
}
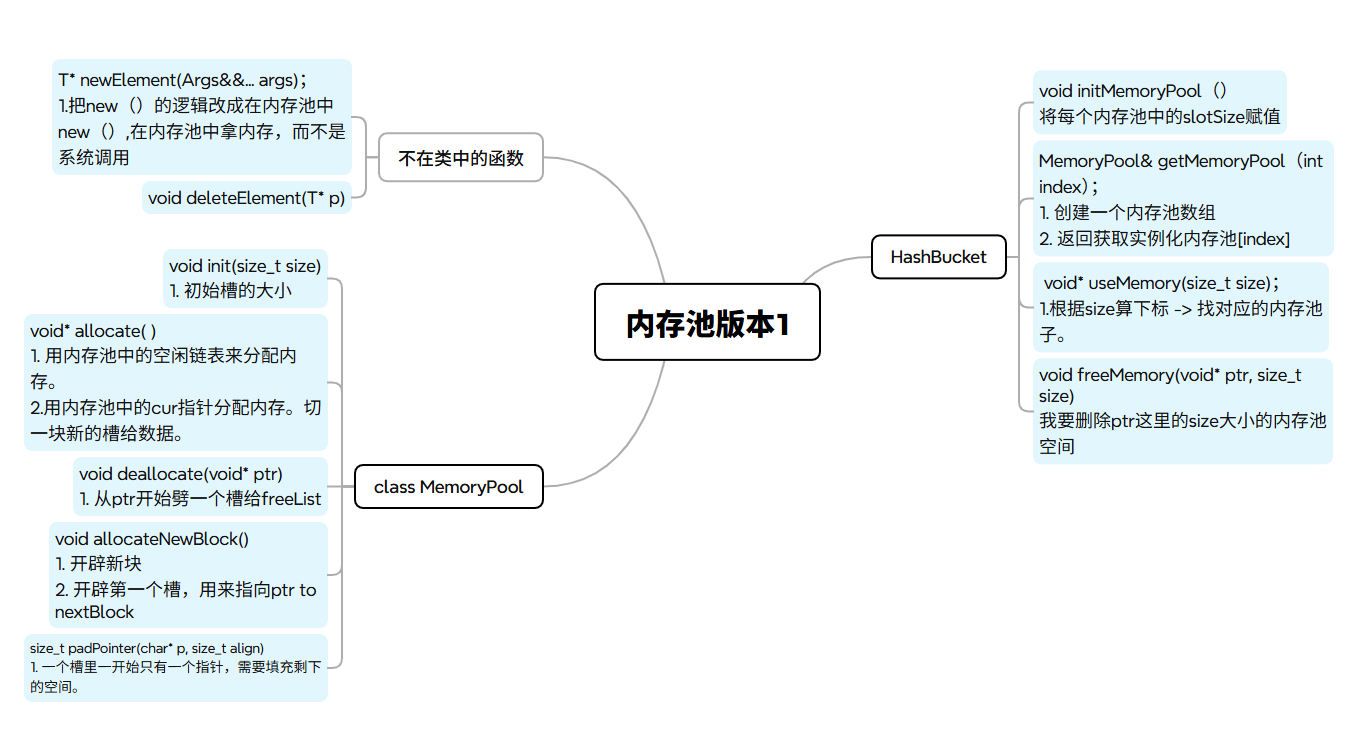
} 内存池的三层结构
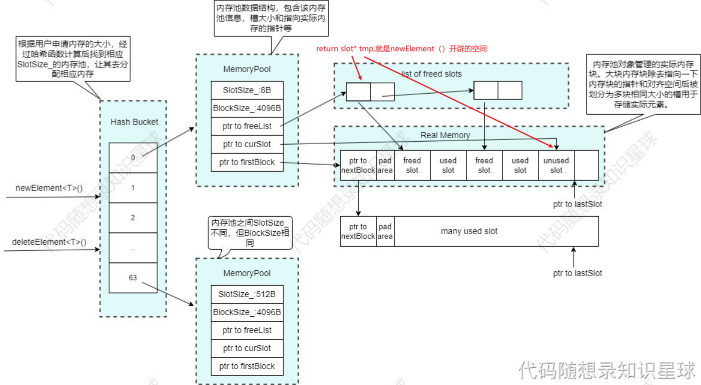
门卫Hash Bucket
前台MemoryPool
房间Real Memory
读源码的思考
神奇的结构体
cpp
struct Slot
{
Slot* next;
};- 作用1.在申请的内存池块中,前8个字节用来把各个内存池串起来。(前8个B内存池不使用)
- 作用2.释放过的槽,前8个字节把这几个槽串起来。(因为这些都是空空的内存,占用8个无所谓)

哈希桶HashBucket
搞了好久,终于是给盘明白了。
-
哈希桶就是处理哈希冲突的一种方式,学名叫"链地址法"(Chaining)。

-
哈希 是一种思想。y=f(x)这就是哈希!!!
-
哈希桶其实就是unordered_map的特列。他的哈希关系f(x)是自己写的,unordered_map是stl规定的。
-
一个简单的哈希桶雏形。由一个链表数组组成。
cpp
#include <iostream>
#include <vector>
#include <list> // 用标准库的链表来模拟"桶"的深度
// 定义一个哈希桶类
class MyHashMap {
private:
// 1. 桶的个数:这里我们只准备 10 个桶
static const int BUCKET_COUNT = 10;
// 2. 真正的"桶"数组
// 这是一个数组,数组的每个元素是一个链表(list)
// 链表里存的是 pair<学号, 分数>
std::list<std::pair<int, int>> buckets[BUCKET_COUNT];
// 3. 哈希函数:决定你去哪个桶
int hashFunction(int key) {
return key % BUCKET_COUNT; // 取个模,结果一定是 0-9
}
public:
// 插入数据
void insert(int id, int score) {
int index = hashFunction(id); // 算出桶号
// 把数据"扔"进对应的桶里(链表尾部插入)
buckets[index].push_back({id, score});
std::cout << "学号 " << id << " -> 放入了 " << index << " 号桶" << std::endl;
}
// 查找数据
int findScore(int id) {
int index = hashFunction(id); // 先算桶号,直接定位到那个桶
// 然后在这个桶(链表)里挨个找(线性查找)
// 只要桶里的数据不多,这个过程非常快
for (auto& pair : buckets[index]) {
if (pair.first == id) {
return pair.second; // 找到了!
}
}
return -1; // 没找到
}
};
int main() {
MyHashMap myMap;
// 模拟插入
myMap.insert(11, 95); // 11 % 10 = 1,去1号桶
myMap.insert(21, 88); // 21 % 10 = 1,也去1号桶(冲突了,但没关系,桶里能装)
myMap.insert(35, 60); // 35 % 10 = 5,去5号桶
// 模拟查找
std::cout << "查找学号 21 的成绩: " << myMap.findScore(21) << std::endl;
return 0;
}单例模式
单实例对象,操作来操作去都是针对一个对象
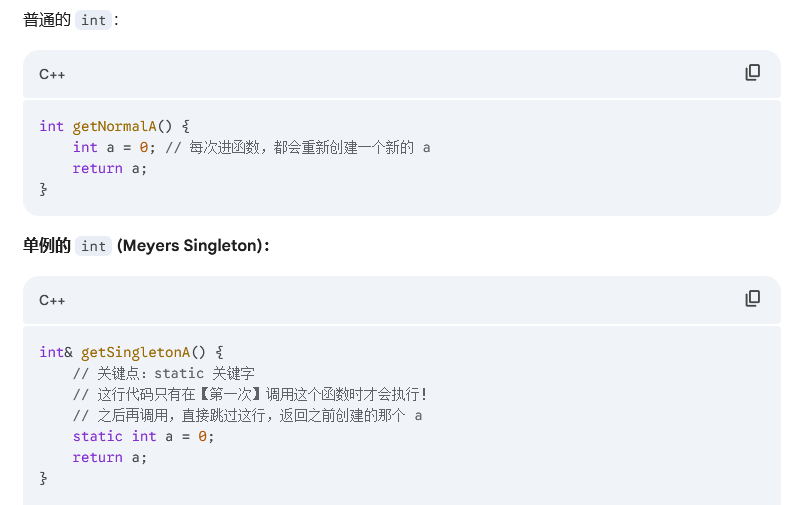
memoryPool的单例模式为什么不在memoryPool的类中写,要在hashbucket中写?
如果是在memoryPool类中写,就不能体现缓存池的差异化了。而且本身缓存池就是哈希桶中的桶,又哈希桶来进行管理。
static void initMemoryPool()/static MemoryPool& getMemoryPool(int index);这个两个函数的定义为什么不像其他Hashbucket类中的函数一样,在类里面定义。反而是在cpp文件中定义?
首先我们得知道函数定义写在类中,编译器会把这些函数当做内联函数处理。
内联函数就是,在处理函数调用的时候,不会在回调call,而是直接在这里展开函数。
这两个函数使用频率很低,所以就不设置为内联函数喽!
缓存池数组要设计成单例模式,为什么哈希桶不也设计成单例模式呢?哈希桶整个程序也是独一份啊?
- 首先HashBucket 其实已经实现了"精神上的单例",但它采用了一种更轻量级、性能更高的手段------全静态成员。
- 其次单例模式是给会实例化变成对象的类用的。HashBucket是一个无成员变量的函数,他没有实例化的需要,所以不需要设计成单例模式。
- 所以哈希桶是一种哈希y=f(x)的规则,内存池是一个对象!!!
operator new(size)
与 new a()不同 。= 分配内存 + 在上面构造对象。
operator new(size)= 只申请这么一块空间。
void* 与nullptr的区别
void* 是无类型指针,`void* useMemory(size_t size)`是有返回值的,不是没有
nullptr是空指针。new T()与 new(ptr)T()的区别?
-
普通 new: new T() = 申请新内存 + 构造。
-
定位构造。new§ T() = 指针p之前有申请过内存,只是在上面没有创建对象。现在直接在已有的地址 p 上,调用构造函数把对象造出来。
项目测试(重要,先看这)
线程的创建
cpp
vthread[k] = std::thread([&]() {
。。。
}
如果不写Lambda表达式就得
cpp
// 1. 必须先在外面定义一个函数,用来干活
// 注意:还要把所有需要的变量通过参数传进去,很麻烦
void worker_task(size_t rounds, size_t ntimes, long long& total_costtime) {
for (size_t j = 0; j < rounds; ++j) {
// ... 你的测试逻辑 ...
}
}
// 2. 然后在创建线程时,传入函数名和参数
vthread[k] = std::thread(worker_task, rounds, ntimes, std::ref(total_costtime));在主线程中定义的size_t total_costtime = 0; 为什么新线程也能使用total_costtime += end1 - begin1;
因为Lambda函数有一个【&】,可以把主线程中的变量全部拿过来用,哈哈哈哈哈哈哈。join()函数
就是主线程会在这里等待,等新线程返回。根据测试代码捋清思路
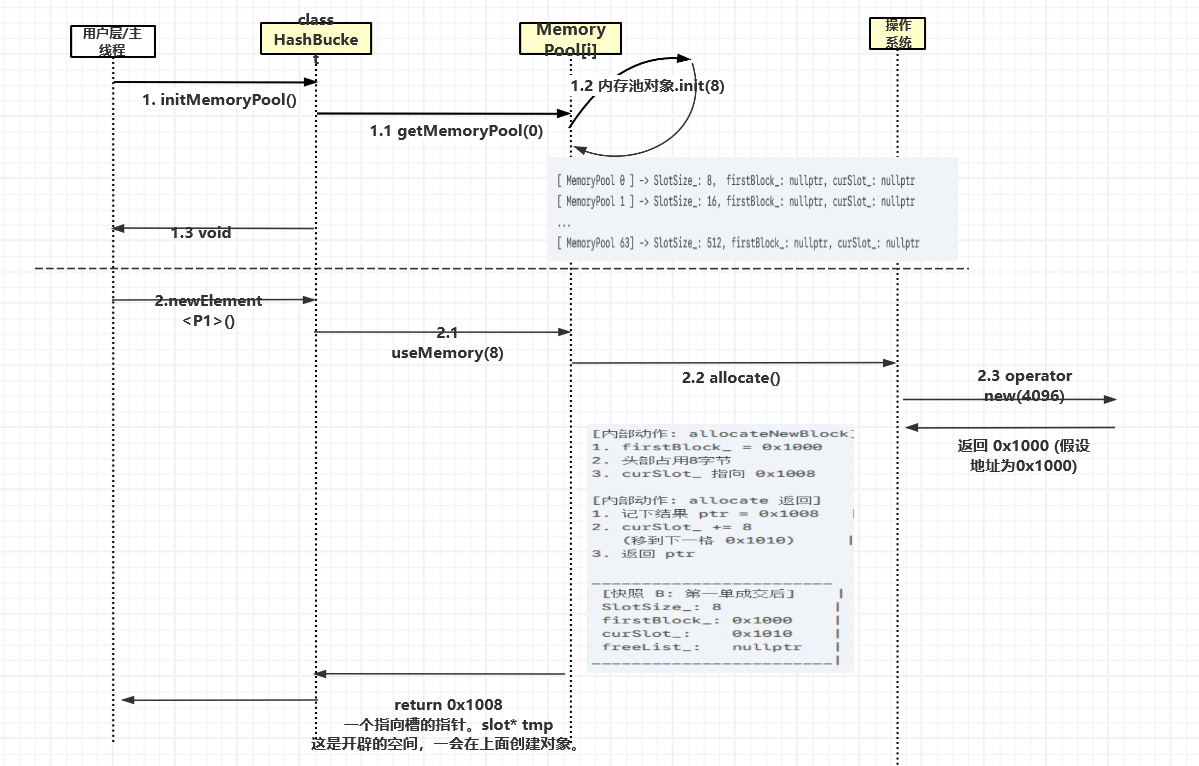
-
HashBucket::initMemoryPool();- 创建了几个对象(一个对象数组),同时规定对象的槽大小。
- 没有哈希桶就是这几个对象数组。

-
从
BenchmarkMemoryPool(100, 1, 10); 进入P1* p1 = newElement<P1>();- 假设sizeof(P1) 是 8字节(对应 0号池子,SlotSize=8)
- 进入
useMemory(8)算出来找 0号池子。 - 进入 0号池子的对象重。memoryPool0.allocate()。
-
现在是memoryPool对象的逻辑。
freeList_是 nullptr? 是。(没人退货),curSlot_是 nullptr 吗? 是。(还没进过货),curSlot==lastSlot,触发allocateNewBlock(),进入allocateNewBlock()- 调用系统: operator new(4096)。更新firstBlock_,curSlot_,lastSlot_。
allocateNewBlock()结束后,回到allocate中,把P1类型放入第一个槽中,curSlot_再次后移,返回指向第一个槽的指针给useMemory(),再返回给newElement()。- newElement()就
new(返回的槽指针) P1(); 