一、传输层协议UDP
1. 理解UDP协议
我们以前说过,0-1023端口号是知名端口号,它们是与指定的协议进行关联的,那么我们如何证明呢?
在指定目录下就可以查找到这些协议的端口号了 (/etc/services)。


这里以两个例子来说明情况。
前面我们也说过协议就是一种约定,本质就是结构体。今天我们来正式认识一下UDP协议。
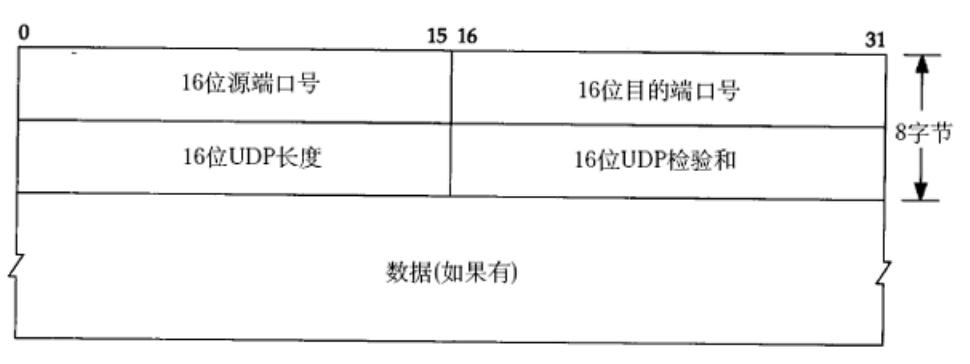
可以看到UDP协议的宽度是32位,源端口号和目的端口号分别占16位,UDP协议的报头是8字节。
前面我们说过,源主机的数据发送给目标主机需要先经历封装在解包的过程 ,而在这个过程中需要面临两个问题,一是报头和有效载荷的分离,二是分用问题(即应该将有效载荷交给上层的哪一个协议进行处理)。
现在就可以回答这两个问题了。报头和有效载荷的分离是通过报头的长度解决的,UDP协议的报头固定是8个字节。
那该如何解决分用问题呢?如何返回给对端呢?(假设目标向源主机返回)
是通过端口号实现的,UDP协议里带着源主机和目标主机的端口号呀,端口号唯一约定着关联的协议。
2. 面向数据报
那为什么说UDP协议是面向数据报的呢?
UDP协议里还有一个16位的UDP长度,该长度表明UDP协议的总长度,总长度 - 8字节,剩下的就是正文部分的长度了,只需要比较正文长度和总长度 - 8 字节(即剩下的字节长度)是否相等即可。
UDP的长度是发送端的UDP层填写的,应用层交给UDP多长的报文,UDP原样发送,既不会拆分也不会合并 ,假设发送端调用一次sendto,发送100个字节,那么接收端也必须调用一次recvfrom,接收100个字节,而不能循环调用recvfrom,这就叫做面向数据报。
3. UDP的缓冲区
UDP没有真正的发送缓冲区,因为没必要,UDP协议不考虑可靠性,不考虑失败了重传等问题,调用sendto会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作。
UDP具有接收缓冲区,但是这个接收缓冲区不能保证接收的UDP报的顺序和发送UDP报的顺序一致。如果缓冲区满了,再到达的UDP数据就会被丢弃,所以,下下一次到达的数据就有可能被接收,而上一次到达的数据会被丢弃,所以不能保证一致性。
udp的socket既能读也能写,这个概念叫做全双工。
UDP的注意事项 :我们可以看到在UDP协议里有一个16位的UDP长度,代表着UDP协议的总长度,也就是说UDP协议一次性最多只能发送2^16次方大小的数据 ,那如果发送的数据比这个数值大呢?那就只能在应用层进行分包,多次发送了。
4. 理解什么是报文
比如,主机A现在给主机B发送数据,该数据在应用层就要经历一次封装,即添加报头,形成一个新的报文,再将该报文传递给传输层,传输层添加自己的协议报头,形成一个新的报文,以此类推,对端再依次进行解包,可是主机A给主机B发送数据并不只是发送一次,而且在网络中也不仅仅只有这两台主机在通信,所以在OS中一定会有大量的报文,在不同的层,也一定会同时存在多个报文 ,那么OS要不要对这些报文进行管理呢?答案是要的,先描述在组织。
所以,在OS内就会有描述报文的结构体 ,但是有一个新的问题,数据在网络中传输是需要经过网络协议栈的,也就是说在每一层都会有不同的报文,那我们要用结构体去描述报文,难道要给每一层都要描述一个报文的结构体吗 ?那这样岂不是太麻烦了,我们肯定是想要用一个结构体来描述所有报文的。报文也是有数据的,所以也是需要内存空间来存储报文的。
现在大家对于报文已经有了一个概念了,但是大家还不能区分报文和报头的区别,我们就一起来了解一下。
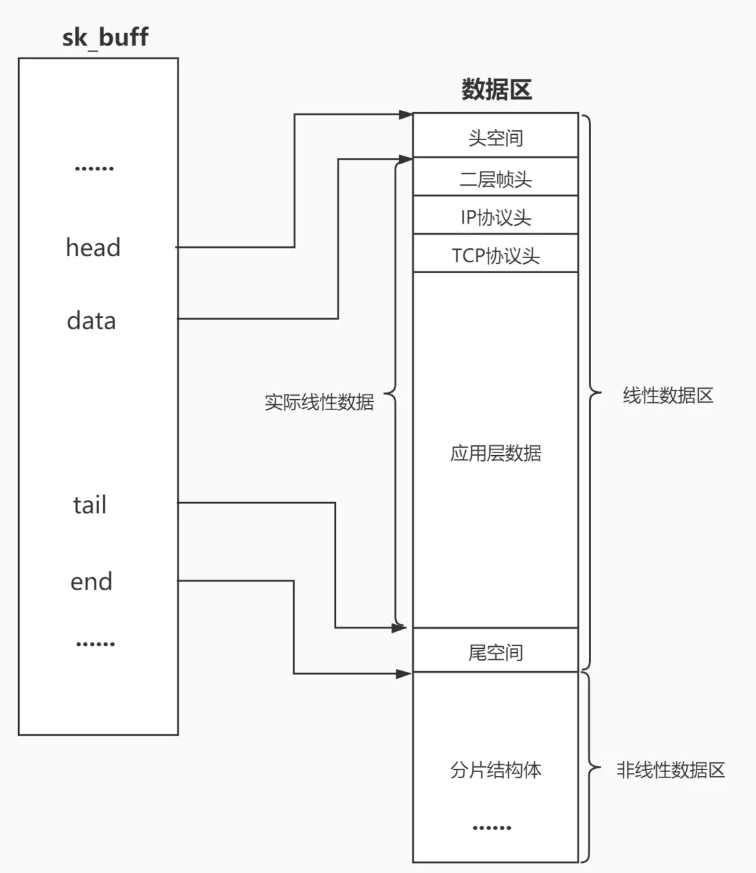
在OS中描述报文的结构体叫做struct sk_buff,这个结构体里有几个成员
struct sk_buff
{
struct sk_buff* next;
struct sk_buff* prev;
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char* head,*data;
}可以看到,next,prev指针就表明了报文在OS中是以双链表的形式管理的,而head,end指针分别指向数据区的起始和末尾位置,这两个不作为重点。接着便是data,tail指针了,tail指针指向应用层数据的末尾位置,data指针刚开始指向应用层数据的起始位置,当应用层数据传递给传输层,添加传输层协议报头之前,就需要对data指针进行操作了,将data指针向上移动传输层协议报头的长度,就可以添加报头了,到达网络层也是一样的道理,继续向上移动网络层协议的报头长度,就为网络层协议报头留出了空间,这就是封装。反之,解包就是封装的反过程,将data指针向下移动链路层协议的报头,剩下的就是有效载荷。这就是解包。之所以封装时指针向上移动,是因为默认上面的地址空间是低地址。
网络报文,在系统中的存在,其实就是一个内存空间布局。
可以结合下面这张图理解。
5. socket和文件系统的关系
网络通信的操作本质上也是一个进程发起的,是进程就有PCB,文件描述符 ,所以在struct file结构体里有一个void* private_data指针,该指针就指向struct socket结构体,这个结构体里有以下几个成员
struct socket
{
socket_state state;//描述网络通信的状态
const struct proto_ops* ops;//网络协议的操作
struct file* file;//回指向struct file
struct sock* sk;//指向struct sock结构体
wait_queue_head_t wait;//等待队列
}这就是为什么网络通信需要返回一个文件描述符的原因了 ,通过file指针回指向file结构体,就可以通过private_data指针找到socket,从而进行网络通信,符合linux下一切皆文件的大一统思想,同时降低了学习者的成本,要不然还要再系统性的学习一套关于网络通信的接口。
在struct socket结构体里还有一个指针struct sock* sk指针,该指针指向一个struct sock结构体。
struct sock
{
struct sk_buff_head sk_receive_queue;//接收缓冲区
struct sk_buff_head sk_write_queue;//发送缓冲区
}这两个缓冲区的指针类型是struct sk_buff_head,这也是一个结构体。
struct sk_buff_head
{
struct sk_buff* next;
struct sk_buff* prev;
}看到这里大家应该已经明白的差不多了。不过不知道大家有没有疑问呢?struct sk_buff_head结构体里有struct sk_buff* next,*prev指针,struct sk_buff结构体里也有这两个指针,它们之间是怎么回事呢?
前面我们已经说过,struct sk_buff结构体是用来描述报文的,而这两个指针是用来实现双链表管理报文队列的,那struct sk_buff_head里的这两个指针是用来干什么的呢?
这两个指针是用来分别指向struct sk_buff结构体,即第一个报文的节点,而prev指针是用来指向报文最后一个节点的,这两个指针管理着报文队列的生命周期。struct sk_buff和struct sk_buff_head结构体里的这四个指针一起共同管理着报文队列。