HTTP
1. HTTP协议
HTTP (HyperText Transfer Protocol,超⽂本传输协议)是一种用于传输超文本(例如 HTML)的应用层协议。它定义了客⼾端(如浏览器)与服务器之间如何通信。
HTTP协议是客⼾端与服务器之间通信的基础。客⼾端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP协议是⼀个**⽆连接、⽆状态**的协议,即每次请求都需要建⽴新的连接,且服务器不会保存客⼾端的状态信息。
HTTP 依赖于 TCP(传输控制协议)和 IP(互联网协议)来建立可靠的数据连接。默认使用端口 80 (HTTP)和 443(HTTPS)。
什么是超文本 :超文本 是一种通过超链接将各种信息块(如文本、图片、音频、视频等)相互关联、非顺序地组织起来的信息系统。
什么是无连接:虽然HTTP底层使用的是TCP,而TCP是有连接的,但是HTTP无关连接的概念(比如底层是新连接还是旧连接,是长连接还是短连接),只关注请求(request)和响应(response)。
-
混淆点:HTTP/1.1的 Header 中添加
Connection: keep-alive来建议底层TCP不要关闭连接,以遍通过一个文件描述符重用。换句话说:它允许在同一个TCP连接上,顺序地发送多个HTTP请求和接收多个HTTP响应,而不是发送一个请求,返回一个响应,就关闭连接。 -
为什么?
- 因为现代网页可能因为图片等等一次发送多次请求,每一次建立关闭连接,都伴随着 TCP三次握手的延迟 和 TCP慢启动 的性能损耗,这造成了巨大的资源浪费和页面加载延迟。
什么是无状态:默认情况下,HTTP协议本身不会保留之前任何请求或响应的任何信息。每个请求都被视为一个全新的、独立的请求,服务器不会记住你是谁。 但是这样的方式,会给用户带来困扰,为了解决这种无状态带来的问题,主要技术有 Cookie(存储在客户端) 和 Session(存储在服务端)。
2. 认识URL
URL (统一资源定位符),一个完整的URL包含多个部分,我们以这个例子来说明:
https://www.example.com:8080/path/to/myfile.html?key1=value1&key2=value2#section2
| 部分 | 例子 | 作用解释 |
|---|---|---|
| 协议 | https |
浏览器与服务器之间使用什么协议通信 |
| 域名 | www.example.com |
网站的域名,会被DNS解析成服务器的IP地址 |
| 端口 | 8080 |
服务器的端口号 |
| 路径 | /path/to/myfile.html |
指服务器上web根目录的资源文件路径 |
| 查询字符串 | ?key1=value1&key2=value2 |
向服务器传递额外信息,通常用于搜索、筛选或表单提交。以 ? 开头,多个参数用 & 连接 |
| 片段标识符 | section2 |
URL 中井号 (#) 后面的部分,它用于指向资源内部的某个特定片段或锚点 |
怎么理解web根目录,本质就是服务端的一个文件夹,资源就是该文件夹下的某个文件。
3. urlencode与urldecode
URL 在设计上有严格的格式要求,只能使用一个有限的字符集,主要包括:
- 保留字符 : 如
:,/,?,#,&,=,+等。这些字符在 URL 中有特殊含义(分隔协议、路径、查询参数等)。
如果 URL 中包含这些有特殊含义的字符,就会引起歧义和错误。
1.什么是URLEncode?
URLEncode 是一种机制,用于将 URL 中不允许 或有特殊用途 的字符,转换为一个以百分号(%)开头,后面跟着两个十六进制数字表示的 ASCII 字符。
-
对于需要编码的字符:
-
将其转换为其在 UTF-8 编码下的字节序列。
-
然后将每个自己表示为
%XX的形式,其中XX是该字节的十六进制值。
-
-
例如:中文
中:-
首先,
中字的 UTF-8 编码是三个字节:E4 B8 AD。 -
然后,将每个字节转换为
%XX形式。 -
最终编码结果为:
%E4%B8%AD。
-
2.什么是URLDecode
URLDecode 是 URLEncode 的逆过程。它将 URL 中经过百分号编码的序列(%XX)转换回它们所代表的原始字符。服务器收到客户端编码后的请求,会将其解码回原始数据。
4. HTTP请求与响应格式
请求格式:
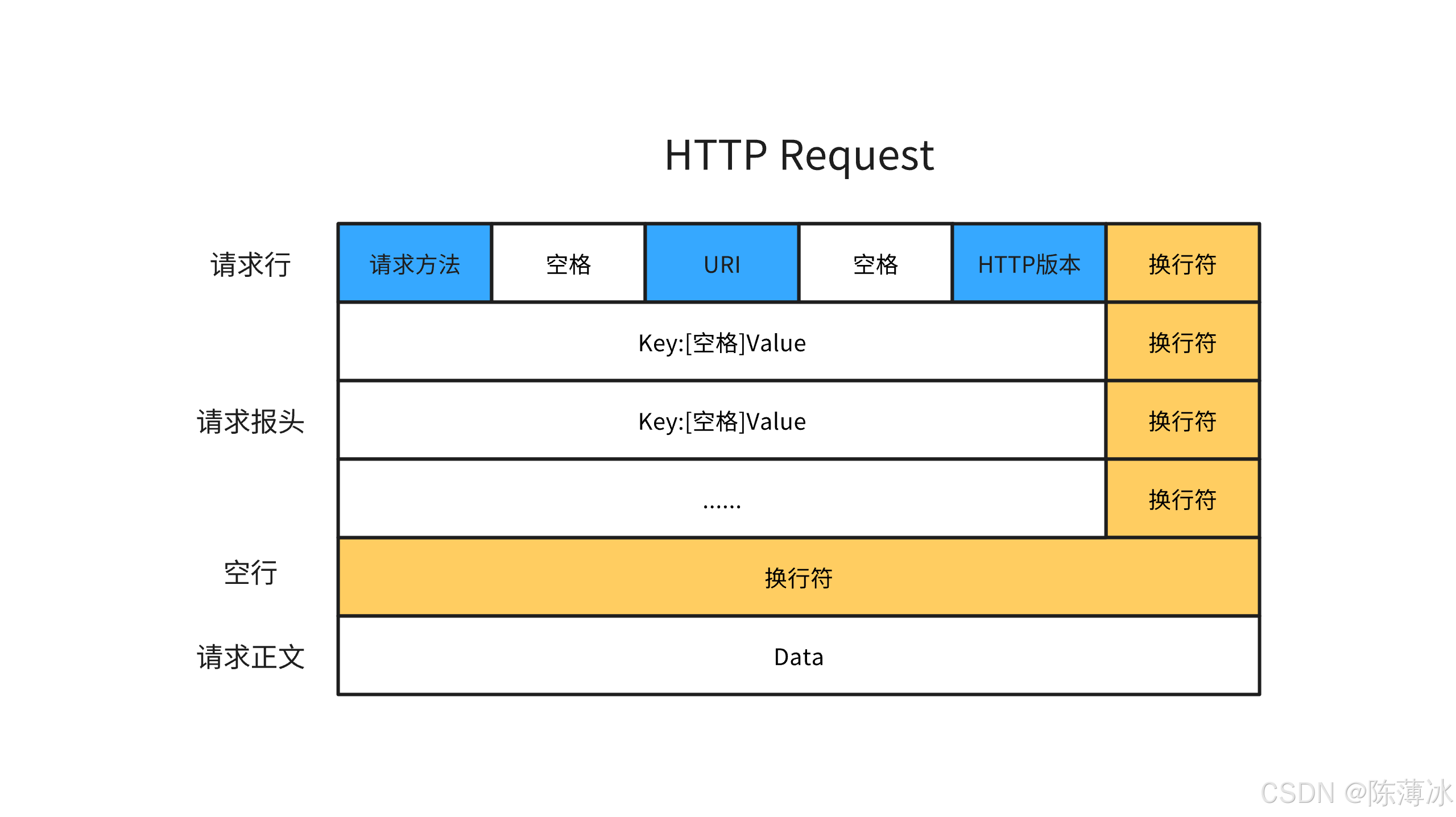
响应格式:
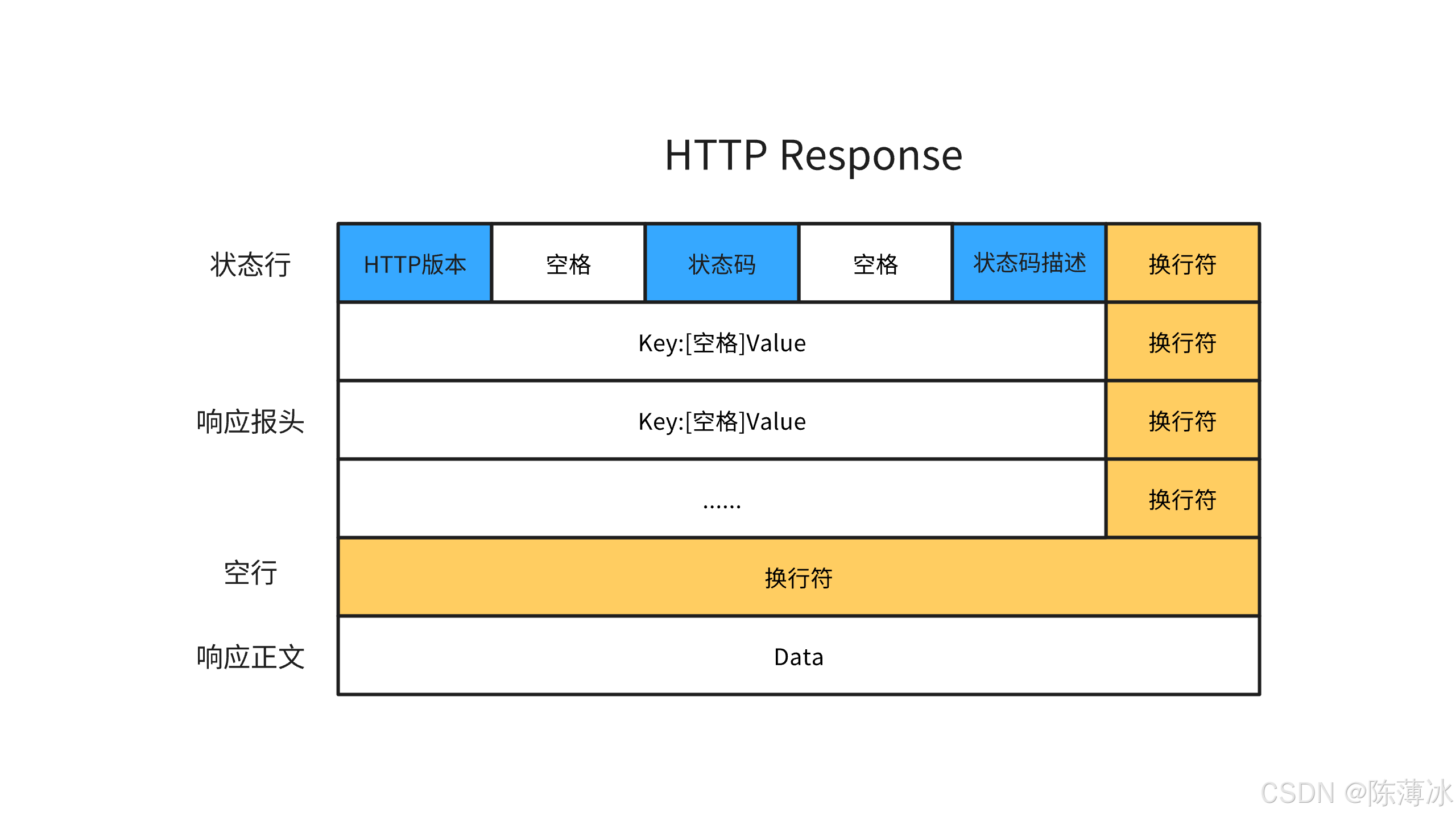
-
HTTP协议中,换行符正确的规范要求是:
\r\n。 -
正文的内容允许为空字串,若正文存在,则Header中会有一个Content-Length属性来表示正文的长度,若服务器返回的一个html页面,那么html页面内容就在正文中。
5. 理解URI
URI 的全称是 Uniform Resource Identifier ,中文是 统一资源标识符 。它的核心作用是:在网络上 唯一地标识 一个静态资源(文件、图片、视频等)或动态资源(执行服务端的逻辑,比如需要后端的某一个函数来处理服务)。
在整个 URL 中,/path/to/myfile.html?key1=value1&key2=value2 属于访问静态资源的 URI;/Login?username=ccc&passwd=123456 属于访问动态资源(比如调用后端的验证登录方法函数)。
当 URI 为
\通常代表访问的是服务端下web根目录的index.html文件。在访问静态资源的时候,通常是服务端通过web根目录 + uri的拼接来完成访问的。
web根目录就是服务端的一个文件夹。
6. HTTP的方法
5.1 GET方法
GET 方法用于请求 指定资源的表示形式。使用 GET 的请求应该只用于获取数据 。GET请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,远小于 POST 方法,因此 GET 不适合传输大量数据。
示例:GET /index.html HTTP/1.1
GET 请求的所有参数都必须放在 URL 的 查询字符串 部分。
格式:
text
https://api.example.com/users?参数1=值1&参数2=值2&...GET请求的语义是获取,但它获取的资源可以是一个静态的数据(如文件),也可以是一个动态过程,完全可能涉及复杂的服务器端服务与计算。
-
静态资源:
GET /images/logo.png,服务器直接读取文件内容并返回。 -
动态资源:
-
GET /Login?user=ccc&password=123456 HTTP/1.1-> 服务器解析这个请求,并调用对应的Login服务(服务端的函数),从数据库中查询该用户信息进行处理和操作。 -
GET /search?q=apple-> 服务器调用搜索服API务(服务端的一个处理函数),在索引中查找apple,对结果进行排序、分页,最后生成一个结果页面返回。
-
Restful API:核心思想如果使用不同的HTTP方法,会被路由到不同的后端函数。
在实践中,一个 RESTful API 通常表现出以下特征:
1.以资源为中心
一切皆资源。资源可以是一个用户、一篇文章、一张图片,或者一个订单。每个资源都有一个唯一的标识符,即 URI。
-
示例URI:
-
https://api.example.com/users- 代表所有用户的集合。 -
https://api.example.com/users/123- 代表 ID 为 123 的特定用户。
-
2.使用标准的 HTTP 方法
对资源的操作通过 HTTP 方法来实现,这些方法对应着经典的 CRUD 操作。
| HTTP 方法 | CRUD 操作 | 描述 | 示例 |
|---|---|---|---|
| GET | Read | 获取资源(一个或多个)。 | GET /users (获取所有用户) |
| POST | Create | 创建新资源。 | POST /users (创建一个新用户) |
| PUT | Update | 更新整个资源(全部替换)。 | PUT /users/123 (更新用户123的所有信息) |
| PATCH | Update | 部分更新资源。 | PATCH /users/123 (只更新用户123的邮箱) |
| DELETE | Delete | 删除资源。 | DELETE /users/123 (删除用户123) |
3.无状态通信
每个请求都是独立的,服务器不保存任何会话信息。认证信息(如 Token、Cookie)必须包含在每一个请求中。
4.返回标准化的数据格式
服务器返回的数据通常是 JSON 或 XML 格式,现在 JSON 是绝对的主流。
5.2 POST方法
POST 方法主要用于向服务器提交数据,与 GET 形成了鲜明的对比。
示例:POST /api/users HTTP/1.1
POST 请求的特性是可以发送⼤量的数据给服务器,并且数据包含在请求体中。
GET和POST都是不安全的,因为是明文传输,通过HTTPS解决的。
7. HTTP的状态码
6.1 状态码类别
| 范围 | 类别 | 原因短语 |
|---|---|---|
| 1XX | 信息性状态码 | 接收的请求正在处理 |
| 2XX | 成功状态码 | 请求正常处理完毕 |
| 3XX | 重定向状态码 | 需要客户端进行附加操作完成请求 |
| 4XX | 客户端错误状态码 | 服务器无法处理请求 |
| 5XX | 服务器错误状态码 | 服务器处理请求出错 |
6.2 具体状态码
| 状态码 | 含义 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时,服务器告诉客户端可以继续上传 |
| 200 | OK | 请求成功,资源已在响应正文中返回 |
| 201 | Created | 请求成功,并且服务器创建了新的资源 |
| 204 | No Content | 服务器成功处理了请求,但不需要返回任何实体内容,例如对 DELETE 请求的成功响应 |
| 301 | Moved Permanently | 网站换域名后,自动跳转到新域名,浏览器会记住这个新地址,下次你访问旧地址时,它会自动跳转到新地址 |
| 302 | Found 或 See Other | 请求的资源被临时地被另一个不同的 URI 响应,用户登录成功时,重定向到用户首页 |
| 304 | Not Modified | 资源未被修改,客户端可以使用缓存的版本 |
| 400 | Bad Request | 请求报文中存在语法错误,服务器无法理解 |
| 401 | Unauthorized | 尝试访问需要登录的页面,未登录或认证失败 |
| 403 | Forbidden | 尝试访问没有权限查看的页面(用户已登录,但没有访问该资源的权限) |
| 404 | Not Found | 服务器找不到请求的资源 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时,代理服务器无法从上游服务获取有效的响应 |
| 503 | Service Unavailable | 服务器暂时处于超负载或正在进行停机维护,暂时无法处理请求 |
8. HTTP常见的Header
-
Content-Type: 数据类型。
-
text/html: HTML格式 -
text/plain:纯文本格式 -
image/jpeg:jpg图片格式 -
image/png:png图片格式 -
application/json: JSON数据格式
-
-
Content-Length: 正文的⻓度。
-
Host: 客⼾端告知服务器,所请求的资源是在哪个主机的哪个端⼝。
-
User-Agent: 声明⽤⼾的操作系统和浏览器版本信息。
-
Referer: 当前⻚⾯是从哪个⻚⾯跳转过来的(发起当前请求的页面的源 URL)。
-
Location: 搭配3xx状态码使⽤, 告诉客⼾端接下来要去哪⾥访问(会二次请求)。
-
Cookie: ⽤于在客⼾端存储少量信息,通常⽤于实现会话(session)的功能。
-
Connection: 管理持久连接,
Connection字段还⽤于管理持久连接(也称为⻓连接)。持久连接允许客⼾端和服务器在请求/响应完成后不⽴即关闭TCP连接,以便在同⼀个连接上发送多个请求和接收多个响应。-
Connection: keep-alive: 表⽰希望保持连接以复⽤TCP连接。 -
Connection: close: 表⽰请求/响应完成后,应该关闭TCP连接。
HTTP/1.1协议中,默认使用持久连接,HTTP/1.0中,默认连接是非持久的。
-
| 字段名 | 含义 | 样例 |
|---|---|---|
| Accept | 客⼾端可接受的响应内容类型 | Accept: text/html,application/xhtml+xml,application/xm l;q=0.9,image/webp,image/apng,*/*;q=0.8 |
| Accept-Encoding | 客⼾端⽀持的数据压缩格式 | Accept-Encoding: gzip, deflate, br |
| Accept-Language | 客⼾端可接受的语⾔类型 | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 |
| Host | 请求的主机名和端⼝号 | Host: www.example.com:8080 |
| User-Agent | 客⼾端的软件环境信息 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 |
| Cookie | 客⼾端发送给服务器的HTTP cookie 信息 | Cookie: session_id=abcdefg12345; user_id=123 |
| Referer | 请求的来源URL | Referer: http://www.example.com/previous_page.html |
| Content-Type | 实体主体的媒体类型 | Content-Type: application/x-www-form-urlencoded (对于表单提交)或 Content-Type: application/json(对于JSON数据) |
| Content-Length | 实体主体的字节⼤⼩ | Content-Length: 150 |
| Authorization | 认证信息,如⽤⼾名和密码 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== (Base64编码后的⽤⼾名:密码)` |
| Connection | 请求完后是关闭还是保持连接 | Connection: keep-alive 或 Connection: close |
| Date | 请求或响应的⽇期和时间 | Date: Wed, 21 Oct 2023 07:28:00 GMT |
| Location | 重定向的⽬标URL(与3xx状态码配合使⽤ | Location: http://www.example.com/new_location.html (与302状态码配合使⽤) |
| Server | 服务器类型 | Server: Apache/2.4.41 (Unix) |
| Last-Modified | 资源的最后修改时间 | Last-Modified: Wed, 21 Oct 2023 07:20:00 GMT |
| ETag | 资源的唯⼀标识符,⽤于缓存 | ETag: "3f80f-1b6-5f4e2512a4100" |
| Expires | 响应过期的⽇期和时间 | Expires: Wed, 21 Oct 2023 08:28:00 GMT |
9. Cookie与Session
什么是Cookie: 是一小段文本信息,由服务器发送给浏览器,由浏览器保存在本地 。下次浏览器再访问同一服务器时,会自动携带这个Cookie。(比如登录时的用户名和密码)
-
类别:
-
内存级Cookie
-
文件级Cookie
-
什么是Session: 是服务器上创建和维护的一个会话对象(class),用于在服务器端存储用户的状态信息。
通过登录例子理解(Cookie + Session):
-
你在登录页面输入了用户名和密码,点击登录按钮,浏览器会向对应服务器发送一个HTTP请求,请求体中包含了你的账号和密码。(此时浏览器和请求头中还没有任何Cookie信息)
-
服务器收到请求后,进行验证,验证通过后,并在服务器内部为该用户创建一个Session对象,Session对象包含你想要记录的信息(用户名、密码、登录时间、权限级别等),并为该Session对象生成一个唯一的Session ID。
-
服务器返回给客户端的HTTP响应头中添加Set-Cookie:
httpSet-Cookie: session_id=sess_abc123xyz; Path=/; HttpOnlyPath=/: 意味着这个 Cookie 对于该网站下的所有路径都是有效的。HttpOnly: 仅用于 HTTP,这是一个至关重要的安全属性 。它告诉浏览器,这个 Cookie 只能通过 HTTP 请求来访问,而不能通过客户端的 JavaScript 代码来读取、修改或删除。
-
客户端在收到该响应后,就会在本地创建一个Cookie,把这个键值对保存起来。
-
客户端在之后的请求中,会在该请求头中带上这个Cookie:
httpCookie: session_id=sess_abc123xyz -
服务器通过请求头中的 session_id 去自己的 Session 存储库中查找,查找到,就可以进行资源的访问了。
若没有cookie + session 可能每次访问资源都需要重新登录,对用户很不友好,这正是因为HTTP本身是无状态的。
10. HTTP版本
10.1 HTTP/1.0
核心:
-
引⼊POST和HEAD请求⽅法。
-
请求和响应头信息,⽀持多种数据格式(MIME)。
-
⽀持缓存(cache)。
-
状态码(status code)、多字符集⽀持等。
时代背景:
-
1996年,随着互联⽹的快速发展,⽹⻚内容逐渐丰富,HTTP/1.0版本应运⽽⽣。
-
为了满⾜⽇益增⻓的⽹络应⽤需求,HTTP/1.0增加了更多的功能和灵活性。
-
然⽽,HTTP/1.0的⼯作⽅式是每次TCP连接只能发送⼀个请求,性能上存在⼀定局限。
10.2 HTTP/1.1
核心:
-
引⼊持久连接(persistent connection),⽀持管道化(pipelining)。
-
允许在单个TCP连接上进⾏多个请求和响应,提⾼了性能。
-
引⼊分块传输编码(chunked transfer encoding)。
-
⽀持Host头,允许在⼀个IP地址上部署多个Web站点。
时代背景:
-
1999年,随着⽹⻚加载的外部资源越来越多,HTTP/1.0的性能问题愈发突出。
-
HTTP/1.1通过引⼊持久连接和管道化等技术,有效提⾼了数据传输效率。
-
同时,互联⽹应⽤开始呈现出多元化、复杂化的趋势,HTTP/1.1的出现满⾜了这些需求。
10.3 HTTP/2.0
核心:
-
多路复⽤(multiplexing),⼀个TCP连接允许多个HTTP请求。
-
⼆进制帧格式(binary framing),优化数据传输。
-
头部压缩(header compression),减少传输开销。
-
服务器推送(server push),提前发送资源到客⼾端。
时代背景:
-
2015年,随着移动互联⽹的兴起和云计算技术的发展,⽹络应⽤对性能的要求越来越⾼。
-
HTTP/2.0通过多路复⽤、⼆进制帧格式等技术,显著提⾼了数据传输效率和⽹络性能。
-
同时,HTTP/2.0还⽀持加密传输(HTTPS),提⾼了数据传输的安全性。
10.4 HTTP/3.0
核心:
-
使⽤QUIC协议替代TCP协议,基于UDP构建的多路复⽤传输协议。
-
减少了TCP三次握⼿及TLS握⼿时间,提⾼了连接建⽴速度。
-
解决了TCP中的线头阻塞问题,提⾼了数据传输效率。
时代背景:
-
2022年,随着5G、物联⽹等技术的快速发展,⽹络应⽤对实时性、可靠性的要求越来越⾼。
-
HTTP/3.0通过使⽤QUIC协议,提⾼了连接建⽴速度和数据传输效率,满⾜了这些需求。
-
同时,HTTP/3.0还⽀持加密传输(HTTPS),保证了数据传输的安全性。