前言

你是否曾遇到过这种情况?你写的服务器程序,在几个用户访问时一切正常,但当连接数稍微一多,整个服务就变得异常缓慢,甚至直接卡死。你查看CPU和内存,发现资源远未耗尽,但请求就是被堵在了某个地方,无法得到响应。
这背后的"罪魁祸首",往往就是低效的I/O处理模型。它就像一条狭窄的公路,即使你的汽车(CPU)性能再强,一旦车流(并发请求)增大,所有的车都会被堵在路上,谁也动不了。
而解决这个问题的钥匙,就在于理解从"阻塞I/O"到"异步I/O"的演进之路。今天,我们将一起揭开五种I/O模型的神秘面纱,看看从最原始的"苦苦等待"到最高效的"全自动处理",技术是如何一步步解决高并发难题的。
重谈IO
网络的本质是进程间通信。我们编程时,总以为是在和另一台"电脑"对话,但真正在收发数据、处理请求的,并不是一个抽象的机器,而是运行在对方主机上的一个具体的进程 (比如一个Nginx服务器进程、一个MySQL数据库进程)。因此,所谓网络通信,剥去IP地址和端口的外衣,其核心就是一个进程与另一个进程在交换数据。
既然是两个进程在交换数据,那么这个过程就必然涉及到数据的输入和输出。一个进程要将数据发送出去(Output),另一个进程要接收并读取这些数据(Input)。所以,这自然而然地就归结为了一个I/O问题。无论底层网络链路多么复杂,协议如何封装,对于应用程序而言,它需要解决的核心问题就是:"如何高效地把我这里的数据'写'出去,以及如何高效地把对方'写'过来的数据'读'进来"。
因此,网络问题的本质就是I/O问题。我们平时遇到的绝大多数网络编程挑战,如连接缓慢、吞吐量低、高并发下资源耗尽等,其根源往往不在于网络本身的速度,而在于我们采用的I/O模型是否高效。你是用最基础的"阻塞I/O",让一个线程傻傻地等待数据,从而在成千上万个连接面前无力招架?还是用"I/O多路复用"(如epoll)来让一个线程管理所有连接,只在数据ready时进行处理?或是采用终极的"异步I/O",将整个数据收发过程全权交由内核处理,实现真正的"fire and forget"?你所选择的I/O处理方式,直接决定了你程序处理网络请求的能力上限。所以,优化网络性能,其主战场就在于选择和优化I/O模型。
要理解什么是高效的I/O,我们首先要看清I/O的本质。对于我们的机器而言,一个网络报文的抵达,一定是硬件层先收到的,比如一个网络报文可以始于网卡接收到物理信号。这个过程就像一个门铃被按响------硬件中断 就是这个"门铃"。操作系统被这个中断唤醒,然后才着手将数据从网卡的缓冲区读取到内核的内存空间中。这个"读取进来"的动作,就是最基础的 Input ;反之,将数据从内存发送到网络,就是 Output。
那么,如何衡量I/O的效率呢?关键在于认识到,一次I/O操作所消耗的时间,绝大部分并不是在真正地搬运数据(拷贝),而是在"等待"数据准备就绪。 比如,等待网络包穿越千山万水到达网卡,等待对方主机发送下一个数据包。因此,我们可以建立一个核心公式:I/O耗时 = 等待时间 + 数据拷贝时间。
既然I/O主要由"等待"和"拷贝"构成,而数据拷贝的速度受限于CPU和内存带宽,其优化空间相对有限。那么,提升I/O效率的主攻方向,自然就在于如何对付"等待"这个时间黑洞。高效的I/O,其目标就是最大限度地减少"等待"在总耗时中的比重,让系统在别人等待的时候去干别的活,从而在单位时间内完成更多的I/O操作。
那么,如何实现从"等"到"不用等"的转变呢?这中间一定会发生了一个关键的状态转换。当数据已经到达、可以被读取,或者缓冲区已空闲、可以写入时,我们就说发生了一个 "I/O事件"。识别并利用这个事件,是构建高效I/O模型的核心。像 select、poll、epoll 这样的I/O多路复用技术,其本质就是一个"I/O事件监听器",它让我们的程序可以同时监视成百上千个连接,但只在真正有事情可做(事件发生)时才会被唤醒,从而将无谓的等待时间降至最低。
最后,我们必须承认,任何通信场景的效率都存在上限,正所谓"花盆里长不出苍天大树"。我们的I/O效率最终会受到硬件(如CPU、内存、网卡)和网络资源(如带宽、延迟)的物理限制。高效I/O编程的艺术,就在于如何通过精巧的软件设计(比如使用事件驱动模型、异步I/O),让这些宝贵的硬件资源在绝大部分时间都处于忙碌的"拷贝"状态,而不是空闲的"等待"状态。当你的系统将时间几乎都花在数据拷贝上时,你就已经无限逼近于当前硬件条件下的性能极限了。
一个例子帮助理解IO模型:钓鱼
在了解我们后面介绍的五种IO模型之前,我先给大家讲一个例子,希望大家可以通过这个例子的辅助,更好的区分与理解这些IO模型。
张三
张三是一个捕鱼新手,他买好钓鱼竿,放上鱼饵,便将鱼钩置入河中,自己坐在小河旁边的小板凳上。
由于张三是一个新手,他没有经验。于是钓鱼的时候,他就一直盯着鱼竿,随时提防着鱼竿的异动。
这是张三的钓鱼方式。
李四
李四是一个钓鱼老手的,有着一些经验,他来到河边,将自己的鱼竿鱼饵,鱼钩弄好,也开始钓鱼,并坐到张三旁边。
李四看见张三在目不转睛的盯着鱼竿,就笑着说,诶,张三,你这样不行啊。就想着跟张三聊会天,但是张三正在目不转睛的盯着鱼竿,就没有理李四。
李四不想自讨没趣,于是拿出手机刷了会抖音,然后看了下鱼竿,没啥动静。随后继续想着跟张三聊天,张三不理,李四刷抖音,看鱼竿...
就这样,李四在这几个动作直接不断循环,这是李四的钓鱼方式。
王五
王五是一个钓鱼高手了,他来到二人旁边之后,冷哼一生,随后放好自己的工具,并坐到一边。只是与二人不同的是,王五他拿出了一个铃铛,放在鱼竿上。
在铃铛没响的时候,王五就一直刷手机。当铃铛响的时候,代表鱼竿有动静了,于是王五就把鱼竿拿起来。
最后王五就一直重复这个过程,这是王五的钓法。
赵六
赵六则不一样了,赵六是个富爷,他买来了一卡车的鱼竿,随后将每个鱼竿都放上饵,一齐放在合理钓鱼,随后他一个人在这一排的鱼竿后面来回走动,哪个鱼竿动了,就负责提杆,换饵。
田七
田七就更有钱了,他是一个公司的老总。这天他的司机开着车带着田七来到了河边,打算钓鱼。正当他要下车的时候,突然秘书给他打电话,说现在有一个突发会议,需要他去开会。
田七没有办法,于是对司机说,我自己开车回去吧,你留在这帮我钓鱼,如果钓到足够的鱼之后,你再给我打电话通知我。
以上五个人的钓鱼方法,一一对应着五种IO模型。
- 张三一直专注的盯着自己的钓钩的鱼漂,鱼不上钩,他不会做其他事。这就跟我们平常调用scanf,或者waitpid等函数一样,进入了一个阻塞的状态。这就是阻塞式IO。
- 阻塞式I/O是最简单、最基础的I/O模型。当应用程序发起一个I/O操作(如读取数据)后,其执行流程会主动停止,并一直等待(即被"阻塞"),直到该系统调用完成,数据从内核缓冲区准备好并拷贝到用户空间后,才恢复执行。在此过程中,程序无法进行任何其他任务。
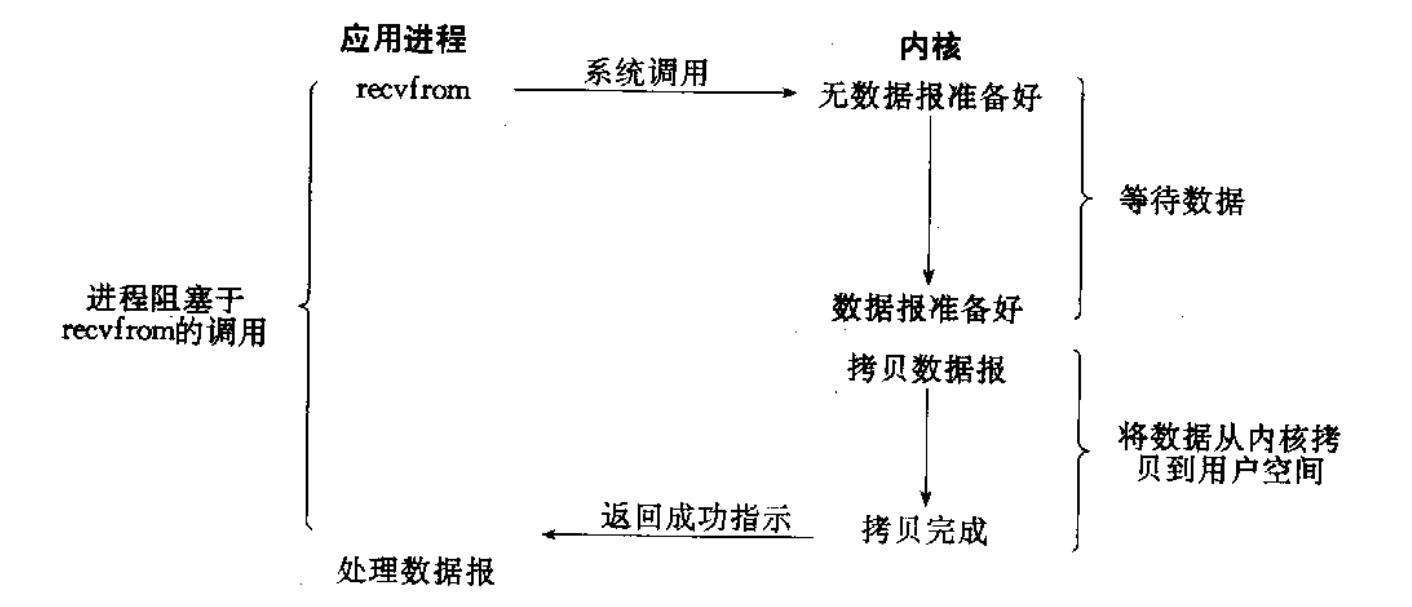
- 李四则聪明了一点,不是一直在等待鱼漂信息,而是做了一段时间的其他事情后再去看看钓上鱼没。这种方式,就是非阻塞式IO ,它是以一种轮循的方式进行非阻塞IO。
- 非阻塞式I/O中,应用程序发起I/O操作后,无论数据是否准备好,该调用都会立即返回一个状态值。如果数据未就绪,程序不会进入等待状态,而是可以继续执行其他任务,但需要通过一个循环不断地重复发起调用,以轮询检查数据是否就绪。这种方式以消耗CPU资源为代价,换取了程序执行流程的主动权,当然,这个方式这对 CPU 来说是较大的浪费, 一般只有特定场景下才使用。
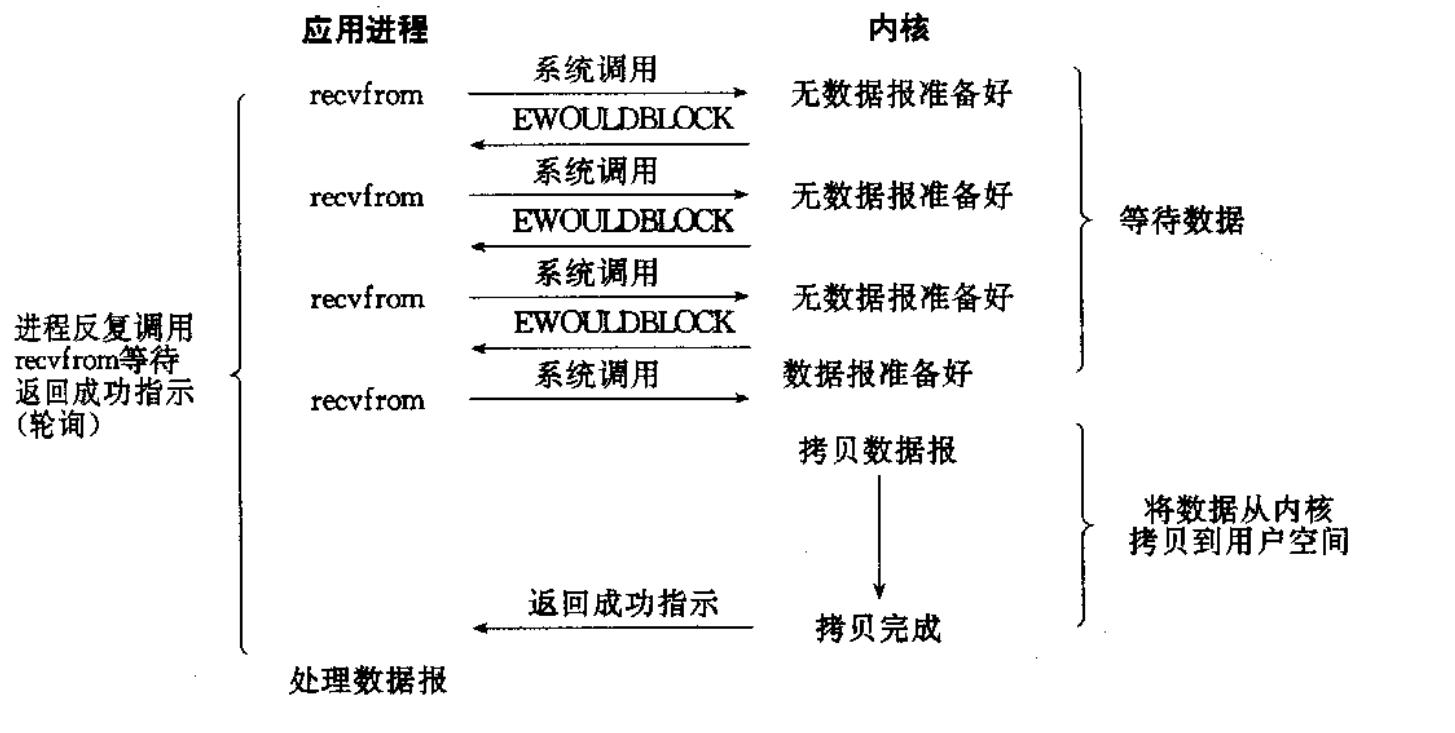
- 王五头也不抬的玩手机,他敢这么专心的做其他事情的原因是因为有一个铃铛在提醒他,如果鱼漂动了,铃铛也会随之摇晃,随后发出声响提醒。这就是信号驱动式IO。
- 信号驱动式I/O允许应用程序在发起I/O操作后继续执行,不被阻塞。它首先为对应的I/O描述符安装一个信号处理函数。当内核数据准备就绪时,会向应用程序发送一个特定的信号。应用程序在收到信号后,再执行实际的数据读写操作。这种方式将轮询的负担从应用程序转移到了内核,实现了事件通知。
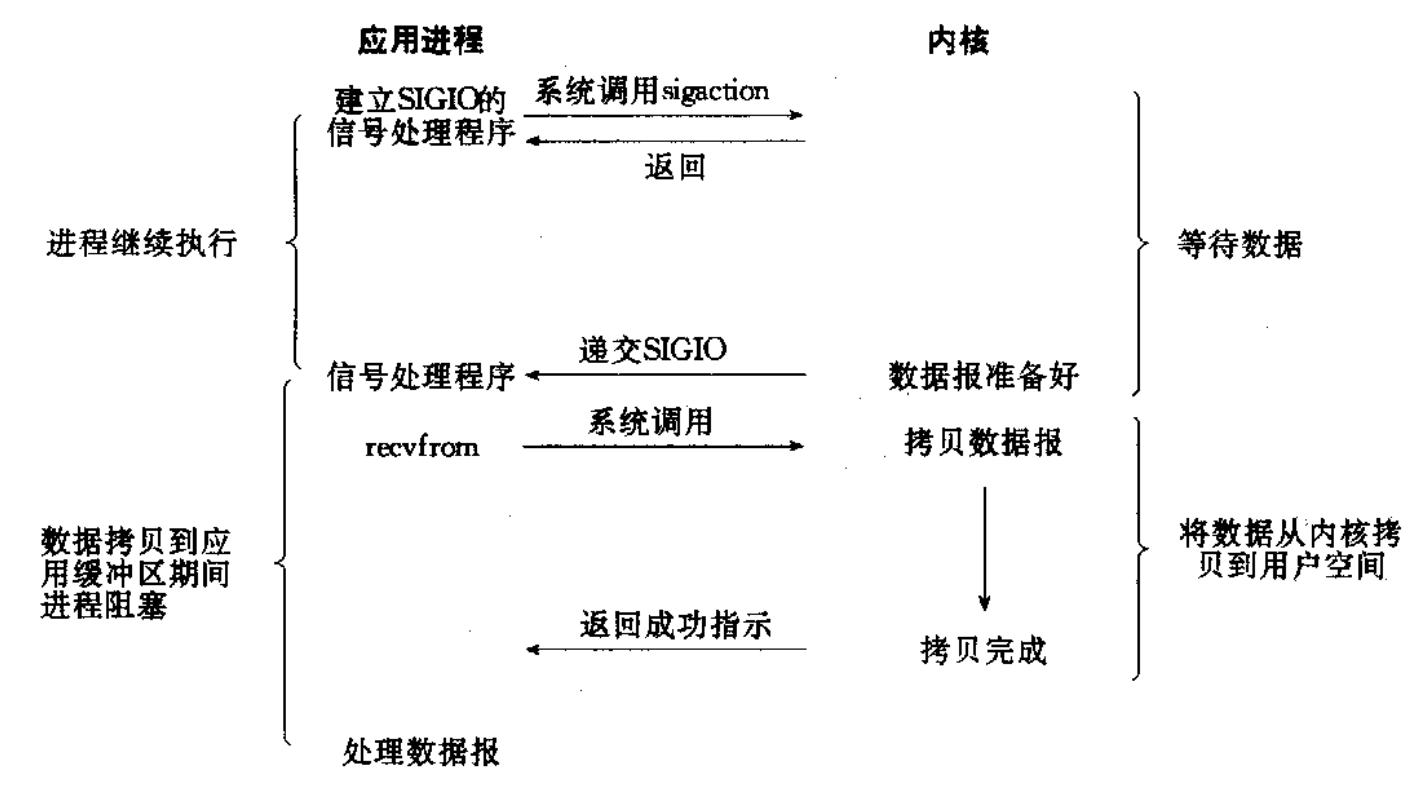
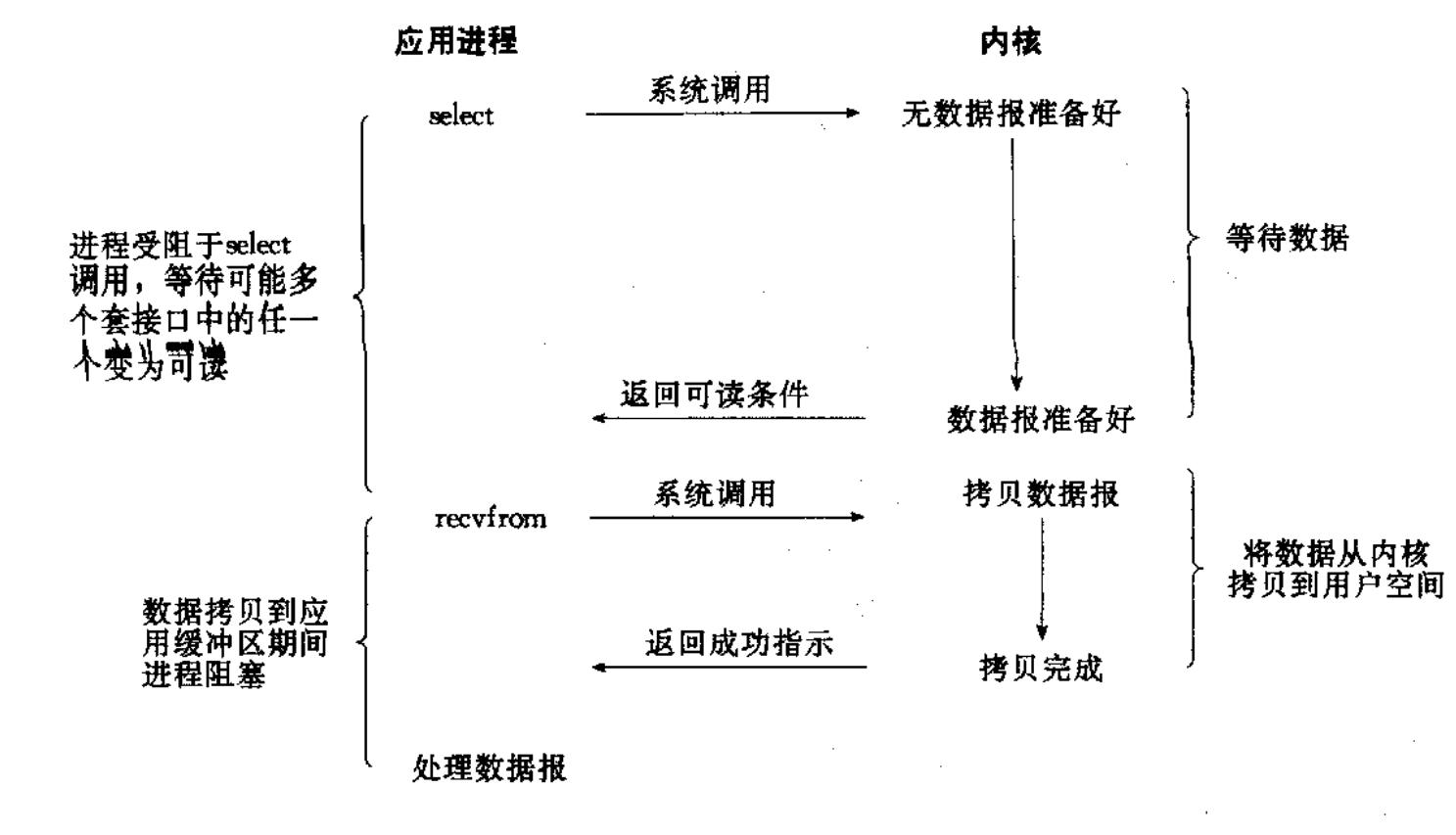
- 赵六有着许多的钓竿,同时在等待鱼上钩,这种方式等到输入的信息,就是多路转接IO ,或者称为多路复用式IO。
-
多路复用式I/O,也称为事件驱动I/O,其核心是使用
select、poll或epoll等系统调用,将一个进程的多个I/O描述符集中起来进行统一监听。该调用会阻塞,直到有一个或多个被监听的描述符上有事件(如数据可读)发生。然后,应用程序再对就绪的描述符进行实际的I/O操作。它极大地提高了单进程处理多并发I/O连接的效率。 -
-
Recvfrom等函数都只是传递一个文件描述符,但是select可以传递多个文件描述符(多路转接)
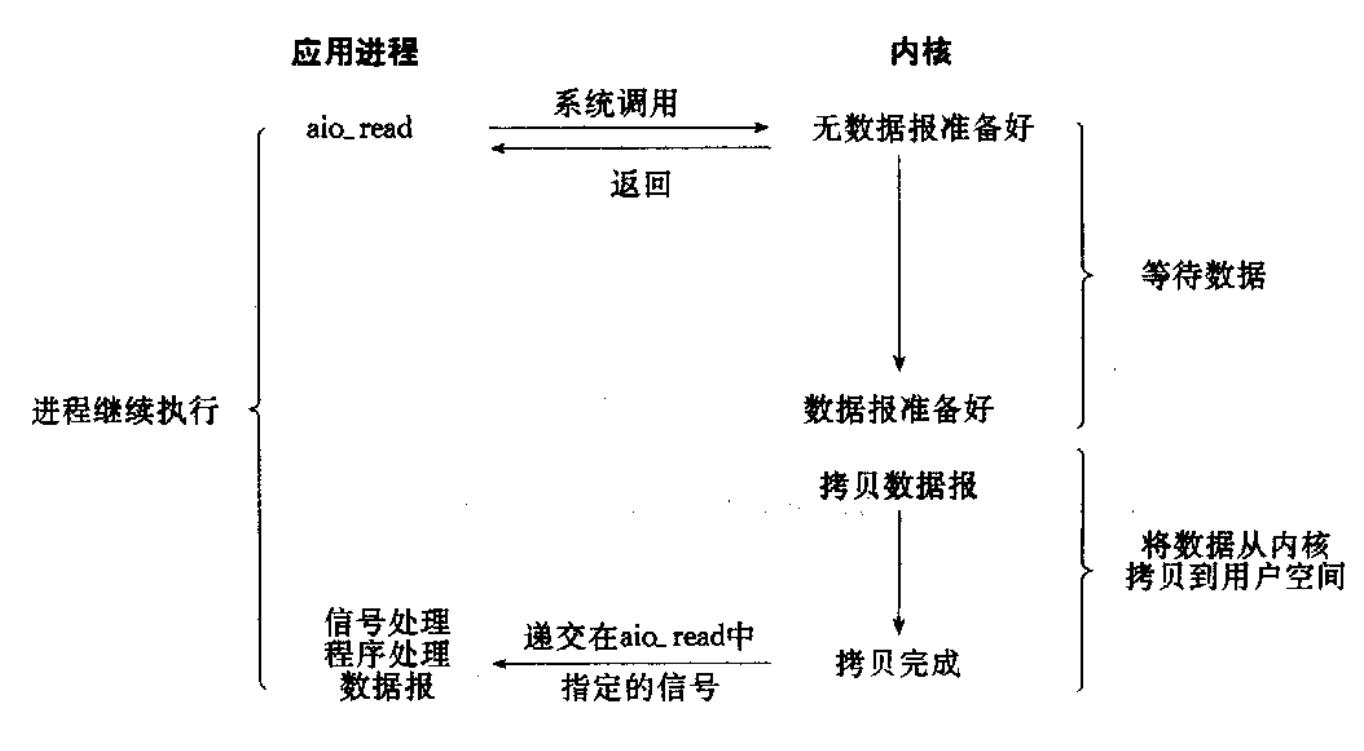
- 田七虽然发起了这个钓鱼的活动,但是却让别人替他钓鱼,并让其钓满了给他发消息(用这个水桶钓满了给他打电话),给了别人缓冲区(指钓鱼的水桶)和通知方式(打电话),这种叫做异步IO。
- 异步I/O是最为彻底的异步模型。应用程序发起一个I/O操作后,内核会接管整个操作过程,包括等待数据就绪和将数据从内核拷贝到用户空间。这两个步骤完成后,内核才会通知应用程序操作已经全部完成。在整个过程中,应用程序完全无需等待,也无需在数据就绪时再介入,可以立即去处理其他任务。
五种IO模型的普遍疑问
1、阻塞与非阻塞IO的比较
我想问一下大家,我们之前说,IO=等+拷贝,那么阻塞与非阻塞也存在等吗?
当然,只是这两个IO方式等待的方式不一样,一个是一直在等待,一个是不会卡主的等待。
那么这就说明非阻塞IO的效率就高吗?
这个说法对吗?当然是不对的。
两者从IO效率上来讲其实并无本质区别,为什么这么说呢?
首先,我们要明确"IO效率"在这里指的是什么。它主要指完成一次有效数据IO(即"等+拷贝")这个核心过程的速度。在这个核心层面上,两者确实没有区别。
1. 核心过程相同:"等"与"拷贝"
无论是阻塞还是非阻塞IO,一个完整的读数据操作都必须经历两个阶段:
-
阶段一:等待数据就绪。数据从物理设备(如网卡)到内核缓冲区的这个过程,对于应用程序来说是不可见的,它只能"等待"。
-
阶段二:将数据从内核缓冲区拷贝到用户空间。这是由CPU执行的具体操作。
关键在于 :对于一次有效的IO操作(即你确实读到了数据),无论是阻塞还是非阻塞,都必须经历这两个阶段,缺一不可。因此,从"完成一次有效IO所花费的时间"来看,它们没有本质区别。
2. 核心差异在于:"等待"期间进程的行为
它们的根本区别不在于IO本身的速度,而在于在"阶段一"(等待数据就绪期间),应用程序是否能做别的事情。
-
阻塞IO :在"阶段一",进程被操作系统挂起,让出CPU,直到数据准备好才被唤醒。在等待期间,它什么都不做。
-
非阻塞IO :在"阶段一",系统调用立即返回一个错误(如 EWOULDBLOCK),告诉应用程序"还没好"。为了能最终读到数据,应用程序必须不断地、主动地发起系统调用去轮询(polling)检查状态。
3. 为什么非阻塞IO的效率"感觉"更高?
我们通常觉得非阻塞IO"高效",其实是一种资源利用率的提升,而非IO本身速度的提升。
-
阻塞IO的问题:如果一个进程需要处理多个连接,用阻塞IO就必须为每个连接创建一个线程/进程。上下文切换的开销很大。
-
非阻塞IO的优势 :它允许单个线程 通过轮询来管理多个连接。虽然轮询本身消耗CPU,但在连接数多、活跃度不高的场景下(比如大量的HTTP长连接),用一个线程的CPU时间换来避免创建成千上万个线程的巨大开销,是非常划算的。这提高了系统的整体吞吐量 和可扩展性。
效率最高问题
那么,在这五个模型中,你觉得谁才是IO效率最高的呢?
答案当然是:
赵六!!!
为什么是赵六呢?
因为赵六有多个鱼竿,对于赵六来说,他的任意一个鱼竿上,鱼(数据)就绪的概率都很高。而IO=等+拷贝,一个人他有多个鱼竿,就变相降低了等的比重。
-
从"等待的串行"到"等待的并行"
- 张三(阻塞IO)和李四(非阻塞IO) 本质上都是串行的。他们在一个时间段内,只能有效地等待一个鱼竿。即使李四可以抽空刷手机,他检查鱼竿的动作也是依次、轮流的。
- 赵六(多路复用IO) 是并行等待 。他将所有的"等待"任务(监控所有鱼竿)一次性交给了操作系统内核这个"超级助手"(通过
select,epoll等系统调用)。内核会同时帮他盯着所有鱼竿。
-
"等的比重"是如何被降低的?
-
对于有N个连接的应用程序,使用阻塞或非阻塞IO,在最坏情况下,需要完成N次"等待"(每次等待一个连接的数据就绪)。
-
而使用多路复用IO,它只需要进行一次"等待" ------就是调用
epoll_wait那次。这一次等待,可以同时等到N个连接中任何一个或多个数据就绪的事件。然后,程序就可以集中精力去处理这些已经就绪的连接,执行"拷贝"操作。 -
所以,它不是消除了"等",而是将大量零散的、串行的"等",合并成了一次高效的、并行的"等"。
-
多路复用IO通过单线程同时监控多个文件描述符(连接),将原本串行发生的多个"等待"过程合并为一个。这使得CPU能够将时间片集中用于处理已就绪的IO事件上进行数据拷贝,从而在宏观上显著降低了等待在整个IO操作中的时间占比,提升了系统的整体吞吐率。
所以同样的想法,一个鱼塘的鱼越多,那你在这个池塘的钓鱼效率肯定也就越高。
我们想象在极端情况下,数据非常的多,鱼儿十分容易上钩。
这时候赵六是什么体验?
他刚做完一次巡视(调用 epoll_wait),这个动作几乎没有任何停顿,立刻就发现有成百上千个鱼竿在同时乱晃!他的"等待"时间被压缩到了几乎为零。
他也顾不上了,只能一头扎进这堆鱼竿里,开始马不停蹄地收鱼(数据拷贝)。好不容易处理完这一大波,他以为能喘口气了,结果下一次巡视(再次调用 epoll_wait)又是瞬间完成,眼前赫然是另一大批已经就绪的鱼竿等着他!
此时的节奏就变成了:[等≈0] -> [疯狂拷贝] -> [等≈0] -> [继续疯狂拷贝] -> ...
总结一下:
所以你看,在极端的高并发场景下,"等待"这个动作被极大地压缩了。赵六(进程)的大部分时间和精力,都消耗在了实实在在的"收鱼"(数据拷贝)这个体力活上,这才是效率最高的状态。
信号驱动式的IO的特点
信号驱动式的IO有一个特点,就是它逆转了获取就绪事件的方式!!!
在它之前,无论是阻塞式去傻等,还是非阻塞式去轮询,都是我们应用程序主动地、一次次地去问操作系统:"数据好了没?数据好了没?"
而信号驱动式IO不一样,它反过来对操作系统说:"嘿,内核老哥,我把这个Socket交给你。等它数据准备好了,你主动发个信号通知我一下,我再来处理。"
这就引出一个关键问题:它都把主动权交出去了,为什么还不算异步IO,反而被归为同步IO呢?
这里面的门道,就在于我们必须死死扣住 "同步"和"异步"的本质区别。
评判标准就一句话:看你有没有真正"参与"IO的两个核心过程------即"等数据"和"拷贝数据"。
-
"等数据"这个阶段:
- 信号驱动IO确实没有参与。它把这个最耗时的"等待"过程完全委托给了内核,通过信号来接收通知。这是它聪明的地方,也是它容易被误解为"异步"的原因。
-
"拷贝数据"这个阶段:
-
这才是判定的关键! 当内核发来信号说数据好了,应用程序接下来必须亲自调用
read函数 ,将数据从内核缓冲区拷贝到自己的用户空间缓冲区。 -
只要你自己动手干了"拷贝"这个活儿,你就参与了IO的核心过程。
-
所以,我们给IO模型定性,要看的是它的"完全体",是整个流程的终点。
-
真正的异步IO(田七): 是整个IO操作(等+拷贝)全部由内核包办,内核干完了所有脏活累活之后,直接把最终结果通知你。你从头到尾都是一个"甩手掌柜"。
-
信号驱动IO(王五): 内核只是个"侦察兵",它只负责告诉你"目标出现了"(数据就绪),但最终的"开枪击毙"(拷贝数据)还得你亲自动手。你依然是一个"一线战斗人员"。
信号驱动式IO,它只是在"等待"的方式上耍了个花招,搞了个"消息通知",显得很高级。但在最关键的临门一脚------数据拷贝 这个环节,它依然需要应用程序同步地、阻塞地去调用读写函数。
因此,它本质上还是一个"同步IO模型"。它逆转了获知消息的方式,但没有逆转它需要亲自下场干活的本质。
同步IO VS 异步IO
同步与异步的区别就是看其是否参与了IO的过程(哪怕是局部参与),这是我们刚刚所说的。
所以异步IO的角色(田七)通常只是一个发起者,小王,这个田七的司机(操作系统)才是参与者。
我们这个钓鱼的过程,就是系统调用。一个进程通过函数调用系统调用来完成钓鱼这个过程
鱼竿的脾气:阻塞问题
在我们之前的钓鱼例子中,大家可能会发现一个现象:张三的鱼竿会让他一直干等着,而李四的鱼竿却允许他刷会儿抖音再回来查看。
难道他们用的是不同品牌的鱼竿吗?
其实完全不是!问题的根源在于:在Linux系统中,每一个文件描述符(就是我们的"鱼竿")在刚创建时,默认都是"阻塞模式"的。
什么是默认阻塞?
简单来说,当你创建一个新的socket(就像买了一根新鱼竿),操作系统给它设置的默认属性就是:
-
调用
read时,如果河里没鱼(内核缓冲区没数据),就死等 -
调用
accept时,如果没有新连接,就死等 -
调用
write时,如果对方接收慢,也可能死等
这就好比鱼竿出厂时都被设置了"不等到鱼就别想干别的"这个默认属性。
我们之前的学习误区
很多人在学习网络编程时,陷入了这样一个误区:拼命去记每个函数的行为:
-
read函数会阻塞 -
accept函数会阻塞 -
recv函数会阻塞...
这样记忆的成本太高了!而且很容易混淆和遗忘。
正确的理解方式
其实,不是这些函数本身会阻塞,而是它们操作的文件描述符默认就是阻塞的!
想明白这一点,问题就简单了:既然根源在文件描述符的属性上,那我们只需要改变这个属性就行了。
解决方案:修改鱼竿的脾气
c++
// 关键一步:告诉操作系统,把这根鱼竿设为非阻塞模式
fcntl(fd, F_SETFL, O_NONBLOCK);一旦设置了非阻塞,同样的鱼竿,同样的read、accept函数,就都不会再阻塞你的线程了。
在Linux"一切皆文件"的哲学下,我们只需要关注文件描述符的属性设置,而不需要死记硬背每个函数的行为。
我们接下来就来带着大家详细使用一下fcntl函数。
非阻塞IO
一个文件描述符, 默认都是阻塞 IO。
而我们可以使用fcntl函数来修改该文件描述符的默认属性。
c
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );传入的 cmd 的值不同, 后面追加的参数也不相同.
fcntl 函数有 5 种功能:
- 复制一个现有的描述符(cmd=F_DUPFD)
- 获得/设置文件描述符标记(cmd=F_GETFD 或 F_SETFD)
- 获得/设置文件状态标记(cmd=F_GETFL 或 F_SETFL)
- 获得/设置异步 I/O 所有权(cmd=F_GETOWN 或 F_SETOWN)
- 获得/设置记录锁(cmd=F_GETLK,F_SETLK 或 F_SETLKW)
我们此处只是用第三种功能, 获取/设置文件状态标记, 就可以将一个文件描述符设置为非阻塞
基于 fcntl, 我们实现一个 SetNoBlock 函数, 将文件描述符设置为非阻塞
实现SetNoBlock
我们这里先使用read函数搭配while循环实现一个一直从标准输入读取数据并回显的程序:
c++
#include<iostream>
#include<unistd.h>
#include<fcntl.h>
int main()
{
char buffer[1024];
while(true)
{
int n=::read(0,buffer,sizeof(buffer));
if(n>0)
{
buffer[n]=0;
std::cout<<"echo# "<<buffer<<std::endl;
}
else
{
std::cout<<"read error"<<std::endl;
}
}
return 0;
}如果我们运行该程序,就会是这样的效果:

此时我们新建一个函数来专门实现非阻塞的设置的功能:
c++
void SetNoBlock(int fd)
{
// 1. 获取文件描述符当前的标志位
int fl = fcntl(fd, F_GETFL);
if (fl < 0)
{
perror("fcntl"); // 获取失败时输出错误信息
return;
}
// 2. 设置文件描述符为非阻塞模式
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
// fl | O_NONBLOCK: 保留原有标志位,同时添加非阻塞标志
}我们这里第一步是先获取当前文件描述符的标志位,为什么要获取呢?
这是为了避免覆盖掉文件描述符上已经存在的其他重要设置。
随后将获取的标志信息 | 上一个NOBLOCK的标志信息,就只给我们的fd文件描述符添加上了非阻塞功能。
此时再来看我们的主函数,我们就在循环开始前使用刚刚定义的SetNoBlock函数将0文件描述符,也就是标准输入符进行一个非阻塞的设置。
c++
int main()
{
char buffer[1024];
SetNoBlock(0);
while (true)
{
int n = ::read(0, buffer, sizeof(buffer));
if (n > 0)
{
buffer[n] = 0;
std::cout << "echo# " << buffer << std::endl;
}
else
{
std::cout << "read error" << std::endl;
}
sleep(1);
}
return 0;
}这样,我们的程序就变成了这样:

非阻塞,如果我们不做输入,数据不就绪,read的返回值就会以出错形式返回
read不是有读取失败(-1)吗?那么我们这个到底算不算失败呢??
------底层数据没就绪,不算失败
但是read都是返回-1啊,我们后面面对准备不就绪或者返回出错,我们的应对是不同的,那我们应该如何区分出来呢?
------errno!
errno 是一个全局变量,存储了最近一次系统调用失败的具体原因。
c++
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h> // 必须包含这个头文件
#include <cstring> // 为了strerror
void SetNoBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if (fl < 0)
{
perror("fcntl");
return;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}
int main()
{
char buffer[1024];
SetNoBlock(0);
while (true)
{
int n = ::read(0, buffer, sizeof(buffer)-1);
if (n > 0)
{
// 成功读取到数据
buffer[n] = 0;
std::cout << "echo# " << buffer;
}
else if (n == 0)
{
// 读到文件结尾(比如Ctrl+D)
std::cout << "End of file reached" << std::endl;
break;
}
else // n < 0
{
// 关键区分:是真错误还是数据没就绪?
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
// 数据没就绪 - 这不是真正的错误!
std::cout << "数据还没准备好,我可以做其他事情..." << std::endl;
}
else
{
// 真正的错误:如文件描述符无效、权限问题等
std::cout << "真正的读取错误: " << strerror(errno) << std::endl;
break;
}
}
sleep(1);
}
return 0;
}这里我们有一行代码:
if (errno == EAGAIN || errno == EWOULDBLOCK)
这行代码,是你从 "阻塞世界" 踏入 "非阻塞世界" 的入门券。它在做一件非常重要的事:区分"还没好"和"真出错"。
1. 核心任务:识别"假错误"
在非阻塞IO中,read 返回 -1 时,情况可能天差地别:
-
情况A(假错误):"数据现在还没到,但你等会儿再问我,说不定就有了。"
-
情况B(真错误):"别问了,出大事了(比如文件描述符坏了),永远不可能成功了。"
这行代码的唯一目的,就是把"情况A"给揪出来。
EAGAIN和EWOULDBLOCK在Linux上本质是同一个东西,不同的历史别名。它们传达的信息完全一致: "资源暂时不可用,你应该稍后重试。"
2. 信号中断 (EINTR):一个必须考虑的"搅局者"
刚才我们区分了"没数据"和"真错误",但在真实的系统编程中,还有一个常见的"假错误"来源:信号中断。
想象这个场景:
-
你的
read调用(即使是阻塞的)正在等待数据。 -
突然,一个信号(比如
SIGALRM定时器信号)送到了进程。 -
内核会把你的
read系统调用中断,让它先返回,以便进程去处理信号。 -
信号处理完后,
read并不会自动继续,而是返回-1,并把errno设置为EINTR。
这意味着一行 if (errno == EAGAIN ...) 是不够的。 一个健壮的非阻塞IO循环,必须同时处理这两种"假错误":
c++
int n = read(fd, buffer, size);
if (n < 0) {
// 先判断是不是被信号中断的"假错误"
if (errno == EINTR) {
// 信号中断,不是真错,直接重试
continue;
}
// 再判断是不是非阻塞导致的"没数据"
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据没就绪,可以去干点别的,然后回来重试
usleep(1000); // 比如睡1毫秒
continue;
}
// 最后,才是处理真正的错误
perror("read");
break;
}所以,if (errno == EAGAIN || errno == EWOULDBLOCK) 这行代码,是在 非阻塞IO的语境下 ,专门用于判断 "失败原因是不是因为数据暂时没准备好"。
它是构建高性能、高可靠性网络服务的基础判断之一,让你能清晰地知道:当前的失败是正常的、可恢复的,你只需要稍后重试即可。
总结:从阻塞到非阻塞的思维转变
通过这次对五种I/O模型的深入探讨,我们完成了一次从"被动等待"到"主动掌控"的思维升级。让我们最后回顾一下核心要点:
核心认知转变
从"记忆函数行为"到"控制文件属性"
-
不再需要死记硬背
read、accept哪个会阻塞 -
只需关注文件描述符的阻塞/非阻塞属性
-
通过
fcntl(fd, F_SETFL, fl | O_NONBLOCK)一键切换
从"串行等待"到"并行处理"
-
阻塞I/O:一次只能等一个连接
-
多路复用I/O:一次等待,处理多个就绪事件
-
真正的高效在于压缩等待时间比重
关键编程实践
非阻塞I/O的错误处理三段论
c++
int n = read(fd, buf, size);
if (n < 0) {
if (errno == EINTR) /* 信号中断,重试 */;
else if (errno == EAGAIN || errno == EWOULDBLOCK) /* 数据未就绪,稍后重试 */;
else /* 真正错误,处理异常 */;
}同步vs异步的判定标准
-
同步I/O:参与了数据拷贝过程(前四种模型)
-
异步I/O:完全委托,只关心最终结果(田七模式)
性能优化的本质
I/O优化的目标不是消除等待,而是让等待变得更有价值。在多路复用模型下,当海量请求来袭时,我们的工作模式变成了:
[等待≈0] → [批量处理] → [等待≈0] → [批量处理]
这正是现代高性能服务器的核心秘密------用一次系统调用的代价,换取处理成百上千个就绪连接的机会。
最后的思考
选择什么样的I/O模型,决定了你程序处理并发请求的能力上限。从张三的"死等"到赵六的"批量监控",再到田七的"全权委托",每一步演进都是对"等待"这个时间黑洞的更深层次征服。
记住:高效的I/O编程,就是让CPU的时间尽可能花在数据拷贝上,而不是无谓的等待中。 当你理解了这一点,就掌握了构建高性能网络服务的钥匙。