记录研一数字通信课设,课设题目"语音信号的FFT变换",要求:使用matlab,不直接调用内置函数。
一、思路:
1、生成几个示例信号,观察FFT变换
2、导入音频信号进行FFT变换
3、得出了FFT变换的结果是否能对实际生活提供帮助呢?比如是否能对语音信号进行降噪处理呢?------利用谱减法进行降噪处理
4、生成时域频域对比图,并播放降噪前后音频进行对比
二、基本原理和代码
1、FFT变换------Cooley-Tukey算法
关于该算法的博客有很多,都讲的很清楚。接下来我直接附上我PPT中梳理的步骤和对应的代码。
附上我觉的讲的很清楚的一个up主的视频:

2、谱减法
语音增强--谱减法介绍及MATLAB实现_减谱法-CSDN博客

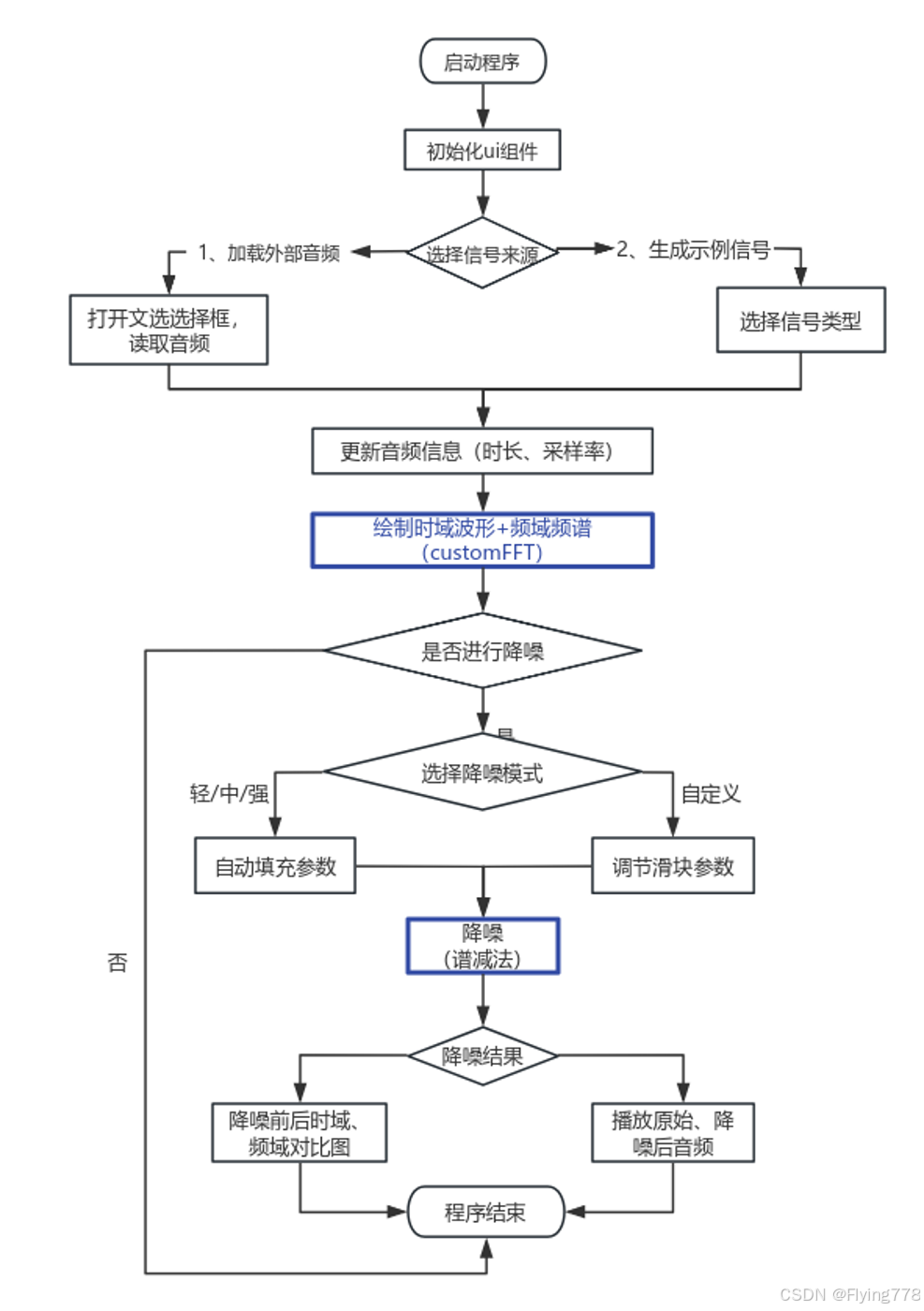
 三、程序流程图
三、程序流程图
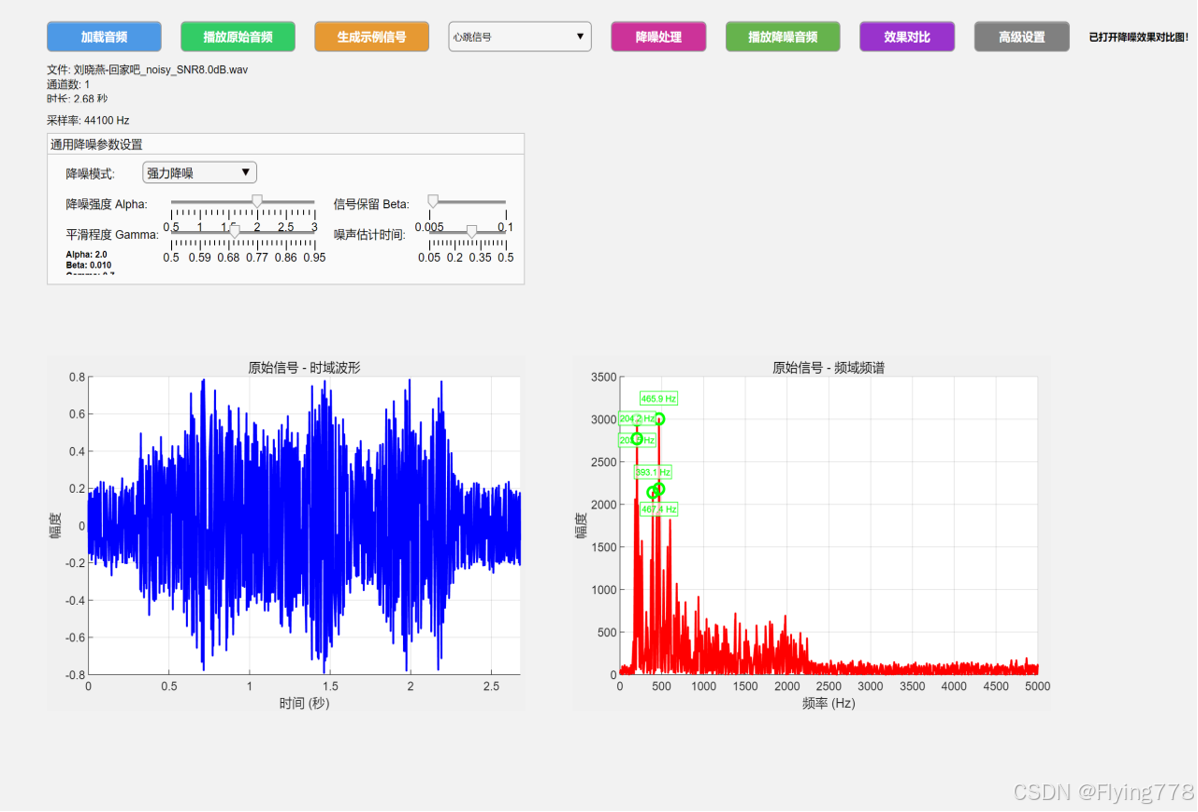
四、效果演示
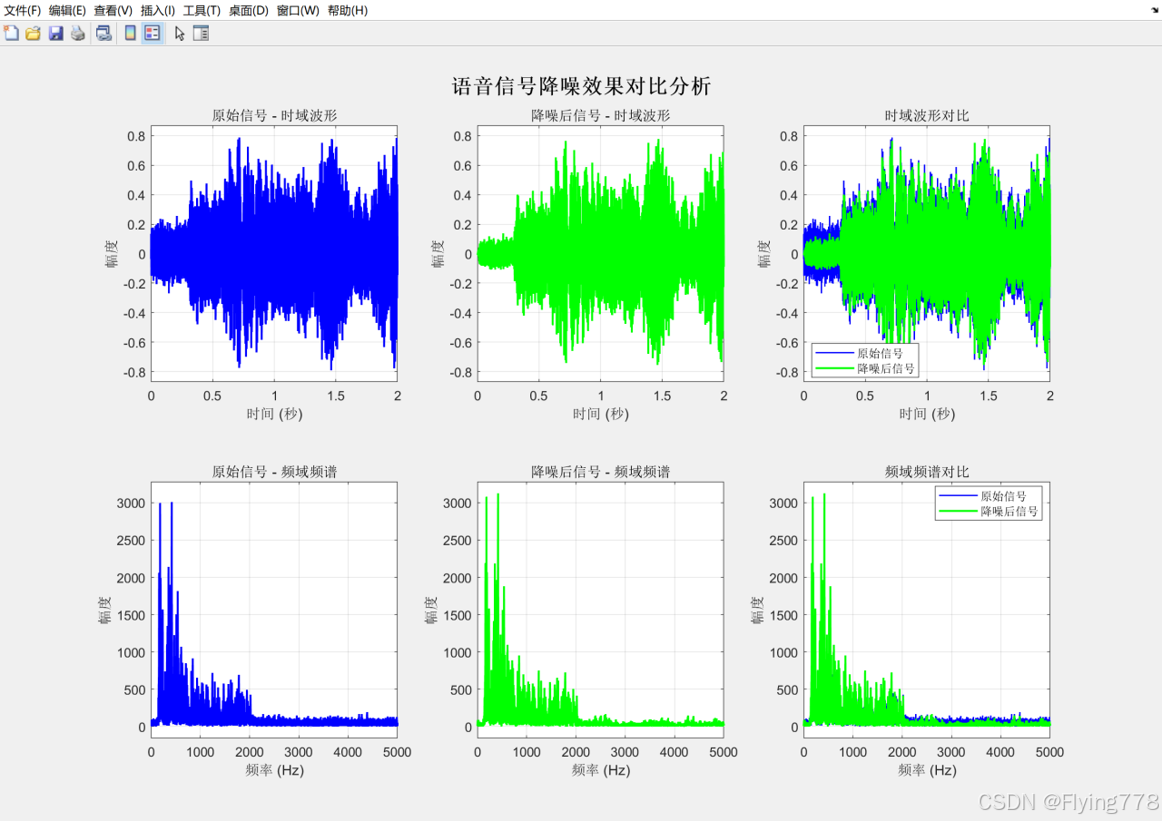
结果分析:
时域波形对比:绿色的波形在噪声密集的地方,比蓝色的平滑一点。
频域对比图:高频区域的噪声杂波被大幅削弱,仅保留语音的 "有效频率成分"(如低频基频、中高频谐波),频谱更加干净。
五、谱减法关键代码
Matlab
function [cleanSignal, noiseProfile] = spectralSubtraction(noisySignal, fs, varargin)
% 改进的通用谱减法降噪 - 适用于各种音频类型
% 输入:
% noisySignal - 含噪声信号
% fs - 采样率
% varargin - 可选参数: 'NoiseEstimationTime', 'Alpha', 'Beta', 'Gamma'
% 输出:
% cleanSignal - 降噪后信号
% noiseProfile - 噪声谱估计
% 默认参数 - 调整为更保守的值
noiseEstimationTime = 0.3; % 增加噪声估计时间
alpha = 1.5; % 降低过减因子,避免过度抑制
beta = 0.02; % 增加谱下限,保留更多信号
gamma = 0.8; % 增加平滑因子,减少音乐噪声
% 解析可选参数
for i = 1:2:length(varargin)
switch varargin{i}
case 'NoiseEstimationTime'
noiseEstimationTime = varargin{i+1};
case 'Alpha'
alpha = varargin{i+1};
case 'Beta'
beta = varargin{i+1};
case 'Gamma'
gamma = varargin{i+1};
end
end
N = length(noisySignal);
% 参数设置 - 根据信号长度自适应调整
frameSize = min(1024, 2^nextpow2(N/8)); % 自适应帧大小
overlap = 0.75; % 增加重叠率,减少边界效应
hopSize = round(frameSize * (1 - overlap));
numFrames = floor((N - frameSize) / hopSize) + 1;
% ==================1、噪声估计 - 使用多段平均==========================
noiseStartSamples = min(round(noiseEstimationTime * fs), round(0.2 * N));
if noiseStartSamples < frameSize
noiseStartSamples = frameSize * 2;
end
% 选择多段噪声样本进行平均
numNoiseSegments = 3;
noisePower = 0;
for seg = 1:numNoiseSegments % 循环3次,处理每一段噪声
% 4.1 计算当前段噪声的起始/结束采样点(均匀分割)
startSample = round((seg-1) * noiseStartSamples / numNoiseSegments) + 1;
endSample = min(startSample + noiseStartSamples - 1, N);
% 4.2 提取当前段的噪声信号
noiseSegment = noisySignal(startSample:endSample);
% 4.3 仅处理长度≥帧长的噪声段(确保能提取1帧数据做FFT)
if length(noiseSegment) >= frameSize
% 4.4 从当前噪声段中提取1帧数据(长度=frameSize)
noiseFFT = customFFT(noiseSegment(1:frameSize));
% 4.5 计算当前段噪声的功率谱(幅度平方),并累积到noisePower
noisePower = noisePower + abs(noiseFFT).^2;
end
end
avgNoisePower = noisePower / numNoiseSegments;
%================2、分帧加窗======================================
% 初始化输出信号
cleanSignal = zeros(N, 1);
window = hann(frameSize); % 使用汉宁窗,减少频谱泄漏
previousMagnitude = zeros(frameSize, 1);
for i = 1:numFrames
% 提取当前帧
startIdx = (i-1) * hopSize + 1;
endIdx = startIdx + frameSize - 1;
if endIdx > N
% 处理最后一帧
frame = [noisySignal(startIdx:end); zeros(endIdx - N, 1)];
else
frame = noisySignal(startIdx:endIdx);
end
frame = frame .* window;
%===================3、频域转换==========================
% 计算当前帧的FFT
frameFFT = customFFT(frame); % 原理:时域→频域,转换为复数信号
frameMagnitude = abs(frameFFT);% 原理:提取幅度谱(信号+噪声的能量分布)
framePhase = angle(frameFFT); % 原理:提取相位谱(保留,后续重构用)
%==================4、谱减===============================
posteriorSNR = (frameMagnitude.^2) ./ (avgNoisePower + eps); % 计算后验信噪比
adaptiveAlpha = alpha ./ (1 + posteriorSNR); % 自适应过减因子 - 高信噪比区域使用较小的alpha
smoothedMagnitude = gamma * frameMagnitude + (1 - gamma) * previousMagnitude; % 频谱平滑(减少音乐噪声)
previousMagnitude = frameMagnitude;
cleanMagnitude = sqrt(max(smoothedMagnitude.^2 - adaptiveAlpha .* avgNoisePower, ...
beta * avgNoisePower));
%==================5、还原为时域信号======================
cleanFrameFFT = cleanMagnitude .* exp(1i * framePhase);
cleanFrame = real(customIFFT(cleanFrameFFT));
% 重叠相加
if endIdx > N
actualEnd = N - startIdx + 1;
cleanSignal(startIdx:end) = cleanSignal(startIdx:end) + cleanFrame(1:actualEnd);
else
cleanSignal(startIdx:endIdx) = cleanSignal(startIdx:endIdx) + cleanFrame;
end
end
% 归一化输出 - 保持原始信号的动态范围
originalMax = max(abs(noisySignal));
cleanMax = max(abs(cleanSignal));
if cleanMax > 0
cleanSignal = cleanSignal / cleanMax * originalMax;
else
cleanSignal = noisySignal; % 如果降噪失败,返回原始信号
end
noiseProfile = sqrt(mean(avgNoisePower));
end