跟新-update
语法: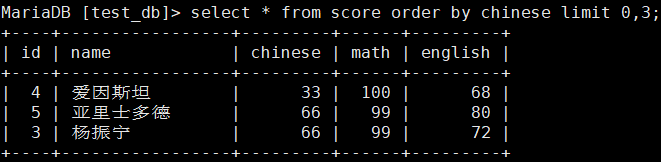
UPDATE table_name SET column = expr , column = expr ...
WHERE ...\] \[ORDER BY ...\] \[LIMIT ...
跟新与select的基本用法类似。指定修改的表和列,使用where,order by limit等关键字筛选出具体需要修改的数据,通过set修改。
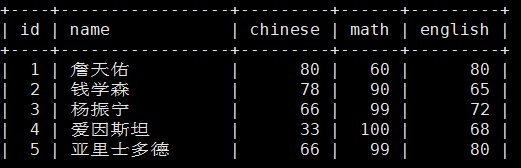
MariaDB [test_db]> update score set english=60 where id=2;修改后,id为2的列中的english就被设置成60了。
也可以通过,order by排序再使用limit筛选最低最高的几位进行更改。
筛选出语文最差的3为进行更改。
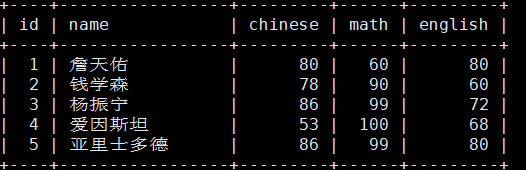
MariaDB [test_db]> update score set chinese=chinese+20 order by chinese limit 3;将三者的语文加20;
若是不加任何限定,筛选语句的话就是全表对应列都进行更新
MariaDB [test_db]> update score set math=80;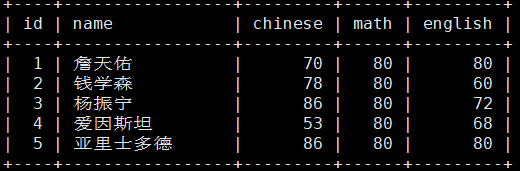
删除数据-delete
语法
DELETE FROM table_name WHERE ... ORDER BY ... LIMIT ...
删除行数据,若不设置筛选条件则删除整张表所有数据。
MariaDB [test_db]> delete from score where name='詹天佑';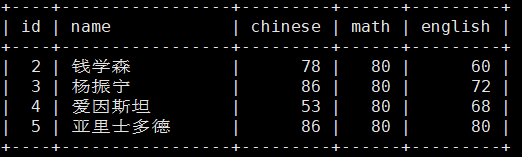
delete只删除数据,走事务流程,不会改变表结构,
MariaDB [test_db]> delete from score where id=5;这里删除了自增主键中id最大的值

自增主键的计数器不会变的,即使是删除了整张表所有数据,继续插入也是从6开始。
截断表 truncate
语法
TRUNCATE TABLE table_name
其作用是删除表中的所有数据
只能对整表操作,实际上mysql不对数据做任何操作,并不走事务的流程,效率比delete更快,也无法回滚。也会重置auto_increment。
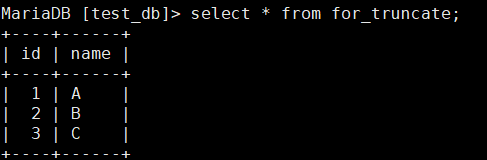

这个表的自增计数已经到4了。
MariaDB [test_db]> truncate table for_truncate;对表进行截断后

自增计数也被删除了。
MariaDB [test_db]> insert into for_truncate (name) values ('A');从新插入,计数器又是从1开始了。
插入查询结构
语法
INSERT INTO table_name (column \[, column ...)] SELECT ...
可以将查询的结果作为另外一张表插入的值。
先创建一张数据源表

 插入一些测试值。
插入一些测试值。
接下来我们将原表的数据进行去重然后放入另外一张结构相同的表中
MariaDB [test_db]> create table objective like soure;
MariaDB [test_db]> insert into objective select distinct * from soure;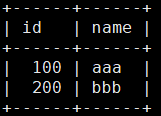 表中就是去重后的数据了。
表中就是去重后的数据了。
聚合函数
mysql里面也是拥有一些可以直接使用的函数的。
count(distinctexpr):返回数据的数量。
sum(distinctexpr):计算所有查询到的数据的总和,数据必须可聚合得是数字才有意义
avg(distinctexpr):计算所有查询到得数据得平均数,数据必须可聚合得是数字才有意义
max(distinctexpr):计算所有查询到得数据得最大值,数据必须可聚合得是数字才有意义
min(distinctexpr):计算所有查询到得数据得最小值,数据必须可聚合得是数字才有意义
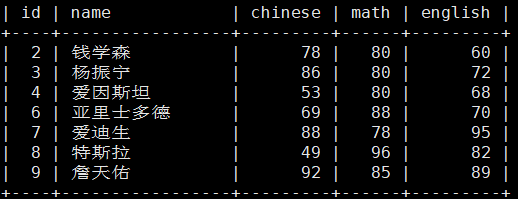
MariaDB [test_db]> select count(*) from score;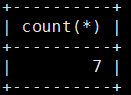 ()内是*或者数字都是一般都是*或1。
()内是*或者数字都是一般都是*或1。
这里表示一共有7列数据
MariaDB [test_db]> select count(name) from score;括号中也可以是列名,查找这个列一共有几行数据,NULL不计入数量。
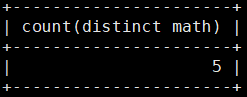
MariaDB [test_db]> select count(distinct math) from score;也可以进行去重查找,将有重复得都去掉
数据总和
MariaDB [test_db]> select sum(math+chinese+english) from score;将所有分数加总,当然可以单独列,也可以重命名。也可以去重,所有得聚合函数功能不同,但是用法基本相同。
MariaDB [test_db]> select sum(math) 数学,sum(chinese) 语文,sum(english) 英文 from score;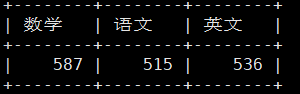
条件筛选平均数
MariaDB [test_db]> select avg(math) 数学 from score where chinese>60;将语文成绩大于60的数学成绩取其平均数。
MAX和MIN就不继续演示了,就是在筛选出来的数据中按照某一列取其最大最小值。
分组-group by
语法
select column1, column2, .. from table group by column;
分组一般都与聚合函数一起使用,在mysql中中间过程其实我们也能将其看作是一张表。
这里就不创建表,直接导入一张oracle的一张测试表
MariaDB [test_db]> source /root/ljj2025/MySQL/scott_data.sql;source +文件路径,文件必须是.sql文件。


三张表,一张是部门表,一张员工表,一张薪资表。
虽然这里并没有明确定义但是员工表中的deptno实际上是部门表的foreign key,部门表是主表,员工表是丛表。
MariaDB [scott]> select deptno from emp group by deptno;这是按部门编号对emp表中的内容进行分组查询
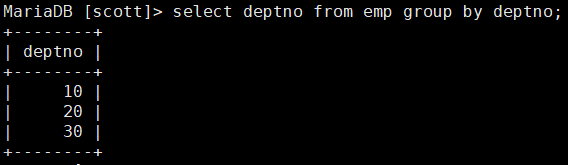
我们查看deptno列,里面只有三种部门编号-10,20,30,所以一共可以分为三组。
根据多个属性进行分组
MariaDB [scott]> select deptno,job from emp group by deptno,job;根据部门进行分组再根据据工作进行分组。
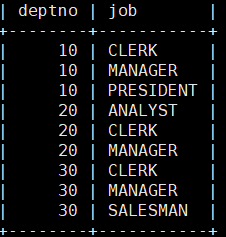
加上对分组的结构进行计数。
MariaDB [scott]> select deptno,job,count(*) from emp group by deptno,job;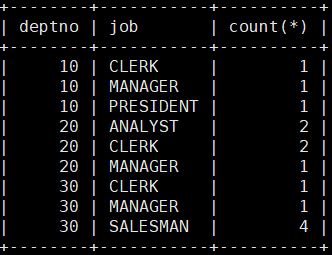
这里结果就是,部门为10的工作为CLERK的人数为1。
也可以惊醒where条件去除一些行
MariaDB [scott]> select deptno,job,count(*) from emp where ename!='MILLER' group by deptno,job;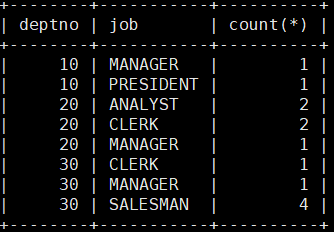 10号部门的MILLER其工作为CLERK,这里就去除掉了。
10号部门的MILLER其工作为CLERK,这里就去除掉了。
分组后一般就是对其进行聚合运算了,如平均值
MariaDB [scott]> select deptno,avg(sal) from emp group by deptno;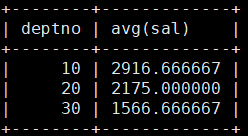 按照部门计算每部门的平均工资
按照部门计算每部门的平均工资
MariaDB [scott]> select deptno,avg(sal),max(sal),min(sal) from emp group by deptno;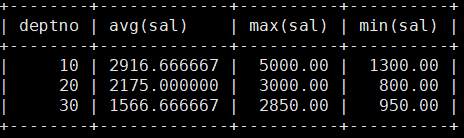 部门的最高最低工资
部门的最高最低工资
对分组之后,进行聚合计算后的表进行筛选
MariaDB [scott]> select deptno,avg(sal) avgsal,max(sal),min(sal) from emp group by deptno having avgsal<2000;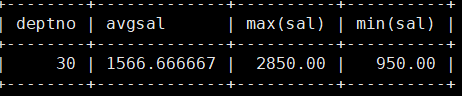
筛选出平均工资低于2000的部门。这里是使用的having关键字,其用作与where的作用一样,都是按列进行筛选,但是优先序不同,where的优先序很高,仅在from table_name的后面,having的优先序在这里是最低的,所以是可以表数据进行分组,聚合,重命名,最后再根据having的表达式进行筛选数据。
整个优先级为select->from table_name->where->group by->having->deptno...(需要显示的列)->order by->limit。