前言
传统的行存与列存都有着各自的优势。行存按行存储,写入快但分析慢;列存按列存储,分析快但写入慢。面对复杂的智慧工厂场景中时序数据高效写入与实时分析的实际需求时,二者都难以满足业务需要。
这次我们将从真实工厂的产线业务出发,详细解密 MARS3 存储引擎的运作机制,看看 YMatrix 数据库是如何解决"时序+分析"这类智慧工厂场景中业务难题的。
01为什么智慧工厂中的产线的数据,容易将数据库写垮?
在智慧工厂产线中包含 数以万计的 IoT 设备、上百条工业流水线,数据有非常鲜明的特点:
- 持续写入。设备状态、传感器指标几乎是 7×24 不间断写入;
- **时间戳驱动。**每一条数据,首先关心的不是 ID,而是 "什么时候发生的";
- **写入之后立即分析。**运维监控、质量分析、异常回溯,并不是"第二天跑离线任务"。
在这样的场景下,对数据库的挑战也随之而来:
- 写入频率高,数据量增长极快,如何实现数据的稳定高效写入;
- 查询几乎永远带有时间条件,如何合理有效进行数据存储;
- 查询时往往只关心少数指标列,如何最大程度减少数据分析时的无效 I/O。
02行存 vs 列存:为什么无法应对智慧工厂带来的挑战?
一个智慧工厂中典型的表结构:
ts | device_id | metric_1 | metric_2 | metric_3 | ...行存:经典数据库的主流存储方式
行存是一种将数据按行存储的数据库存储方式。对于一个包含时间戳(ts)、设备ID(device_id)、指标1(metric_1)、指标2(metric_2)等字段的表,行存会将每一行完整的数据打包放在一起,像一个个"整箱快递"。特点是一行数据,整体存放。多使用于银行转账、订单创建等 TP 业务。
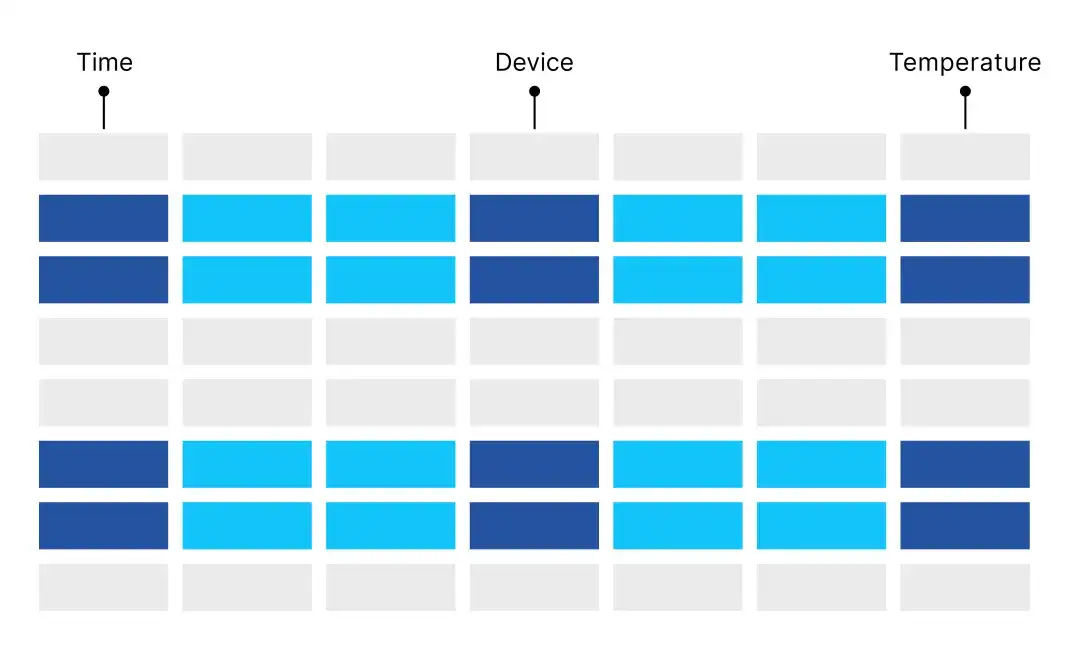
使用行存在智慧工厂中会出现什么样的效果呢?
-
设备每上报一次状态 ,需写一整行数据;
-
单条数据记录查询,查询速度非常快。
但一旦进入数据分析阶段,如:查过去 24 小时的温度变化趋势、查某指标在 1000 台设备上的分布情况等。即使只关心一列数据,但也需要把整行数据读出,这会产生大量无效 IO,成为时序分析场景中最常见的性能杀手。
列存:分析数据库的主流存储方式
列存是一种将数据按列存储的数据库存储方式。对于一个包含时间戳(ts)、设备ID(device_id)、指标1(metric_1)、指标2(metric_2)等字段的表,列存会将时间戳的所有值存储在一起,设备ID的所有值存储在一起,依此类推。多使用于指标聚合、大范围扫描、历史数据分析等 AP 业务。
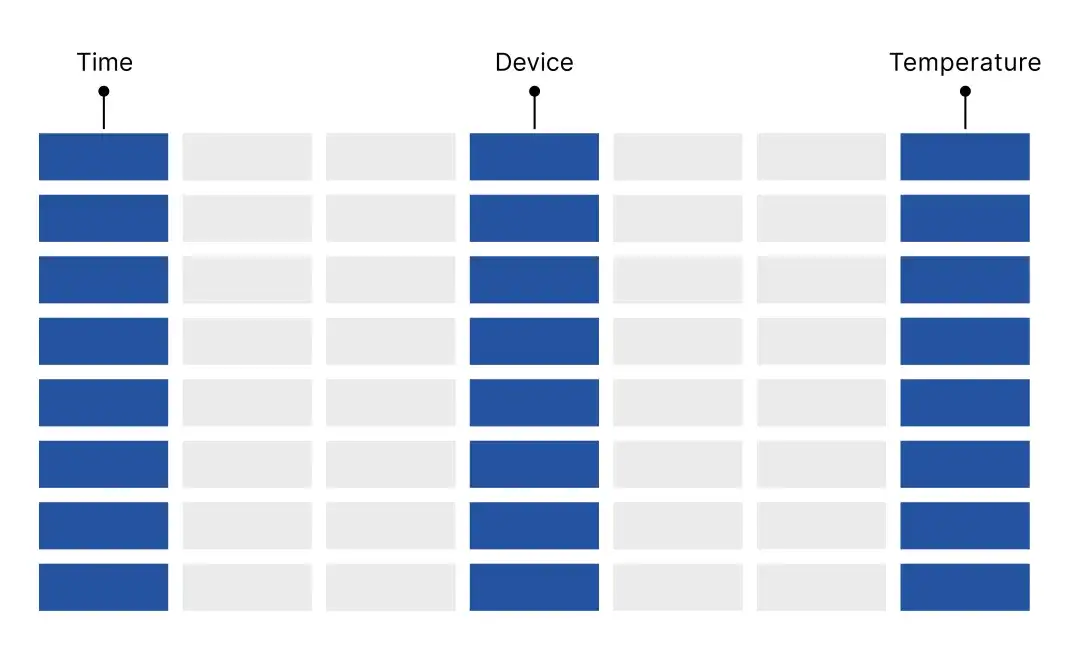
使用列存在智慧工厂中会出现什么样的效果呢?
-
"时间戳 + 指标列",每列的数据类型相同,可通过数据压缩等技术来减少存储空间,压缩率高。
-
无需整行读取,只需扫描少量指标,IO 消耗低。
但问题同样突出,写入压力极大:面对高频小批量写入和持续追加这类场景就会显得有心无力。这会带来频繁的列组织调整、更高的写放大和明显的写入延迟等问题。
因此,智慧工厂场景既不是传统的 TP 业务,也不是单纯的 AP 业务,而是典型的"TP + AP"混合负载,需要将行存与列存进行融合,挣脱"偏科"束缚。
03MARS3 存储引擎完美融合行存与列存,实现"时序+分析"一体
MARS3 存储引擎是 YMatrix 针对"时序+分析"型负载设计的行列混存架构,该架构不是简单地在行存和列存之间进行"折中",而是引入先行后列(Row → Column)的双存储路径,以实现「写入像行存一样轻,分析像列存一样快」的效果。
写入优先:先接住数据,再谈分析
在智慧工厂场景中,写入的第一优先级是:不阻塞、不抖动、不丢数据 。在 MARS3 中, 新数据,会优先进行行存,类似"缓冲草稿区",不做复杂压缩,不要求立刻排序。
这一步非常关键,使得 MARS3 存储引擎能够轻松承接:
- 高频传感器上报
- 设备状态实时写入
- 流水线持续数据流
后台转列:把"原始流水"变成"分析友好数据"
当行存达到一定大小 (如 64MB),MARS3 存储引擎会自动按照以下规则完成数据整理:1. 按时间戳排序;2. 拆分为列存格式;3. 按 Range 切块;4. 对同一指标列进行压缩。
这一步非常适合智慧工厂数据的结构特性:
- 时间戳单调递增
- 同一指标随时间变化
- 相邻数据高度相似
列式压缩与时间序列数据天然契合。
数据合并:让系统越跑越稳
随着数据持续写入,如果不加以控制的话,会出现查询会扫描大量重叠数据、写放大与读放大现象愈发严重等问题。
MARS3 存储引擎通过自动数据合并:
- 合并重叠数据
- 删除/更新过期的数据
- 控制读放大
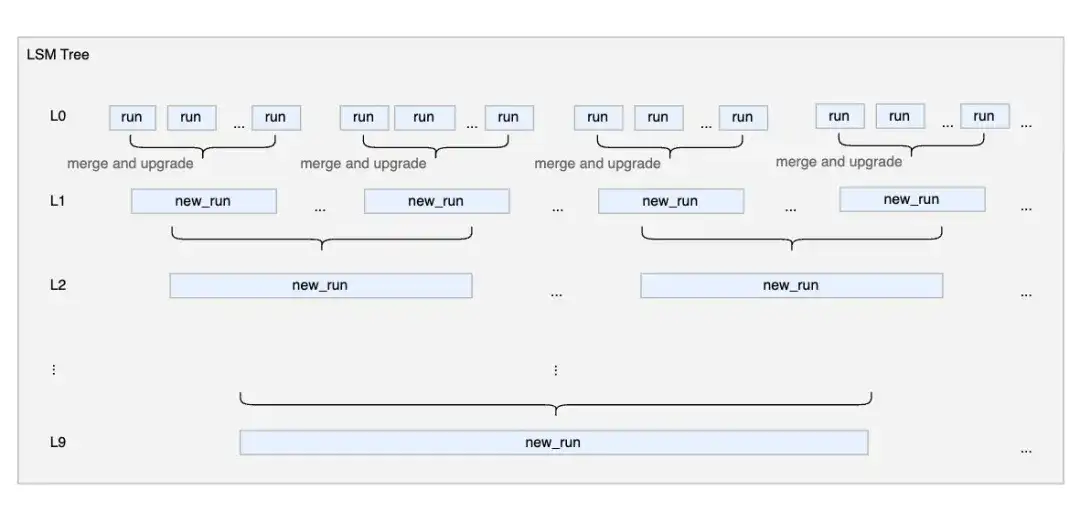
整个数据合并过程不阻塞写、不阻塞读,可达到实现空间清理、提升查询性能的效果,这对于长期运行的智慧工厂系统来说至关重要。
查询路径:时间戳就是"天然索引"
以智慧工厂中的典型特征查询为例:WHERE ts >= now() - interval '1 hour'。
MARS3 存储引擎在进行数据查询时,设计了"四层过滤"机制,最大程度减少无效 IO,查询速度比传统列存更快:
- Run 过滤:用 Run 的 MIN / MAX 信息跳过与查询数据无关的文件(如查"2025 年数据",直接跳过 2023 年的 Run)。
- Range 过滤:在 Run 内用 Range 块的 MIN / MAX 定位目标数据,不用扫描全块。
- 列裁剪:只读查询需要的列(如查销售额,只需读 ts 和 amount 所在列,避免无关数据读取)。
- 版本过滤:自动跳过已删除/已更新的无效行,避免无效计算
04总结
我们可以把 MARS3 存储引擎的优势简单总结为四句话:
- **写入不等待:**稳定承接持续、高频的时序数据。
- **行列混存:**自动化行转列触发,无需人工干预。
- **分析不扫全表:**多重过滤机制,减少查询等待。
- **长期运行不退化:**自动数据整理合并,保持性能稳定。
这也正是 MARS3 存储引擎从容应对智慧工厂场景给数据库所带来挑战的成功秘诀之一。
目前,YMatrix 已经具备成熟的智慧工厂解决方案,且已经在众多制造企业中得到了广泛应用与一致认可。
🌟 如需了解更多案例详情,可查看 YMatrix 客户案例:Case-studies
🌟 如需了解更多 MARS3 存储引擎内容,可查看:MARS3