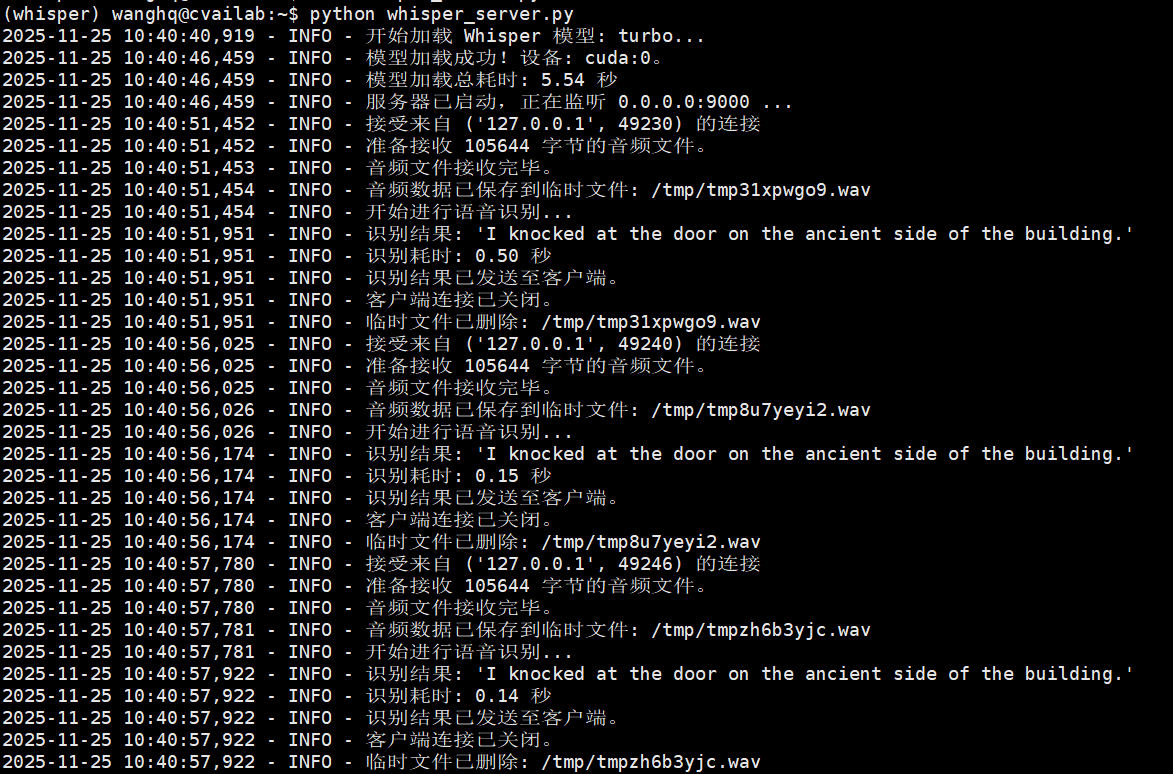
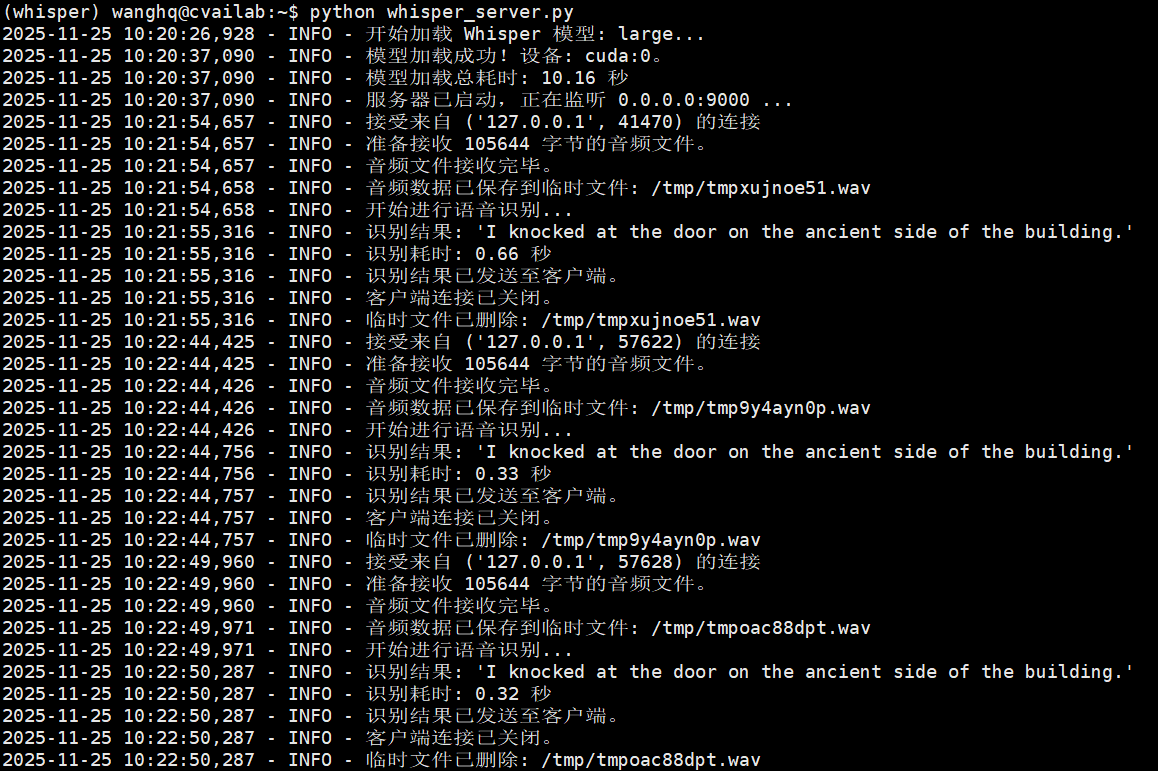
背景
语音识别是人机交互的一个关键技术,机器人本体携带的算力和能源一般比较有限,通过TCP/IP socket通信,把计算分配到云端是一种选择。
根据官方的提供的代码,进行了server和client的代码实现。现在好像只能通过文件进行识别,不能直接使用接收到的音频文件(多了一次把音频写到文件和从文件读取)。
目录
环境介绍:
系统:Ubuntu 20.04.6 LTS
显卡:Nvidia RTX 4090
Python版本:Anaconda Python 3.10.19
whisper_server.py
python
import socket
import struct
import os
import logging
import time
import tempfile
import whisper
import argparse
# --- 配置日志 ---
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
class WhisperServer:
def __init__(self, host='0.0.0.0', port=9000, model_name="large"):
self.host = host
self.port = port
self.model_name = model_name
self.server_socket = None
self.model = None
# --- 模型加载和计时 ---
logging.info(f"开始加载 Whisper 模型: {self.model_name}...")
start_time = time.time()
try:
# 自动选择 CUDA 或 CPU
self.model = whisper.load_model(self.model_name)
load_time = time.time() - start_time
logging.info(f"模型加载成功!设备: {self.model.device}。")
logging.info(f"模型加载总耗时: {load_time:.2f} 秒")
except Exception as e:
logging.error(f"加载 Whisper 模型失败: {e}")
raise
def start(self):
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
try:
self.server_socket.bind((self.host, self.port))
self.server_socket.listen(5)
logging.info(f"服务器已启动,正在监听 {self.host}:{self.port} ...")
while True:
client_socket, addr = self.server_socket.accept()
logging.info(f"接受来自 {addr} 的连接")
self.handle_client(client_socket)
except Exception as e:
logging.error(f"服务器发生错误: {e}")
finally:
if self.server_socket:
self.server_socket.close()
logging.info("服务器套接字已关闭。")
def _receive_all(self, sock, n):
"""确保接收到指定长度的字节数据"""
data = bytearray()
while len(data) < n:
# 尝试接收剩余的数据
packet = sock.recv(n - len(data))
if not packet:
return None # 连接断开
data.extend(packet)
return data
def handle_client(self, client_socket):
temp_audio_file = None
try:
# 1. 接收文件大小 (8字节头部)
header_data = self._receive_all(client_socket, 8)
if not header_data:
logging.warning("未能接收到头部信息,客户端可能已断开。")
return
file_size = struct.unpack('!Q', header_data)[0]
logging.info(f"准备接收 {file_size} 字节的音频文件。")
# 2. 接收完整的音频文件数据
wav_data = self._receive_all(client_socket, file_size)
if not wav_data or len(wav_data) != file_size:
logging.warning(f"接收到的文件大小与头部信息不匹配或连接中断。")
return
logging.info("音频文件接收完毕。")
# 3. 保存到临时文件 (使用 .wav 扩展名确保 whisper 正确识别格式)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as fp:
temp_audio_file = fp.name
fp.write(wav_data)
logging.info(f"音频数据已保存到临时文件: {temp_audio_file}")
# 4. 执行转写和计时
logging.info("开始进行语音识别...")
recognize_start_time = time.time()
# 默认进行自动语言检测和转写
result = self.model.transcribe(temp_audio_file)
result_text = result["text"].strip()
recognize_time = time.time() - recognize_start_time
logging.info(f"识别结果: '{result_text}'")
logging.info(f"识别耗时: {recognize_time:.2f} 秒")
# 5. 将结果发送回客户端
response_data = result_text.encode('utf-8')
client_socket.sendall(response_data)
logging.info("识别结果已发送至客户端。")
except Exception as e:
logging.error(f"处理客户端时发生错误: {e}", exc_info=True)
# 发送错误信息给客户端,防止客户端无限等待
client_socket.sendall(f"[SERVER_ERROR]: {e}".encode('utf-8'))
finally:
client_socket.close()
logging.info("客户端连接已关闭。")
if temp_audio_file and os.path.exists(temp_audio_file):
os.remove(temp_audio_file)
logging.info(f"临时文件已删除: {temp_audio_file}")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="OpenAI Whisper ASR Socket Server")
parser.add_argument('--host', type=str, default='0.0.0.0', help='服务器监听的主机地址')
parser.add_argument('--port', type=int, default=9000, help='服务器监听的端口')
parser.add_argument('--model', type=str, default='turbo', choices=['tiny', 'base', 'small', 'medium', 'large', 'turbo'], help='Whisper模型名称')
args = parser.parse_args()
server = WhisperServer(host=args.host, port=args.port, model_name=args.model)
server.start()whisper_client.py
python
import socket
import struct
import os
import logging
import time
# --- 配置日志 ---
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- 服务器配置 ---
SERVER_IP = "127.0.0.1"
SERVER_PORT = 9000
TEST_WAV_FILE = "./zh.wav" # 请替换为实际的音频文件路径
def send_and_recognize(server_ip: str, server_port: int, wav_file_path: str) -> str:
"""
通过Socket连接到Whisper服务器,发送WAV文件并获取识别结果。
"""
if not os.path.exists(wav_file_path):
raise FileNotFoundError(f"音频文件不存在: {wav_file_path}")
client_socket = None
total_start_time = time.time()
try:
# --- 1. 创建socket并连接服务器 ---
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
logging.info(f"正在连接到服务器 {server_ip}:{server_port}...")
client_socket.connect((server_ip, server_port))
logging.info("连接成功!")
# --- 2. 读取WAV文件并准备数据 ---
with open(wav_file_path, 'rb') as f:
wav_data = f.read()
file_size = len(wav_data)
# --- 3. 发送文件大小的头部信息 ---
header = struct.pack('!Q', file_size)
client_socket.sendall(header)
logging.info(f"已发送文件头,文件大小: {file_size} 字节。")
# --- 4. 发送完整的WAV文件数据 ---
client_socket.sendall(wav_data)
logging.info("已发送WAV文件数据。")
# --- 5. 接收服务器的识别结果 ---
buffer = bytearray()
while True:
# 接收服务器返回的识别结果
chunk = client_socket.recv(4096)
if not chunk:
break
buffer.extend(chunk)
result_text = buffer.decode('utf-8')
total_time = time.time() - total_start_time
logging.info(f"从服务器接收到结果: '{result_text}'")
logging.info(f"客户端总耗时 (含网络传输和等待识别): {total_time:.2f} 秒")
return result_text
except socket.error as e:
logging.error(f"Socket错误: {e}")
raise ConnectionError(f"无法连接或与服务器通信: {server_ip}:{server_port}")
except Exception as e:
logging.error(f"发生未知错误: {e}")
raise
finally:
if client_socket:
client_socket.close()
logging.info("与服务器的连接已关闭。")
if __name__ == '__main__':
# --- 请在这里修改您要测试的音频文件路径 ---
#TEST_WAV_FILE = "./audio.wav"
TEST_WAV_FILE = "./Downloads/en.wav"
if not os.path.exists(TEST_WAV_FILE):
print(f"\n错误:测试文件 '{TEST_WAV_FILE}' 不存在。请准备一个音频文件并修改 TEST_WAV_FILE 变量。")
else:
try:
recognized_text = send_and_recognize(SERVER_IP, SERVER_PORT, TEST_WAV_FILE)
print("\n" + "="*40)
print(f"最终识别结果:\n{recognized_text}")
print("="*40 + "\n")
except Exception as e:
print(f"\n调用识别函数时出错: {e}")识别时间测试
large模型大约是turbo的2倍