你有没有过这样的经历?想画个法兰盘的CAD模型,得打开专业软件、调坐标系、画草图、做拉伸......步骤繁琐还得熟稔操作逻辑。现在,基于大语言模型(LLM)和CadQuery的CAD-Coder方案,能让你输入一段零件描述,直接生成可执行的CAD代码------今天我们就来拆解这个让CAD建模"动口不动手"的技术!
一、从文本到3D模型:不同表示方式的对比
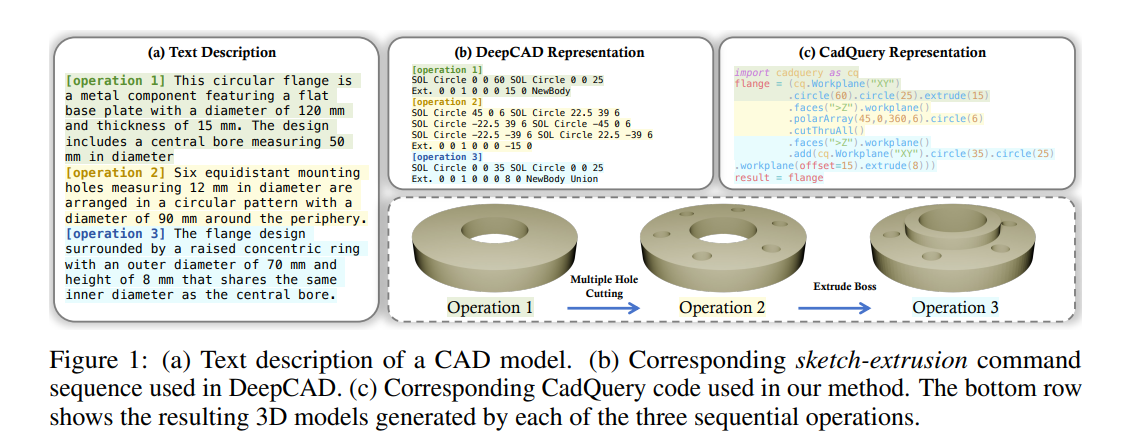
先看一个法兰盘的例子:
- 文本描述:只需要说明"120mm直径的金属法兰盘,15mm厚,中心50mm孔,6个12mm安装孔(分布在90mm圆周),还有70mm外径、8mm高的凸环"。
- DeepCAD表示 :是一套自定义的命令序列(比如
SOL_Circle 0 0 60),虽然能生成模型,但语法封闭、不易扩展。 - CadQuery表示 :直接用Python代码实现(比如
cq.Workplane("XY").circle(60).circle(25).extrude(15)),既贴合工程习惯,又能直接在CadQuery中执行生成3D模型。
更直观的是"分步建模":操作1画底座、操作2打安装孔、操作3加凸环,每一步的代码和模型都清晰对应,出错了也能精准调试。
二、CAD-Coder怎么训练?让LLM学会"逻辑建模"
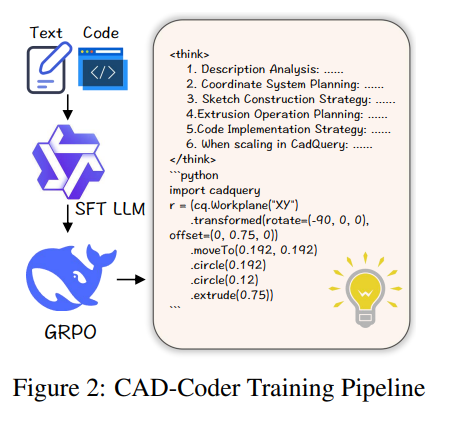
CAD-Coder的训练 pipeline :
输入是零件文本描述+对应的CadQuery代码 ,经过有监督微调(SFT)的LLM 和GRPO优化策略,让模型学会"有逻辑地生成代码"------生成前会先做"思考":
- 分析文本描述的零件特征;
- 规划坐标系(比如以零件中心为原点);
- 设计草图的绘制顺序;
- 确定拉伸/切割的操作参数......
这种"先思考、再编码"的方式,让生成的CadQuery代码更贴合工程实际,不是盲目拼接语法。
三、高质量数据集:靠"择优"搞定标注
要训练LLM,得有文本-CadQuery-3D模型的三元组数据,但现有Text2CAD数据集只有命令序列。怎么办?
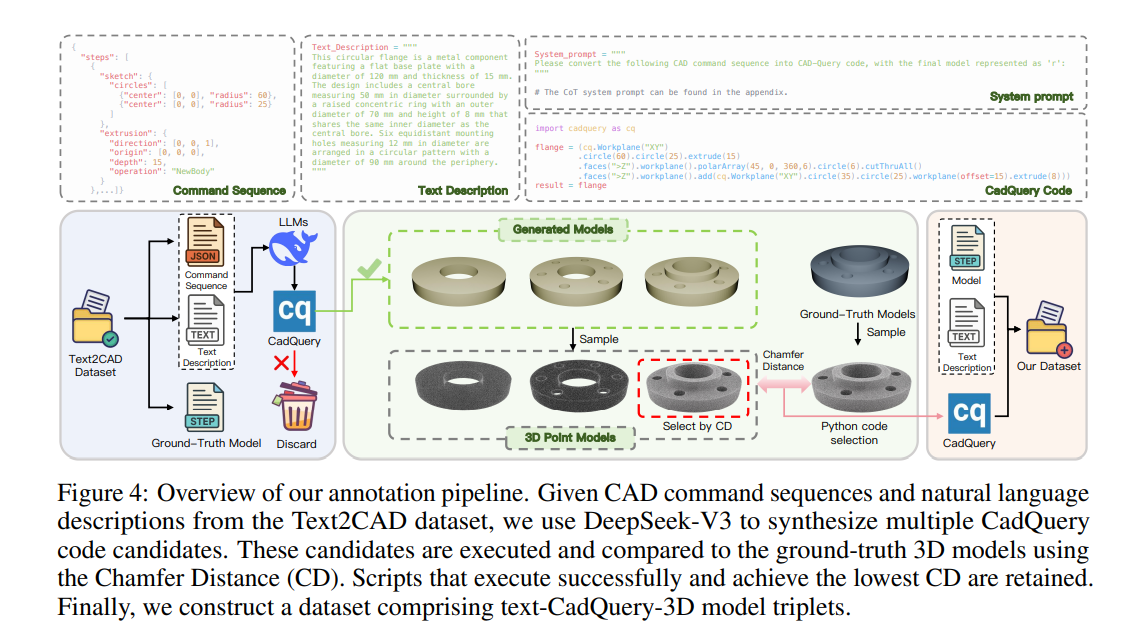
我们用标注 pipeline 自动"择优":
- 用DeepSeek-V3生成多个CadQuery代码候选;
- 执行每个候选代码,得到对应的3D模型;
- 计算生成模型与"真值模型"的Chamfer Distance(CD,衡量3D模型相似度);
- 保留CD最小、能成功执行的代码,组成最终数据集。
这个流程既解决了数据缺失问题,又保证了代码的准确性------毕竟"能生成和真值一致的3D模型"才是硬标准。
为什么这个方案更实用?
- CadQuery的优势:基于Python的开源库,代码可复用、易修改,工程师不用学新语法;
- 可解释性强:分步建模的逻辑和CAD软件操作一致,出错了能定位到具体代码行;
- 数据集质量高:通过Chamfer Distance筛选,避免了"代码能跑但模型不对"的情况。
这个方案把LLM的自然语言理解能力和CadQuery的工程实用性结合,让非专业人员也能快速生成CAD模型。未来还能扩展到带螺纹、倒角的复杂零件~
总结
当前 CAD Coder 虽实现了文本到 CAD 模型的自动化转换,但仍存局限性:
- 数据集多聚焦简单零件(如基础法兰、凸台),对复杂装配体、自由曲面或带精密公差的零件支持不足,难覆盖实际工程的高复杂度需求;
- 生成代码侧重几何形状还原,缺乏对加工工艺、尺寸链约束、装配兼容性等工程实用信息的考量,模型易 "可看不可用";
- 交互灵活性有限,暂不支持自然语言驱动的实时迭代修改,且对行业专属术语的歧义处理能力较弱。
其未来趋势将更贴近工程实际:一方面会拓展融合装配关系、公差、工艺参数的高质量数据集,提升复杂场景适配性;另一方面会强化交互与工程知识融合,支持自然语言增量编辑、自动嵌入工艺约束,探索草图 + 文本的多模态协同建模;同时会推进与主流 CAD 软件的生态集成,实现代码向专业工具的无缝导入,并针对机械、航空等领域做定制化优化,让文本驱动建模真正落地生产流程。