目录
- 前言
- [一、Node.js 概览](#一、Node.js 概览)
- 二、关键组件
-
- 1、关键组件的运行时架构图
- [2、JavaScript 单线程运行时(JS Runtime)](#2、JavaScript 单线程运行时(JS Runtime))
- [3、V8 引擎(Chrome 里的那套)](#3、V8 引擎(Chrome 里的那套))
- [4、事件循环(Event Loop)------Node 核心中的核心(⭐️)](#4、事件循环(Event Loop)——Node 核心中的核心(⭐️))
- 5、事件驱动架构(EventEmitter)
- [6、非阻塞 I/O 模型------Node 的杀手级能力(⭐️)](#6、非阻塞 I/O 模型——Node 的杀手级能力(⭐️))
- [7、Libuv(Node 背后的 C++ 引擎)------必须理解(⭐️)](#7、Libuv(Node 背后的 C++ 引擎)——必须理解(⭐️))
- [8、线程池(Thread Pool)------文件/压缩/加密 都靠它(⭐️)](#8、线程池(Thread Pool)——文件/压缩/加密 都靠它(⭐️))
- [9、模块系统(CommonJS, ES Modules)](#9、模块系统(CommonJS, ES Modules))
- 10、Buffer(处理二进制数据)------大文件/网络必须掌握(⭐️)
- [11、Stream(流)------Node 最强能力之一(⭐️)](#11、Stream(流)——Node 最强能力之一(⭐️))
- [12、网络栈(HTTP / TCP / UDP)](#12、网络栈(HTTP / TCP / UDP))
- [13、NPM(Node 包管理生态)](#13、NPM(Node 包管理生态))
- [三、Node.js 核心 API(按功能分类)](#三、Node.js 核心 API(按功能分类))
-
- [1、基础平台能力:运行环境 / 事件系统](#1、基础平台能力:运行环境 / 事件系统)
-
- [(1)、process(进程信息、环境变量)✔ 全栈必会](#(1)、process(进程信息、环境变量)✔ 全栈必会)
- [(2)、events(事件驱动)✔ Node 核心原理](#(2)、events(事件驱动)✔ Node 核心原理)
- (3)、timers(定时器)
- 2、文件与目录(后端最常用)
-
- [(1)、fs(文件系统)✔ 必会](#(1)、fs(文件系统)✔ 必会)
- [(2)、path(路径管理)✔ Webpack/Vite 必备](#(2)、path(路径管理)✔ Webpack/Vite 必备)
- (3)、os(操作系统信息)
- [3、网络与通信(Node 最强能力)](#3、网络与通信(Node 最强能力))
-
- [(1)、http(创建 HTTP 服务器)✔ Express 的底层](#(1)、http(创建 HTTP 服务器)✔ Express 的底层)
- [(2)、https(HTTPS 服务器)](#(2)、https(HTTPS 服务器))
- [(3)、net(TCP 服务器)](#(3)、net(TCP 服务器))
- (4)、dns(域名解析)
- [(5)、dgram(UDP 消息)](#(5)、dgram(UDP 消息))
- [4、子进程与多线程(处理 CPU 密集任务)](#4、子进程与多线程(处理 CPU 密集任务))
-
- [(1)、child_process(创建子进程)✔ 生产环境常用](#(1)、child_process(创建子进程)✔ 生产环境常用)
- [(2)、worker_threads(多线程)✔ 解决 CPU 密集](#(2)、worker_threads(多线程)✔ 解决 CPU 密集)
- (3)、cluster(多核负载均衡)
- 5、数据流(流式处理)
- 6、压缩/加密/工具类
-
- (1)、zlib(压缩)
- [(2)、crypto(加密、哈希)✔ 账号系统必用](#(2)、crypto(加密、哈希)✔ 账号系统必用)
- 7、调试与诊断
- 8、URL、查询参数等网络工具
- [9、最实用的 Node.js API 记忆法(高频 24 个)(⭐️⭐️⭐️⭐️⭐️)](#9、最实用的 Node.js API 记忆法(高频 24 个)(⭐️⭐️⭐️⭐️⭐️))
- [四、一个超简单 Node.js 的示例](#四、一个超简单 Node.js 的示例)
- 五、全面升级上面的这个示例
-
- 1、初始化项目
- [2、搭建后端:Express + SQLite](#2、搭建后端:Express + SQLite)
- 3、搭建前端:React
- 4、前端实现用户管理
- 5、测试
- 6、最终目录结构
- [六、Node.js 性能优化指南(企业级)](#六、Node.js 性能优化指南(企业级))
-
- 1、总体原则(先观测再优化)
- 2、必须搭建的观测与诊断体系(工具与指标)
- 3、定位瓶颈(诊断流程)
- 4、代码级优化(高影响项)
-
- (1)、避免阻塞事件循环
- [(2)、使用流(Streams)与 backpressure](#(2)、使用流(Streams)与 backpressure)
- (3)、减少对象分配与内存抖动
- [(4)、优化 JSON 序列化](#(4)、优化 JSON 序列化)
- (5)、避免不必要的同步加解密
- [(6)、智能缓存(本地 & 分布式)](#(6)、智能缓存(本地 & 分布式))
- (7)、连接池与并发限制
- [5、运行时调优(Node 级别参数)](#5、运行时调优(Node 级别参数))
-
- (1)、NODE_ENV
- [(2)、GC 与堆大小](#(2)、GC 与堆大小)
- (3)、UV_THREADPOOL_SIZE
- (4)、启用并限制抓取
- 6、多核与可靠扩缩(进程/线程层)
-
- [(1)、Cluster / PM2 / Process Manager](#(1)、Cluster / PM2 / Process Manager)
- [(2)、Worker Threads(处理 CPU 密集)](#(2)、Worker Threads(处理 CPU 密集))
- (3)、分布式扩缩
- [7、I/O 与外部依赖优化](#7、I/O 与外部依赖优化)
-
- [(1)、DB 优化](#(1)、DB 优化)
- (2)、网络请求
- [(3)、使用 CDN 与边缘缓存](#(3)、使用 CDN 与边缘缓存)
- [8、网络层优化(Nginx / Proxy)](#8、网络层优化(Nginx / Proxy))
- 9、安全与稳定性(影响性能的非功能项)
- [10、容器化与 K8s 实践](#10、容器化与 K8s 实践)
- 11、日志、指标与可观测性实践
- [12、性能测试与回归(CI 集成)](#12、性能测试与回归(CI 集成))
- 13、常见场景与解决方案速查表
- [14、十四、示例监控指标导出(Prometheus 简单实现)](#14、十四、示例监控指标导出(Prometheus 简单实现))
- 15、优先级清单(落地执行顺序)
- [16、常用命令 & 快速检查清单](#16、常用命令 & 快速检查清单)
前言
安装 Node.js 和初始化项目:mac/windows安装|卸载node以及用n/nvm管理node版本
一、Node.js 概览
-
定义:Node.js = 在服务器/桌面环境运行 JavaScript 的运行时。核心由 V8 引擎(执行 JS) + libuv(事件循环与异步 I/O) + Node 的标准库(核心模块)构成。
-
设计目标:高并发 I/O(非阻塞、事件驱动)、轻量级服务器端开发。
-
擅长场景:HTTP API、实时通信(WebSocket/Socket.IO)、代理/网关、CLI 工具、构建工具、Electron 桌面应用。
-
不擅长场景:CPU 密集型任务(长时间阻塞主线程)。
二、关键组件
1、关键组件的运行时架构图
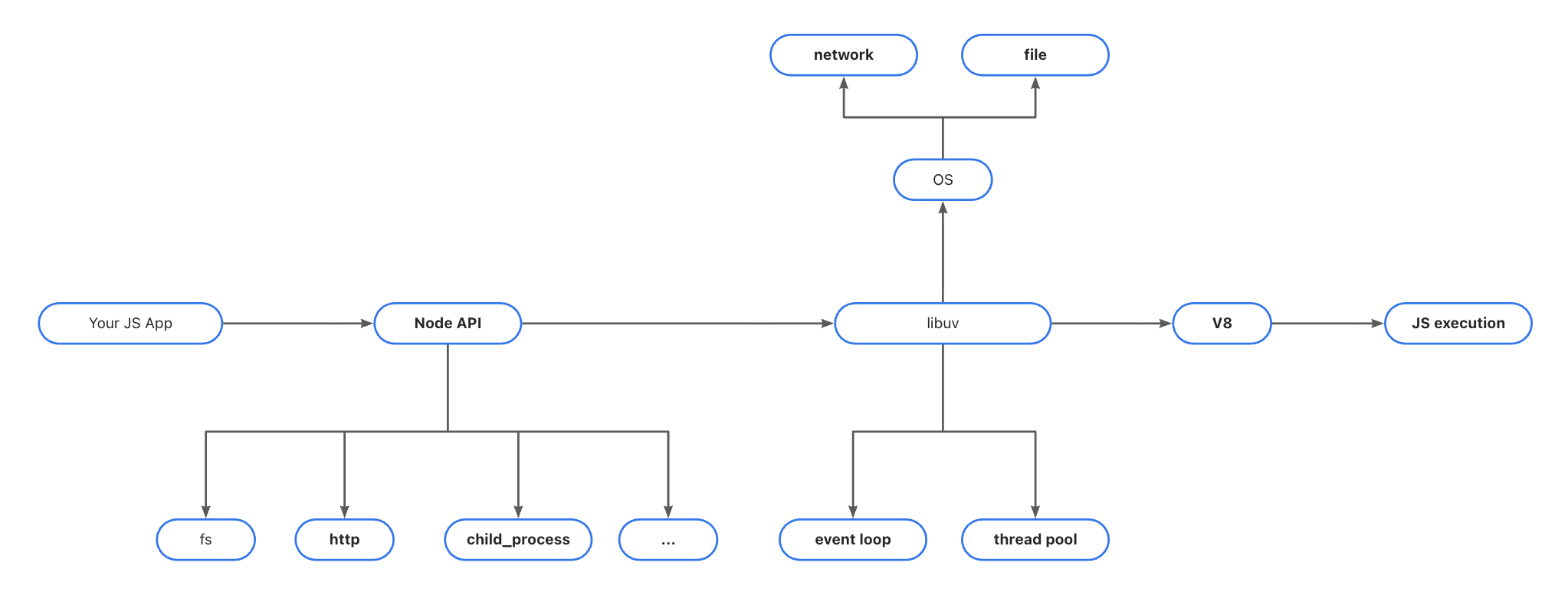
2、JavaScript 单线程运行时(JS Runtime)
Node.js 使用 单线程 执行 JavaScript 代码。
意味着:
- 代码一个接一个执行(类似浏览器)
- 不能直接用多线程跑 JavaScript
但 单线程不等于 Node.js 只能处理一个请求,因为它有:
- 事件循环(调度任务)
- 线程池(处理重任务)
- 系统内核(处理网络 I/O)
这就是 Node 高并发的根本原因:不是靠 JS,而是靠事件循环 + libuv。
3、V8 引擎(Chrome 里的那套)
Node.js 的 JS 引擎就是:Chrome 的 V8
功能包括:
- 解析 JS(Parser)
- 解释执行(Interpreter)
- 编译优化(TurboFan)
- 垃圾回收(GC)
优点:
- 执行速度极快
- 内建优化器,适合服务器代码
- Node 之所以快,就是因为背后是 Google 花巨资优化的 V8。
4、事件循环(Event Loop)------Node 核心中的核心(⭐️)
事件循环是 Node.js 的调度中心。
它负责:
- 执行 JS 主线程任务
- 处理异步任务的回调
- 管理 I/O 完成事件
- 分配 Timer / Promise / I/O 队列顺序
核心阶段包括:
- timers(setTimeout/setInterval)
- pending callbacks
- idle/prepare
- poll(I/O)
- check(setImmediate)
- close callbacks
理解事件循环 = 理解 Node 性能与异步。
5、事件驱动架构(EventEmitter)
Node 内部所有组件都基于事件机制:
- fs 文件读写
- http 请求事件 (req.on('data'))
- net socket
- stream 流
- process 的 exit 事件
你也可以自己写事件:
cpp
const EventEmitter = require('events');
const emitter = new EventEmitter();
emitter.on('start', msg => console.log(msg));
emitter.emit('start', 'hello');事件 = Node 处理异步的核心哲学
6、非阻塞 I/O 模型------Node 的杀手级能力(⭐️)
传统后端(Java、PHP、Python):
- 一次请求 = 一条线程
- I/O 要等待(阻塞)
Node.js:
- I/O 交给系统内核或线程池
- 当 I/O 完成时发事件通知
- JS 主线程继续跑别的任务
因此:
- Node 可以轻松处理 几万并发
- Node 非常适合 I/O 密集(数据库、文件、网络)
7、Libuv(Node 背后的 C++ 引擎)------必须理解(⭐️)
libuv 是 Node.js 底层最重要的组件,它提供:
- I/O 多路复用(epoll / kqueue)
- 事件循环的实现
- 线程池
- 文件系统封装
- TCP/UDP 实现
事件循环 ≠ JS 写的
事件循环 = libuv 写的(C++)
libuv 的存在,让 Node 能提供:
- 非阻塞 I/O
- 大规模并发
- 高性能网络
8、线程池(Thread Pool)------文件/压缩/加密 都靠它(⭐️)
Node 虽然是单线程 JS,但底层有一个 线程池(默认 4 个) 处理重任务。
由 libuv 管理,用于:
- fs.readFile 读取大文件
- crypto.pbkdf2 密码哈希
- zlib.gzip 压缩
- DNS lookup
示例:
cpp
const crypto = require('crypto');
crypto.pbkdf2('password', 'salt', 100000, 64, 'sha512', () =>
console.log('done')
);CPU 密集任务不会卡死主线程,因为它们跑在线程池里。
9、模块系统(CommonJS, ES Modules)
Node 原生支持两套模块系统:
- CommonJS(require)------传统、最常用:
cpp
const fs = require('fs');
module.exports = {}- ESM(import)------现代语法:
cpp
import fs from 'fs';
export default {}Node 现在同时支持两者,但 ESM 正逐渐成为主流。
10、Buffer(处理二进制数据)------大文件/网络必须掌握(⭐️)
Buffer 是 Node.js 专门处理 二进制数据 的结构。
例子:
cpp
const buf = Buffer.from('hello');
console.log(buf);用途:
- 文件读写
- 网络传输数据包
- 图片、音频处理
- Stream 的底层数据结构
Buffer + Stream 是 Node.js 最底层的两个核心。
11、Stream(流)------Node 最强能力之一(⭐️)
Node 的 Stream 是对大数据量的按"块"处理方式。
四类流:
| 类型 | 说明 |
|---|---|
| Readable | 可读流(文件读取) |
| Writable | 可写流(文件写入) |
| Duplex | 双工(TCP) |
| Transform | 转换流(gzip) |
示例:
cpp
fs.createReadStream('./big.file')
.pipe(fs.createWriteStream('./copy.file'));优点:
- 大文件不占内存
- 更快
- 可以边读边写
12、网络栈(HTTP / TCP / UDP)
Node 的网络组件都是底层自己实现,而不是依赖 Apache/Nginx。
- HTTP 服务器
cpp
http.createServer((req, res) => {
res.end('hello');
});- TCP 服务器
cpp
net.createServer(socket => {});- UDP 服务器
cpp
dgram.createSocket('udp4');Node 在网络高并发领域非常强。
13、NPM(Node 包管理生态)
Node 的生态繁荣得益于 NPM:
- 世界最大开源库仓库
- 所有 Node 项目都依赖 npm/yarn/pnpm
含义:
- Node = 运行时
- npm = 生态系统
- Node.js 实力的 50% 来自 NPM。
三、Node.js 核心 API(按功能分类)
1、基础平台能力:运行环境 / 事件系统
(1)、process(进程信息、环境变量)✔ 全栈必会
常用功能:
| 功能 | 示例 |
|---|---|
| 读取环境变量 | process.env.NODE_ENV |
| 退出进程 | process.exit(1) |
| 获取当前目录 | process.cwd() |
| 获取命令行参数 | process.argv |
| CPU 数量 | process.cpuUsage() |
示例:
cpp
console.log(process.env.NODE_ENV);用途:配置分环境部署、CLI 工具。
(2)、events(事件驱动)✔ Node 核心原理
Node 内部所有模块都基于 EventEmitter,如 HTTP、文件流等。
cpp
const { EventEmitter } = require('events');
const emitter = new EventEmitter();
emitter.on('start', () => console.log('started'));
emitter.emit('start');用途:自定义事件机制、插件系统。
(3)、timers(定时器)
| 用法 | API |
|---|---|
| 定时 | setTimeout |
| 轮询 | setInterval |
| 立即执行 | setImmediate |
| 下一事件循环 | process.nextTick() |
nextTick 常用于同步代码后立刻执行。
2、文件与目录(后端最常用)
(1)、fs(文件系统)✔ 必会
常用功能:
| 场景 | API |
|---|---|
| 读文件 | fs.readFile / fs.readFileSync |
| 写文件 | fs.writeFile |
| 追加内容 | fs.appendFile |
| 判断文件/目录状态 | fs.stat |
| 创建目录 | fs.mkdir |
| 删除文件 | fs.rm |
| 创建文件流 | fs.createReadStream |
常用示例:
cpp
const fs = require('fs');
fs.readFile('./data.txt', 'utf8', (err, data) => console.log(data));(2)、path(路径管理)✔ Webpack/Vite 必备
| 场景 | API |
|---|---|
| 拼接路径 | path.join |
| 绝对路径 | path.resolve |
| 扩展名 | path.extname |
示例:
cpp
const path = require('path');
const p = path.join(__dirname, 'data', 'file.txt');(3)、os(操作系统信息)
常用:
- os.cpus()
- os.totalmem()
- os.freemem()
- os.homedir()
3、网络与通信(Node 最强能力)
(1)、http(创建 HTTP 服务器)✔ Express 的底层
示例:
cpp
const http = require('http');
http.createServer((req, res) => {
res.end('Hello');
}).listen(3000);用途:REST API、微服务。
(2)、https(HTTPS 服务器)
cpp
https.createServer({ key, cert }, handler);用于:部署安全站点。
(3)、net(TCP 服务器)
例如实现 WebSocket、Socket 聊天室:
cpp
const net = require('net');
net.createServer(socket => {
socket.write('hello');
});用途:底层通信、代理、代理服务器。
(4)、dns(域名解析)
cpp
dns.lookup()
dns.resolve4()用途:网络诊断、服务发现。
(5)、dgram(UDP 消息)
用于:
- 游戏服务器
- 视频流
- 局域网广播
4、子进程与多线程(处理 CPU 密集任务)
(1)、child_process(创建子进程)✔ 生产环境常用
四种方式:
| 场景 | API |
|---|---|
| 执行 shell 命令 | exec |
| 执行命令并得到 stream | spawn |
| 启动 Node 子脚本 | fork |
| 同步执行 | execSync |
示例:
cpp
const { exec } = require('child_process');
exec('ls', (err, stdout) => console.log(stdout));(2)、worker_threads(多线程)✔ 解决 CPU 密集
例:图片压缩、大计算任务。
(3)、cluster(多核负载均衡)
一行代码让 Node 用满所有 CPU 核心:
cpp
cluster.fork();5、数据流(流式处理)
Node 的二级核心:Stream
常见 Stream 类型:
| 类型 | 举例 |
|---|---|
| 可读流 | 文件读取、HTTP Request |
| 可写流 | 文件写入、HTTP Response |
| 双工流 | TCP socket |
| 转换流 | gzip 压缩/解压 |
示例:
cpp
fs.createReadStream('./file.txt')
.pipe(fs.createWriteStream('./copy.txt'));优点:处理大文件不占内存。
6、压缩/加密/工具类
(1)、zlib(压缩)
常用于 gzip 网站内容:
cpp
zlib.createGzip();(2)、crypto(加密、哈希)✔ 账号系统必用
常用:
cpp
crypto.createHash('sha256')
crypto.randomBytes()
crypto.createCipheriv()示例:
cpp
crypto.createHash('sha256').update('password').digest('hex');7、调试与诊断
- console(日志)
- inspector(调试)
- perf_hooks 性能分析
8、URL、查询参数等网络工具
- URL(新 API)------Web 兼容
9、最实用的 Node.js API 记忆法(高频 24 个)(⭐️⭐️⭐️⭐️⭐️)
如果你只想记重点,下面这 24 个是最常用的,够开发 90% 项目。
- 文件/目录
- fs.readFile
- fs.writeFile
- fs.createReadStream
- fs.createWriteStream
- fs.stat
- fs.mkdir
- path.join
- path.resolve
- 网络/通信
- http.createServer
- https.createServer
- net.createServer
- url.URL
- dns.lookup
- 系统
- process.env
- process.cwd
- os.cpus
- os.homedir
- 多线程/进程
- child_process.exec
- child_process.fork
- worker_threads.Worker
- 工具类
- crypto.createHash
- zlib.createGzip
- 事件 & 定时器
- events.EventEmitter
- setImmediate
- process.nextTick
四、一个超简单 Node.js 的示例
1、创建最小 Node.js 服务器
在项目根目录创建 index.js:
cpp
// index.js
const express = require('express');
const app = express();
const PORT = 3000;
// 中间件,解析 JSON
app.use(express.json());
// 根路由
app.get('/', (req, res) => {
res.send('Hello Node.js from 0 to 1!');
});
// 启动服务器
app.listen(PORT, () => {
console.log(`Server running at http://localhost:${PORT}`);
});运行:
bash
node index.js浏览器访问 http://localhost:3000,你会看到:
cpp
Hello Node.js from 0 to 1!这是最小 Node.js 项目✅。
2、添加一个简单 API
比如我们做一个 用户列表 API:
cpp
// 模拟数据库
let users = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' }
];
// 获取用户列表
app.get('/api/users', (req, res) => {
res.json(users);
});
// 添加新用户
app.post('/api/users', (req, res) => {
const { name } = req.body;
const newUser = { id: users.length + 1, name };
users.push(newUser);
res.status(201).json(newUser);
});测试:
bash
curl http://localhost:3000/api/users
curl -X POST http://localhost:3000/api/users -H "Content-Type: application/json" -d '{"name":"Charlie"}'3、添加前端页面
在项目根目录创建 index.html:
cpp
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Node.js Demo</title>
</head>
<body>
<h1>用户列表</h1>
<ul id="userList"></ul>
<input type="text" id="username" placeholder="输入名字">
<button onclick="addUser()">添加用户</button>
<script>
async function fetchUsers() {
const res = await fetch('/api/users');
const users = await res.json();
const list = document.getElementById('userList');
list.innerHTML = '';
users.forEach(u => {
const li = document.createElement('li');
li.textContent = `${u.id}. ${u.name}`;
list.appendChild(li);
});
}
async function addUser() {
const name = document.getElementById('username').value;
if (!name) return alert('请输入名字');
await fetch('/api/users', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name })
});
document.getElementById('username').value = '';
fetchUsers();
}
fetchUsers();
</script>
</body>
</html>修改 index.js 让它能返回这个 HTML 页面:
cpp
const path = require('path');
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'index.html'));
});现在访问 http://localhost:3000,你就能看到用户列表和添加用户功能了。
4、目录结构
最终项目结构示例:
cpp
my-node-app/
├─ index.js
├─ package.json
├─ package-lock.json
└─ index.html五、全面升级上面的这个示例
我们就把刚才的最小 Node.js 项目升级为一个 完整的全栈 CRUD 项目,具备以下特点:
- 后端:Node.js + Express + SQLite 数据库
- 前端:React + Fetch 调用后端 API
- 功能:用户管理(增删改查)
- 自动重启:Nodemon
1、初始化项目
假设你在项目目录 my-node-app:
bash
mkdir my-fullstack-app
cd my-fullstack-app
npm init -y安装后端依赖:
bash
npm install express sqlite3 cors
npm install -D nodemon- express:后端框架
- sqlite3:数据库
- cors:允许前端跨域请求
- nodemon:开发时自动重启
修改 package.json 增加脚本:
json
"scripts": {
"start": "node index.js",
"dev": "nodemon index.js"
}2、搭建后端:Express + SQLite
在根目录创建 index.js:
cpp
const express = require('express');
const sqlite3 = require('sqlite3').verbose();
const cors = require('cors');
const app = express();
const PORT = 3000;
app.use(cors());
app.use(express.json());
// 初始化数据库
const db = new sqlite3.Database('./users.db', (err) => {
if (err) console.error(err.message);
else console.log('Connected to SQLite database.');
});
// 创建用户表
db.run(`CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL
)`);
// --- CRUD API ---
// 获取用户列表
app.get('/api/users', (req, res) => {
db.all(`SELECT * FROM users`, [], (err, rows) => {
if (err) return res.status(500).json({ error: err.message });
res.json(rows);
});
});
// 添加用户
app.post('/api/users', (req, res) => {
const { name } = req.body;
db.run(`INSERT INTO users(name) VALUES(?)`, [name], function(err) {
if (err) return res.status(500).json({ error: err.message });
res.status(201).json({ id: this.lastID, name });
});
});
// 更新用户
app.put('/api/users/:id', (req, res) => {
const { id } = req.params;
const { name } = req.body;
db.run(`UPDATE users SET name=? WHERE id=?`, [name, id], function(err) {
if (err) return res.status(500).json({ error: err.message });
res.json({ id, name });
});
});
// 删除用户
app.delete('/api/users/:id', (req, res) => {
const { id } = req.params;
db.run(`DELETE FROM users WHERE id=?`, [id], function(err) {
if (err) return res.status(500).json({ error: err.message });
res.json({ id });
});
});
// 启动服务器
app.listen(PORT, () => {
console.log(`Server running at http://localhost:${PORT}`);
});到这里,后端已经可以完成完整的 CRUD ✅。
3、搭建前端:React
在根目录创建 React 项目(使用 Vite 更轻量):
bash
npm create vite@latest frontend -- --template react
cd frontend
npm install启动前端:
bash
npm run dev前端默认在
http://localhost:5173
4、前端实现用户管理
修改 frontend/src/App.jsx:
cpp
import { useEffect, useState } from 'react';
function App() {
const [users, setUsers] = useState([]);
const [name, setName] = useState('');
const [editId, setEditId] = useState(null);
const API = 'http://localhost:3000/api/users';
// 获取用户
const fetchUsers = async () => {
const res = await fetch(API);
const data = await res.json();
setUsers(data);
};
useEffect(() => { fetchUsers(); }, []);
// 添加或更新用户
const saveUser = async () => {
if (!name) return alert('请输入名字');
if (editId) {
await fetch(`${API}/${editId}`, {
method: 'PUT',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name })
});
setEditId(null);
} else {
await fetch(API, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name })
});
}
setName('');
fetchUsers();
};
// 删除用户
const deleteUser = async (id) => {
await fetch(`${API}/${id}`, { method: 'DELETE' });
fetchUsers();
};
// 编辑用户
const editUser = (user) => {
setName(user.name);
setEditId(user.id);
};
return (
<div style={{ padding: 20 }}>
<h1>用户管理系统</h1>
<input
value={name}
onChange={e => setName(e.target.value)}
placeholder="输入名字"
/>
<button onClick={saveUser}>{editId ? '更新用户' : '添加用户'}</button>
<ul>
{users.map(u => (
<li key={u.id}>
{u.id}. {u.name}
<button onClick={() => editUser(u)}>编辑</button>
<button onClick={() => deleteUser(u.id)}>删除</button>
</li>
))}
</ul>
</div>
);
}
export default App;5、测试
运行后端:
bash
npm run dev运行前端:
bash
cd frontend
npm run dev打开浏览器 http://localhost:5173,你可以:
- 查看用户列表
- 添加新用户
- 编辑已有用户
- 删除用户
所有数据会保存到 SQLite 数据库 users.db。
6、最终目录结构
cpp
my-fullstack-app/
├─ index.js # 后端
├─ package.json
├─ users.db # SQLite 数据库
├─ frontend/ # React 前端
│ ├─ index.html
│ ├─ src/
│ │ ├─ App.jsx
│ │ └─ main.jsx
│ └─ package.json
└─ ...六、Node.js 性能优化指南(企业级)
1、总体原则(先观测再优化)
- 衡量优先于猜测:先收集指标(延迟、QPS、CPU、内存、事件循环延迟、GC、错误率),再找瓶颈。
- 先解决慢/热路径:优化 hot path(高频、耗时的代码)比无差别微优化更有效。
- 分而治之:把系统拆成可独立测量的组件(API、DB、外部依赖、缓存)。
- 渐进式变更 + 回滚:小步快跑、A/B 测试、灰度发布。
- 自动化与可观测性:所有优化前后都要有可量化的指标证明。
2、必须搭建的观测与诊断体系(工具与指标)
指标(最低要有):
- 吞吐(QPS)
- 平均/95/99 P95/P99 响应时间
- 错误率(4xx/5xx)
- CPU/内存/线程数
- 事件循环延迟(event loop lag)
GC 时间与频率:
- 链路追踪(分布式追踪:latency per call)
建议工具:
- APM/Tracing:OpenTelemetry / Jaeger / Zipkin / Datadog / NewRelic
- Profiling:Clinic.js(doctor/ flame/ bubbleprof)、0x、node --inspect、Chrome DevTools
- Flamegraph:0x / Linux perf -> flamegraph.pl
- Live metrics:Prometheus + Grafana(event loop lag、heap、file descriptors)
- Logs:pino / bunyan(结构化日志 -> stdout -> log aggregator)
- Load testing:wrk, k6, locust, Artillery
关键命令:
- 事件循环延迟(node 系统包或 perf_hooks):
cpp
const { monitorEventLoopDelay } = require('perf_hooks');
const h = monitorEventLoopDelay({ resolution: 10 });
h.enable();
// later: h.mean, h.max- 启动带 inspector:node --inspect app.js
- GC 跟踪(排查内存):node --trace-gc --trace-gc-verbose app.js
3、定位瓶颈(诊断流程)
- 用负载测试重现问题(在测试环境)。
- 监控指标,确认是 CPU-bound 还是 I/O-bound:
- CPU-bound:CPU 占用接近 100%,事件循环延迟明显上升。
- I/O-bound:CPU 空闲、外部依赖(DB/HTTP)延迟高。
- 采样/火焰图定位热点(Clinic/0x)。
- 分析 GC 日志(是否频繁 full GC、内存抖动)。
- 检查同步阻塞调用(fs.readFileSync、加密的同步 API、JSON 序列化大量数据)。
- 检查线程池耗尽(默认 UV_THREADPOOL_SIZE=4)。
4、代码级优化(高影响项)
(1)、避免阻塞事件循环
- 绝对避免同步 I/O(*Sync API)和长时间同步计算。
- 切割大任务:批处理、分片、使用 setImmediate / process.nextTick 谨慎调度微任务。
- CPU 密集任务 -> 使用 worker_threads 或子进程(child_process/fork)。
示例:worker_threads
cpp
// main.js
const { Worker } = require('worker_threads');
function runTask(data) {
return new Promise((resolve, reject) => {
const w = new Worker('./worker.js', { workerData: data });
w.on('message', resolve);
w.on('error', reject);
});
}(2)、使用流(Streams)与 backpressure
- 处理大文件/大数据应使用 stream 而非一次性读入内存。
- 使用 stream.pipeline() 以自动处理错误和销毁。
cpp
const { pipeline } = require('stream');
pipeline(fs.createReadStream(src), zlib.createGzip(), fs.createWriteStream(dest), err => {});(3)、减少对象分配与内存抖动
- 避免在热路径频繁创建对象、字符串拼接(use template literals carefully)。
- 复用 Buffer(Buffer.allocUnsafe 当心安全)或对象池(connection pooling、buffer pool)。
(4)、优化 JSON 序列化
- 大量数据传输时,避免 JSON.stringify 在主线程阻塞。可考虑流式 JSON 序列化(例如 JSONStream)。
(5)、避免不必要的同步加解密
- 加密/哈希/压缩放到线程池或 worker 里。对 PBKDF2 等是关键。
(6)、智能缓存(本地 & 分布式)
- 缓存热点数据(in-memory LRU,如 lru-cache)和分布式缓存(Redis)。
- 缓存策略:TTL、主动失效、缓存穿透防护(加互斥锁或空结果缓存)。
(7)、连接池与并发限制
- 数据库使用连接池(配置合适大小)。
- 限制外部服务并发(semaphore / p-limit)以防止雪崩。
5、运行时调优(Node 级别参数)
(1)、NODE_ENV
bash
export NODE_ENV=production禁用 dev-only 功能(额外日志、热重载),影响性能。
(2)、GC 与堆大小
- 设置最大堆:--max-old-space-size=2048(MB)
- 调试 GC:--trace-gc --trace-gc-verbose
生产中,避免设置过大内存导致 OOM killer 或长 GC 暂停,监测并调整。
(3)、UV_THREADPOOL_SIZE
- 默认 4。若应用大量 fs/crypto/zlib 调用,增大到 16 或 32(取决于 CPU & workload)。
bash
UV_THREADPOOL_SIZE=16 node app.js(4)、启用并限制抓取
- 开启 --enable-source-maps 与 --perf-basic-prof 只在需要时使用(调试)。
6、多核与可靠扩缩(进程/线程层)
(1)、Cluster / PM2 / Process Manager
使用 cluster 或 PM2 cluster mode 启用多进程,利用所有 CPU 核心。
cpp
// 简单 cluster
const cluster = require('cluster');
if (cluster.isMaster) {
const cpus = require('os').cpus().length;
for (let i=0;i<cpus;i++) cluster.fork();
} else {
require('./app');
}PM2 更方便:pm2 start app.js -i max
(2)、Worker Threads(处理 CPU 密集)
对于 CPU 密集任务,优先 worker_threads,比 cluster 更轻量、共享内存(SharedArrayBuffer)。
(3)、分布式扩缩
在 Kubernetes 上用 Horizontal Pod Autoscaler,根据 CPU 或自定义指标(请求延迟)扩容。注意避免过短的探针/扩缩轮询导致抖动。
7、I/O 与外部依赖优化
(1)、DB 优化
- 使用索引、合理 SQL、分页(limit/offset -> cursor)
- 使用 prepared statements / ORM batch
- 连接池配置(大小依据 R/W 并发、DB 能力)
(2)、网络请求
- 使用 keep-alive 复用 TCP 连接(HTTP/1.1 Keep-Alive 或 HTTP/2)。
- 对外 HTTP 客户端设置连接池(axios/http.Agent)。
cpp
const http = require('http');
const agent = new http.Agent({ keepAlive: true, maxSockets: 100 });- 使用短超时、防止长尾慢请求占用资源。
(3)、使用 CDN 与边缘缓存
- 静态内容放 CDN(减少 Node 负载)。
- SSR 或动态内容考虑边缘计算(Cloudflare Workers / Vercel Edge)。
8、网络层优化(Nginx / Proxy)
- 在 Node 前放 Nginx 做 TLS 终端、静态缓存、负载均衡、gzip/brotli 和健康检查。示例 Nginx snippet:
cpp
server {
listen 443 ssl;
gzip on;
gzip_types text/plain application/json text/css application/javascript;
location / {
proxy_set_header Connection "";
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://node_upstream;
proxy_cache_bypass $http_upgrade;
}
}- 配置 proxy_buffering on/off 根据响应大小调整。
9、安全与稳定性(影响性能的非功能项)
- Rate limiting(限流):防止 DoS,使用 rate-limit 中间件或 API Gateway。
- 故障隔离:对外调用使用熔断器(circuit breaker,如 opossum)。
- 重试策略:有指数退避,避免雪崩。
- 超时设置:DB、HTTP 客户端、内部调用都应设超时。
10、容器化与 K8s 实践
Docker 最佳实践(减小镜像与启动时间):
- 基于 node:18-alpine / node:20-bullseye-slim 选择,使用多阶段构建。
- 非 root 运行,最小化依赖,使用 npm ci --production.
- 预热依赖(build 阶段)并在运行时只复制产物。
示例 Dockerfile:
bash
FROM node:20-bullseye-slim AS builder
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
FROM node:20-bullseye-slim
WORKDIR /app
COPY --from=builder /app/dist ./dist
COPY package*.json ./
RUN npm ci --production
USER node
CMD ["node", "dist/index.js"]K8s 注意:
- 设置资源 requests/limits(CPU & memory)。防止 OOM/Killed。
- readiness/liveness probes(HTTP endpoints)。
- 使用 PodDisruptionBudget、合理滚动升级策略。
- 使用 Vertical Pod Autoscaler + HPA 基于自定义指标(比如平均响应时间)。
11、日志、指标与可观测性实践
- 结构化日志(JSON),异步写 stdout,配合 ELK/EFK。
- 日志级别分离(error/warn/info/debug),生产默认 info 或 warn。
- 捕获 unhandledRejection 与 uncaughtException:记录并优雅退出(不要继续运行)。
cpp
process.on('unhandledRejection', (r) => {
console.error('Unhandled Rejection', r);
});- 导出 Prometheus 指标:event loop lag、heap usage、GC pause、requests total、latencies。
12、性能测试与回归(CI 集成)
- 在 CI 中加入性能基线测试(使用 k6/wrk),防止 PR 引入回归。
- 每次依赖升级、Node 升级后都跑性能回归。
- 在 Canary/灰度环境先跑真实流量采样。
13、常见场景与解决方案速查表
| 问题 | 可能原因 | 解决建议 |
|---|---|---|
| 高延迟 P95/P99 | 外部 DB 慢 / 队列堆积 | 增加缓存 / 限流 / 异步化 / DB 优化 |
| CPU 飙高 | 同步操作或计算 | 抽离到 worker_threads 或微服务 |
| 内存不断增长 | 内存泄露 / 大对象缓存 | heapdump 分析、避免全局缓存、限制队列长度 |
| 频繁 GC | 堆太大或对象分配过多 | 减少分配、调整 GC 参数、缩小堆 |
| 线程池耗尽 | 大量 fs/crypto/zlib 并发 | 增加 UV_THREADPOOL_SIZE 或拆分任务到 worker |
14、十四、示例监控指标导出(Prometheus 简单实现)
cpp
const client = require('prom-client');
const gauge = new client.Gauge({ name: 'node_event_loop_delay_mean', help: '...' });
const { monitorEventLoopDelay } = require('perf_hooks');
const h = monitorEventLoopDelay();
h.enable();
setInterval(() => gauge.set(h.mean / 1e6), 5000); // ms15、优先级清单(落地执行顺序)
- 建监控与日志(Prometheus + Grafana + structured logs)
- 加入事件循环 & heap 指标采集
- 压测复现问题(k6/wrk),收集 baseline
- 采样分析(Clinic / 0x / flamegraph)定位热点
- 针对热点做代码优化(流、worker、缓存)
- 调整运行时(UV_THREADPOOL_SIZE、--max-old-space-size)
- 部署多进程(cluster/PM2)并做灰度发布
- 持续回归测试 & 自动告警
16、常用命令 & 快速检查清单
- 查看 Node 版本:node -v(尽量用 LTS/Active 支持版本)
- 启用 inspector:node --inspect-brk app.js
- 事件循环延迟(perf_hooks 采样)
- 增加线程池:UV_THREADPOOL_SIZE=16 node app.js
- 限制内存:node --max-old-space-size=2048 app.js
- PM2 多进程:pm2 start app.js -i max
- 压测:wrk -t12 -c400 -d30s http://host:port/path
- 火焰图:clinic flame -- node app.js(clinic 会生成可视化)