玩转 Ollama:手把手教你本地部署开源大模型
在 AI 大模型席卷各行各业的今天,从代码生成到智能对话,大模型已经成为程序员、产品人日常工作的 "标配工具"✨。
但使用 OpenAI、Claude 等闭源大模型时,我们总会面临一个核心痛点:敏感数据要上传到第三方服务器,数据安全和隐私保护如同悬在头顶的 "达摩克利斯之剑"。而 Ollama 的出现,彻底改变了这一现状 ------ 它能让我们把开源大模型部署到本地,既享受 AI 的便捷,又守住数据安全的底线。今天就带大家全面拆解 Ollama,从基础认知到实操实战,玩转本地大模型!
一、什么是 Ollama?🤔
Ollama 并非一款大模型,而是一款「轻量级、易上手的本地大模型部署工具」。它的核心使命是降低开源大模型本地部署的门槛,让非专业运维人员也能轻松把 LLama3、Qwen(千问)、Deepseek 等开源大模型部署到自己的电脑 / 服务器上。
Ollama 的核心特性堪称 "懒人友好":
- 简化部署流程:无需复杂的环境配置、依赖安装,一条命令就能完成模型的拉取和启动;
- 内置标准化 API 服务:启动模型后,默认在 11434 端口提供兼容 OpenAI 接口规范的 API 服务,开发者无需重新适配接口,极大降低开发成本;
- 丰富的模型仓库:内置海量开源大模型,支持按需拉取(
ollama pull 模型名),兼顾轻量化和高性能需求; - 跨平台兼容:支持 Windows、Mac、Linux 等主流系统,无需担心环境适配问题。
简单来说,Ollama 就像 "大模型的本地管家",把复杂的部署、运维、接口适配工作都包揽了,让我们聚焦于使用大模型解决业务问题。
二、大模型分类:闭源 VS 开源🔍
在选择本地部署大模型前,先搞清楚大模型的核心分类 ------ 不是所有大模型都能实现本地部署:
1. 闭源大模型
这类模型由科技巨头开发,仅开放云端调用接口,不对外公开模型权重和源码,典型代表有:OpenAI 5.1、Claude(主打代码生成)、Gemini 3.0+、Deepseek 闭源版、Qwen 闭源版。
❌ 不支持本地部署的核心原因:厂商出于商业保护、技术壁垒、算力管控等考虑,不开放模型的核心权重文件,所有请求必须通过厂商的云端服务器处理,数据也会经过第三方服务器流转。
2. 开源大模型
这类模型开放权重文件和源码,支持开发者自行下载、部署和二次开发,典型代表有:LLama3(羊驼)、Deepseek 开源版、Qwen(千问)开源版。✅ 支持本地部署的核心原因:模型权重和部署方案完全公开,开发者可将模型下载到本地,借助 Ollama 这类工具快速完成部署,所有数据无需对外传输。
三、为什么要将大模型部署到本地?💡
本地部署的核心价值,本质是 "可控性"------ 对数据、成本、使用体验的全面可控:
1. 数据安全与隐私保护(核心诉求)
在 "vibe coding" 时代,程序员常做这些操作:把产品设计稿传给第三方 LLM 生成前端代码、用 Cursor 工具把全量代码上传到云端 AI 平台... 这些操作会让核心代码、设计稿、业务数据等敏感信息对外传输,存在数据泄露、知识产权被盗的巨大风险。而本地部署大模型时,所有数据仅在本地环境流转,完全规避了数据对外暴露的可能,尤其适合 ToB 类 AI 服务场景,从根源上解决数据安全问题。
2. 降低使用成本
- 长期成本优化:闭源大模型按调用量收费,高频使用下成本会持续累积;本地部署只需一次性投入硬件成本(或复用现有设备),后续无额外调用费用;
- 资源复用:可复用本地 / 企业私有服务器的算力资源,无需为云端调用单独付费,中小团队性价比拉满。
3. 使用稳定性
本地部署的大模型完全无网络依赖,哪怕断网、云端服务宕机,也能正常使用;而云端调用受网络波动、厂商服务限流影响,偶尔会出现响应慢、调用失败的情况。
4. 与云端部署对比
云端部署的优势是无需维护硬件、开箱即用,但缺点明显:算力成本高、数据传输有泄露风险、受厂商规则限制(比如调用限额);本地部署虽然需要考虑硬件适配,但胜在数据可控、成本更低、使用更稳定,尤其适合对数据安全要求高的企业 / 个人。
四、将大模型部署到本地需要考量到哪些因素?📝
本地部署不是 "下载即用",需要提前评估这些关键因素:
- 硬件资源(核心):开源大模型对 GPU / 内存有明确要求,模型参数规模越大,需要的算力越高。比如轻量化的 Qwen2.5:0.5b(0.5B 参数),普通办公电脑也能运行;而 LLama3 70B 这类大参数模型,需要高性能独立 GPU(如 NVIDIA A100)支撑。
- 模型参数规模:参数规模决定了模型的体积和性能 ------ 小参数模型(如 0.5B、7B)轻量化、启动快、硬件要求低,适合入门 / 简单对话场景;大参数模型(如 70B、176B)理解能力、生成能力更强,但部署门槛高、启动慢。
- 模型功能适配:不同模型的擅长领域不同,比如 Deepseek 适合代码生成、Qwen 千问适合中文对话、LLama3 适合多语言交互,需根据业务场景选择,避免 "大材小用" 或 "小材大用"。
- 部署环境:是部署在个人电脑还是企业私有服务器?个人电脑适合轻量使用、本地调试;服务器适合团队共享、高并发场景,需提前规划硬件和网络环境。
五、Ollama 实操:从下载到启动🚗
接下来是实操环节,一步一步带你搞定 Ollama 的基础使用:
1. 下载 Ollama
访问 Ollama 官网(https://ollama.com/),根据自己的系统(Windows/Mac/Linux)下载安装包,默认路径安装即可(无需手动配置环境变量)。验证是否安装成功:打开 CMD / 终端,输入「ollama --version」,如果输出 Ollama 的版本号(如ollama version 0.1.48),就说明安装成功啦!
2. 选择大模型
Ollama 仓库内置海量开源大模型,选择时重点关注三点:
- 模型版本:优先选新版本(如 Qwen2.5、LLama3.1),新版本通常修复了 BUG、提升了响应速度;
- 模型参数规模:入门首选小参数(如 qwen2.5:0.5b),避免硬件扛不住;
- 功能适配:代码生成选 Deepseek,日常对话选 Qwen/LLama3。
3. 拉取大模型到本地
命令:「ollama pull 大模型名称」,比如拉取轻量化千问模型:「ollama pull qwen2.5:0.5b」。这个过程会自动下载模型权重文件,耐心等待即可(小参数模型下载速度很快,通常几分钟完成)。
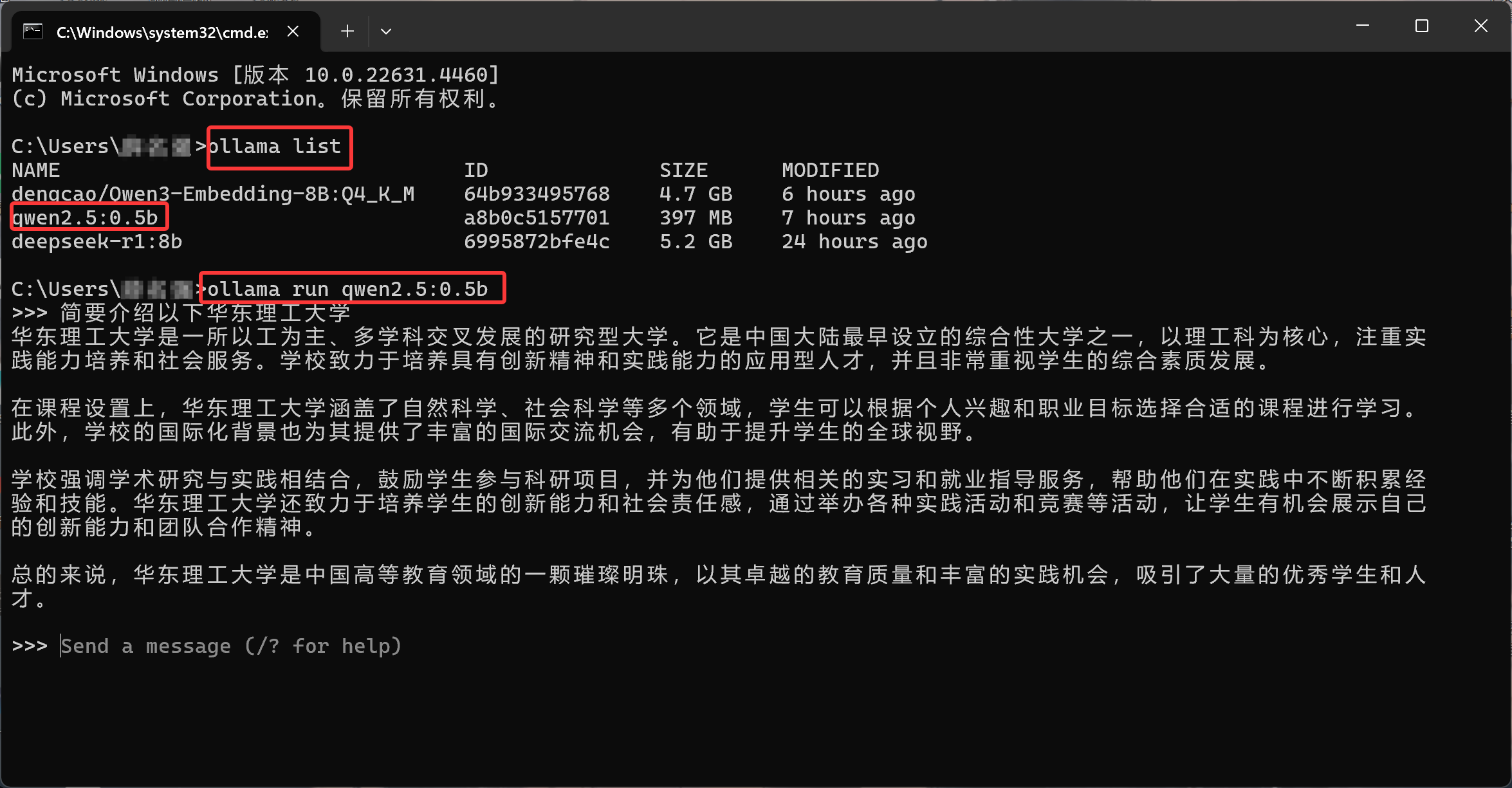
4. 查询本地已部署模型
命令:「ollama list」,终端会列出所有已拉取的本地模型(包括模型名称、ID、大小),方便管理和排查问题。
5. 启动本地模型
命令:「ollama run 大模型名称」(如ollama run qwen2.5:0.5b)。启动后,Ollama 会自动在 11434 端口启动 API 服务 ------ 这是后续调用模型的核心入口,切记这个端口号!
六、实战:用 JS 实现简单的 Chat 交互💻
光说不练假把式,接下来用 JavaScript 写一个简单的聊天程序,调用本地部署的 Qwen2.5 模型,实现智能对话。
1. 用到的大模型:qwen2.5:0.5b
这是千问 2.5 的轻量化版本,仅 0.5B 参数,普通电脑轻松运行,是入门实战的最佳选择。
2. 项目简述
工具:VSCode 编辑器;
开发语言:JavaScript;
核心逻辑:通过 fetch API 调用 Ollama 的 11434 端口 API,实现和本地大模型的聊天交互。
3. 初始化项目
打开 VSCode,新建文件夹(比如demo),终端输入「npm init -y」,快速初始化一个 Node.js 项目(自动生成 package.json 文件,无需手动配置)。
4. 核心代码
新建2.js文件,写入以下代码:
javascript
/**
* 核心功能:调用本地Ollama部署的开源大模型API,实现聊天交互
* Ollama默认在11434端口提供开源大模型的API服务,且兼容OpenAI的接口规范
*/
// 定义Ollama的聊天接口地址,路径v1/chat/completions与OpenAI接口保持一致,降低适配成本
const OLLAMA_URL = 'http://localhost:11434/v1/chat/completions';
// 配置请求头,满足API接口的认证和数据格式要求
const headers = {
// Ollama的认证令牌,固定为Bearer ollama(Ollama默认的认证方式)
'Authorization': 'Bearer ollama',
// 指定请求体的数据格式为JSON,确保服务端能正确解析
'Content-Type': 'application/json',
}
// 构造接口请求体数据,符合OpenAI兼容的聊天接口规范
const data = {
// 指定要调用的本地大模型名称,qwen2.5:0.5b表示千问2.5的0.5B参数轻量化版本
model: 'qwen2.5:0.5b',
// 对话消息列表,数组形式存储多轮对话(此处为单轮用户提问)
messages: [
{
// 消息角色:user表示这是用户发送的消息(其他可选值:assistant-助手回复、system-系统指令)
role: 'user',
// 具体的用户提问内容,此处为示例问题:"你好,威海的海浪漫吗?"
content: '你好,威海的海浪漫吗?'
}
]
}
// 使用fetch API发起POST请求,调用Ollama本地大模型接口
fetch(OLLAMA_URL, {
// 请求方法:POST(聊天接口要求使用POST方式提交数据)
method: 'POST',
// 携带预定义的请求头
headers,
// 将请求体对象转换为JSON字符串(因为HTTP请求只能传输字符串)
body: JSON.stringify(data),
})
// 第一步:处理响应,将返回的Response对象解析为JSON格式(异步操作)
.then(res => res.json())
// 第二步:处理解析后的JSON响应数据
.then(data => {
// 打印大模型的回复结果
// data.choices[0]表示第一个回复选项(Ollama默认返回一个选项)
// message是回复的核心内容,包含role(assistant)和content(回复文本)
console.log('大模型回复:', data.choices[0].message);
})
// 捕获请求过程中的所有异常(如网络错误、接口报错、解析失败等)
.catch(err => {
// 打印错误信息,便于调试和问题定位
console.error('请求失败:', err);
});5. 代码详细讲解
- 接口地址设计:
OLLAMA_URL指定为http://localhost:11434/v1/chat/completions,① localhost是本地部署,数据安全;② 11434 是 Ollama 官方默认端口;③/v1/chat/completions接口路径对齐 OpenAI 行业标准,降低适配成本,同时也是 Ollama 聊天功能的专属路径。 - 请求头配置:
Authorization固定为Bearer ollama(Ollama 默认的认证方式,无需额外配置密钥),Content-Type指定为application/json,确保服务端能正确解析 JSON 格式的请求体; - 请求体设计:
model字段指定要调用的本地模型(qwen2.5:0.5b),messages数组存储对话消息,role: user表示用户提问,content是具体的问题内容; - 请求与响应处理:用 fetch 发起 POST 请求,将请求体转为 JSON 字符串(HTTP 请求仅支持字符串传输);响应后先解析为 JSON 格式,再提取
data.choices[0].message(Ollama 默认只返回一个回复选项),最后打印大模型的回复; - 异常捕获:通过
catch捕获网络错误、接口报错、JSON 解析失败等所有异常,方便调试和问题定位。
6. 项目效果
确保本地 Ollama 已启动 qwen2.5:0.5b 模型(11434 端口正常运行),终端输入「node 2.js」,程序会调用本地大模型接口,控制台会打印出模型的回复(比如:"威海的海真的很浪漫呀~威海的海岸线绵长,海水清澈,傍晚走在金沙滩的海边,吹着温柔的海风,看着落日融进海里,氛围感直接拉满✨..."),至此,本地大模型的调用就完成啦!

七、面试官会问:Ollama 相关高频问题🎯
如果面试中聊到本地大模型部署,这些问题大概率会被问到:
- Ollama 的核心优势是什么?(简化开源大模型部署流程、内置兼容 OpenAI 的 API 服务、跨平台、轻量级);
- 本地部署大模型的核心价值是什么?(数据安全可控、长期使用成本低、无网络依赖、稳定性高);
- Ollama 启动模型后,默认提供 API 服务的端口是多少?(11434);
- 闭源大模型和开源大模型的核心区别?(是否开放模型权重、是否支持本地部署、数据是否对外传输);
- 如何保证本地大模型调用的安全性?(数据本地流转、私有服务器部署、权限管控、定期更新模型版本)。
八、结语🎈
Ollama 的出现,让 "人人都能部署本地大模型" 从口号变成了现实。它不仅解决了闭源大模型的数据安全痛点,还大幅降低了开源大模型的部署门槛 ------ 无论你是个人开发者想体验本地 AI,还是企业团队要搭建安全的 AI 服务,Ollama 都是绝佳选择。
当然,本地大模型部署只是起点,后续还可以根据业务需求优化模型参数、扩展多轮对话、对接前端界面,但只要迈出了第一步,就已经走在了 AI 自主可控的路上。快去下载 Ollama,试试部署自己的第一个本地大模型吧~