
在自然语言处理领域,大规模预训练与指令微调技术已成功构建出具备广泛能力的通用语言模型,但视觉语言领域的通用化探索仍面临严峻挑战。额外的视觉输入带来了丰富的输入分布与任务多样性,使得现有方法难以实现跨任务、跨数据集的高效泛化。Salesforce Research 等机构联合推出的 InstructBLIP 框架,通过系统的视觉语言指令微调研究,为解决这一难题提供了全新方案。
原文链接:https://arxiv.org/pdf/2305.06500
代码链接:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
沐小含将持续分享前沿算法论文,欢迎关注...
1. 研究背景与核心挑战
1.1 视觉语言任务的独特性
与单一文本输入的 NLP 任务不同,视觉语言任务因引入多样化的视觉输入而呈现出更高的复杂性。从图像描述到视频问答,从视觉推理到知识驱动的图像理解,不同任务对视觉特征的需求差异显著,这对模型的通用化能力提出了极高要求。
现有方法主要分为两类:多任务学习 将不同任务统一为相同输入输出格式,但缺乏指令引导导致对未见过的任务泛化能力薄弱;基于预训练语言模型扩展视觉组件的方法,受限于图像描述类训练数据,难以覆盖复杂的视觉语言任务需求。
1.2 指令微调的价值与视觉语言领域的空白
指令微调通过在多样化自然语言指令描述的任务上微调大语言模型,使其具备遵循任意指令的能力,这一技术在 NLP 领域已被证明有效。BLIP-2 作为早期尝试,将冻结的指令微调语言模型适配视觉输入,初步实现了图像到文本生成的指令遵循能力,但未充分挖掘视觉语言指令微调的潜力。此前的视觉语言指令微调研究缺乏系统性,数据覆盖范围有限且模型结构未针对指令感知进行优化,导致通用化性能受限。
2. InstructBLIP 核心框架设计
InstructBLIP 基于 BLIP-2 预训练模型,通过构建大规模视觉语言指令微调数据、设计指令感知的特征提取机制与优化的训练策略,实现了通用视觉语言能力的突破。其核心目标是通过统一的自然语言接口,让模型能够解决各类视觉语言任务。
2.1 模型基础架构
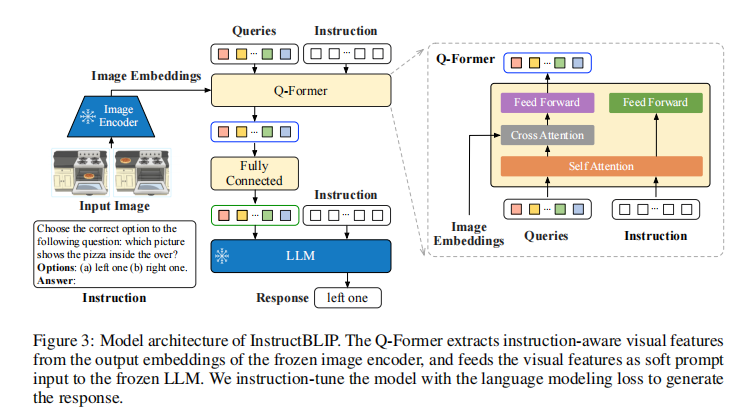
InstructBLIP 继承了 BLIP-2 的模块化设计,主要包含三个核心组件:
- 冻结的图像编码器(ViT-g/14):负责提取图像的底层视觉特征;
- 冻结的大语言模型(LLM):提供强大的语言生成与理解能力,支持 FlanT5(编码器 - 解码器结构)和 Vicuna(仅解码器结构)两个系列;
- 查询转换器(Q-Former):作为图像编码器与语言模型之间的桥梁,通过可学习的查询嵌入提取视觉特征,并将其转换为语言模型可理解的格式。
InstructBLIP 在指令微调阶段仅微调 Q-Former 参数,保持图像编码器与 LLM 冻结,既保证了模型稳定性,又大幅降低了计算成本。
BLIP-2模型解读:BLIP-2:冻结预训练单模态模型的高效跨模态预训练范式-CSDN博客**
2.2 关键技术创新
2.2.1 指令感知的视觉特征提取
现有零样本图像到文本生成方法(包括 BLIP-2)采用指令无关的特征提取方式,无论任务类型如何,均输出固定的视觉表示。InstructBLIP 提出指令感知的 Q-Former 模块,将文本指令同时输入至 Q-Former 与 LLM,使 Q-Former 能够根据指令提取任务相关的视觉特征。
具体实现中,指令文本 tokens 作为额外输入传入 Q-Former,通过自注意力层与查询嵌入交互,引导模型关注与当前指令相关的图像区域。例如,在空间视觉推理任务中,指令可引导 Q-Former 聚焦于物体的位置关系;在视频问答任务中,则优先提取时序相关特征。这一机制使 LLM 获得更具针对性的视觉信息,显著提升指令遵循能力。
2.2.2 平衡的数据集采样策略
由于不同数据集规模差异显著(从数千到数百万样本),若采用均匀采样会导致模型过拟合小规模数据集、欠拟合大规模数据集。InstructBLIP 提出基于数据集大小平方根的采样策略,采样概率计算公式为:,其中
为数据集
的样本数量。
在此基础上,结合任务特性进行手动调整:降低选择题型数据集(如 A-OKVQA)的权重,提高开放式文本生成数据集(如 OKVQA)的权重,确保不同类型任务的均衡学习。
3. 实验设计:数据构建与评估方案
3.1 指令微调数据集构建
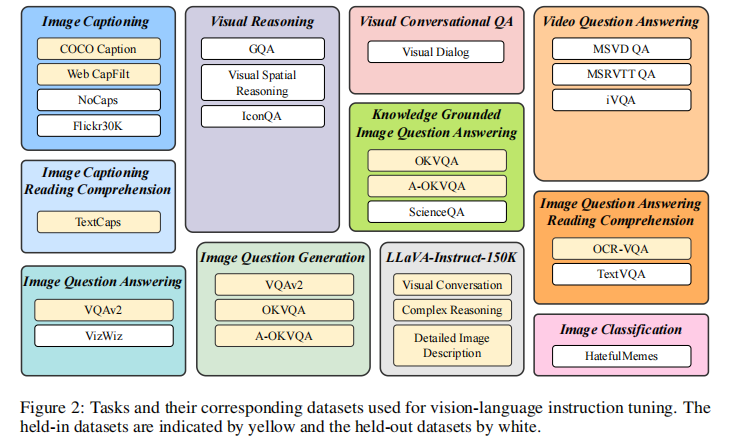
为保证训练数据的多样性与可访问性,InstructBLIP 收集了 26 个公开视觉语言数据集,涵盖 11 个任务类别,具体包括:
- 基础任务:图像描述(COCO Caption、NoCaps 等)、图像问答(VQAv2、GQA 等);
- 复杂任务:视觉推理(ScienceQA、IconQA)、知识驱动图像问答(OKVQA、A-OKVQA)、视频问答(MSVD QA、MSRVTT QA);
- 特殊任务:视觉对话(Visual Dialog)、图像分类(HatefulMemes)、基于 OCR 的问答(TextVQA、OCR-VQA)。
针对每个任务,设计 10-15 个不同的自然语言指令模板,例如图像描述任务的模板包括 "简要描述图像内容""用几句话说明图片中发生的事情" 等。对于短响应倾向的数据集,模板中加入 "简短""简洁" 等词汇,避免模型过度拟合短输出模式。LLaVA-Instruct-150K 数据集因天然具备指令格式,未额外设计模板。
3.2 训练与评估协议
3.2.1 数据集划分
将 26 个数据集分为 13 个训练集(held-in)和 13 个零样本评估集(held-out),其中 4 个任务类别(视觉推理、视频问答、视觉对话、图像分类)完全未参与训练,用于任务级别的零样本评估,确保评估的公平性与泛化能力验证。
3.2.2 训练细节
- 优化目标:采用标准语言建模损失,直接生成指令对应的响应;
- 训练配置:使用 LAVIS 库实现,最大训练步数 60K,每 3K 步验证一次,选择最优 checkpoint 进行评估;
- 批次大小:根据模型规模调整,3B 模型为 192,7B 模型为 128,11/13B 模型为 64;
- 优化器:AdamW,β₁=0.9,β₂=0.999,权重衰减 0.05;
- 学习率策略:初始 1000 步线性预热至 1e-5,随后余弦衰减至 0。
所有模型均在 16 块 Nvidia A100(40G)GPU 上训练,训练周期不超过 1.5 天,兼顾训练效率与性能。
3.2.3 推理方法
针对不同任务类型设计差异化推理策略:
- 生成式任务(图像描述、开放式 VQA):直接生成响应并与真实标签对比计算指标;
- 分类与选择题任务(ScienceQA、IconQA 等):采用词汇排序方法,限制模型生成候选集中的答案,计算每个候选的对数似然并选择最高值;
- 二进制分类任务:扩展正负标签的表述形式(如正类包括 "是""正确",负类包括 "否""错误"),利用自然文本中的词频特性提升性能;
- 视频问答任务:每个视频采样 4 帧,分别提取视觉特征后拼接输入至 LLM。
4. 核心实验结果与分析
4.1 零样本性能评估
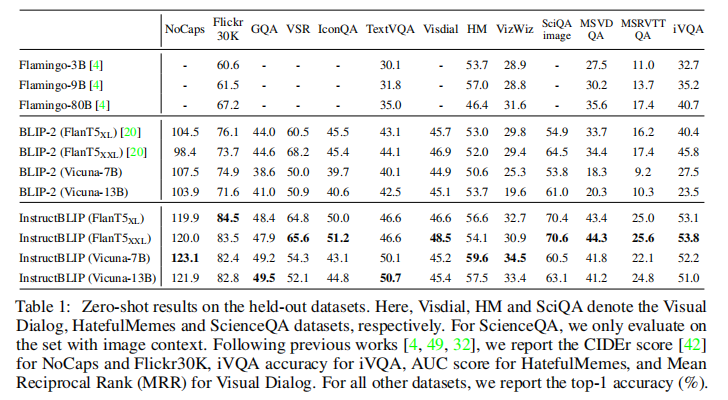
InstructBLIP 在 13 个 held-out 数据集上进行零样本测试,对比现有 SOTA 模型 BLIP-2 与 Flamingo,结果如表 1 所示。
关键结论如下:
- 全数据集 SOTA:InstructBLIP 在所有评估数据集上均实现性能突破,相较于基础模型 BLIP-2,各版本均取得显著提升。例如 InstructBLIP(FlanT5 XL)相较于 BLIP-2(FlanT5 XL)平均相对提升 15.0%;
- 跨任务泛化能力:在完全未训练过的任务类别上表现优异,如视频问答任务 MSRVTT-QA 中,相对提升高达 47.1%,即使未使用任何时序视频训练数据;
- 模型效率优势:最小的 InstructBLIP(FlanT5 XL,4B 参数)在 6 个共享评估数据集上全面超越 80B 参数的 Flamingo 模型,平均相对提升 24.8%,展现出高效的模型设计;
- 任务适配性:在 Visual Dialog 数据集上采用 MRR 指标替代 NDCG,因 MRR 更偏好明确响应,更符合零样本评估场景,结果显示 InstructBLIP 的响应质量更优。
4.2 消融实验:关键技术有效性验证
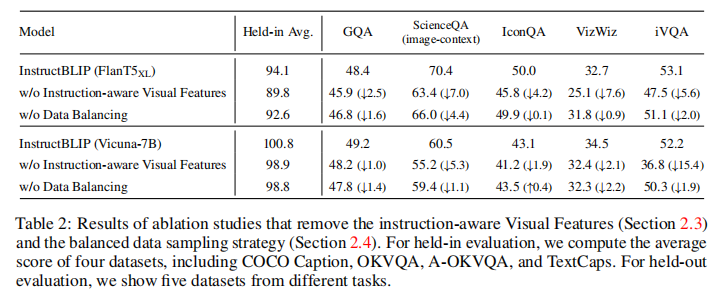
为验证指令感知视觉特征提取与平衡数据集采样策略的有效性,进行消融实验,结果如表 2 所示。
4.2.1 指令感知特征提取的影响
移除指令感知机制后,所有数据集性能均显著下降,其中空间视觉推理(ScienceQA)和时序视觉推理(iVQA)任务降幅最大,分别达 7.0 和 5.6 个百分点。这表明指令输入能够引导 Q-Former 聚焦于任务相关的图像区域,对复杂推理任务至关重要。
4.2.2 平衡采样策略的影响
取消数据平衡后,模型训练稳定性下降,不同数据集在不同训练步数达到性能峰值,导致整体性能受损。例如 ScienceQA 任务性能下降 4.4 个百分点,验证了平衡采样对多数据集联合训练的重要性。
4.3 定性评估:模型能力可视化
通过多样化图像与指令的测试,InstructBLIP 展现出全面的视觉语言能力(如图 1 所示):

- 复杂视觉推理:能够基于图像场景进行合理推断,如从棕榈树等视觉线索判断灾害发生区域为热带地区;
- 知识驱动描述:将视觉输入与文本知识结合,如准确介绍《戴珍珠耳环的少女》的作者、创作年代等背景信息;
- 隐喻理解能力:在图像描述中能够捕捉视觉意象的隐喻含义,如将 "跨越门槛进入太空" 解读为 "走出舒适区开启新冒险";
- 多轮对话能力:能够结合对话历史生成连贯响应,如基于蔬菜食材图像生成沙拉制作步骤,并支持多轮追问交互。
与同期多模态模型(GPT-4、LLaVA、MiniGPT-4)的对比显示,InstructBLIP 的输出更具视觉 grounding、逻辑更连贯,且能根据指令自适应调整响应长度,避免冗余信息(如图 5-7 所示,注:图表后续补充)。例如在 "这幅画的作者是谁?" 的查询中,InstructBLIP 直接给出 "达芬奇" 的精准答案,而其他模型生成冗长但相关性较低的内容。
4.4 下游任务微调性能
将 InstructBLIP 作为初始化模型,在特定下游数据集上微调,结果如表 3 所示。

关键发现:
- 初始化优势:InstructBLIP 作为预训练初始化模型,在所有下游数据集上均优于 BLIP-2 微调结果,验证了其作为通用模型的潜力;
- 新 SOTA 突破:在 ScienceQA(图像上下文)、OCR-VQA、A-OKVQA 三个数据集上刷新 SOTA,仅在 OKVQA 上略逊于 562B 参数的 PaLM-E;
- 模型特性适配:FlanT5 系列更擅长选择题型任务,Vicuna 系列在开放式生成任务中表现更优,这与两者的指令微调数据特性相关 ------FlanT5 基于多选择 QA 数据集微调,Vicuna 则聚焦于开放式指令遵循。
4.5 指令微调与多任务学习对比
为明确指令微调的核心价值,对比指令微调与多任务学习的性能差异,结果如图 4 所示。
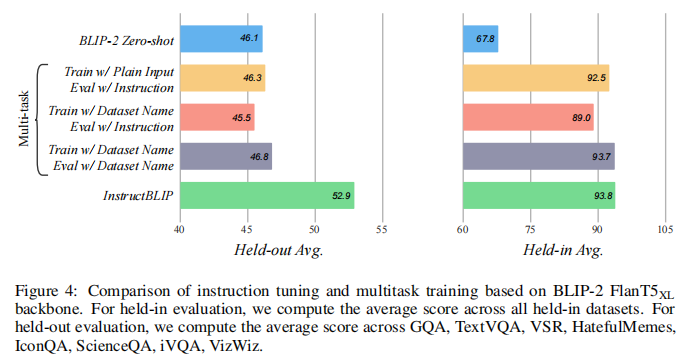
两种多任务学习方案:
- 方案 1:使用数据集原始输入输出格式训练,评估时提供指令;
- 方案 2:训练时添加 任务:数据集 标识符,评估时使用指令或标识符。
结果显示:
- held-in 数据集上:指令微调与多任务学习性能相近,表明模型对不同输入格式的适配能力;
- held-out 数据集上:指令微调性能显著优于多任务学习,后者与原始 BLIP-2 表现相当,证明指令微调是提升零样本泛化能力的关键。
5. 相关工作与对比
5.1 指令微调研究脉络
NLP 领域的指令微调技术主要分为两类:基于模板将现有数据集转换为指令格式,或利用 LLM 生成多样化指令数据。在视觉语言领域,现有方法存在明显局限:
- BLIP-2:仅将 LLM 适配视觉输入,缺乏系统的指令微调;
- MiniGPT-4:使用 ChatGPT 生成的长文本描述训练,数据类型单一;
- LLaVA:直接将视觉编码器输出投影至 LLM 输入空间,微调 LLM;
- mPLUG-owl:采用低秩适配(LoRA)技术,指令数据覆盖有限;
- MultiInstruct:未使用预训练 LLM,性能竞争力不足。
5.2 InstructBLIP 的核心优势
与现有方法相比,InstructBLIP 的创新点体现在:
- 多样化指令数据:融合模板转换数据与 LLM 生成数据,覆盖 11 个任务类别 26 个数据集;
- 指令感知架构:提出 Q-Former 指令交互机制,实现任务自适应的视觉特征提取;
- 系统全面评估:从零样本泛化、下游微调、定性分析多维度验证模型能力,为视觉语言指令微调提供基准。
6. 研究局限与未来方向
6.1 现有局限
- 继承 LLM 缺陷:因使用冻结 LLM,仍存在幻觉生成、偏见输出等问题;
- 安全评估不足:未针对特定下游应用进行安全与公平性评估,实际部署需额外验证;
- 复杂视频处理:视频问答仅采用多帧拼接方式,未充分利用时序信息。
6.2 未来探索方向
- 多模态指令数据扩展:纳入更多模态(如音频)与更复杂任务场景;
- 模型压缩与高效部署:进一步优化 Q-Former 结构,降低推理延迟;
- 安全对齐技术:结合视觉 grounding 增强输出可靠性,减少偏见与幻觉。
7. 结论
InstructBLIP 通过系统的视觉语言指令微调研究,构建了具备强大通用能力的视觉语言模型。其核心创新包括:大规模多样化指令数据集构建、指令感知的 Q-Former 设计、平衡的多数据集采样策略。实验证明,InstructBLIP 在零样本跨任务泛化、下游任务微调性能上均达到 SOTA 水平,且具备优异的模型效率。
该研究不仅为通用视觉语言模型的构建提供了完整范式,更通过详细的实验分析揭示了指令微调在视觉语言领域的核心价值。开源的 InstructBLIP 系列模型为后续研究提供了重要基础,有望推动多模态 AI 在更广泛实际场景中的应用。