ElevenLabs、HeyGen 等闭源服务已经把跨语言视频翻译 体验推到近乎"完美"级别: 嘴型精准同步、音色自然还原、画面完整不失真,几乎就是工业标准。
但一旦涉及 私有化部署 或 开源落地,现实立刻变得残酷:
- 商用 API 成本高、限制死、可控性差,能选的供应商屈指可数
- 开源生态高度碎片化,各模块效果断层严重,工程链路难以打磨到生产可用
尤其是在「根据音频修改原视频中人物口型 」这一核心能力上几乎是断档: 国内数字人技术生态确实成熟,但那主要是 "给一张照片做口播" 或 "合成虚拟主播" 。 真正需要 "驱动原视频人物的嘴型,与新语音逐帧对齐" 的开放 API 极其稀缺, 目前只有科灵、阿里提供一些基础接口,但限制多、可控性不足,很难在真实业务中使用。
因此,真正的视频翻译绝不只是"ASR → 翻译 → TTS"这么一条三步流水线。 整个难点浓缩成一个词:视听一致性------如何在替换语音后,让原视频人物的嘴型、表情、微动作都与新声音严格同步,并且保持画质不崩。
视听一致性
即更换语音后,如何让 人物的口型、表情、嘴唇动态、头部微动、画质细节 与新语音高度一致,同时不破坏原视频质量。
本文将尝试系统拆解一套 可自部署的完整工程链路,覆盖从音频清洗、声纹聚类、音素级对齐,到口型驱动、画质修复的全流程结构,真正直击视频翻译的"最后一公里"。
一、构建语音克隆所需的高质量参考音频
语音克隆效果的上限,99% 取决于参考音源的质量。 原始互联网视频中的音频几乎必然包含:
- 背景音乐
- 环境噪音
- 房间混响
- 压缩伪影
这些问题不解决,后续 TTS 克隆再强也只能"垃圾进、垃圾出"。
1. 人声分离 + 去混响 ------ 两步缺一不可
(1)人声伴奏分离
推荐方案:UVR5 + MDX-Net 模型族
(2)去混响
只做人声分离是不够的。原视频常会带强烈房间混响,克隆后的语音会出现"电子腔调""浴室音"。
推荐开源方案:DeepFilterNet (github.com/Rikorose/De...)
pyVideoTrans 当前仅使用
UVR-MDX-NET-Voc_FT做人声分离,并未包含去混响环节。
2. VAD → 声纹聚类 → 构建长参考音频
高质量 TTS 通常需要15--60秒连续、干净、同说话人的音频。 但原始字幕切片只有 2--10 秒,而且多说话人视频非常普遍。
- 精准 VAD 切分
- 可用 Silero VAD 或 WhisperX 自带 VAD
- 去掉静音,切成可用语音单元
-
提取声纹嵌入 推荐:
- Pyannote.audio (huggingface.co/pyannote/sp...)
- speechbrain 相关声纹模型 (github.com/speechbrain...)
-
按声纹聚类,区分不同说话人
-
对同说话人的短片段进行拼接 得到连续 30~60 秒的参考音频,用于 TTS 克隆。
pyVideoTrans 当前使用 Silero VAD + 简易声纹区分(eres2net / NeMo titanetsmall),尚未支持同簇片段拼接。
二、语音合成与时域对齐:解决"音画不同步"的根源
语言之间的时长差异是不可避免的。 英文翻译成中文通常会 变长 20--50%,若不处理,会出现:
- 画面还没说完,但音频已经结束
- 口型节奏明显对不上
- 人物张嘴时音频无声,闭嘴时出现语音
行业所有成熟方案都采用 音素级精对齐 + 时长控制 的方式来解决此问题。
1. 音素级强制对齐
普通 Whisper 只有 词级 时间戳,做不了口型驱动。 必须使用能提供 音素级对齐的 ASR。
推荐:WhisperX (github.com/m-bain/whis...)
pyVideoTrans 当前未集成音素级对齐,仍使用普通 Whisper。
2. TTS 等时性控制
想达到工程级控制链至少包括以下三步
(1)翻译阶段限制音节/字数
在 LLM Prompt 中加入:
- 最大音节数
- 对齐原句时长的约束
从源头减少时长偏差。
(2)高自然度语音克隆模型
推荐(中英双语):
- CosyVoice 2.0
- F5-TTS
- Index-TTS2
- Fish-Speech v1.5
特点:自然度高、克隆效果稳定。
(3)精细时域拉伸/压缩(保持音调不变)
使用 rubberband (breakfastquay.com/rubberband/... 将 TTS 输出控制在原视频时长的 0.9×--1.2× 内。
pyVideoTrans 目前仅支持 API 级克隆,未包含完整的音节控制 + 时长控制链路。
三、视觉重构:口型驱动的真正核心与难点
目标非常明确:只动嘴,不动脸。不破坏视频画质
视觉部分的工程量与算力投入在整个链路中是最高的。
1. 时长差异下的视频帧处理策略
| 时长差距 | 推荐处理方式 |
|---|---|
| ≤20% | 音频 rubberband 微调 + FFmpeg setpts 对齐 |
| >20% | 必须插帧,必要时生成静态微动帧 |
推荐开源:
-
RIFE (视频插帧) github.com/hzwer/Pract...
-
Stable Video Diffusion 生成自然的眨眼、轻微头部运动等微动画面
pyVideoTrans 目前只做简单的 setpts 时间拉伸。
2. 多人同框时的"面部锁定"
如果不对人物身份进行绑定,背景人脸会莫名张嘴,视频会直接毁掉。
解决方案:
- 使用 InsightFace 做人脸检测 + 人脸识别 (github.com/deepinsight...
- 将每个说话人的声纹ID与屏幕上的脸ID绑定
- 当前说话人 → 只驱动对应面部区域
- 其他脸保持静止
- 侧脸/遮挡帧自动跳过推理
3. 高保真口型驱动
-
当前开源最优选: MuseTalk(腾讯) 实时推理、唇形自然、牙齿纹理优秀,画质保留好。 github.com/TMElyralab/...
-
次选: VideoReTalking 效果稳定但较慢。 github.com/OpenTalker/...
pyVideoTrans 当前完全没有口型驱动能力。
四、后处理:画质修复与最终合成
口型驱动模型一般只在 96×96 或 128×128 的小区域推理。 直接贴回视频必然产生:
- 嘴部模糊
- 局部马赛克
- 面部细节不完整
必须进行 面部超分辨率。
推荐开源方案流程:
-
GPEN 速度快、面部纹理还原好 github.com/yangxy/GPEN
-
CodeFormer 身份保持极强、可作为补偿阶段 github.com/sczhou/Code...
-
GFPGAN 经典、稳健,可在链路中兜底 github.com/TencentARC/...
最终使用 FFmpeg:
- 合并新音频流
- 合成处理后的视频流
- 插入对齐的字幕
真正工业级的视频翻译链路
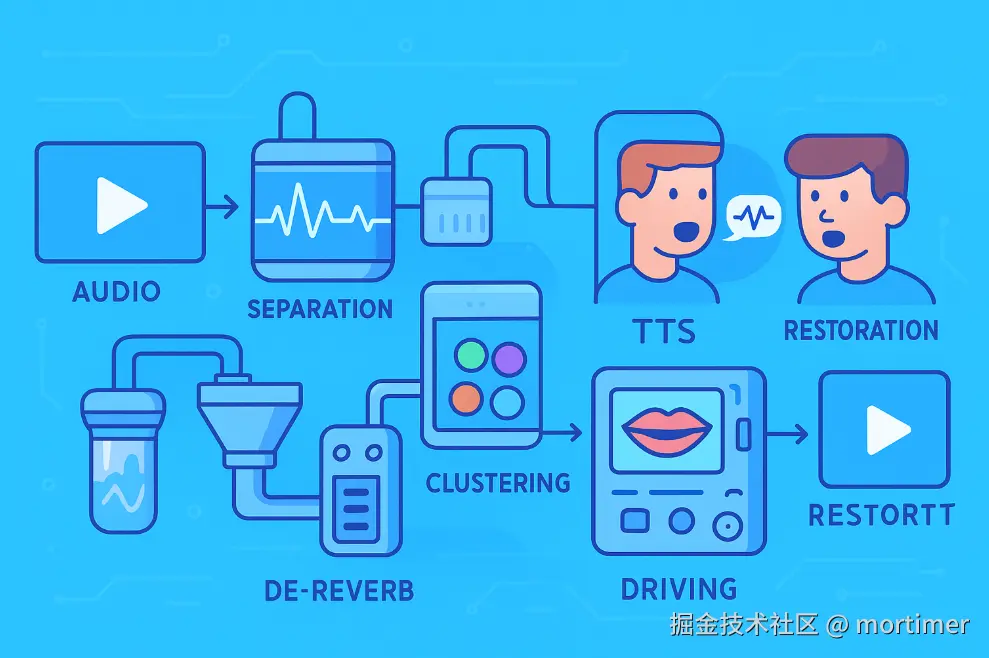
人声分离 → 去混响 → 声纹聚类 → 长参考音频 → 音素级 ASR → 对齐翻译 → 高品质 TTS 克隆 → 时长控制 → 面部识别与锁定 → MuseTalk 驱动 → GPEN/CodeFormer 修复 → FFmpeg 合成
猜测这条链路在结构上应与 ElevenLabs / HeyGen 相差无几,但全部使用开源可自部署模型。
想实现这套流程,显然所需较多的硬件资源,以及不小的技术难度,出于 pyVideoTrans 业余爱好项目的定位,未考虑完整环节, 丢失了 去混响、 声纹聚类与拼接、音素级对齐、 面部锁定、 高保真口型驱动、 面部修复 这些较困难的部分。
真正要破局视频翻译的"最后一公里",必须把上述每一步都补齐------缺一不可。