"这款模型在 Python 错误修复上表现惊艳,但在 Java 功能实现上却惨不忍睹","同一个模型在 Web 开发场景游刃有余,面对基础设施代码却束手无策"------这些开发者社区的常见吐槽,折射出现有代码大模型评估体系的严重局限。关于"谁是最强的代码大模型?"这一问题,答案众说纷纭,对于同一款大模型,对于不同的编程场景、不同编程任务、不同编程语言甚至不同智能体框架其风评都可能大相径庭。然而,现有的基准测试大多数仍然局限于单文件任务、以 Python 为中心的错误修复或合成算法问题,而关键的开发者活动,如功能实现、重构、配置和性能优化,尚未得到充分探索。在这种情况下,开发者们只能亲自测试,难免导致人和代码都变成"喜庆"的颜色。
在激烈的"最强代码模型"争论中,我们急需一个能够真实反映工业级软件开发复杂度的评估基准。近日,快手 KwaiKAT 团队与南京大学刘佳恒老师 NJU-LINK 合作推出 SWE-Compass ------一个涵盖 8 大任务类型、8 大编程场景、10 种编程语言的代码智能统一评估框架,它包含 2000 个高质量实例,在任务类别、编程场景和语言方面实现了良好的平衡,为评估大型语言模型在实际软件工程任务中的能力提供了一个严格且具有代表性的评估框架。

一、破局之作:为什么是 SWE-Compass?
当前代码大模型的评估生态存在三大核心痛点:任务覆盖狭窄 、语言偏见严重 、与真实开发流程脱节。主流基准如 HumanEval、MBPP 等专注于算法题求解,SWE-Bench 系列虽转向仓库级评估,但仍过度聚焦于 Python 语言的错误修复任务。评估广度的缺乏,导致模型在特定任务上的优异表现被过度放大,却无法回答一个关键问题:它能否真正胜任多元化的工业级开发需求?
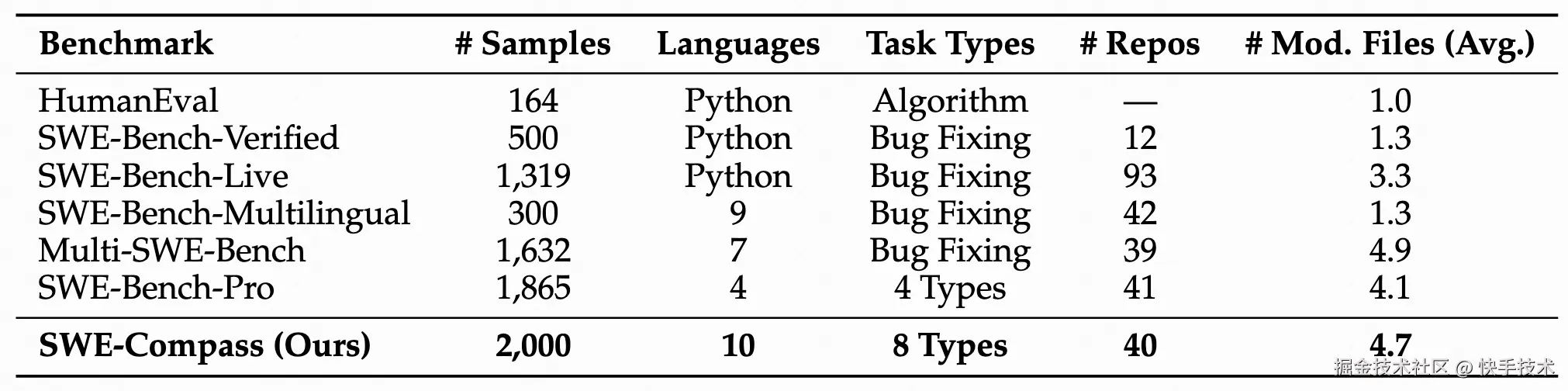
表 1:SWE-Compass 与现有基准测试在不同维度上的综合比较
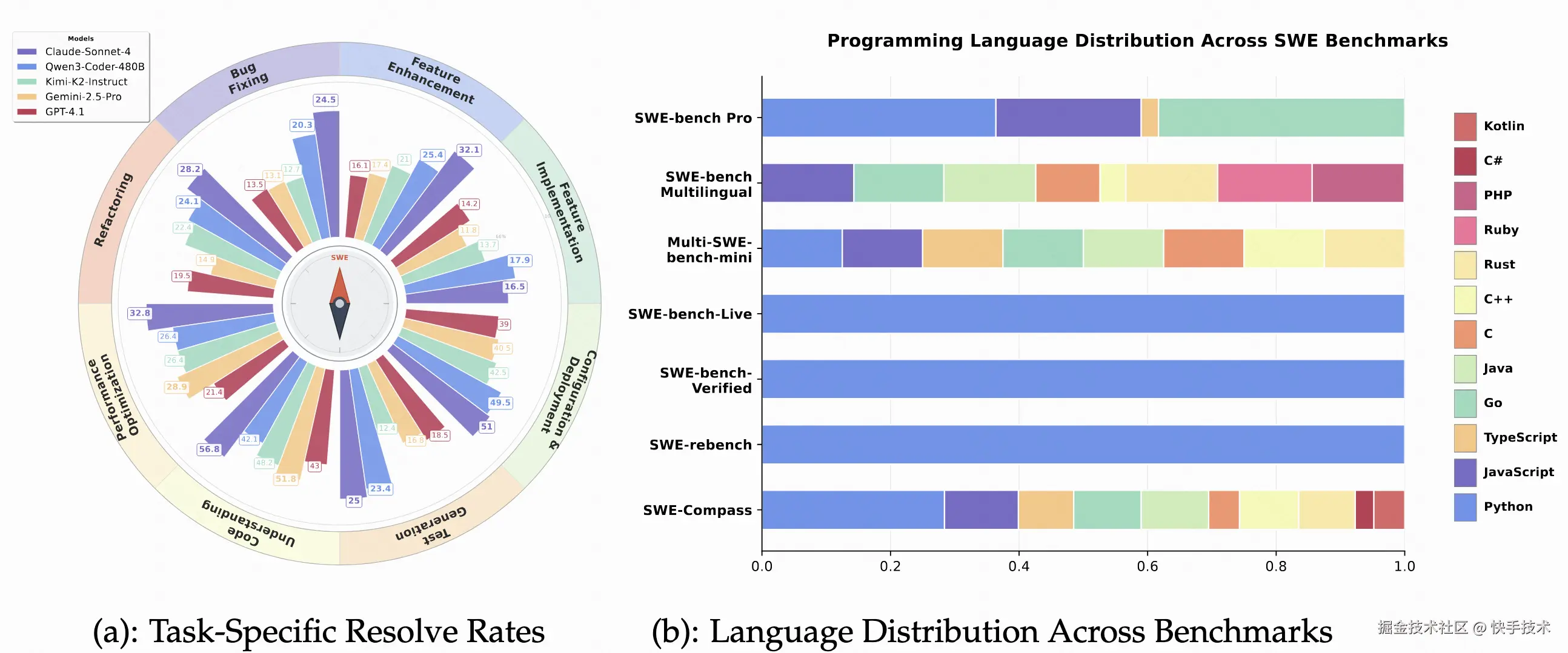
图 2: 比较分析:跨任务类型的模型性能(a)和跨基准测试的语言覆盖范围(b)
SWE-Compass 的诞生正是为了解决这一困境。研究团队通过分析海量 GitHub 讨论和 Stack Overflow 问题,首次构建了覆盖软件工程全生命周期的三维评估体系:
-
8 大任务类型:从基础的功能实现(FI)、错误修复(BF)到高阶的代码理解(CU)、性能优化(PO)
-
8 大编程场景:涵盖应用开发(AD)、数据科学(DE)、机器学习(ML)、基础设施(ID)等关键领域
-
10 种编程语言:除 Python / Java / JavaScript 等主流语言外,更纳入 Rust / Go / Kotlin 等新兴语言
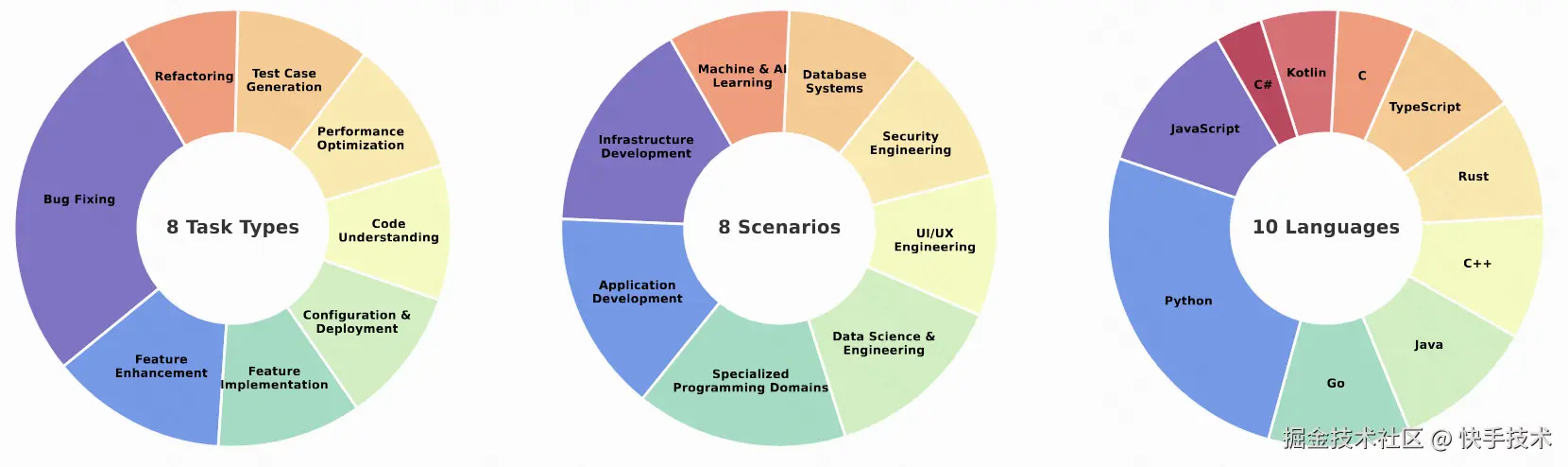
图 3: 任务类型、编程场景和语言的分布
二、匠心设计:如何构建真实可信的评估基准?
SWE-Compass 的构建过程堪称工程与学术的完美结合。研究团队采用五阶段流水线,确保每个实例都具备可执行性和可验证性:
-
阶段 1:需求挖掘通过主动学习框架分析开发者讨论,迭代优化标签体系。使用 Qwen3-Coder-30B 模型进行多轮标注,最终确定 8 类任务、8 类场景和 10 种语言的分类框架。
-
阶段 2:数据筛选从 GitHub 精选 50000 个高质量 PR,筛选标准包括:项目星标≥500、近半年活跃、含完整测试套件等。每个 PR 需关联具体 Issue 、包含代码补丁和测试补丁。
-
阶段 3:环境构建最挑战的环节在于创建可复现的 Docker 环境。初始构建成功率仅 2%,经 30 位专家逐条修复依赖冲突后,最终获得 4000 个可运行环境,留存率提升至 8%。
-
阶段 4:任务合成针对不同任务类型采用差异化策略:
-
代码理解任务:通过 GPT-5 生成带检查清单的推理问题
-
测试生成任务:采用反向掩码技术构造不完整测试用例
-
性能优化任务:筛选实际提升 30%以上性能的 PR 案例
-
阶段 5:质量验证通过难度过滤、平衡采样和人工验证三重保障,最终形成 2000 个高质量实例。如图 3 所示,整个构建过程体现了系统工程般的严谨性。
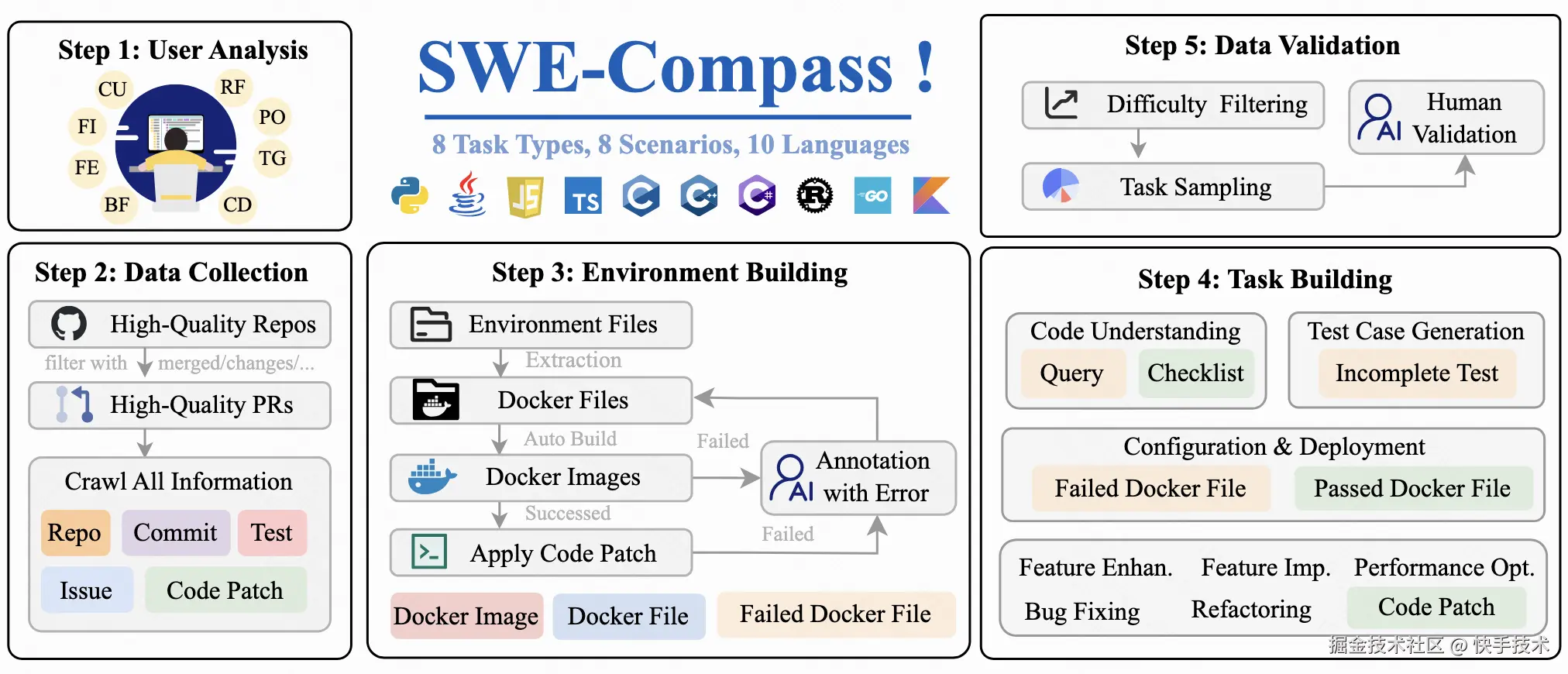
图 4: SWE-Compass 的构建流程图
三、巅峰对决:十款顶尖模型的全方位比拼
研究团队在 SWE-Agent 和 Claude Code 两种主流智能体框架下,对 10 款前沿模型进行严格测试,包括 Claude-Sonnet-4、Qwen3-Coder 系列、GPT-4.1、Gemini-2.5 等明星模型。
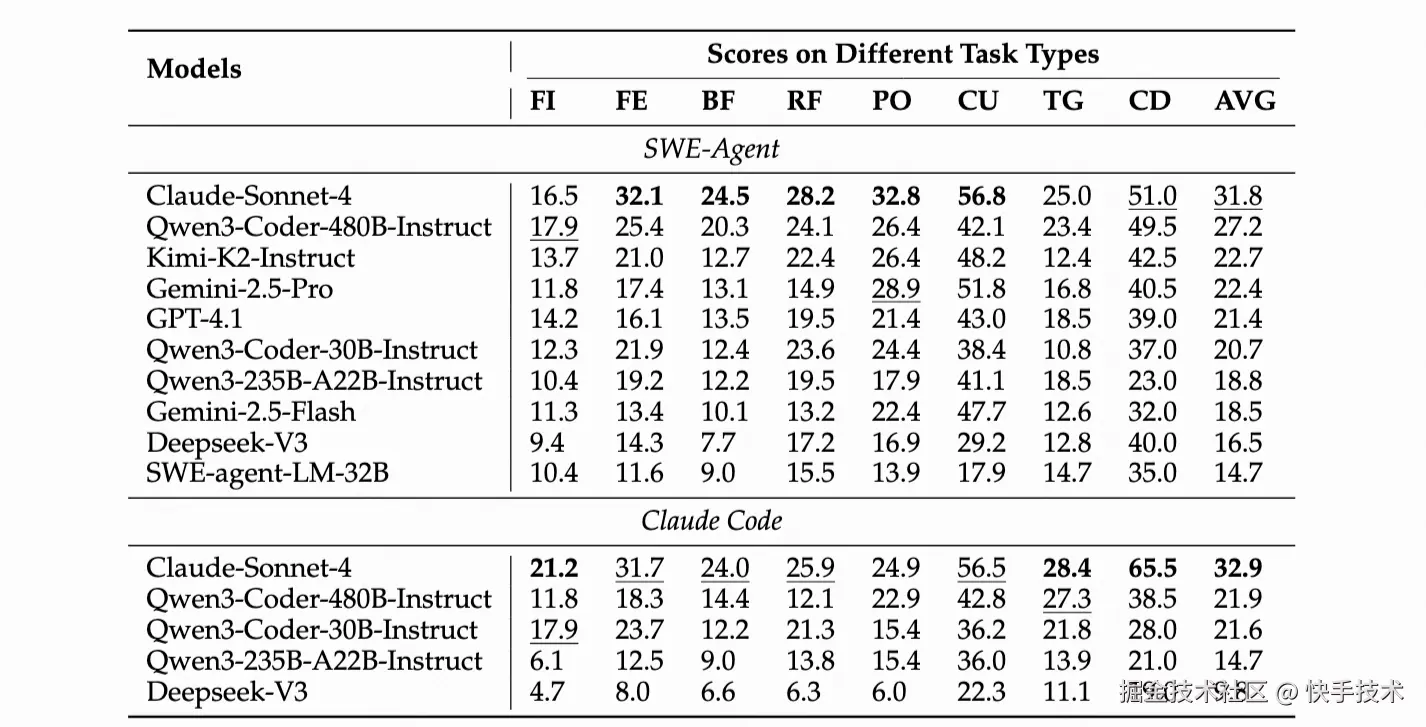
表 5: SWE-Compass 上按任务类型的主要结果。AVG 是跨任务类型的宏观平均值。缩写:FI=功能实现;FE=功能增强;BF=错误修复;RF=重构;PO=性能优化;CU=代码理解;TG=测试用例生成;CD=配置与部署。
核心发现 1:任务难度分层明显如上表所示,所有模型在代码理解(CU)和配置部署(CD)任务上表现最佳,平均通过率超 40%。而功能实现(FI)和错误修复(BF)成为最大挑战,凸显了模型在代码定位和集成方面的短板。特别值得注意的是,性能优化(PO)和测试生成(TG)任务虽难度较高,但部分模型仍能达到 20%以上的通过率,展现出了潜力。
核心发现 2:智能体框架各有千秋 Claude Code 在配置部署等确定性任务上优势明显,而 SWE-Agent 在复杂定位任务中表现更稳健。SWE-Compass 揭示了这种互补性:没有万能的最优框架,只有最适合特定场景的工具链。为开发者选择智能体框架提供了指南。
核心发现 3:语言生态差异显著如下图所示,模型在 JVM 生态和 JavaScript 上表现最佳,而系统级语言( C / C++ / Rust / Go)成为普遍难点。这种分层反映了不同语言生态的工具链成熟度和诊断便利性对模型性能的深刻影响。
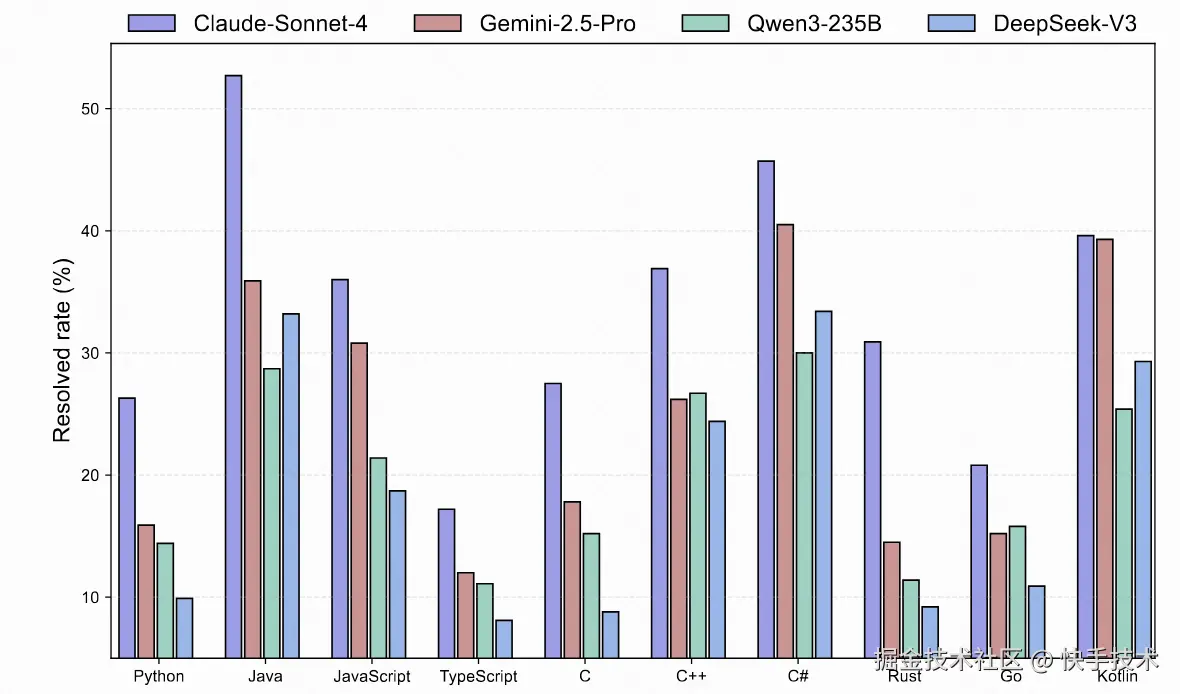
图 6: 不同模型对于 SWE-Compass 上不同语言任务的 Pass@1
核心发现 4: 交互轮次与成功率。下图展示了每种语言的轮次分布。在 Claude Code 下,确定性生态系统( Java / Kotlin / JavaScript / C# )的中位数较低,四分位距较窄,而实现相似或更高的 Pass@1 提升来自可靠信号而非更多轮次。系统语言(C/C++/Rust/Go)的尾部较重,尤其是对于 SWE - Agent,收益明显递减;Rust 最为脆弱。Python 表现出高方差:在 Claude Code 下,固定环境收敛迅速,而异质性则促使 SWE - Agent 进行许多低收益的轮次。总体而言,对于系统语言,优先进行仓库级本地化,对于 Python,优先进行环境强化;在 JVM / JS 中,专注于更精确的假设修剪和并行验证。
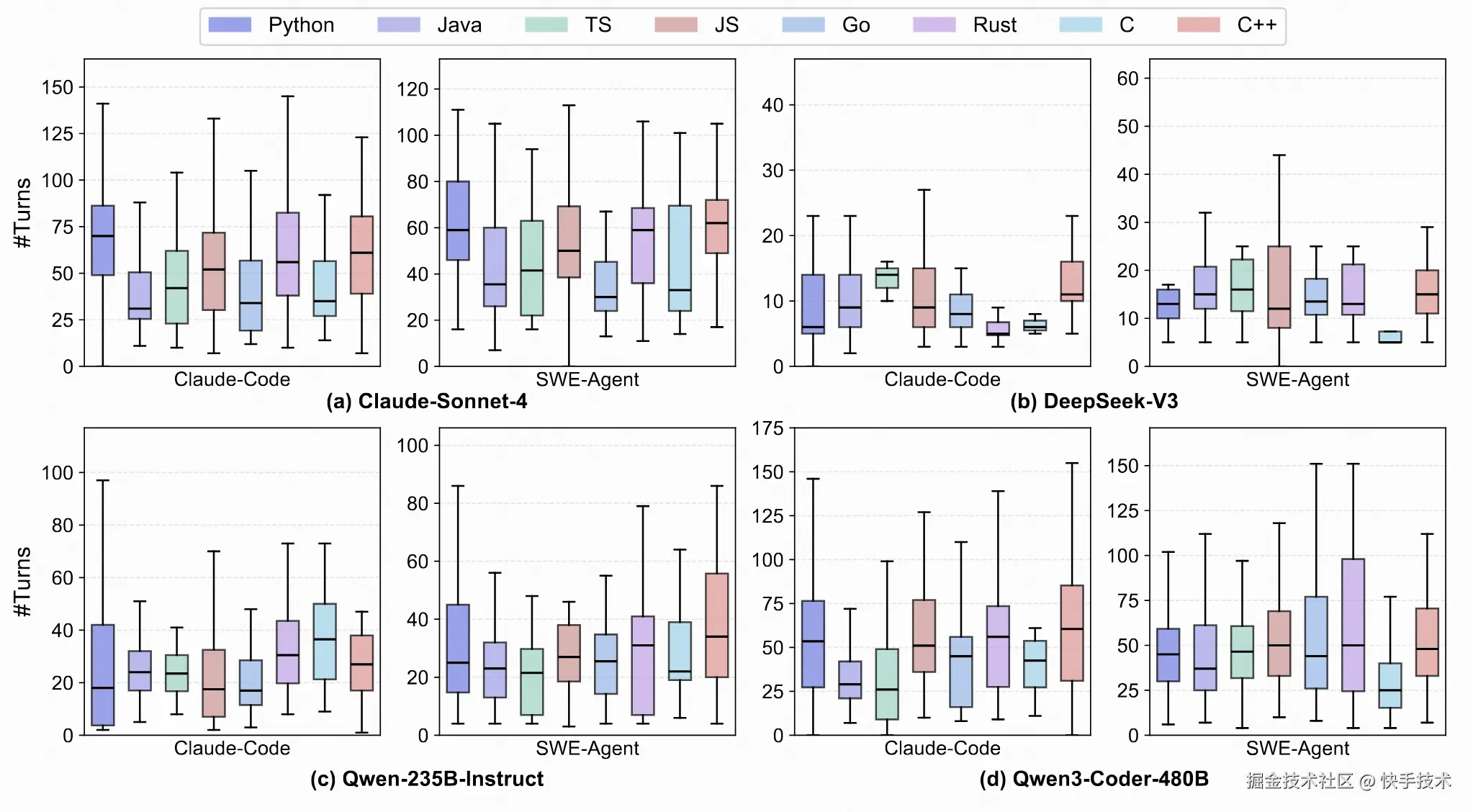
图 7: 不同模型对于 SWE-Compass 上不同语言任务的交互轮数
**核心发现 5: 跨语言的一致性和专业化。**下图总结了强聚合结果是广泛分布还是集中分布。在图(a)中,聚合 Pass@1 和每种语言的中位数 Pass@1 呈现出明显的视觉正趋势,表明排名较高的系统往往在各语言中更一致地提升,而非依赖单一语言。顶级系统在右侧聚集,一致性更高,而中级模型分布更分散,中位数较低。在图(b)中,总体性能越高,视觉上与跨语言/任务的变异性(变异系数,CV)越低相吻合,这表明更强的模型通常变异性更小。综合这些观察结果支持我们早期的发现:(i)顶级的改进反映了本地化和执行可靠性的广泛提升,而非狭隘的专业化;(ii)减少跨语言方差是缩小差距的有效杠杆,尤其是对于对变异性贡献不成比例的系统语言;(iii)评估协议应同时报告集中趋势和离散度,以避免夸大由部分语言驱动的收益。
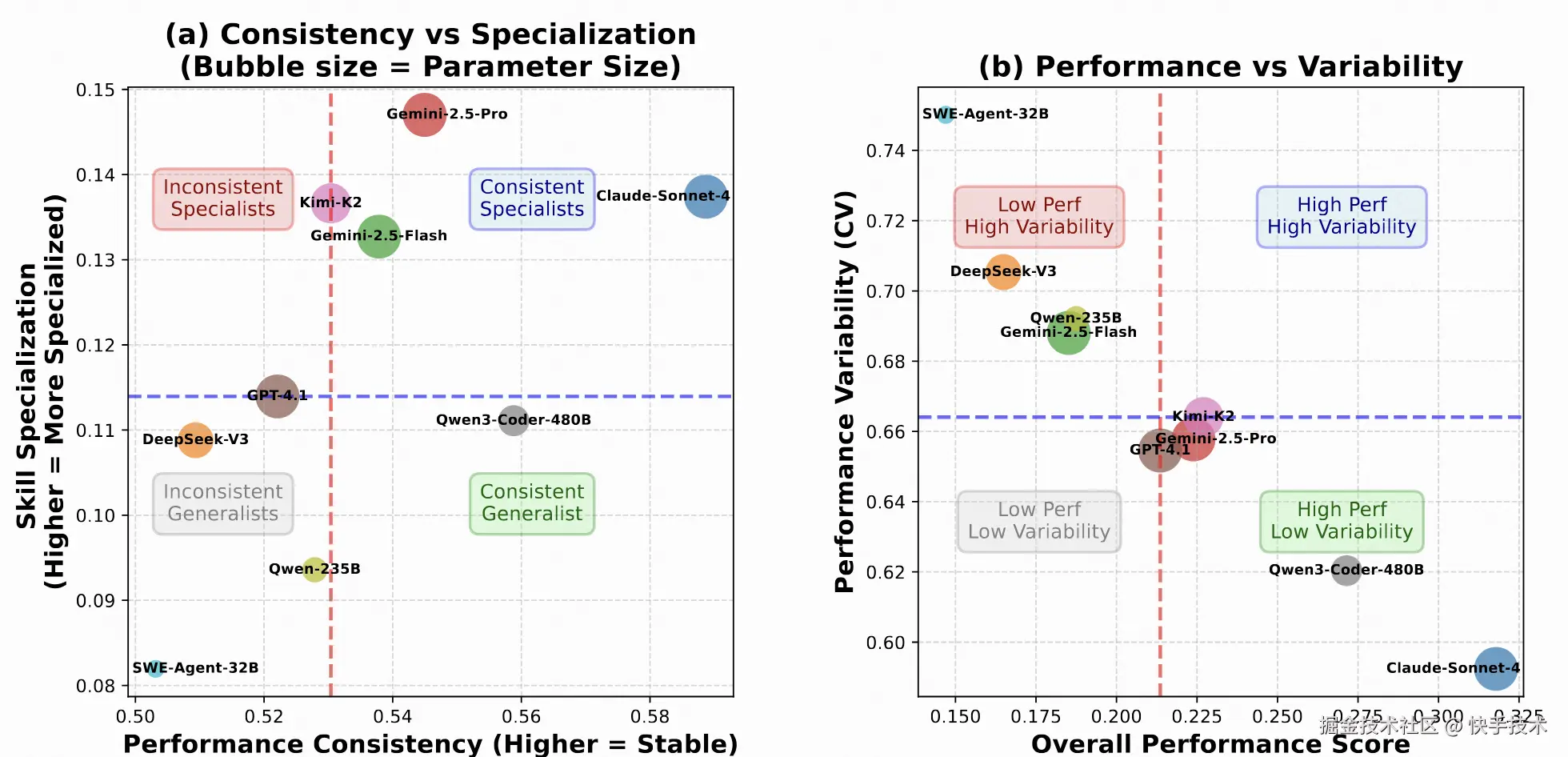
图 8: 不同模型在 SWE-Compass 上语言倾向性与性能稳定性分析
**核心发现 5: 细粒度场景分析。下表显示,**场景难度与工具确定性和所需编辑的局部性密切相关。诸如用户界面/用户体验工程、安全工程和应用程序开发等高得分类别将成熟的框架与清晰的预言机和快速运行的测试相结合,在这些类别中, Claude Code 以编辑器为中心的工作流程将稳定的反馈转化为更少轮次下更高的 Pass@1。相比之下,数据库系统、基础设施开发、机器学习/人工智能和专业编程领域涉及多阶段构建、跨进程依赖或非确定性输出;在这里,SWE-Agent 的迭代定位通常更具弹性,但也更容易超时。因此,在我们的设置中,Claude Code 在各个场景中相对于 WE-Agent 的一致平均优势集中在具有可靠、低方差信号的管道中。为了弥合剩余的差距,未来的系统应该:
-
增强复杂堆栈的存储库级可观测性和可重复性(最小化重现脚本、固定环境、工件隔离)
-
对确定性堆栈进行假设修剪和并行验证投资,其中瓶颈是搜索效率而不是原始探索预算。
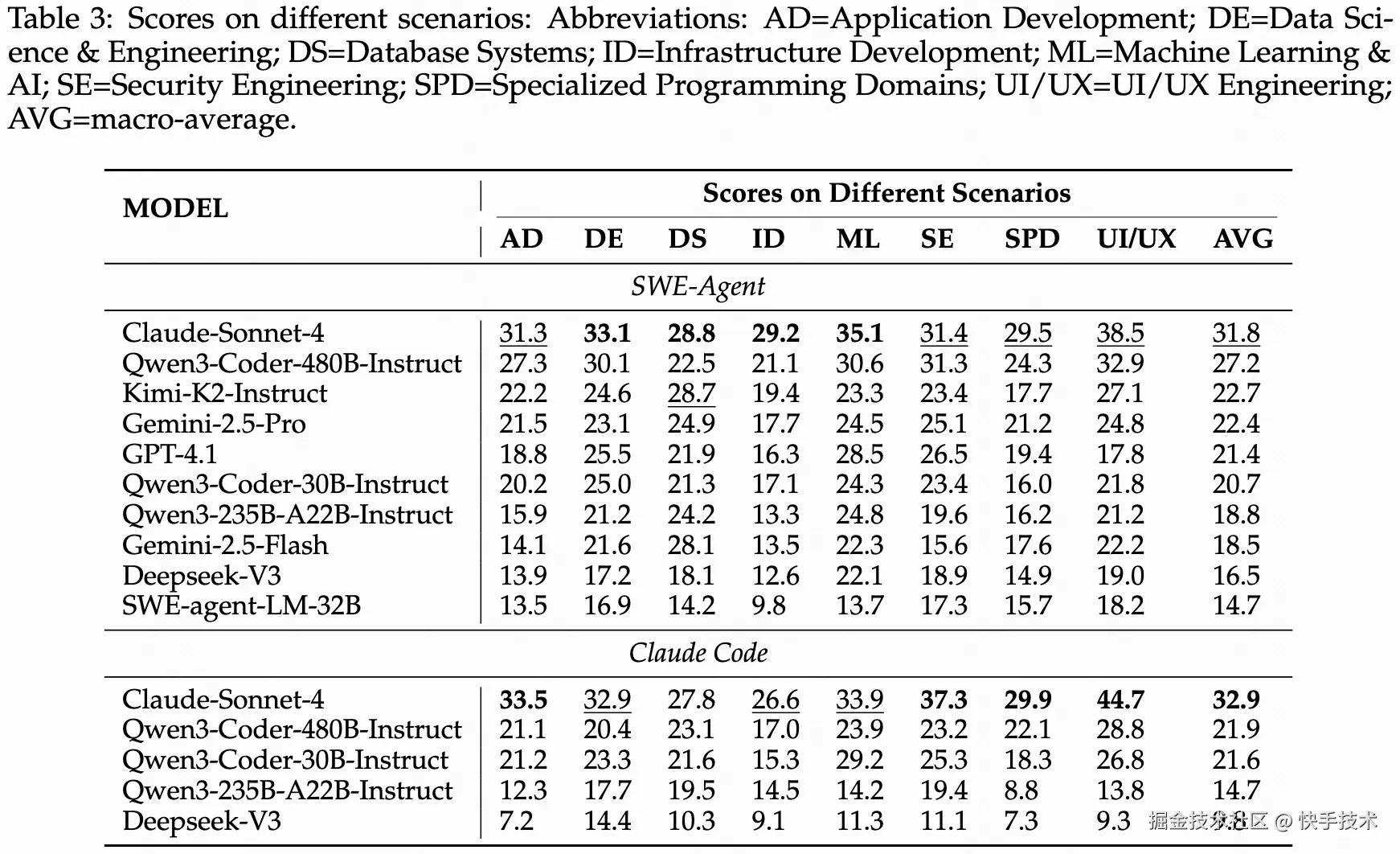
表 9: 不同模型在 SWE-Compass 的不同编程场景上表现
四、深度洞察:模型失败根因分析
为了系统地理解当前编码代理的局限性,我们对来自 SWE-Compass 基准测试的 SWE-Agent 轨迹进行事后失败分析,通过对 600 个失败轨迹的精细分析,研究团队揭示了当前代码智能体的六大失败模式:
-
需求误解(34%):模型未能准确理解问题本质,包括错误定位文件、误判严重性等
-
解决方案不完整(32%):仅解决表面症状而忽略根本原因,或引入新缺陷
-
测试不充分(21%):遗漏边界情况、兼容性问题和性能影响评估
-
工具调用错误(5%):语法错误、上下文溢出等基础技术问题
-
技术知识缺口(5%):缺乏领域专业知识(如安全、前端等)
-
无限循环(3%):陷入重复尝试同一解决方案的僵局
图 10: 错误类型分布
这一发现指向一个关键结论:当前模型的核心瓶颈不在代码生成质量,而在需求理解和系统设计能力。这为下一代代码智能体的研发指明了方向。
五、行业影响与未来展望
SWE-Compass 的发布标志着代码大模型评估进入了一个新时代。其影响主要体现在以下几个方面:
-
对模型开发者的价值:为模型研发提供了明确的改进方向,帮助开发者识别模型在特定任务、场景和语言上的弱点,有针对性地进行优化。
-
对企业用户的意义:为企业选择适合自身技术栈的代码助手提供了科学依据,避免了盲目选型带来的效率损失。
-
对学术研究的推动:为软件工程和 AI 交叉领域研究提供了标准化评估平台,促进了不同研究之间的可比性和可复现性。研究团队也规划了未来的扩展方向,包括规模和覆盖范围的扩展、更难的长上下文设置、指标和协议的丰富、评估轨道的探索、人在环校准以及可复现性、安全性和可访问性的持续改进。
结语
SWE-Compass 的出现恰逢其时,为尚不完善的代码大模型评估市场带来了秩序和科学。
通过将 2,000 个验证实例与可复现执行环境集成,SWE-Compass 提供了对软件开发生命周期的全面覆盖。大规模实验揭示了任务难度的一致性层次结构、语言特定变异性和根植于需求误解和不完整解决方案的主导失败模式。
这些发现强调,自动化软件工程的未来进展较少依赖于孤立的代码生成改进,而更多依赖于增强需求 grounding、环境可靠性和推理一致性。SWE-Compass 为推进下一代健壮、通用编码代理提供了严谨、可扩展和可复现的基础。
在 AI 编程助手日益普及的今天,SWE-Compass 就像一枚指南针,为开发者在大模型迷宫中导航提供了方向。我们希望更多研究者和开发者采用这一基准,助力代码大模型能力的快速提升,最终实现 AI 与人类开发者协同创作软件的新范式。
研究团队:快手技术 KwaiKAT 团队 × 南京大学刘佳恒老师 NJU-LINK