
◆ 博主名称: 小此方-CSDN博客
大家好,欢迎来到晓此方的博客。
⭐️个人专栏:《C语言》_小此方的博客-CSDN博客
⭐️踏破千山志未空,拨开云雾见晴虹。 人生何必叹萧瑟,心在凌霄第一峰。
目录
[➤ 堆的性质](#➤ 堆的性质)
[➤ 堆的存储](#➤ 堆的存储)
[三, 堆排序](#三, 堆排序)
[1. 堆的结构设定](#1. 堆的结构设定)
[2. 单次调整代价](#2. 单次调整代价)
[3. 总体时间复杂度(最坏情况)](#3. 总体时间复杂度(最坏情况))
一,什么是堆
➤一句话定义
堆是一种特别的完全二叉树。分为大根堆(大堆)和小根堆(小堆)。在小根堆中,所有父节点的值都小于或等于其子节点;而在大根堆中,所有父节点的值都大于或等于其子节点。
➤ 堆的性质
● 堆中某个结点的值总是不大于或不小于其父结点的值。
● 堆总是一棵完全二叉树。
➤ 堆的存储
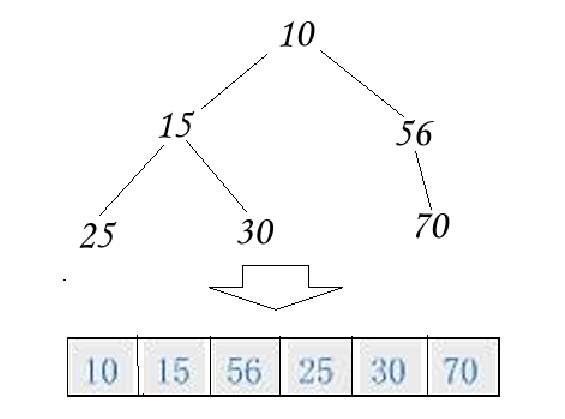
二叉树本质上都可以通过二叉链的形式存储。但是完全二叉树和满二叉树由于其特性,可以用数组存储。
优点:
- 数组存储能显著提高缓存命中率。
- 利用下标之间的数学关系,可以快速定位父子节点,便于插入、删除等操作。
一个非线性的数据结构以线性方式存储,这样的存储方式让现实与想象产生隔阂,让物理与逻辑发生分歧。但是出于效率需要,这样的操作是不可避免的。
● 访问左孩子: index*2+1;
● 访问右孩子:index*2+2;
● 访问父亲 :(index-1)/2;
为什么只有一种方式?
因为整数除法中 (n-1)/2 == (n-2)/2 当 n 是奇数时成立,因此无论从左孩子还是右孩子回溯到父节点,结果一致。所以统一采用 **(index - 1) / 2**即可。
这种线性化存储方式虽然牺牲了直观性,却极大提升了性能,是实际应用中的优选方案。
二,如何实现一个堆
我们以 C 语言为例,实现一个通用类型的堆(支持任意数据类型),并提供基本接口。
cpp
//堆的初始化
void HeapInit(Heap* php);
// 堆的销毁
void HeapDestory(Heap* php);
// 堆的插入
void HeapPush(Heap* php, HPDataType x);
// 堆的删除
void HeapPop(Heap* php);
// 取堆顶的数据
HPDataType HeapTop(Heap* php);
// 堆的判空
int HeapEmpty(Heap* php);1,创建一个堆:初始化和销毁
cpp
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;我们的堆是基于数组的,事实上我们也可以理解为顺序表。
● 指针_a用来指向数组的位置。
● size表示数组中已经有的数据个数。
● capacity表示数组的容量大小。
cpp
//初始化
void HeapInit(Heap* php)
{
assert(php);
php->_capacity = 0;
php->_a = NULL;
php->_size = 0;
}
cpp
// 堆的销毁
void HeapDestory(Heap* php)
{
assert(php);
free(php->_a);
php->_a = NULL;
php->_capacity = 0;
php->_size = 0;
}2,在堆中插入一个数
插入过程分为两步:
- 扩容检查:确保有足够的空间;
- 插入并调整:将新元素放入末尾,并向上调整至正确位置(维持堆的性质)。
cpp
assert(php);
if (php->_size== php->_capacity)
{
int newcapacity = php->_capacity == 0 ? 4 : php->_capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->_a,newcapacity * sizeof(HPDataType));
if (tmp == NULL)
{
perror("realloc::tmp");
exit(1);
}
php->_capacity = newcapacity;
php->_a = tmp;
}赋值,然后插入:
cpp
php->_a[php->_size] = x;
php->_size++;例如,在大根堆中,插入的新元素必须小于等于 其父节点;在小根堆中,则必须大于等于其父节点。
为此,我们需要实现一个核心辅助函数:向上调整(shift_up)
4,向上调整函数(shift_up)
cpp
void shift_up(HPDataType*a,int child)
{
assert(a);
int futher = (child - 1) / 2;
while (child > 0)
{
if (a[futher] > a[child])
{
swap(&a[futher], &a[child]);
child = futher;
futher = (child - 1) / 2;
}
else
{
break;
}
}
}这个函数的核心逻辑如下:
输入的是新插入元素在数组中的下标,即"孩子"的位置。
通过公式
计算出其父节点的位置,然后比较父节点与子节点的值。
以小根堆 为例:如果父节点的值大于子节点的值,则违反了堆的性质。此时,交换父子节点的值,并将交换后的新父节点位置作为下一个待处理的"孩子"位置,继续向上进行比较与调整。
这一过程不断重复,直到满足堆的性质(父节点 ≤ 子节点)或到达堆顶为止。
由此实现了自动向上调整(shift_up) 的机制,确保新插入的元素被正确地"上浮"到合适位置。
以下是我提供的swap()函数的一个参考:
cpp
void swap(HPDataType* num1, HPDataType* num2)
{
HPDataType num3 = *num1;
*num1 = *num2;
*num2 = num3;
}3,在堆顶删除一个数据
cpp
void HeapPop(Heap* php)
{
assert(php);
assert(php->_size > 0);
swap(&php->_a[0], &php->_a[php->_size - 1]);
php->_size--;
be_down(php->_a, 0,php->_size);
}首先,删除操作前必须确保堆不为空,并且堆的指针有效(非空指针)。
若直接删除堆顶元素,会导致原本的第二个元素成为新的堆顶,但此时它可能违背堆的性质(例如在大根堆中比其子节点小),从而破坏整个堆的结构。这种破坏会引发连锁反应,使得所有父子和兄弟关系失序,堆不再满足定义。
为避免这一问题,我们采用一种巧妙的"间接删除法":
- 将堆顶元素与数组末尾的元素交换;
- 然后将最后一个元素逻辑上移除(即
size--); - 此时新堆顶可能不满足堆的性质,因此需要对它进行向下调整(shift_down),使其重新恢复堆的有序性。
这样既保留了堆的结构完整性,又实现了高效删除。
4,向下调整算法
cpp
void shift_down(HPDataType* a, int futher,int n)
{
int child = futher * 2 + 1;
while (child < n)
{
if (child + 1 < n&& a[child + 1] < a[child])
{
child++;
}
if (a[child] < a[futher])
{
swap(&a[futher], &a[child]);
futher=child;
child = futher * 2 + 1;
}
else
{
break;
}
}
}和向上调整算法不同。向下调整算法首先得找到父亲。
用父亲找到左孩子和右孩子,以小堆为例。判断得到左右孩子中较小的那个,比较它和父亲的大小关系,如果它比父亲小,交换,然后让孩子的位置变成新的父亲反复操作直到找不到下一个孩子 为止。
关键点解析
-
为何要先判断左右孩子?
- 直接比较左右孩子的大小可能带来额外开销;
- 使用"假设法"更高效:先假设左孩子较小,再判断是否应改为右孩子。
- 这样减少了不必要的比较次数。
-
边界条件处理
- 当 **
child + 1 >= n**时,说明右孩子不存在,无需比较; - 因此在比较前必须加上 **
child + 1 < n**的判断,防止越界。
- 当 **
-
循环终止条件
while (child < n)表示当前子节点仍在有效范围内;- 当 **
child >= n**时,说明当前节点没有子节点,无需继续调整; - 虽然 **
father < 0**也能正常运行,但写法不够直观,建议避免。
5,取堆顶数据以及判空方法
cpp
HPDataType HeapTop(Heap* php)
{
assert(php);
assert(php->_size > 0);
return php->_a[0];
}
// 堆的判空
int HeapEmpty(Heap* php)
{
assert(php);
return php->_size == 0;
}不用过多解释,最简单的部分。
------------------------------------------------接下来是我想讲的重点------------------------------------------------
三, 堆排序
先说结论
1,建堆:正向排序建大堆,逆向排序建小堆。
2,首尾互换 ,顶部元素在前n-k(k从1开始每次循环自增1)个结点内调整。
3,循环以上操作。
cpp
void HeapSort(int* a, int n)
{
//从下往上建堆法
for (int i = (n - 1 - 1) / 2; i>=0; i--)
{
be_up(a, i);
}
int end = n - 1;
while (end>=0)
{
swap(&a[0], &a[end]);
be_down(a, 0, end);
end--;
}
}解释原理
1.建堆(以建小堆为例)
这是一个非常抽象的过程。
建堆分为从上向下调整建堆 和从下向上调整建堆。
假如我们有这样一个数组
10,11,7,9,12,66,13,8,16,14,15,并把它想象成树型结构:
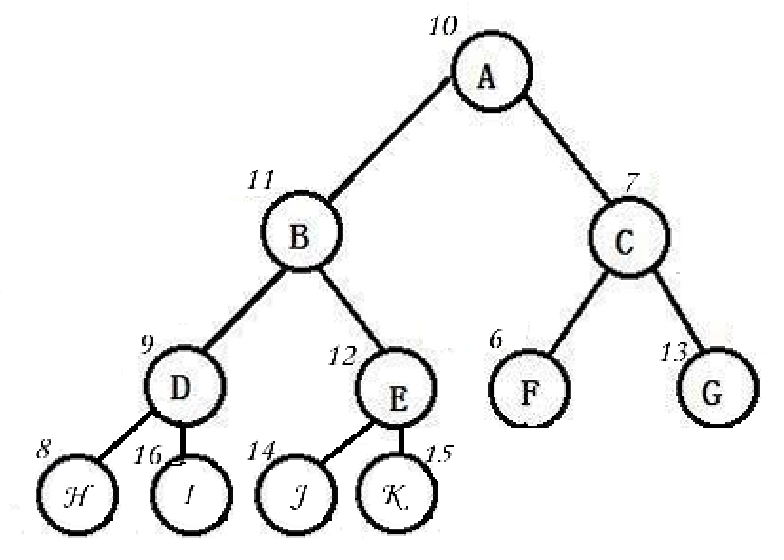
从上向下调整建堆: 先假设A已经在堆里面了,然后从B开始到K结束,所有的结点全部做一次向上调整算法。从而达到建堆。
从下向上调整建堆 :从最后一位父亲(最后一个非叶子节点)开始(也就是E)到A的所有结点全部做一次向下调整算法**,**从而达到建堆。
2,首尾交换,调整,从尾向首形成排序
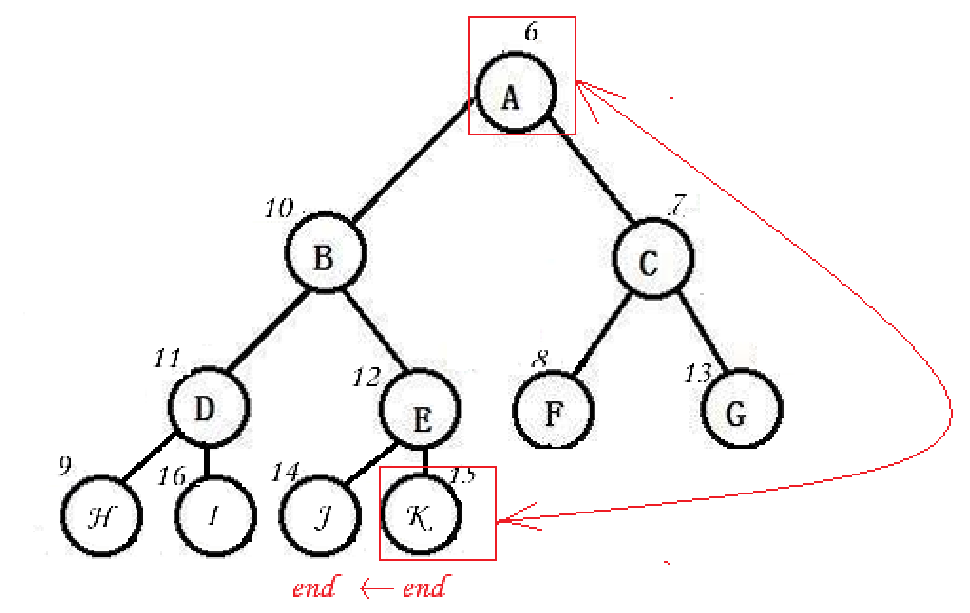
建成小根堆后,堆顶元素即为当前所有元素中的最小值。
接下来,执行以下步骤:
-
交换堆顶与末尾元素
将堆顶与当前堆的最后一个元素交换位置。
-
缩小堆的范围
将有效堆的边界指针
end减 1,表示最小值已"归位",不再参与后续调整。 -
向下调整新堆顶
对新的堆顶元素执行 向下调整,使其重新满足小根堆的性质。
-
重复上述过程
每次都将当前最小值沉到数组末尾已排序区域,逐步得到:
- 从后往前:从小到大的升序序列
- 从前往后:从大到小的降序排列
四,Topk算法
1,一句话定义:
Top-K 算法是一种基于堆的数据处理方法,用于高效找出海量数据中最大(或最小)的前 K 个元素,在大规模数据场景下具有显著优势。
2,探索实现思路:
很多人最先想到的 Top-K 解法是:先对全部数据建堆,再用类似堆排序的方式依次取出前 K 个最大(或最小)的元素。
但问题来了------
如果数据量是 100 万 ,还可以接受;
可如果是 10 亿条数据呢?
一个 int 占 4 字节,10 亿个整数就需要:
4 × 10⁹ 字节 ≈ 4 GB 内存。
(注:1 KB = 1024 B,1 MB = 1024 KB,1 GB = 1024 MB → 10⁹ 字节 ≈ 0.93 GB,若为 40 亿字节则约为 3.73 GB)
为找区区 K 个数,而占用数 GB 内存,代价显然过高。
于是你可能会想:
"那我把数据分批处理!比如分 100 次,每次从硬盘读 1000 万条,分别找出每批的前 K 个,最后从这 100×K 个候选中再选 Top-K。"
这确实缓解了内存压力,但带来了新问题:
- 需要多次 I/O 操作,速度慢;
- 最终仍需处理 100×K 的数据,若 K 很大,效率依然低下;
- 时间复杂度和工程复杂度显著上升。
那么,有没有一种既节省内存,又高效的方法?
答案是:有!那就是top-k经典解法------使用大小为 K 的堆。
Top-k的经典解决办法:
一,生成大量随机数
cpp
//创造10万个随机数据
int n = 100000;
FILE* fin = fopen("data.txt", "w");
if (fin == NULL)
{
perror("fileopen::error");
exit(1);
}
while (n)
{
int a = rand()%10000+n;
fprintf(fin, "%d", a);
fprintf(fin, "\n");
n--;
}
fclose(fin);1,原理
这个代码,通过写的方式打开data.txt文件,并利用rand函数创造大量随机数,用标准文件输入函数fprintf打印到文件中。(最后不要忘记关闭文件)。
2,如何找到这些数据
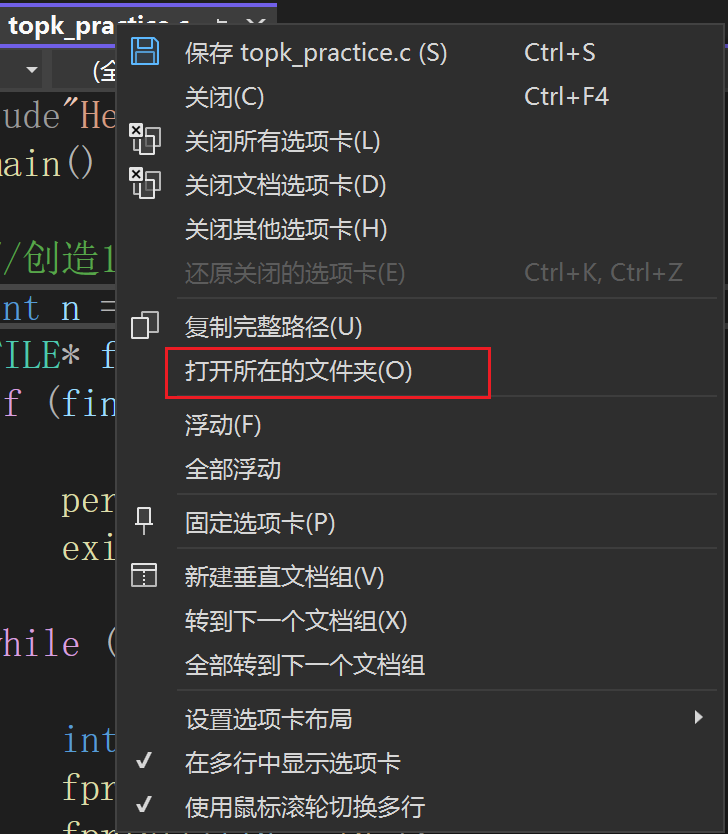
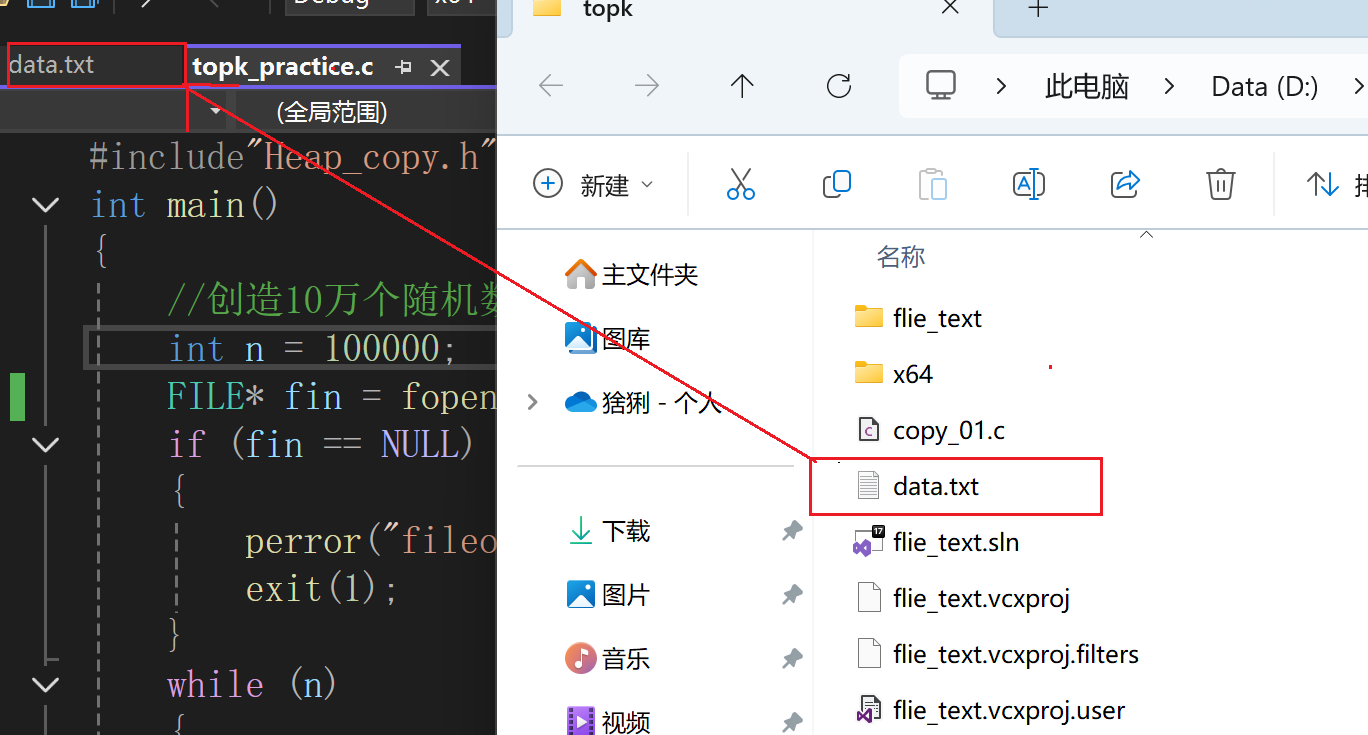
步骤如下:
1,右击当前top-k文件。
2,点击打开所在文件夹。
3,找到文件data.txt,并将它拖拽到编译器中。
二,实现top-k
两大步骤:
1,读取并建一个k个数据大小的小堆
2,从剩下的n-k个元素中,每次读取一个数据,和堆顶的数据进行比较
------------大,和堆顶交换进堆并调整。
------------小,不进堆。
cpp
//topk最大的10个数据
FILE* fin2 = fopen("data.txt", "r");
int k = 10;
int arr[10];
for (int i = 0; i < k; i++)
{
fscanf(fin2, "%d", &arr[i]);
}
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
be_down(arr,i, k);
}
n = 100000;
for (int t = 0; t < n - k; t++)
{
int num = 0;
fscanf(fin2, "%d", &num);
if (num > arr[0])
{
arr[0] = num;
be_down(arr, 0, k);
}
}
for (int i = 0; i < k; i++)
{
printf("%d", arr[i]);
printf("\n");
}
fclose(fin2);
return 0;
}五,数学证明向下调整建堆比向上调整建堆算法的时间复杂度更优
我在上文实际上埋藏了一个伏笔------为什么堆排序的建堆操作要使用向下建堆法?
1,向上调整建堆的时间复杂度
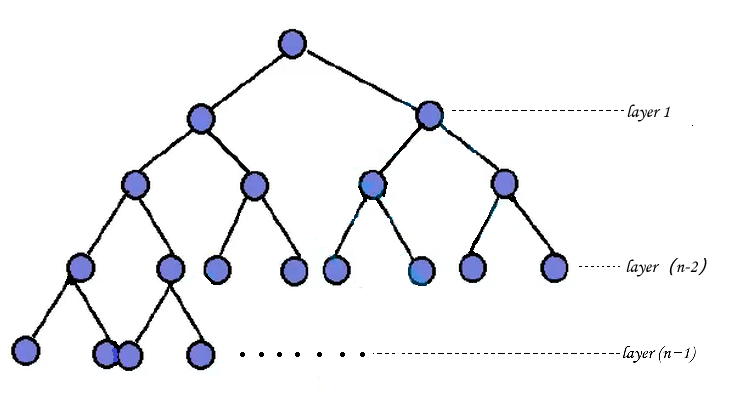
向上调整建堆的时间复杂度分析(最坏情况)
我们考虑最坏情况:每个新插入的结点都需要从其初始位置一路向上调整至堆顶。
1. 堆的结构设定
-
设堆共有 h 层(根结点位于第 0 层)。
-
第 0 层有 20 个结点
第 1 层有 21 个结点
第 2 层有 22 个结点
⋮
第 h−1 层有 2h−1 个结点
-
总结点数为等比数列之和:
N=20+21+22+⋯+2h−1=2h−1
-
由此可得堆的高度:
h=log2(N+1)
2. 单次调整代价
在向上调整建堆过程中,一个位于第 i 层的结点(i≥1),最多需要向上移动 i 次才能到达根结点。
因此,单次调整的时间复杂度为 O(logN)。
3. 总体时间复杂度(最坏情况)
在最坏情况下,假设每一层的所有结点都需执行最大次数的向上调整:
- 第 1 层有 21 个结点,每个最多调整 1 次 → 贡献 21⋅1
- 第 2 层有 22 个结点,每个最多调整 2 次 → 贡献 22⋅2
- 第 3 层有 23 个结点,每个最多调整 3 次 → 贡献 23⋅3
- ⋮
- 第 h−1 层有 2h−1 个结点,每个最多调整 h−1 次 → 贡献 2h−1⋅(h−1)
因此,总操作次数为:
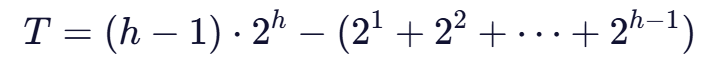
该式可通过错位相减法化简为:
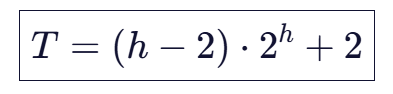
代入 2h=N+1 和 h=log2(N+1),得:
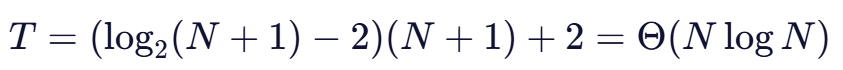
4. 结论
向上调整建堆在最坏情况下的时间复杂度为:O(NlogN)
同样的计算方式:我们可以得到:向下调整算法的时间复杂度是O(N)
因此:向下调整算法更优。
希望这篇内容能帮助你真正了解堆的原理,如果觉得有收获,欢迎点赞、收藏并分享给更多人!
本期内容到此结束。