摘要:在大模型幻觉频发的今天,RAG 架构成为救命稻草。但面对"知识库"与"知识图谱"两大技术路线,开发者该如何抉择?本文深度解析两者的定义、区别与融合趋势,助你构建更聪明的 AI 系统。
在大语言模型(LLM)重塑技术版图的今天,"幻觉(Hallucination)"问题依然是悬在企业级应用头顶的达摩克利斯之剑。为了解决这一问题,检索增强生成(RAG)架构应运而生,而 RAG 的核心在于"外部知识"的有效存储与检索。
在这个背景下,两个概念频繁出现在技术架构图中:知识库(Knowledge Base, KB) 和 知识图谱(Knowledge Graph, KG)。
很多开发者在选型时会感到困惑:它们究竟有何区别?是互斥的替代关系,还是互补的搭档?本文将从技术原理、应用场景及落地实践三个维度,为您深度拆解这两大知识管理支柱。
一、 核心概念拆解
1. 知识库(Knowledge Base):广义的知识容器
在传统定义中,知识库是用于知识管理的信息集合。但在当今的 AI 语境下(特别是 RAG 架构中),当我们谈论"知识库"时,通常指的是基于向量检索(Vector Search)的非结构化数据存储。
- 核心逻辑:将文档(PDF、Wiki、Markdown)切分成片段(Chunks),通过 Embedding 模型转化为高维向量,存储在向量数据库中。
- 检索方式:计算"语义相似度"。例如,用户问"苹果怎么卖?",系统能匹配到"红富士价格优惠"的片段,因为它们在向量空间距离相近。
- 特点:模糊匹配、构建速度快、适合处理海量非结构化文本。
2. 知识图谱(Knowledge Graph):万物互联的语义网络
知识图谱本质上是一种基于图数据结构(Graph Data Structure)的知识表示方法 。它由节点(Entities)和边(Relationships)组成,以"主-谓-宾"的三元组形式(如 <埃隆·马斯克, 是CEO, 特斯拉>)描述世界。

- 核心逻辑:通过信息抽取(Information Extraction)技术,从数据中提炼实体与关系,构建一张网状的拓扑结构。
- 检索方式:图遍历(Graph Traversal)与子图匹配。例如,查询"马斯克管理的公司有哪些?",系统会沿着"CEO"这条边找到所有关联节点。
- 特点:精确匹配、具备推理能力、结构化程度高、适合处理复杂关系。
二、 深度对比:多维度的技术博弈
为了更直观地理解两者的差异,我们从以下五个维度进行对比:
| 维度 | 知识库 (Vector-based KB) | 知识图谱 (Knowledge Graph) |
|---|---|---|
| 数据结构 | 高维向量空间(扁平化) | 节点与边的拓扑网络(结构化) |
| 构建成本 | 低:切片 + Embedding 即可 | 高:需要 Schema 设计、实体识别、关系抽取 |
| 查询逻辑 | 语义相似度(模糊匹配) | 逻辑查询与多跳遍历(精确匹配) |
| 推理能力 | 弱(依赖 LLM 上下文理解) | 强(具备传递性、归纳性推理能力) |
| 可解释性 | 黑盒(向量距离难以直观解释) | 白盒(路径清晰,可追溯) |
| 更新维护 | 简单(增删文档片段) | 复杂(需维护图结构的完整性与一致性) |
一句话总结 :知识库胜在广度与效率 ,知识图谱胜在精度与深度。
三、 典型应用场景
1. 适合使用知识库(KB)的场景
- 企业内部文档问答:员工查询 HR 政策、IT 操作手册。这类数据通常是非结构化的文本,语义搜索能快速定位相关段落。
- 长文本辅助写作:寻找相关的历史文章或素材。
- 初级智能客服:基于 FAQ 列表的快速响应。
2. 适合使用知识图谱(KG)的场景
- 金融风控与反欺诈:通过分析借款人之间的关联关系(如共同联系人、担保链),发现隐蔽的欺诈团伙。这是向量搜索无法做到的。
- 供应链管理:分析零部件短缺对下游产品的级联影响(图的传导性)。
- 精准推荐系统:不仅推荐商品,还能解释"为什么推荐"(因为你购买了 A,A 与 B 属于同系列)。
- 复杂多跳问答(Multi-hop QA):例如"马斯克第一任妻子的职业是什么?"这需要先找到妻子,再查找其职业,图谱的遍历能力在此具有压倒性优势。
四、 技术实现概览
1. 数据建模与存储
-
KB 方案:
- 工具链:LangChain / LlamaIndex (数据处理), OpenAI / HuggingFace (Embedding)。
- 存储:Pinecone, Milvus, Weaviate, 或 PostgreSQL (pgvector)。
- 关键点:Chunking Strategy(切片策略)直接影响检索质量。
-
KG 方案:
- 工具链:DeepDive (抽取), SpaCy (NER)。
- 存储:Neo4j (属性图), NebulaGraph (大规模分布式), JanusGraph。
- 关键点:Ontology Design(本体设计),即定义数据世界的"骨架"。
2. 融合趋势:GraphRAG
单纯的向量检索存在"切片丢失上下文"的问题,而单纯的图谱构建成本过高。目前的业界趋势是 GraphRAG ------将两者结合。微软研究院(Microsoft Research)在 2024 年发布的 GraphRAG 项目正是这一方向的里程碑式工作。
- 原理:利用 LLM 提取文本中的关键实体构建局部子图,存储在图数据库中;同时保留文本向量。
- 优势:在回答"总结全书主旨"或"分析人物关系"这类宏观问题时,图谱能提供全局结构信息,弥补向量检索过于微观的缺陷。
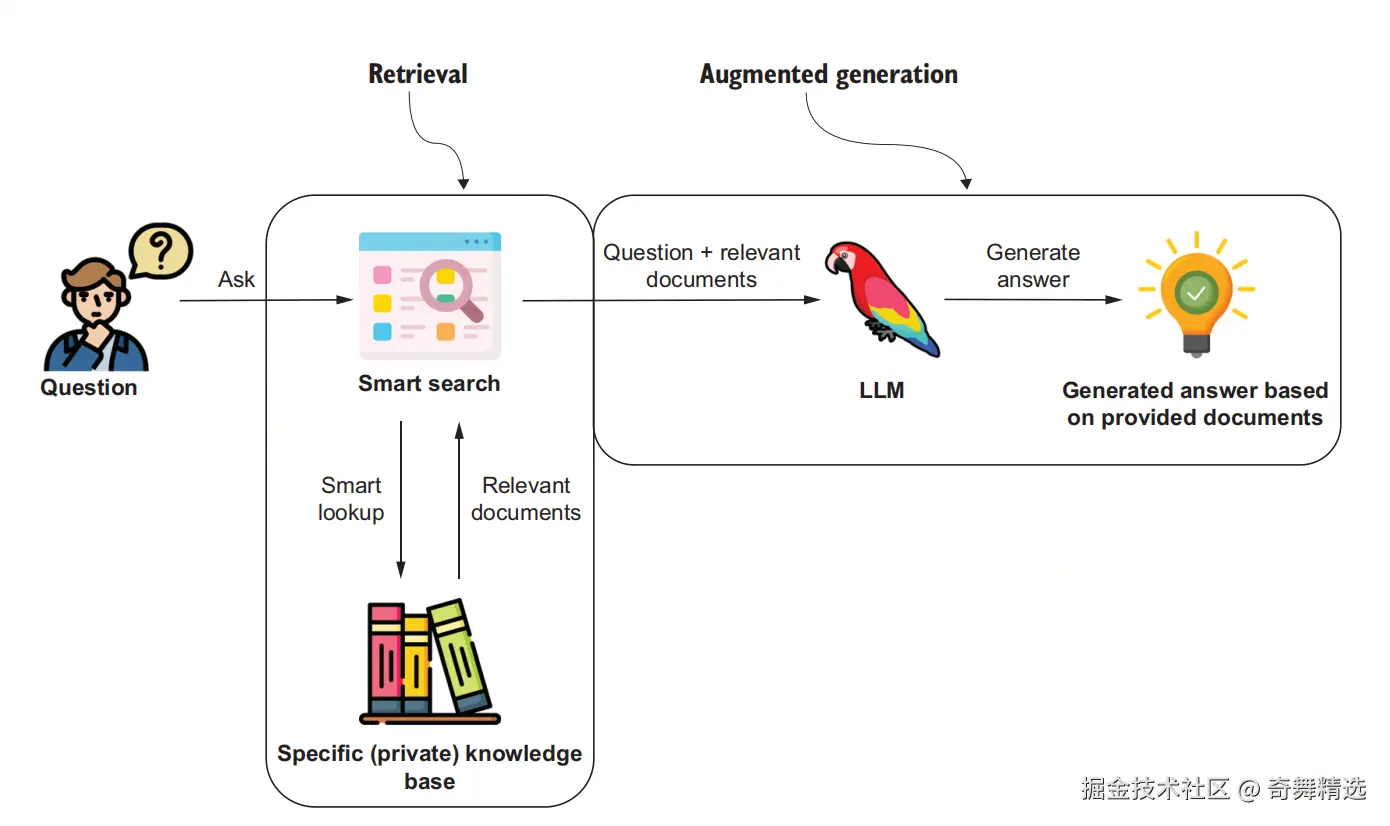 (GraphRAG)
(GraphRAG)
五、 实践建议与落地案例
对于大多数初创团队或从 0 到 1 的项目,我的建议遵循 "先僵化,后优化" 的路径:
阶段一:快速冷启动(Vector KB)
场景 :某电商搭建售后机器人。 做法 :直接将产品手册、退换货政策 PDF 导入向量数据库。 收益:1-2 周即可上线,解决 80% 的常见语义匹配问题。
阶段二:精度调优(Hybrid Search)
场景 :用户反馈搜不到特定型号参数。 做法:引入关键词搜索(BM25)与向量搜索结合,确保专有名词的精确匹配。
阶段三:引入图谱(Knowledge Graph)
场景 :需要处理"兼容性"咨询,如"镜头 A 能不能装在相机 B 上?"。 做法 :构建小规模图谱,定义 <镜头, 适配卡口, 卡口型号> 和 <相机, 适配卡口, 卡口型号> 的关系。 收益:利用图的逻辑推理能力,给出 100% 准确的兼容性回答,避免 LLM 胡编乱造。
结语
知识库赋予了 AI "博学" 的底色,而知识图谱则注入了 "逻辑" 的灵魂。
在实际工程中,不要为了用图谱而用图谱。从业务痛点出发,以低成本的向量知识库起步,在需要处理复杂关联与严谨推理的深水区,再引入知识图谱这一重型武器。两者的有机结合,才是通往下一代认知智能的必经之路。