AI大模型调用日志监控-Advisor环绕通知
什么是AI大模型的调用日志监控:
- 是SpringAI框架提供的内置日志拦截器,基于AOP机制实现对AI交互请求的日志记录。
- 通过拦截AI模型的调用过程,自动记录用户输入,系统指令,AI响应等关键信息,适用与开发调试和生产监控场景。
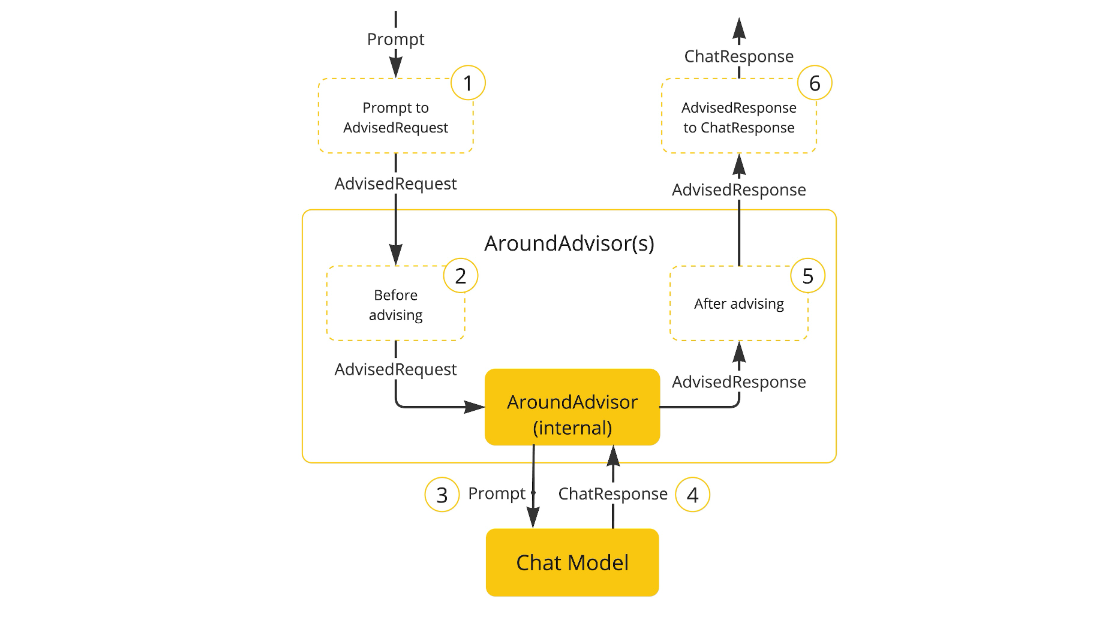
核心功能:
- 请求/响应追踪:记录用户输入文本,系统预设指令以及AI生成的完整响应内容。
- 默认日志级别:基于SLF4J输出DEBUG级别的日志,但是需要手动调整日志配置才会在默认环境下显示。
案例:
在ChatClient初始时通过defaultAdvisors()方法添加。这里我们设置简单日志级别就行。
@Configuration
public class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder){
return builder
.defaultSystem("你是guslegend团队的智能学习助手,你可以回答各种各样关于it的问题")
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
}然后我们需要开启DEBUG日志,否则SimpleLoggerAdvisor输出看不见。
logging:
level:
org.springframework.ai.chat.client.advisor: debug
2025-11-22T09:49:08.503+08:00 DEBUG 41332 --- [SpringAI] [nio-8080-exec-4] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"refusal" : "",
"finishReason" : "STOP",
"annotations" : [ ],
"index" : 0,
"id" : "44d7ed80-cc24-430e-9dae-3e54e9f683e5"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!我是你的智能学习助手,来自guslegend团队。我可以帮助你解答关于IT领域的各种问题,比如编程、网络、数据库、人工智能等等。如果你有任何疑问或需要学习资源,随时告诉我,我会尽力协助你!😊 有什么我可以帮你的吗?"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
},
"metadata" : {
"id" : "44d7ed80-cc24-430e-9dae-3e54e9f683e5",
"model" : "deepseek-chat",
"rateLimit" : {
"requestsLimit" : null,
"requestsRemaining" : null,
"requestsReset" : null,
"tokensLimit" : null,
"tokensRemaining" : null,
"tokensReset" : null
},
"usage" : {
"promptTokens" : 21,
"completionTokens" : 57,
"totalTokens" : 78,
"nativeUsage" : {
"completion_tokens" : 57,
"prompt_tokens" : 21,
"total_tokens" : 78,
"prompt_tokens_details" : {
"cached_tokens" : 0
}
}
},
"promptMetadata" : [ ],
"empty" : false
},
"results" : [ {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"refusal" : "",
"finishReason" : "STOP",
"annotations" : [ ],
"index" : 0,
"id" : "44d7ed80-cc24-430e-9dae-3e54e9f683e5"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!我是你的智能学习助手,来自guslegend团队。我可以帮助你解答关于IT领域的各种问题,比如编程、网络、数据库、人工智能等等。如果你有任何疑问或需要学习资源,随时告诉我,我会尽力协助你!😊 有什么我可以帮你的吗?"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
} ]
}我们通过观察可以发现输出内容为:请求阶段(用户输入文本,系统指令,上下文对话),响应阶段(AI生成的完整内容,token 消耗,模型名称和参数)。
SprinAI整合ChatModel对话记忆存储
什么是会话基于ChatMemory:是AI对话系统的大脑,通过存储和服用历史对话内容,使模型能够理解上下文关联,实现连贯的多轮交互。
核心价值:
- 避免失忆:解决大模型无状态特性导致上下文丢失问题。
- 提升效率:减少用户重复输入,降低模型Token 消耗(每次请求仅需要传递关键增量信息)。
- 支持复杂流程:如多步骤任务引导(填写表单,故障排查),个性化服务(基于历史偏好推荐)。
SpringAI针对会话内容存储做了封装其中关键组件:
- ChatMemory接口:定义存储/检索对话历史的核心方法(add/get/clear)。
- ChatMemoryRepository:底层存储实现,默认提供内容,好处是方便开箱即用,缺点是数据不持久化,重启后丢失。还可以数据库,Redis等方案。
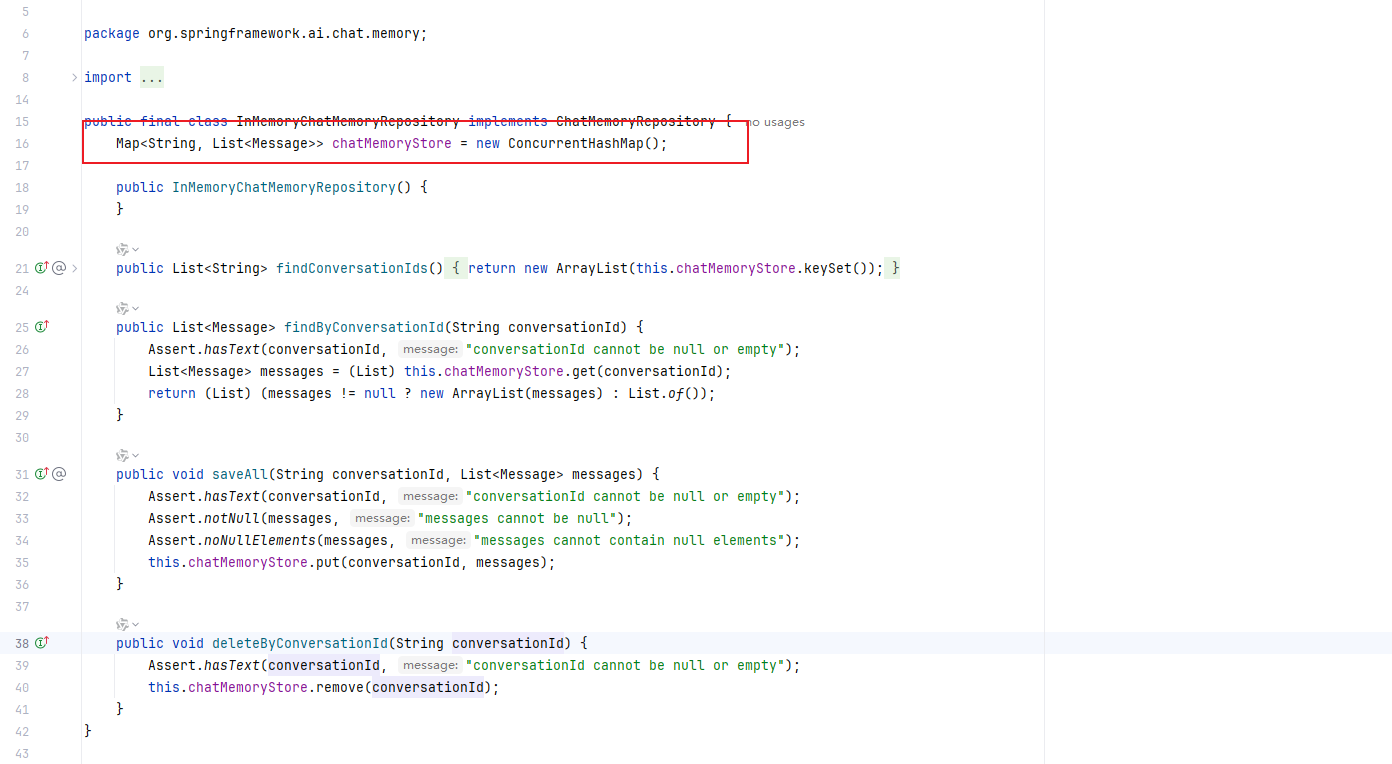
- MessageWindowChatMemory:默认对话历史管理器,采用滑动窗口策略(默认保留20条消息),自动过滤旧消息以控制内存占用。
- MessageChatMemoryAdvisor:SpringAI拦截器,自动将历史对话附加到模型请求中,无需手动维护上下文数组。
案例实战:
首先需要配置存储方案
@Configuration
public class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder, ChatMemory chatMemory){
return builder
.defaultSystem("你是guslegend团队的智能学习助手,你可以回答各种各样关于it的问题")
.defaultAdvisors(new SimpleLoggerAdvisor(), MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
}对话接口整合
@RestController
@RequestMapping("/ai")
public class MemoryController {
@Autowired
private ChatClient chatClient;
@GetMapping("/memory")
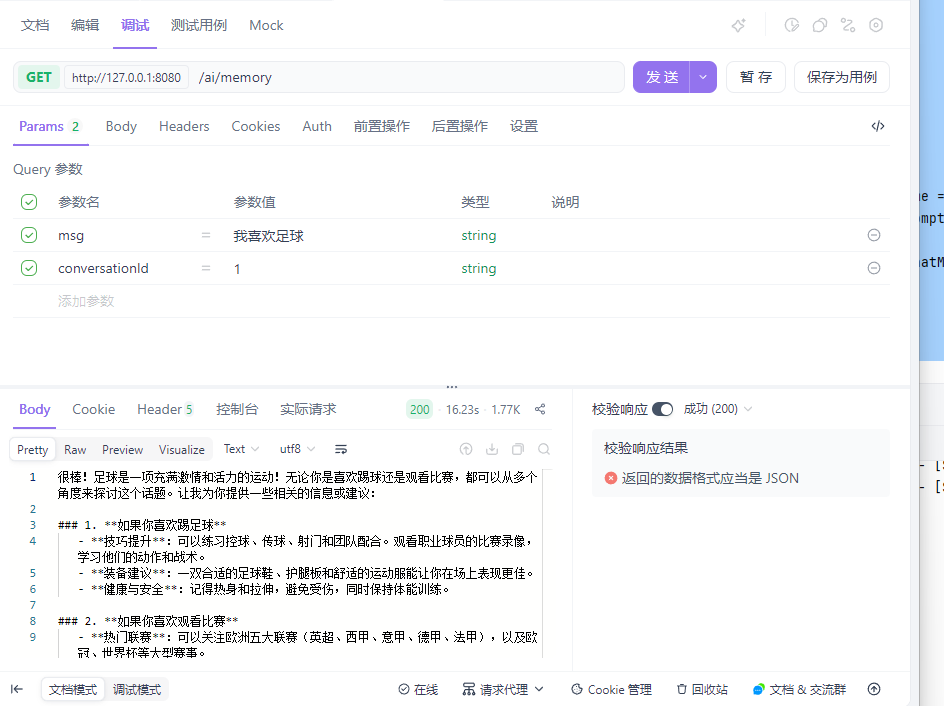
public String chat(@RequestParam(name = "msg")String msg,@RequestParam(name = "conversationId")String conversationId){
String res = this.chatClient.prompt()
.user(msg)
.advisors(a ->a.param(ChatMemory.CONVERSATION_ID, conversationId))
.call()
.content();
return res;
}
}
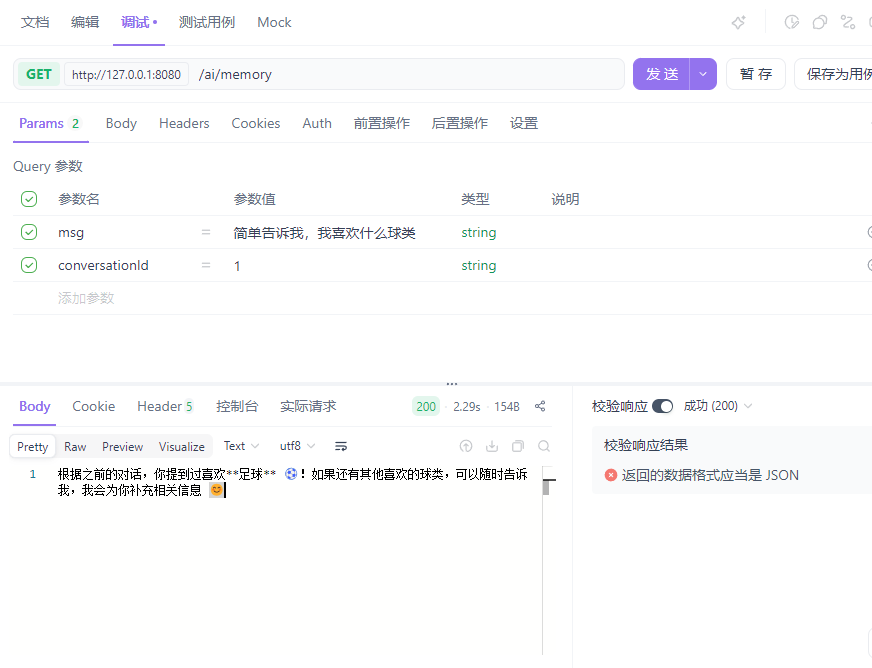
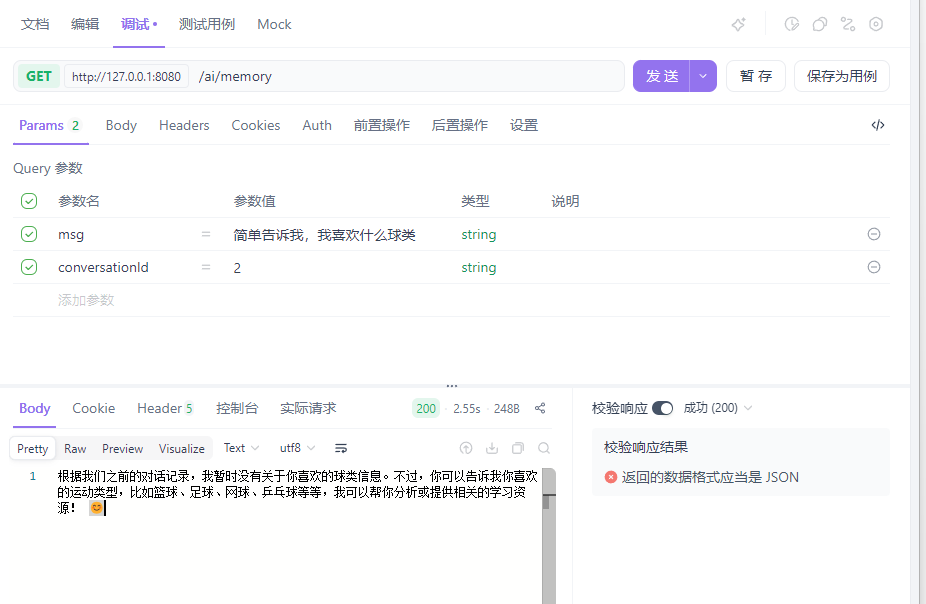
那么为什么大模型可以记住历史对话?
主要是通过ChatMemory.CONVERSATION_ID参数来指定对话会话ID的。ChatClient自动从memory中检索到历史消息并添加到prompt提示词中,再给大模型进行整合回答。响应后自动将对话记录存储到memory中,存储起来。
CharModel对话记存储常见问题
内存泄漏:
问题表现**:**为长期运行后内存占用时间持续增长。
解决方法**:** 配置滑动窗口大小MessageWindowChatMemory.builder().maxMessages(20).build();定期清理过期会话(如Redis设置TTL)。
上下文冗余token消化大:
问题表现:模型响应包含过时信息。
解决方法:自动过滤旧消息,根据历史对话,提取关键信息,生成摘要;调用LLM对历史对话生成摘要,后续交互仅传递摘要而非完整历史;结合业务逻辑动态调整上下文(如用户切换话题时清空历史)。
存储性能瓶颈:
问题表现:高并发场景下数据库写入延迟高。
解决方案(混合存储方案):读取分离(读请求走Redis,写请求异步写入数据库);批量操作(使用Redis管道Pipeline或MySQL批量插入);热数据也叫近期对话(使用Redis缓存,保证高并发场景下的读写性能);冷数据也叫历史对话:归档到Mysql,支持长期查询和审计。 你