
引言:Java 开发者的 AI 入门 "通关秘籍"
作为 Java 生态的 "AI 赋能利器",Spring AI 最核心的价值在于 ------让 Java 开发者无需从零学习 AI 底层技术,就能用熟悉的 Spring 生态快速构建 AI 原生应用。
在 Spring AI 基础篇系列中,我们已经手把手完成了环境搭建、基础模型调用、向量存储集成等实操内容。但很多开发者在落地时仍会陷入困惑:
- Spring AI 的技术架构到底是什么样的?各组件如何协同工作?
- 模型调用超时、向量维度不匹配这些高频问题,有没有根治方案?
- 基础入门后,该聚焦哪些核心技术才能真正落地实战项目?
本文作为基础篇的总结与升华,将从 "核心能力图谱→四层技术栈拆解→高频问题根治→进阶方向预告" 四个维度,帮你系统梳理 Spring AI 的知识体系,夯实基础的同时明确后续学习路径,为下一阶段的 RAG 与工具调用攻坚做好准备。
1. Spring AI 核心能力图谱与循序渐进学习路径
1.1 核心能力图谱
Spring AI 的核心能力围绕 "简化 AI 应用开发全链路" 展开,覆盖从模型调用到实战落地的关键环节,可清晰划分为四大核心模块:

1.2 阶梯式学习路径(避免跳跃式踩坑)
Spring AI 的学习无需盲目跟风,建议遵循 "基础打通→核心深化→实战落地→优化进阶" 的路径,确保每个阶段的知识都能扎实落地:
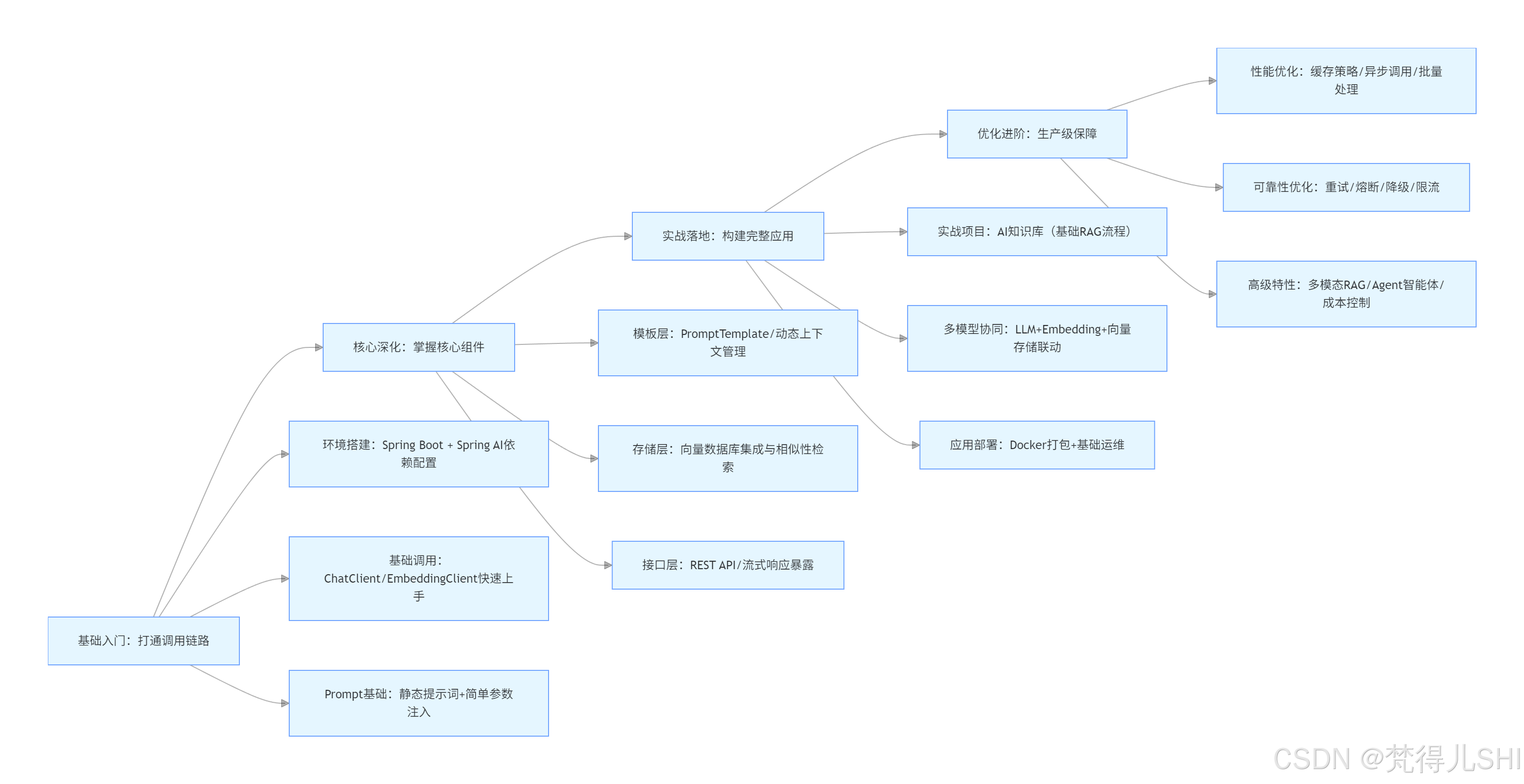
关键结论:基础篇的核心是 "打通 AI 能力的端到端调用 "------ 让你能调用模型、处理数据、存储向量、暴露接口;而进阶篇的核心是 "解决实战中的核心痛点"------ 比如 RAG 的检索精度、工具调用的灵活性、生产环境的可靠性。
2. 基础技术栈全景图:四层架构深度拆解(模型层→模板层→存储层→接口层)
Spring AI 采用 "分层设计" 思想,各层职责清晰、解耦性强,支持 "按需替换组件"(比如从 Chroma 切换到 Milvus,从 OpenAI 切换到通义千问),无需改动整体架构。以下是四层核心架构的详细拆解,含实战示例和生产级注意事项:
2.1 模型层:AI 能力的 "核心引擎"
2.1.1 核心定位
模型层是 Spring AI 的 "能力源头",负责提供 AI 基础能力(文本生成、语义向量转换、多模态处理等),是所有 AI 交互的起点。Spring AI 通过统一接口封装了不同厂商的模型,让开发者 "切换模型无需改代码"。
2.1.2 核心组件分类(含实战配置)
| 模型类型 | 核心作用 | 常用实现 | 配置示例(application.yml) |
|---|---|---|---|
| 大语言模型(LLM) | 文本生成、对话交互、逻辑推理 | OpenAI GPT-3.5/4、通义千问、Llama 3、Qwen | spring.ai.openai.chat.model=gpt-3.5-turbospring.ai.alibaba.tongyi.chat.model=qwen-turbo |
| 嵌入模型(Embedding) | 将文本转为向量(语义表征) | OpenAI Embeddings、Sentence-BERT、通义千问 Embedding | spring.ai.openai.embedding.model=text-embedding-3-smallspring.ai.sentence-transformer.model=all-MiniLM-L6-v2 |
| 多模态模型 | 跨模态数据处理(文本→图、语音→文) | DALL・E、通义万相、Whisper | spring.ai.openai.image.model=dall-e-3spring.ai.openai.audio.transcription.model=whisper-1 |
2.1.3 实战代码:多模型调用(OpenAI→通义千问无缝切换)
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class MultiModelDemoApplication {
public static void main(String[] args) {
SpringApplication.run(MultiModelDemoApplication.class, args);
}
// 注入ChatClient(无需关心底层是OpenAI还是通义千问)
@Bean
CommandLineRunner run(ChatClient chatClient) {
return args -> {
Prompt prompt = new Prompt("用Java代码示例说明Spring AI的模型无关性");
String response = chatClient.call(prompt);
System.out.println("AI响应:\n" + response);
};
}
}2.1.4 生产级注意事项
- 密钥安全:API 密钥避免硬编码,通过环境变量注入(如
${OPENAI_API_KEY});- 模型选择:轻量场景用 GPT-3.5-turbo/Qwen-7B(快、成本低),复杂推理用 GPT-4/Llama 3-70B(准、成本高);
- 本地模型部署:对网络依赖敏感的场景,用 Docker+Ollama 部署本地模型(如
ollama run llama3:8b),配置spring.ai.ollama.base-url=http://localhost:11434。
2.2 模板层:简化调用的 "中间件"
2.2.1 核心定位
模板层是 Spring AI 的 "简化器",封装了模型调用的复杂细节(HTTP 请求、JSON 序列化、响应解析、异常处理),提供统一的 API(ChatClient、EmbeddingClient、PromptTemplate),让开发者无需关注底层实现,专注业务逻辑。
2.2.2 核心组件与实战示例
| 模板组件 | 核心作用 | 实战场景 |
|---|---|---|
ChatClient |
LLM 调用模板(同步 / 流式) | 聊天机器人、文本摘要、代码生成 |
EmbeddingClient |
文本→向量转换(单文本 / 批量) | RAG 检索、语义相似度计算 |
PromptTemplate |
Prompt 模板化(动态参数注入) | 标准化提示词、上下文复用 |
示例 1:PromptTemplate 动态生成提示词(解决硬编码问题)
java
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.openai.OpenAiChatClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.Map;
@SpringBootApplication
public class PromptTemplateDemo {
@Bean
CommandLineRunner run(OpenAiChatClient chatClient) {
return args -> {
// 1. 定义模板(静态文本+动态参数)
String template = "作为{role},请为{company}编写一份{length}字的AI应用落地方案概述";
// 2. 动态注入参数(支持Map/实体类)
Map<String, Object> params = Map.of(
"role", "Java技术架构师",
"company", "某制造业企业",
"length", 300
);
// 3. 渲染模板并调用LLM
PromptTemplate promptTemplate = new PromptTemplate(template);
String prompt = promptTemplate.render(params);
String response = chatClient.call(prompt);
System.out.println("AI生成方案:\n" + response);
};
}
}示例 2:EmbeddingClient 批量文本转向量(RAG 前置步骤)
java
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.openai.OpenAiEmbeddingClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.List;
@SpringBootApplication
public class EmbeddingDemo {
@Bean
CommandLineRunner run(EmbeddingClient embeddingClient) {
return args -> {
// 知识库文本列表
List<String> knowledgeTexts = List.of(
"Spring AI 1.0.0版本支持向量存储集成:Milvus、Chroma、Redis Vector",
"Spring AI的ChatClient支持流式响应,通过stream()方法实现",
"PromptTemplate支持Freemarker语法,可复杂动态参数渲染"
);
// 批量转向量(OpenAI Embeddings返回1536维向量)
List<float[]> embeddings = embeddingClient.embedAll(knowledgeTexts);
// 输出向量维度(验证转换结果)
System.out.println("向量维度:" + embeddings.get(0).length);
System.out.println("第一条文本向量前10位:");
for (int i = 0; i < 10; i++) {
System.out.print(embeddings.get(0)[i] + " ");
}
};
}
}2.2.3 核心价值
- 模型无关性:切换 LLM/Embedding 模型时,调用代码无需修改(如从 OpenAiChatClient 切换到 TongyiChatClient);
- 内置最佳实践:支持流式响应、批量处理、上下文管理等,无需手动实现;
- 降低学习成本:Java 开发者用熟悉的 API 风格调用 AI 模型,无需学习模型厂商的原生 SDK。
2.3 存储层:数据持久化的 "仓库"
2.3.1 核心定位
存储层负责持久化 AI 应用中的关键数据,解决 "数据留存" 和 "高效查询" 问题,主要包括三类数据:
- 向量数据:知识库文本的语义向量(RAG 检索核心);
- 结构化数据:用户对话历史、系统配置、权限信息;
- 缓存数据:高频访问的模型响应、向量结果(提升性能、降低成本)。
2.3.2 核心存储组件对比(含选型建议)
| 存储类型 | 核心作用 | 常用实现 | 选型建议 |
|---|---|---|---|
| 向量数据库 | 向量存储 + 相似性查询(RAG 核心) | Milvus、Chroma、Redis Vector、PostgreSQL pgvector | 开发 / 测试:Chroma(轻量、易部署)生产(中小规模):Redis Vector(复用 Redis 集群)生产(大规模):Milvus(高吞吐、高可用) |
| 关系型数据库 | 结构化数据存储(对话历史 / 用户信息) | MySQL、PostgreSQL | 已有关系型数据库集群的场景,直接复用;需向量存储 + 结构化存储一体化,选 PostgreSQL(pgvector 插件) |
| 缓存数据库 | 高频数据缓存(模型响应 / 向量) | Redis | 所有场景必备,降低模型调用次数和向量转换成本 |
2.3.3 实战:Chroma 向量数据库集成(RAG 基础流程)
步骤 1:引入依赖(Maven)
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma</artifactId>
<version>1.0.0-SNAPSHOT</version> <!-- 使用最新稳定版本 -->
</dependency>步骤 2:配置 Chroma(application.yml)
bash
spring:
ai:
chroma:
host: localhost
port: 8000 # Chroma默认端口(启动命令:chroma run --host 0.0.0.0 --port 8000)
collection-name: spring_ai_knowledge # 向量集合名称(类似数据库表名)
embedding:
openai:
model: text-embedding-3-small # 统一Embedding模型步骤 3:代码实现(向量存储 + 相似性检索)
java
import org.springframework.ai.chroma.ChromaVectorStore;
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.List;
@SpringBootApplication
public class ChromaVectorStoreDemo {
@Bean
CommandLineRunner run(ChromaVectorStore vectorStore, EmbeddingClient embeddingClient) {
return args -> {
// 1. 知识库文本(模拟业务场景中的文档)
List<String> knowledgeTexts = List.of(
"Spring AI的核心特性:模型集成、向量存储、RAG、工具调用",
"Spring AI支持Spring Boot自动配置,引入依赖即可使用",
"Chroma是轻量级向量数据库,适合开发测试和小规模生产环境"
);
// 2. 文本→向量并存储到Chroma(带原始文本元数据)
vectorStore.add(embeddingClient.embedAll(knowledgeTexts), knowledgeTexts);
System.out.println("向量存储完成,共存储" + knowledgeTexts.size() + "条数据");
// 3. RAG检索:根据用户问题匹配相似文本
String userQuery = "Spring AI有哪些核心特性?";
float[] queryEmbedding = embeddingClient.embed(userQuery);
// 相似性检索(返回Top2最相似结果)
List<String> similarTexts = vectorStore.similaritySearch(queryEmbedding, 2);
// 4. 输出检索结果(后续可拼接Prompt调用LLM生成答案)
System.out.println("\n用户问题:" + userQuery);
System.out.println("相似知识库文本:");
similarTexts.forEach(text -> System.out.println("- " + text));
};
}
}2.4 接口层:AI 能力的 "对外出口"
2.4.1 核心定位
接口层负责将 Spring AI 的 AI 能力暴露给外部(前端应用、其他微服务),通过标准接口提供服务,是 AI 应用与外部交互的桥梁。Spring AI 无缝集成 Spring MVC/WebFlux,让开发者用熟悉的方式暴露 API。
2.4.2 核心接口类型与实战示例
| 接口类型 | 核心作用 | 实现方式 | 实战场景 |
|---|---|---|---|
| REST API | 同步 AI 服务(文本生成、检索) | Spring MVC | 前端表单提交、批量数据处理 |
| SSE/WebSocket | 流式 AI 服务(实时聊天、逐步生成) | Spring WebFlux + SSE | 聊天机器人、长文本生成、实时日志 |
示例 1:REST API 暴露 AI 聊天服务(带权限控制 + 异常处理)
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.web.bind.annotation.*;
import java.util.Map;
// 全局异常处理
@RestControllerAdvice
class AIChatExceptionHandler {
@ExceptionHandler(Exception.class)
public Map<String, Object> handleException(Exception e) {
return Map.of("code", 500, "msg", "AI服务异常:" + e.getMessage(), "data", null);
}
}
// AI聊天接口(带Spring Security权限控制)
@RestController
@RequestMapping("/api/ai")
public class AIChatController {
private final ChatClient chatClient;
public AIChatController(ChatClient chatClient) {
this.chatClient = chatClient;
}
// 需ROLE_USER角色才能访问
@PreAuthorize("hasRole('USER')")
@GetMapping("/chat")
public Map<String, Object> chat(
@RequestParam String role, // 角色(如技术顾问)
@RequestParam String question // 用户问题
) {
// Prompt模板化
String template = "作为{role},简洁回答问题:{question}(回答不超过100字)";
String prompt = new PromptTemplate(template).render(Map.of("role", role, "question", question));
// 调用LLM
String answer = chatClient.call(prompt);
return Map.of("code", 200, "msg", "success", "data", answer);
}
}示例 2:SSE 流式响应(聊天机器人实时生成)
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/api/ai")
public class AISteamController {
private final ChatClient chatClient;
public AISteamController(ChatClient chatClient) {
this.chatClient = chatClient;
}
// SSE流式响应:MediaType.TEXT_EVENT_STREAM
@GetMapping(value = "/stream-chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamChat(@RequestParam String question) {
Prompt prompt = new Prompt("详细回答问题:" + question);
// 流式调用:返回Flux<String>,前端逐字渲染
return chatClient.stream(prompt)
.map(chatResponse -> "data: " + chatResponse.getResult().getOutput().getContent() + "\n\n");
}
}2.4.3 生产级必备配置
- 限流:通过 Spring Cloud Gateway 或 Resilience4j 实现限流(如
spring.cloud.gateway.routes[0].filters[0]=RequestRateLimiter=redis-rate-limiter.replenishRate=10,redis-rate-limiter.burstCapacity=20);- 权限:敏感 AI 服务(如代码生成、数据处理)需集成 Spring Security+JWT,避免未授权访问;
- 监控:通过 Spring Boot Actuator 暴露监控指标(如模型调用次数、响应时间),结合 Prometheus+Grafana 可视化。
3. 常见问题答疑:三大高频坑根治方案
基础篇实践中,开发者最常踩的坑集中在 "模型调用超时""向量维度不匹配""依赖冲突" 三类。以下是问题根源分析和可直接落地的解决方案(按 "根源→解决方案→验证方法" 结构呈现):
3.1 坑 1:模型调用超时(最高频,占比 60%+)
3.1.1 核心根源
- 网络问题:境外模型(OpenAI)国内网络延迟高、丢包率高;
- 模型负载:GPT-4 等热门模型高峰期处理慢,超出默认超时时间;
- 请求过大:单次请求文本过长(如上万字),模型处理耗时超阈值。
3.1.2 根治方案(按优先级排序)
方案 1:配置超时重试 + 合理超时时间
bash
spring:
ai:
openai:
base-url: https://api.openai.com/v1 # 国内用户可配置合规代理
chat:
timeout: 60000 # 超时时间延长至60秒(默认30秒)
retry:
max-attempts: 3 # 最多重试3次
initial-interval: 1000 # 首次重试间隔1秒
multiplier: 2 # 重试间隔倍增(1→2→4秒)
retry-on: [CONNECT_TIMEOUT, READ_TIMEOUT] # 仅对超时异常重试方案 2:切换国内模型(彻底解决网络问题)
国内开发者优先选择通义千问、文心一言等国内模型,无网络延迟问题:
bash
spring:
ai:
alibaba:
tongyi:
api-key: ${TONGYI_API_KEY} # 环境变量注入密钥
chat:
model: qwen-turbo # 通义千问轻量版(响应快、成本低)
timeout: 30000方案 3:优化请求参数(减少模型处理压力)
- 拆分长文本:将上万字的输入拆分为多个短文本,分批调用;
- 降低模型复杂度:非关键场景从 GPT-4 降级为 GPT-3.5-turbo,响应速度提升 50%+;
- 流式调用:长文本生成场景用
chatClient.stream(),避免等待完整响应。
方案 4:本地部署模型(无网络依赖)
对响应速度和网络稳定性要求高的场景,用 Ollama 部署本地模型:
bash
# 1. 安装Ollama(官网:https://ollama.com/)
# 2. 拉取并启动Llama 3 8B模型
ollama run llama3:8b
bash
# 配置本地模型
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: llama3:8b
timeout: 120000 # 本地模型处理慢,超时适当延长3.1.3 验证方法
- 查看日志:确认重试机制生效(如 "Retry attempt 1 for exception: ReadTimeoutException");
- 压测工具:用 JMeter 模拟 10 并发请求,观察响应时间是否在超时阈值内;
- 本地模型:断开网络后仍能正常调用,说明本地部署生效。
3.2 坑 2:向量维度不匹配(RAG 场景高频)
3.2.1 核心根源
- 模型不一致:存储向量时用的 Embedding 模型(如 OpenAI Embeddings,1536 维)与检索时的模型(如 Sentence-BERT,768 维)不一致;
- 模型版本变更:同一模型不同版本维度不同(如 OpenAI Embeddings v1 是 1536 维,v2 是 2048 维);
- 手动修改向量:自定义向量时维度与数据库中存储的向量维度不匹配。
3.2.2 根治方案
方案 1:全局统一 Embedding 模型(核心)
在配置文件中明确指定 Embedding 模型,确保存储和检索用同一个:
bash
spring:
ai:
embedding:
# 统一使用OpenAI Embeddings 3 Small(1536维)
openai:
model: text-embedding-3-small
api-key: ${OPENAI_API_KEY}
# 向量数据库配置(无需单独指定维度,由Embedding模型决定)
chroma:
host: localhost
collection-name: knowledge_base方案 2:锁定模型版本(避免版本变更)
bash
spring:
ai:
embedding:
openai:
model: text-embedding-3-small # 明确版本,不使用模糊匹配方案 3:自定义向量时校验维度
手动构造向量时,需与 Embedding 模型维度一致:
java
// 错误:手动构造向量维度为768,与OpenAI的1536维不匹配
float[] customEmbedding = new float[768];
// 正确:获取模型维度后构造(以OpenAI为例)
int embeddingDimension = 1536; // 可通过模型文档查询
float[] customEmbedding = new float[embeddingDimension];方案 4:向量数据库维度校验(生产级)
部分向量数据库支持创建集合时指定维度,强制校验:
java
// Chroma创建集合时指定维度(1536维)
ChromaApi chromaApi = new ChromaApi("http://localhost:8000");
CreateCollectionRequest request = new CreateCollectionRequest();
request.setName("knowledge_base");
request.setMetadata(Map.of("dimension", 1536)); // 强制维度为1536
chromaApi.createCollection(request);3.2.3 验证方法
打印向量维度:存储和检索时打印向量长度,确认一致:
javafloat[] embedding = embeddingClient.embed("测试文本"); System.out.println("向量维度:" + embedding.length); // 输出1536数据库查询:通过向量数据库 API 查询集合元数据,确认维度正确(如 Chroma:
chroma get-collection --name knowledge_base)。
3.3 坑 3:依赖冲突(新手高频)
3.3.1 核心根源
- Spring 版本不兼容:Spring AI 1.0.0 + 要求 Spring Boot 3.2+,低版本 Spring Boot 会导致依赖冲突;
- 重复依赖:同时引入多个模型的 SDK(如
spring-ai-openai和openai-java),导致类冲突;- 版本不一致:Spring AI 相关依赖版本不统一(如
spring-ai-core是 1.0.0,spring-ai-chroma是 0.9.0)。
3.3.2 根治方案
方案 1:统一 Spring Boot 版本(3.2+)
XML
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version> <!-- 必须3.2+,推荐最新稳定版 -->
<relativePath/>
</parent>方案 2:用 Spring AI BOM 统一版本
通过 BOM 管理所有 Spring AI 相关依赖,避免版本不一致:
XML
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version> <!-- 统一版本 -->
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 引入依赖时无需指定版本 -->
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma</artifactId>
</dependency>
</dependencies>方案 3:排除冲突依赖
若存在重复依赖(如同时引入spring-ai-openai和openai-java),排除冲突项:
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai</artifactId>
<exclusions>
<exclusion>
<groupId>com.theokanning.openai-gpt3-java</groupId>
<artifactId>api</artifactId>
</exclusion>
</exclusions>
</dependency>方案 4:使用mvn dependency:tree分析冲突
通过 Maven 命令查看依赖树,定位冲突根源:
bash
mvn dependency:tree | grep openai # 查找所有openai相关依赖3.3.3 验证方法
- 启动应用:无
NoClassDefFoundError或ClassCastException异常;- 依赖树检查:确认所有 Spring AI 相关依赖版本一致;
- 功能测试:模型调用、向量存储 / 检索功能正常。
4. 下阶段预告:核心技术攻坚之 RAG 与工具调用
基础篇的学习让我们打通了 AI 应用的 "基础链路",但要实现真正实用的 AI 应用(如企业知识库问答、智能办公助手),还需要掌握两大核心技术:RAG(检索增强生成) 和工具调用(Function Call)。
4.1 为什么这两项技术是 "实战关键"?
- LLM 的天然缺陷:知识截止日期(如 GPT-3.5 截止 2023 年 9 月)、无法访问实时数据、不了解企业内部知识;
- RAG 的价值:通过 "检索外部知识库 + 拼接 Prompt",让 LLM 能回答实时数据、企业内部知识,解决 "知识过期" 问题;
- 工具调用的价值:让 LLM 能调用外部工具(如数据库查询、API 调用、文件处理),解决 "无法执行具体操作" 的问题(如 "查询 2024 年 10 月的销售额"→ 调用数据库工具执行 SQL)。
4.2 下阶段学习重点
4.2.1 RAG 核心攻坚
- 进阶知识点:
- 文档加载与分割(PDF/Word/TXT→chunk 拆分,解决长文档处理问题);
- 检索优化(混合检索:向量检索 + 关键词检索,提升精度);
- Prompt 优化(检索结果拼接策略、上下文压缩);
- 评估与调优(检索召回率、答案准确率评估方法)。
- 实战项目:企业级知识库问答系统(支持 PDF 上传、模糊查询、答案溯源)。
4.2.2 工具调用核心攻坚
- 进阶知识点:
- 工具注册与描述(如何让 LLM 理解工具功能);
- 函数参数自动填充(LLM 根据用户问题生成工具所需参数);
- 多工具协同(如 "查询销售额→生成 Excel→发送邮件");
- 错误处理(工具调用失败时的重试、降级策略)。
- 实战项目:智能办公助手(支持查询数据库、生成报表、调用 OA 接口)。
4.3 学习路径规划
- 先攻克 RAG:从基础检索→文档处理→优化调优,落地知识库问答系统;
- 再学习工具调用:从单工具调用→多工具协同→错误处理,落地智能助手;
- 融合应用:将 RAG 与工具调用结合(如 "知识库问答 + 数据库查询"),构建更强大的 AI 应用。
5. 总结:Spring AI 基础篇核心要点回顾
Spring AI 基础篇的核心是 "理解分层架构,打通端到端链路",关键要点总结如下:
- 架构层面:四层技术栈(模型层→模板层→存储层→接口层)职责清晰,支持组件替换,灵活适配不同场景;
- 核心组件:
ChatClient/EmbeddingClient简化模型调用,PromptTemplate解决提示词硬编码,向量数据库支撑 RAG,接口层实现 AI 能力对外暴露; - 避坑关键:模型调用超时用 "重试 + 国内模型 + 本地部署",向量维度不匹配用 "统一 Embedding 模型",依赖冲突用 "统一版本 + BOM 管理";
- 进阶方向:RAG 解决 "知识过期" 问题,工具调用解决 "无法执行操作" 问题,是下一阶段的核心攻坚目标。
学习 Spring AI 的过程中,建议 "边学边练"------ 每个知识点都结合实战示例验证,每个坑都亲手踩一遍再解决,这样才能真正掌握。基础篇的知识是后续进阶的基石,只有夯实基础,才能在 RAG 和工具调用的学习中事半功倍。
如果本文对你有帮助,欢迎点赞、收藏、转发!如果有疑问或补充,欢迎在评论区交流~ 下阶段我们将深入 RAG 与工具调用,一起攻克 Spring AI 实战核心技术!
附录:Spring AI 基础篇常用依赖速查表
| 功能 | Maven 依赖 |
|---|---|
| Spring AI 核心依赖 | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-core</artifactId></dependency> |
| OpenAI 集成 | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai</artifactId></dependency> |
| 通义千问集成 | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-alibaba-tongyi</artifactId></dependency> |
| Chroma 向量数据库 | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-chroma</artifactId></dependency> |
| Redis Vector | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-redis</artifactId></dependency> |
| Prompt 模板 | <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-prompt</artifactId></dependency> |
| WebFlux(流式响应) | <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency> |
