作者:来自 Elastic Mike Pellegrini

探索如何在 Elasticsearch 中使用适用于 linear 和 RRF retrievers 的多字段查询格式来简化混合搜索,并在对你的 Elasticsearch 索引没有任何先验知识的情况下创建查询。
Elasticsearch 充满了新特性,可以帮助你为你的使用场景构建最佳搜索解决方案。了解如何在我们关于构建现代 Search AI 体验的动手网络研讨会上将它们付诸实践。你也可以立即开始免费云试用,或在本地机器上试用 Elastic。
混合搜索被广泛认为是一种强大的搜索方法,它将词法搜索的精确性和速度与语义搜索的自然语言能力结合在一起。然而,在实践中应用它可能很棘手,通常需要对你的索引有深入了解,并构建冗长且包含非平凡配置的查询。在这篇博客中,我们将探索用于 linear 和 RRF retrievers 的多字段查询格式如何让混合搜索变得更简单、更容易接近,消除常见的麻烦,并让你更轻松地充分利用它的强大能力。我们还将回顾多字段查询格式如何让你在对你的索引没有任何先验知识的情况下执行混合搜索查询。
分数范围问题

为了铺垫背景,让我们先回顾一下混合搜索之所以困难的主要原因之一:分数范围不同。我们熟悉的 BM25 会产生无上限的分数。换句话说,BM25 可以生成从接近 0 到(理论上)无限大的分数。相比之下,对 dense_vector 字段的查询会产生介于 0 到 1 之间的分数。更让问题复杂的是,semantic_text 会隐藏用于索引 embedding 的字段类型,因此除非你对索引和推理(inference)端点配置非常了解,否则很难知道查询的分数范围。这在尝试交错展示词汇和语义搜索结果时会造成问题,因为词法结果可能会压过语义结果,即使语义结果更相关。解决这个问题的通用方法是在交错结果之前对分数进行归一化。Elasticsearch 为此提供了两个工具:linear 和 RRF 检索器。
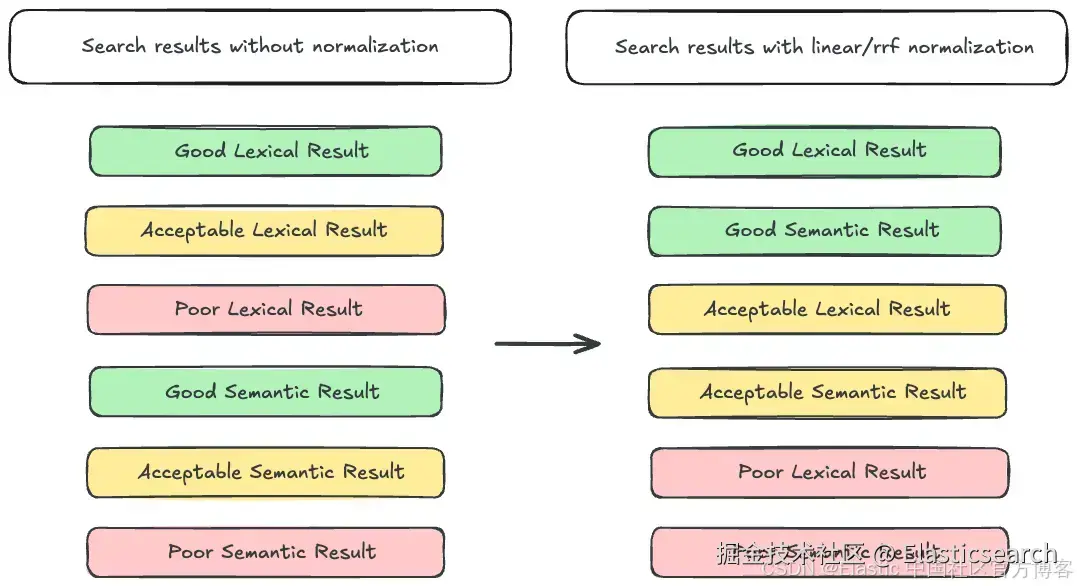
RRF 检索器使用 RRF 算法,用文档的排序作为相关性的衡量,并丢弃 score。因为不考虑 score,score 范围不一致就不会造成问题。
Linear 检索器使用线性组合来决定文档的最终 score。它会取每个子查询对文档的 score,先做归一化,然后把它们相加得到总 score。数学上可以表示为:
ini
`Total Score = 𝚺(N(Sx))`AI写代码其中 N 是归一化函数,SX 是查询 X 的分数。归一化函数在这里非常关键,因为它会把每个查询的分数转换到同一个范围。你可以在这里了解更多关于 linear retriever 的信息。
分解说明
用户可以使用这些工具实现有效的混合搜索,但这需要对你的索引有一定了解。让我们来看一个使用 linear retriever 的例子,在这个例子中,我们将查询一个包含两个字段的索引:
bash
`
1. PUT linear_retriever_example
2. {
3. "mappings": {
4. "properties": {
5. "semantic_text_field": { <1>
6. "type": "semantic_text",
7. "inference_id": ".multilingual-e5-small-elasticsearch"
8. },
9. "text_field": { <2>
10. "type": "text"
11. }
12. }
13. }
14. }
`AI写代码
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "retrievers": [
6. {
7. "retriever": {
8. "standard": {
9. "query": {
10. "match": { <1>
11. "semantic_text_field": "foo"
12. }
13. }
14. }
15. },
16. "normalizer": "minmax"
17. },
18. {
19. "retriever": {
20. "standard": {
21. "query": {
22. "match": {
23. "text_field": "foo"
24. }
25. }
26. }
27. },
28. "normalizer": "minmax"
29. }
30. ]
31. }
32. }
33. }
`AI写代码- 我们在 semantic_text 字段上使用 match 查询,这在 Elasticsearch 8.18/9.0 中得到支持
在构建查询时,我们需要注意 semantic_text_field 使用了文本嵌入模型,因此对它的任何查询都会生成 0 到 1 之间的分数。我们还需要知道 text_field 是标准文本字段,因此对它的查询会生成不受限制的分数。为了创建具有适当相关性的结果集,我们需要使用一个在合并查询前会对查询分数进行归一化的 retriever。在这个例子中,我们使用带有 minmax 归一化的 linear retriever,它会将每个查询的分数归一化到 0 到 1 之间。
这个例子中的查询构建相对简单,因为只涉及两个字段。然而,随着更多字段和不同类型字段的加入,情况会迅速变得复杂。这展示了编写有效的 hybrid search 查询通常需要对被查询索引有更深入的了解,以便在组合之前正确归一化各个组件查询的分数。这对 hybrid search 的更广泛采用构成了障碍。
查询分组
让我们扩展这个例子:如果我们想查询一个文本字段和两个 semantic_text 字段怎么办?我们可以构建如下查询:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "retrievers": [
6. {
7. "retriever": {
8. "standard": {
9. "query": {
10. "semantic": {
11. "field": "semantic_text_field_1",
12. "query": "foo"
13. }
14. }
15. }
16. },
17. "normalizer": "minmax"
18. },
19. {
20. "retriever": {
21. "standard": {
22. "query": {
23. "semantic": {
24. "field": "semantic_text_field_2",
25. "query": "foo"
26. }
27. }
28. }
29. },
30. "normalizer": "minmax"
31. },
32. {
33. "retriever": {
34. "standard": {
35. "query": {
36. "match": {
37. "text_field": "foo"
38. }
39. }
40. }
41. },
42. "normalizer": "minmax"
43. }
44. ]
45. }
46. }
47. }
`AI写代码表面上看起来没问题,但存在潜在问题。现在 semantic_text 字段的匹配占总分的 ⅔:
scss
`Total Score = N(semantic_text_field_1 score) + N(semantic_text_field_2 score) + N(text_field score)`AI写代码这可能不是你想要的,因为它会造成分数不平衡。在像这个只有 3 个字段的示例中,影响可能不太明显,但当查询更多字段时就会成为问题。例如,大多数索引包含的词汇字段远多于语义字段(即 dense_vector、sparse_vector 或 semantic_text)。如果我们用上面的模式查询一个有 9 个词汇字段和 1 个语义字段的索引呢?词汇匹配将占总分的 90%,削弱语义搜索的效果。
解决这个问题的常用方法是将查询分组为词汇和语义类别,并均匀加权两者。这可以防止任一类别主导总分。
让我们来实践一下。当使用 linear retriever 时,这种分组查询方法在这个示例中会是什么样子?
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "retrievers": [
6. {
7. "retriever": {
8. "linear": {
9. "retrievers": [
10. {
11. "retriever": {
12. "standard": {
13. "query": {
14. "semantic": {
15. "field": "semantic_text_field_1",
16. "query": "foo"
17. }
18. }
19. }
20. },
21. "normalizer": "minmax"
22. },
23. {
24. "retriever": {
25. "standard": {
26. "query": {
27. "semantic": {
28. "field": "semantic_text_field_2",
29. "query": "foo"
30. }
31. }
32. }
33. },
34. "normalizer": "minmax"
35. }
36. ]
37. }
38. },
39. "normalizer": "minmax"
40. },
41. {
42. "retriever": {
43. "standard": {
44. "query": {
45. "match": {
46. "text_field": "foo"
47. }
48. }
49. }
50. },
51. "normalizer": "minmax"
52. }
53. ]
54. }
55. }
56. }
`AI写代码收起代码块哇,这变得很啰嗦了!你甚至可能需要上下滚动多次才能查看完整查询!在这里,我们使用两个层次的归一化来创建查询分组。数学上可以表示为:
scss
`Total Score = N(N(semantic_text_field_1 score) + N(semantic_text_field_2 score)) + N(text_field score)`AI写代码第二层归一化确保了对 semantic_text 字段和 text 字段的查询权重均衡。注意,在这个示例中,我们省略了 text_field 的第二层归一化,因为只有一个词汇字段,这样可以避免更多冗长。
这个查询结构已经很笨重了,而且我们只查询了三个字段。随着查询更多字段,即使是经验丰富的搜索从业者,也会变得越来越难以管理。
多字段查询格式

在 Elasticsearch 8.19、9.1 和 serverless 中,我们为 linear 和 RRF retrievers 添加了多字段查询格式,以简化这一切。你现在只需使用以下方式执行上面的相同查询:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "fields": [ "semantic_text_field_1", "semantic_text_field_2", "text_field" ]
6. "query": "foo",
7. "normalizer": "minmax"
8. }
9. }
10. }
`AI写代码这将查询从 55 行缩减到仅 9 行!Elasticsearch 会自动使用索引映射来:
- 确定每个查询字段的类型
- 将每个字段分组为 lexical 或 semantic 类别
- 在最终得分中均匀加权每个类别
这允许任何人执行有效的 hybrid search 查询,而无需了解索引或使用的 inference endpoints 的详细信息。
在使用 RRF 时,你可以省略 normalizer,因为 rank 被用作相关性的代理:
bash
`
1. GET rrf_retriever_example/_search
2. {
3. "retriever": {
4. "rrf": {
5. "fields": [ "semantic_text_field_1", "semantic_text_field_2", "text_field" ]
6. "query": "foo"
7. }
8. }
9. }
`AI写代码按字段加权
在使用 linear retriever 时,你可以对每个字段应用 boost,以调整某些字段匹配的重要性。例如,假设你正在查询四个字段:两个 semantic_text 字段和两个 text 字段:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "fields": [ "semantic_text_field_1", "semantic_text_field_2", "text_field_1", "text_field_2" ]
6. "query": "foo",
7. "normalizer": "minmax"
8. }
9. }
10. }
`AI写代码默认情况下,每个字段在其组(lexical 或 semantic)中权重相等。得分分布如下:

换句话说,每个字段占总分的 25%。
我们可以使用 field^boost 语法为任意字段添加单字段提升。我们给 semantic_text_field_1 和 text_field_1 应用提升 2:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "fields": [ "semantic_text_field_1^2", "semantic_text_field_2", "text_field_1^2", "text_field_2" ]
6. "query": "foo",
7. "normalizer": "minmax"
8. }
9. }
10. }
`AI写代码现在分数分布如下:
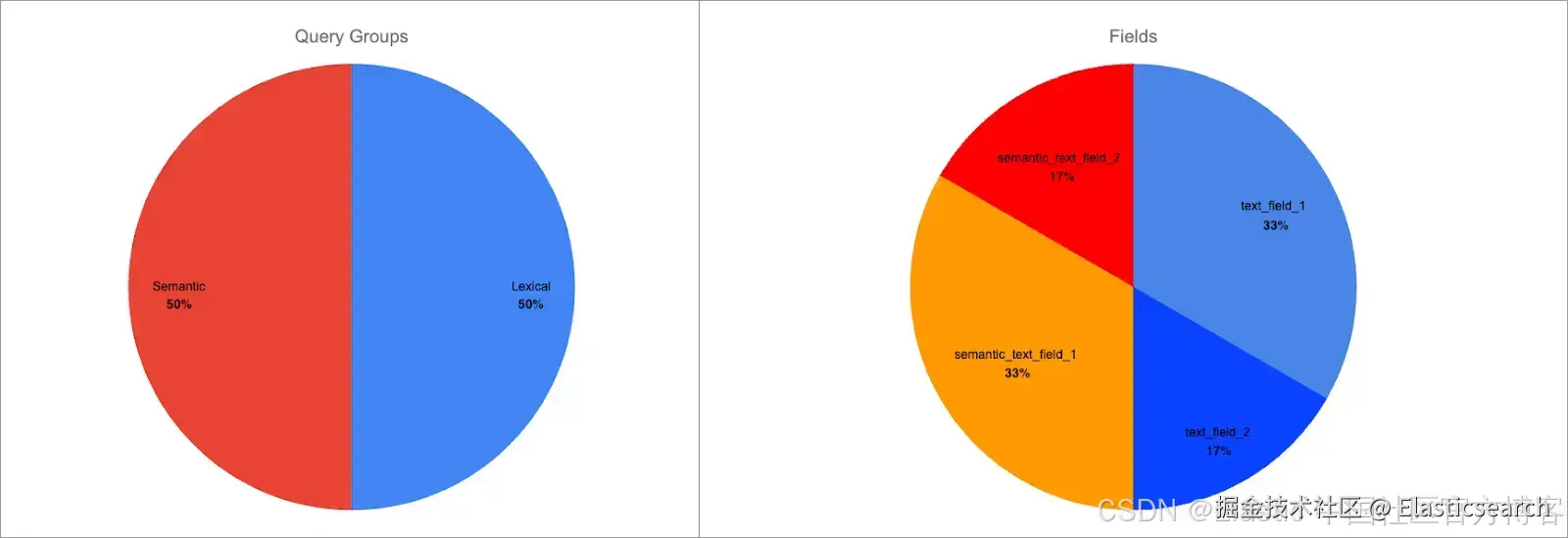
每个查询组仍然权重相等,但组内字段权重已更改:
- semantic_text_field_1 占语义查询组分数的 66%,占总分的 33%
- text_field_1 占词汇查询组分数的 66%,占总分的 33%
ℹ️ 注意,当应用每字段提升时,总分范围不会改变。这是分数归一化的预期副作用,它确保词汇查询和语义查询的分数仍然可以直接比较。
ℹ️ 每字段提升也可以在 Elasticsearch 9.2+ 中与 RRF retriever 一起使用。
通配符解析
你可以在 fields 参数中使用 * 通配符来匹配多个字段。延续上面的例子,这个查询在功能上等同于显式查询 semantic_text_field_1、semantic_text_field_2 和 text_field_1:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "fields": [ "semantic_text_field_*", "*_field_1" ]
6. "query": "foo",
7. "normalizer": "minmax"
8. }
9. }
10. }
`AI写代码有趣的是,*_field_1 模式同时匹配 text_field_1 和 semantic_text_field_1。这会被自动处理;查询将像显式查询每个字段一样执行。同样没问题,semantic_text_field_1 同时匹配两个模式;所有字段名匹配在查询执行前都会去重。
你可以以多种方式使用通配符:
- 前缀匹配(例如:text_field)
- _内联匹配(例如:semantic___field)
- 后缀匹配(例如:semantic_text_field*)
你也可以使用多个通配符来组合上述方式,例如 text_field。
默认查询字段
多字段查询格式还允许你查询一个你一无所知的索引。如果省略 fields 参数,它将查询 index.query.default_field 索引设置中指定的所有字段:
bash
`
1. GET linear_retriever_example/_search
2. {
3. "retriever": {
4. "linear": {
5. "query": "foo",
6. "normalizer": "minmax"
7. }
8. }
9. }
`AI写代码默认情况下,index.query.default_field 设置为 *。这个通配符会解析为索引中支持 term 查询的所有字段类型,大多数字段都支持。例外包括:
- dense_vector 字段
- rank_vector 字段
- 几何字段:geo_point、shape
当你想对第三方提供的索引执行混合搜索查询时,这个功能尤其有用。多字段查询格式允许你以简单的方式执行合适的查询。只需省略 fields 参数,所有适用字段都会被查询。
结论
分数范围问题可能会让有效的混合搜索实现变得头疼,尤其是在对查询的索引或使用的推理端点了解有限的情况下。线性和 RRF 检索器的多字段查询格式通过将基于查询分组的混合搜索方法打包到一个简单易用的 API 中,缓解了这一问题。额外功能,如按字段提升、通配符解析和默认查询字段,扩展了功能以覆盖多种使用场景。
今天就试试多字段查询格式
你可以在完全托管的 Elasticsearch Serverless 项目中,通过免费试用检查多字段查询格式的线性和 RRF 检索器。它也适用于从 8.19 & 9.1 开始的堆栈版本。
在本地环境中,只需一个命令即可在几分钟内开始:
sql
`curl -fsSL https://elastic.co/start-local | sh`AI写代码