一、拆分:从 "单体瓶颈" 到 "分布式承载"
拆分的核心目标是将单节点 / 单集群的压力,分散到多节点 / 多分片,同时利用云原生的弹性能力降低运维复杂度。
1. 服务拆分(微服务 + 云原生负载均衡)
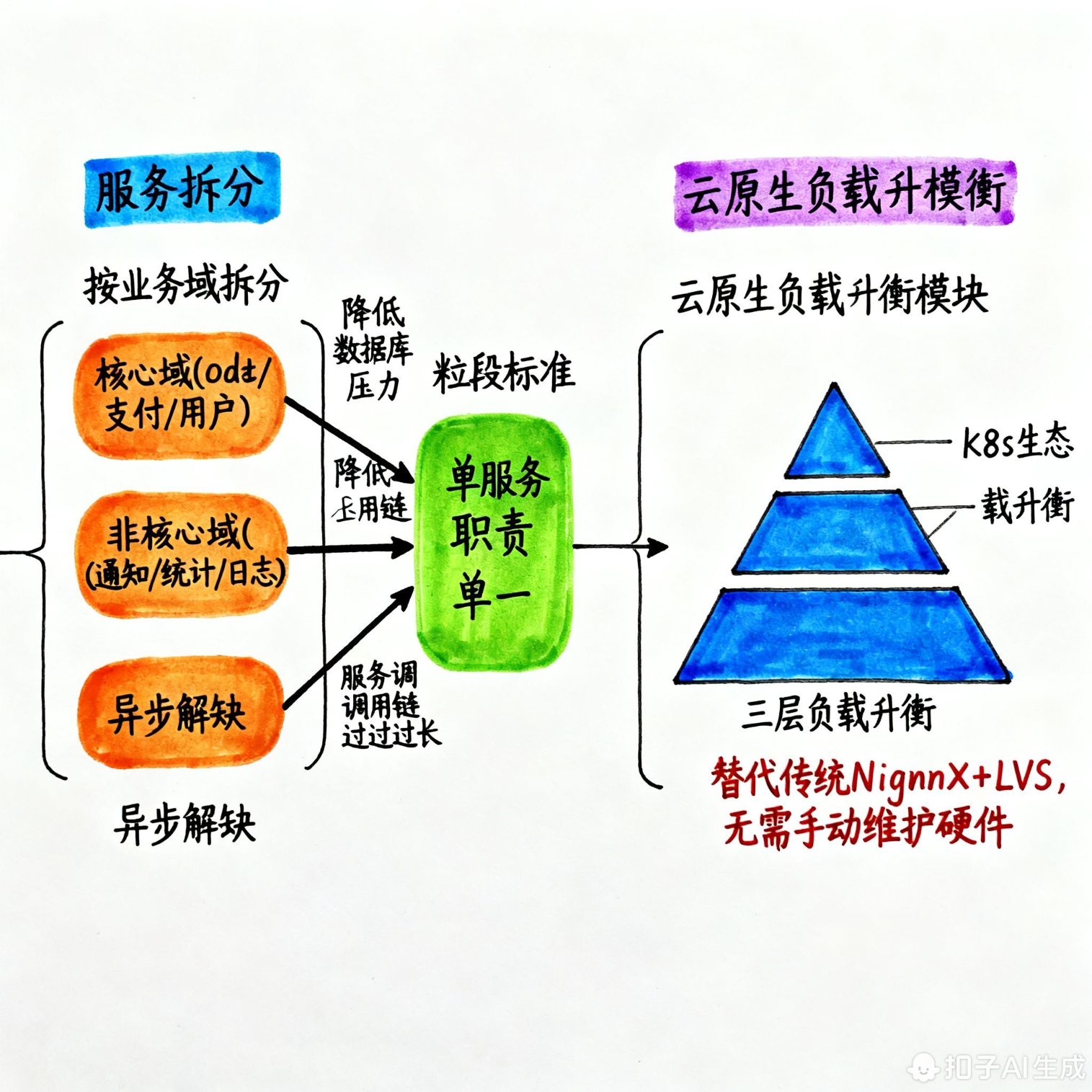
(1)拆分逻辑
- 按 "业务域" 拆分:核心域(订单、支付、用户)独立服务,降低各自数据库压力;非核心域(通知、统计、日志)异步解耦;
- 粒度标准:单服务职责单一(如 "订单服务" 仅处理订单创建、状态更新),服务间调用链不宜过长(避免 latency 累积)。
(2)云原生负载均衡方案(替代传统 Nginx+LVS)
云原生环境下,负载均衡分 3 层,完全依托 K8s 生态,无需手动维护硬件负载:
| 层级 | 组件 | 作用 | 核心配置 |
|---|---|---|---|
| 入口层 | 云厂商 LB(如阿里云 ALB、AWS ALB) | 集群入口,TCP/HTTP 负载均衡,抗 DDoS | 监听 80/443 端口,转发到 K8s Service |
| 集群层 | K8s Service(NodePort/ClusterIP) | 服务发现 + 内部负载均衡 | 匹配 Pod 标签,采用轮询 / 会话亲和性(可选) |
| 服务层 | Istio/Linkerd | 细粒度流量控制(按权重路由、灰度发布) | 基于 CRD 配置路由规则,无需修改服务代码 |
落地示例 :用户下单请求链路:云LB → Istio Ingress Gateway → 订单Service → 订单Pod集群
- Istio 负责:流量路由(如 10% 流量到新版本 Pod)、超时重试(接口超时 2s 自动重试 1 次)、监控埋点(全链路追踪);
- K8s 负责:Pod 弹性伸缩(CPU>70% 时自动扩容 Pod 数量,扩容上限 = 20 副本)。
2. 数据库拆分(分库分表 + 分布式事务)
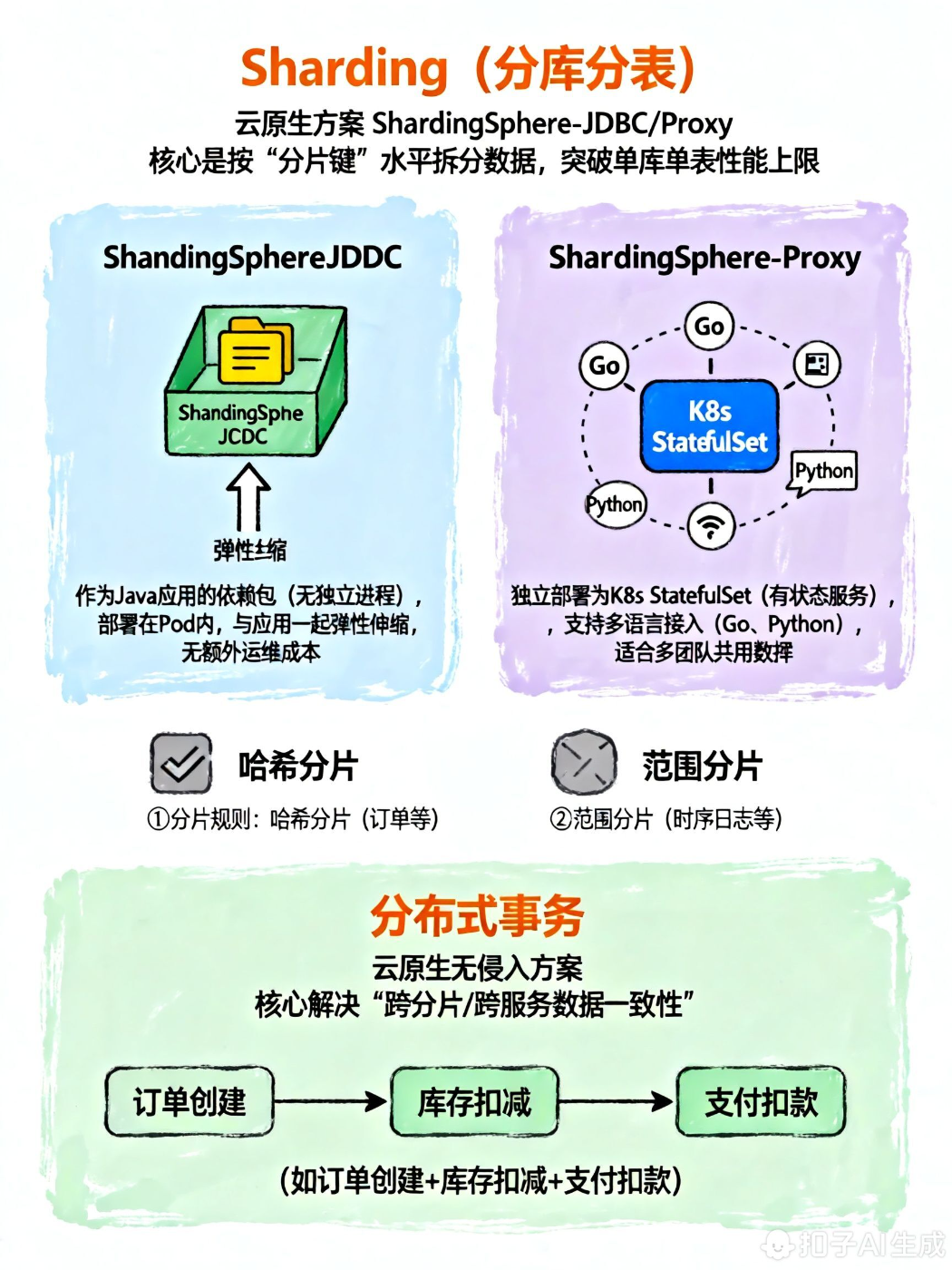
(1)Sharding(分库分表):云原生方案 ShardingSphere-JDBC/Proxy
核心是按 "分片键" 水平拆分数据,突破单库单表性能上限。
① 分片规则
| 分片维度 | 适用场景 | 示例(订单表) | 优点 |
|---|---|---|---|
| 哈希分片(用户 ID 取模) | 用户相关数据(订单、购物车) | 分 8 库 16 表:库索引=user_id%8,表索引=user_id%16 |
数据分布均匀,扩容方便(翻倍扩容无数据迁移) |
| 范围分片(时间) | 日志、账单等时序数据 | 按月份分表:t_order_202501、t_order_202502 |
查询时按时间过滤,减少扫描分片 |
② 云原生部署方式
- ShardingSphere-JDBC:作为 Java 应用的依赖包(无独立进程),部署在 Pod 内,与应用一起弹性伸缩,无额外运维成本;
- ShardingSphere-Proxy:独立部署为 K8s StatefulSet(有状态服务),支持多语言接入(Go、Python),适合多团队共用数据库网关。
核心配置(ShardingSphere-JDBC + K8s ConfigMap):将分片规则配置在 ConfigMap 中,Pod 挂载后动态生效,无需重启应用:
# ConfigMap配置分片规则
apiVersion: v1
kind: ConfigMap
metadata:
name: sharding-config
data:
application.yml: |
spring:
shardingsphere:
mode:
type: Cluster # 集群模式(适配K8s)
rules:
sharding:
tables:
t_order:
actual-data-nodes: db${0..7}.t_order${0..15}
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: order_db_hash
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: order_table_hash
sharding-algorithms:
order_db_hash:
type: HASH_MOD
props:
sharding-count: 8
order_table_hash:
type: HASH_MOD
props:
sharding-count: 16(2)分布式事务:云原生无侵入方案
核心解决 "跨分片 / 跨服务数据一致性"(如订单创建 + 库存扣减 + 支付扣款),云原生场景优先选择以下 2 种方案:
| 方案 | 组件 | 适用场景 | 核心逻辑 | 云原生适配 |
|---|---|---|---|---|
| 柔性事务(AT 模式) | Seata | 核心业务(订单、支付),要求最终一致性 + 低侵入 | 1. 业务代码加@GlobalTransactional;2. Seata Server 部署为 K8s StatefulSet;3. 自动生成 undo_log,异常时回滚 |
支持 K8s 服务发现,事务日志存储在云原生存储(如 MinIO) |
| 事务消息 | RocketMQ/Kafka | 非核心业务(订单通知、积分发放),允许短时间不一致 | 1. 生产者发送 "半消息";2. 本地事务执行成功后确认消息;3. 消费者消费消息,失败时重试 | 消息队列部署为 K8s 集群,支持分区扩容,应对高并发消息生产 |
// 订单服务(Seata AT模式)
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private InventoryFeignClient inventoryFeignClient; // 库存服务Feign客户端
// 全局事务注解,Seata自动协调订单+库存事务
@GlobalTransactional(timeout = 3000)
public void createOrder(OrderDTO orderDTO) {
// 1. 本地事务:创建订单(订单库分片)
orderMapper.insert(orderDTO);
// 2. 跨服务调用:扣减库存(库存库分片)
boolean deductSuccess = inventoryFeignClient.deductStock(orderDTO.getProductId(), orderDTO.getQuantity());
if (!deductSuccess) {
throw new RuntimeException("库存不足,事务回滚");
}
}
}二、缓冲:从 "瞬间峰值" 到 "平稳承载"
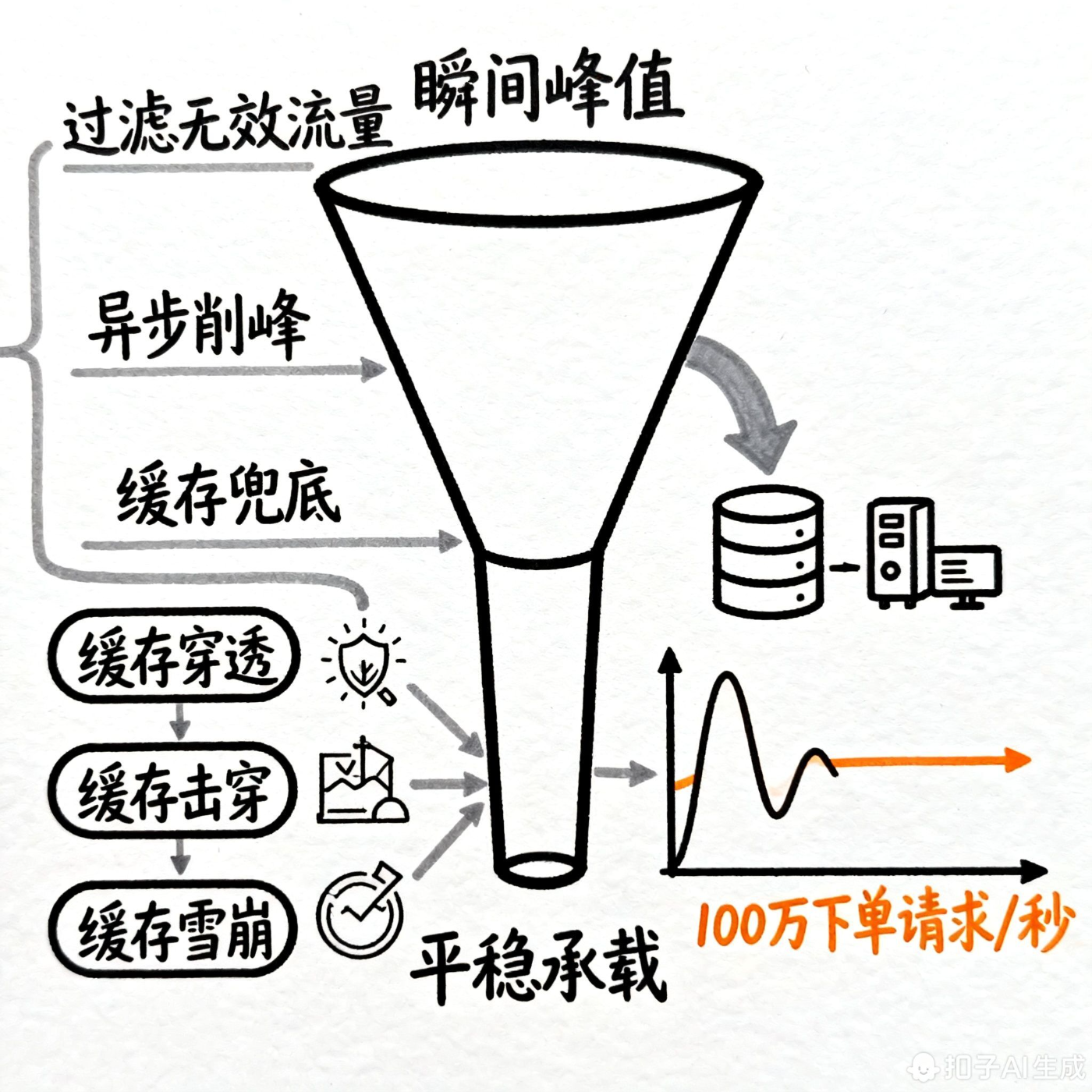
缓冲的核心是**"过滤无效流量 + 异步削峰 + 缓存兜底"**,减少核心链路(数据库、核心服务)的直接压力。
1. 过滤无效 / 非法请求(缓存 + 风控)
核心解决 "恶意请求、无效查询" 对系统的冲击,重点处理缓存三大问题:
| 问题 | 云原生解决方案 | 落地示例 |
|---|---|---|
| 缓存穿透 (查不存在的数据) | 布隆过滤器(Redis Cluster + Redisson) | 1. 启动时加载所有商品 ID 到布隆过滤器; 2. 查询商品前先校验布隆过滤器,不存在则直接返回 404 |
| 缓存击穿 (热点 key 过期) | 本地缓存(Caffeine)+ 分布式锁(Redis Redlock) | 1. Caffeine 缓存热点商品(永不过期,定时更新); 2. Redis 缓存过期时,用 Redlock 加锁,仅 1 个线程查询 DB 更新缓存 |
| 缓存雪崩 (大量 key 同时过期) | Redis Cluster + 过期时间随机值 | 1. Redis 集群避免单点; 2. 缓存过期时间 = 基础时间 + 随机值(如 30 分钟 ±5 分钟) |
云原生部署细节:
- 布隆过滤器:Redisson 集群部署在 K8s,配置
spring.redis.redisson.config加载集群地址 - 本地缓存:Caffeine 配置在应用 Pod 内,结合 K8s ConfigMap 动态调整缓存大小
2. 异步降低峰值(消息队列 + 订单场景落地)
核心是 "将同步请求转为异步消息",用消息队列的 "削峰填谷" 能力,应对秒杀、大促等瞬间高并发(如 100 万下单请求 / 秒)。
(1)订单场景异步链路设计
用户下单 → 网关限流 → 应用层校验(库存预扣减) → 发送Kafka消息 → 返回"下单中" → Kafka消费者(异步创建订单、扣减实际库存、发送通知)(2)关键问题解决(消息重复 + 堆积)
| 问题 | 原因 | 云原生解决方案 |
|---|---|---|
| 消息重复 | 生产者重试、消费者重试、网络抖动 | 1. 消息幂等性:订单表用user_id+product_id+下单时间作为唯一索引,重复消息插入失败; 2. 消费者记录消费 offset(Kafka 手动提交 offset) |
| 消息堆积 | 消费者处理速度低于生产者发送速度 | 1. 水平扩容:Kafka Topic 分区数扩容(如从 6→12),消费者 Pod 数量 = 分区数; 2. 消费降级:非核心消费逻辑(如日志上报)暂时关闭,优先处理订单创建; 3. 死信队列:失败消息转入死信 Topic,后续人工处理 |
K8s 部署配置(Kafka 消费者弹性伸缩):通过 K8s HPA(Horizontal Pod Autoscaler),根据 Kafka Topic 堆积数自动扩容消费者 Pod:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-consumer-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-consumer-deployment
minReplicas: 3
maxReplicas: 20
metrics:
- type: External
external:
metric:
name: kafka_consumergroup_lag
selector:
matchLabels:
topic: order_topic
consumergroup: order_consumer_group
target:
type: Value
value: 10000 # 堆积数超过1万时扩容三、防线:从 "过载崩溃" 到 "稳定兜底"
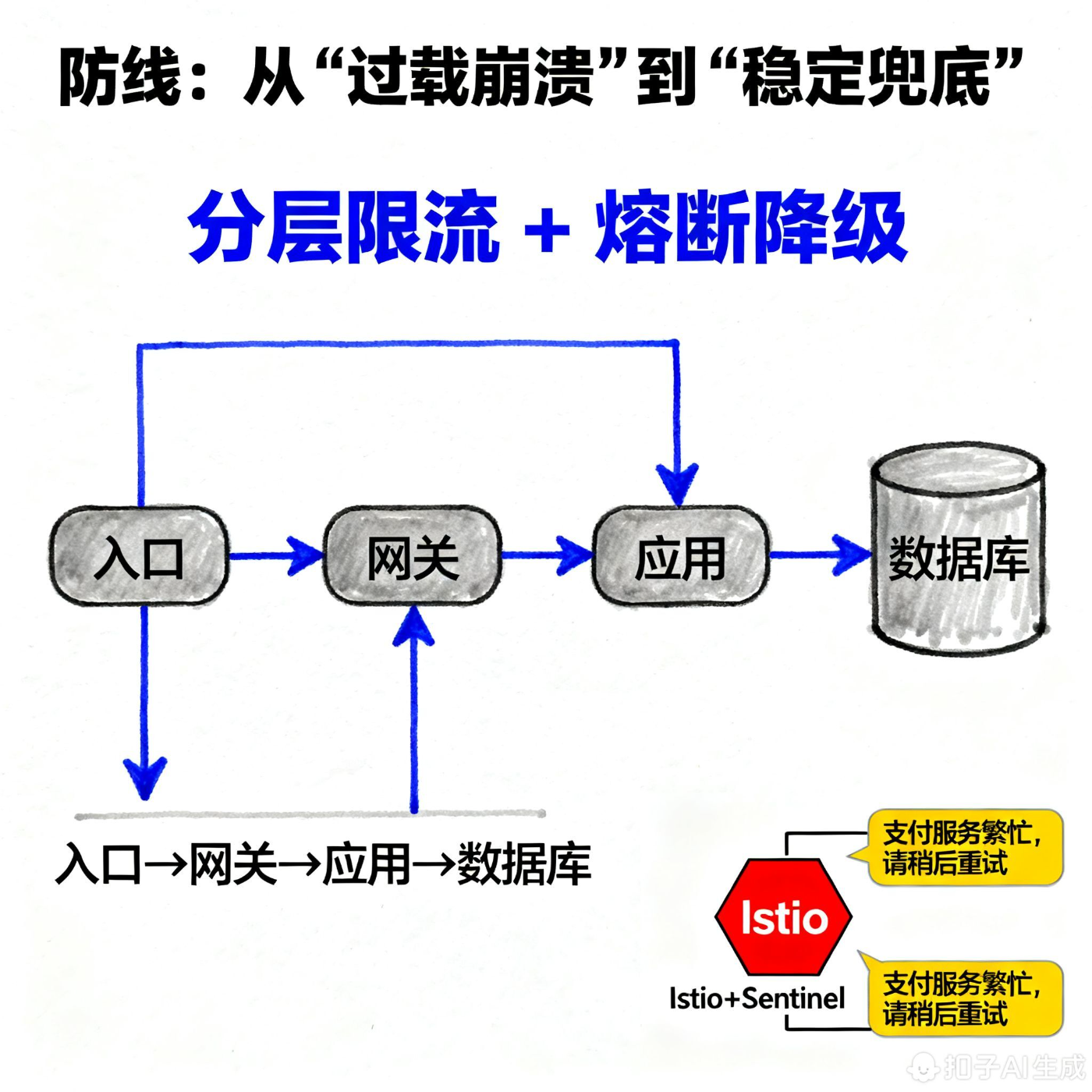
防线的核心是**"分层限流 + 熔断降级"**,提前拦截过载流量,避免某一层级故障扩散(如数据库挂了导致整个系统雪崩)。
1. 分层限流(云原生组件落地)
按 "入口→网关→应用→数据库" 分层设置限流,粒度由粗到细:
| 层级 | 组件 | 限流策略 | 示例配置 |
|---|---|---|---|
| 入口层 | 云 LB(ALB) | 单 IP 限流、全局限流 | 单 IP 每秒最多 100 请求,全局限流 100 万 QPS |
| 网关层 | Istio/APISIX | 按服务、接口限流 | 订单服务/create接口限流 5 万 QPS,非核心服务/notify接口限流 1 万 QPS |
| 应用层 | Sentinel(K8s Sidecar 模式) | 按接口、用户、集群限流 | 单用户每秒最多 5 次下单请求,应用集群 QPS 限流 20 万 |
| 数据库层 | ShardingSphere + 云数据库(如 RDS) | 按分片限流、SQL 限流 | 单分片每秒最多 1 万写请求,禁止全表扫描 SQL |
Sentinel Sidecar 部署(无侵入限流):在 K8s Pod 中注入 Sentinel Sidecar 容器,无需修改应用代码,通过 ConfigMap 配置限流规则:
# 注入Sentinel Sidecar
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service-deployment
spec:
template:
spec:
containers:
- name: order-service
image: order-service:v1
- name: sentinel-sidecar
image: sentinel-sidecar:latest
env:
- name: SENTINEL_DASHBOARD
value: "sentinel-dashboard:8080"2. 熔断降级(Istio+Sentinel)
当下游服务(如支付服务)故障时,通过熔断避免连锁反应,同时降级返回兜底数据(如 "支付服务繁忙,请稍后重试")。
| 组件 | 熔断逻辑 | 降级策略 |
|---|---|---|
| Istio | 基于服务调用成功率(如 5 秒内错误率 > 50%)触发熔断 | 直接返回 503,不调用下游服务 |
| Sentinel | 基于接口响应时间(P95>2s)、错误率(>30%)触发熔断 | 返回默认值(如订单查询返回空列表)、调用备用服务(如备用支付渠道) |
Istio 熔断配置示例:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: payment-service-dr
spec:
host: payment-service
trafficPolicy:
outlierDetection:
consecutiveErrors: 5 # 连续5次错误触发熔断
interval: 30s # 检测间隔
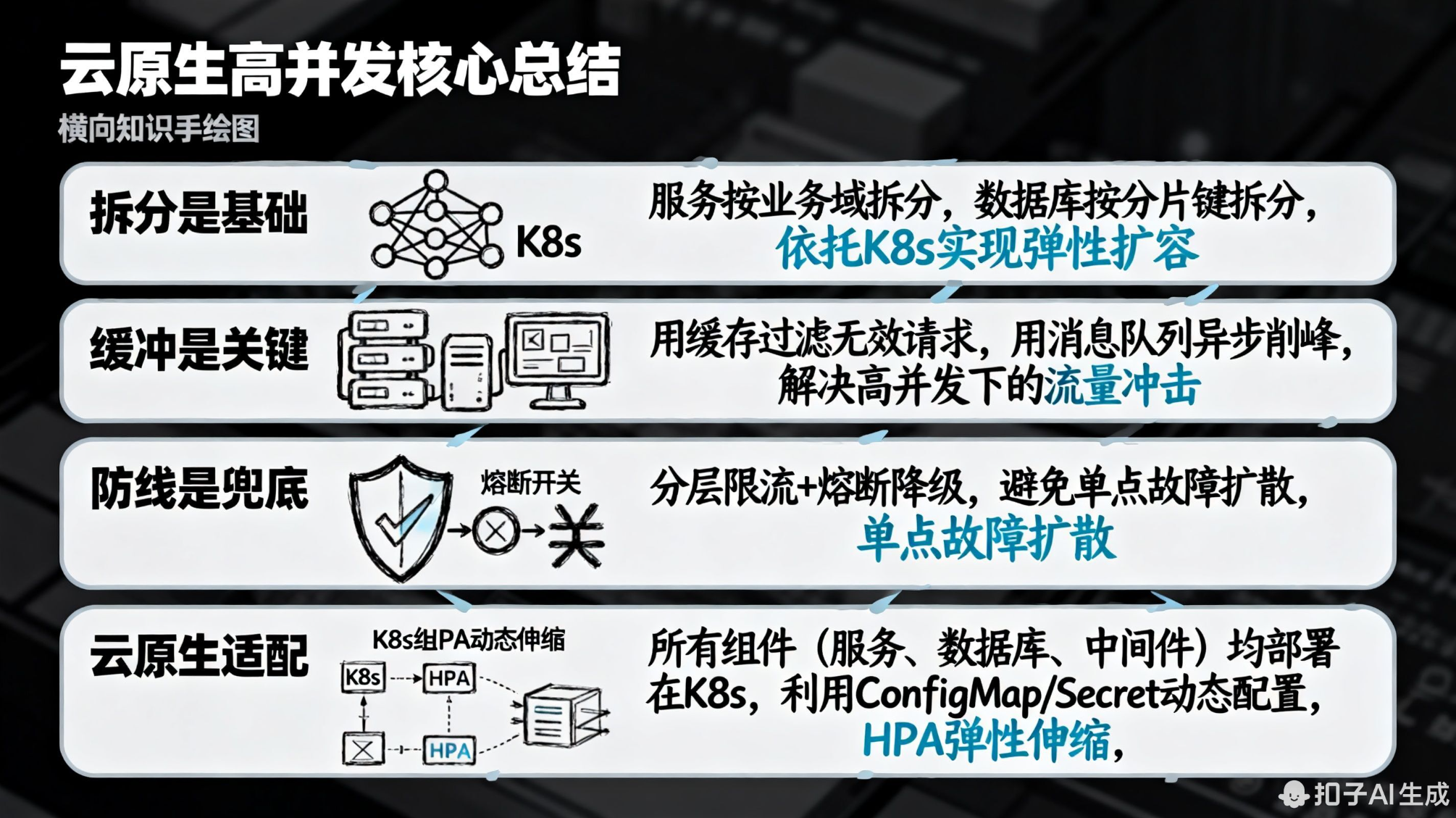
baseEjectionTime: 60s # 熔断时长60秒四、云原生高并发核心总结
- 拆分是基础:服务按业务域拆分,数据库按分片键拆分,依托 K8s 实现弹性扩容;
- 缓冲是关键:用缓存过滤无效请求,用消息队列异步削峰,解决高并发下的流量冲击;
- 防线是兜底:分层限流 + 熔断降级,避免单点故障扩散;
- 云原生适配 :所有组件(服务、数据库、中间件)均部署在 K8s,利用 ConfigMap/Secret 动态配置,HPA 弹性伸缩,降低运维复杂度
