目录
[二、MoE 的优势](#二、MoE 的优势)
[1. 参数量巨大但计算量几乎不变](#1. 参数量巨大但计算量几乎不变)
[2. 专家自动分工,能力更丰富(专精化)](#2. 专家自动分工,能力更丰富(专精化))
[3. 训练效率高](#3. 训练效率高)
[4. 扩展性极强(Scalability)](#4. 扩展性极强(Scalability))
[5. 专家之间天然并行(Parallelism-friendly)](#5. 专家之间天然并行(Parallelism-friendly))
[三、MoE 为什么会变慢?](#三、MoE 为什么会变慢?)
[1. Router 造成额外计算与同步开销](#1. Router 造成额外计算与同步开销)
[2. Token 需要在不同专家之间"分发"和"再聚合"](#2. Token 需要在不同专家之间“分发”和“再聚合”)
[3. 专家负载不均衡导致流水线堵塞](#3. 专家负载不均衡导致流水线堵塞)
[4. 批次小的时候 MoE 效率最差](#4. 批次小的时候 MoE 效率最差)
写在前面
DeepSeek 的出现引发了广泛关注,它以极低的训练成本与高参数规模令人惊叹。但我们在实际体验中也遇到一个问题,相比ChatGPT、Kimi、豆包等同类型的NLP大模型"腹泻"式的推理速度:"为什么 DeepSeek 这么慢?"

许多人误以为 DeepSeek 的算力更强,因此理应速度更快,其实不然。DeepSeek 使用了极大规模的稀疏 Mixture-of-Experts (MoE) 架构 ,让模型在等价 FLOPs 基础上拥有远超 dense 模型的参数规模。
但在推理场景,越大的 MoE 参数规模往往意味着:路由复杂度增加、通信成本上升、跨设备同步放大、负载不均衡加剧。
深度学习工程界一个常识是:稀疏模型在训练时能用稀疏化减少计算,但在推理时绝大多数延迟源自通信,而不是计算。
一、什么是MoE
MoE 的核心思想是"不是所有 token 都由同一组参数处理",而是让不同的 token 动态选择最适合它们的"专家网络"(Expert)。它的优势是 大幅提升模型容量却几乎不增加计算量。
MoE 是一种参数稀疏化架构,给定 token 表示 x,路由器计算各专家权重,用公式描述如下:
Top-K(通常 K=1 或 K=2)选择得分最高的 K 个专家集合。
每个专家 是一个 FFN:
最终输出为:
MoE 模块结构示意图:
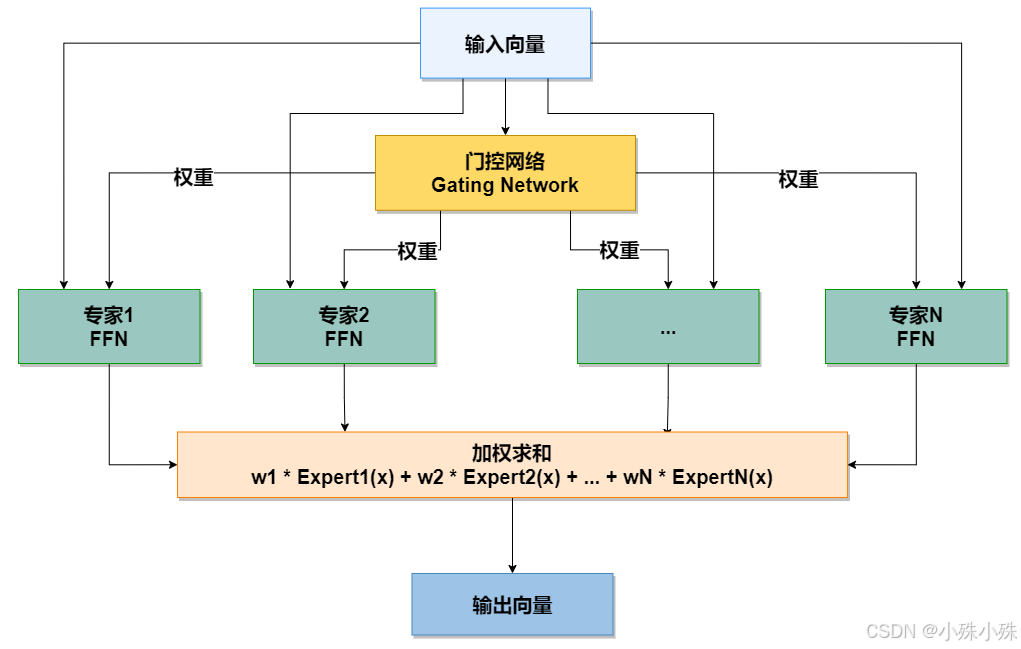
核心组件详解
1.输入
一个输入向量(例如,来自Transformer模型前一层输出的 token 表示)。
2.门控网络
功能: 这是 MoE 的"路由控制器"。它接收输入向量,并产生一个权重分布(通常通过 Softmax 函数)。
输出: 一个权重向量 w1, w2, w3, ..., wN,其中每个 w_i 表示对应专家对于当前输入的重要性。通常,只有 Top-K(例如 Top-1, Top-2)的专家会被激活,其余权重置零,这实现了稀疏激活,是保证计算效率的关键。
3.专家网络
功能: 一群独立的、通常是结构相同的子网络(例如,每个专家都是一个前馈神经网络)。每个专家都专注于学习输入数据分布中的不同部分或模式。
**特点:**所有专家并行存在,但对于任何一个特定输入,只有少数(K个)专家被激活并参与计算。这使得模型总参数量巨大,但计算成本只与激活的专家数成比例。
4.加权求和
功能: 将门控网络计算出的权重,与对应激活专家的输出进行加权求和。
公式: Output = w1 * Expert1(x) + w2 * Expert2(x) + ... + wN * ExpertN(x)
结果: 最终生成一个与输入向量同维度的输出向量,传递给模型的下一层。
二、MoE 的优势
MoE 用更少的计算,获得更大的模型容量与更强的任务适应性,是现代大模型最具性价比的扩展技术。
1. 参数量巨大但计算量几乎不变
MoE 最大的强项是稀疏激活:只启用 Top-K 个专家,其余专家不参与计算。因此模型参数量可以做到 dense 的 10倍~100倍,但每个 token 的计算量几乎不增加,这让 MoE 可以用较低计算成本获得接近"超大模型"的能力。
2. 专家自动分工,能力更丰富(专精化)
路由器会将不同 token 分配给不同专家,使专家自动学习不同子任务,例如:文本推理、数学、翻译、代码、文本纠错等。
**MoE 内部形成多个专精子网络,使整体泛化能力更强。**Dense 模型无法天然做到这种"特化"。
3. 训练效率高
训练时每个 token 只激活少数专家,因此FLOPs 低、内存带宽压力小、可以用更大的 batch、训练吞吐率高。
大规模研究显示:MoE 的训练速度可比同性能 dense 模型快 3~7 倍。
4. 扩展性极强(Scalability)
Dense 模型参数一旦超过百亿级就很难继续扩展,因为GPU 内存不够、通信量爆炸、optimizer 状态占用率巨大等原因。
MoE 通过稀疏化规避了密集 FFN 的扩展瓶颈:MoE 非常适合构建万亿参数级 LLM。
5. 专家之间天然并行(Parallelism-friendly)
MoE 的专家彼此独立,使其非常适合分布式并行,每个 GPU 可以负责多个独立专家\训练负载容易拆分。相比之下,dense FFN 很难做细粒度并行。
三、MoE 为什么会变慢?
虽然 MoE 理论上计算量低,但它在工程上会造成大量 延迟。DeepSeek 正是因为采用 MoE 才显得"慢"。
1. Router 造成额外计算与同步开销
每个 token 都要先经过路由器决定专家选择,这一步虽然轻量,但需要对所有 token 进行 softmax/排序、多 GPU 之间交换路由信息。这些操作会显著增加 通信延迟。
2. Token 需要在不同专家之间"分发"和"再聚合"
**这是MoE速度慢的最主要原因。**在 GPU 上,专家通常分布在不同显卡甚至不同机器上,因此每个 token 必须经过一个All-to-All 分布式通信的过程:
tokens -> router -> 分发到对应专家 -> 各专家计算 -> 再汇聚
这就导致:通信远大于计算、延迟剧烈增加,这一步通常比"推理本身"要慢得多。
3. 专家负载不均衡导致流水线堵塞
Router 不可能完美均衡 token 的分布,有些专家可能被大量选择,有些无人使用,结果会出现某些 GPU 堆积大量请求;整个推理速度由最慢的专家决定。这通常叫做 load imbalance(负载不均衡)。
4. 批次小的时候 MoE 效率最差
对于对话式推理(单用户、一个一个 token 地预测),MoE 的并行度利用率极低,因此专家利用率低、通信成本更显著就成为批次小的时候 MoE 效率最差的原因。
换言之,MoE 更适合大批量推理,但不适合单请求对话场景。
四、总结
DeepSeek 的慢来自 MoE 架构的系统性瓶颈,而不是工程不足。其根本原因包括:
1.Router 造成额外计算与同步开销
2.Token → Expert → 汇聚 的 All-to-All 通信主导延迟
3.专家负载不均衡导致流水线堵塞
4.MoE 在小 batch 推理时性能坍塌
5.专家数目大导致通信复杂度上升
6.每层 MoE 都叠加两次通信 + 路由开销
Dense 模型推理快,因为:所有计算都是矩阵乘法,没有任何跨设备不规则通信。
MoE 模型推理慢,因为:大部分时间都在跨 GPU 派发 token、等待最慢专家工作、再同步结果。
这就是 DeepSeek 的慢的技术本质。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583