2025 年已接近尾声,这一年里,大模型加速从单点提效工具升级为支撑业务系统的底层基础设施。过程中,推理效率决定了大模型能否真正落地。对于超大规模 MoE 模型,复杂推理链路带来了计算、通信、访存等方面的挑战,亟需行业给出高效可控的推理路径。
华为亮出了面向准万亿参数 MoE 推理的完整技术栈:openPangu-Ultra-MoE-718B-V1.1 展现 MoE 架构的模型潜力、包括 Omni Proxy 调度特性、将昇腾硬件算力利用率推至 86% 的 AMLA 技术在内的昇腾亲和加速技术,使得超大规模 MoE 模型具备了走向生产级部署的现实可行性。开源实现:
如果说过去数年大模型竞争的焦点在训练规模与能力突破上,那么如今,推理效率正迅速成为影响模型能否落地的关键变量。
从任务属性来看,训练侧重于通过更多算力和数据扩展模型能力,而推理比拼的是谁能以低成本、低延迟将模型稳定运行起来。尤其对于超大规模混合专家(MoE)模型而言,真正的落地挑战来自于计算、通信、访存和并行策略等的最优策略选择。
这些挑战迫使企业必须把推理成本精确到每一次节点通信和每一个算子开销。在高度耦合的推理链路中,调度或资源分配上的微小偏差都可能被放大为延迟上升、吞吐下降,甚至导致部署成本偏离预期。也正因为如此,推理成本是否可控,很大程度上决定了大模型的可用性,并直接影响能否高效进入业务场景。
在大 EP 部署下,MoE 模型能更好地发挥芯片和组网能力,实现更低成本的推理,但是其整个推理体系也会变得异常复杂。每一个算子的极致性能、通信 - 计算的多流并发、节点间通信的极致掩盖、整个系统的协同调度,每一环都可能成为大规模部署中的瓶颈。在国内 token 需求指数级增长的今天,推理效率更需要做到极致,以更好地支撑大模型的商业闭环。
因此,如何以更快、更稳的方式跑通千亿乃至准万亿参数规模的 MoE 模型,让它们具备生产级部署能力,已经成为整个行业迫切需要解决的核心难题。如今,随着推理加速、智能调度和硬件算力释放的系统性演进,这一问题在昇腾硬件上有了清晰的解法。
上个月,华为发布并开源了准万亿级 MoE 模型 openPangu-Ultra-MoE-718B-V1.1,它基于昇腾硬件训练,总参数为 718B,激活参数量为 39B,提升了 Agent 工具调用和其他综合能力。与业内所有尝试超大规模 MoE 的团队一样,摆在面前的一大挑战是:让这个「庞然大物」高效地跑起来。这意味着必须要在推理层面做出突破。
一番深挖之下,我们发现该模型的量化版本------openPangu-Ultra-MoE-718B-V1.1-Int8(以下简称 openPangu-Ultra),已经在昇腾硬件上构建起一条完整可行的推理路径。

模型 GitCode 地址:ai.gitcode.com/ascend-trib...
具体来讲,依托开源的 Omni Proxy 调度算法以及极致释放硬件算力的全新 AMLA 算法的昇腾亲和加速技术,openPangu-Ultra 实现了在昇腾硬件上的稳定部署。
昇腾亲和加速技术,
更快更稳跑通准万亿 MoE
此前,超大规模 MoE 部署更多依赖通用推理框架,如 vLLM、SGLang。虽然能跑起来,但并不擅长,往往在专家路由、All-to-All 通信、节点负载均衡以及专家放置策略等环节难以支撑 EP 百级以上的巨型专家并行规模。
同时,大厂内部自研的 MoE 分布式推理方案大多不开源,不具备可复用性,并且难以迁移到昇腾等硬件平台。更重要的是,在缺乏系统级优化的情况下,MoE 推理受限于通信瓶颈、资源碎片化、硬件利用率低等问题,不仅工程成本高,推理效率也难达到可商业化的要求。
随着近期一系列昇腾亲和加速技术的持续开源,过去依赖深度定制和巨额投入才能跑通的超大规模 MoE 推理出现了新的可能。得益于推理框架与加速套件的深度融合,这些昇腾亲和的加速技术形成了一套完整高效的超大规模 MoE 推理体系。
接下来,我们将从框架层面、调度层面到算子层面,逐步解析这套推理体系的关键技术支点。
全链路推理调度特性
先来看框架层面,Omni-Infer 为 vLLM、SGLang 等当前主流的开源大模型推理框架提供了昇腾亲和加速库,在保持上层接口与开发体验一致的前提下,将昇腾硬件的底层能力无缝接入到现有推理链路。这样一来,开发者无需迁移服务架构、无需重写应用逻辑,就能在昇腾硬件上运行大模型。
作为 Omni-Infer 框架层面的重要组成部分, Global Proxy 承载着请求调度与资源优化的核心使命,是超大规模 MoE 模型的高性能推理调度特性,主要负责分布式推理时的请求分发、P/D(Prefill 与 Decode) 调度与并行策略协调,以降低延迟、提升吞吐。在 Omni-Infer V0.3.0 中,Global Proxy 带来了超过 10% 的推理性能提升。

推理框架
为了满足后续更复杂的调度需求,Omni-Infer 带来了 Global Proxy 的升级版 ------Omni Proxy,也即第二代请求调度特性。它基于开源的高性能 Web 服务器和反向代理服务器 Nginx 打造,在继承 Global Proxy 算法优势的基础上,通过多项技术创新进一步解决了传统调度器在大模型推理场景下的局限性。
大模型推理请求的独特性主要在于其显著的周期性负载特征、性能感知缺失、KV 缓存匹配以及冗余计算问题。
首先大模型推理通常呈长周期性,如 Prefill 秒级、Decode 几十毫秒级,导致新请求在当前批次推理结束前无法进入;其次传统调度器无法准确感知模型运行中的关键指标,如 tokenize 时间、批次大小、调度周期和 KV 缓存利用率,调度决策缺乏数据支撑。此外传统调度器无法对字符串格式的 prompt 请求与实际 KV 缓存状态进行精准匹配,缓存命中率达不到预期。最后多机 P/D 分离部署中 Prefill 和 Decode 节点分别执行相同的 tokenizer 处理,计算资源浪费与延迟开销较高。
传统调度器在应对大模型推理的这些挑战时往往难以提供有效支持,因此亟需效率更高、延迟更低、运行更稳的智能调度方案。
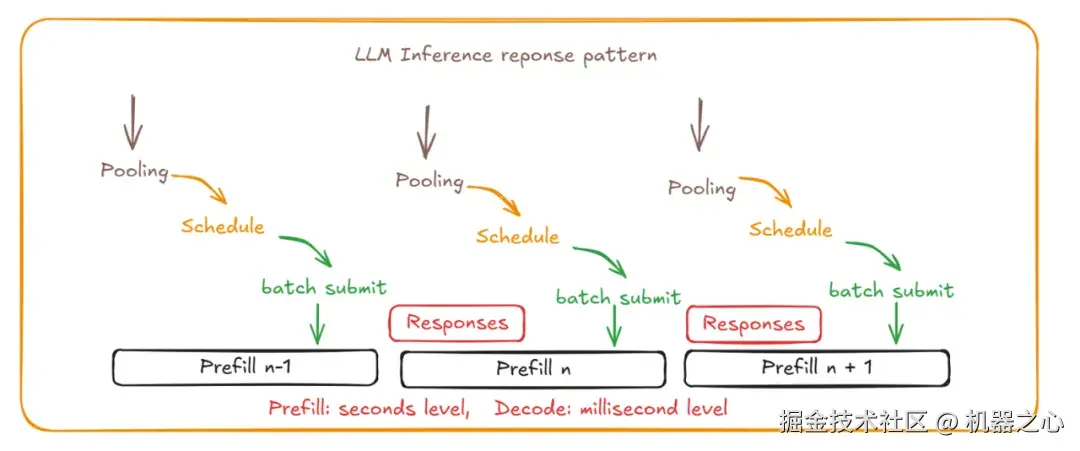
大模型推理响应模式
在以全生命周期监控、APC 感知调度、Tokenizer 复用和负载感知的 P/D 协同调度为主线的调度体系下,Omni Proxy 的系统吞吐量和推理效率又提升了一个台阶。
创新 1:通过将每个推理请求拆解为 10 个细粒度的生命周期阶段(如下图),Omni Proxy 实现了基于全链路性能数据的精确请求级调度,最大化 Prefill 与 Decode 资源池的利用率并保持整体负载均衡。
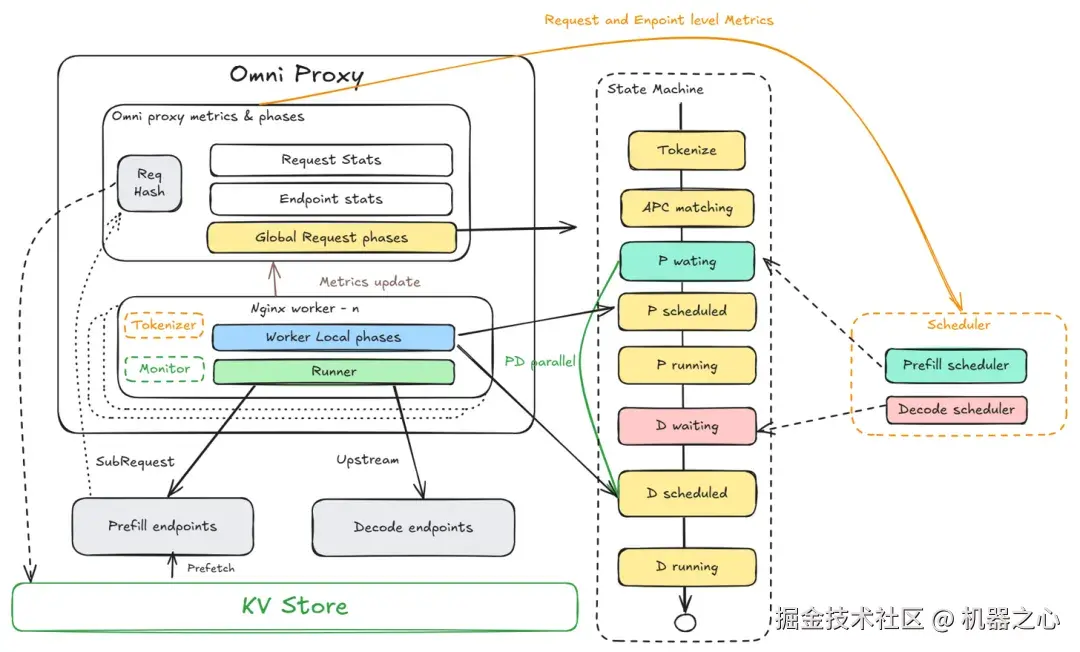
从接收请求、Tokenize、APC 匹配,到 Prefill 等待、调度与执行,再到 Decode 等待、调度与执行、直至完成
创新 2:同时提供 sequential(先 P 后 D、按需分配并拉取 KV)和 parallel(P/D 同步选择、KV 预分配并按层推送)两种模式,以适配 vLLM 与 SGLang 在 P/D 分离场景下截然不同的 KV Cache 传输与协同方式,确保两类框架都能实现高效的 Prefill-Decode 调度。
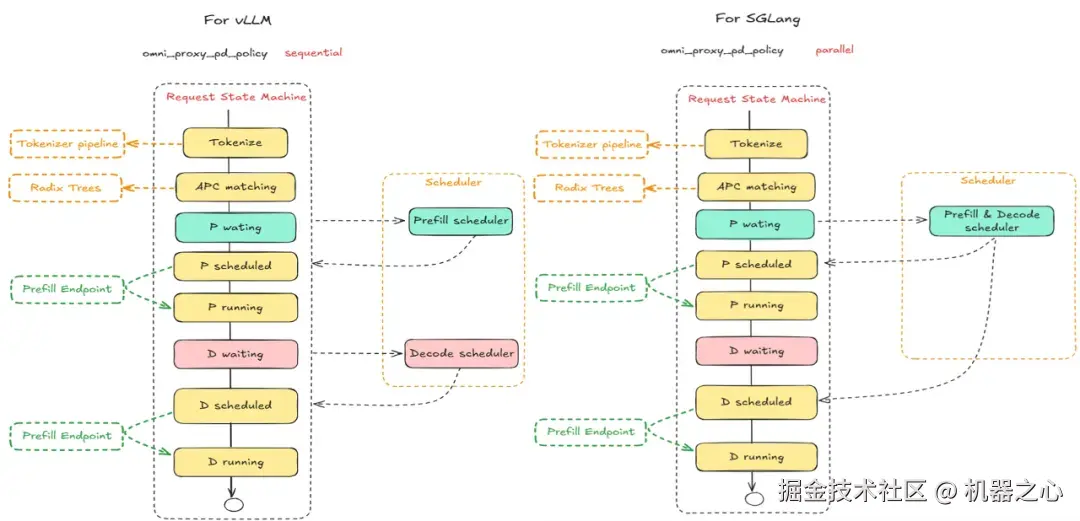
左为 sequential 模式,右为 parallel 模式
创新 3:通过实时同步 KV 缓存状态、基于 tokenizer 与一致哈希的精准匹配以及多 worker 共享的全局缓存状态,实现 APC 感知的高效 KV 缓存复用与智能调度,减少重复计算与节点传输开销。
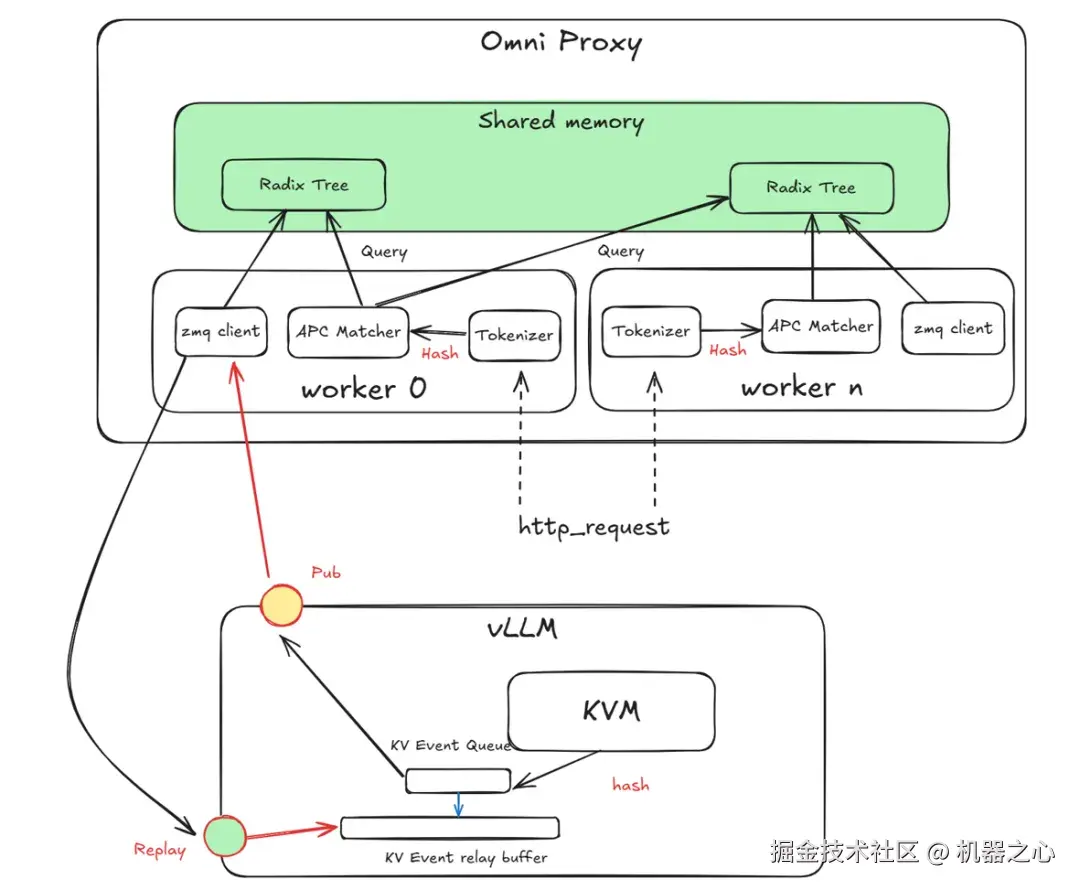
APC 感知智能调度流程
创新 4:在上游预先完成对话模板展开与 tokenizer 处理并将结果随请求下传,避免下游节点重复计算,并在 DeepSeek v3 等多机 P/D 分离场景下降低约 30% 的 tokenizer 开销。
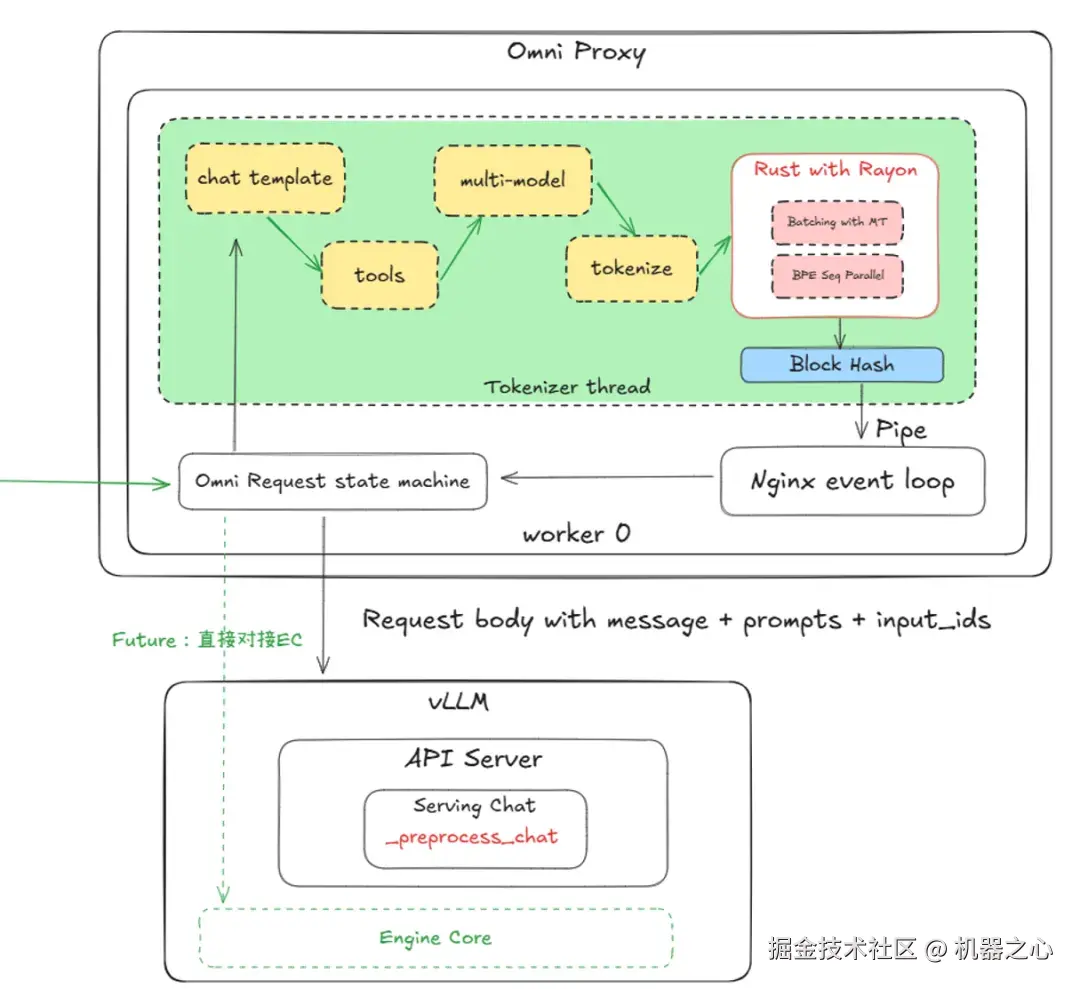
Tokenizer 结果复用优化流程
创新 5:通过对请求按长度与等待时间加权排序、结合 APC 优先匹配以及基于负载与预期处理时间的节点选择,Prefill 调度器实现对长短请求的动态平衡以及对上游节点的精准匹配,达到提升吞吐、降低等待和避免过载的效果。
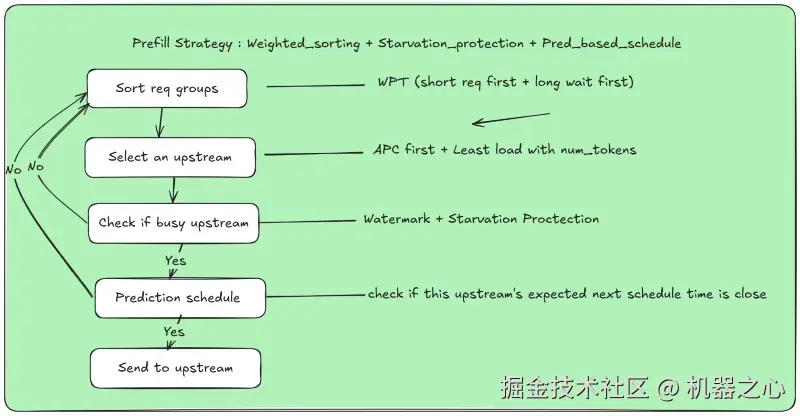
基于负载与等待时间的批处理请求
创新 6:结合主从调度与共享内存的数据聚合机制,在多 worker 架构下实现全局一致的调度决策与低开销的性能同步,确保系统高可用性与扩展性。
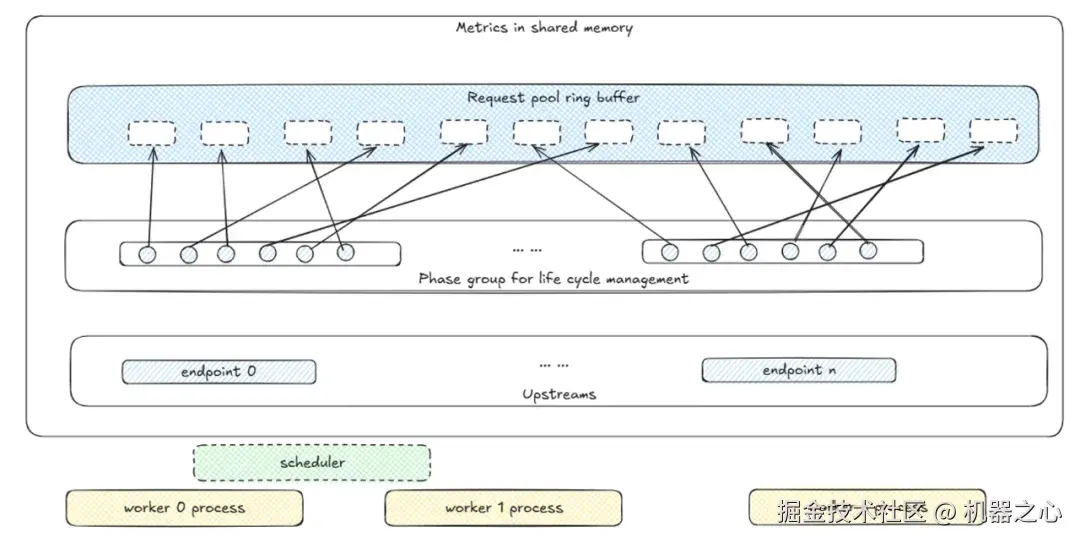
分布式架构优化
Omni Proxy 的六大创新点不是零散的功能补丁,而是进行了一次系统性整合升级,打造出一套面向超大规模 MoE 推理的高性能调度基础设施,让模型在推理链路中保持可控的延迟和稳定的吞吐。
全栈推理加速体系
至于推理加速套件,同样不是简单堆叠若干优化模块,而是将推理的核心瓶颈逐层重构:
-
API Server 与 Scale Out 能力让推理服务在昇腾集群中顺畅扩展;序列均衡调度确保不同长度、不同阶段的请求在集群内合理分配,避免出现局部节点拥堵。
-
模型部署侧支持 DeepSeek、Qwen、openPangu 等不同体系、不同架构的大模型,兼容性良好;Omni Placement 进一步瞄准 MoE 推理最棘手的问题之一 ------ 专家放置与负载均衡,通过 Layer-wise 与 Uneven 机制实现不同层、非均匀分布的大规模专家的高效调度。
-
MTP 与 Fusion Operator,前者提高多 token 并行生成能力,后者通过算子融合减少冗余计算、提升执行效率。
可以看到,从服务扩展、任务调度、专家管理到算子加速,这些组件共同构筑起支撑超大规模 MoE 推理的核心加速体系。
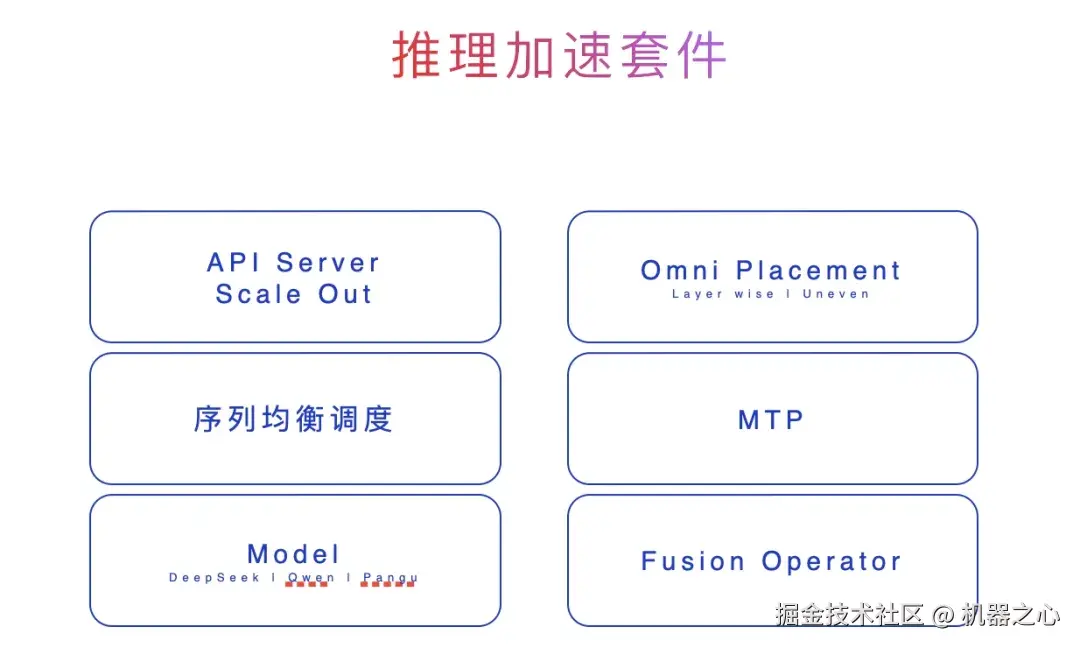
推理加速套件
进一步地,这些推理加速套件连同 Omni Proxy 一起,将并行策略、调度决策、节点通信等分散的环节整合进同一套系统栈,让原本复杂而碎片化的流程被编织成一个真正可落地的推理体系,为昇腾硬件承载准万亿 MoE 推理提供了关键的软件支撑。
不过,框架层面的协同优化只是完成了第一步,想要继续压榨推理潜力,算子层面的创新同样不可缺少。
AMLA 将昇腾硬件 FLOPS 利用率推至 86%
对于准万亿参数的 MoE 模型,推理性能的高低,关键在于芯片算力能否充分释放、算子是否贴合芯片结构、数据流是否高效、通信开销是否构成瓶颈。这些都将直接影响推理的单 token 成本,并进一步决定推理链路的稳定性与可扩展性。
在昇腾硬件上,高效软硬件协同的关键是 AMLA(Ascend MLA)。作为超大规模 MoE 推理极致性能的一大支点,其算力利用率最高可达 86%,这在推理场景下是绝无仅有的。
作为一种「以加代乘」的高性能 MLA 算子,AMLA 是昇腾体系中极具代表性的底层创新。通过从数学层面对计算逻辑进行解构,让原本受限的计算在昇腾架构上获得了更加贴合的执行方式。

作为大语言模型的核心,注意力机制在处理不断扩展的超长上下文时面临着越来越大的计算开销与内存压力。为此,DeepSeek 采用的多头潜变量注意力(MLA)方法可以在大幅压缩 KV 缓存的同时保持模型精度。并且,该方法将注意力计算从访存密集转向计算密集,从而非常契合昇腾这类强调高 FLOPS 密度与高能效的硬件。
不过,直接实现的 MLA 受限于巨大输出张量的反复搬运和异构计算单元无法并行利用这两大瓶颈,导致算力无法充分释放。FlashMLA 等更优方案虽可以提升 FLOPS,但因 KV 缓存的重复搬运引入了额外开销。要想 MLA 真正在昇腾硬件上跑满,需要在算子级的数据组织与流水化执行方面有所突破。
此次,AMLA 带来了两项关键创新,在数值 Rescaling 和算子流水化两方面同时发力,让注意力算子在昇腾硬件上具备高效跑满的可能。
首先,AMLA 提出了一种基于 FlashAttention 的全新算法,利用 FP32 和 INT32 在二进制上的对应关系,将原本需要大量浮点乘法的步骤改成只用更轻量的整数加法来完成,从算法层面减少了计算开销以及数据搬运。需要指出的是,它不是对某几个 kernel 做局部优化,而是通过重新构造浮点运算,把乘法拆解并映射为更适合芯片执行的加法模式。完整的 AMLA 算法实现如下所示:

在 FlashAttention 的 Rescaling 步骤中,通常需要读取 FP32 格式的输出块并乘以缩放因子,再写回 GM(全局内存)。这一过程须将数据从 GM 搬运至 UB(向量缓冲区) 进行计算。AMLA 创新性地将这一更新过程利用 代替,与此同时,这一操作可转化为对 x 的整数表示的加法运算。这种变换允许使用昇腾硬件支持的原子加法指令,直接在 GM 中完成输出张量的更新。这彻底消除了中间张量在 GM 与 UB 之间的往返搬运,显著降低了访存延迟。
代替,与此同时,这一操作可转化为对 x 的整数表示的加法运算。这种变换允许使用昇腾硬件支持的原子加法指令,直接在 GM 中完成输出张量的更新。这彻底消除了中间张量在 GM 与 UB 之间的往返搬运,显著降低了访存延迟。
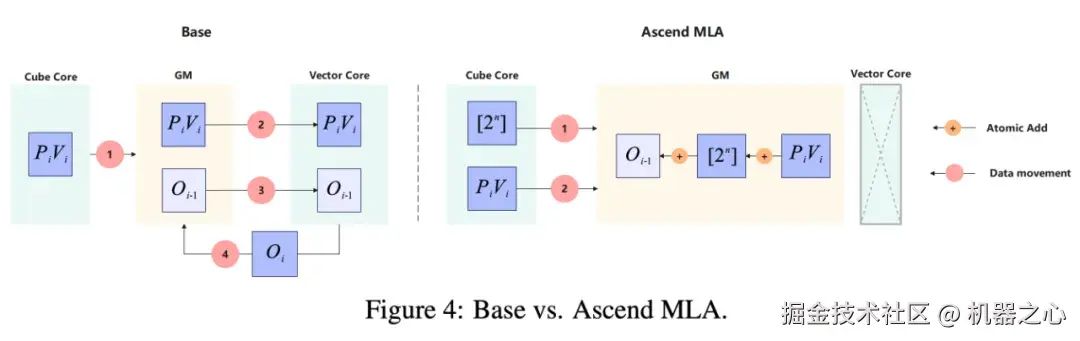
基线 MLA 与 AMLA 的流程对比。
在以加代乘之外,AMLA 又设计了一套结合预加载流水线(Preload Pipeline)和层级分块的执行策略。前者通过将计算任务解耦,使负责矩阵运算的 Cube 核与负责 Softmax / 归一化的 Vector 核能够并行工作。结合预加载机制,确保 Cube 核始终处于饱和计算状态(Cube-bound),避免因等待 Vector 核处理而产生的流水线气泡。在 Cube 核内部,AMLA 引入了多级分块策略。通过细粒度的数据切分,实现了数据从高层存储向寄存器搬运的过程与实际计算过程的完全重叠。这种双层流水线优化确保了数据流的连续性,最大化了 FLOPS 利用率。
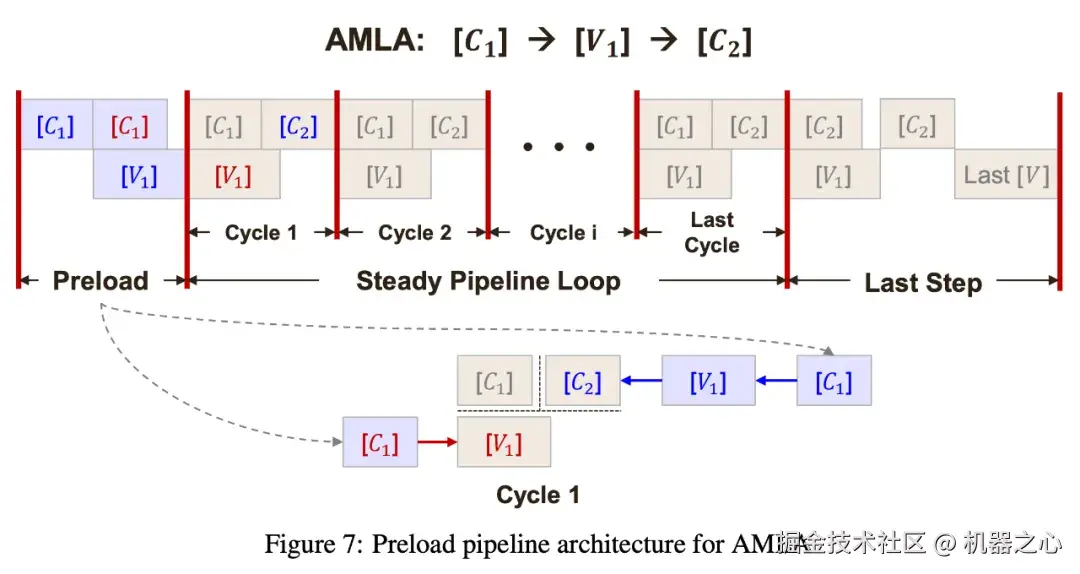
AMLA 的预加载流水架构
AMLA 的实测结果进一步印证了其含金量,在昇腾硬件上跑出了最高 614 TFLOPS 的性能,算力利用率达到理论峰值的 86.8%,远高于当前最好的开源 FlashMLA(在 NVIDIA H800 SXM5 上算力利用率约 66.7%)。
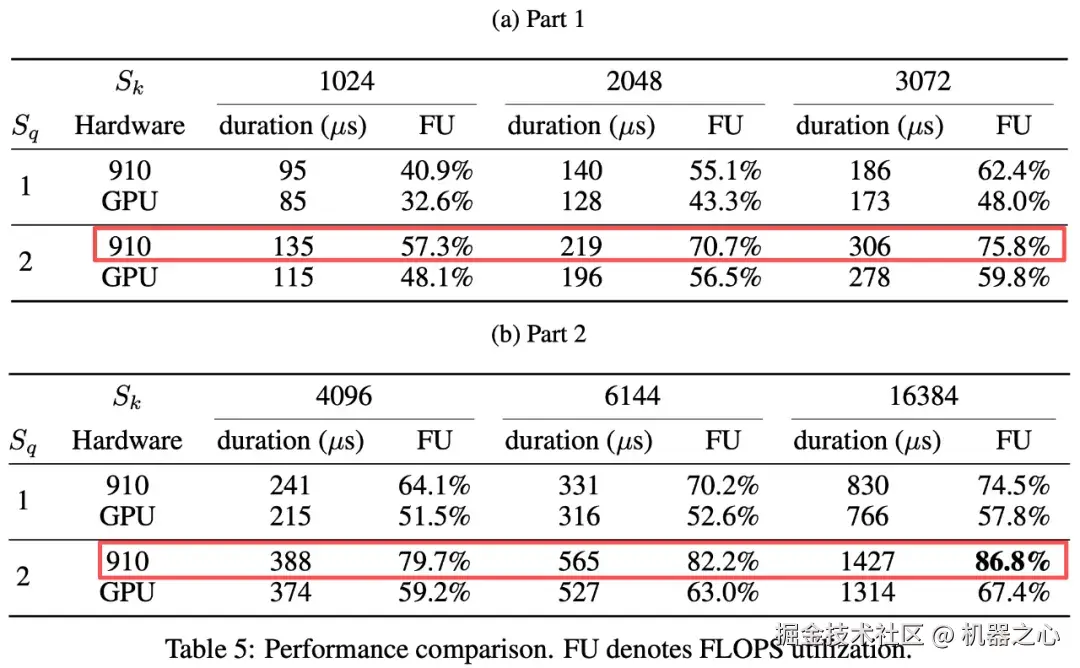
以往大模型推理的天花板往往受限于硬件实际可用算力,而 AMLA 抬升了芯片的性能上限,打破了行业长期停留在 50% 以下的利用率瓶颈,使得昇腾硬件更有效地支撑大模型的推理需求。硬件利用率的提升也将进一步打开系统层面、框架层面乃至模型层面的优化空间,提供更强的可持续优化与扩展潜力。
至此,围绕系统性推理加速、全链路智能调度与底层算子优化,华为打出了一套面向超大规模 MoE 推理的组合拳。
写在最后
为了让超大规模 MoE 模型的部署不再是业界难题,华为在昇腾硬件上祭出了准万亿参数 openPangu-Ultra 与昇腾亲和加速技术的最佳实践,并在框架层面、调度层面和算子层面进行了一系列技术创新。
其中昇腾亲和加速技术在框架层面提供适配 vLLM、SGLang 等的加速器以及多个加速套件,Omni Proxy 带来了更稳更快的智能调度,AMLA 通过算子优化提升硬件算力利用率。这些技术的组合让准万亿参数 MoE 推理在成本、性能与稳定性之间找到可落地的平衡点,并为其迈向商业可行性奠定了基础。
如今,尽管 Scaling Laws 的边际收益正在放缓,但模型能力仍在上探。同时,推理效率的底座也在系统、算法与硬件协同优化下不断加固。模型能力与推理效率的双向提升让大模型加速走向产业化落地阶段。
随着大模型的价值判断逐步从「能否训练」转向「能否以可控成本长期运行」,行业正在经历一场由推理效率驱动的结构性重构。而 openPangu-Ultra 与昇腾亲和加速技术的结合,为这种重构给出了一个清晰的范本。