1. 执行摘要与技术背景
信息检索技术的演进历程,本质上是人类试图让机器理解语言深层含义的漫长探索。从早期的布尔逻辑检索、倒排索引(Inverted Index)到如今的向量搜索(Vector Search),这一领域的每一次飞跃都重塑了数据交互的边界。当前,随着大语言模型(LLM)的爆发式增长和检索增强生成(RAG)架构的普及,向量搜索技术已从学术界的边缘课题跃升为企业级AI基础设施的核心组件 。
传统的关键词搜索(Keyword Search)依赖于词汇的字面匹配(Lexical Matching),虽然在精确匹配场景下表现优异,但其固有的"词汇鸿沟"(Lexical Gap)------即无法处理同义词、多义词及复杂的语义上下文------限制了其在现代智能应用中的效能。例如,用户搜索"犬类护理",传统引擎可能无法检索到仅包含"狗"或"幼崽"的文档,除非人工维护庞大的同义词库 1。相比之下,向量搜索通过深度学习模型将非结构化数据(文本、图像、音频、视频)映射为高维向量空间中的数值点(Embedding),利用几何距离来度量语义相似性。这种机制使得搜索"canine"(犬科)能够自然地关联到"dog"(狗)或"wolf"(狼),彻底突破了符号匹配的限制 。
然而,向量搜索的工业化落地并非易事。在海量规模(十亿级甚至百亿级向量)下进行毫秒级检索,对计算资源和算法效率提出了极高的挑战。这催生了以分层导航小世界(HNSW)和倒排文件索引(IVF)为代表的近似最近邻(ANN)算法,以及以Pinecone、Milvus、Weaviate为代表的专用向量数据库生态 。与此同时,为了弥补纯向量检索在精确匹配上的短板,混合搜索(Hybrid Search)和晚期交互(Late Interaction/ColBERT)等高级架构应运而生,成为当前构建高性能AI应用的标准范式 。
我们以数学基础、核心索引算法、数据库架构对比、高级检索策略及未来趋势等维度,对向量搜索技术进行详尽的剖析。我们将深入探讨HNSW的图遍历机制、量化压缩的精度权衡、BEIR基准测试的实证结果,以及面向Agentic RAG(代理式检索增强生成)的下一代系统设计挑战。
2. 向量搜索的数学基础与语义表征
要深入理解向量搜索,首先必须掌握其背后的数学原理。不同于传统数据库中的标量(Scalar)数据,向量数据是高维空间中的几何实体,其核心价值在于能够将抽象的语义概念转化为可计算的空间位置关系。
2.1 向量嵌入(Embeddings):语义的数值化映射
在向量搜索的语境下,向量(Vector)不仅仅是一个浮点数列表,它是信息在语义空间(Latent Semantic Space)中的坐标。嵌入(Embedding)是指通过神经网络模型将离散的高维输入(如单词、句子或像素矩阵)转换为低维、稠密的连续向量表示的过程 。
2.1.1 从稀疏到稠密的历史演进
向量表示的概念并非始于今日。早在20世纪60年代中期,信息检索领域的研究就开始萌芽,Gerard Salton及其康奈尔大学的同事在1978年发表的开创性论文中,就探讨了稀疏向量和稠密向量的概念,奠定了现代语义搜索的理论基石 。早期的词袋模型(Bag-of-Words)和TF-IDF生成的向量是极其稀疏的,维度等于词汇表的大小(往往数万维),且绝大多数元素为零。这种表示法无法捕捉词序和语义关联。
现代嵌入技术(如Word2Vec、BERT及OpenAI的text-embedding-3)生成的则是稠密向量。这些向量通常具有几百到几千个维度(例如384维、768维、1536维甚至3072维)。在这些模型中,语义相似的实体在向量空间中距离更近。一个经典的例子是向量算术运算能够捕捉类比关系:

这表明模型不仅编码了词义,还编码了性别、皇室身份等高层语义特征 。
2.1.2 维度与信息的权衡
向量的维度(Dimensionality)是一个关键的设计参数。维度越高,理论上能承载的语义信息越丰富,能够区分更细微的含义差别。然而,高维向量也带来了存储成本的线性增长和计算复杂度的指数级挑战(维度灾难)。例如,OpenAI的text-embedding-3-large模型支持高达3072维的嵌入,但在某些应用中,为了节省成本,开发者可能会通过截断或降维技术使用较小的维度 。
2.2 相似度度量(Similarity Metrics):几何空间的距离定义
一旦数据被转化为向量,搜索的核心任务就变成了计算查询向量与数据库中向量之间的"距离"。选择正确的相似度度量标准至关重要,它必须与嵌入模型训练时使用的度量保持一致,否则检索结果将失去意义 。
2.2.1 欧几里得距离(Euclidean Distance / L2)
欧几里得距离测量的是两点在空间中的直线距离。其公式为:
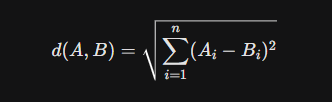
-
特性:距离值越小,表示越相似。该度量对向量的模长(Magnitude)敏感。
-
应用场景:适用于那些模长具有实际物理意义或统计意义的场景,例如在某些异常检测算法中,远离密集簇的点即为异常。但在高维文本嵌入中,由于"维度灾难"效应,所有点之间的欧氏距离可能趋于均一化,导致区分度下降 。
2.2.2 余弦相似度(Cosine Similarity)
余弦相似度测量的是两个向量夹角的余弦值,关注的是方向的一致性而非长度。
-
特性:结果范围从-1(完全相反)到1(完全相同)。它是模长无关的(Magnitude-Invariant)。
-
应用场景:这是NLP领域最常用的度量。在文本检索中,文档的长度(即向量的模长)往往不应影响其主题分类。例如,一篇关于"量子物理"的长文和一篇短文,其在语义空间的方向应该是一致的。OpenAI等主流嵌入模型通常针对余弦相似度进行了优化 。
2.2.3 点积(Dot Product)
点积是对应元素的乘积之和。
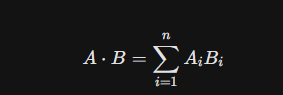
-
特性:点积的结果受向量方向和模长的共同影响。
-
应用场景:在推荐系统中广泛使用,其中模长可能代表用户的活跃度或物品的热门程度(Popularity)。
-
关键洞察 :如果向量经过了归一化处理(Normalized,即模长为1),点积与余弦相似度在数学上是完全等价的。由于点积计算不需要进行开方和除法运算,计算效率更高,因此许多高性能向量数据库(如Milvus、Faiss)在内部处理归一化向量时,实际执行的是点积运算以加速检索 。
| 度量标准 | 核心关注点 | 归一化向量表现 | 典型应用场景 | 计算复杂度 |
|---|---|---|---|---|
| 欧几里得 | 绝对距离 | 与余弦成反比 | 图像处理、空间数据 | 中 |
| 余弦相似度 | 方向(夹角) | 等同于点积 | 文本语义搜索、NLP | 高 (需除以模长) |
| 点积 | 方向 + 模长 | 等同于余弦 | 推荐系统、矩阵分解 | 低 |
3. 核心索引算法:高维空间的导航艺术
如果说嵌入是向量搜索的燃料,那么索引算法就是引擎。对于小规模数据集(例如几万条数据),我们可以使用暴力搜索(Flat Search),即计算查询向量与所有存储向量的距离。这种方法的召回率(Recall)是100%,但在计算复杂度上是O(N)。当数据量达到千万或十亿级别时,暴力搜索的延迟将变得不可接受。因此,业界普遍采用**近似最近邻(ANN, Approximate Nearest Neighbor)**算法,通过牺牲微小的精度(例如从100%降至99%)来换取数量级的速度提升。
3.1 分层导航小世界(HNSW):当前性能之王
HNSW(Hierarchical Navigable Small World)是目前内存向量搜索领域公认的最强算法,它在查询速度、召回率和对数据分布的鲁棒性之间取得了最佳平衡 。
3.1.1 结构原理:图与跳表的结合
HNSW的灵感来源于"六度分隔"理论(Small World)和数据结构中的跳表(Skip List)。它构建了一个多层的图结构:
-
基底层(Layer 0):包含数据集中的所有节点(向量)。这些节点通过边相连,形成一个导航小世界图(NSW),保证局部连通性。
-
上层结构(Hierarchy):每一层都是下一层节点的子集。最顶层极其稀疏,节点间距很远。这构成了类似"高速公路"的结构。
-
搜索过程:查询从最顶层开始,算法贪婪地跳转到距离查询点最近的节点。当在当前层找不到更近的邻居时,算法"降落"到下一层,利用在上一层找到的最近点作为起始点继续贪婪搜索。这种机制使得算法能够快速跨越广阔的向量空间,逐步逼近目标区域,最后在Layer 0进行精细搜索 。
3.1.2 关键参数与构建细节
HNSW的性能高度依赖于几个核心参数:
-
M(Max Links) :每个节点在图中允许的最大连接数。
M值越大,图的连通性越好,召回率越高,但内存消耗也随之增加(需要存储更多的边)。 -
efConstruction:构建索引时的动态候选列表大小。增加此值可以构建出质量更高(导航性能更好)的图,但会显著增加索引构建时间。这是一个典型的"一次构建成本换取长期查询收益"的权衡 。
-
efSearch :查询时的候选列表大小。这是用户在搜索时唯一可调的参数。较高的
efSearch会探索更多的节点,从而提高召回率,但会线性增加查询延迟。通过调整此参数,用户可以在运行时动态平衡速度与精度 。
3.1.3 局限性与挑战
尽管HNSW性能卓越,但它并非完美无缺:
-
内存消耗大:除了存储原始向量外,HNSW还需要存储图的邻接表结构,这通常会带来显著的内存开销(Overhead)。
-
实时更新困难:向图中插入节点相对容易,但删除节点则相当复杂,需要"重连"断开的边以维持图的导航属性(Navigability)。在高并发写入和删除的场景下,图的质量可能会退化。最新的研究指出了动态更新中可能出现的"不可达点"(Unreachable Point)现象,即某些节点在删除操作后变得无法通过贪婪遍历访问到,导致召回率下降 。
3.2 倒排文件索引(IVF):聚类与降维
IVF(Inverted File Index)采取了完全不同的思路,它基于聚类(Clustering)来缩小搜索范围,是应对大规模数据集的经典方法 。
3.2.1 核心机制
-
训练与聚类:首先,算法在向量空间中训练一个粗糙量化器(Coarse Quantizer),通常使用K-Means算法将空间划分为K个簇(Cluster),每个簇有一个中心点(Centroid)。
-
倒排列表:数据库中的每个向量被分配到距离其最近的簇中,并存储在该簇对应的倒排列表中。这类似于文本搜索中的倒排索引,只不过这里的"词项"是簇中心ID。
-
查询过程:
-
粗搜(Coarse Search) :查询向量首先与所有簇中心进行比较,找到距离最近的
nprobe个簇。 -
细搜(Fine Search) :算法仅扫描这
nprobe个簇中的向量,计算精确距离。 -
参数nprobe :这是控制精度的关键。如果
nprobe=1,只搜索最近的一个簇,速度最快但容易漏掉位于簇边界的目标;如果nprobe=K,则退化为暴力搜索。通常设置nprobe为簇总数的1%-10%即可获得极高的召回率 。
-
3.3 量化技术(Quantization):内存与速度的极致压缩
当向量数量达到十亿级时,原始浮点数的存储成本变得惊人。例如,10亿个1536维的float32向量需要约6TB的内存(1B * 1536 * 4B)。为了在有限的内存中容纳更多数据,量化技术不可或缺 。
3.3.1 乘积量化(PQ, Product Quantization)
PQ是一种有损压缩技术。它将长向量切分为m个子向量,对每个子向量空间独立进行K-Means聚类。原始向量不再直接存储,而是存储其每个子向量对应的簇中心ID(Code)。
-
优势:可以实现极高的压缩比(如4x-32x)。
-
计算加速:在查询时,可以预先计算查询向量与所有子空间簇中心的距离表(Look-Up Table, LUT),之后的距离计算仅需查表求和,极大地利用了SIMD指令集 。
3.3.2 标量量化(SQ)与二进制量化(BQ)
-
标量量化(SQ):将32位浮点数转换为8位整数(int8)甚至更低。这通常能减少4倍内存,且精度损失极小,是许多数据库的默认优化选项 。
-
二进制量化(BQ):这是一种极端的压缩方式,将每个维度转换为1个比特(大于0为1,小于等于0为0)。这意味着1024维向量仅需128字节。
-
Hamming距离:BQ利用异或(XOR)和位计数(Popcount)指令计算汉明距离,速度比浮点运算快几十倍。
-
2025趋势:随着嵌入模型维度越来越高(如3072维),BQ带来的精度损失被高维度的冗余信息所抵消。Elasticsearch等引擎正在引入"BBQ"(Better Binary Quantization),并在重排序阶段结合原始向量,实现了速度与精度的双赢 。
-
3.4 DiskANN:突破内存限制
对于无法完全装入内存的超大规模数据集,微软提出的DiskANN算法(及其变体Vamana图)提供了一种基于SSD的解决方案。
-
原理:它将压缩后的向量(用于导航)保留在内存中,而将全精度的原始向量存储在高速NVMe SSD上。
-
流程:搜索时,利用内存中的压缩索引快速定位候选邻居,然后通过异步IO请求从磁盘读取全精度向量进行最终的距离计算和重排序。
-
价值:这使得单机能够以极低的成本服务十亿级向量搜索,大大降低了硬件TCO(总体拥有成本)31。
4. 向量数据库生态全景:架构对比与选型指南
随着向量搜索需求的爆发,市场上涌现了多种技术流派。从架构上,我们可以将其分为专用向量数据库 (Native Vector DBs)和集成向量功能的通用数据库(Vector-capable General DBs)。
4.1 专用向量数据库:为AI而生
这类数据库从底层存储引擎到查询优化器都专为向量运算设计,通常提供极致的性能和特定的AI功能。
4.1.1 Pinecone
-
定位:全托管的闭源SaaS服务,是"Serverless向量数据库"的先驱。
-
架构优势:采用存算分离架构。其Serverless模式将索引数据存储在Blob存储(如S3)中,仅在查询时加载到计算层,极大地降低了空闲成本并支持无限扩展 33。
-
适用场景:适合不想维护基础设施、追求快速开发(Time-to-market)的企业。其简单的API和高可靠性是主要卖点。
-
局限:数据隐私(必须上云)、成本在极大规模下可能高于自建 。
4.1.2 Milvus
-
定位:开源界的"重型武器",专为十亿级(Billion-scale)向量设计。
-
架构优势:真正的云原生分布式架构,将接入层、协调服务、执行节点(Worker)和存储层完全解耦。支持多种索引类型(HNSW, IVF, DiskANN)和GPU加速 。
-
适用场景:拥有强大运维团队、对吞吐量和延迟有极致要求的大型互联网企业或AI公司。
-
局限:部署架构复杂(依赖Etcd, MinIO, Pulsar/Kafka等组件),学习曲线陡峭 33。
4.1.3 Weaviate
-
定位:AI原生(AI-Native)的开源数据库,强调模块化和开发者体验。
-
特色功能:不仅存储向量,还内置了"向量化模块"(Vectorizers),可以直接输入文本/图片,由数据库调用模型生成向量。支持GraphQL接口,允许以面向对象的方式组织数据(Class/Object) 。
-
适用场景:需要快速构建端到端RAG应用、重视数据建模灵活性和混合搜索能力的团队。
-
混合搜索:内置BM25算法,支持极其灵活的混合检索配置。
4.1.4 Qdrant
-
定位:基于Rust编写的高性能开源数据库。
-
架构优势:Rust带来的内存安全和高性能。Qdrant不仅支持HNSW,还特别优化了带有过滤条件的向量搜索(Filtered Search),通过在图遍历过程中动态应用过滤(Payload Filtering),解决了传统预过滤/后过滤的性能痛点 。
-
适用场景:对性能和资源效率敏感、需要复杂元数据过滤的推荐系统或匹配系统。
4.2 通用数据库的向量化扩展:融合的便利
许多企业倾向于在现有的技术栈上增加向量能力,而非引入新的数据库组件。
4.2.1 Elasticsearch / OpenSearc
-
实现:基于Lucene库的HNSW实现。
-
优势:真正的"混合搜索"王者。Elasticsearch拥有业界最成熟的倒排索引(BM25)和文本处理能力。通过Reciprocal Rank Fusion (RRF) 结合向量搜索,它在许多基准测试中提供了最佳的开箱即用相关性 。
-
劣势:作为基于Java的通用引擎,其纯向量搜索的QPS和延迟通常不如C++/Rust编写的专用引擎极致 。
4.2.2 PostgreSQL (pgvector)
-
实现:作为一个开源插件,为Postgres增加了向量数据类型和IVFFlat/HNSW索引。
-
优势:单一事实来源(Single Source of Truth)。开发者可以在同一个SQL查询中结合关系型数据(JOINs)和向量相似度。对于大多数中小规模(<1亿向量)应用,这是最经济、架构最简单的选择 。
-
劣势:在极大规模下的索引构建速度和查询性能受限于Postgres的进程模型,不如分布式专用库灵活 。
4.3 核心特性对比矩阵
| 特性 | Pinecone | Milvus | Weaviate | Qdrant | Elasticsearch | Pgvector |
|---|---|---|---|---|---|---|
| 类型 | 托管 SaaS | 开源 / 分布式 | 开源 / 模块化 | 开源 / 高性能 | 搜索引擎 | DB 扩展 |
| 核心算法 | 专有图算法 | HNSW, IVF, DiskANN | HNSW, Flat | HNSW | HNSW (Lucene) | IVFFlat, HNSW |
| 混合搜索 | 支持 (Sparse-Dense) | 支持 | 原生 BM25 | 支持 | 业界标杆 | SQL 组合 |
| 扩展性 | Serverless 自动伸缩 | 分布式集群 | 分片集群 | 分布式 | 分片集群 | 垂直/读写分离 |
| 主要场景 | 企业级 SaaS, 快速落地 | 超大规模, 本地部署 | RAG 应用, 灵活性 | 高性能过滤, 边缘 | 日志+搜索 | 关系型+向量 |
| 元数据过滤 | 专有优化 | 位图/分区 | 预过滤优化 | Payload索引 | DSL 过滤 | SQL WHERE |
5. 高级检索架构与策略
仅仅存储向量是不够的。为了在复杂的真实世界场景中提供高质量的搜索结果,必须采用更高级的检索架构。
5.1 混合搜索(Hybrid Search):关键词与向量的协奏
纯向量搜索虽然擅长捕捉概念关联,但在处理精确匹配任务(如搜索特定的错误代码"Error 505"、人名或产品型号)时往往表现不佳。向量模型可能会将"Error 505"关联到"系统故障"或"崩溃",但排除了具体包含该代码的文档 。
混合搜索旨在结合两者的优势:
-
稀疏检索(Sparse Retrieval):使用BM25或TF-IDF算法,关注关键词的精确匹配和频率(TF)与逆文档频率(IDF)。
-
稠密检索(Dense Retrieval):使用向量嵌入,关注语义匹配。
-
融合算法(Fusion):最常用的融合方法是倒数排名融合(Reciprocal Rank Fusion, RRF)。
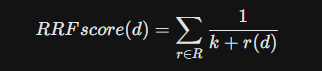
RRF不依赖具体的相似度分数(因为BM25的分数是无界的,而余弦相似度是0-1,难以直接相加),而是依赖文档在不同列表中的排名。这种方法鲁棒性极强,在BEIR基准测试中,混合搜索的性能几乎总是优于单独使用任何一种方法 。
5.2 过滤策略(Filtering):性能与精度的博弈
在实际应用中,用户往往结合元数据进行搜索(例如:"查找2023年发布的关于AI的论文")。过滤与向量搜索的结合时机至关重要 。
-
后过滤(Post-Filtering):先进行向量搜索找到Top K(比如100个),然后在结果中应用过滤器(年份=2023)。
- 风险:如果Top 100中没有一个是在2023年发布的,用户将得到零结果,即使数据库中确实存在符合条件的文档。这会导致召回率的灾难性下降。
-
预过滤(Pre-Filtering):先筛选出所有2023年的文档,然后在该子集中进行向量搜索。
- 挑战:对于HNSW索引,预过滤意味着在遍历图时必须忽略不符合条件的节点。如果符合条件的节点在图中分布稀疏,或者被大量不符合条件的节点"包围",贪婪搜索算法可能会陷入死胡同(无法找到下一个有效的邻居),导致搜索提前终止。这被称为"连接性断裂"。
-
优化方案 :现代数据库(如Qdrant, Azure AI Search)采用"适应性过滤"或"严格后过滤"(Strict Post-Filtering)策略。例如,Azure的
strictPostFilter会动态扩大搜索范围,直到找到足够数量的符合过滤条件的结果;或者在构建HNSW图时就考虑到元数据连接,确保图在特定过滤条件下的连通性(如Acorn算法)。
5.3 晚期交互(Late Interaction)与 ColBERT
传统的向量搜索采用**双编码器(Bi-Encoder)**架构:查询和文档分别被编码为一个单向量。这意味着文档中所有的细微语义都必须被压缩到一个定长向量中,不可避免地会造成信息丢失(Information Bottleneck)。
**ColBERT(Contextualized Late Interaction over BERT)**提出了一种范式转移:
-
机制 :它不将文档压缩为一个向量,而是为文档中的每个Token生成一个向量。查询也是如此。
-
交互:在搜索时,它计算查询中的每个Token向量与文档中每个Token向量的相似度(MaxSim操作),然后求和。
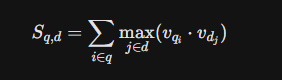
-
优势:这种"细粒度"匹配能力使得ColBERT在处理复杂查询时具有惊人的准确性,能够捕捉到"单向量"模型忽略的细节。
-
代价:存储成本激增。存储一篇1000词的文档需要1000个向量,是Bi-Encoder的1000倍。因此,ColBERT通常用于**重排序(Re-ranking)**阶段,即先用高效的Bi-Encoder检索Top 100,再用ColBERT进行精细排序 。
5.4 多模态检索(Multi-Modal):跨越感官的搜索
以OpenAI的CLIP(Contrastive Language-Image Pre-training)模型为代表的多模态技术,将图像和文本映射到了同一个向量空间 。
-
原理:模型通过对比学习训练,使得描述图片的文本向量(如"一只在草地上奔跑的狗")与该图片的视觉向量在空间中尽可能接近。
-
零样本能力(Zero-Shot):这意味着系统可以在从未见过特定标签的情况下进行分类或检索。用户搜索"红色复古连衣裙",系统直接计算该文本向量与商品图片向量的相似度,无需人工给图片打上"红色"、"复古"的标签 。
-
应用:以图搜图、文本搜视频、甚至通过草图搜索实物。Weaviate等数据库已内置了对多模态模型的支持(如ColPali),使得处理PDF等复杂图文文档变得更加直接 。
6. 性能基准与评估体系
如何评价一个向量搜索系统的好坏?除了基本的QPS(每秒查询数)和延迟,我们更关注检索的质量。
6.1 BEIR 基准测试:权威的试金石
BEIR(Benchmarking IR)是目前评估信息检索模型泛化能力的标准框架,包含18个不同领域的数据集(如生物医学、金融、新闻、问答)。
-
关键发现:
-
BM25的鲁棒性:在许多特定领域(Out-of-Distribution)的任务中,传统的BM25表现依然强劲,甚至优于某些未微调的稠密向量模型。这打破了"向量即万能"的迷思。
-
混合搜索的统治力:BEIR结果一致表明,BM25 + Dense Retrieval的混合方案能获得最高的NDCG@10(归一化折损累计增益)分数 。
-
ColBERT的优越性:在精细排序任务上,ColBERT类模型显著优于单向量模型,尽管计算成本更高。
-
6.2 延迟与召回率的权衡曲线(Recall-Latency Trade-off)
在工程实践中,不存在单一的"最佳配置"。通过调整HNSW的efSearch参数,我们可以绘制出一条曲线:
-
低延迟区 :
efSearch较小,响应时间亚毫秒级,召回率可能在85%-90%。这对于电商推荐等容错率高的场景足够了。 -
高召回区 :
efSearch较大,响应时间增加到10ms+,召回率逼近99%。这对于法律搜证、反欺诈等不能漏掉关键信息的场景是必须的 。 -
长尾延迟问题:平均召回率高并不代表一切。正如55中提到的案例,某些"长尾"查询(Tail Queries)的性能可能极差,导致用户体验断崖式下跌。评估系统时必须关注P95或P99延迟下的召回率表现 。
7. 未来趋势
向量搜索技术正处于快速迭代期,以下趋势将定义未来几年的技术格局。
7.1 二进制量化(BQ)的全面普及
随着嵌入模型维度向3072维甚至更高发展,存储压力迫使业界转向更激进的压缩。二进制量化(Binary Quantization)将浮点数压缩为比特位,实现32倍的空间节省。
- 趋势:结合"重排序"策略(先用BQ快速检索Top N,再用原始向量精排),BQ将在保持高精度的同时,使单机承载百亿级向量成为可能。Elasticsearch的BBQ测试表明,其速度比PQ快2-4倍 。
7.2 实时图索引的动态更新挑战
目前的HNSW实现在处理大量删除和更新操作时往往表现不佳,会导致图结构的退化和"脏数据"残留。
- 趋势:下一代索引算法将专注于"实时图"(Real-time Graph)的维护,采用更智能的垃圾回收机制和局部图重构算法,以解决"不可达点"问题,适应高频交易或实时推荐等场景 。
7.3 Agentic RAG 与多跳检索(Multi-Hop)
随着AI代理(Agent)的兴起,检索不再是一次性的。一个复杂的Agent可能需要自主进行多次检索、推理、再检索(Multi-hop Retrieval)才能回答一个问题。
- 影响:这对向量数据库的并发能力和超低延迟提出了极高要求。因为一次用户交互可能在后端触发数十次向量搜索。未来的数据库将更多地集成"推理"能力,甚至在数据库内部运行轻量级Agent逻辑 。
8. 结论
向量搜索技术已经完成了从实验室到生产环境的跨越,成为连接人类认知意图与机器数据处理的桥梁。对于企业架构师而言,选择不再是"是否使用向量搜索",而是"如何设计向量架构"。
是选择Milvus这样的重型分布式系统以应对百亿规模,还是选择Postgres+pgvector以保持架构简洁?是追求纯向量的极致语义,还是通过混合搜索兼顾关键词的精确性?答案隐藏在对应用场景的深刻理解中:对召回率的容忍度、对延迟的敏感度、以及数据本身的模态特征。
随着二进制量化的成熟和Agentic RAG的爆发,向量数据库将变得更加轻量、高效且智能。它们将不再仅仅是存储数据的仓库,而是成为AI系统长期记忆和动态知识获取的主动参与者。