一、模型蒸馏的核心思想
大模型蒸馏,就像一个学生(小模型)向一位知识渊博的老师(大模型)学习,目的是让这个学生变得和老师一样聪明,但体型更小、反应更快。

通俗易懂的比喻
老师(大模型): 一位茶道大师。他不仅能告诉你一杯茶是"好喝"还是"不好喝"(硬标签),还能细致地描述出这杯茶有"茉莉花香、回甘微甜略带涩感"(软标签/知识)。他的知识非常渊博,但泡茶的过程很复杂、很慢。
学生(小模型): 一个想学泡茶的徒弟。他想学到大师的本事,但希望自己的泡茶流程能更简单、更快速,以便在茶馆里服务更多客人。
二、蒸馏过程:
a.大师泡好一壶茶(大模型在大量数据上训练完成)
b.徒弟不是只看大师给出的最终结论("这茶好喝")而是去仔细品味大师泡的茶,学习其中细微的滋味层次(学生模型学习大模型输出的概率分布)
c.徒弟通过反复品尝和模仿,最终自己也能泡出味道非常接近大师的茶,而且速度更快、流程更简单。
这个"学习细微滋味"的过程,就是蒸馏的精髓。
三、为什么要做模型蒸馏?
既然已经有了大模型,为什么还需要一个小模型呢?
1.体积小,部署易:
大模型: 可能有数百亿甚至万亿参数,需要0巨大的存储空间和内存,普通服务器或手机根本无法运行。
小模型: 经过蒸馏后,可能只有几亿或几十亿参数,可以轻松部署在手机或普通的云服务器上。
2.速度快,效率高:
大模型: 生成一次回答可能需要好几秒甚至0更长时间,计算成本非常高。
小模型: 响应速度极快,可以达到毫秒级。非常适合需要实时交互的应用(如智能客服,语音助手)。
3. * 成本低:*
运行大模型需要昂贵的GPU集群,电力和硬件成本巨大。
运行小模型成本低廉,可以让更多企业和开发者用得起。
四、蒸馏是如何工作的?(技术核心)
蒸馏的关键在于让学生模型模仿教师模型的"输出概率分布",而不仅仅是最终答案。
举个例子: 识别一张图片是"猫"、"狗"还是"狐狸"
硬标签(普通训练):
数据标签是1,0,0。
小模型只朝着"100%是猫,0%是狗,0%是狐狸"这个绝对正确的目标学习。
软标签(蒸馏训练):
我们让大模型看同一张猫的图片,它可能会输。出一个概率分布:0.85,0.1,0.05。
这个分布就是"软标签"。它告诉我们: 这极大概率是猫,但也和狗有一点点像(比如耳朵),和狐狸相似度最低。
这个 0.85,0.1,0.05包含了比1,0,0更丰富的知识(比如猫和狗的相似性)
图解:
将同一批训练数据分别输入教师模型和学生模型。根据硬标签和软标签,计算学生模型的损失函数,从而更新学生模型参数。重复上述步骤直到学生模型收敛。

由此可见,损失函数的设计是整个蒸馏过程的核心。
五、蒸馏的损失函数:
在训练学生模型时,我们会设计一个损失函数,它同时考虑两个方面:
1.蒸馏损失:
让学生模型的输出概率分布,尽可能地接近老师模型的输出概率分布。通常使用 KL散度 来衡量两个分布之间的差异。
蒸馏损失=KL散度(学生模型的软标签||教师模型的软标签)
2.学生损失: 让学生模型的输出,也尽可能地接近真实的硬标签数据。
学生损失=交叉熵损失(学生模型的输出||真实硬标签)
通过平衡这两个目标,学生模型既能从老师的"经验"中学习,也不会完全偏离真实答案。
把两部分结合起来:
总损失=α x KL散度(学生软标签,教师 软标签)+(1-α) x 交叉熵(学生输出,真实硬标签)
α是一个超参数(通常 0<α<1),用来平衡两个损失的权重
痛点
不同的大模型Tokenizer分词器不统一,在软标签知识蒸馏中,教师模型与学生模型若为不同模型,学生模型无法直接学习教师模型输出软标签
比如: 同一句话(大模型的底层原理),Tokenizer不同的大模型会被切分成不同的token序列
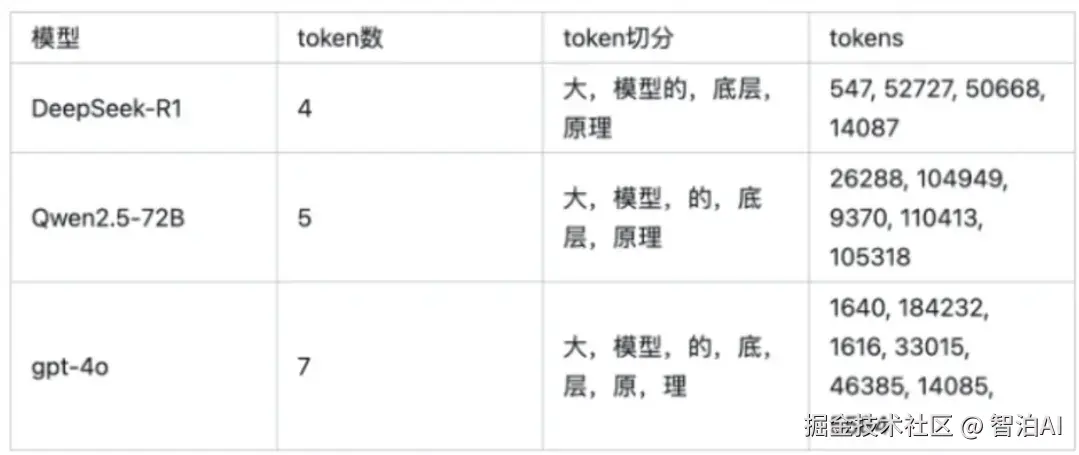
解决办法:
1、统一Tokenizer
让学生模型使用与教师模型相同的Tokenizer。那么教师模型的软标签可以直接用来训练学生模型
2、数据蒸馏法
让教师模型先生成大量高质量回答,构建出QA对然后使用SFT技术训练学生模型,完全避开了token层面的比较,而是统一为纯文本数据。基于知识蒸馏是大语言模型蒸馏的常用方法。
数据蒸馏也能解决目前很多领域缺乏高质量的标注数据的问题
六、数据(QA对)合成流程:
业务场景逻辑确认 -->LLM反向合成Query -->Query清洗(或改写)-->LLM打标 -->人工复核 -->数据交付
怎么生成高质量、多样性的问答对
1、不同采样参数设置:
设置不同的温度参数、top-p等,形成多种参数组合,可合成多样性相对丰富的数据,例如增加temperature,让模型采样随机性增加; 加大topp,让模型的采样范围扩大;
2、多模型组合合成: 采样不同大模型进行合成或清洗,例如分别使用Gemini-2.5、Claude-4、GPT4.1、DeepSeek-R1进行合成,同时也可以编写多套prompt进行处理以此提升合成数据的多样性与质量。
更多AI大模型学习视频及资源,都在智泊AI。