备注 :回顾看过的论文,对目前看过的DeepSeek MoE进行整理在此总结(注:笔者水平有限,若有描述不当之处,欢迎大家留言。后期会继续更新LLM系列,文生图系列,VLM系列,agent系列等。如果看完有收获,可以【点赞】【收藏】【加粉】)
阐述的思维逻辑:会给出论文中的核心点和核心点的描述。
一句话总结: DeepSeekMoE 通过将更强的"专家专精 "策略(路由专家与共享专家 结合),消除了传统 MoE 的知识冗余;通过协同的平衡损失与并行策略,在大幅扩展专家组合容量的同时实现更强的专家专精,从而以显著更低的激活计算(FLOPs)接近或超越更大规模的传统 MoE/稠密基线,是目前 MoE 架构演进中的重要里程碑。
技术亮点:
1架构改变:实现了**"通专分离"**。通用知识被压缩在共享专家中,路由专家则从通用知识的负担中解脱出来,能够专注于学习特定任务的细节,从而大幅减少了模型参数的冗余
-
共享专家(Shared Experts) :指定一部分专家始终被激活,负责处理所有 Token 共享的通用知识。
-
路由专家(Routed Experts):其余专家通过 Router 动态选择,专注于处理特定领域的稀疏知识。
2双层均衡损失:DeepSeekMoE 并没有简单地使用单一的负载均衡损失,而是将其拆分为两个维度,分别解决模型训练的有效性和硬件计算的效率问题
-
专家级平衡 (Expert-Level Balance):防坍塌,保性能。防止出现"赢家通吃"现象(即少数专家处理大部分 Token,而其他专家闲置),确保 Routed Experts 被充分利用。
-
设备级平衡 (Device-Level Balance):优化计算效率。解决**专家并行(Expert Parallelism, EP)**带来的硬件瓶颈。当专家分布在不同的 GPU 上时,如果不同设备上的专家负载不均,会导致整个系统的计算速度取决于最慢的那个 GPU(木桶效应)。
备注:后续为机器翻译
摘要
在大语言模型时代,Mixture-of-Experts(MoE)是一种在扩展模型参数规模时管理计算成本的有前景的架构。然而,传统的 MoE 架构(如 GShard),采用在 𝑁 个专家中激活 top-𝐾 个的方式,面临难以确保"专家专精"(expert specialization)的问题------即每个专家获得不重叠且聚焦的知识。为此,我们提出了 DeepSeekMoE 架构,旨在实现"终极专家专精"。该架构包含两个主要策略:(1)将专家细致划分为 𝑚𝑁 个,并从中激活 𝑚𝐾 个,使得被激活专家的组合更加灵活;(2)隔离出 𝐾𝑠 个专家作为共享专家 ,以捕获通用知识并减少路由专家之间的冗余。从具有 20 亿参数的小规模模型开始,我们展示了 DeepSeekMoE 2B 的性能可与 GShard 2.9B 相媲美,而后者的专家参数与计算量均为前者的 1.5 倍。此外,DeepSeekMoE 2B 的性能几乎接近其具有相同总参数量的稠密模型(dense counterpart),该稠密模型代表了 MoE 模型性能的上限。随后,我们将 DeepSeekMoE 扩展到 160 亿参数,并展示了其性能可与 LLaMA2 7B 相当,但计算量仅约为其 40%。进一步地,我们将 DeepSeekMoE 初步扩展到 1450 亿参数,其结果持续验证了DeepSeekMoE 相比 GShard 架构的显著优势,并显示其性能可与 DeepSeek 67B 相当,而计算量仅为后者的 28.5%(甚至可能是 18.2%)。
一 介绍
最近的研究和实践经验表明,在有足够的训练数据的情况下,用增加的参数和计算预算来缩放语言模型可以产生非常强大的模型(Brown等人,2020;Hoffmann等人,2022;OpenAI,2023;Touvron等人,2023a)。然而,必须承认,将模型扩展到超大规模的努力也与极高的计算成本有关。考虑到巨大的成本,混合专家(MoE)架构(Jacobs等人,1991;Jordan和Jacobs,1994;Shazeer等人,2017)已成为一种流行的解决方案。它可以实现参数缩放,同时将计算成本保持在适度的水平。最近,MoE架构在Transformers中的应用(Vaswani等人,2017)成功地将语言模型扩展到了相当大的规模(Du等人,2022;Fedus等人,2021;Lepikhin等人,2021,Zoph,2022),并取得了显著的性能。这些成就突显了MoE语言模型的巨大潜力和前景。
尽管MoE架构具有巨大的潜力,但现有的MoE架构可能存在知识混合(knowledge hybridity )和知识冗余(knowledge redundancy)的问题,这限制了专家的专业化,即每个专家都获得了不重叠和集中的知识。传统的MoE架构用MoE层代替 Transformer 中的前馈网络(FFN)。每个MoE层由多个专家组成,每个专家的结构都与标准FFN相同,每个令牌(token)都分配给一个(Fedus等人,2021)或两个(Lepikhin等人,2021年)专家。这种架构体现了两个潜在的问题 :(1)知识混合 :现有的 MoE 实践通常雇佣有限数量的专家(例如8或16名),分配给特定专家的标记可能会涵盖不同的知识。因此,指定的专家将打算在其参数中收集截然不同类型的知识,这些知识很难同时使用。(2)知识冗余:分配给不同专家的令牌可能需要共同知识。因此,多个专家在获取各自参数的共享知识时可能会趋同,从而导致专家参数中的冗余。这些问题共同阻碍了现有 MoE 实践中的专家专业化,使其无法达到 MoE 模型的理论上限性能。
针对上述问题,我们介绍了DeepSeekMoE,这是一种专门为最终专家专业化而设计的创新MoE架构。我们的架构涉及两个主要策略 :(1)细粒度专家分割 :在保持参数数量不变的同时,我们通过分割FFN中间隐藏维度将专家分割成更细粒度。相应地,在保持恒定计算成本的情况下,我们还激活了更细粒度的专家,以实现更灵活、适应性更强的激活专家组合。细粒度的专家细分允许将不同的知识更精细地分解,并更精确地学习到不同的专家中,每个专家都将保持更高的专业水平。此外,组合活跃专家的灵活性增加也有助于更准确、更有针对性地获取知识。(2)共享专家隔离 :我们隔离某些专家,作为始终处于活动状态的共享专家,旨在在不同的环境中捕获和巩固共同知识。通过将共同知识压缩到这些共享专家中,将减少其他路由专家之间的冗余。这可以提高参数效率,并确保每个路由专家通过专注于独特的方面来保持专业性。DeepSeekMoE中的这些架构创新为训练一个参数高效的MoE语言模型提供了机会,在这个模型中,每个专家都是高度专业化的。
从2B参数的适度规模开始,我们验证了DeepSeek MoE架构的优势。我们对跨越不同任务的12个零样本或少样本基准进行评估。实证结果表明,DeepSeekMoE 2B远远超过了GShard 2B(Lepikhin等人,2021),甚至与GShard 2.9B相匹配,后者是一个具有1.5×专家参数和计算的更大MoE模型。值得注意的是,我们发现DeepSeekMoE 2B在参数数量相等的情况下几乎接近其密集对应物的性能,这设定了MoE语言模型的严格上限。为了寻求更深入的见解,我们对DeepSeekMoE的专家专业进行了详细的消融研究和分析。这些研究验证了细粒度专家分割和共享专家隔离的有效性,并提供了实证证据支持DeepSeekMoE可以实现高水平的专家专业化。
利用我们的架构,我们随后将模型参数扩展到16B,并在具有2T令牌的大规模语料库上训练DeepSeekMoE 16B。评估结果显示,DeepSeekMoE 16B的计算量仅为40%左右,其性能与DeepSeek 7B(DeepSeek AI,2024)相当,DeepSeek是一个在相同2T语料库上训练的密集模型。我们还将DeepSeekMoE与开源模型进行了比较,评估结果表明,DeepSeekMoE 16B在激活参数数量相似的情况下始终表现出色,并与LLaMA2 7B(Touvron等人,2023b)达到了相当的性能,后者大约是激活参数的2.5倍。图1显示了Open LLM排行榜上的评估结果1。此外,我们进行监督微调(SFT)以进行对齐,将模型转换为聊天模型。评估结果显示,DeepSeekMoE Chat 16B在聊天设置中也实现了与DeepSeek Chat7B和LLaMA2 SFT 7B相当的性能。受到这些结果的鼓舞,我们进一步开展了将De epSeekMoE规模扩大到145B的初步努力。实验结果仍然一致地证明了其相对于GShard架构的实质性优势。此外,它的性能与DeepSeek 67B相当,只使用了28.5%(甚至18.2%)的计算。
我们的贡献总结如下:
架构创新 。我们介绍了DeepSeekMoE,这是一种旨在实现最终专家专业化的创新MoE架构,它采用了细粒度专家分割和共享专家隔离两种主要策略。
实验验证 。我们进行了广泛的实验,以实证验证DeepSeekMoE架构的有效性。实验结果验证了DeepSeekMoE 2B的高水平专家专业化,并表明DeepSeekMoE 2B几乎可以接近MoE模型的上限性能。
可扩展性 。我们扩大了DeepSeekMoE的规模来训练16B模型,并表明仅需约40%的计算,DeepSeekMoE 16B的性能与DeepSeek 7B和LLaMA2 7B相当。我们还初步尝试将DeepSeekMoE扩展到145B,突出其相对于GShard架构的持续优势,并显示出与DeepSeek 67B相当的性能。
MOE 的校准 。我们成功地对 DeepSeekMoE 16B进行了监督微调,创建了一个对齐的聊天模型,展示了DeepSeekMoE 16B的适应性和多功能性。
公开发布。本着开放研究的精神,我们向公众发布了DeepSeekMoE 16B的模型检查点。值得注意的是,该模型可以部署在具有40GB内存的单个GPU上,而不需要量化。
二 前置知识:Transformers 架构下的MoE
首先,我们介绍一种在Transformer语言模型中常用的通用MoE(Mixture of Experts,混合专家)架构。一个标准的 Transformer语言模型是通过堆叠 L LL 层标准的Transformer块构建的,每个块可以表示如下:
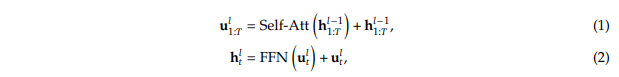
其中 𝑇 表示序列长度,Self-Att(·) 表示自注意力模块,FFN(·) 表示前馈网络(FFN),u𝑙1:𝑇∈ R𝑇×𝑑 是经过第 𝑙 层注意力模块后所有 token 的隐藏状态,而 h𝑙𝑡 ∈ R𝑑 是经过第 𝑙 个 Transformer 模块后第 𝑡 个 token 的输出隐藏状态。为简洁起见,我们在上述公式中省略了层归一化(layer normalization)。
一种典型的构建 MoE 语言模型的方法是,在 Transformer 中以特定的间隔将 FFN 替换为 MoE 层(Du et al., 2022; Fedus et al., 2021; Lepikhin et al., 2021; Zoph, 2022)。一个 MoE 层由多个专家(experts)组成,其中每个专家在结构上与标准 FFN 相同。然后,每个 token 将被分配给一个(Fedus et al., 2021)或两个(Lepikhin et al., 2021)专家。如果第 𝑙 个 FFN 被替换为一个 MoE 层,则其输出隐藏状态 h𝑙𝑡 的计算形式为:
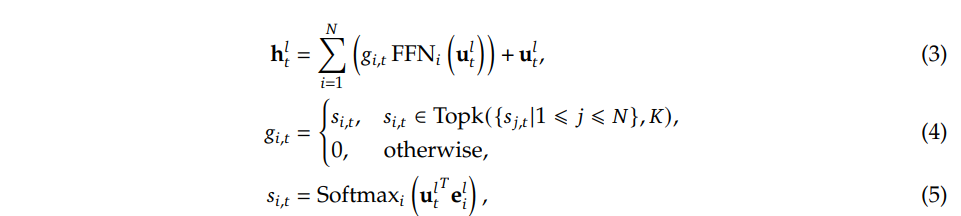
其中 𝑁 表示专家总数,FFN𝑖(·) 是第 𝑖 个专家 FFN,𝑔𝑖,𝑡 表示第 𝑖 个专家的门控值(gate value),𝑠𝑖,𝑡 表示 token 与专家之间的亲和度(affinity),Topk(·, 𝐾) 表示针对第 𝑡 个 token 在全部 𝑁 个专家中选取得分最高的 𝐾 个亲和度分数的集合,而 e𝑙𝑖 表示第 𝑙 层中第 𝑖 个专家的中心(centroid)。注意 𝑔𝑖,𝑡 是稀疏的,这意味着只有 𝐾 个门控值是非零的。该稀疏性保证了 MoE 层的计算效率,即每个 token 仅会被分配给 𝐾 个专家进行计算。同样地,在以上公式中,我们为简洁起见省略了层归一化操作。
三 DeepSeekMoE架构
在第2节概述的通用MoE架构基础上,我们引入了DeepSeekMoE,该架构专门设计用于充分利用专家专业化的潜力。如图2所示,我们的架构包含两个主要策略:细粒度专家分割和共享专家隔离。这两种策略旨在提升专家专业化的水平。
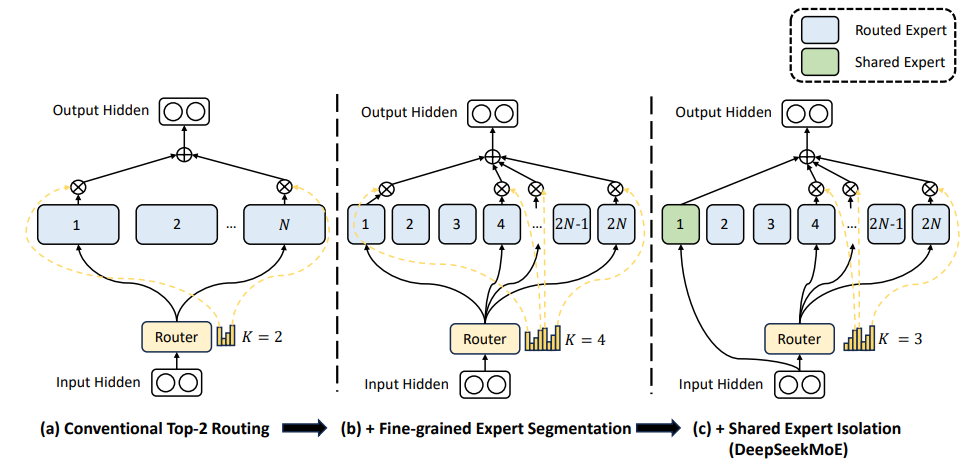 图2为 DeepSeekMoE 的示意图。子图(a) 展示了采用传统 top-2 路由策略的 MoE 层。子图(b)展示了细粒度的专家分割策略。随后,子图(c)展示了共享专家隔离策略的集成,从而构成了完整的DeepSeekMoE 架构。值得注意的是,在这三种架构中,专家参数的数量和计算成本保持不变。
图2为 DeepSeekMoE 的示意图。子图(a) 展示了采用传统 top-2 路由策略的 MoE 层。子图(b)展示了细粒度的专家分割策略。随后,子图(c)展示了共享专家隔离策略的集成,从而构成了完整的DeepSeekMoE 架构。值得注意的是,在这三种架构中,专家参数的数量和计算成本保持不变。
3.1 细粒度专家分割
在专家数量有限的情况下,被分配到某个特定专家的 tokens 更可能覆盖多样化的知识类型。因此,指定的专家会倾向于在其参数中学习大量不同类型的知识,而这些知识难以同时被有效利用。然而,如果每个 token 可以被路由到更多的专家,那么多样化的知识将有可能在不同的专家中被分别分解和学习。在这种情况下,每个专家仍然可以保持较高水平的专业化,从而实现更为集中的知识分布。
在追求这一目标的过程中,在保持专家参数数量和计算成本一致的前提下,我们对专家进行更细粒度的拆分。更细粒度的专家分割使得激活专家的组合更加灵活与适应性更强。具体而言,在图 2(a) 所示的典型 MoE 架构基础上,我们通过将 FFN 的中间隐藏维度缩小为原来的 1/𝑚,将每个专家 FFN 拆分成 𝑚 个更小的专家。由于每个专家变得更小,为了保持相同的计算成本,我们也将激活专家的数量增加为原来的 𝑚 倍,如图 2(b) 所示。借助这种细粒度专家分割,一个 MoE 层的输出可表示为:

其中,专家参数总量等于 𝑁 倍的标准 FFN 的参数数量,而 𝑚𝑁 表示细粒度专家的总数量。采用细粒度专家分割策略后,非零 gate 的数量也将增加为 𝑚𝐾
从组合的角度来看,细粒度专家划分策略显著增强了已激活专家的组合灵活性。作为说明性示例,我们考虑 𝑁 = 16 的情况。典型的 top-2 路由策略可以产生种可能的组合。相比之下,如果每个专家被划分为 4 个更小的专家,则细粒度路由策略可以产生
种潜在组合。组合灵活性的激增提升了实现更精确、更具针对性知识获取的潜力。
3.2. 共享专家隔离
在传统路由策略中,被分配到不同专家的 token 可能需要某些共同的知识或信息。结果是,多个专家可能会在其各自参数中收敛并获取这些共享知识,从而导致专家参数的冗余。然而,如果存在专门用于捕获并整合跨不同上下文的公共知识的共享专家,那么其他需要路由的专家之间的参数冗余将得到缓解。冗余的减少能够促使模型更加参数高效,并具备更专门化的专家。
为了达到这一目标,除了细粒度专家划分策略之外,我们进一步隔离 𝐾ₛ 个专家作为共享专家。无论路由模块如何,每个 token 都会被确定性地分配到这些共享专家中。为了保持恒定的计算成本,其他路由专家中被激活的专家数量将减少 𝐾ₛ,如图 2(c) 所示。结合共享专家隔离策略后,完整的 DeepSeekMoE 架构中,一个 MoE 层可形式化为: 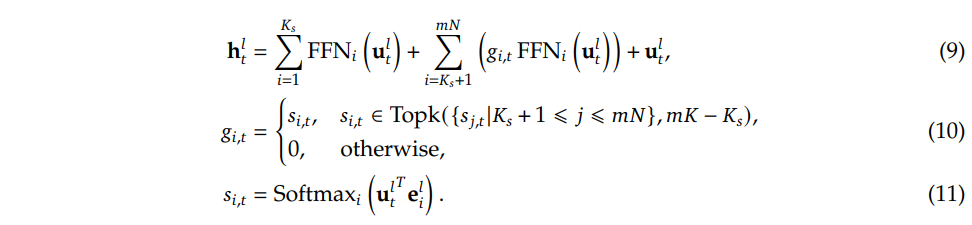
最后,在 DeepSeekMoE 中,共享专家的数量为 𝐾ₛ,总的可路由专家数量为mN−Ks,非零门控(nonzero gates)的数量为mK−Ks。
需要说明的是,共享专家隔离的原型可以归功于Rajbhandari等人(2022)。关键的区别在于,他们是从工程角度推导出了这一策略,而我们则是从算法的角度来进行处理。
3.3 负载均衡考虑
自动学习的路由策略可能会遇到负载不平衡的问题,这表现出两个明显的缺陷。首先,存在路由崩溃的风险(Shazeer等人,2017),即模型总是只选择少数专家,导致其他专家无法得到充分的培训。其次,如果专家分布在多个设备上,负载不平衡会加剧计算瓶颈。
专家级余额损失。为了降低路由崩溃的风险,我们还采用了专家级余额损失。余额损失的计算方法如下:

其中 𝛼1 是一个称为专家级平衡因子的超参数,𝑁′ 等于 (𝑚𝑁 − 𝐾𝑠),𝐾′ 等于 (𝑚𝐾 − 𝐾𝑠),为简洁起见。1(·) 表示指示函数。
设备级平衡损失(Device-Level Balance Loss) 。除了专家级平衡损失之外,我们还引入了设备级平衡损失。在旨在缓解计算瓶颈时,没有必要在专家级别强制施加严格的平衡约束,因为过度的负载均衡约束会损害模型性能。相反,我们的主要目标是确保设备间计算的均衡。如果我们将所有可路由专家划分为 𝐷 个组 {E1, E2, ..., E𝐷},并将每一组部署在一台设备上,则设备级平衡损失计算如下: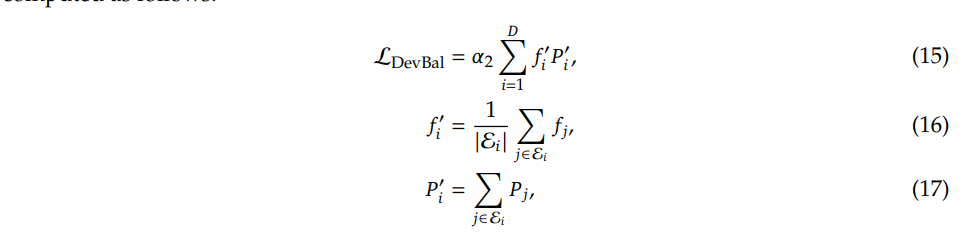
其中 α2 是一个称为设备级均衡因子的超参数。在实践中,我们设置一个较小的专家级均衡因子来降低路由崩溃的风险,同时设置一个较大的设备级均衡因子来促进设备间的均衡计算。
四 实验验证
4.1 实验设置
4.1.1 训练数据和标记化
我们的训练数据是从DeepSeek AI创建的大规模多语言语料库中采样的。该语料库主要关注英语和汉语,但也包括其他语言。它来自不同的来源,包括网络文本、数学材料、编码脚本、已发表的文献和各种其他文本材料。为了进行验证实验,我们从语料库中抽取了一个包含100B个标记的子集来训练我们的模型。对于标记化,我们利用HuggingFace Tokenizer2工具在训练语料库的较小子集上训练字节对编码(BPE)(Sennrich等人,2016)标记器。在验证实验中,我们准备了一个词汇量为8K的标记器,当训练更大的模型时,词汇量会扩大。
4.1.2 基础设施
我们基于HAI-LLM(High Flyer,2023)进行实验,这是一种高效且轻量级的训练框架,集成了多种并行策略,包括张量并行性(Korthikanti等人,2023;Narayanan等人,2021;Shoeybi等人,2019)、ZeRO数据并行性(Rajbhandari等人,2020)、PipeDream流水线并行性(Harlap等人,2018),更具体地说,是通过结合数据和张量并行性来实现专家并行性(Lepikhin等人,2021)。为了优化性能,我们使用CUDA和Triton(Tillet等人,2019)开发了GPU内核,用于不同专家的门控算法和跨线性层的融合计算。
所有实验均在配备NVIDIA A100或H800 GPU的集群上进行。A100集群中的每个节点都包含8个通过NVLink网桥成对连接的GPU。H800集群每个节点还具有8个GPU,在节点内使用NVLink和NVSwitch互连。对于A100和H800集群,InfiniBand互连用于促进节点之间的通信。
4.1.3 超参数
模型设置。在验证实验中,我们将Transformer层数设置为9,隐藏维度设置为1280。我们采用多头注意力机制,共有10个注意力头,每个头的尺寸为128。对于初始化,所有可学习参数都以0.006的标准偏差随机初始化。我们用MoE层替换所有FFN,并确保专家参数的总数等于标准FFN的16倍。此外,我们将激活的专家参数(包括共享专家参数和激活的路由专家参数)保持为标准FFN的2倍。在这种配置下,每个MoE模型的总参数约为2B,激活的参数数量约为0.3B。
训练设置。我们使用 AdamW优化器(Loshchilov和Hutter,2019),将超参数设置为β 1=0.9,β2=0.95,weight_decay=0.1。使用预热和逐步衰减策略来安排学习率。最初,在前2K个步骤中,学习率从0线性增加到最大值。随后,在80%的训练步骤中将学习率乘以0.316,在90%的训练步骤中再次乘以0.316。验证实验的最大学习率设置为1.08×10−3,梯度裁剪范数设置为1.0。批大小设置为2K,最大序列长度为2K,每个训练批包含4M个令牌。相应地,训练步骤的总数被设置为25000,以实现100B个训练令牌。由于训练数据丰富,我们在训练过程中不使用dropout。鉴于模型尺寸相对较小,所有参数(包括专家参数)都部署在单个GPU设备上,以避免计算不平衡。
相应地,我们在训练过程中不会丢弃任何令牌,也不会使用设备级余额损失。为了防止路由崩溃,我们将专家级平衡因子设置为0.01。
4.1.4 评估基准
我们对涵盖各种类型任务的广泛基准进行评估。我们列出了以下基准。
语言建模 。对于语言建模,我们在Pile的测试集上评估模型(Gao等人,2020),评估指标是交叉熵损失。
语言理解和推理 。对于语言理解和推理,我们考虑了HellaSwag(Zellers等人,2019)、PIQA(Bisk等人,2020)、ARC挑战和AREasy(Clark等人,2018)。这些任务的评估指标是准确性。
阅读理解 。对于阅读理解,我们使用RACE high和RACE middleLai等人(2017),评估指标是准确性。
代码生成 。对于代码生成,我们评估了HumanEval(Chen等人,2021)和MBPP(Austin等人,2021年)上的模型。评估指标为Pass@1,其表示仅一代尝试的通过率。
封闭式问答。对于封闭式问答,我们考虑TriviaQA(Joshi等人,2017)和NaturalQuestions(Kwiatkowski等人,2019)。评估指标是精确匹配(EM)率。
4.2 评价
基线。包括DeepSeekMoE在内,我们比较了五个模型进行验证实验。Dense表示总参数为0.2B的标准密集Transformer语言模型。哈希层(Roller等人,2021)是一种基于前1哈希路由的MoE架构,总参数为2.0B,激活参数为0.2B,与密集基线对齐。Switch Transformer(Fedus等人,2021)是另一种基于top-1可学习路由的著名MoE架构,其总参数和激活参数与哈希层相同。GShard(Lepikhin等人,2021)采用了前2名可学习路由策略,与前1名路由方法相比,总共有2.0B个参数和0.3B个激活参数,因为多了一个专家被激活。DeepSeekMoE有1个共享专家和63个路由专家,每个专家的大小是标准FFN的0.25倍。包括DeepSeekMoE在内,所有比较模型共享相同的训练语料库和训练超参数。所有比较的MoE模型具有相同数量的总参数,GShard具有与DeepSeekMoE相同数量的激活参数。
结果。我们将评估结果列于表1中。对于所有演示的模型,我们报告了在100B令牌上训练后的最终评估结果。从表中,我们得出以下观察结果:(1)在稀疏架构和更多总参数的情况下,哈希层和开关变换器的性能明显强于具有相同激活参数数量的密集基线。(2) 与哈希层和开关变换器相比,GShard具有更多的激活参数,性能略优于开关变换器。(3) 在总参数和激活参数数量相同的情况下,DeepSeekMoE比GShard具有压倒性的优势。这些结果展示了我们的DeepSeekMoE架构在现有MoE架构中的优势。
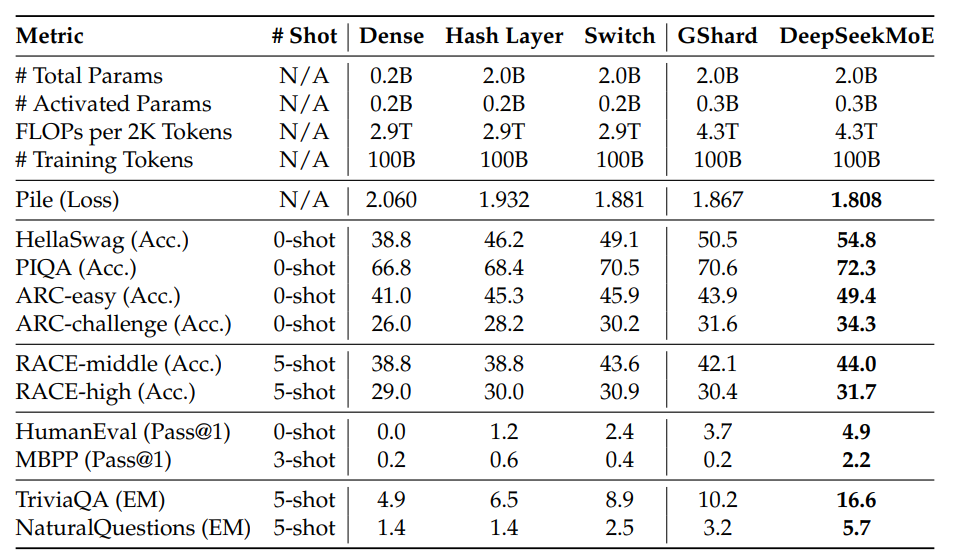 表1 验证实验的评估结果。粗体字表示最佳结果。与其他MoE架构相比,DeepSeekMoE展现出显著的性能优势。
表1 验证实验的评估结果。粗体字表示最佳结果。与其他MoE架构相比,DeepSeekMoE展现出显著的性能优势。
4.3 DeepSeekMoE 与 MoE模型的上限紧密对齐
我们已经证明,DeepSeekMoE的性能优于密集基线和其他MoE架构。为了更精确地了解DeepSeekMoE的性能,我们将其与具有更多总参数或激活参数的较大基线进行了比较。这些比较使我们能够估计GShard或密集基线所需的模型大小,以实现与DeepSeekMoE相当的性能。
与 GShard×1.5 的比较**。** 表 2 展示了 DeepSeekMoE 与一个更大的 GShard 模型的比较,该模型的专家规模是前者的 1.5 倍,因此其专家参数量与专家计算量也均为前者的 1.5 倍。总体而言,我们观察到 DeepSeekMoE 的性能可与 GShard×1.5 相当,凸显了 DeepSeekMoE 架构所固有的显著优势。除了与 GShard×1.5 的比较外,我们还在附录 B 中提供了与 GShard×1.2 的比较。
此外,我们将 DeepSeekMoE 的总参数量增加至 13.3B,并将其与具有 15.9B 和 19.8B 总参数量的 GShard×1.2 和 GShard×1.5 进行比较。我们发现,在更大规模下,DeepSeekMoE 甚至可以明显超越 GShard×1.5。这些结果也在附录 B 中提供。
与 Dense×16 的比较**。** 表 2 还展示了 DeepSeekMoE 与更大稠密模型的比较。为了公平比较,我们没有使用注意力参数与 FFN 参数之间广泛采用的 1:2 比例。相反,我们配置了 16 个共享专家,其中每个专家具有与标准 FFN 相同数量的参数。这种架构模拟了一个 FFN 参数量为标准 16 倍的稠密模型。从表中我们可以看到,DeepSeekMoE 的性能几乎接近 Dense×16,而 Dense×16 在模型容量方面为 MoE 模型设定了严格的上限。这些结果表明,至少在约 20 亿参数和 1000 亿训练 token 的规模下,DeepSeekMoE 的性能与 MoE 模型的理论上限非常接近。此外,我们还在附录 B 中提供了与 Dense×4 的更多比较。
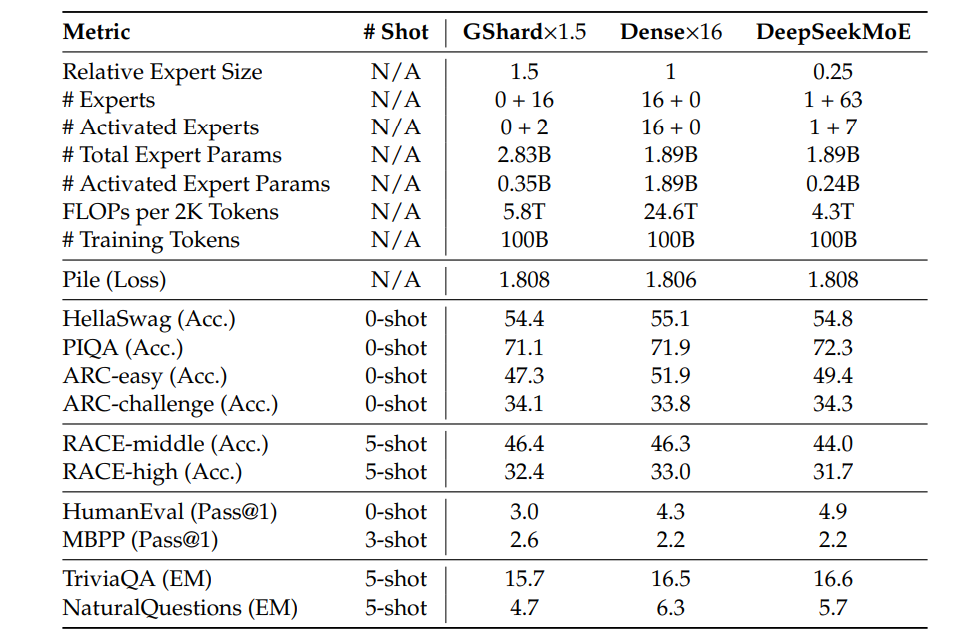 Table 2 | DeepSeekMoE、较大规模 GShard 模型以及较大规模稠密模型的比较。在"# Experts"一行中,𝑎 + 𝑏 表示 𝑎 个共享专家和 𝑏 个路由专家。在"# Activated Experts"一行中,𝑎 + 𝑏 表示 𝑎 个被激活的共享专家和 𝑏 个被激活的路由专家。DeepSeekMoE 在专家参数量和计算量仅为 GShard 模型的约2/3 的情况下,实现了与一个包含 1.5 倍专家参数和计算量的 GShard 模型相当的性能。此外,DeepSeekMoE 的性能几乎接近一个 FFN 参数量为其 16 倍的稠密模型,而该稠密模型代表了在模型容量方面 MoE 模型可达到的上限。
Table 2 | DeepSeekMoE、较大规模 GShard 模型以及较大规模稠密模型的比较。在"# Experts"一行中,𝑎 + 𝑏 表示 𝑎 个共享专家和 𝑏 个路由专家。在"# Activated Experts"一行中,𝑎 + 𝑏 表示 𝑎 个被激活的共享专家和 𝑏 个被激活的路由专家。DeepSeekMoE 在专家参数量和计算量仅为 GShard 模型的约2/3 的情况下,实现了与一个包含 1.5 倍专家参数和计算量的 GShard 模型相当的性能。此外,DeepSeekMoE 的性能几乎接近一个 FFN 参数量为其 16 倍的稠密模型,而该稠密模型代表了在模型容量方面 MoE 模型可达到的上限。
4.3 消融实验
为了验证细粒度专家切分和共享专家隔离策略的有效性,我们对 DeepSeekMoE 进行了消融实验,并在图 3 中展示了实验结果。为了公平比较,我们确保比较中的所有模型具有相同的总参数量和激活参数量。
共享专家隔离。 为了评估共享专家隔离策略的影响,我们基于 GShard 隔离了一个专家作为共享专家。从图 3 可以看到,与 GShard 相比,有意隔离一个共享专家在大多数基准测试中都带来了性能提升。这些结果支持了共享专家隔离策略能够提升模型性能的观点。
细粒度专家切分。 为了评估细粒度专家切分策略的有效性,我们通过进一步将专家切分为更小的粒度进行更详细的比较。具体来说,我们将每个专家切分为 2 个或 4 个更小的专家,从而得到总计 32(1 个共享 + 31 个路由)或 64(1 个共享 + 63 个路由)个专家。图 3 显示出一个一致的趋势:专家切分粒度的持续细化对应着整体模型性能的持续提升。这些结果为细粒度专家切分策略的有效性提供了实证支持。
共享与路由专家比例。 此外,我们研究了共享专家与路由专家的最佳比例。基于总计 64 个专家的最细粒度设置,并保持总专家数量和激活专家数量不变,我们尝试隔离 1、2 和 4 个专家作为共享专家。我们发现,不同的共享与路由专家比例对性能影响不大,1、2 和 4 个共享专家分别达到 1.808、1.806 和 1.811 的 Pile 损失。考虑到 1:3 的比例带来了略微更好的 Pile 损失,在扩展 DeepSeekMoE 时,我们保持共享专家与激活路由专家的比例为 1:3。
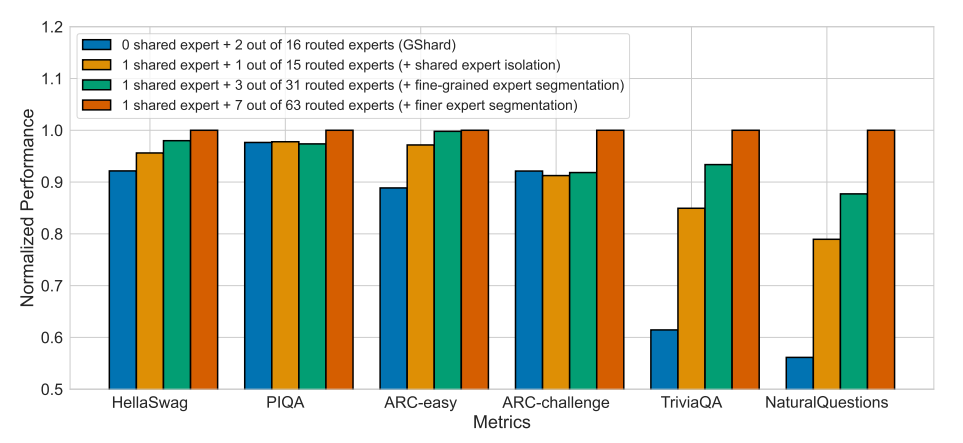 图3为 DeepSeekMoE 的消融研究。为了便于展示,性能已根据最佳性能进行归一化。所有对比模型均具有相同数量的参数和激活参数。我们可以发现,细粒度的专家分割和共享专家隔离均有助于提升整体性能。
图3为 DeepSeekMoE 的消融研究。为了便于展示,性能已根据最佳性能进行归一化。所有对比模型均具有相同数量的参数和激活参数。我们可以发现,细粒度的专家分割和共享专家隔离均有助于提升整体性能。
4.5 专家专业化分析
在本节中,我们对DeepSeekMoE 2B的专家专业化进行了实证分析。本节中的DeepSeekMoE 2B是指表1中报告的模型,即包括2.0B的总参数,其中1个共享专家和63个路由专家中的7个被激活。
DeepSeekMoE在路由专家中表现出较低的冗余度。为了评估路由专家之间的冗余,我们禁用了不同比例的顶级路由专家,并评估了桩损失。具体来说,对于每个令牌,我们屏蔽一定比例的具有最高路由概率的专家,然后从剩余的路由专家中选择前K名专家。为了公平起见,我们将DeepSeekMoE与GShard×1.5进行了比较,因为当没有专家被禁用时,它们具有相同的桩损失。如图4所示,与GShard×1.5相比,DeepSeekMoE对顶级路由专家的禁用更敏感。这种敏感性表明DeepSeekMoE中的参数冗余程度较低,因为每个路由专家都是不可替代的。相比之下,GShard×1.5在其专家参数中表现出更大的冗余,因此当顶级路由专家被禁用时,它可以缓冲性能下降。
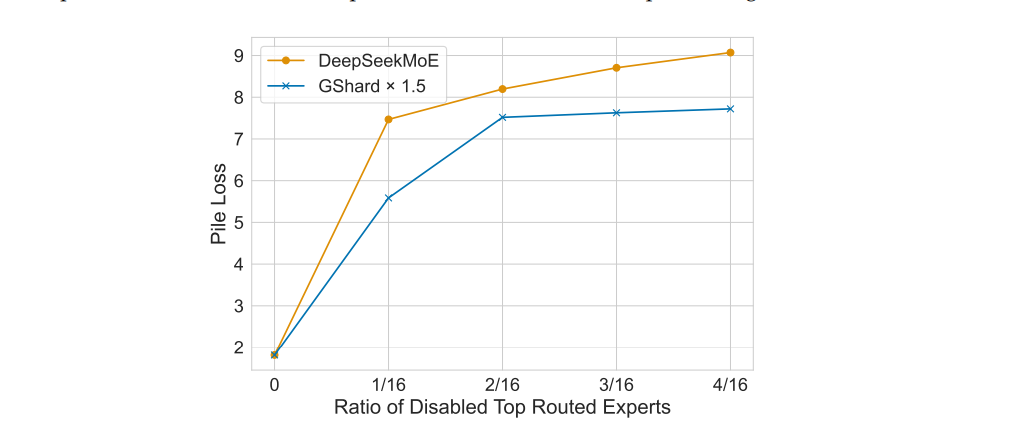 图 4 显示了不同失效顶级路由专家比例下的堆香损失。值得注意的是,DeepSeekMoE 对失效顶级路由专家的比例更为敏感,表明 DeepSeekMoE 中路由专家之间的兄余度较低。
图 4 显示了不同失效顶级路由专家比例下的堆香损失。值得注意的是,DeepSeekMoE 对失效顶级路由专家的比例更为敏感,表明 DeepSeekMoE 中路由专家之间的兄余度较低。
共享专家不可被路由专家所取代。为了调查共享专家在DeepSeekMoE中的作用,我们禁用它并激活另一个路由专家。对桩的评估显示,桩损失显著增加,从1.808上升到2.414,尽管我们保持了相同的计算成本。这一结果突出了共享专家的关键作用,并表明共享专家捕获了与路由专家不共享的基础和基本知识,使其成为路由专家不可替代的知识。
DeepSeekMoE更准确地获取知识。为了验证我们的说法,即结合激活专家的更高灵活性有助于更准确、更有针对性地获取知识,我们研究了DeepSeekMoE是否可以用更少的激活专家获取必要的知识。具体来说,我们将激活的路由专家的数量从3人增加到7人,并评估由此产生的桩损失。如图5所示,即使只有4名路由专家被激活,DeepSeekMoE的桩损失也与GShard相当。这一观察结果支持了DeepSeekMoE可以更准确、更有效地获取必要知识的观点。
受到这些发现的鼓舞,为了更严格地验证DeepSeekMoE的专家专业化和准确的知识获取,我们从头开始训练了一个新模型。该模型包括1个共享专家和63个路由专家,其中只有3个路由专家被激活。图6所示的评估结果表明,即使使用相同的总专家参数和只有一半的激活专家参数,DeepSeekMoE仍然优于GShard。这突显了DeepSeekMoE更有效地利用专家参数的能力,即激活专家中有效参数的比例远高于GShard。
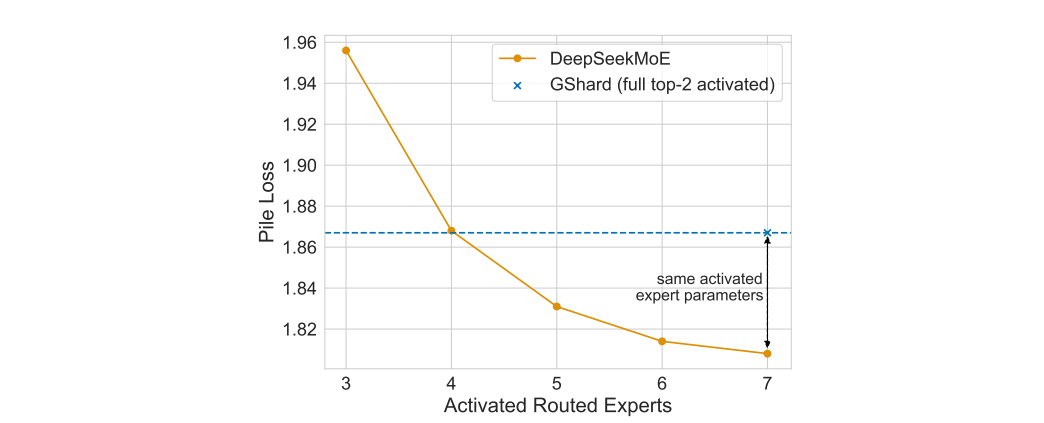 图5 展示了 DeepSeekMoE 中不同激活路由专家数量下的 Pile Loss 情况。仅激活 4 个路由专家时,DeepSeekMoE的Pile Loss 即可与 GShard 相媲美。
图5 展示了 DeepSeekMoE 中不同激活路由专家数量下的 Pile Loss 情况。仅激活 4 个路由专家时,DeepSeekMoE的Pile Loss 即可与 GShard 相媲美。 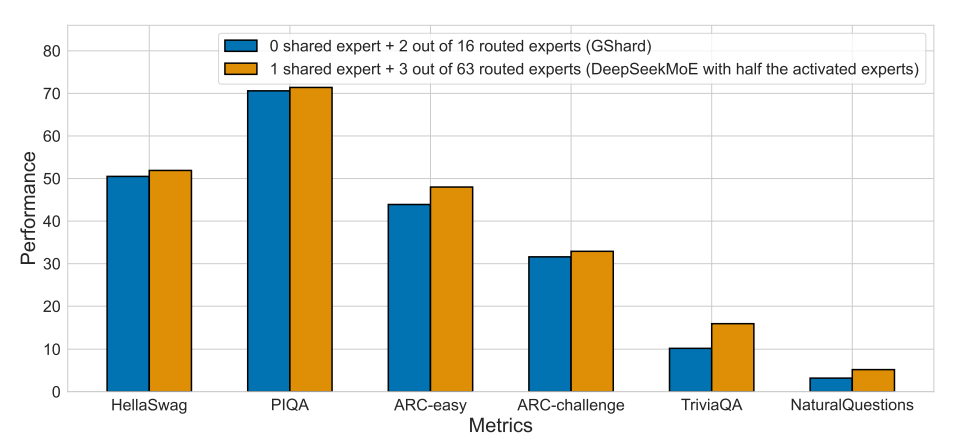 图6 展示了 GShard 和 DeepSeekMoE 在激活专家数量减半(从头开始训练)的情况下的对比。在专家参数总数相同但激活专家参数仅减半的情况下,DeepSeekMoE 的性能仍然优于 GShard。
图6 展示了 GShard 和 DeepSeekMoE 在激活专家数量减半(从头开始训练)的情况下的对比。在专家参数总数相同但激活专家参数仅减半的情况下,DeepSeekMoE 的性能仍然优于 GShard。
五 放大到 DeepSeekMoE 16B
通过DeepSeekMoE架构,我们将MoE模型扩展到更大的规模,总参数为16B,并在2T令牌上进行训练。我们的结果表明,与LLaMA2 7B相比,DeepSeekMoE 16B仅需约40%的计算即可实现卓越的性能。
5.1 实验设置
5.1.1 训练数据和标记化
我们从第4.1.1节所述的同一语料库中采样训练数据。与验证实验不同,我们使用2T令牌对大量数据进行采样,与LLaMA2 7B的训练令牌数量一致。我们还使用HuggingFace Tokenizer工具来训练BPE标记器,但DeepSeekMoE 16B的词汇量设置为100K。
5.1.2 超参数
模型设置。 对于 DeepSeekMoE 16B,我们将 Transformer 层数设为 28,隐层维度设为 2048。我们采用具有 16 个注意力头的多头注意力机制,其中每个头的维度为 128。对于初始化,所有可学习参数均以标准差 0.006 进行随机初始化。我们将除第一层外的所有 FFN 替换为 MoE 层,因为我们观察到第一层的负载均衡状态收敛特别慢。每个 MoE 层由 2 个共享专家和 64 个路由专家组成,其中每个专家的尺寸为标准 FFN 的 0.25 倍。每个 token 会被路由到这 2 个共享专家以及 64 个路由专家中的 6 个。由于过小的专家规模可能导致计算效率下降,因此未采用更细粒度的专家切分。在超过 16B 的更大规模下,仍然可以采用更细的粒度。根据上述配置,DeepSeekMoE 16B 约有 16.4B 的总参数量,其中激活参数量约为 2.8B。
训练设置。 我们采用 AdamW 优化器(Loshchilov and Hutter, 2019),其超参数设置为 𝛽1 = 0.9、𝛽2 = 0.95,weight_decay = 0.1。学习率通过 warmup 和分段衰减策略进行调度。首先,学习率在前 2K 步中从 0 线性上升至最⼤值。随后,在训练步骤的 80% 时将学习率乘以 0.316,并在 90% 时再次乘以 0.316。DeepSeekMoE 16B 的最⼤学习率设为 4.2 × 10⁻⁴,梯度裁剪范数设为 1.0。batch size 设为 4.5K,最大序列长度为 4K,则每个训练 batch 包含 18M tokens。相应地,总训练步数设为 106,449,以完成 2T 训练 token。由于训练数据非常充足,我们在训练中未使用 dropout。我们利用流水线并行将模型的不同层部署到不同设备上,并确保每一层的所有专家部署到同一设备上。因此,我们在训练中不丢弃任何 token,也未使用设备级负载均衡损失。为了防止路由坍塌,我们设置了一个非常小的专家级负载均衡因子 0.001,因为我们发现,在当前的并行策略下,更高的专家级均衡因子不能提升计算效率,反而会损害模型性能。
5.1.3. 评测基准
在验证实验使用的基准之外,我们引入了更多评测基准,以实现更全面的评估。与验证实验基准的区别如下。
语言建模。 在语言建模方面,我们还在 Pile(Gao et al., 2020)的测试集上评估模型。由于 DeepSeekMoE 16B 使用的 tokenizer 与 LLaMA2 7B 不同,为公平比较,我们使用 bits per byte(BPB)作为评测指标。
阅读理解。 在阅读理解方面,我们额外考虑 DROP(Dua et al., 2019)。评测指标为 Exactly Matching(EM)。
数学推理。 在数学推理方面,我们额外加入 GSM8K(Cobbe et al., 2021)和 MATH(Hendrycks et al., 2021),评测指标为 EM。
多学科多项选择。 在多学科多项选择评测中,我们额外在 MMLU(Hendrycks et al., 2020)上评估模型,评测指标为 accuracy。
消歧任务。 在消歧任务中,我们额外考虑 WinoGrande(Sakaguchi et al., 2019),评测指标为 accuracy。
中文基准。 由于 DeepSeekMoE 16B 在双语语料上进行了预训练,我们还在四个中文基准上进行了评测。CLUEWSC(Xu et al., 2020)是中文消歧基准;CEval(Huang et al., 2023)与 CMMLU(Li et al., 2023)是与 MMLU 类似的中文多学科多项选择基准;CHID(Zheng et al., 2019)是中文成语填空任务,评测模型对中文文化的理解。上述中文基准的评测指标均为 accuracy 或 EM。
公开LLM排行榜。 我们将上述所有评测基于内部评估框架完成。为了与开源模型进行公平且便捷的比较,我们还在 Open LLM Leaderboard 上评测 DeepSeekMoE 16B。Open LLM Leaderboard 是由 HuggingFace 提供支持的公共排行榜,包含六项任务:ARC(Clark et al., 2018)、HellaSwag(Zellers et al., 2019)、MMLU(Hendrycks et al., 2020)、TruthfulQA(Lin et al., 2022)、Winogrande(Sakaguchi et al., 2019)以及 GSM8K(Cobbe et al., 2021)。
5.2 评估
5.2.1 与 DeepSeek 7B 的内部对比
我们首先将 DeepSeekMoE 16B 与 DeepSeek 7B(DeepSeekAI, 2024)进行对比,后者是一个具有 6.9B 参数的稠密语言模型。为了确保公平性,两者均在相同语料上的 2T token 上训练。这使我们能够准确评估 MoE 架构本身的效果,排除训练数据差异的影响。
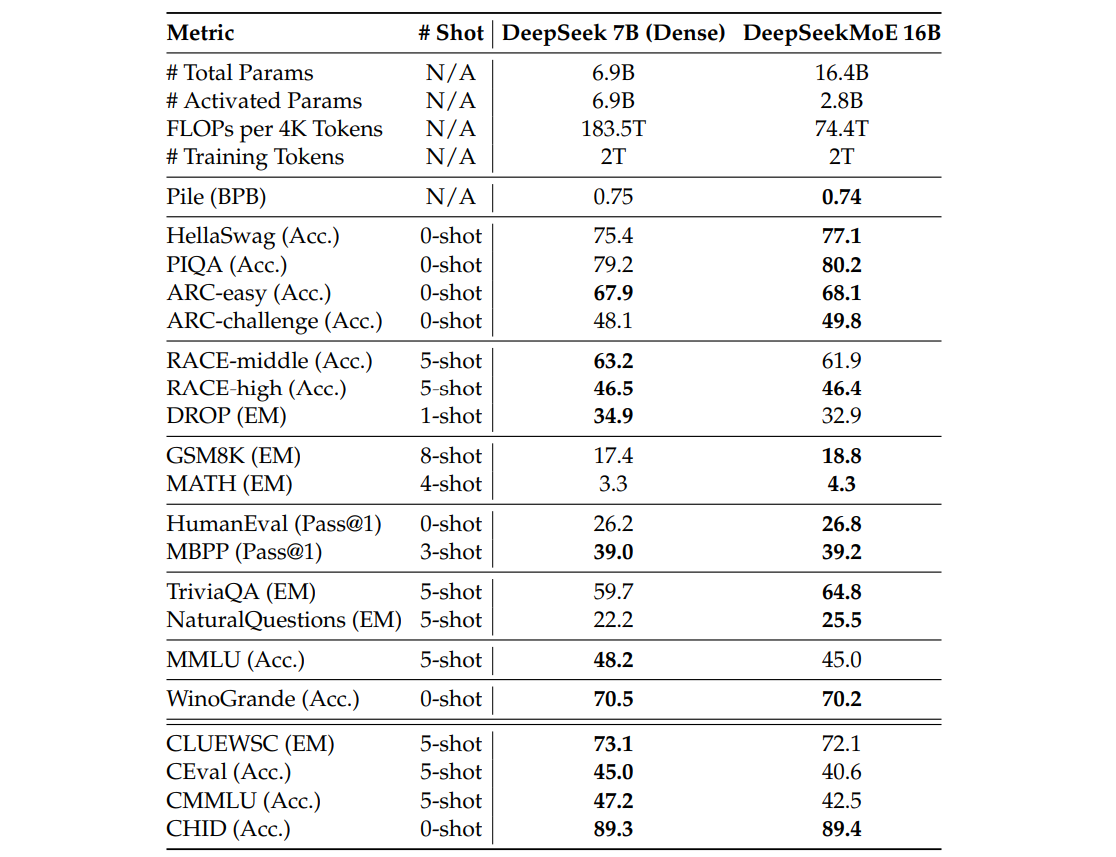 表3 DeepSeek7B与DeepSeekMoE16B的比较粗体字表示最佳或接近最佳的性能。DeepSeekMoE 16B仅需40.5%的计算量即可达到与DeepSeek 7B相当的性能。
表3 DeepSeek7B与DeepSeekMoE16B的比较粗体字表示最佳或接近最佳的性能。DeepSeekMoE 16B仅需40.5%的计算量即可达到与DeepSeek 7B相当的性能。
评估结果如表 3 所示,可得出以下观察:(1) 总体而言,DeepSeekMoE 16B 仅使用约 40% 的计算量,即可达到与 DeepSeek 7B 可比的性能。(2) DeepSeekMoE 16B 在语言建模和知识密集型任务上表现出显著优势,例如 Pile、HellaSwag、TriviaQA 和 NaturalQuestions。由于 MoE 模型中 FFN 参数远多于注意力参数,这一结果与"Transformer 的 FFN 具备记忆知识能力"的观点一致(Dai et al., 2022a)。(3) 与其他任务相比,DeepSeekMoE 在多项选择任务上表现较弱。这一不足源于 DeepSeekMoE 16B 的注意力参数量有限(DeepSeekMoE 16B 仅约 0.5B 注意力参数,而 DeepSeek 7B 有 2.5B)。我们此前对 DeepSeek 7B 的研究也发现注意力容量与多项选择任务性能呈正相关。例如,采用多查询注意力机制(MQA)的 DeepSeek 7B MQA 在 MMLU 类任务中也表现较差。此外,为了提供更全面的训练过程理解,我们在附录 C 中提供了 DeepSeekMoE 16B 与 DeepSeek 7B(Dense)的训练曲线供参考。
值得注意的是,由于 DeepSeekMoE 16B 参数量适中,它可以在单张 40GB GPU 上部署。在适当的算子优化下,其推理速度可达到 7B 稠密模型的近 2.5 倍。
5.2.2 与开源模型的比较
与 LLaMA2 7B 的内部对比。 在开源模型领域,我们主要将 DeepSeekMoE 16B 与著名且性能强劲的开源语言模型 LLaMA2 7B(Touvron et al., 2023b)进行比较,后者具有 6.7B 参数。DeepSeekMoE 16B 与 LLaMA2 7B 均在 2T token 上预训练。与 LLaMA2 7B 相比,DeepSeekMoE 的总参数量为其 245%,但只需 39.6% 的计算量。内部基准结果如表 4 所示,可得以下观察: (1) 在评测基准中,DeepSeekMoE 16B 仅凭约 40% 的计算量,即在大多数任务上优于 LLaMA2 7B。(2) DeepSeekMoE 16B 的数学推理与代码生成能力强于 LLaMA2 7B,主要由于我们的预训练语料中数学与代码相关文本比例更高。(3) 由于预训练语料中包含中文文本,DeepSeekMoE 16B 在中文任务上对 LLaMA2 7B 具有显著性能优势。(4) 尽管在英文语料上的训练量更少,DeepSeekMoE 16B 在英文理解与知识密集型任务上仍取得不输甚至优于 LLaMA2 7B 的表现,体现了模型的卓越能力。
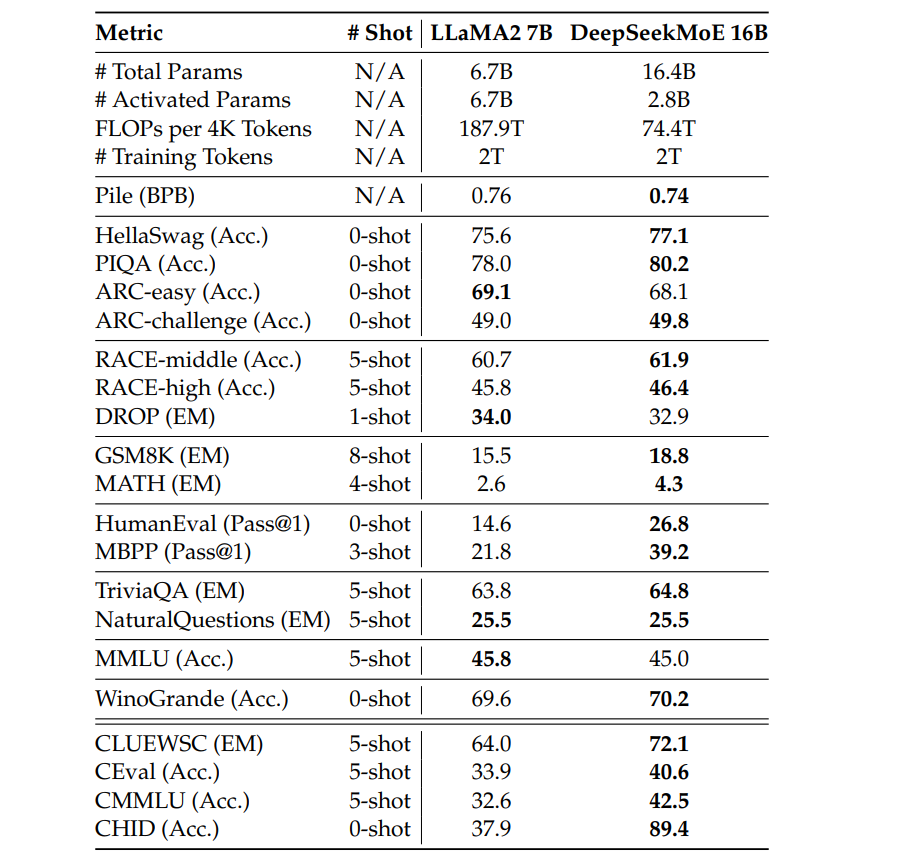 表4 LLaMA2 7B与DeepSeekMoE 16B的比较:DeepSeekMoE 16B仅需39.6%的计算量,在大多数基准测试中均优于LLaMA2 7B。
表4 LLaMA2 7B与DeepSeekMoE 16B的比较:DeepSeekMoE 16B仅需39.6%的计算量,在大多数基准测试中均优于LLaMA2 7B。
在公开LLM排行榜上的评测。 除内部评估外,我们还将 DeepSeekMoE 16B 放到 Open LLM Leaderboard 上,与更多开源模型对比。除 LLaMA2 7B 外,还包括 LLaMA 7B(Touvron et al., 2023a)、Falcon 7B(Almazrouei et al., 2023)、GPT-J 6B(Wang and Komatsuzaki, 2021)、RedPajama-INCITE 7B/3B(Together-AI, 2023)、Open LLaMA 7B/3B(Geng and Liu, 2023)、OPT 2.7B(Zhang et al., 2022)、Pythia 2.8B(Biderman et al., 2023)、GPT-neo 2.7B(Black et al., 2021)以及 BLOOM 3B(Scao et al., 2022)。
评测结果如图 1 所示,DeepSeekMoE 16B 在激活参数量相近的模型中显著领先。此外,其性能接近激活参数量约为其 2.5 倍的 LLaMA2 7B。
六 DeepSeekMoE 16B 对齐
先前的研究表明,MoE模型通常不会从微调中获得显著收益(Artetxe等人,2022;Fedus等人,2021)。然而,Shen等人(2023)的研究结果表明,MoE模型确实可以从指令调优中受益。为了评估DeepSeekMoE 16B是否可以从微调中受益,我们进行了监督微调,以构建基于DeepSeekMoE 16B的聊天模型。实验结果表明,DeepSeekMoE Chat 16B的性能也与LLaMA2 SFT 7B和DeepSeek Chat 7B相当。
6.1 评估实验设置
**训练数据。**为了训练聊天模型,我们对内部策划的数据进行监督微调(SFT),包括140万个训练示例。该数据集涵盖了广泛的类别,包括数学、代码、写作、问答、推理、总结等。我们的大多数SFT训练数据都是英文和中文的,这使得聊天模型功能多样,适用于双语场景。
**超参数。**在监督微调过程中,我们将批大小设置为1024个示例,并使用AdamW优化器进行8个迭代的训练(Loshchilov和Hutter,2019)。我们采用4K的最大序列长度,并尽可能密集地打包训练示例,直到达到序列长度限制。我们不使用dropout进行监督微调,只需将学习率设置为10-5,而不采用任何学习率调度策略。
**评估基准。**为了评估聊天模型,我们采用了类似于第5.1.3节中使用的基准,但有以下调整:(1)我们排除了Pile(Gao等人,2020),因为聊天模型很少用于纯语言建模。(2) 我们排除了CHID(Zheng等人,2019),因为观察到的结果不稳定,阻碍了可靠结论的推导。(3) 我们还包括BBH(Suzgun等人,2022),以对聊天模型的推理能力进行更全面的评估。
6.2 评价
基线模型。 为验证 DeepSeekMoE 16B 在对齐后的潜力,我们对 LLaMA2 7B、DeepSeek 7B 和 DeepSeekMoE 16B 进行监督微调,并使用完全相同的微调数据以确保公平性。相应地,我们构建了三个对话模型,包括 LLaMA2 SFT 7B³、DeepSeek Chat 7B 和 DeepSeekMoE Chat 16B。随后,我们将 DeepSeekMoE Chat 16B 与另外两个稠密对话模型(其 FLOPs 大约是前者的 2.5 倍)在广泛的下游任务上进行比较。
结果。 评估结果呈现在表 5 中。我们的主要观察如下:(1) 在仅使用约 40% 计算量的情况下,DeepSeekMoE Chat 16B 在语言理解与推理(PIQA、ARC、BBH)、机器阅读理解(RACE)、数学任务(GSM8K、MATH)以及知识密集型任务(TriviaQA、NaturalQuestions)上取得了与 7B 稠密模型相当的性能。(2) 在代码生成任务上,DeepSeekMoE Chat 16B 显著优于 LLaMA2 SFT 7B,在 HumanEval 和 MBPP 上取得明显提升。此外,它也超过了 DeepSeek Chat 7B。(3) 在 MMLU、CEval 和 CMMLU 等多项选择问答基准测试中,DeepSeekMoE Chat 16B 仍然落后于 DeepSeek Chat 7B,这与基础模型的观察结果一致(第 5.2.1 节)。但值得注意的是,经过监督微调后,DeepSeekMoE 16B 与 DeepSeek 7B 的性能差距有所缩小。(4) 得益于双语语料的预训练,DeepSeekMoE Chat 16B 在所有中文基准上均显著超越 LLaMA2 SFT 7B。这些结果体现了 DeepSeekMoE 16B 在中文和英文方面的平衡能力,增强了其在多场景下的通用性与适用性。总而言之,对对话模型的评估突显出 DeepSeekMoE 16B 在对齐后的潜力,并验证了其在仅使用约 40% 计算量的情况下仍能达到与稠密模型相当性能的一贯优势。
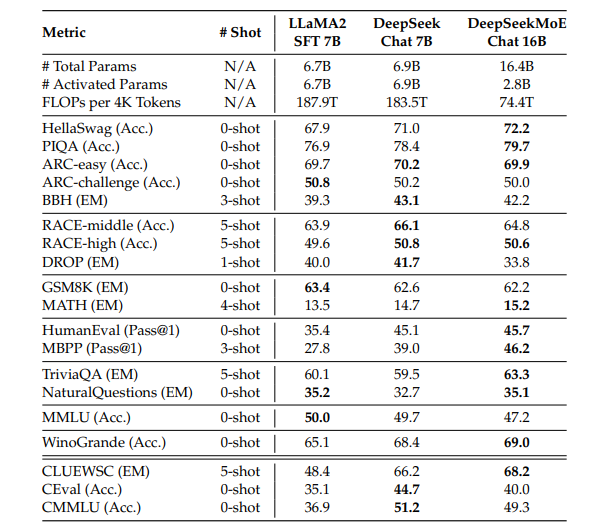 表5比较了LLaMA2 SFT7B、DeepSeek Chat 7B和DeepSeekMoE Chat16B,这三个模型均使用相同的SFT数据集进行微调。与两个7B密集模型相比,DeepSeekMoE Chat16B在大多数基准测试中仍能达到相当或更优的性能,且计算量仅为前者的40%。
表5比较了LLaMA2 SFT7B、DeepSeek Chat 7B和DeepSeekMoE Chat16B,这三个模型均使用相同的SFT数据集进行微调。与两个7B密集模型相比,DeepSeekMoE Chat16B在大多数基准测试中仍能达到相当或更优的性能,且计算量仅为前者的40%。
七 DeepSeekMoE 145B 对齐
在DeepSeekMoE 16B出色表现的鼓舞下,我们进一步努力将DeepSeekMoE规模扩大到145B。在这项初步研究中,DeepSeekMoE 145B使用245B令牌进行训练,但它已经证明了优于GShard架构的持续优势,并有望达到或超过DeepSeek 67B(密集型)的性能。此外,在DeepSeekMoE 145B的最终版本和全面培训完成后,我们还计划将其公之于众。
7.1 实验设置
训练数据和标记化 。 对于DeepSeekMoE 145B,我们使用了与DeepSeekMoE 16B完全相同的训练语料库和标记器,唯一的区别是DeepSeek MoE 145B在初始研究中使用了245B标记进行训练。
模型设置。对于DeepSeekMoE 145B,我们将Transformer层数设置为62,隐藏维度设置为4096。我们采用多头注意力机制,共有32个注意力头,每个头的尺寸为128。至于初始化,所有可学习的参数都是随机初始化的,标准偏差为0.006。与DeepSeekMoE 16B一样,我们也用MoE层替换除第一层之外的所有FFN。每个MoE层由4个共享专家和128个路由专家组成,其中每个专家的大小是标准FFN的0.125倍。每个令牌将被路由到这4个共享专家和128个路由专家中的12个。在这种配置下,DeepSeekMoE 145的总参数约为144.6B,激活的参数数量约为22.2B。
Training Settings. 我们使用 AdamW 优化器(Loshchilov and Hutter, 2019),其超参数设置为 𝛽1 = 0.9、𝛽2 = 0.95,以及 weight_decay = 0.1。对于 DeepSeekMoE 145B 的初步研究,我们采用 warmup-and-constant 的学习率调度策略。开始时,学习率在前 2K 步内从 0 线性增加到最大学习率。随后,学习率在剩余训练过程中保持不变。DeepSeekMoE 145B 的最大学习率设为 3.0 × 10⁻⁴,梯度裁剪范数设为 1.0。批大小设为 4.5K,并在最大序列长度为 4K 时,每个训练批次包含 18M tokens。我们训练 DeepSeekMoE 145B 共 13,000 步,实现 245B 训练 tokens。同样,我们在训练过程中不使用 dropout。我们采用流水线并行将模型的不同层部署在不同设备上,并对每一层,将所有 routed experts 均匀部署在 4 个设备上(即专家并行结合数据并行)。由于 DeepSeekMoE 145B 使用了专家并行,因此需要考虑设备级负载均衡以减少计算瓶颈。为此,我们将设备级平衡因子设置为 0.05,以促进设备间计算负载均衡。此外,我们仍将专家级平衡因子设置为 0.003,以防止路由崩溃。
Evaluation Benchmarks. 我们在与 DeepSeekMoE 16B 完全相同的内部基准测试上评估 DeepSeekMoE 145B(见第 5.1.3 节)。
7.2 Evaluations
Baselines. 除 DeepSeekMoE 145B 之外,我们还考虑了三个其他模型作为对比。DeepSeek 67B(Dense)是一个拥有 67.4B 总参数的稠密模型(关于模型和训练细节可参考 DeepSeek-AI(2024))。GShard 137B 与 DeepSeekMoE 145B 在隐藏维度和层数上相同,但采用 GShard 架构。需要注意的是,为了提高计算效率,DeepSeekMoE 145B 将每个 expert 的中间隐藏维度对齐为 64 的倍数,因此其模型规模比 GShard 137B 大 6%。DeepSeekMoE 142B(Half Activated)在架构上与 DeepSeekMoE 145B 类似,但仅包含 2 个共享专家,且 128 个 routed experts 中仅有 6 个被激活。值得注意的是,所有对比模型(包括 DeepSeekMoE 145B)均使用相同的训练语料。此外,对比中的所有 MoE 模型均从头训练,并共享相同的训练超参数。
Results. 从表 6 中的评估结果,我们得到以下观察:(1)尽管总参数量和计算量相当,DeepSeekMoE 145B 的性能显著优于 GShard 137B,再次突显了 DeepSeekMoE 架构的优势。(2)总体来看,仅使用 28.5% 的计算量,DeepSeekMoE 145B 即可达到与 DeepSeek 67B(Dense)相当的性能。与 DeepSeekMoE 16B 的发现一致,DeepSeekMoE 145B 在语言建模和知识密集型任务中表现突出,但在多选任务上仍有所限制。(3)在更大规模下,DeepSeekMoE 142B(Half Activated)的性能与 DeepSeekMoE 145B 相比并没有明显落后。此外,尽管其激活的专家参数量只有一半,DeepSeekMoE 142B(Half Activated)仍能匹敌 DeepSeek 67B(Dense)的性能,同时仅使用 18.2% 的计算量。它也优于 GShard 137B,这与第 4.5 节的结论一致。
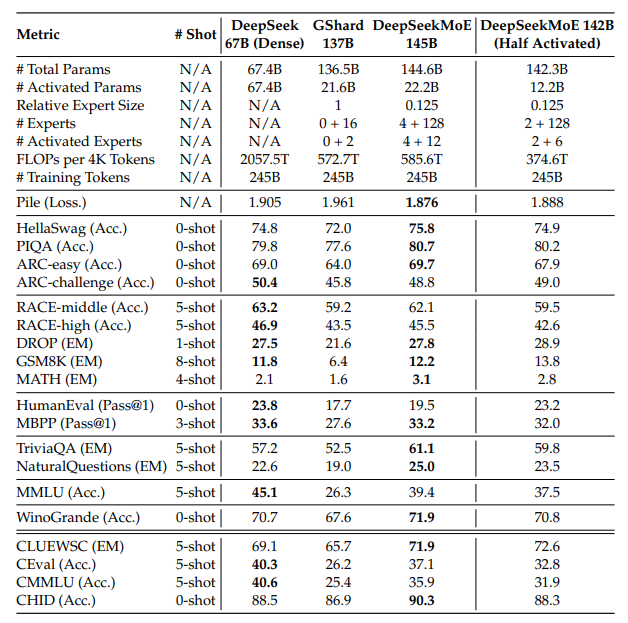 表 6 比较了总参数量约为 1400 亿时的 DeepSeek67B(密集型)和 MoE 模型。在"# 专家"和"# 激活专家"两行中,+分别表示个共享专家和个路由专家。粗体字表示最佳或接近最佳的性能(最后一列除外)。DeepSeekMoE145B,甚至只有一半激活专家参数的 DeepSeekMoE142B(半激活型),都大幅优于 GShard 137B。此外,DeepSeekMoE 145B 仅需 28.5% 的计算量即可达到与 DeepSeek 67B 相当的性能。
表 6 比较了总参数量约为 1400 亿时的 DeepSeek67B(密集型)和 MoE 模型。在"# 专家"和"# 激活专家"两行中,+分别表示个共享专家和个路由专家。粗体字表示最佳或接近最佳的性能(最后一列除外)。DeepSeekMoE145B,甚至只有一半激活专家参数的 DeepSeekMoE142B(半激活型),都大幅优于 GShard 137B。此外,DeepSeekMoE 145B 仅需 28.5% 的计算量即可达到与 DeepSeek 67B 相当的性能。
八 相关工作
Mixture of Experts(MoE)技术最初由 Jacobs et al.(1991)以及 Jordan and Jacobs(1994)提出,用于通过独立专家模块处理不同样本。Shazeer et al.(2017)将 MoE 引入语言模型训练,并构建了基于大规模 LSTM 的 MoE 模型(Hochreiter and Schmidhuber, 1997)。随着 Transformer 成为 NLP 的主流架构,许多研究尝试将 Transformer 中的 FFN 扩展为 MoE 层,以构建 MoE 语言模型。GShard(Lepikhin et al., 2021)和 Switch Transformer(Fedus et al., 2021)是先驱模型,它们采用可学习的 top-2 或 top-1 路由策略,将 MoE 模型扩展到极大规模。Hash Layer(Roller et al., 2021)和 StableMoE(Dai et al., 2022b)使用固定路由策略以获得更稳定的路由和训练。Zhou et al.(2022)提出了 expert-choice 路由策略,其中每个 token 可以被分配到不同数量的 experts。Zoph(2022)关注 MoE 模型中的训练不稳定性和微调困难,并提出 ST-MoE 来克服这些挑战。除了架构和训练策略方面的研究,近年来还出现了许多基于现有 MoE 架构的大规模语言或多模态模型(Du et al., 2022;Lin et al., 2021;Ren et al., 2023;Xue et al., 2023)。总体来看,大多数以往的 MoE 模型基于传统的 top-1 或 top-2 路由策略,这在专家专业化方面仍有较大提升空间。对此,我们提出的 DeepSeekMoE 架构旨在最大程度提升专家的专业化程度。
九 总结
本文提出了用于 MoE 语言模型的 DeepSeekMoE 架构,其目标是实现极致的专家专业化。通过细粒度的专家切分与共享专家隔离机制,DeepSeekMoE 相较主流 MoE 架构实现了显著更高的专家专业化与性能。从拥有 2B 参数的小规模模型入手,我们验证了 DeepSeekMoE 的优势,证明其能够接近 MoE 模型的性能上限。此外,我们提供了实证结果表明 DeepSeekMoE 的专家专业化水平高于 GShard。
在扩展到 16B 总参数规模时,我们在 2T tokens 上训练了 DeepSeekMoE 16B,并展示了其在仅使用约 40% 计算量的情况下即可达到与 DeepSeek 7B 和 LLaMA2 7B 相当的性能。此外,我们基于 DeepSeekMoE 16B 进行对齐监督微调构建了一个 MoE 聊天模型,进一步展示了其适应性和多功能性。与此同时,我们对 DeepSeekMoE 扩展至 145B 参数进行了初步探索,发现 DeepSeekMoE 145B 仍保持对 GShard 的明显优势,并仅使用 28.5%(甚至可能 18.2%)的计算量,即可达到与 DeepSeek 67B 相近的性能。
为了科研目的,我们开放发布了 DeepSeekMoE 16B 的模型 checkpoint,它可部署在单张 40GB 显存的 GPU 上。我们希望本工作能够为学术界和工业界提供有价值的参考,并推动大规模语言模型的进一步发展。
参考文献
1 DeepSeekMoE : https://arxiv.org/pdf/2401.06066