第一章:HTTP协议
虽然我们说,应用层协议是我们程序员自己定的。但实际上,已经有大佬们定义了一些现成的,又非常好用的应用层协议,供我们直接参考使用。HTTP(超文本传输协议)就是其中之一。
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如HTML文档)。
HTTP协议是客户端与服务器之间通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP协议是一个无连接、无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
第二章:认识URL
平时我们俗称的 "网址" 其实就是说的 URL
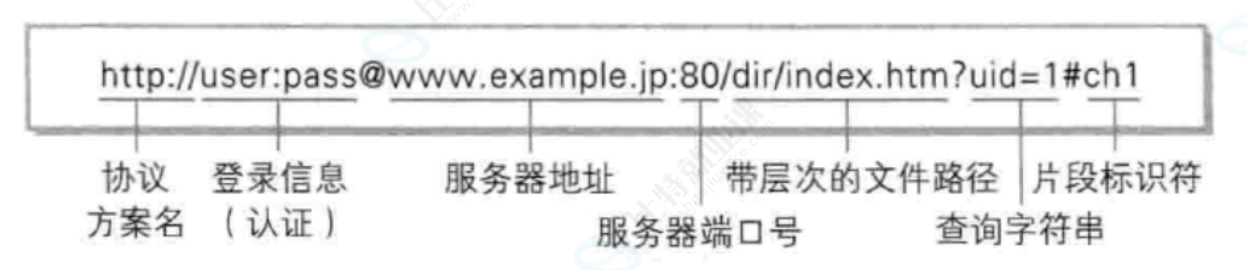
第三章:urlencode和urldecode(了解)
像 / ? : 等这样的字符,已经被 url 当做特殊意义理解了。因此这些字符不能随意出现。
比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如:

"+" 被转义成了 "%2B"
urldecode就是urlencode的逆过程;
urlencode工具
第四章:HTTP协议请求与响应格式
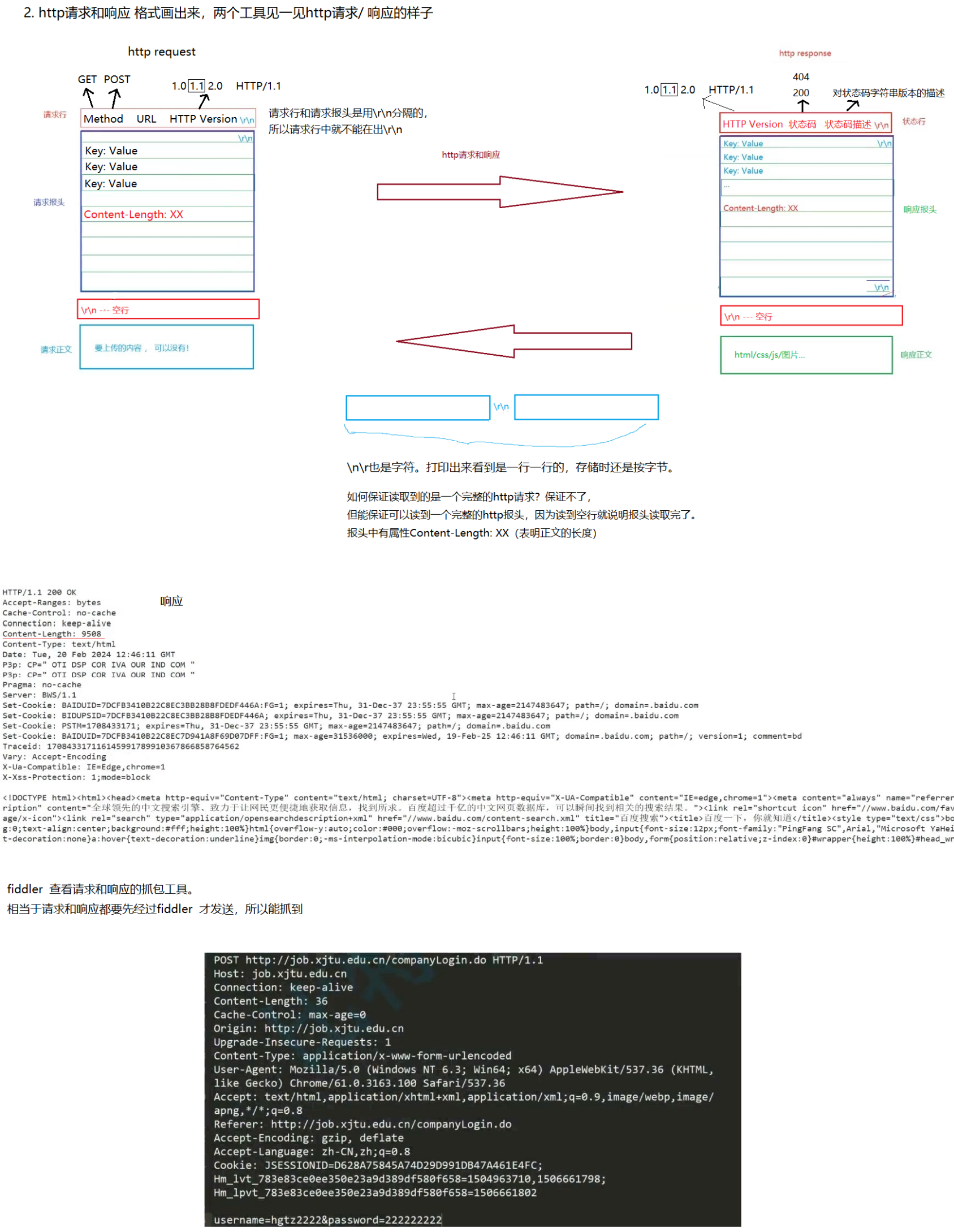
HTTP请求
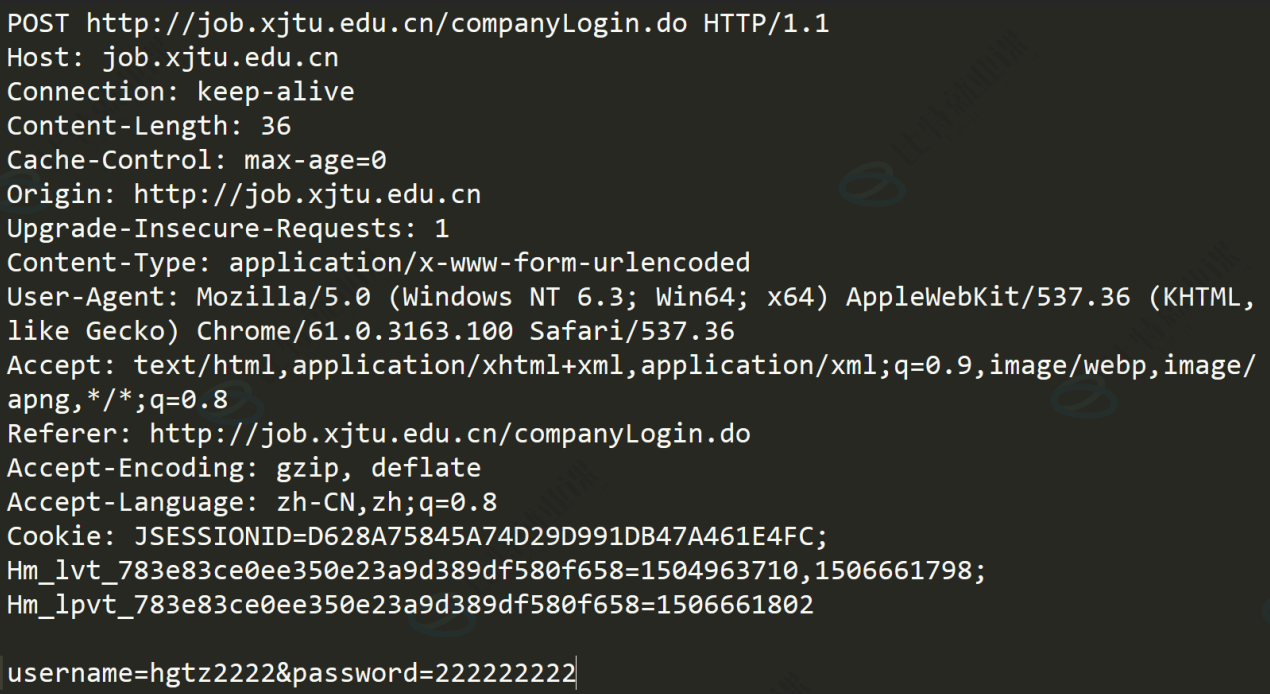
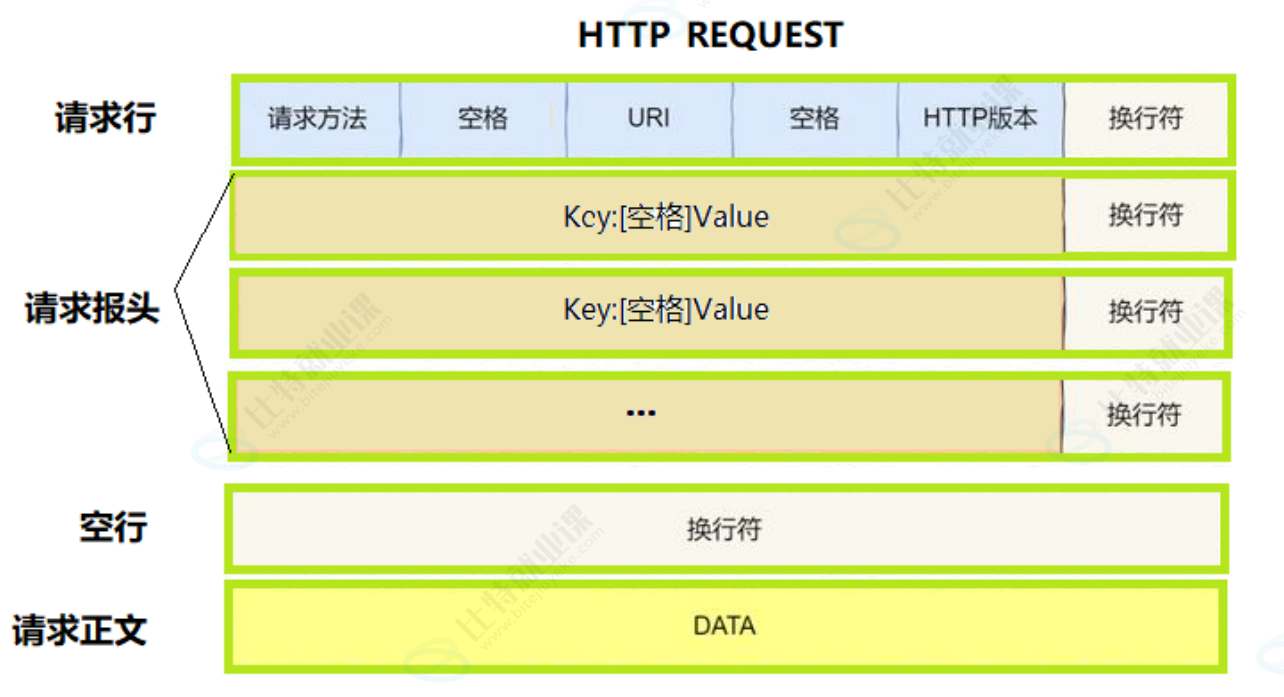
- 首行:方法 + url + 版本
- Header:请求的属性,冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示 Header部分结束
- Body:空行后面的内容都是Body。Body允许为空字符串。如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应
- 首行:版本号 + 状态码 + 状态码解释
- Header:请求的属性,冒号分割的键值对;每组属性之间使用\r\n分隔;遇到空行表示Header部分结束
- Body:空行后面的内容都是Body。Body允许为空字符串。如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度;如果服务器返回了一个html页面,那么html页面内容就是在body中。

基本的应答格式
第五章:HTTP的方法
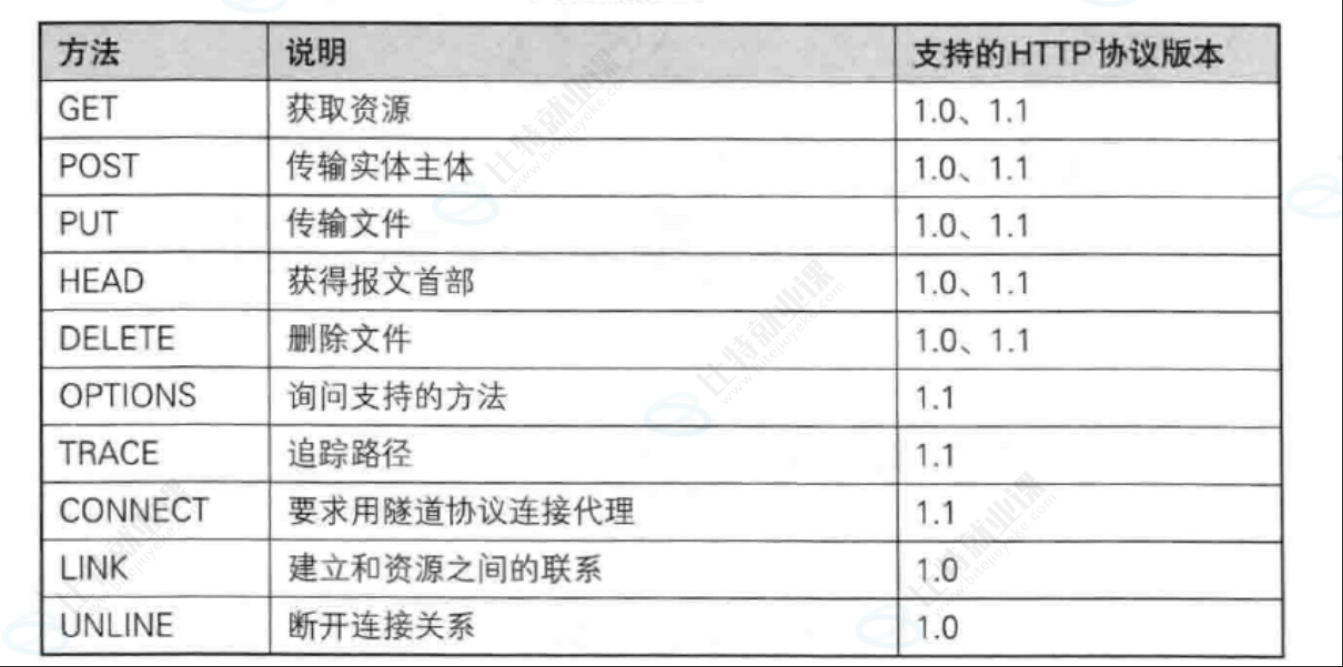
其中最常用的就是GET方法和POST方法。
HTTP常见方法
1. GET方法(重点)
用途:用于请求URL指定的资源。
示例:GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容。
form表单:https://www.runoob.com/html/html-forms.html
2. POST方法(重点)
用途:用于传输实体的主体,通常用于提交表单数据。
示例:POST /submit.cgi HTTP/1.1
特性:可以发送大量的数据给服务器,并且数据包含在请求体中。
form表单:https://www.runoob.com/html/html-forms.html
3. PUT方法(不常用)
用途:用于传输文件,将请求报文主体中的文件保存到请求URL指定的位置。
示例:PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如RESTful API中,用于更新资源。
4. HEAD方法
用途:与GET方法类似,但不返回报文主体部分,仅返回响应头。
示例:HEAD /index.html HTTP/1.1
特性:用于确认URL的有效性及资源更新的日期时间等。
bash
// curl -i 显示
$ curl -i www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 2381
Content-Type: text/html
Date: Sun, 16 Jun 2024 08:38:04 GMT
Etag: "588604dc-94d"
Last-Modified: Mon, 23 Jan 2017 13:27:56 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<!DOCTYPE html>
...
// 使⽤head方法,只会返回响应头
$ curl --head www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Sun, 16 Jun 2024 08:43:38 GMT
Etag: "575e1f71-115"
Last-Modified: Mon, 13 Jun 2016 02:50:25 GMT
Pragma: no-cache
Server: bfe/1.0.8.185. DELETE方法(不常用)
用途:用于删除文件,是PUT的相反方法。
示例:DELETE /example.html HTTP/1.1
特性:按请求URL删除指定的资源。
6. OPTIONS方法
用途:用于查询针对请求URL指定的资源支持的方法。
示例:OPTIONS * HTTP/1.1
特性:返回允许的方法,如GET、POST等。
第六章:HTTP的状态码
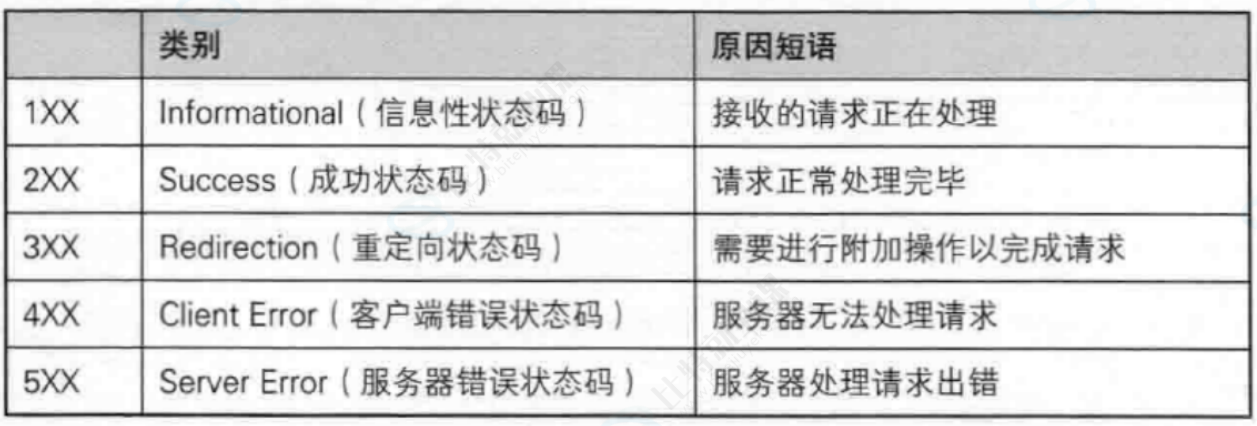
最常见的状态码,比如 200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)

好的,以下是仅包含重定向相关状态码的表格:

关于重定向的验证,以301为代表
**HTTP状态码301(永久重定向)和302(临时重定向)都依赖Location选项。**以下是关于两者依赖Location选项的详细说明:
HTTP状态码301(永久重定向)
- 当服务器返回HTTP 301状态码时,表示请求的资源已经被永久移动到新的位置。
- 在这种情况下,服务器会在响应中添加一个Location头部,用于指定资源的新位置。这个Location头部包含了新的URL地址,浏览器会自动重定向到该地址。
- 例如,在HTTP响应中,可能会看到类似于以下的头部信息:
cpp
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\nHTTP状态码302(临时重定向)
当服务器返回HTTP 302状态码时,表⽰请求的资源临时被移动到新的位置。
同样地,服务器也会在响应中添加⼀个Location头部来指定资源的新位置。浏览器会暂时使⽤新的URL进⾏后续的请求,但不会缓存这个重定向。
例如,在HTTP响应中,可能会看到类似于以下的头部信息:
cpp
HTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n**总结:**无论是HTTP 301还是HTTP 302重定向,都需要依赖Location选项来指定资源的新位置。这个Location选项是一个标准的HTTP响应头部,用于告诉浏览器应该将请求重定向到哪个新的URL地址。
第七章:HTTP常见Header
- Content-Type:数据类型(text/html等)
- Content-Length:Body的长度
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上;
- User-Agent:声明用户的操作系统和浏览器版本信息;
- Referer:当前页面是从哪个页面跳转过来的;
- Location:搭配3xx状态码使用,告诉客户端接下来要去哪里访问;
- Cookie:用于在客户端存储少量信息。通常用于实现会话(session)的功能;
关于connection报头
HTTP中的 Connection 字段是HTTP报文头的一部分,它主要用于控制和管理客户端与服务器之间的连接状态
核心作用
- 管理持久连接:Connection 字段还用于管理持久连接(也称为长连接)。持久连接允许客户端和服务器在请求/响应完成后不立即关闭TCP连接,以便在同一个连接上发送多个请求和接收多个响应。
持久连接(长连接)
- HTTP/1.1:在HTTP/1.1协议中,默认使用持久连接。当客户端和服务器都不明确指定关闭连接时,连接将保持打开状态,以便后续的请求和响应可以复用同一个连接。
- HTTP/1.0:在HTTP/1.0协议中,默认连接是非持久的。如果希望在HTTP/1.0上实现持久连接,需要在请求头中显式设置 Connection: keep-alive。
语法格式
- Connection: keep-alive:表示希望保持连接以复用TCP连接。
- Connection: close:表示请求/响应完成后,应该关闭TCP连接。
下面附上一张关于HTTP常见header的表格

第八章:最简单的HTTP服务器
Log.hpp
cpp
#pragma once
#include <iostream>
#include <stdarg.h>
#include <time.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
using namespace std;
#define SIZE 1024
//表示不同严重程度
#define Info 0
#define Debug 1
#define Warning 2
#define Error 3
#define Fatal 4
#define Screen 1 //打印到屏幕
#define Onefile 2 //所有日志写入同一个文件
#define Classfile 3 //按日志级别分文件
#define LogFile "log.txt"
class Log {
public:
//默认输出到屏幕,日志目录为 ./log/
Log() {
printMethod = Screen;
path = "./log/";
}
void Enable(int method) { printMethod = method; } //设置日志输出方式
string levelToString(int level) { //把数字型的日志级别 → 转成人类可读的字符串
switch (level) {
case Info: return "Info";
case Debug: return "Debug";
case Warning: return "Warning";
case Error: return "Error";
case Fatal: return "Fatal";
default: return "None";
}
}
void printLog(int level, const string& logtxt) { //根据 printMethod 的值决定日志去哪
switch (printMethod) {
case Screen:
cout << logtxt << endl;
break;
case Onefile:
printOneFile(LogFile, logtxt);
break;
case Classfile:
printClassFile(level, logtxt);
break;
default:
break;
}
}
void printOneFile(const string& logname, const string& logtxt) {
string _logname = path + logname;
int fd = open(_logname.c_str(), O_WRONLY|O_CREAT|O_APPEND, 0666);
if (fd < 0 ) return;
write(fd, logtxt.c_str(), logtxt.size());
close(fd);
}
void printClassFile(int level, const string& logtxt) {
string filename = LogFile;
filename += ".";
filename += levelToString(level);
printOneFile(filename, logtxt);
}
void operator()(int level, const char* format, ...) {
//获取当前时间 → 格式化到 leftbuffer
time_t t = time(nullptr);
struct tm* ctime = localtime(&t);
char leftbuffer[SIZE];
snprintf(leftbuffer, sizeof(leftbuffer), "[%s][%d-%d-%d %d:%d:%d]", levelToString(level).c_str(),
ctime->tm_year+1900, ctime->tm_mon+1, ctime->tm_mday, ctime->tm_hour, ctime->tm_min, ctime->tm_sec);
//处理用户传入的可变参数 → 格式化到 rightbuffer
va_list s;
va_start(s, format);
char rightbuffer[SIZE];
vsnprintf(rightbuffer, sizeof(rightbuffer), format, s);
va_end(s);
//拼接成完整日志字符串
char logtxt[SIZE*2];
snprintf(logtxt, sizeof(logtxt), "%s %s", leftbuffer, rightbuffer);
//格式:默认部分+自定义部分
// printf("%s", logtxt);
printLog(level, logtxt);
}
~Log() {}
private:
int printMethod;
string path;
};
Log lg;Socket.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "Log.hpp"
enum {
SocketErr = 2,
BindErr,
ListenErr
};
const int backlog = 10;
class Sock {
public:
Sock() {}
~Sock() {}
public:
void Socket() {
sockfd_ = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd_ < 0) {
lg(Fatal, "socket error, %s:%d", strerror(errno), errno);
exit(SocketErr);
}
int opt = 1;
setsockopt(sockfd_, SOL_SOCKET, SO_REUSEADDR|SO_REUSEPORT, &opt, sizeof(opt));
}
void Bind(uint16_t port) {
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(sockfd_, (struct sockaddr*)&local, sizeof(local)) < 0) {
lg(Fatal, "bind error, %s:%d", strerror(errno), errno);
exit(BindErr);
}
}
void Listen() {
if (listen(sockfd_, backlog) < 0) {
lg(Fatal, "listen error, %s:%d", strerror(errno), errno);
exit(ListenErr);
}
}
int Accepet(std::string* clientip, uint16_t* clientport) {
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newfd = accept(sockfd_, (struct sockaddr*)&peer, &len);
if (newfd < 0) {
lg(Warning, "accept error, %s:%d", strerror(errno), errno);
return -1;
}
char ipstr[64];
inet_ntop(AF_INET, &peer.sin_addr, ipstr, sizeof(ipstr));
*clientip = ipstr;
*clientport = ntohs(peer.sin_port);
return newfd;
}
bool Connect(const std::string& ip, const uint16_t& port) {
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
peer.sin_family = AF_INET;
peer.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &peer.sin_addr);
int n = connect(sockfd_, (struct sockaddr*)&peer, sizeof(peer));
if (n == -1) {
std::cerr << "Connect to " << ip << ":" << port << " error" << std::endl;
return false;
}
return true;
}
void Close() { close(sockfd_); }
int Fd() { return sockfd_; }
private:
int sockfd_;
};HttpServer.hpp版本一 演示404和302
cpp
//演示302
const std::string wwwroot = "./wwwroot";//web根目录
const std::string sep = "\r\n";
const std::string homepage = "index.html";
static const int defaultport = 8080;
class Httpserver;
class ThreadData {
public:
ThreadData(int fd)
:sockfd(fd) {}
public:
int sockfd;
};
class HttpRequest {
public:
void Deserialize(std::string req) { // 反序列化HTTP请求,将原始请求字符串按行分割
while (true) {
ssize_t pos = req.find(sep);
if (pos == std::string::npos) break;
std::string temp = req.substr(0, pos);
if (temp.empty()) break;//如果找到正文前的空行就停
req_header.push_back(temp);
req.erase(0, pos + sep.size());//每push一行就移除一行
}
text = req;//req最后剩下的就是正文
}
// .png:image/png
void Parse() { // 取出请求行的3部分信息
std::stringstream ss(req_header[0]);
ss >> method >> url >> http_version;
// 处理URL,确定请求的文件路径
file_path = wwwroot; // ./wwwroot/
if (url == "/" || url == "/index.html") {
file_path += "/";
file_path += homepage; // ./wwwroot/index.html
}
else file_path += url; // /a/b/c/d.html -> ./wwwroot/a/b/c/d.html
}
void DebugPrint() {
std::cout << "-------------------------------" << std::endl;
for (auto& line : req_header) {
std::cout << line << "\n\n";
}
std::cout << "method: " << method << std::endl;
std::cout << "url: " << url << std::endl;
std::cout << "http_version: " << http_version << std::endl;
std::cout << "file_path: " << file_path << std::endl;
std::cout << text << std::endl;
std::cout << "-------------------------------" << std::endl;
}
public:
std::vector<std::string> req_header; //按行存储http请求
std::string text;
//解析之后的结果
std::string method;
std::string url;
std::string http_version;
std::string file_path; // ./wwwroot/a/b/c.html 2.png
};
class HttpServer {
public:
HttpServer(uint16_t port = defaultport)
:port_(port) {
content_type.insert({".html", "text/html"});
content_type.insert({".png", "image/png"});
content_type.insert({".jpeg", "image/jpeg"});
content_type.insert({".jpg", "image/jpeg"});
}
bool Start() {
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for(;;) { //持续接受客户端连接
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accepet(&clientip, &clientport);
if (sockfd < 0) continue;
lg(Info, "get a new connect, sockfd:%d", sockfd);
pthread_t tid;
ThreadData* td = new ThreadData(sockfd);
td->sockfd = sockfd;
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
static std::string ReadHtmlContent(const std::string& htmlpath) { // 读取HTML文件内容
std::ifstream in(htmlpath);
if (!in.is_open()) return "";
std::string content;
std::string line;
while (std::getline(in, line))
content += line;
in.close();
return content;
}
//演示302
static void HandlerHttp(int sockfd) { // 处理HTTP请求的主要逻辑
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0) {
buffer[n] = 0;
std::cout << buffer;//假设读取到的就是一个完整的独立的http请求
HttpRequest req;
req.Deserialize(buffer);// 将原始请求按行分割
req.Parse();// 解析请求行,确定请求的文件路径
req.DebugPrint();
//返回响应的过程
//req.file_path 就是index(网页)文件的完整路径,ReadHtmlContent 函数读取该文件内容到 text 变量中。
std::string text;
bool ok = true;
text = ReadHtmlContent(req.file_path);
if (text.empty()) {
ok = false;
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
}
std::string responseline;
if (ok) responseline = "HTTP/1.0 200 OK\r\n";
else responseline = "HTTP/1.0 404 Not Found\r\n";
responseline = "HTTP/1.0 302 Found\r\n";
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += "\r\n";
response_header += "Location: https://www.qq.com/\r\n";
std::string blank_line = "\r\n";
std::string response = responseline;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
//演示404
static void HandlerHttp(int sockfd) { // 处理HTTP请求的主要逻辑
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0) {
buffer[n] = 0;
std::cout << buffer;//假设读取到的就是一个完整的独立的http请求
HttpRequest req;
req.Deserialize(buffer);// 将原始请求按行分割
req.Parse();// 解析请求行,确定请求的文件路径
req.DebugPrint();
//返回响应的过程
//req.file_path 就是index(网页)文件的完整路径,ReadHtmlContent 函数读取该文件内容到 text 变量中。
std::string text;
bool ok = true;
text = ReadHtmlContent(req.file_path);
if (text.empty()) {
ok = false;
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
}
std::string responseline;
if (ok) responseline = "HTTP/1.0 200 OK\r\n";
else responseline = "HTTP/1.0 404 Not Found\r\n";
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += "\r\n";
std::string blank_line = "\r\n";
std::string response = responseline;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
static void* ThreadRun(void* args) { // 线程入口函数
pthread_detach(pthread_self());
ThreadData* td = static_cast<ThreadData*>(args);
HandlerHttp(td->sockfd);
delete td;
return nullptr;
}
~HttpServer() {}
private:
Sock listensock_;
uint16_t port_;
std::unordered_map<std::string, std::string> content_type;
};HttpServer.hpp版本二 演示404和302
cpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include <fstream>
#include <vector>
#include <sstream>
#include <sys/types.h>
#include <sys/socket.h>
#include <unordered_map>
#include "Socket.hpp"
#include "Log.hpp"
//演示图片展示
const std::string wwwroot = "./wwwroot";//web根目录
const std::string sep = "\r\n";
const std::string homepage = "index.html";
static const int defaultport = 8080;
class HttpServer;
class ThreadData {
public:
ThreadData(int fd, HttpServer* s)
:sockfd(fd), svr(s) {}
public:
int sockfd;
HttpServer* svr;
};
class HttpRequest {
public:
void Deserialize(std::string req) { // 反序列化HTTP请求,将原始请求字符串按行分割
while (true) {
ssize_t pos = req.find(sep);
if (pos == std::string::npos) break;
std::string temp = req.substr(0, pos);
if (temp.empty()) break;//如果找到正文前的空行就停
req_header.push_back(temp);
req.erase(0, pos + sep.size());//每push一行就移除一行
}
text = req;//req最后剩下的就是正文
}
// .png:image/png
void Parse() { // 取出请求行的3部分信息
std::stringstream ss(req_header[0]);
ss >> method >> url >> http_version;
// 处理URL,确定请求的文件路径
file_path = wwwroot; // ./wwwroot/
if (url == "/" || url == "/index.html") {
file_path += "/";
file_path += homepage; // ./wwwroot/index.html
}
else file_path += url; // /a/b/c/d.html -> ./wwwroot/a/b/c/d.html
//获取后缀
auto pos = file_path.rfind(".");
if (pos == std::string::npos) suffix = ".html";
else suffix = file_path.substr(pos);
}
void DebugPrint() {
std::cout << "-------------------------------" << std::endl;
for (auto& line : req_header) {
std::cout << line << "\n\n";
}
std::cout << "method: " << method << std::endl;
std::cout << "url: " << url << std::endl;
std::cout << "http_version: " << http_version << std::endl;
std::cout << "file_path: " << file_path << std::endl;
std::cout << text << std::endl;
std::cout << "-------------------------------" << std::endl;
}
public:
std::vector<std::string> req_header; //按行存储http请求
std::string text;
//解析之后的结果
std::string method;
std::string url;
std::string http_version;
std::string file_path; // ./wwwroot/a/b/c.html 2.png
std::string suffix;//文件后缀
};
class HttpServer {
public:
HttpServer(uint16_t port = defaultport)
:port_(port) {
content_type.insert({".html", "text/html"});
content_type.insert({".png", "image/png"});
content_type.insert({".jpeg", "image/jpeg"});
content_type.insert({".jpg", "image/jpeg"});
}
bool Start() {
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for(;;) { //持续接受客户端连接
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accepet(&clientip, &clientport);
if (sockfd < 0) continue;
lg(Info, "get a new connect, sockfd:%d", sockfd);
pthread_t tid;
ThreadData* td = new ThreadData(sockfd, this);
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
//可以读取二进制文件(比如图片)
static std::string ReadHtmlContent(const std::string& htmlpath) { // 读取HTML文件内容
std::ifstream in(htmlpath, std::ios::binary);
if (!in.is_open()) return "";
in.seekg(0, std::ios_base::end);
auto len = in.tellg();
in.seekg(0, std::ios_base::beg);
std::string content;
content.resize(len);
in.read((char*)content.c_str(), content.size());
return content;
}
// //这种只能读取字符串
// static std::string ReadHtmlContent(const std::string& htmlpath) { // 读取HTML文件内容
// std::ifstream in(htmlpath);
// if (!in.is_open()) return "";
// std::string content;
// std::string line;
// while (std::getline(in, line))
// content += line;
// in.close();
// return content;
// }
std::string SuffixToDesc(std::string& suffix) {
auto iter = content_type.find(suffix);
if (iter == content_type.end()) return content_type[".html"];
else return content_type[suffix];
}
//演示302
void HandlerHttp(int sockfd) { // 处理HTTP请求的主要逻辑
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0) {
buffer[n] = 0;
std::cout << buffer;//假设读取到的就是一个完整的独立的http请求
HttpRequest req;
req.Deserialize(buffer);// 将原始请求按行分割
req.Parse();// 解析请求行,确定请求的文件路径
// req.DebugPrint();
//返回响应的过程
//req.file_path 就是index(网页)文件的完整路径,ReadHtmlContent 函数读取该文件内容到 text 变量中。
std::string text;
bool ok = true;
text = ReadHtmlContent(req.file_path);
if (text.empty()) {
ok = false;
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
}
std::string responseline;
if (ok) responseline = "HTTP/1.0 200 OK\r\n";
else responseline = "HTTP/1.0 404 Not Found\r\n";
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += "\r\n";
response_header += "Content-Type: ";
response_header += SuffixToDesc(req.suffix);
response_header += "\r\n";
response_header += "Set-Cookie: name=wanghb";
response_header += "\r\n";
response_header += "Set-Cookie: passwd=123456";
response_header += "\r\n";
response_header += "Set-Cookie: view=hello.html";
response_header += "\r\n";
std::string blank_line = "\r\n";
std::string response = responseline;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
static void* ThreadRun(void* args) { // 线程入口函数
pthread_detach(pthread_self());
ThreadData* td = static_cast<ThreadData*>(args);
td->svr->HandlerHttp(td->sockfd);// 等价于:this->HandlerHttp(sockfd);
delete td;
return nullptr;
}
~HttpServer() {}
private:
Sock listensock_;
uint16_t port_;
std::unordered_map<std::string, std::string> content_type;
};HttpServer.cc
cpp
#include "HttpServer.hpp"
#include <iostream>
#include <memory>
using namespace std;
int main(int argc, char* argv[]) {
if (argc != 2) exit(1);
uint16_t port = stoi(argv[1]);
unique_ptr<HttpServer> svr(new HttpServer(port));
svr->Start();
return 0;
}网页文件资源
bash
[sxy@VM-12-13-centos 05_01_HTTP_Protocol_lesson4]$ tree wwwroot/
wwwroot/
├── a
│ └── b
│ └── hello.html
├── err.html
├── image
│ ├── 1.jpg
│ ├── 2.jpeg
│ ├── 3.jpg
│ ├── 4.png
│ └── 5.jpg
├── index.html
└── x
└── y
└── world.html
5 directories, 9 files
第九章:HTTP历史及版本核心技术与时代背景
HTTP(Hypertext Transfer Protocol,超文本传输协议)作为互联网中浏览器和服务器间通信的基石,经历了从简单到复杂、从单一到多样的发展过程。以下将按照时间顺序,介绍HTTP的主要版本、核心技术及其对应的时代背景。
HTTP/0.9
核心技术:
- 仅支持GET请求方法。
- 仅支持纯文本传输,主要是HTML格式。
- 无请求和响应头信息。
时代背景:
- 1991年,HTTP/0.9版本作为HTTP协议的最初版本,用于传输基本的超文本HTML内容。
- 当时的互联网还处于起步阶段,网页内容相对简单,主要以文本为主。
HTTP/1.0
核心技术:
- 引入POST和HEAD请求方法。
- 请求和响应头信息,支持多种数据格式(MIME)。
- 支持缓存(cache)。
- 状态码(status code)、多字符集支持等。
时代背景:
- 1996年,随着互联网的快速发展,网页内容逐渐丰富,HTTP/1.0版本应运而生。
- 为了满足日益增长的网络应用需求,HTTP/1.0增加了更多的功能和灵活性。
- 然而,HTTP/1.0的工作方式是每次TCP连接只能发送一个请求,性能上存在一定局限。
HTTP/1.1
核心技术:
- 引入持久连接(persistent connection),支持管道化(pipelining)。
- 允许在单个TCP连接上进行多个请求和响应,提高了性能。
- 引入分块传输编码(chunked transfer encoding)。
- 支持Host头,允许在一个IP地址上部署多个Web站点。
时代背景:
- 1999年,随着网页加载的外部资源越来越多,HTTP/1.0的性能问题愈发突出。
- HTTP/1.1通过引入持久连接和管道化等技术,有效提高了数据传输效率。
- 同时,互联网应用开始呈现出多元化、复杂化的趋势,HTTP/1.1的出现满足了这些需求。
HTTP/2.0
核心技术:
- 多路复用(multiplexing),一个TCP连接允许多个HTTP请求。
- 二进制帧格式(binary framing),优化数据传输。
- 头部压缩(header compression),减少传输开销。
- 服务器推送(server push),提前发送资源到客户端。
时代背景:
- 2015年,随着移动互联网的兴起和云计算技术的发展,网络应用对性能的要求越来越高。
- HTTP/2.0通过多路复用、二进制帧格式等技术,显著提高了数据传输效率和网络性能。
- 同时,HTTP/2.0还支持加密传输(HTTPS),提高了数据传输的安全性。
HTTP/3.0
核心技术:
- 使用QUIC协议替代TCP协议,基于UDP构建的多路复用传输协议。
- 减少了TCP三次握手及TLS握手时间,提高了连接建立速度。
- 解决了TCP中的线头阻塞问题,提高了数据传输效率。
时代背景:
- 2022年,随着5G、物联网等技术的快速发展,网络应用对实时性、可靠性的要求越来越高。
- HTTP/3.0通过使用QUIC协议,提高了连接建立速度和数据传输效率,满足了这些需求。
- 同时,HTTP/3.0还支持加密传输(HTTPS),保证了数据传输的安全性。
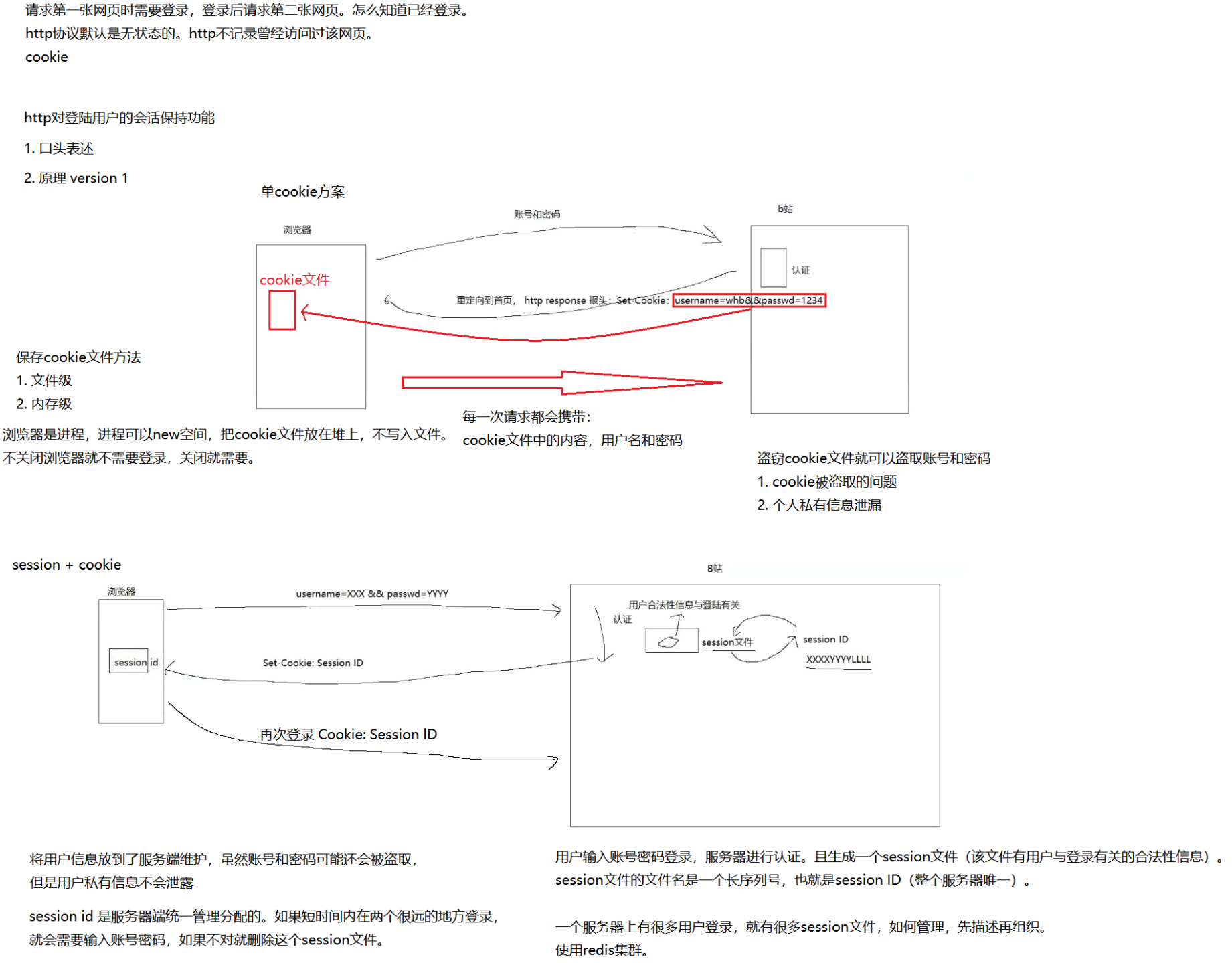
第十章:引入HTTP Cookie
定义
HTTP Cookie(也称为Web Cookie、浏览器Cookie或简称Cookie)是服务器发送到用户浏览器并保存在浏览器上的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态、记录用户偏好等。
工作原理
- 当用户第一次访问网站时,服务器会在响应的HTTP头中设置 Set-Cookie 字段,用于发送Cookie到用户的浏览器。
- 浏览器在接收到Cookie后,会将其保存在本地(通常是按照域名进行存储)。
- 在之后的请求中,浏览器会自动在 HTTP 请求头中携带 Cookie 字段,将之前保存的Cookie信息发送给服务器。
分类
- 会话 Cookie(Session Cookie):在浏览器关闭时失效。
- 持久 Cookie(Persistent Cookie):带有明确的过期日期或持续时间,可以跨多个浏览器会话存在。
- 如果 cookie 是一个持久性的 cookie,那么它其实就是浏览器相关的,特定目录下的一个文件。但直接查看这些文件可能会看到乱码或无法读取的内容,因为 cookie 文件通常以二进制或 sqlite 格式存储。一般我们查看,直接在浏览器对应的选项中直接查看即可。
类似于下面这种方式:
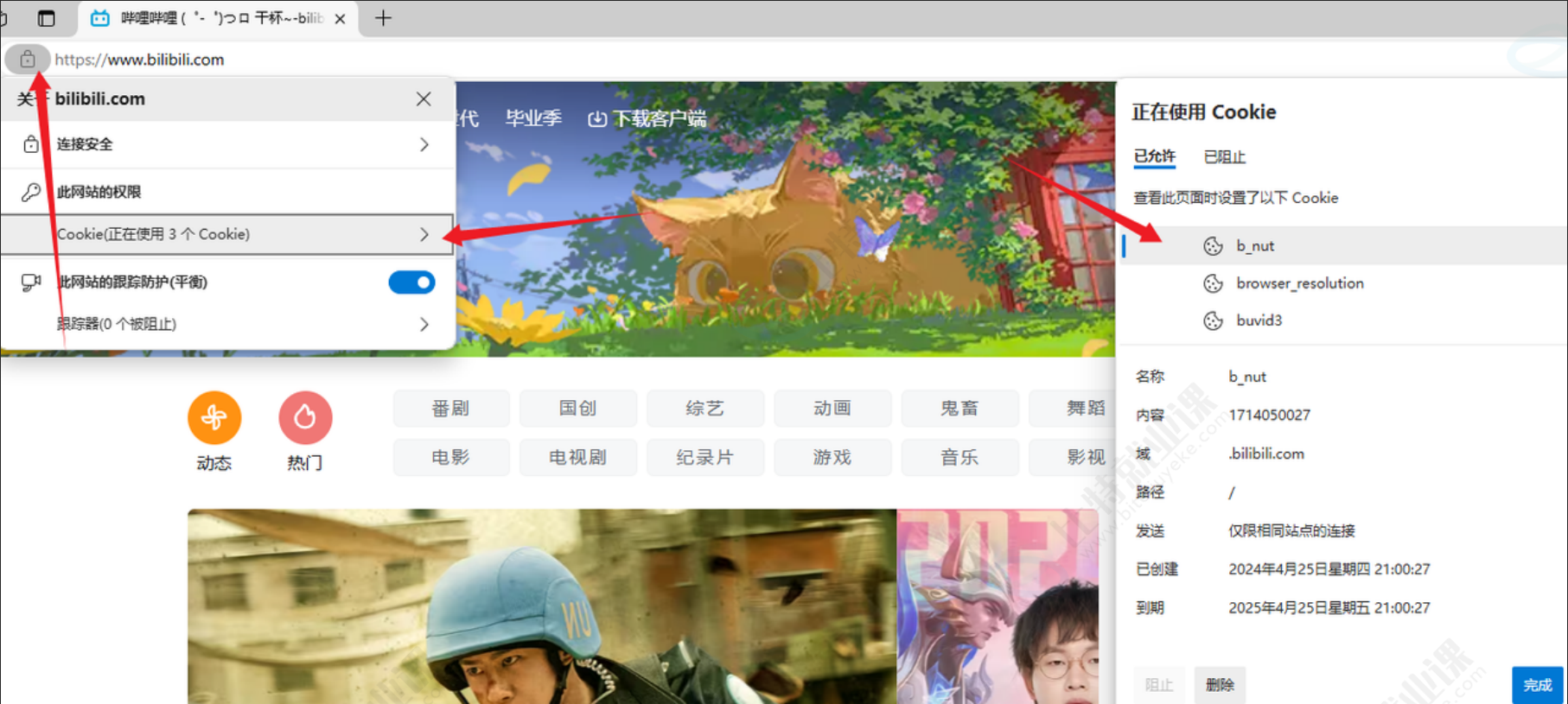
安全性
由于 Cookie 是存储在客户端的,因此存在被篡改或窃取的风险。
用途
- 用户认证和会话管理(最重要)
- 跟踪用户行为
- 缓存用户偏好等
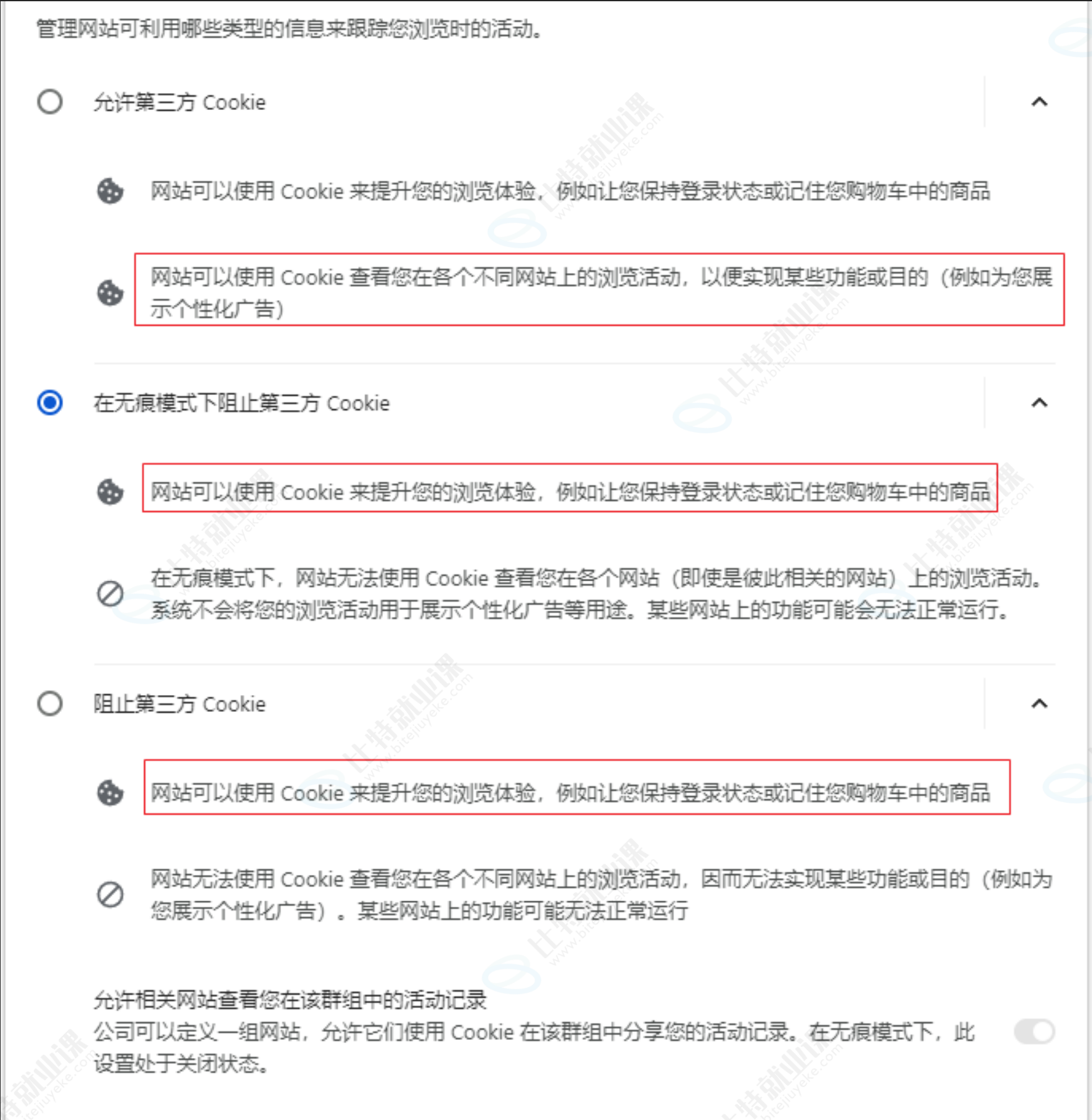
- 比如在chrome浏览器下,可以直接访问:chrome://settings/cookies
第十一章:认识 cookie
- HTTP 存在⼀个报头选项: Set-Cookie , 可以⽤来进⾏给浏览器设置 Cookie 值。
- 在 HTTP 响应头中添加,客⼾端(如浏览器)获取并⾃⾏设置并保存 Cookie 。
基本格式
bash
Set-Cookie: <name>=<value>
其中 <name> 是 Cookie 的名称,<value> 是 Cookie 的值。完整的 Set-Cookie 示例
bash
Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00 UTC; path=/;
domain=.example.com; secure; HttpOnly时间格式必须遵守RFC 1123标准,具体格式样例: Tue, 01 Jan 2030 12:34:56 GMT或者UTC(推荐) 。
关于时间解释
- Tue: 星期⼆(星期⼏的缩写)
- ,: 逗号分隔符
- 01: ⽇期(两位数表⽰)
- Jan: ⼀⽉(⽉份的缩写)
- 2030: 年份(四位数)
- 12:34:56: 时间(⼩时、分钟、秒)
- GMT: 格林威治标准时间(时区缩写)
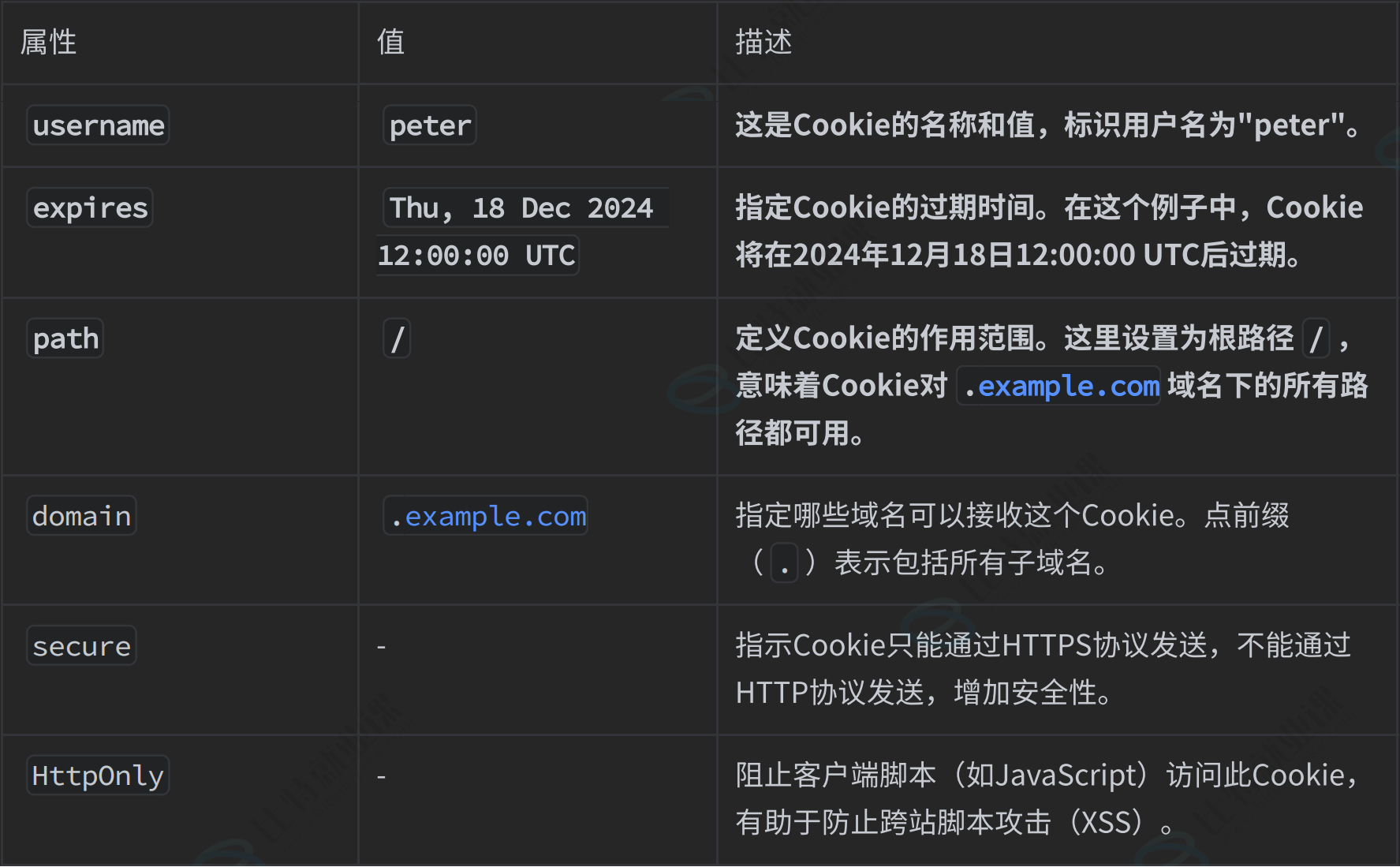
关于其他可选属性的解释
- expires=<date> 要验证:设置 Cookie 的过期⽇期/时间。如果未指定此属性,则Cookie 默认为会话 Cookie,即当浏览器关闭时过期。
- path=<some_path> 要验证:限制 Cookie 发送到服务器的哪些路径。默认为设置它的路径。
- domain=<domain_name> 了解即可:指定哪些主机可以接受该 Cookie。默认为设置它的主机。
- secure 了解即可:仅当使⽤ HTTPS 协议时才发送 Cookie。这有助于防⽌ Cookie 在不安全的 HTTP 连接中被截获。
- HttpOnly 了解即可:标记 Cookie 为 HttpOnly,意味着该 Cookie 不能被客⼾端脚本(如JavaScript)访问。这有助于防⽌跨站脚本攻击(XSS)。
以下是对 Set-Cookie 头部字段的简洁介绍
注意事项
- 每个 Cookie 属性都以分号(;)和空格( )分隔。
- 名称和值之间使用等号(=)分隔。
- 如果 Cookie 的名称或值包含特殊字符(如空格、分号、逗号等),则需要进行 URL 编码。
Cookie 的生命周期
- 如果设置了 expires 属性,则 Cookie 将在指定的日期/时间后过期。
- 如果没有设置 expires 属性,则 Cookie 默认为会话 Cookie,即当浏览器关闭时过期。
安全性考虑了解即可
- 使用 secure 标志可以确保 Cookie 仅在 HTTPS 连接上发送,从而提高安全性。
- 使用 HttpOnly 标志可以防止客户端脚本(如 JavaScript)访问 Cookie,从而防止 XSS 攻击。
- 通过合理设置 Set-Cookie 的格式和属性,可以确保 Cookie 的安全性、有效性和可访问性,从而满足 Web 应用程序的需求。
第十二章:实验测试cookie
测试 cookie 写入到浏览器

测试自动提交

单独使用Cookie,有什么问题?
我们写入的是测试数据,如果写入的是用户的私密数据呢?比如,用户名密码,浏览痕迹等。
本质问题在于这些用户私密数据在浏览器(用户端)保存,非常容易被人盗取,更重要的是,除了被盗取,还有就是用户私密数据也就泄漏了。
第十三章:引入HTTP Session
定义
HTTP Session是服务器用来跟踪用户与服务器交互期间用户状态的机制。由于HTTP协议是无状态的(每个请求都是独立的),因此服务器需要通过Session来记住用户的信息。
工作原理
- 当用户首次访问网站时,服务器会为用户创建一个唯一的 Session ID,并通过 Cookie 将其发送到客户端。
- 客户端在之后的请求中会携带这个 Session ID,服务器通过 Session ID 来识别用户,从而获取用户的会话信息。
- 服务器通常会将 Session 信息存储在内存、数据库或缓存中。
安全性:
- 与 Cookie 相似,由于 Session ID 是在客户端和服务器之间传递的,因此也存在被窃取的风险。
- 但是一般虽然 Cookie 被盗取了,但是用户只泄漏了一个 Session ID,私密信息暂时没有被泄露的风险。
- Session ID便于服务端进行客户端有效性的管理,比如异地登录。
- 可以通过 HTTPS 和设置合适的 Cookie 属性(如 HttpOnly 和 Secure)来增强安全性。
超时和失效:
- Session可以设置超时时间,当超过这个时间后,Session会自动失效。
- 服务器也可以主动使Session失效,例如当用户登出时。
用途:
- 用户认证和会话管理
- 存储用户的临时数据(如购物车内容)
- 实现分布式系统的会话共享(通过将会话数据存储在共享数据库或缓存中)
总结
HTTP Cookie和Session都是用于在Web应用中跟踪用户状态的机制。Cookie是存储在客户端的,而Session是存储在服务器端的。它们各有优缺点,通常在实际应用中会结合使用,以达到最佳的用户体验和安全性。
第十四章:HTTPS 是什么
HTTPS 也是一个应用层协议。是在 HTTP 协议的基础上引入了一个加密层。
HTTP 协议内容都是按照文本的方式明文传输的。这就导致在传输过程中出现一些被篡改的情况。
第十五章:概念准备
1. 什么是"加密"
- 加密就是把 明文 (要传输的信息)进行一系列变换,生成 密文。
- 解密就是把 密文 再进行一系列变换,还原成 明文。
- 在这个加密和解密的过程中,往往需要一个或者多个中间的数据,辅助进行这个过程,这样的数据称为 密钥 (正确发音 yue 四声,不过大家平时都读作 yao 四声)。
加密解密到如今已经发展成一个独立的学科:密码学。
而密码学的奠基人,也正是计算机科学的祖师爷之一,艾伦·麦席森·图灵。
2. 为什么要加密
臭名昭著的"运营商劫持"
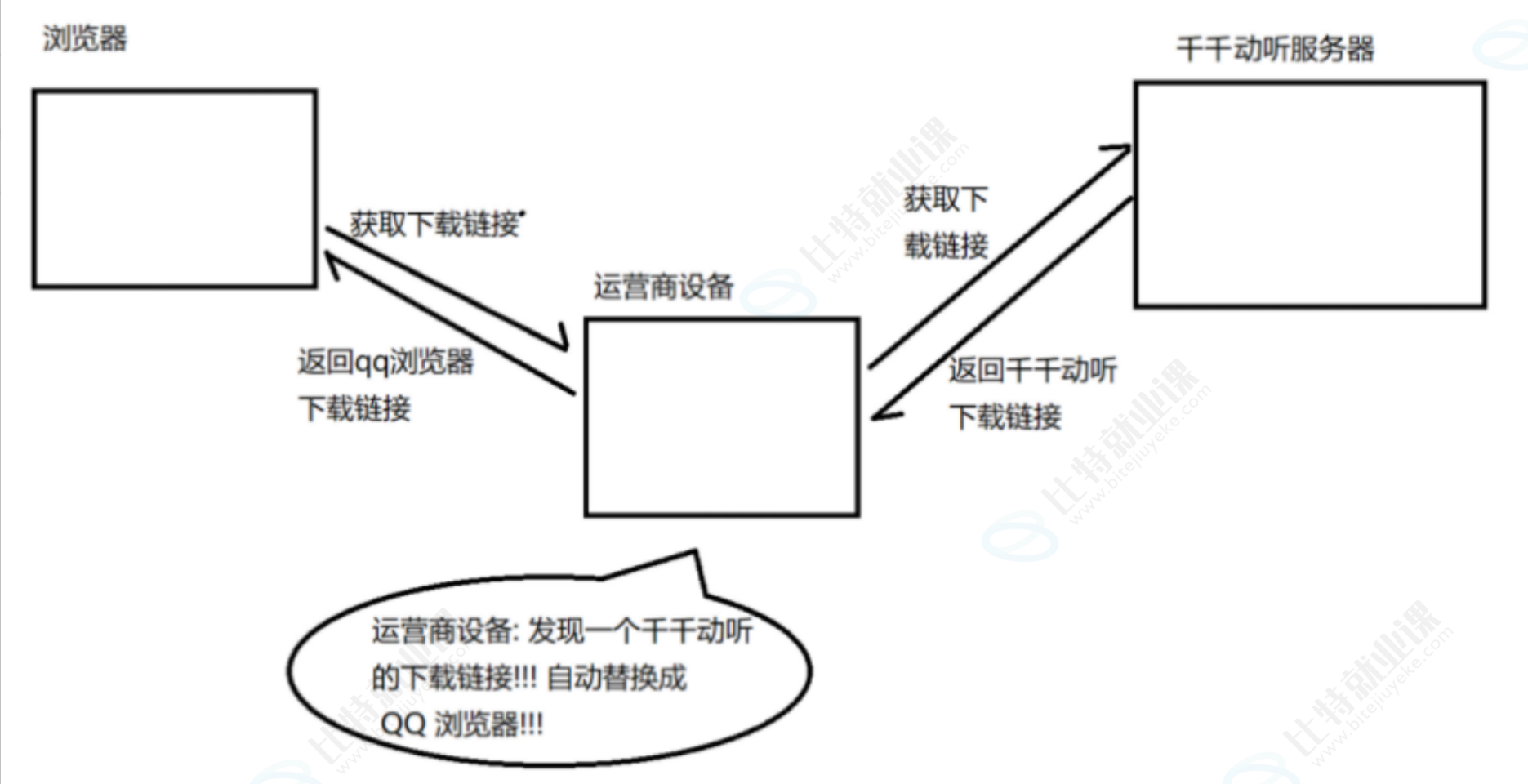
下载一个天天动听
未被劫持的效果,点击下载按钮,就会弹出天天动听的下载链接。
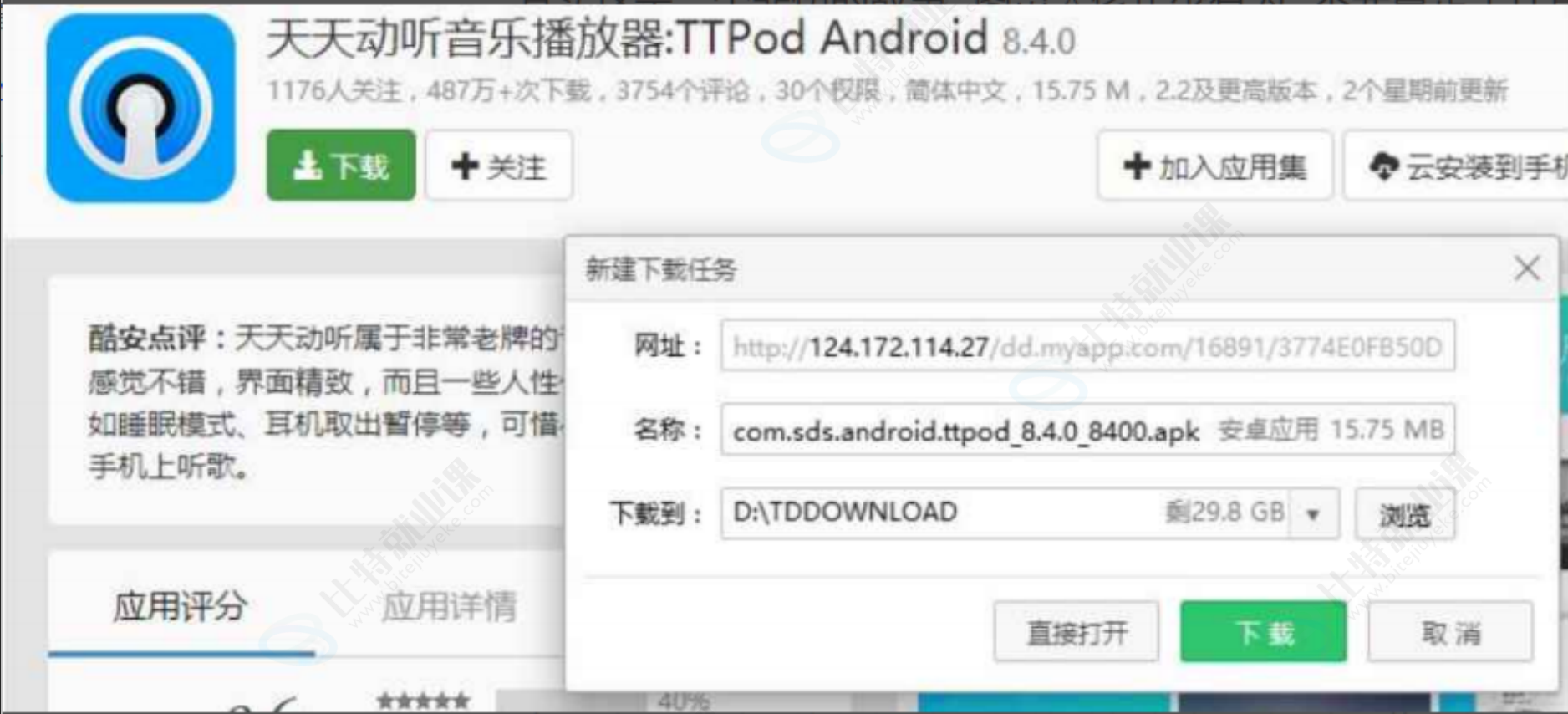
已被劫持的效果,点击下载按钮,就会弹出QQ浏览器的下载链接
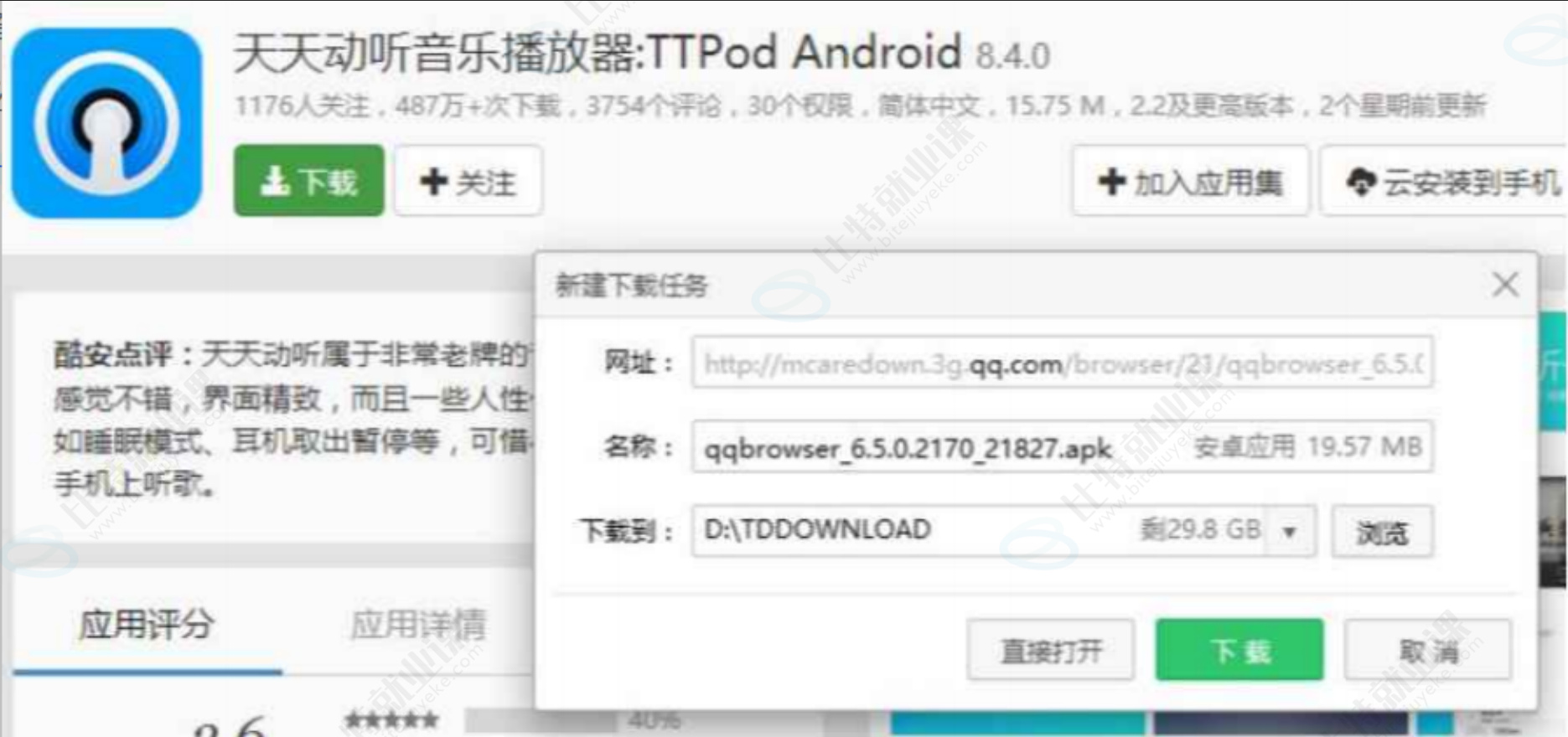
由于我们通过网络传输的任何的数据包都会经过运营商的网络设备(路由器,交换机等),那么运营商的网络设备就可以解析出你传输的数据内容,并进行篡改。
点击"下载按钮",其实就是在给服务器发送了一个 HTTP 请求,获取到的 HTTP 响应其实就包含了该APP 的下载链接。运营商劫持之后,就发现这个请求是要下载天天动听,那么就自动的把交给用户的响应给篡改成"QQ浏览器"的下载地址了。
所以:因为http的内容是明文传输的,明文数据会经过路由器、wifi热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双方察觉,这就是中间人攻击,所以我们才需要对信息进行加密。
不止运营商可以劫持,其他的黑客也可以用类似的手段进行劫持,来窃取用户隐私信息,或者篡改内容。
试想一下,如果黑客在用户登陆支付宝的时候获取到用户账户余额,甚至获取到用户的支付密码。
在互联网上,明文传输是比较危险的事情。
HTTPS 就是在 HTTP 的基础上进行了加密,进一步的来保证用户的信息安全。
3. 常见的加密方式
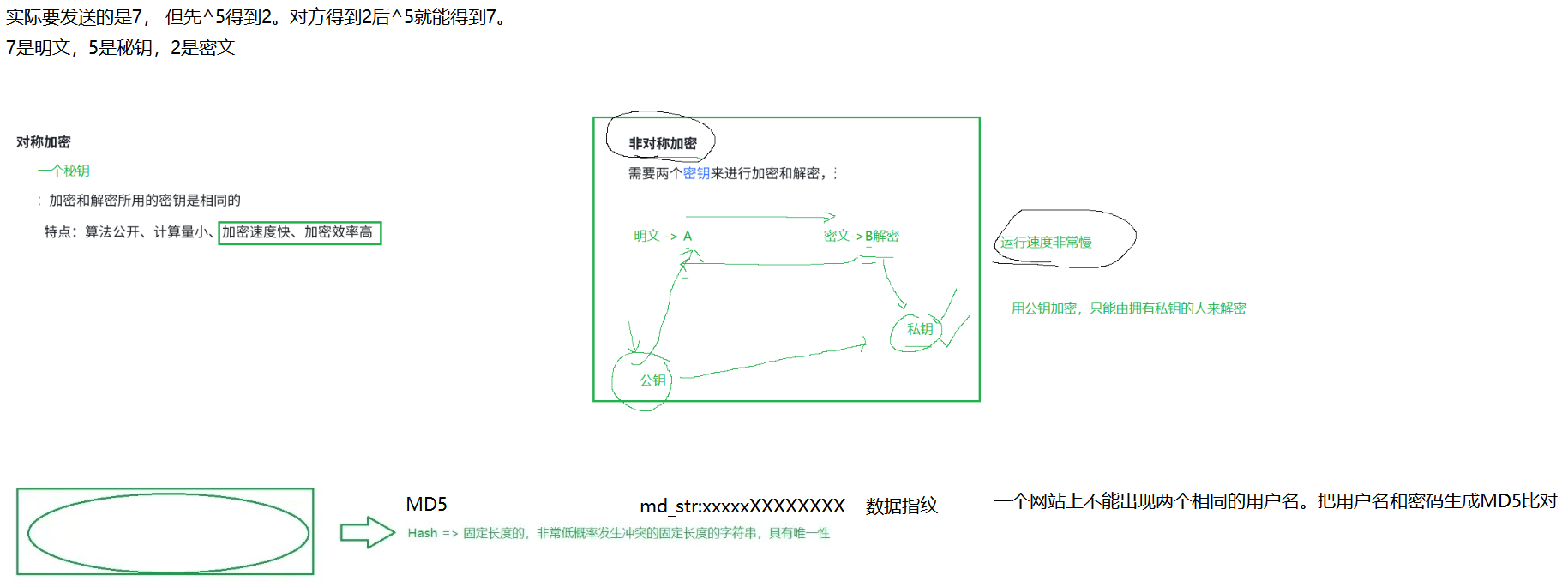
对称加密
- 采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密,特征:加密和解密所用的密钥是相同的
- 常见对称加密算法(了解):DES、3DES、AES、TDEA、Blowfish、RC2等
- 特点:算法公开、计算量小、加密速度快、加密效率高
对称加密其实就是通过同一个"密钥",把明文加密成密文,并且也能把密文解密成明文。
一个简单的对称加密,按位异或
假设 明文 a = 1234,密钥 key = 8888
则加密 a ^ key 得到的密文 b 为 9834。
然后针对密文 9834 再次进行运算 b ^ key,得到的就是原来的明文 1234。
(对于字符串的对称加密也是同理,每一个字符都可以表示成一个数字)
当然,按位异或只是最简单的对称加密。HTTPS 中并不是使用按位异或。
非对称加密
- 需要两个密钥来进行加密和解密,这两个密钥是公开密钥(public key,简称公钥)和私有密钥(private key,简称私钥)。
- 常见非对称加密算法(了解):RSA,DSA,ECDSA
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,而使得加密解密速度没有对称加密解密的速度快。
非对称加密要用到两个密钥,一个叫做"公钥",一个叫做"私钥"。
公钥和私钥是配对的。最大的缺点就是运算速度非常慢,比对称加密要慢很多。
- 通过公钥对明文加密,变成密文
- 通过私钥对密文解密,变成明文
也可以反着用
- 通过私钥对明文加密,变成密文
- 通过公钥对密文解密,变成明文
非对称加密的数学原理比较复杂,涉及到一些数论相关的知识。这里举一个简单的生活中的例子。
A 要给 B 一些重要的文件,但是 B 可能不在。于是 A 和 B 提前做出约定:
B 说:我桌子上有个盒子,然后我给你一把锁,你把文件放盒子里用锁锁上,然后我回头拿着钥匙来开锁取文件。
在这个场景中,这把锁就相当于公钥,钥匙就是私钥。公钥给谁都行(不怕泄露),但是私钥只有 B 自己持有。持有私钥的人才能解密。
4. 数据摘要 && 数据指纹
- 数字指纹(数据摘要),其基本原理是利用单向散列函数(Hash函数)对信息进行运算,生成一串固定长度的数字摘要。数字指纹并不是一种加密机制,但可以用来判断数据有没有被篡改。
- 摘要常见算法:有MD5、SHA1、SHA256、SHA512等,算法把无限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率非常低)
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常用来进行数据对比
5. 数字签名
摘要经过加密,就得到数字签名(后面细说)
6. 理解链 - 承上启下
对http进行对称加密,是否能解决数据通信安全的问题?问题是什么?
为何要用非对称加密?为何不全用非对称加密?
第十六章:HTTPS 的工作过程探究
既然要保证数据安全,就需要进行 "加密"。
网络传输中不再直接传输明文了,而是加密之后的 "密文"。
加密的方式有很多,但是整体可以分成两大类:对称加密 和 非对称加密
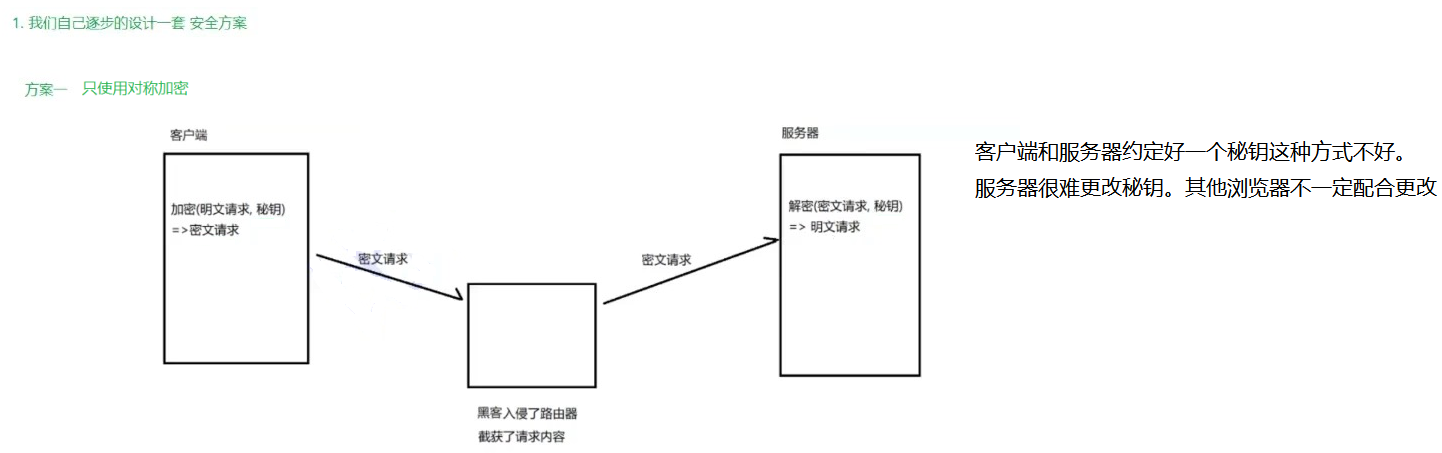
方案 1 - 只使用对称加密
如果通信双方都各自持有同一个密钥 X,且没有别人知道,这两方的通信安全当然是可以被保证的(除非密钥被破解)
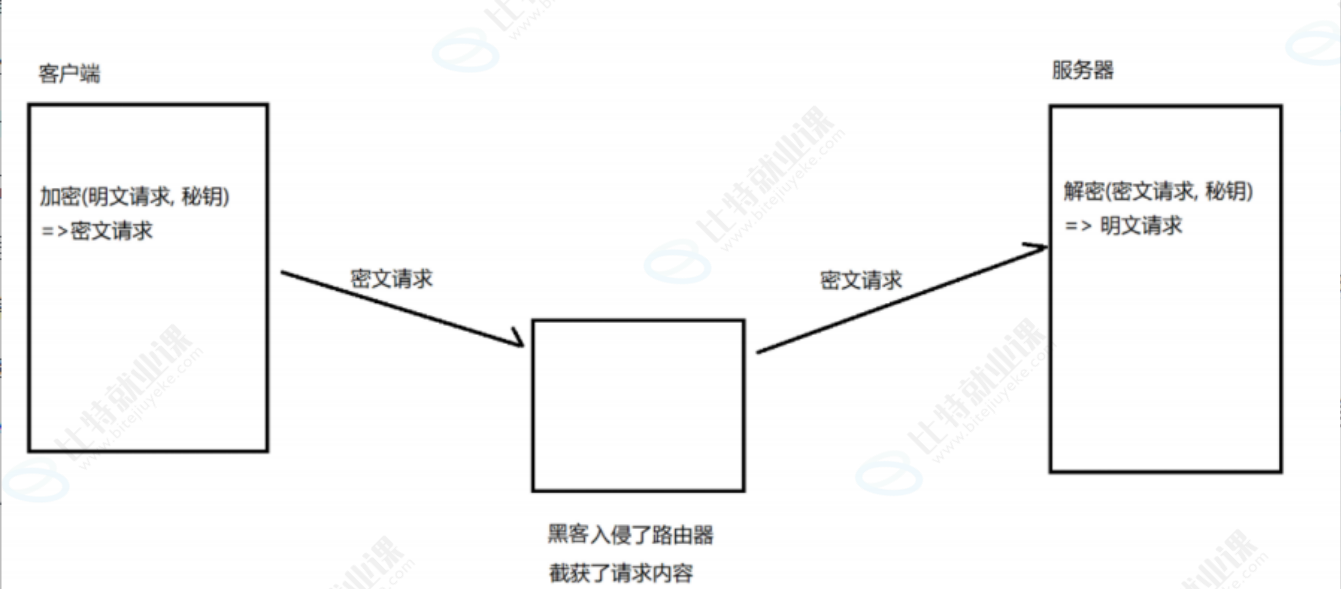
引入对称加密之后,即使数据被截获,由于黑客不知道密钥是啥,因此就无法进行解密,也就不知道请求的真实内容是啥了。
但事情没这么简单。服务器同一时刻其实是给很多客户端提供服务的。这么多客户端,每个人用的秘钥都必须是不同的(如果是相同那密钥就太容易扩散了,黑客就也能拿到了)。因此服务器就需要维护每个客户端和每个密钥之间的关联关系,这也是个很麻烦的事情~
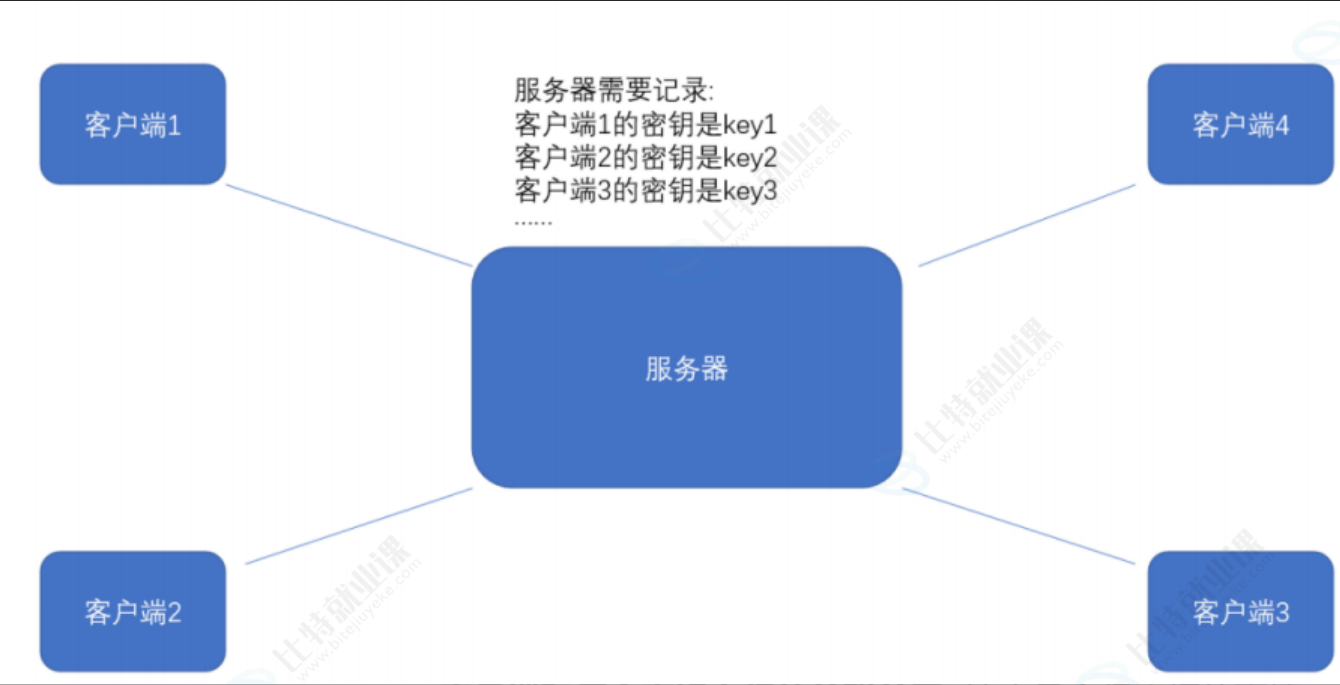
比较理想的做法 ,就是在客户端和服务器建立连接的时候,双方协商确定这次的密钥是啥~
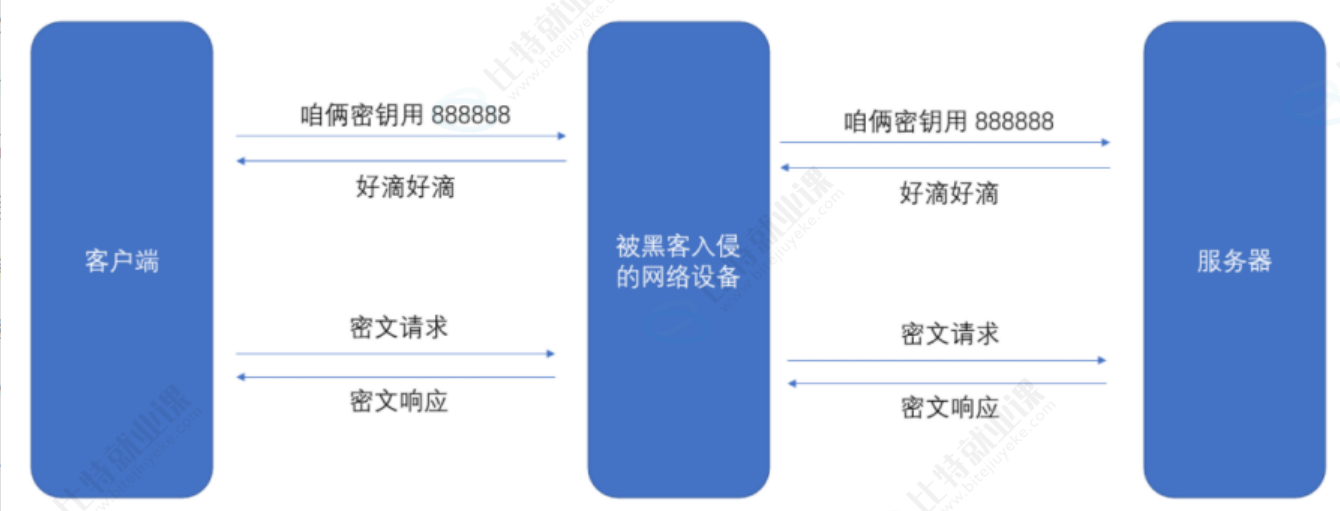
但是如果直接把密钥明文传输,那么黑客也就能获得密钥了~~ 此时后续的加密操作就形同虚设了。
因此密钥的传输也必须加密传输!
但是要想对密钥进行对称加密,就仍然需要先协商确定一个 "密钥的密钥"。这就成了 "先有鸡还是先有蛋" 的问题了。此时密钥的传输再用对称加密就行不通了。
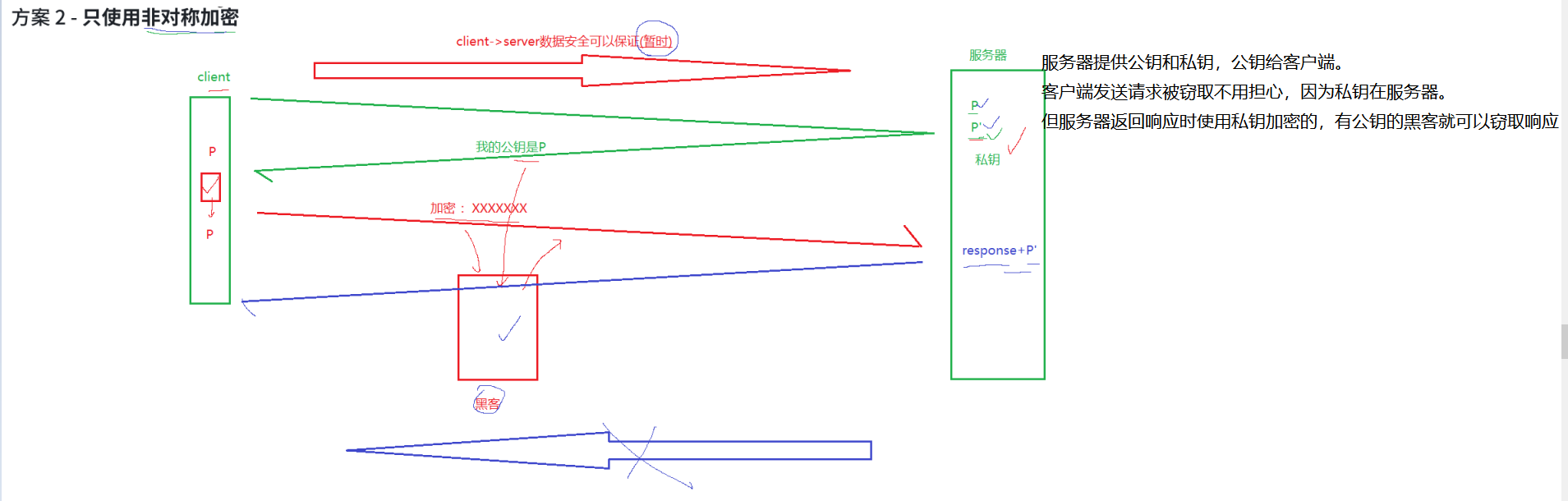
方案 2 - 只使用非对称加密
鉴于非对称加密的机制,如果服务器先把公钥以明文方式传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,从客户端到服务器信道似乎是安全的(有安全问题),因为只有服务器有相应的私钥能解开公钥加密的数据。
但是服务器到浏览器的这条路怎么保障安全?
如果服务器用它的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,若这个公钥被中间人劫持到了,那他也能用该公钥解密服务器传来的信息了。
方案 3 - 双方都使用非对称加密
- 服务端拥有公钥 S 与对应的私钥 S',客户端拥有公钥 C 与对应的私钥 C'
- 客户和服务端交换公钥
- 客户端给服务端发信息:先用 S 对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥 S'
- 服务端给客户端发信息:先用 C 对数据加密,再发送,只能由客户端解密,因为只有客户端有私钥 C'
这样貌似也行啊,但是
- 效率太低
- 依旧有安全问题

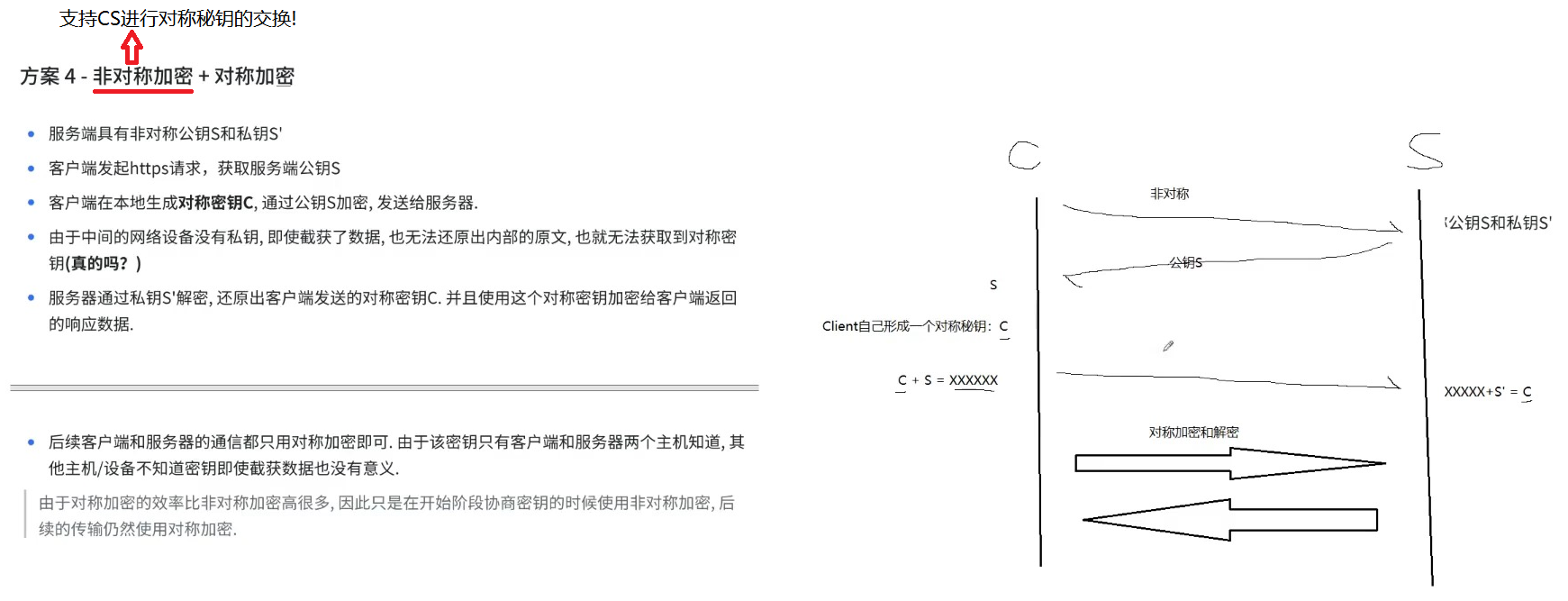
方案 4 - 非对称加密 + 对称加密
先解决效率问题
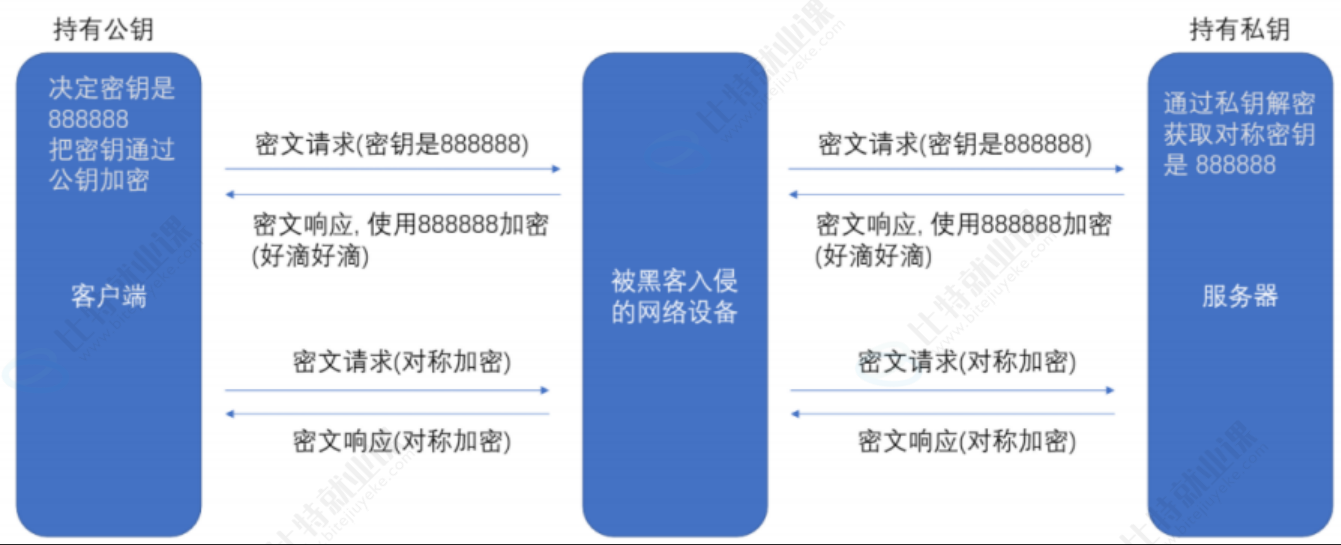
- 服务端具有非对称公钥 S 和私钥 S'
- 客户端发起 https 请求,获取服务端公钥 S
- 客户端在本地生成对称密钥 C,通过公钥 S 加密,发送给服务器。
- 由于中间的网络设备没有私钥,即使截获了数据,也无法还原出内部的原文,也就无法获取到对称密钥(真的吗?)
- 服务器通过私钥 S' 解密,还原出客户端发送的对称密钥 C,并且使用这个对称密钥加密给客户端返回的响应数据。
- 后续客户端和服务器的通信都只用对称加密即可。由于该密钥只有客户端和服务器两个主机知道,其他主机/设备不知道密钥即使截获数据也没有意义。
由于对称加密的效率比非对称加密高很多,因此只是在开始阶段协商密钥的时候使用非对称加密,后续的传输仍然使用对称加密。
虽然上面已经比较接近答案了,但是依旧有安全问题
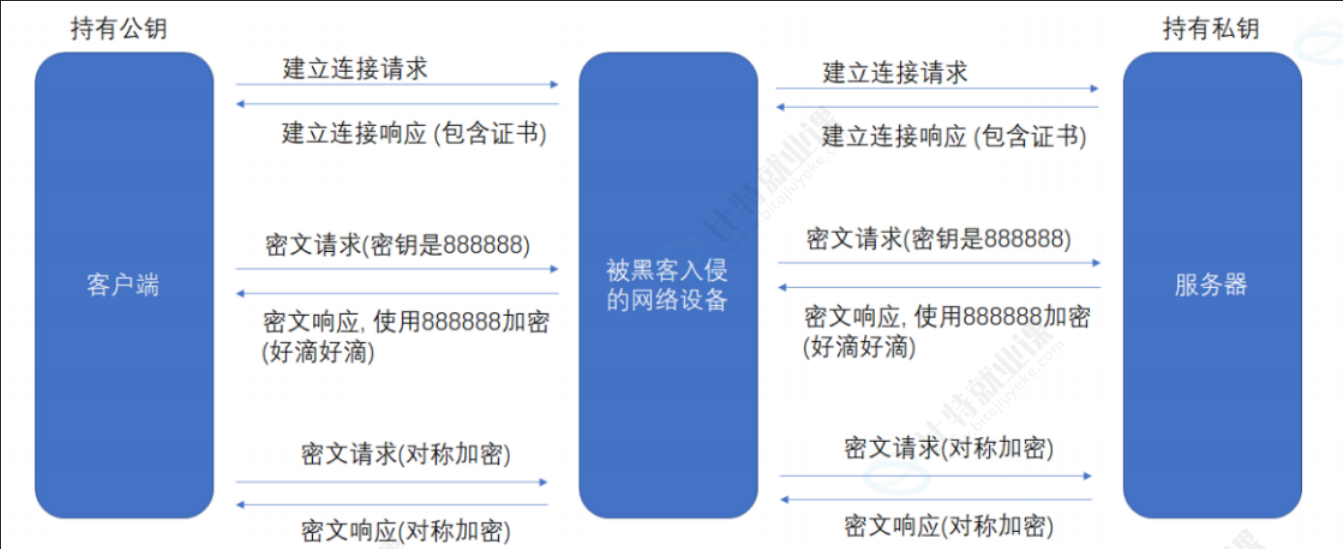
方案 2,方案 3,方案 4 都存在一个问题,如果最开始,中间人就已经开始攻击了呢?
中间人攻击 - 针对上面的场景
- Man-in-the-MiddleAttack,简称"MITM攻击"
确实,在方案 2/3/4 中,客户端获取到公钥 S 之后,对客户端形成的对称秘钥 X 用服务端给客户端的公钥 S 进行加密,中间人即使窃取到了数据,此时中间人确实无法解出客户端形成的密钥 X,因为只有服务器有私钥 S'
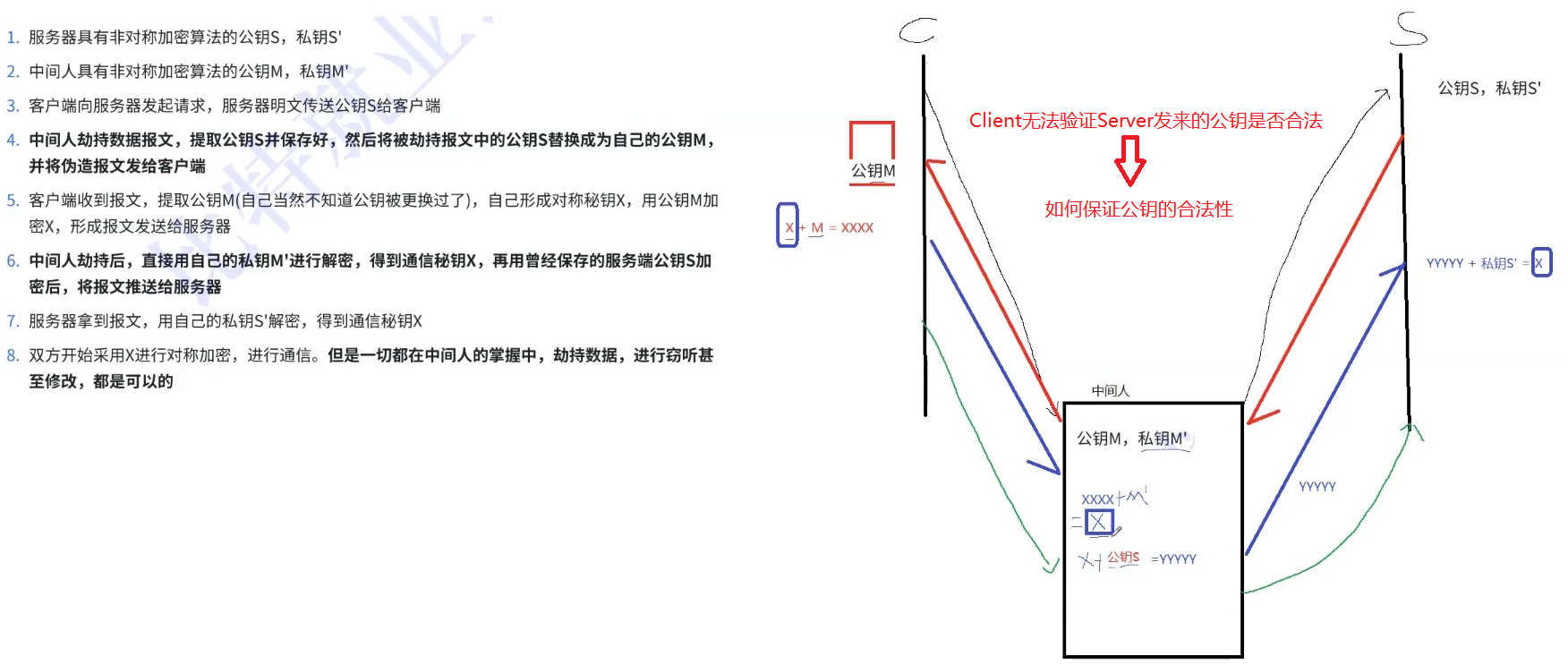
但是中间人的攻击,如果在最开始握手协商的时候就进行了,那就不一定了,假设 hacker 已经成功成为中间人
- 服务器具有非对称加密算法的公钥 S,私钥 S'
- 中间人具有非对称加密算法的公钥 M,私钥 M'
- 客户端向服务器发起请求,服务器明文传送公钥 S 给客户端
- 中间人劫持数据报文,提取公钥 S 并保存好,然后将被劫持报文中的公钥 S 替换成为自己的公钥 M,并将伪造报文发给客户端
- 客户端收到报文,提取公钥 M(自己当然不知道公钥被更换过了),自己形成对称秘钥 X,用公钥 M 加密 X,形成报文发送给服务器
- 中间人劫持后,直接用自己的私钥 M' 进行解密,得到通信秘钥 X,再用曾经保存的服务端公钥 S 加密后,将报文推送给服务器
- 服务器拿到报文,用自己的私钥 S' 解密,得到通信秘钥 X
- 双方开始采用 X 进行对称加密,进行通信。但是一切都在中间人的掌握中,劫持数据,进行窃听甚至修改,都是可以的
上面的攻击方案,同样适用于方案 2,方案 3
问题本质出在什么地方了呢?客户端无法确定收到的含有公钥的数据报文,就是目标服务器发送过来的!
引入证书
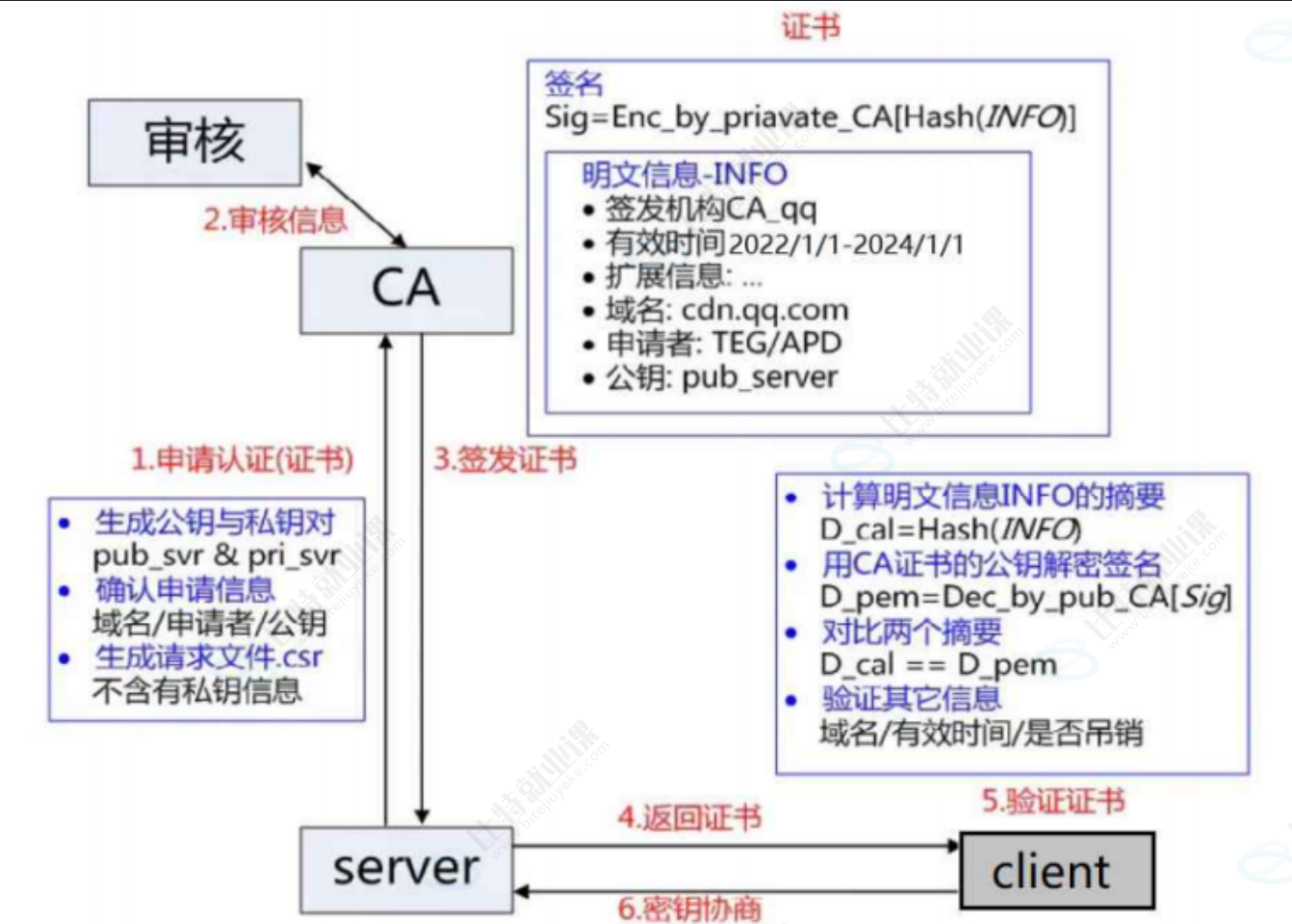
CA 认证
服务端在使用 HTTPS 前,需要向 CA 机构申领一份数字证书,数字证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明服务端公钥的权威性。
基本说明:https://baike.baidu.com/item/CA%E8%AE%A4%E8%AF%81/6471579?fr=aladdin
这个证书可以理解成是一个结构化的字符串,里面包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- ......
需要注意的是:申请证书的时候,需要在特定平台生成,会同时生成一对儿密钥对儿,即公钥和私钥。这对密钥对儿就是用来在网络通信中进行明文加密以及数字签名的。
其中公钥会随着 CSR 文件,一起发给 CA 进行权威认证,私钥服务端自己保留,用来后续进行通信(其实主要就是用来交换对称秘钥)

可以使用在线生成 CSR 和私钥:https://myssl.com/csr_create.html
形成 CSR 之后,后续就是向 CA 进行申请认证,不过一般认证过程很繁琐,网络各种提供证书申请的服务商,一般真的需要,直接找平台解决就行
理解数据签名
签名的形成是基于非对称加密算法的,注意,目前暂时和 https 没有关系,不要和 https 中的公钥私钥搞混了。
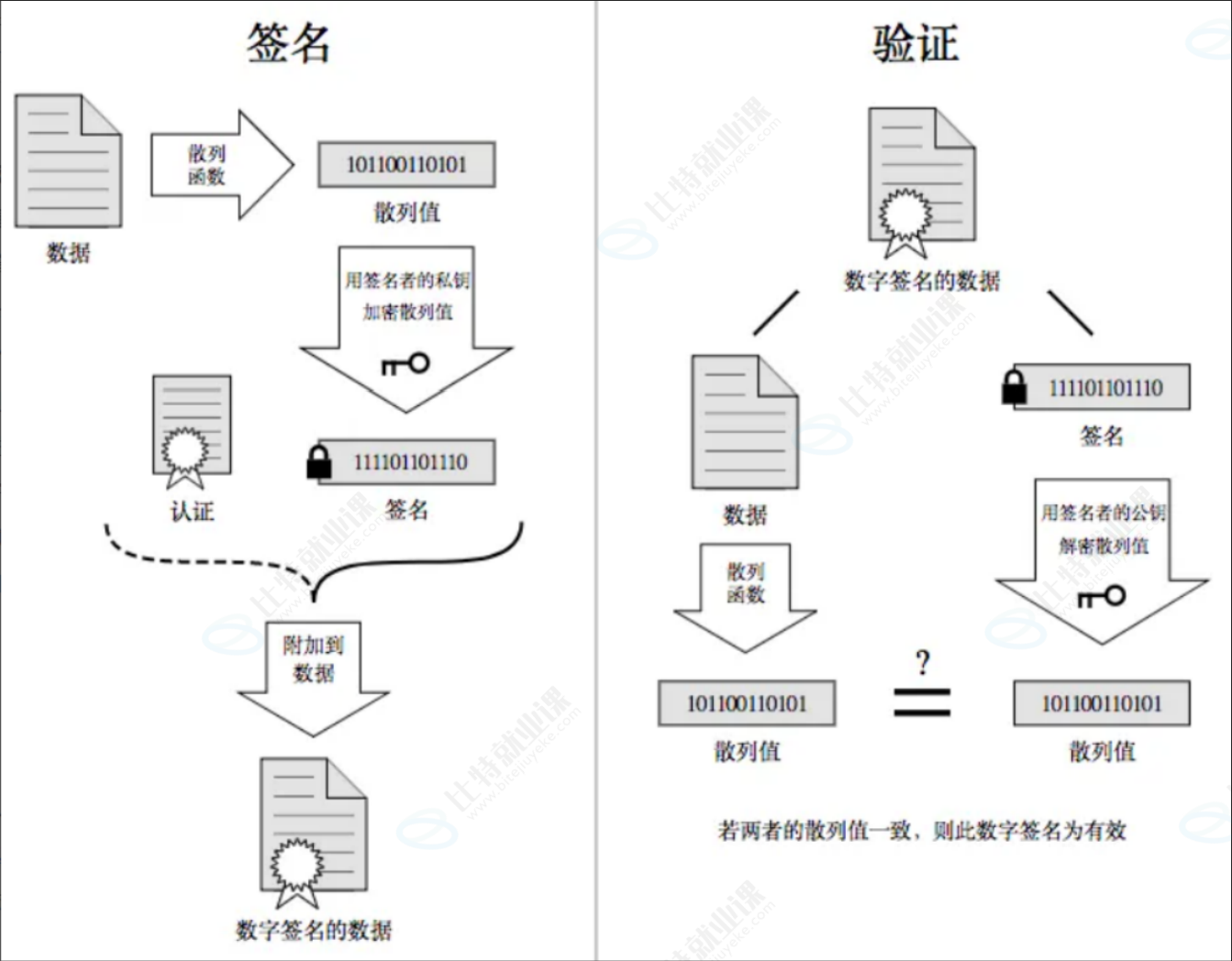
当服务端申请 CA 证书的时候,CA 机构会对该服务端进行审核,并专门为该网站形成数字签名,过程如下:
- CA 机构拥有非对称加密的私钥 A 和公钥 A'
- CA 机构对服务端申请的证书明文数据进行 hash,形成数据摘要
- 然后对数据摘要用 CA 私钥 A' 加密,得到数字签名 S
服务端申请的证书明文和数字签名 S 共同组成了数字证书,这样一份数字证书就可以颁发给服务端了
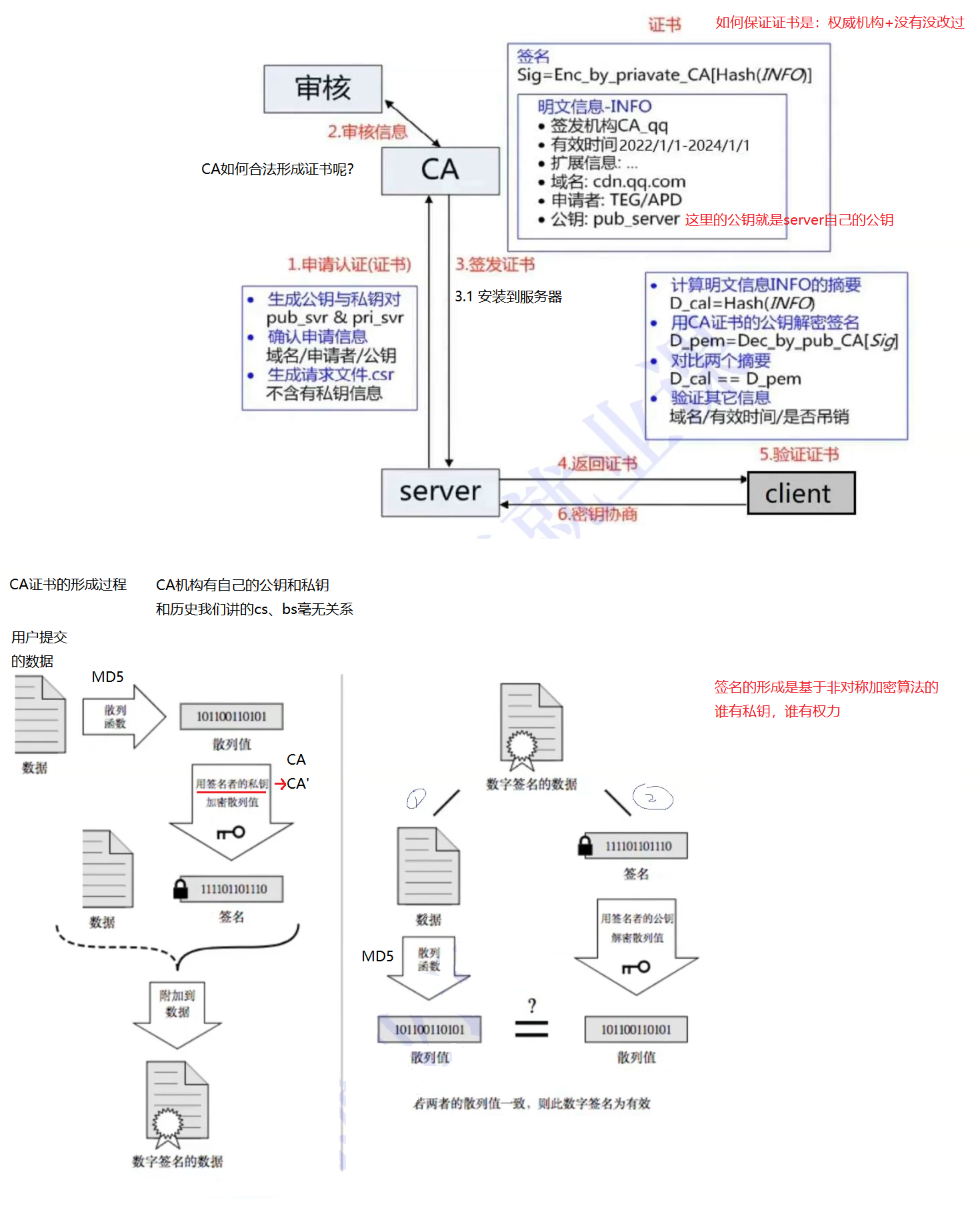
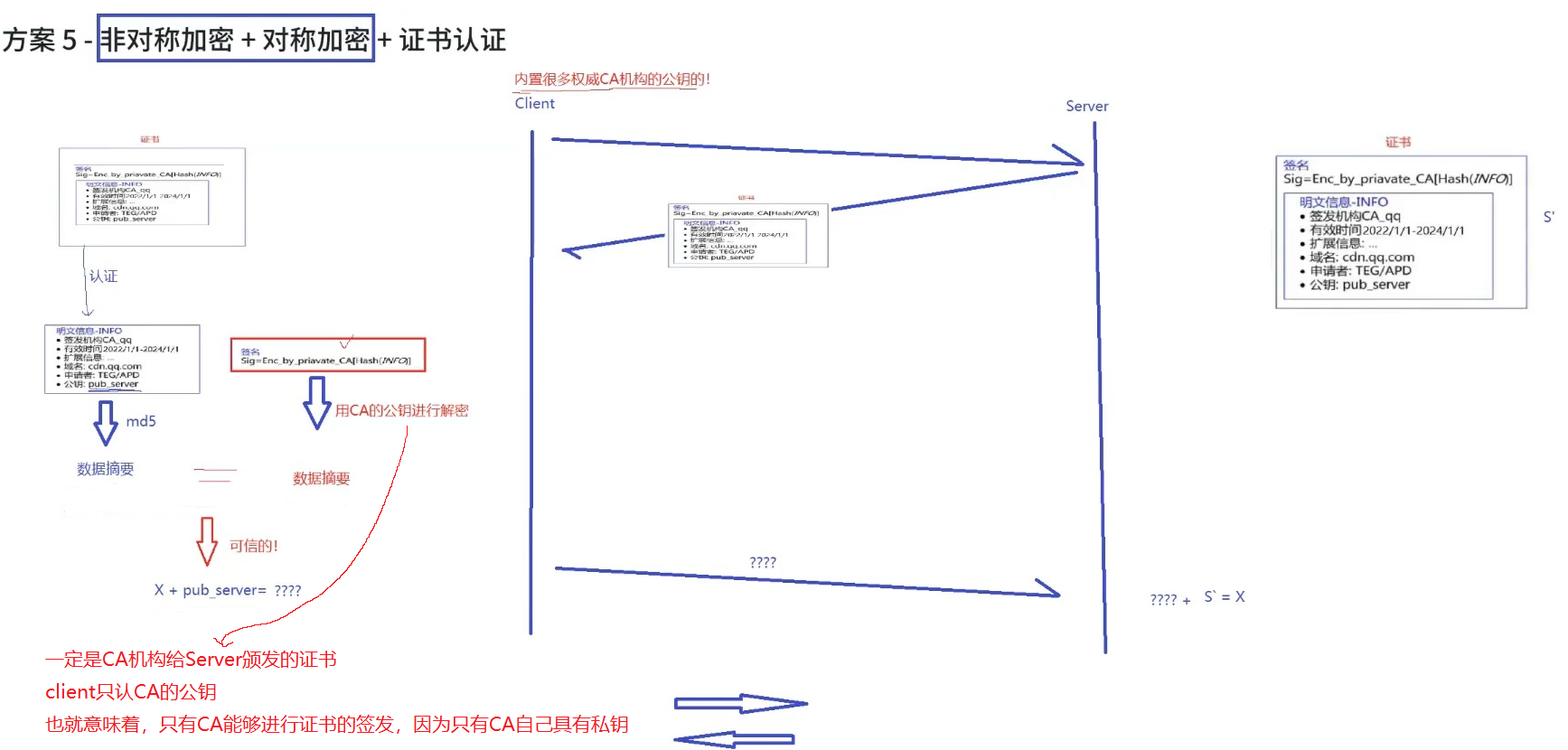
方案 5 - 非对称加密 + 对称加密 + 证书认证
在客户端和服务器刚一建立连接的时候,服务器给客户端返回一个证书,证书包含了之前服务端的公钥,也包含了网站的身份信息。
客户端进行认证
当客户端获取到这个证书之后,会对证书进行校验(防止证书是伪造的)。
- 判定证书的有效期是否过期
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)。
- 验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到一个 hash 值(称为数据摘要),设为 hash1。然后计算整个证书的 hash 值,设为 hash2。对比 hash1 和 hash2 是否相等。如果相等,则说明证书是没有被篡改过的。
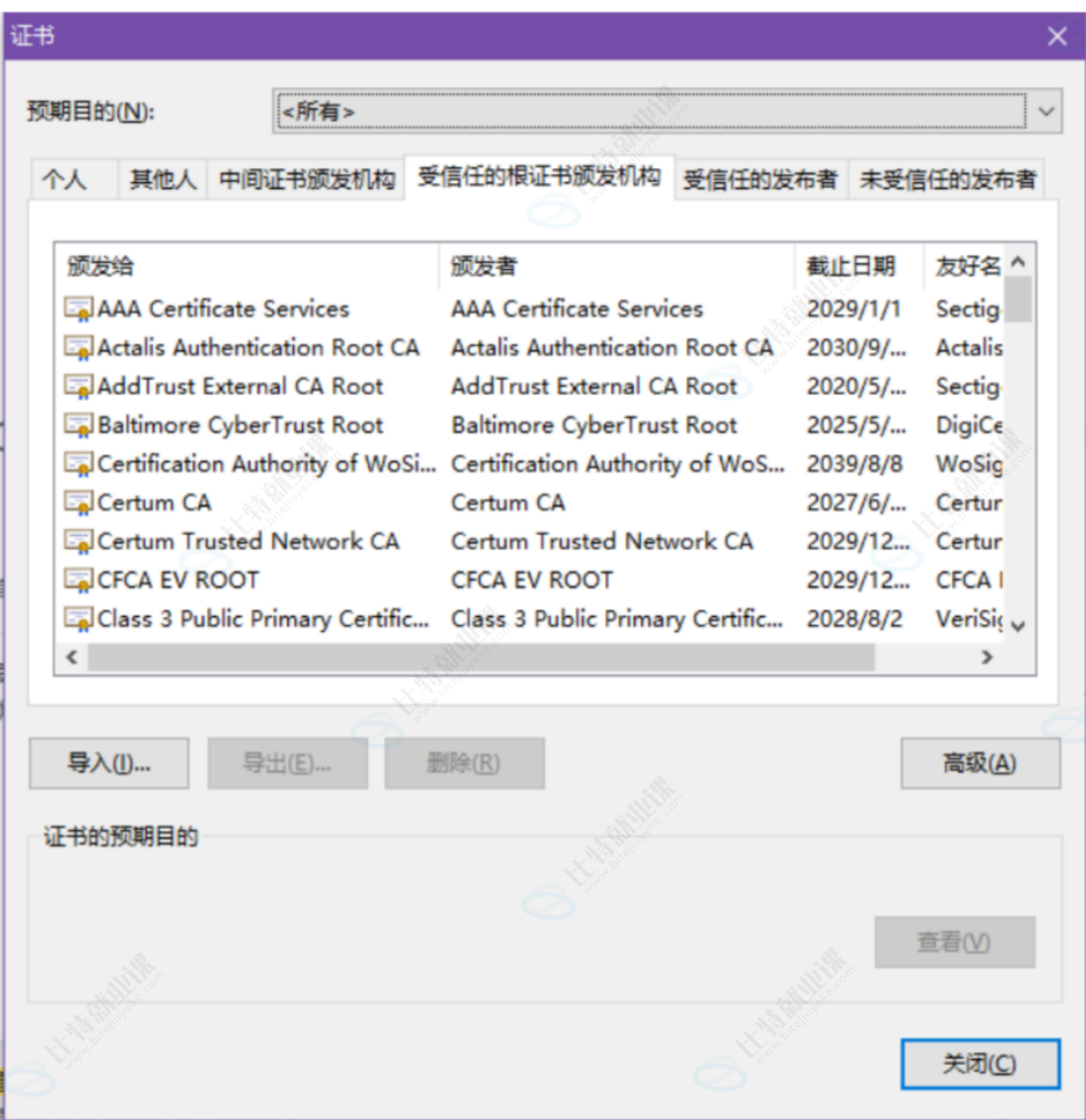
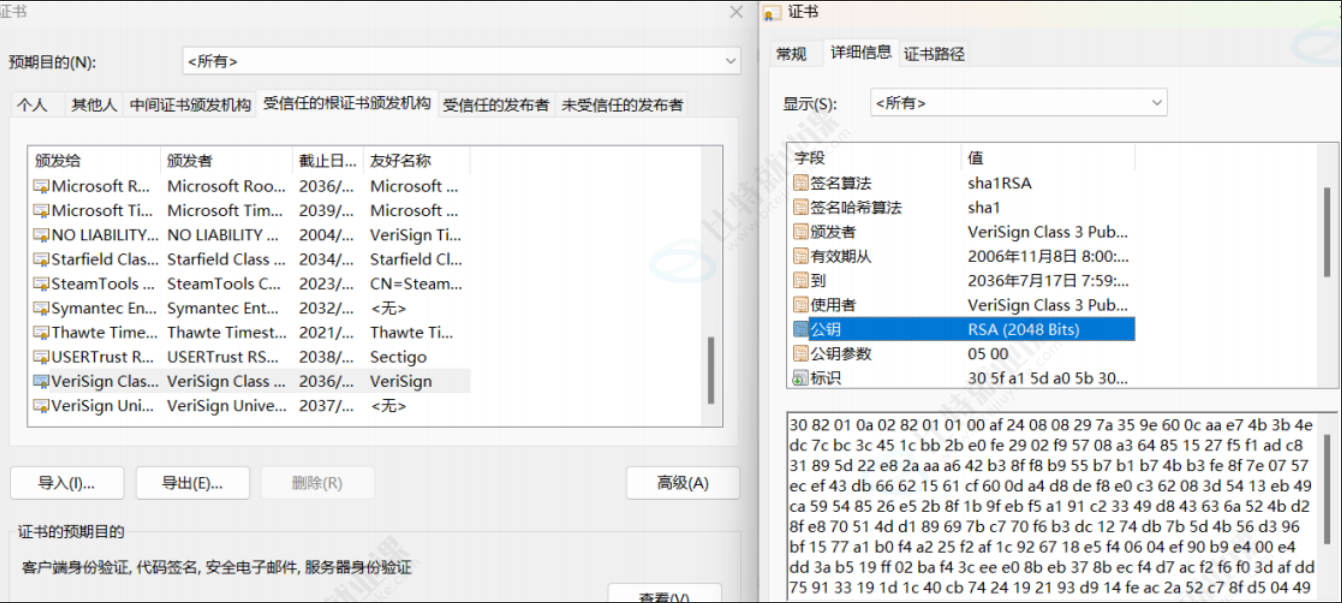
查看浏览器的受信任证书发布机构
Chrome 浏览器,点击右上角的菜单

选择 "设置",搜索 "证书管理",即可看到以下界面。(如果没有,在隐私设置和安全性 -> 安全里面找找)
中间人有没有可能篡改该证书?
- 中间人篡改了证书的明文
- 由于他没有 CA 机构的私钥,所以无法 hash 之后用私钥加密形成签名,那么也就没办法对篡改后的证书形成匹配的签名
- 如果强行篡改,客户端收到该证书后会发现明文和签名解密后的值不一致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间人
中间人整个掉包证书?
- 因为中间人没有 CA 私钥,所以无法制作假的证书(为什么?)
- 所以中间人只能向 CA 申请真证书,然后用自己的证书进行掉包
- 这个确实能做到证书的整体掉包,但是别忘记,证书明文中包含了域名等服务端认证信息,如果整体掉包,客户端依旧能够识别出来。
- 永远记住:中间人没有 CA 私钥,所以对任何证书都无法进行合法修改,包括自己的
第十七章:常见问题
为什么摘要内容在网络传输的时候一定要加密形成签名?
常见的摘要算法有:MD5 和 SHA 系列
以 MD5 为例,我们不需要研究具体的计算签名的过程,只需要了解 MD5 的特点:
- 定长:无论多长的字符串,计算出来的 MD5 值都是固定长度(16 字节版本或者 32 字节版本)
- 分散:源字符串只要改变一点点,最终得到的 MD5 值都会差别很大。
- 不可逆:通过源字符串生成 MD5 很容易,但是通过 MD5 还原成原串理论上是不可能的。
正因为 MD5 有这样的特性,我们可以认为如果两个字符串的 MD5 值相同,则认为这两个字符串相同。
理解判定证书篡改的过程:(这个过程就好比判定这个身份证是不是伪造的身份证)
假设我们的证书只是一个简单的字符串 hello,对这个字符串计算 hash 值(比如 md5),结果为 BC4B2A76B9719D91
如果 hello 中有任意的字符被篡改了,比如变成了 hella,那么计算的 md5 值就会变化很大。BDBD6F9CF51F2FD8
然后我们可以把这个字符串 hello 和哈希值 BC4B2A76B9719D91 从服务器返回给客户端,此时客户端如何验证 hello 是否是被篡改过?
那么就只要计算 hello 的哈希值,看看是不是 BC4B2A76B9719D91 即可。

但是还有个问题,如果黑客把 hello 篡改了,同时也把哈希值重新计算下,客户端就分辨不出来了呀。
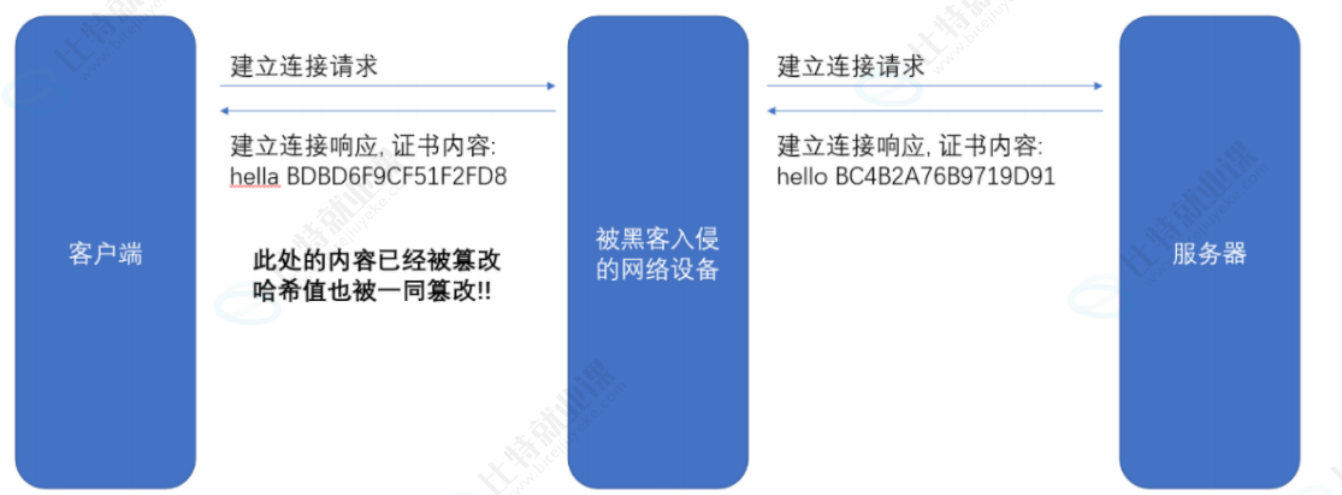
所以被传输的哈希值不能传输明文,需要传输密文。
所以,对证书明文(这里就是"hello")hash 形成散列摘要,然后 CA 使用自己的私钥加密形成签名,将 hello 和加密的签名合起来形成 CA 证书,颁发给服务端,当客户端请求的时候,就发送给客户端,中间人截获了,因为没有 CA 私钥,就无法更改或者整体掉包,就能安全的证明,证书的合法性。
最后,客户端通过操作系统里已经存了的证书发布机构的公钥进行解密,还原出原始的哈希值,再进行校验。
为什么签名不直接加密,而是要先 hash 形成摘要?
缩小签名密文的长度,加快数字签名的验证签名的运算速度
如何成为中间人 - 了解
- ARP 欺骗:在局域网中,hacker 经过收到 ARP Request 广播包,能够偷听到其它节点的 (IP, MAC) 地址。例,黑客收到两个主机 A, B 的地址,告诉 B (受害者),自己是 A,使得 B 在发送给 A 的数据包都被黑客截取
- ICMP 攻击:由于 ICMP 协议中有重定向的报文类型,那么我们就可以伪造一个 ICMP 信息然后发送给局域网中的客户端,并伪装自己是一个更好的路由通路。从而导致目标所有的上网流量都会发送到我们指定的接口上,达到和 ARP 欺骗同样的效果
- 假 wifi && 假网站等
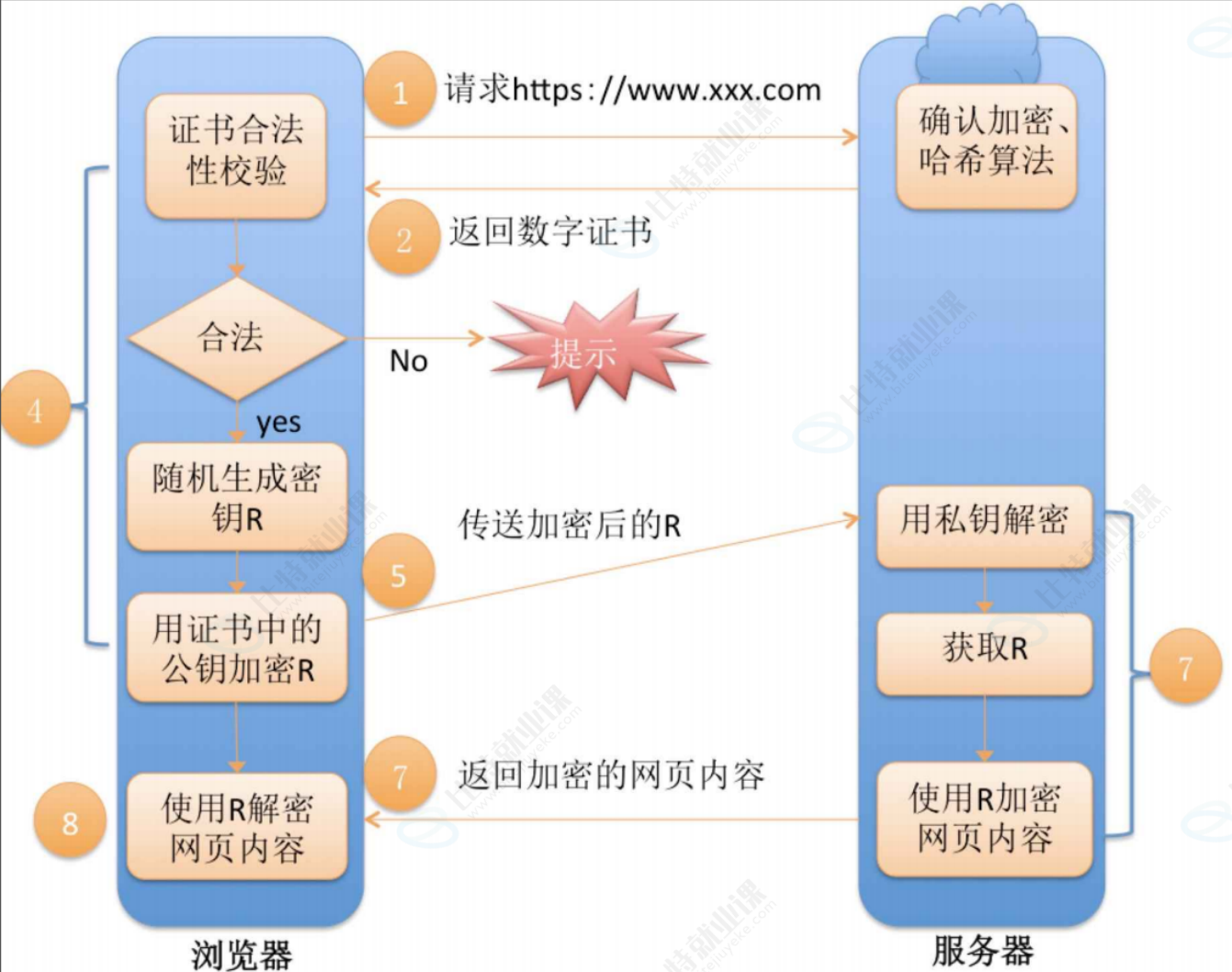
第十八章:完整流程
左侧都是客户端做的事情,右侧都是服务器做的事情。
第十九章:总结
HTTPS 工作过程中涉及到的密钥有三组。
第一组(非对称加密):用于校验证书是否被篡改。服务器持有私钥(私钥在形成 CSR 文件与申请证书时获得),客户端持有公钥(操作系统包含了可信任的 CA 认证机构有哪些,同时持有对应的公钥)。服务器在客户端请求时,返回携带签名的证书。客户端通过这个公钥进行证书验证,保证证书的合法性,进一步保证证书中携带的服务端公钥权威性。
第二组(非对称加密):用于协商生成对称加密的密钥。客户端用收到的 CA 证书中的公钥(是可被信任的)给随机生成的对称加密的密钥加密,传输给服务器,服务器通过私钥解密获取到对称加密密钥。
第三组(对称加密):客户端和服务器后续传输的数据都通过这个对称密钥加密解密。
其实一切的关键都是围绕这个对称加密的密钥。其他的机制都是辅助这个密钥工作的。
第二组非对称加密的密钥是为了让客户端把这个对称密钥传给服务器。
第一组非对称加密的密钥是为了让客户端拿到第二组非对称加密的公钥。
作业
1. 以下关于HTTP协议叙述正确的是()
A.HTTP协议是建立在 TCP/IP 协议之上的网络层规范,分为三个部分:状态行、请求头、消息主体
B.Cookie数据在消息主体(body)中传输
C.HTTP协议支持一定时间内的TCP连接保持,这个连接可以用于发送/接收多次请求
D.HTTP是有状态的,每个请求都是独立的
答案:C
答案解析:
A错误:HTTP协议,是TCP / IP协议栈中应用层的协议
B错误:Cookie数据是在HTTP协议头部字段中传输
C正确:HTTP协议在目前1.1版本中支持了长连接管理,也就是支持在一定时间内保持TCP连接建立,用于发送 / 接收多次请求
D错误:HTTP协议是无状态的协议,在最初设计的时候HTTP协议是一种简单的请求 - 响应协议,即一次建立连接中,完成一次请求一次响应后,通信结束关闭连接,所以是无状态的
2. 文件传输使用的协议是()
A.SMTP
B.FTP
C.UDP
D.TELNET
答案:B
答案解析:
SMTP:简单邮件协议
FTP:文件传输协议
UDP : 用户数据报协议
TELNET : Internet远程登录服务的标准协议
3. 【多选题】.以下对http请求方法描述正确的是()
A.POST请求永远不会被缓存,且对数据长度没有限制
B.我们可以从浏览器历史记录中查找到GET请求
C.我们无法从浏览器历史记录中查找到POST请求
D.PUT方法会将包含的元素放在所提供的URI下,如果URI指示的是当前资源,则会被改变。如果URI未指示当前资源,则服务器不可以使用该URI创建资源
答案:ABC
答案解析:
A正确:POST请求主要用于向服务器提交表单数据,因此POST请求不会被缓存,POST请求不会保留在浏览器历史记录当中,POST请求不能被保存为书签,POST请求对数据长度没有要求
B正确:GET请求主要用于从服务器获取实体资源,资源可被缓存,可以记录历史记录
C正确:
D错误:PUT方法请求服务器去把请求里的实体存储在请求URI(Request - URI)标识下。
- 如果请求URI(Request - URI)指定的的资源已经在源服务器上存在,那么此请求里的实体应该被当作是源服务器关于此URI所指定资源实体的最新修改版本。
- 如果请求URI(Request - URI)指定的资源不存在,并且此URI被用户代理定义为一个新资源,那么源服务器就应该根据请求里的实体创建一个此URI所标识下的资源。如果一个新的资源被创建了,源服务器必须能向用户代理(user agent) 发送201(已创建)响应。如果已存在的资源被改变了,那么源服务器应该发送200(Ok)或者204(无内容)响应
4. 以下对http请求方法描述错误的是()
A.GET请求是安全的,长度是有限制的
B.HEAD请求是没有响应体的,仅传输状态行和标题部分
C.DELETE方法用来删除指定的资源,它会删除URI给出的目标资源的所有当前内容
D.PUT方法用于将数据发送到服务器以创建或更新资源,它可以用上传的内容替换目标资源中的所有当前内容
答案:A
答案解析:
A错误:安全的定义很宽泛....这里的安全更多的指的是在提交参数时的安全系数,它是不够安全的。
BCD正确 :选项中的解释都是对对应请求方法的文档解释,作为固定概念性理解即可。
5. 【多选题】以下关于HTTP说法正确是的:()
A. HTTP POST方式比GET更私密
B.HTTP GET请求提交参数没有长度限制
C.HTTP POST请求提交参数没有长度限制
D.HTTP GET和POST请求提交参数都没有长度限制
答案:AC
答案解析:
A正确:更私密指的是将请求的数据放在了body中
B错误:Http Get方法提交的数据大小长度并没有限制,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制,而这个限制是实实在在存在的。
C正确:理论上讲,POST是没有大小限制的。HTTP协议规范也没有进行大小限制,起限制作用的是服务器的处理程序的处理能力,而并非限制。
D错误:与B选项是相同的,GET提交参数有长度限制,而POST没有
6. 以下不是合法HTTP请求方法的是( )
A.GET
B.SET
C.HEAD
D.PUT
答案:B
答案解析:
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法
7. HTTP1.1的请求方法不包括?()
A.PUT
B.DELETE
C.POLL
D.TRACE
答案:C
答案解析:
http1.0,三种:post,get,head
http1.1,八种:post,get,head,options,put,delete,trace,connect
8. HTTP 应答中的 500 错误是:()
A.服务器内部出错
B.文件未找到
C.客户端网络不通
D.没有访问权限
答案:A
答案解析
500 表示服务器内部出错
9. 【不定项选择题】关于HTTP状态码说法正确的是 ()
A.404 表示正常返回信息
B.302 表示永久性重定向
C.503 表示服务器端暂时无法处理请求
D.403 表示禁止访问
答案:CD
答案解析
404 NOT FOUND,表示客户端请求的资源不存在
302 表示临时重定向
503 由于临时的服务器维护或者过载,服务器当前无法处理请求。.这个状况是临时的,并且将在一段时间以后恢复。
403 禁止访问,服务器理解请求客户端的请求,但是拒绝执行此请求(比如权限不足,ip被拉黑。。。等一系列原因)
10. 以下http状态码中哪一个是永久重定向?( )
A.301
B.302
C.303
D.307
答案:A
答案解析
301:
- 301 状态码表明目标资源被永久的移动到了一个新的 URI,任何未来对这个资源的引用都应该使用新的 URI。
302:
- 302 状态码表示目标资源临时移动到了另一个 URI 上。由于重定向是临时发生的,所以客户端在之后的请求中还应该使用原本的 URI。
- 由于历史原因,用户代理可能会在重定向后的请求中把 POST 方法改为 GET方法。如果不想这样,应该使用 307(Temporary Redirect) 状态码
303:
- 303 状态码表示服务器要将浏览器重定向到另一个资源。从语义上讲,重定向到的资源并不是你所请求的资源,而是对你所请求资源的一些描述。
- 比如303 常用于将 POST 请求重定向到 GET 请求,比如你上传了一份个人信息,服务器发回一个 303 响应,将你导向一个"上传成功"页面。
307:
- 307 的定义实际上和 302 是一致的,唯一的区别在于,307 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上。
308:
- 308 的定义实际上和 301 是一致的,唯一的区别在于,308 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上。
11. http状态码中,( )表示访问成功,( )表示坏请求,( )表示服务不可用。()
A.2xx, 4xx, 5xx
B.1xx, 4xx, 3xx
C.2xx, 4xx, 3xx
D.3xx, 1xx, 4xx
答案:A
答案解析
1xx:信息状态码,接受到请求正在处理
2xx : 成功状态码,请求正常处理完毕
3xx : 重定向状态码,需要进行附加操作来完成请求
4xx : 客户端错误状态码,服务器无法处理请求
5xx : 服务器错误状态码,服务器处理请求出错
12. HTTP CODE中403代表什么含义?()
A.服务器当前无法处理请求
B.服务器不能或者不会处理该请求
C.服务器收到该请求但是拒绝提供服务
D.服务器无法回应且不知原因
答案:C
答案解析
403:服务器拒绝接收到请求但拒绝提供服务,原因较多,比如权限不足,IP被拉入黑名单.....
13. 如何在响应报文头部去设置字符编码()
A.Content-Type: charset=utf-8
B.Content-language: charset=utf-8
C.Content-Type: charset=UTF-8
D.Content-language: charset=UTF-8
答案:AC
答案解析
Content - Type:用于告诉客户实际返回的内容的内容类型或者说编码类型,比如 Content - Type: text / html; charset = utf - 8 用于表示正文是 text / html文档类型,字符集为utf - 8
Content - Language:用于表示用户希望采用的语言或语言组合,比如 Content - Language: de - DE 表示该文件为说德语的人提供,但是要注意者不代表文件内容就是德语的。
这里理解 Content - Type 和 Content - Language 区别: Content - Language更多表示上层语言的表示, 而Content - Type用于底层数据编码的表示
因此在响应报文头部设置字符编码是在Content - Type中设置charset属性,大小写不敏感,正确选项为 AC选项
14. 【多选题】标准的http请求报文头中,以下哪个说法是正确的()
A.User-Agent: 声明用户的操作系统和浏览器版本信息
B.Content-Type: 正文数据类型,用于告知对端正文的编码类型及处理方式
C.Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
D.location: 搭配3xx状态码使用, 实现重定向,告诉客户端接下来要去哪里访问
答案:ABCD
这道题的选项都是正确的,选项内容既是每个头部字段的基本解释。
15. 标准的http响应报文中,以下哪个说法是错误的()
A.可以从响应的头部首行中查看状态码以及状态码的解释
B.响应报文中是不存在Header的,只有请求的时候才会有
C.如果存在Body则可以查看Content-Length来去确定Body的长度
D.响应报文中的Body中可以返回任意长度的内容
答案:B
答案解析:
A正确:响应首行元素包含协议版本,响应状态码, 状态码描述
B错误:不论是请求还是响应报文,都是存在Header的
C正确:头部字段中的Content - Length属性用于存储正文的长度
D正确:HTTP协议对正文大小并不做长度限制要求
16. 以下 HTTP 请求里,不带有 HTTP Body 的请求有?()
A.HTTP DELETE
B.HTTP GET
C.HTTP POST
D.HTTP HEAD
答案:B
答案解析
GET请求中是不带有HTTP body的,get方式在url后面拼接参数,只能以文本的形式传递参数
17. 如果没有为Cookie指定失效时间,则设置的Cookie将在何时失效?( )
A.关机时
B.下次访问该网站时
C.结束当前会话时
D.访问另一个网站时
答案:C
答案解析
Cookie的Expires属性指定了cookie的生存期,默认情况下coolie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max - age属性所取代,max - age用秒来设置cookie的生存期
因此当没有设定过期时间时,则退出当前会话时cookie失效,正确选项为:C
18. 【多选题】cookie安全机制,cookie有哪些设置可以提高安全性?()
A.指定cookie domain的子域名
B.httponly设置
C.cookie secure设置,保证cookie在https层面传输
D.都不对
答案:ABC
答案分析:
domain:可以访问该Cookie的域名。如果设置为".google.com",则所有以"google.com"结尾的域名都可以访问该Cookie。注意第一个字符必须为"."。
path:Cookie的使用路径。如果设置为" / sessionWeb / ",则只有contextPath为" / sessionWeb"的程序可以访问该Cookie。如果设置为" / ",则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为" / "。
httponly:如果cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击,窃取cookie内容,这样就增加了cookie的安全性, 但不是绝对防止了攻击
secure:该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。
expires : 指定了coolie的生存期,默认情况下cookie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max - age属性所取代,max - age用秒来设置cookie的生存期
bash
Set-Cookie: qwerty=219ffwef9w0f; Domain=somecompany.co.uk; Path=/; Expires=Wed, 30 Aug 2019 00:00:00 GMT- 对保存到cookie里面的敏感信息加密
- 设置指定的访问域名
- 设置HttpOnly为true
- 设置Secure为true
- 给Cookie设置有效期
- 给Cookies加个时间戳和IP戳,实际就是让Cookies在同个IP下多少时间内失效
基于以上理解,正确选项为:ABC
19. 【多选题】cookie有什么用?()
A.记录用户的ID
B.记录用户的密码
C.记录用户浏览过的商品记录
D.记录用户的浏览器设置
答案:ABC
答案解析
cookie是一种保存在客户端的小型文本文件,用于保存服务器通过Set - Cookie字段返回的数据,在下次请求服务器时通过Cookie字段将内容发送给服务器。是HTTP进行客户端通信状态维护的一种方式。
cookie的可以记录用户的ID,记录用户的密码,记录用户浏览过的商品记录。但是无法记录用户的浏览器设置(浏览器设置属于浏览器,而并不属于某次请求的信息)
因此正确选项为:ABC选项
20. 【多选题】cookie的基础属性有哪些?()
A.Domain
B.path
C.httponly
D.secure
E.expires
答案:ABCDE
答案解析
- domain:可以访问该Cookie的域名。如果设置为".google.com",则所有以"google.com"结尾的域名都可以访问该Cookie。注意第一个字符必须为"."。
- path:Cookie的使用路径。如果设置为" / sessionWeb / ",则只有contextPath为" / sessionWeb"的程序可以访问该Cookie。如果设置为" / ",则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为" / "。
- httponly:如果cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击,窃取cookie内容,这样就增加了cookie的安全性, 但不是绝对防止了攻击
- secure:该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。
- expires : 指定了coolie的生存期,默认情况下cookie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max - age属性所取代,max - age用秒来设置cookie的生存期
bash
Set-Cookie: qwerty=219ffwef9w0f; Domain=somecompany.co.uk; Path=/; Expires=Wed, 30 Aug 2019 00:00:00 GMT选项中的所有选项都是cookie中的选项字段,因此全部正确。
21. 下面有关Cookie的说法,错误的是()
A.Cookie不是只有一个
B.Cookie总是保存在客户端中,按在客户端中的存储位置,可分为内存Cookie和硬盘Cookie
C.在HTTP请求中的Cookie是密文传递的
D.有一些Cookie在用户退出会话的时候就被删除了,这样可以有效保护个人隐私
答案:C
答案解析:
cookie是一种保存在客户端的小型文本文件,用于保存服务器通过Set - Cookie字段返回的数据,在下次请求服务器时通过Cookie字段将内容发送给服务器。是HTTP进行客户端状态维护的一种方式
而Set - Cookie以及Cookie字段可以包含有多条信息,也可以由多个Cookie及 - Set - Cookie字段进行传输多条信息
并且cookie有生命周期,在超过生命周期后cookie将失效,对应的cookie文件将被删除。
C错误:HTTP的cookie是明文传送的,HTTPS是HTTP的加密传输,因此HTTPS的cooike是才密文传送的
22. 关于cookie和session描述错误的是()
A.cookie保存在客户端浏览器中,而session保存在服务器上
B.cookie和session都是用来保存状态信息,都是保存客户端状态的机制,它们都是为了解决HTTP无状态的问题而所做的努力
C.session是有有效期的,而cookie则没有有效期
D.如果浏览器禁用了cookie,session机制不会失效
答案:C
答案解析
C错误:session默认有效期是30分钟,Cookie没有设置expires属性,那么 cookie 的生命周期只是在当前的会话中,关闭浏览器意味着这次会话的结束,此时 cookie 随之失效
D正确:一般情况下Session是通过Cookie传递Session_ID实现的,禁用cookie则session就没法用了,但是劳动人民智慧是无穷的,可以将SESSION_ID附着在URL中来实现,也就是session并不一定完全依赖于cookie实现,因此D选项是正确的。
23. 【多选题】cookie 和 session 的区别描述正确的是()
A.cookie数据存放在客户的浏览器上,session数据放在服务器
B.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
C.session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
D.单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie
答案:ABCD
cookie是一种保存在客户端的小型文本文件,用于保存服务器通过Set - Cookie字段返回的数据,在下次请求服务器时通过Cookie字段将内容发送给服务器。是HTTP进行客户端状态维护的一种方式
但是cookie存在一定的缺陷:比如有大小限制,通常不能超过4k,以及cookie不断的传递客户端的隐私信息,存在一定的安全隐患(比如认为篡改),因此有了session管理
session服务器为了保存用户状态而创建的临时会话,或者说一个特殊的对象,保存在服务器中,将会话ID通过cookie进行传输即可,就算会话ID被获取利用,但是session中的数据并不会被恶意程序获取,这一点相对cookie来说就安全了一些,但是session也存在一些缺陷,需要建立专门的session集群服务器,并且占据大量的存储空间(要保存每个客户端信息)
基于以上理解,四个选项都是正确的。
24. 关于Session对象的属性,下列说法正确的是( )
A.Session的有效期时长默认为90秒,且不能修改
B.Session的有效期时长默认为20分钟,且不能修改
C.SessionID可以存储每个用户Session的代号,是一个不重复的长整型数字
D.以上全都错
答案:C
答案解析:
A和B错误:一般session的有效期默认是30分钟
C正确:session_id是session的代号或者说唯一标识,通常是不重复的整数,但是其实是否用整数倒是无所谓,主要是唯一且要方便使用
25. 下列关于Session的描述中,错误的是()
A.Session存放于服务端
B.默认情况下,Session依赖于Cookie
C.Session中只能存放字符串,不能存放其他类型的数据
D.在分布式架构中,存在Session共享的问题
答案:C
答案解析
cookie是一种保存在客户端的小型文本文件,用于保存服务器通过Set - Cookie字段返回的数据,在下次请求服务器时通过Cookie字段将内容发送给服务器。是HTTP进行客户端状态维护的一种方式
但是cookie不断的传递客户端的隐私信息,存在一定的安全隐患(比如认为篡改),因此有了session管理
session服务器为了保存用户状态而创建的临时会话,或者说一个特殊的对象,保存在服务器中,将会话ID通过cookie进行传输即可,就算会话ID被获取利用,但是session中的数据并不会被恶意程序获取,这一点相对cookie来说就安全了一些,但是session也存在一些缺陷,需要建立专门的session集群服务器,并且占据大量的存储空间(要保存每个客户端信息)
C错误:Session可以存放各种类别的数据,相比只能存储字符串的cookie,能给开发人员存储数据提供很大的便利
26. 关于Session的描述中,错误的是()
A.Session存储在服务端
B.大量的Session会对服务端内存造成压力
C.Session可以在多个服务器之间共享
D.通常下cookie比Session安全
答案:D
答案解析
cookie是一种保存在客户端的小型文本文件,用于保存服务器通过Set - Cookie字段返回的数据,在下次请求服务器时通过Cookie字段将内容发送给服务器。是HTTP进行客户端状态维护的一种方式
但是cookie存在一定的缺陷:比如有大小限制,以及cookie不断的传递客户端的隐私信息,存在一定的安全隐患(比如认为篡改),因此有了session管理
session服务器为了保存用户状态而创建的临时会话,或者说一个特殊的对象,保存在服务器中,将会话ID通过cookie进行传输即可,就算会话ID被获取利用,但是session中的数据并不会被恶意程序获取,这一点相对cookie来说就安全了一些,但是session也存在一些缺陷,需要建立专门的session集群服务器,并且占据大量的存储空间(要保存每个客户端信息)
基于以上理解,ABC选项都是正确的理解,而题目为选择错误选项,因此选择:D,session比cookie安全。
27. 关于http和https描述错误的是()
A.HTTPS是加密传输协议,HTTP是明文件传输协议
B.HTTPS需要用到SSL证书,而HTTP不需要
C.HTTPS标准端口是80,HTTP标准端口是445
D.HTTPS的安全基础是TLS/SSL
答案:C
答案解析:
HTTP协议是一种以字符串明文传输的简单的请求 - 响应协议(HTTP协议无状态,一次请求 - 响应就会结束通信),在传输层基于TCP协议实现。HTTP协议默认使用80端口
HTTPS协议是一种对HTTP加密后的协议(这里的加密采用SSL加密),主要是多了身份验证以及加密传输等功能,HTTPS协议默认使用443端口
A正确
B正确:SSL中的身份验证通过CA签名认证实现(权威机构颁发的CA证书)
C错误:HTTP是80端口,HTTPS是443端口
D正确:HTTPS就是基于TLS / SSL加密保证安全传输的
28. 以下关于http和https说法不正确的是()
A.http协议通常使用80端口
B.https协议通常使用445端口
C.http协议是无状态的
D.https在http的基础上增加ssl层
答案:B
答案解析
HTTP协议是一种以字符串明文传输的简单的请求 - 响应协议(HTTP协议无状态,一次请求 - 响应就会结束通信),在传输层基于TCP协议实现。HTTP协议默认使用80端口
HTTPS协议是一种对HTTP加密后的协议,主要是多了身份验证以及加密传输等功能(这里的加密采用SSL加密),HTTPS协议默认使用443端口
基于以上理解,错误的选项为:B
29. 【多选题】以下关于http和https说法正确的是()
A.http是超文本传输协议
B.https是超文本传输安全协议
C.http是明文传输
D.https是加密传输
答案:ABCD
HTTP协议是一种以字符串明文传输的简单的请求 - 响应协议,在传输层基于TCP协议实现。HTTP协议默认使用80端口
HTTPS协议是一种对HTTP加密后的协议,主要是多了身份验证以及加密传输等功能,HTTPS协议默认使用443端口
基于以上理解,所有选项都是正确的。