Docker核心技术和实现原理第二部分:docker镜像与网络原理
- 一.docker镜像原理
-
- [1.1Union FS(联合文件系统)](#1.1Union FS(联合文件系统))
- [1.2Union FS 的原理](#1.2Union FS 的原理)
- [1.4 分层存储的实现方式(即对联合文件系统的具体实现)](#1.4 分层存储的实现方式(即对联合文件系统的具体实现))
- [1.5 overlay2的实现原理(重点)](#1.5 overlay2的实现原理(重点))
- 1.6docker镜像是什么
- 1.7docker镜像加载原理
- 1.8验证镜像的分层存储(重点)
- 1.9实际操作认识下overlay2的分层文件系统
- 二.docker网络底层原理
-
- [2.1Linux 常见网络虚拟化](#2.1Linux 常见网络虚拟化)
- 2.2实操认识linux中的虚拟网卡tun/tap
- 2.3linux中的虚拟网卡veth
- 2.4实操认识下linux中的veth虚拟网卡
- 2.5虚拟交换机
- 2.6实操认识下linux中的虚拟交换机(网桥)
- [2.7虚拟组网 VxLan](#2.7虚拟组网 VxLan)
- [2.8 MACVLan](#2.8 MACVLan)
- [2.9 IPVLan](#2.9 IPVLan)
- 三.docker网络
-
- 3.1docker网络分类
- [3.2对docker bridge网络的进一步理解](#3.2对docker bridge网络的进一步理解)
一.docker镜像原理
docker 是操作系统层的虚拟化,所以 docker 镜像的本质是在模拟操作系统。我们先看下操作系统是什么。
操作系统由:进程调度子系统、进程通信子系统、内存管理子系统、设备管理子系统、文件管理子系统、网络通信子系统、作业控制子系统组成。
Linux 的文件管理子系统由 bootfs 和 rootfs 组成。
bootfs:要包含 bootloader 和 kernel, bootloader 主要是引导加载 kernel, Linux 刚启动时会加载 bootfs 文件系统,在 Docker 镜像的最底层是引导文件系统 bootfs。这一层与我们典型的 Linux/Unix 系统是一样的,包含 boot 加载器和内核。当 boot 加载完成之后整个内核就都在内存中了,此时内存的使用权已由 bootfs 转交给内核,此时系统也会卸载 bootfs。rootfs: 在 bootfs 之上。包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。 rootfs 就是各种不同的操作系统发行版,比如 Ubuntu, Centos 等等。
1.1Union FS(联合文件系统)
UnionFS(联合文件系统)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。 UnionFS 是一种为 Linux, FreeBSD 和 NetBSD 操作系统设计的把其他文件系统联合到一个联合挂载点的文件系统服务。它使用 branch 把不同文件系统的文件和目录"透明地"覆盖,形成一个单一一致的文件系统。这些 branches 或者是read-only 或者是 read-write 的,所以当对这个虚拟后的联合文件系统进行写操作的时候,系统是真正写到了一个新的文件中。看起来这个虚拟后的联合文件系统是可以对任何文件进行操作的,但是其实它并没有改变原来的文件,这是因为 unionfs 用到了一个重要的资管管理技术叫写时复制。
写时复制(copy-on-write,下文简称 CoW),也叫隐式共享,是一种对可修改资源实现高效复制资源管理技术。它的思想是,如果一个资源是重复的,但没有任何修改,这时候并不需要立即创建一个新的资源;这个资源可以被新旧实例共享。创建新资源发生在第一次写操作,也就是对资源进行修改的时候。通过这种资源共享的方式,可以显著地减少未修改资源复制带来的消耗, 但是也会在进行资源修改的时候增加小部分的开销。
这个我们当时学习进程间通信的时候其实就已经不陌生了。
1.2Union FS 的原理
docker 镜像由多个只读层叠加面成,启动容器时, docker 会加载只读镜像层并在镜像栈顶部加一个读写层;
如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件版本仍然存在,只是已经被读写层中该文件的副本所隐藏 ,此即写时复制(COW)机制。
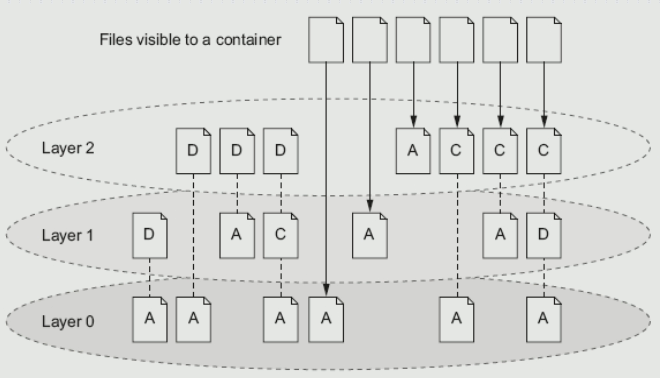
这张图中A表示ADD,D表示Delete,C表示Change。为什么最后六个文件能被layer2看到,我们从左往右进行分析。第一个,虽然文件在0层存在,但是第一层时被删除了,第2层就看不到了。第二个,第二层进行了删除自然看不到怕。第三个,第四个也是。第五个是可以看到的因为从0-2层没有发生任何变化。第六个从1-2层没有变化也可以,第七个是在第二层新增的,也可以看到。但是第八个,虽然能够看到第一层ADD的文件,但是实际上因为它修改了,发生了写时拷贝,所以此时在第二层看到的是0层文件的一个副本。后面两个文件也同理。
1.4 分层存储的实现方式(即对联合文件系统的具体实现)
docker 镜像技术的基础是联合文件系统(UnionFS),其文件系统是分层的
目前 docker 支持的联合文件系统有很多种,包括: AUFS、 overlay、 overlay2、DeviceMapper、 VSF 等
Linux 中各发行版实现的 UnionFS 各不相同,所以 docker 在不同 linux 发行版中使用的也不同。通过 docker info 命令可以查看当前系统所使用哪种 UnionFS,常见的几种发行版使用如下:
CentOS, Storage Driver: overlay2、 overlay
debain, Storage Driver: aufs
RedHat, Storage Driver: devicemapper
overlay2 是 overlay 的升级版,docker官方推荐,更加稳定,而新版的 docker 默认也是这个驱动, linux 的内核 4.0 以上或者或使用 3.10.0-514 或更高版本内核的 RHEL 或CentOS。
1.5 overlay2的实现原理(重点)
架构
OverlayFS 将单个 Linux 主机上的两个目录合并成一个目录。这些目录被称为层,统一过程被称为联合挂载 OverlayFS 底层目录称为 lowerdir, 高层目录称为upperdir,合并统一视图称为 merged
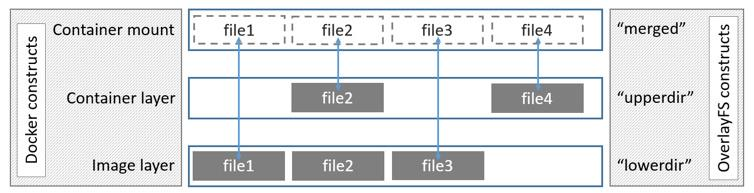
图中可以看到三个层结构,即 lowerdir、 upperdir、 merged 层
分层
lowerdir层
其中 lowerdir 是只读的镜像层(image layer),其中就包含 bootfs/rootfs 层,bootfs(boot file system)主要包含 bootloader 和 kernel, bootloader 主要是引导加载kernel,当 boot 成功 kernel 被加载到内存中, bootfs 就被 umount 了, rootfs(root filesystem)包含的就是典型 Linux 系统中的/dev、 /proc、 /bin、 /etc 等标准目录。
lowerdir 是可以分很多层的,除了 bootfs/rootfs 层以外,还可以通过 Dockerfile 建立很多 image 层upperdir层
upper 是容器的读写层,采用了 CoW(写时复制)机制,只有对文件进行修改才会将文件拷贝到 upper 层,之后所有的修改操作都会对 upper 层的副本进行修改。 upperdir 层是lowerdir 的上一层,只有这一层可读可写的,其实就是 Container 层,在启动一个容器的时候会在最后的 image 层的上一层自动创建,所有对容器数据的更改都会发生在这一层。workdir层
它的作用是充当一个中间层的作用 ,每当对 upper 层里面的副本进行修改时,会先当到workdir,然后再从 workdir 移动 upper 层merged层
是一个统一图层,从 mergedir 可以看到 lower,upper,workdir 中所有数据的整合,整个容器展现出来的就是 mergedir 层.merged 层就是联合挂载层,也就是给用户暴露的统一视觉,将 image 层和 container 层结合,就如最上边的图中描述一致,同一文件,在此层会展示离它最近的层级里的文件内容,或者可以理解为,只要 container 层中有此文件,便展示 container 层中的文件内容,若 container 层中没有,则展示image 层中的。
如何完成读写
- 读 :
如果文件在 upperdir(容器)层,直接读取文件;
如果文件不在 upperdir(容器)层,则从镜像层(lowerdir)读取; - 写 :
首次写入 :如果 upperdir 中不存在, overlay 和 overlay2 执行 copy_up 操作,把文件从 lowdir 拷贝到 upperdir 中,由于 overlayfs 是文件级别的(即使只有很少的一点修改,也会产生 copy_up 的动作),后续对同一文件的再次写入操作将对已经复制到容器层的文件副本进行修改,这也就是常常说的写时复制(copy-on-write)。
删除文件或目录 :当文件被删除时,在容器层(upperdir)创建 whiteout 文件,镜像层(lowerdir)的文件是不会被删除的,因为它们是只读的,但whiteout 文件会阻止它们显示,当目录被删除时,在容器层(upperdir)一个不透明的目录,这个和上边的 whiteout的原理一样,组织用户继续访问, image 层不会发生改变。 - 注意事项
copy_up 操作只发生在文件首次写入,以后都是只修改副本。容器层的文件删除只是一个"障眼法",是靠 whiteout 文件将其遮挡,image 层并没有删除,这也就是为什么使用 docker commit 提交保存的镜像会越来越大,无论在容器层怎么删除数据, image 层都不会改变。
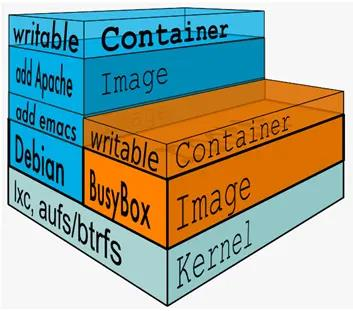
1.6docker镜像是什么
image 里面是一层层文件系统 Union FS。联合文件系统,可以将几层目录挂载到一起,形成一个虚拟文件系统。虚拟文件系统的目录结构就像普通 linux 的目录结构一样, docker 通过这些文件再加上宿主机的内核提供了一个 linux 的虚拟环境。每一层文件系统我们叫做一层 layer,联合文件系统可以对每一层文件系统设置三种权限,只读(readonly)、读写(readwrite)和写出(whiteout-able),但是 docker镜像中每一层文件系统都是只读的。
构建镜像的时候,从一个最基本的操作系统开始,每个构建的操作都相当于做一层的修改,增加了一层文件系统。一层层往上叠加,上层的修改会覆盖底层该位置的可见性,这也很容易理解,就像上层把底层遮住了一样。当你使用的时候,你只会看到一个完全的整体,你不知道里面有几层,也不清楚每一层所做的修改是什么。
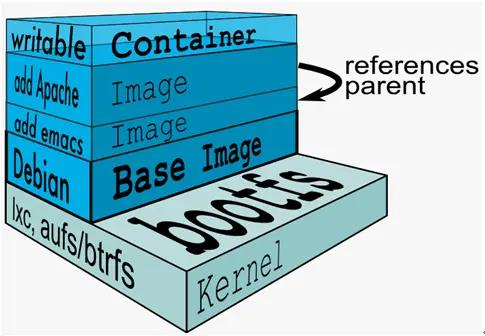
镜像共享宿主机的 kernel(内核)- base 镜像是 linux 的最小发行版
- 同一个 docker 主机支持不同的 Linux 发行版
- 采用分层结构,可以上层引用下层,最大化的共享资源
- 容器层位于可写层,采用 cow 技术进行修改,该层仅仅保持变化的部分,并不修改镜像下面的部分
- 容器层以下都是只读层
- docker 从上到下找文件
1.7docker镜像加载原理
我们先来看下操作系统的文件系统是如何进行加载的:
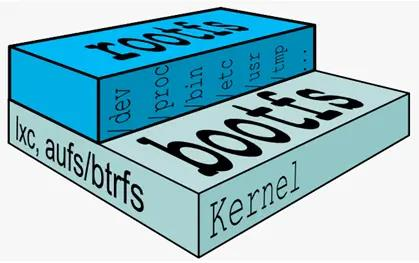
boots(boot file system)主要包含 bootloader 和 Kernel, bootloader 主要是引导加kernel,Linux 刚启动时会加 bootfs 文件系统,在 Docker 镜像的最底层是 bootfs。这一层与我们典型的 Linux/Unix 系统是一样的,包含 boot 加載器和内核。当 boot 加载完成之后整个内核就都在内存中了,此时内存的使用权已由 bootfs 转交给内核,此时系统也会卸载 bootfs。
rootfs(root file system),在 bootfs 之上。包含的就是典型 Linux 系统中的/dev,/proc,/bin,/etc 等标准目录和文件。 rootfs 就是各种不同的操作系统发行版,比如Ubuntu,Centos 等等。
典型的 Linux 在启动后,首先将 rootfs 置为 readonly, 进行一系列检查, 然后将其切换为 "readwrite" 供用户使用。
在 docker 中,起初也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的将一个 readwrite 文件系统挂载在 readonly 的rootfs 之上,并且允许再次将下层的 file system 设定为 readonly 并且向上叠加, 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行目录, 每一个被称作一个 Layer
下面的这张图片非常好的展示了组装的过程,每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
我们来进行下实验具体的来认识下docker的镜像:
1.8验证镜像的分层存储(重点)
实验目的,验证:每个中间镜像对应的目录下的link 和 lower 完成层与层之间链接关系配置, diff 存放了我们中间镜像的实际内容。
tree命令
Linux tree 命令用于以树状图列出目录的内容。
执行 tree 指令,它会列出指定目录下的所有文件,包括子目录里的文件。
安装(ubuntu):
bash
sudo apt install tree -y使用方式
bash
tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式>][目录...]常用参数:
- -a 显示所有文件和目录。
- -d 显示目录名称而非内容。
- -D 列出文件或目录的更改时间。
- -f 在每个文件或目录之前,显示完整的相对路径名称。
- -i 不以阶梯状列出文件或目录名称。
- -L level 限制目录显示层级。
- -l 如遇到性质为符号连接的目录,直接列出该连接所指向的原始目录。
- -P<范本样式> 只显示符合范本样式的文件或目录名称。
具体验证过程
我们以nginx:1.29.4的镜像为例子,先用docker history看看此镜像的具体分层结构:
bash
IMAGE CREATED CREATED BY SIZE COMMENT
ca871a86d45a 7 days ago CMD ["nginx" "-g" "daemon off;"] 0B buildkit.dockerfile.v0
<missing> 7 days ago STOPSIGNAL SIGQUIT 0B buildkit.dockerfile.v0
<missing> 7 days ago EXPOSE map[80/tcp:{}] 0B buildkit.dockerfile.v0
<missing> 7 days ago ENTRYPOINT ["/docker-entrypoint.sh"] 0B buildkit.dockerfile.v0
<missing> 7 days ago COPY 30-tune-worker-processes.sh /docker-ent... 16.4kB buildkit.dockerfile.v0
<missing> 7 days ago COPY 20-envsubst-on-templates.sh /docker-ent... 12.3kB buildkit.dockerfile.v0
<missing> 7 days ago COPY 15-local-resolvers.envsh /docker-entryp... 12.3kB buildkit.dockerfile.v0
<missing> 7 days ago COPY 10-listen-on-ipv6-by-default.sh /docker... 12.3kB buildkit.dockerfile.v0
<missing> 7 days ago COPY docker-entrypoint.sh / # buildkit 8.19kB buildkit.dockerfile.v0
<missing> 7 days ago RUN /bin/sh -c set -x && groupadd --syst... 77.7MB buildkit.dockerfile.v0
<missing> 7 days ago ENV DYNPKG_RELEASE=1~trixie 0B buildkit.dockerfile.v0
<missing> 7 days ago ENV PKG_RELEASE=1~trixie 0B buildkit.dockerfile.v0
<missing> 7 days ago ENV NJS_RELEASE=1~trixie 0B buildkit.dockerfile.v0
<missing> 7 days ago ENV NJS_VERSION=0.9.4 0B buildkit.dockerfile.v0
<missing> 7 days ago ENV NGINX_VERSION=1.29.4 0B buildkit.dockerfile.v0
<missing> 7 days ago LABEL maintainer=NGINX Docker Maintainers <d... 0B buildkit.dockerfile.v0
<missing> 8 days ago # debian.sh --arch 'amd64' out/ 'trixie' '@1... 87.4MB debuerreotype 0.17并不是所有的层都占空间,我们从上面的size一栏能看到。占空间的层主要是发生了COPY,RUN,和基准系统镜像。
而因为具有实际大小的层只有size不为0的层,所以从这个history里我们可以预测下面我们看的时候lowerDir应该是7个目录(如果有连续的 COPY 指令且目标上下文相似,现代的构建器(特别是开启了 BuildKit 时)有时会将它们合并进同一个物理层(Layer Blob)以减少层数开销,所以实际上LowerDir显示的目录数应该小于等于7 )。不过RootFS显示的一定有7个哈希值,这 7 个哈希值(Layer 1 到 Layer 7)是构建 Nginx 镜像所需的 所有物理只读层。
inspect可以进行镜像位置的具体查看,可以看到我使用的docker26.1.3使用的联合文件系统是overlay2(容器没有运行的时候,MergedDir是不存在的):
bash
...
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/5a2fcea06daf59669097e50207e9530bf7dbe6ae2987954230fa53eebfc589b1/diff:/var/lib/docker/overlay2/08b19367f6521c051a16a49256806116defa24c752b3a293bc28b2faa359a574/diff:/var/lib/docker/overlay2/16d30974845e07bf8b0020d49212d290bc30c5e86070aec80149cd765ac43d07/diff:/var/lib/docker/overlay2/d27f9538b5c3b2d75a9474a98a431c6dcc776bd800d622860326e56d65e9ec83/diff:/var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff:/var/lib/docker/overlay2/ec14c9bae8f14afd37f67c6cd73cd6b17c592ae7054b4cb74404a2102f03068a/diff",
"MergedDir": "/var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/merged",
"UpperDir": "/var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/diff",
"WorkDir": "/var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/work"
},
"Name": "overlay2"
},
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:77a2b55fbe8b9984ce0af3ffc0b0ab62507668e63306ec161a585e587a3eb164",
"sha256:20cf308e6957f546aeb5c3358b908dde65f85d4c3e321a1306bfb2a5002b0147",
"sha256:69f56ce8c461dc57973b448f1a17aacfa5bc674b8e23f709d58b5fd2a7e6e6f8",
"sha256:6898c33749d555cdd3df4ba0279a08a58e3b8faaa80bcf76ca71f35ed87e5e0b",
"sha256:6e32bc56a7253358b6292d5b9e9d473397818ccebaec6edd88d20c7ab508fa4e",
"sha256:08ba9962589fcdea2592d16bf47a4c299711e9e394b90bf11a830f3b9c9fa580",
"sha256:8921786c2de3800947893b21f0585eeabc26f7f5a486de5d0ee085596d16d0cc"
]
},额外插一嘴,如果你使用docker info看到了如下内容:
bash
Storage Driver: overlayfs
driver-type: io.containerd.snapshotter.v1
...上面的GraphDriver是查不到的。
但是如果是如下内容是可以查到的:
bash
Storage Driver: overlay2
....在 Docker 29.x 中,存储架构已从传统的 Docker GraphDriver(如 overlay2) 全面迁移到 containerd 的 snapshotter 模型 ,overlayfs 仅表示底层使用的 Linux 内核文件系统类型,而真正负责镜像层和容器可写层管理的是 io.containerd.snapshotter.v1;在这种架构下,镜像本身不再对应固定的 overlay2 目录,容器的联合挂载也不由 Docker 直接维护,因此 GraphDriver 这一概念在 Docker API 层已被弃用并不再暴露 ,导致在 Docker 29.1.3 中无论是镜像还是容器,使用 docker inspect 都无法看到 GraphDriver 信息,这一变化是 Docker 有意的架构升级结果,而非配置错误或异常行为。
好打住继续我们的验证,我们发现 docker history 中有 7 个 大小不为 0 的层(包括 Base, RUN 和 5 个 COPY),这对应了 RootFS 中的 7 个 哈希值。
在 docker inspect 的 GraphDriver 数据中,我们看到 LowerDir 包含 6 个 目录。这并不是因为 RUN 层被优化掉了(因为 RUN 层有 77.7MB,是真实存在的),而是因为 Overlay2 的分层结构逻辑: LowerDir 列出的是当前最顶层(第 7 层)之下的所有父层(共 6 层)。 第 7 层本身的差异存储在 DiffDir 中(或作为挂载时的 UpperDir)。因此,6 个 LowerDir + 1 个顶层 = 7 个物理层,与 History 完全吻合。
这也说明一个问题:
Docker 版本 (26.1.3) 并没有将这个nginx镜像视为最终只读对象,而是将其顶层的元数据以一种类似于容器可写层的方式来展现。
UpperDir (0729...):在这个上下文中,它不是容器可写层(L8)。它很可能指向 Layer 7 的 Diff 目录。
LowerDir:指向 Layer 1 到 Layer 6 的目录链(6 个目录)。
MergedDir:这只是一个预先计算出的路径,表示如果将 LowerDir 和 UpperDir (L1-L6 + L7) 合并后,最终的视图路径会是什么。
停下这个话题,这里我们还无法验证问题是不是如我们所想的那样,我们可以看看MergedDir此时是否存在(容器没有启动是肯定不存在的):
bash
ena@NightCode:~$ sudo tree /var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/merged
/var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/merged [error opening dir]是不存在的此时。
我们来找下/docker-entrypoint.sh这个文件,它在history中是被COPY到容器中的,所以是镜像层的文件,也就是在LowerDir文件夹下,我们来验证下。
bash
ena@NightCode:~$ sudo tree -P "docker-entrypoint.sh" /var/lib/docker/overlay2/ -f | grep "docker-entrypoint.sh"
│ │ └── /var/lib/docker/overlay2/d27f9538b5c3b2d75a9474a98a431c6dcc776bd800d622860326e56d65e9ec83/diff/docker-entrypoint.sh可以看到它是可以与LowerDir的第4个是对的上的,因为本来这就是镜像层的文件,属于overlayer2系统的LowerDir层(:为LowerDir的分隔符)。
还记得nginx的可执行文件是默认放在...sbin/nginx目录下的吗,我们再来看看:
bash
ena@NightCode:~$ sudo tree -P "nginx" /var/lib/docker/overlay2/ -f | grep "nginx"
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/etc/default/nginx
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/etc/init.d/nginx
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/etc/logrotate.d/nginx
│ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/etc/nginx
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/etc/nginx/conf.d
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/lib/nginx
│ │ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/lib/nginx/modules
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/sbin/nginx
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/doc/nginx
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/doc/nginx-module-geoip
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/doc/nginx-module-image-filter
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/doc/nginx-module-njs
│ │ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/doc/nginx-module-xslt
│ │ │ ├── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/nginx
│ │ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/usr/share/nginx/html
│ │ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/var/cache/nginx
│ │ └── /var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/var/log/nginx是在lowerDir的第五个目录底下。
查看内容我们确定并没有什么加密之类的,也就是是镜像的文件分层后放到了 diff 目录下面。
接下来我们进入上面查到的目录的 diff 的上一级目录看看,可以看到 link 文件,里面是每一个 diff 目录的短名称,或者说软链接。
bash
root@NightCode:/var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d# ls
committed diff link lower work
root@NightCode:/var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d# cat ./link
RELRBDZ2YRF3SKDBFG2G7DCJNXroot
root@NightCode:/var/lib/docker/overlay2/ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d# cd ..
root@NightCode:/var/lib/docker/overlay2# ll ./l/RELRBDZ2YRF3SKDBFG2G7DCJNX
lrwxrwxrwx 1 root root 72 Dec 21 18:33 ./l/RELRBDZ2YRF3SKDBFG2G7DCJNX -> ../ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/可以看到overlay2目录下也保存了一个指向ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d目录下的diff目录的一个软连接。
通过遍历 l 目录我们会发现,整个 docker 的镜像的 diff 目录都被做了对应的软链接,或者说起了个短名称。
bash
root@NightCode:/var/lib/docker/overlay2# ll l
total 84
drwx------ 2 root root 4096 Dec 22 01:14 ./
drwx--x--- 22 root root 4096 Dec 22 01:14 ../
lrwxrwxrwx 1 root root 72 Dec 22 01:14 5EE73GQM6LVUTDVBP3TQNTZ52V -> ../e6b876dfc1f53a98e67379ce9b38c76fe4700a4b19ee5f413c8d801de2e102ee/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 6IUT6PFZ46U3OFJE22D5TZECXU -> ../5a2fcea06daf59669097e50207e9530bf7dbe6ae2987954230fa53eebfc589b1/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 7CHKYMW7FIRMBXSIJPZIPCJ3E2 -> ../d7177646627f274409757da130d73b79b5fc45680239c8cd9f66ef8b0ebfc0ed/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 7MWUWFIXOYRGYQRLHVXEOZ5HOZ -> ../d27f9538b5c3b2d75a9474a98a431c6dcc776bd800d622860326e56d65e9ec83/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 DMLRMWTAW7OPFSUWSMUO2YRBEG -> ../b7b20ad870876e5a3f25b2917bad597259f7deff16327c1d9459be9b6b224f16/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 ENFUZZ26S3EXZMSKMPKMEAQO5G -> ../ec14c9bae8f14afd37f67c6cd73cd6b17c592ae7054b4cb74404a2102f03068a/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 H6GYIXESRLGQKA75OUSQW5BQWC -> ../9f68432996202e7072dc99a4eb3028e4c03b2dba03c44ed364938fe3eb79cda8/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 MWYS55L4JN4FOOI742K62PB7QV -> ../e92be3deab58b01fef028b7a5b256d5f79d155330760861bd2abea15f320cc7e/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 NSV6JM7ZEDWFSQCIFMADBXTV27 -> ../b81e4efbb5ff16ab6a4bba4d056bc8ba7b9ee03fec4b88ef923bf82d5a0af9dd/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 PBX2ML6EYAW2GO77VESA4REZBP -> ../08b19367f6521c051a16a49256806116defa24c752b3a293bc28b2faa359a574/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 QZ6DTSMAGJMS55OVMRRIA6LHM4 -> ../6f8d1371eeb2532de446760723615f467ff9bd3bc3fc3a5a658f4835fa5015e9/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 R37DS666GGESJ5OJ3MI3OBZEKB -> ../16d30974845e07bf8b0020d49212d290bc30c5e86070aec80149cd765ac43d07/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 RBKDIWS2FUTLLHO7KOX6SNFDYF -> ../4aaf1783f0c83e5c2e669c2fe4d21a25bddf56b22de4c8c5cc8a5a128daaacea/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 RELRBDZ2YRF3SKDBFG2G7DCJNX -> ../ba728b0edbb01276df2daf2e73d125c1d07d61848d1c8793c7da776e6052d94d/diff/
lrwxrwxrwx 1 root root 72 Dec 21 18:33 S5QQQHZNO5XC76GDM55C6SARPD -> ../072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 SGXBODVSJJD6P2OD5OCUKGQIJ5 -> ../7a340fdf05d6e35f53eb1cfc5ec3ae695e711e6fc90b5e0ff1c3aeb4a311a9a6/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 WQ4CX2SHCMV4CUVVNNP5UEC5YK -> ../8404092d40c568443658275ffc32c3544385e5e548b81d2946db2b358de45645/diff/
lrwxrwxrwx 1 root root 72 Dec 22 01:14 WTLDZ6CK3SGHJQUISDO74S62FV -> ../55158577bf0144d67d7135e68de3abbd1246cd9ccd0ffc8598b74455cc981dcd/diff/
lrwxrwxrwx 1 root root 77 Dec 22 01:14 WUFHMKCIQBIKFF6ED5V75OQJFC -> ../9f68432996202e7072dc99a4eb3028e4c03b2dba03c44ed364938fe3eb79cda8-init/diff/每一个 diff 是一个层级的内容,层级的关系是存放到了 lower 文件中,里面存放着父级的层级。,我们可以验证下,看看LowerDir的第一层父层目录是不是第二个目录:
bash
root@NightCode:/var/lib/docker/overlay2# cat /var/lib/docker/overlay2/5a2fcea06daf59669097e50207e9530bf7dbe6ae2987954230fa53eebfc589b1/lower
l/PBX2ML6EYAW2GO77VESA4REZBP:l/R37DS666GGESJ5OJ3MI3OBZEKB:l/7MWUWFIXOYRGYQRLHVXEOZ5HOZ:l/RELRBDZ2YRF3SKDBFG2G7DCJNX:l/ENFUZZ26S3EXZMSKMPKMEAQO5G
root@NightCode:/var/lib/docker/overlay2# ll ./l/PBX2ML6EYAW2GO77VESA4REZBP
lrwxrwxrwx 1 root root 72 Dec 21 18:33 ./l/PBX2ML6EYAW2GO77VESA4REZBP -> ../08b19367f6521c051a16a49256806116defa24c752b3a293bc28b2faa359a574/diff/不仅验证了我们上面要验证的,还可以看到其其他的四个父层也显示了出来。
那这里我们再验证下UpperDir是不是就是我们说的缺失的那个LowerDir:
bash
root@NightCode:/var/lib/docker/overlay2# cat /var/lib/docker/overlay2/072962071fdd08a130c5e579427c82d8f5ee78eb17bad40d2c1e91930b60bb19/lower
l/6IUT6PFZ46U3OFJE22D5TZECXU:l/PBX2ML6EYAW2GO77VESA4REZBP:l/R37DS666GGESJ5OJ3MI3OBZEKB:l/7MWUWFIXOYRGYQRLHVXEOZ5HOZ:l/RELRBDZ2YRF3SKDBFG2G7DCJNX:l/ENFUZZ26S3EXZMSKMPKMEAQO5G是的,确实是丢失的第7个LowerDir,也就验证了我们上面的猜想。
总结
我们通过镜像实际存储位置可以看到镜像在存储的时候,通过分层来实现,并通过link 和 lower 完成层与层之间链接关系配置, diff 存放了我们的内容,并且没有什么加密。除此之外,我们还验证确认了 OverlayFS 的 LIFO (后进先出),堆栈结构 和 父级引用机制。
1.9实际操作认识下overlay2的分层文件系统
我们首先创建一个目录用来挂载我们的文件系统
bash
mkdir -p /data/myworkdir/fs我们创建文件系统的工作目录:
bash
cd /data/myworkdir/fs
mkdir upper lower merged work准备一些文件:
bash
echo "in lower" > lower/in_lower.txt
echo "in upper" > upper/in_upper.txt
echo "In both. from lower" > lower/in_both.txt
echo "In both. from upper" > upper/in_both.txt挂载 overlay 目录:
bash
root@139-159-150-152:/data/myworkdir/fs$ mount -t overlay overlay -o lowerdir=./lower,upperdir=./upper,workdir=./work ./merged通过 df -h 可以看到我们完成了挂载
bash
overlay 40G 20G 19G 52% /data/myworkdir/fs/merged我们此时看下目录结构,然后发现 merged 目录自动生成了 3 个文件,可以看到boteh,lower,upper 都在。 merged 目录其实就是用户看到的目录,用户的实际文件操作在这里进行。
bash
root@139-159-150-152:/data/myworkdir/fs# tree -a
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
└── work
└── workmerge 目录下编辑一下 in_lower.txt, upper 目录下就会马上出现一个 in_lower.txt,而且内容就是编辑后的。而 lower 目录下的 in_lower.txt 内容不变
bash
root@139-159-150-152:/data/myworkdir/fs# cd merged/
root@139-159-150-152:/data/myworkdir/fs/merged# vi in_lower.txt
#修改内容如下:
in lower! after edit!
root@139-159-150-152:/data/myworkdir/fs/merged# cat in_lower.txt
in lower! after edit!
#再次查看目录树,可以看到 in_lower.txt 在 upper 里面生成了,发生了
copy_up
root@139-159-150-152:/data/myworkdir/fs/merged# cd ..
root@139-159-150-152:/data/myworkdir/fs# tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt│
| ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
└── work
└── work
5 directories, 8 files
#查看文件内容,发现是编辑后的
root@139-159-150-152:/data/myworkdir/fs# cat upper/in_lower.txt
in lower! after edit!如果我们删除 in_lower.txt, lower 目录里的"in_lower.txt"文件不会有变化,只是在upper/ 目录中增加了一个特殊文件来告诉 OverlayFS, "in_lower.txt'这个文件不能出现在 merged/ 里了,类似 AuFS 的 whiteout
bash
root@139-159-150-152:/data/myworkdir/fs# rm -f merged/in_lower.txt
root@139-159-150-152:/data/myworkdir/fs# tree
../
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
└── work
└── work
root@139-159-150-152:/data/myworkdir/fs# ll upper/
total 16
drwxr-xr-x 2 root root 4096 Mar 16 10:39 ./
drwxr-xr-x 6 root root 4096 Mar 16 10:29 ../
-rw-r--r-- 1 root root 21 Mar 16 10:29 in_both.txt
c--------- 1 root root 0, 0 Mar 16 10:39 in_lower.txt
-rw-r--r-- 1 root root 10 Mar 16 10:29 in_upper.txt注意到 upper 下 in_lower.txt 的文件类型没有 ,而是 c 不是-或者 d总结
可以看到这种文件系统对于底层来说不影响,共享比较容易,但是如果编辑,删除频繁的话,性能还是比较差的。要不停的拷贝或者标记。
二.docker网络底层原理
2.1Linux 常见网络虚拟化
什么是虚拟网卡
虚拟网卡(又称虚拟网络适配器),即用软件模拟网络环境,模拟网络适配器。简单来说就是软件模拟的网卡。
虚拟网卡:tun/tap
tap/tun 虚拟了一套网络接口,这套接口和物理的接口无任何区别,可以配置 IP,可以路由流量,不同的是,它的流量只在主机内流通。
tun 和 tap 是两个相对独立的虚拟网络设备,其中 tap 模拟了以太网设备,操作二层数据包(以太帧), tun 则模拟了网络层设备,操作三层数据包(IP 报文)。使用 tun/tap 设备的目的是实现把来自协议栈的数据包先交由某个打开了/dev/net/tun 字符设备的用户进程处理后,再把数据包重新发回到链路中。你可以通俗地将它理解为这块虚拟化网卡驱动一端连接着网络协议栈,另一端连接着用户态程序,而普通的网卡驱动则是一端连接着网络协议栈,另一端连接着物理网卡。最典型的 VPN 应用程序为例,程序发送给 tun 设备的数据包。
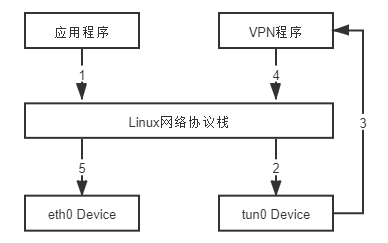
应用程序通过 tun 设备对外发送数据包后, tun 设备,便会把数据包通过字符设备发送给 VPN 程序, VPN 收到数据包,会修改后再重新封装成新报文,譬如数据包原本是发送给 A 地址的, VPN 把整个包进行加密,然后作为报文体,封装到另一个发送给 B 地址的新数据包当中。然后通过协议栈发送到物理网卡发送出去。
使用 tun/tap 设备传输数据需要经过两次协议栈,不可避免地会有一定的性能损耗,所以引入了新的网卡实现方式 veth。
2.2实操认识linux中的虚拟网卡tun/tap
在计算机网络中, tun 与 tap 是操作系统内核中的虚拟网络设备。不同于普通靠硬件网络适配器实现的设备,这些虚拟的网络设备全部用软件实现,并向运行于操作系统上的软件提供与硬件的网络设备完全相同的功能。
tun 是网络层的虚拟网络设备,可以收发第三层数据报文包,如 IP 封包,因此常用于一些点对点 IP 隧道,例如 OpenVPN, IPSec 等。
tap 是链路层的虚拟网络设备,等同于一个以太网设备,它可以收发第二层数据报文包,如以太网数据帧。 Tap 最常见的用途就是做为虚拟机的网卡,因为它和普通的物理网卡更加相近,也经常用作普通机器的虚拟网卡。
基本命令
- 添加网卡
bash
# 创建 tap
ip tuntap add dev tap0 mode tap
# 创建 tun
ip tuntap add dev tun0 mode tun- 删除网卡
bash
# 删除 tap
ip tuntap del dev tap0 mode tap
# 删除 tun
ip tuntap del dev tun0 mode tun- 激活网卡
bash
ip link set tun0 up- 设置 ip
bash
ip addr add 10.5.0.1/24 dev tun0- 查看帮助
bash
ip tuntap help我们来创建一个虚拟网卡然后激活网卡并给他配置一个ip,然后ping下看是否能够ping通就像真的物理网卡那样(为了简单我们使用tun,只配置ip地址即可):
bash
knd@NightCode:~/dockertest$ sudo ip tuntap add dev tun0 mode tun mode tun && sudo ip link set tun0 up && sudo ip addr add 10.5.0.1/24 dev tun0
knd@NightCode:~/dockertest$ ifconfig
...
tun0: flags=4241<UP,POINTOPOINT,NOARP,MULTICAST> mtu 1500
inet 10.5.0.1 netmask 255.255.255.0 destination 10.5.0.1
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
...
knd@NightCode:~/dockertest$ ping 10.5.0.1
PING 10.5.0.1 (10.5.0.1) 56(84) bytes of data.
64 bytes from 10.5.0.1: icmp_seq=1 ttl=64 time=0.026 ms
64 bytes from 10.5.0.1: icmp_seq=2 ttl=64 time=0.023 ms
64 bytes from 10.5.0.1: icmp_seq=3 ttl=64 time=0.030 ms
^C
--- 10.5.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2058ms
rtt min/avg/max/mdev = 0.023/0.026/0.030/0.003 ms可以看到它就像一个真的网卡一样被ping通了。
2.3linux中的虚拟网卡veth
如果说我的两个应用处于不同的网络命名空间(network namespace)时,如果放到现实常见的情况就是两台电脑之间拉跟网线就能通信了,veth就类似于这样,与其说他是一个虚拟网卡,更不如说他是一根网线。
在 Linux Kernel 2.6 版本, Linux 开始支持网络名空间隔离的同时,也提供了专门的虚拟以太网(Virtual Ethernet,习惯简写做 veth)让两个隔离的网络名称空间之间可以互相通信。
直接把 veth 比喻成是虚拟网卡其实并不十分准确,如果要和物理设备类比,它应该相当于由交叉网线连接的一对物理网卡。形象化的理解如下:

veth 实际上不是一个设备,而是一对设备,因而也常被称作 veth pair。要使用 veth,必须在两个独立的网络名称空间中进行才有意义,因为 veth pair 是一端连着协议栈,另一端彼此相连的,在 veth 设备的其中一端输入数据,这些数据就会从设备的另外一端原样不变地流出
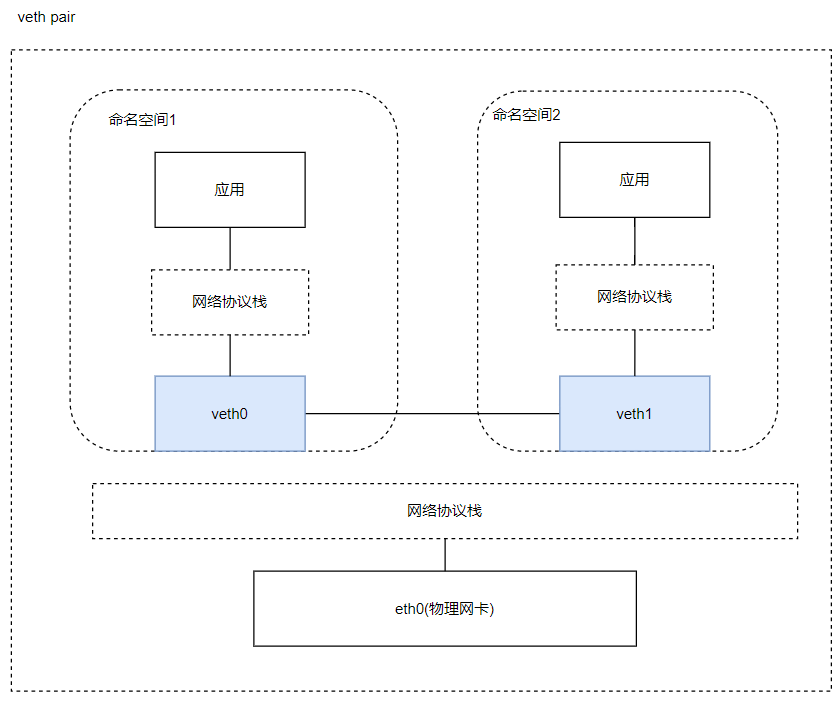
veth 通信不需要反复多次经过网络协议栈,这让 veth 比起 tap/tun 具有更好的性能。veth 实现了点对点的虚拟连接,可以通过 veth 连接两个 namespace,如果我们需要将 3 个或者多个 namespace 接入同一个二层网络时,就不能只使用 veth 了。 在物理网络中,如果需要连接多个主机,我们会使用网桥,或者又称为交换机。 Linux 也提供了网桥的虚拟实现。这个我们后面再说。
2.4实操认识下linux中的veth虚拟网卡
veth pair 是成对出现的一种虚拟网络设备接口,一端连着网络协议栈,一端彼此相连。
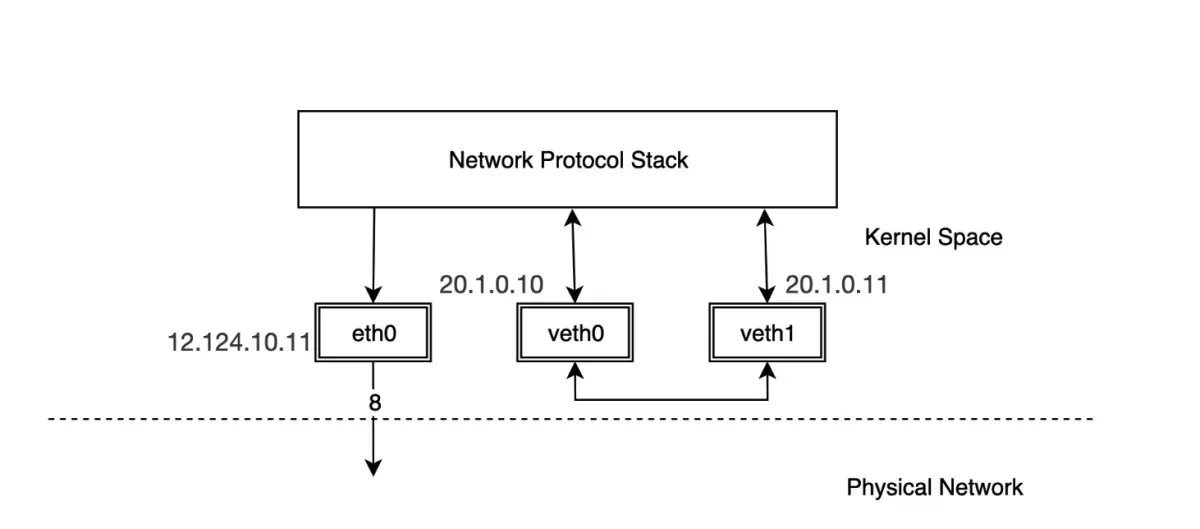
由于它的这个特性,常常被用于构建虚拟网络拓扑。例如连接两个不同的网络命名空间(netns),连接 docker 容器,连接网桥(Bridge)等
相关命令
- veth 操作
bash
# 添加 veth
ip link add <veth name> type veth peer name <peer name>
# 删除 veth
ip link delete <veth name>
# 查看 veth
ip link show- 命名空间操作
bash
#添加 ns
ip netns add <name>
#删除 ns
ip netns del <name>
#执行命令
ip netns exec <name> <cmd>
#遍历 ns
ip netns list因为veth虚拟网卡的创建是成对创建的,所以删除时也是成对删除的。我们来使用veth虚拟网卡让处于不同网络命名空间的设备互相ping下:
- 创建veth虚拟网卡
bash
knd@NightCode:~/dockertest$ sudo ip link add veth1-ns type veth peer name veth1-br- 创建两个网络命名空间
bash
knd@NightCode:~/dockertest$ sudo ip netns add net-ns && sudo ip netns add net-br
knd@NightCode:~/dockertest$ ip netns list
net-br
net-ns- 将网卡分别移动到对应的命名空间中
bash
knd@NightCode:~/dockertest$ sudo ip link set veth1-ns netns net-ns && sudo ip link set veth1-br netns net-br- 激活网卡(因为已经挪到别的网络空间中了,所以要进入空间进行激活与配置ip)
bash
knd@NightCode:~/dockertest$ sudo ip netns exec net-br ip link set veth1-br up && sudo ip netns exec net-br ip addr add 10.5.0.1/24 dev veth1-br
knd@NightCode:~/dockertest$ sudo ip netns exec net-ns ip link set veth1-ns up && sudo ip netns exec net-ns ip addr add 10.5.0.2/24 dev veth1-ns- 让彼此ping对方是能够ping通的
bash
knd@NightCode:~/dockertest$ sudo ip netns exec net-br ping 10.5.0.2
PING 10.5.0.2 (10.5.0.2) 56(84) bytes of data.
64 bytes from 10.5.0.2: icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from 10.5.0.2: icmp_seq=2 ttl=64 time=0.035 ms
64 bytes from 10.5.0.2: icmp_seq=3 ttl=64 time=0.035 ms
^C
--- 10.5.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2084ms
rtt min/avg/max/mdev = 0.033/0.034/0.035/0.000 ms
knd@NightCode:~/dockertest$ sudo ip netns exec net-ns ping 10.5.0.1
PING 10.5.0.1 (10.5.0.1) 56(84) bytes of data.
64 bytes from 10.5.0.1: icmp_seq=1 ttl=64 time=0.025 ms
64 bytes from 10.5.0.1: icmp_seq=2 ttl=64 time=0.038 ms
64 bytes from 10.5.0.1: icmp_seq=3 ttl=64 time=0.033 ms
^C
--- 10.5.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2041ms
rtt min/avg/max/mdev = 0.025/0.032/0.038/0.005 ms- 补充,当我们删veth网卡时直接删除的是一对网卡
bash
knd@NightCode:~/dockertest$ sudo ip netns exec net-br ip link delete veth1-br
knd@NightCode:~/dockertest$ sudo ip netns exec net-ns ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002.5虚拟交换机
使用 veth pair 将两个隔离的 netns 连接在了一起,在现实世界里等同于用一根网线把两台电脑连接在了一起,但是在现实世界里往往很少会有人这样使用。因为一台设备不仅仅只需要和另一台设备通信,它需要和很多很多的网络设备进行通信,如果还使用这样的方式,需要十分复杂的网络接线,并且现实世界中的普通网络设备也没有那么多网络接口。
那么,想要让某一台设备和很多网络设备都可以通信需要如何去做呢?在我们的日常生活中,除了手机和电脑,最常见的网络设备就是路由器了,我们的手机连上 WI-FI,电脑插到路由器上,等待从路由器的 DHCP 服务器上获取到 IP,他们就可以相互通信了,这便是路由器的二层交换功能在工作。 Linux Bridge 最主要的功能就是二层交换,是对现实世界二层交换机的模拟.
Linux Bridge ,由 brctl 命令创建和管理。 Linux Bridge 创建以后,真实的物理设备(如 eth0)抑或是虚拟的设备(veth 或者 tap)都能与 Linux Bridge 配合工作。
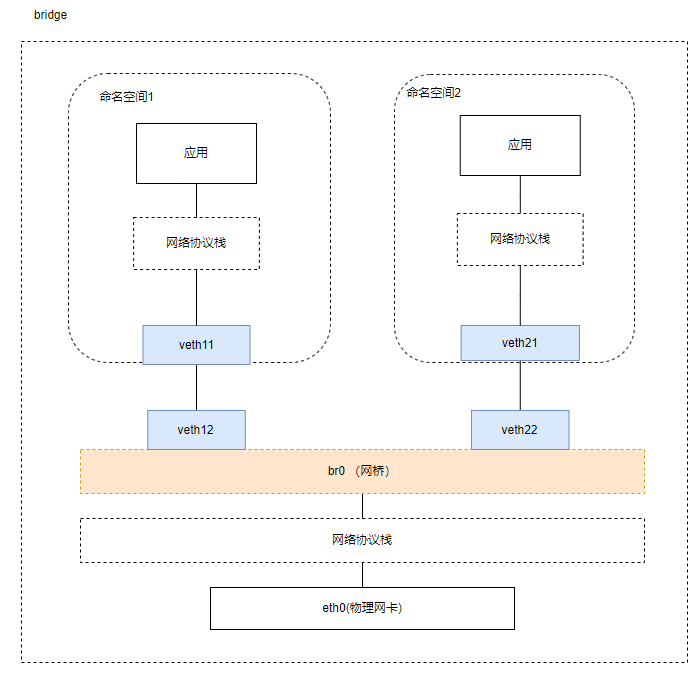
2.6实操认识下linux中的虚拟交换机(网桥)
Linux Bridge(网桥)是用纯软件实现的虚拟交换机,有着和物理交换机相同的功能,例如二层交换, MAC 地址学习等。因此我们可以把 tun/tap, veth pair 等设备绑定到网桥上,就像是把设备连接到物理交换机上一样。此外它和 veth pair、 tun/tap 一样,也是一种虚拟网络设备,具有虚拟设备的所有特性,例如配置 IP, MAC 地址等。
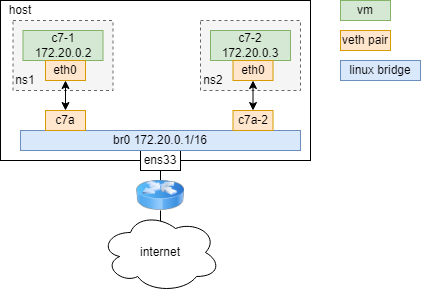
linux 提供了 brctl 工具来管理和查看网桥
- 安装方式
bash
# centos
yum install -y bridge-utils
# ubuntu
apt-get install -y bridge-utils- 新建一个网桥:
bash
brctl addbr <bridge>- 添加一个设备(例如 eth0)到网桥:
bash
brctl addif <bridge> eth0- 显示当前存在的网桥及其所连接的网络端口:
bash
brctl show- 启动网桥:
bash
ip link set <bridge> up- 删除网桥,需要先关闭它:
bash
ip link set <bridge> down
brctl delbr <bridge>或者使用 ip link del 命令直接删除网桥
bash
ip link del <bridge>我们搭建下面这样一个网络测试三者之间能否通过网桥互ping通:
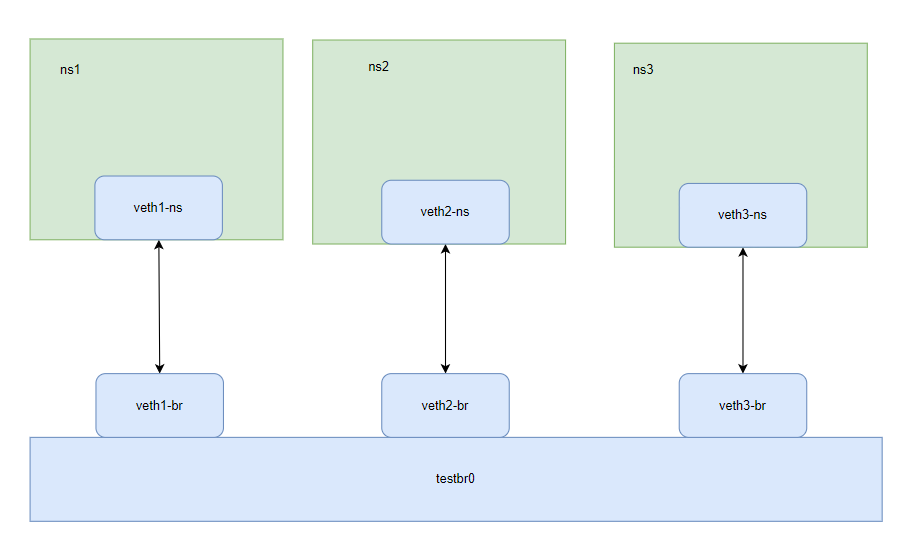
首先还是创建三个网络命名空间和三个veth虚拟网卡:
bash
knd@NightCode:~/dockertest$ sudo ip netns add ns1 && sudo ip netns add ns2 && sudo ip netns add ns3
knd@NightCode:~/dockertest$ sudo ip netns list
ns3
ns2
ns1
knd@NightCode:~/dockertest$ sudo ip link add veth1-ns type veth peer name veth1-br
knd@NightCode:~/dockertest$ sudo ip link add veth2-ns type veth peer name veth2-br
knd@NightCode:~/dockertest$ sudo ip link add veth3-ns type veth peer name veth3-br然后将ns虚拟网卡设置到对应的命名空间中去:
bash
knd@NightCode:~/dockertest$ sudo ip link set dev veth1-ns netns ns1
knd@NightCode:~/dockertest$ sudo ip link set dev veth2-ns netns ns2
knd@NightCode:~/dockertest$ sudo ip link set dev veth3-ns netns ns3启动网卡,并配置 ip,开启本地回环,可以 ping 自己
bash
knd@NightCode:~/dockertest$ sudo ip link set dev veth1-ns netns ns1
knd@NightCode:~/dockertest$ sudo ip link set dev veth2-ns netns ns2
knd@NightCode:~/dockertest$ sudo ip link set dev veth3-ns netns ns3
knd@NightCode:~/dockertest$ sudo ip netns exec ns1 ip link set veth1-ns up
knd@NightCode:~/dockertest$ sudo ip netns exec ns2 ip link set veth2-ns up
knd@NightCode:~/dockertest$ sudo ip netns exec ns3 ip link set veth3-ns up
knd@NightCode:~/dockertest$ sudo ip netns exec ns1 ip link set lo up
knd@NightCode:~/dockertest$ sudo ip netns exec ns2 ip link set lo up
knd@NightCode:~/dockertest$ sudo ip netns exec ns3 ip link set lo up
knd@NightCode:~/dockertest$ sudo ip netns exec ns1 ip addr add 10.100.0.11/24 dev veth1-ns
knd@NightCode:~/dockertest$ sudo ip netns exec ns2 ip addr add 10.100.0.12/24 dev veth2-ns
knd@NightCode:~/dockertest$ sudo ip netns exec ns3 ip addr add 10.100.0.13/24 dev veth3-ns创建网桥,默认会给网桥创建一个同名的虚拟网卡:
bash
knd@NightCode:~/dockertest$ sudo brctl addbr testbr0
...
testbr0: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether c6:03:f0:f3:ef:6f txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0启动网桥并给网桥配置ip:
bash
knd@NightCode:~/dockertest$ sudo ip link set testbr0 up
knd@NightCode:~/dockertest$ sudo ip addr add 10.100.0.1/24 dev testbr0将veth另一端网卡连上网桥并启动:
bash
knd@NightCode:~/dockertest$ sudo ip link set veth1-br up && sudo brctl addif testbr0 veth1-br
knd@NightCode:~/dockertest$ sudo ip link set veth2-br up && sudo brctl addif testbr0 veth2-br
knd@NightCode:~/dockertest$ sudo ip link set veth3-br up && sudo brctl addif testbr0 veth3-br此时我们让三者互ping是能够ping通的:
bash
knd@NightCode:~/dockertest$ sudo ip netns exec ns1 ping 10.100.0.12
PING 10.100.0.12 (10.100.0.12) 56(84) bytes of data.
64 bytes from 10.100.0.12: icmp_seq=1 ttl=64 time=0.044 ms
64 bytes from 10.100.0.12: icmp_seq=2 ttl=64 time=0.041 ms
64 bytes from 10.100.0.12: icmp_seq=3 ttl=64 time=0.037 ms
^C
--- 10.100.0.12 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2030ms
rtt min/avg/max/mdev = 0.037/0.040/0.044/0.003 ms
knd@NightCode:~/dockertest$ sudo ip netns exec ns1 ping 10.100.0.13
PING 10.100.0.13 (10.100.0.13) 56(84) bytes of data.
64 bytes from 10.100.0.13: icmp_seq=1 ttl=64 time=0.048 ms
64 bytes from 10.100.0.13: icmp_seq=2 ttl=64 time=0.038 ms
64 bytes from 10.100.0.13: icmp_seq=3 ttl=64 time=0.041 ms
^C
--- 10.100.0.13 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2030ms
rtt min/avg/max/mdev = 0.038/0.042/0.048/0.004 ms
knd@NightCode:~/dockertest$ sudo ip netns exec ns2 ping 10.100.0.13
PING 10.100.0.13 (10.100.0.13) 56(84) bytes of data.
64 bytes from 10.100.0.13: icmp_seq=1 ttl=64 time=0.051 ms
64 bytes from 10.100.0.13: icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from 10.100.0.13: icmp_seq=3 ttl=64 time=0.045 ms
^C
--- 10.100.0.13 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2047ms
rtt min/avg/max/mdev = 0.029/0.041/0.051/0.009 ms清理资源:
bash
ip link del veth1-br
ip link del veth2-br
ip link del veth3-br
ip link del testbr0
ip netns del ns1
ip netns del ns2
ip netns del ns32.7虚拟组网 VxLan
物理网络的拓扑结构是相对固定的。云原生时代的分布式系统的逻辑拓扑结构变动频率,譬如服务的扩缩、断路、限流,等等,都可能要求网络跟随做出相应的变化。正因如此,软件定义网络(Software Defined Network, SDN)的需求在云计算和分布式时代变得前所未有地迫切, SDN 的核心思路是在物理的网络之上再构造一层虚拟化的网络。
SDN 里位于下层的物理网络被称为 Underlay,它着重解决网络的连通性与可管理性,位于上层的逻辑网络被称为 Overlay,它着重为应用提供与软件需求相符的传输服务和网络拓扑。
vlan
交换机是一个 L2 设备,插在同一个交换机的网络设备组成了一个 L2 网络, L2 网络之间通过 MAC 地址通信,同时这个 L2 网络也是一个广播域。同属于一个广播域的两个设备想要通信,一设备须得向网络中的所有设备发送请求信息,只有对应 MAC 地址的设备才是真正的接收方,但实际上却是数据帧传遍整个网络,所有设备都会收到,且直接丢弃。如此一来,将造成一系列不好的后果:网络整体带宽被占用、潜在的信息安全风险、占用 CPU 资源......
Vlan(Virtual Local Area Network)即虚拟局域网,是一个将物理局域网在逻辑上划分成多个广播域技术。通过在交换机上配置 Vlan,可以实现在同一 Vlan 用户可以进行二层互访,在不同 Vlan 间的用户被二层隔离,这样既能够隔离广播域,又可以提升网络安全性。
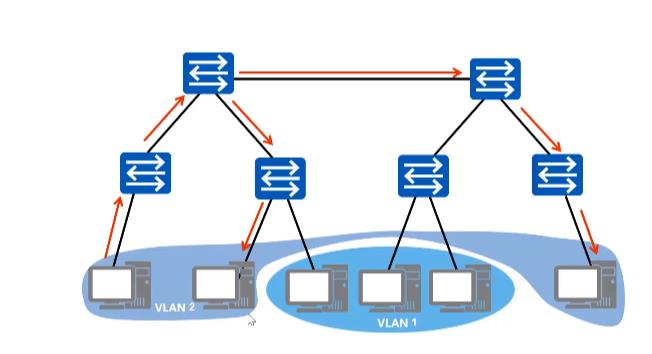
VLAN 究竟能够解决什么问题?
- 限制广播域。广播域被限制在一个局域网内,节省了带宽,提高了网络处理能力。
- 增强局域网的安全性。不同局域网内的报文在传输时是相互隔离的,即一个 VLAN内的用户不能和其它 VLAN 内的用户直接通信,如果不同 VLAN 要进行通信,则需要通过路由器或三层交换机等三层设备。
- 灵活构建虚拟工作组。用局域网可以划分不同的用户到不同的工作组,同一工作组的用户也不必局限于某一固定的物理范围,网络构建和维护更方便灵活。不过 VLAN 也
并非没有缺点。下面三条为缺点 - 随着虚拟化技术的发展,一台物理服务器往往承载了多台虚拟机,公有云或其它大型虚拟化云数据中心动辄需容纳上万甚至更多租户, VLAN 技术最多支持 4000 多个VLAN,逐渐无法满足需求。
- 公有云提供商的业务要求将实体网络租借给多个不同的用户,这些用户对于网络的要求有所同,而不同用户租借的网络有很大的可能会出现 IP 地址、 MAC 地址的重叠。传统的 VLAN 并没有涉及这个问题,因此需要一种新的技术来保证在多个租户网络中存在地址重叠的情况下依旧能有效通信的技术。
- 虚拟化技术使得单台主机可以虚拟化出多台虚拟机同时运行,而每台虚拟机都会有其唯一的 MAC 地址。这样,为了保证集群中所有虚机可以正常通信,交换机必须保存每台虚机的 MAC 地址,这样就导致了交换机中的 MAC 表异常庞大,从而影响交换机的转发性能。
vxlan
VXLAN 是另一种网络虚拟化技术,有点类似于 VLAN,但功能更强大。在传统的 VLAN 网络中,共享同一底层 L2 网段的 VLAN 不能超过 4096 个。只有 12比特用于对 Ethernet Frame 格式中的 VLAN ID 字段进行编码。VXLAN 协议定义了 8 个字节的 VXLAN Header,引入了类似 VLAN ID 的网络标识,称为 VNI(VXLAN Network ID),由 24 比特组成,这样总共是 1600 多万个,从而满足了大规模不同租户之间的标识、隔离需求。
VXLAN 是基于 L3 网络构建的虚拟 L2 网络,是一种 Overlay 网络。 VXLAN 不关心底层物理网络拓扑,它将 Ethernet Frame 封装在 UDP 包中,只要它能承载 UDP 数据包,就可以在远端网段之间提供以太网 L2 连接。
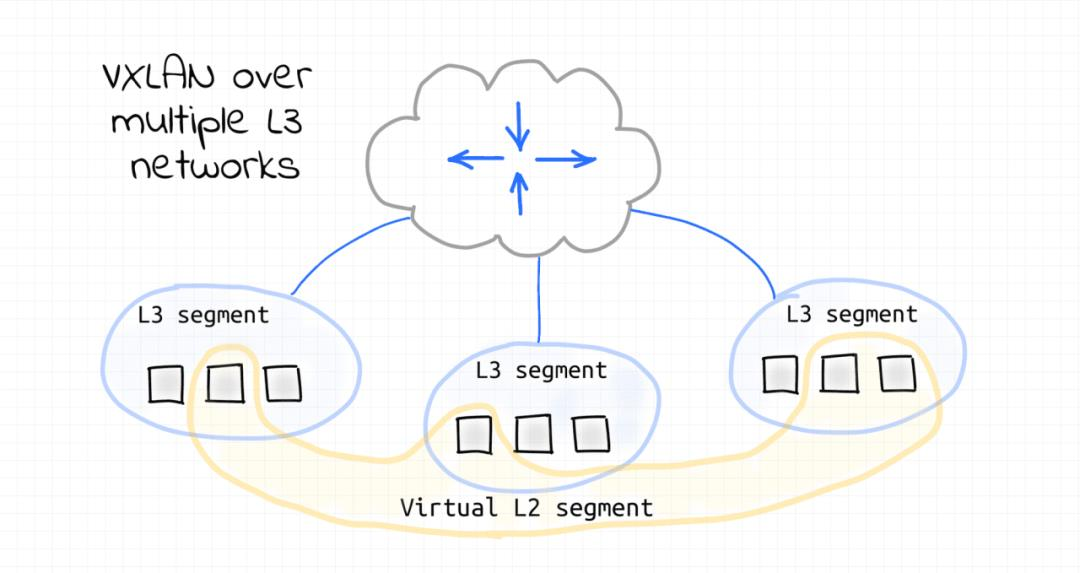
每个 VXLAN 节点上的出站 L2 Ethernet Frame 都会被捕获,然后封装成 UDP 数据包,并通过 L3 网络发送到目标 VXLAN 节点。当 L2 Ethernet Frame 到达 VXLAN 节点时,就从 UDP 数据包中提取(解封装),并注入目标设备的网络接口。这种技术称为隧道。因此, VXLAN 节点会创建一个虚拟 L2 网段,从而创建一个 L2 广播域。
2.8 MACVLan
MACVLAN 允许对同一个网卡设置多个 IP 地址,还允许对同一张网卡上设置多个MAC 地址,这也是 MACVLAN 名字的由来。原本 MAC 地址是网卡接口的"身份证",应该是严格的一对一关系,而 MACVLAN 打破这层关系,方法是在物理设备之上、网络栈之下生成多个虚拟的 Device,每个 Device 都有一个 MAC 地址,新增 Device 的操作本质上相当于在系统内核中注册了一个收发特定数据包的回调函数,每个回调函数都能对一个 MAC 地址的数据包进行响应,当物理设备收到数据包时,会先根据MAC 地址进行一次判断,确定交给哪个 Device 来处理。
可以看到 bridge 到 macvlan 缩短了通讯链路,性能比较高
许多网卡在硬件层面对支持的 MAC 地址数量存在限制。超过该限制会导致性能的下降。所以 macvlan 虽然近乎完美还是没有实际推广完成。
2.9 IPVLan
Ipvlan 与 macvlan 非常相似,但又存在显著不同。 Ipvlan 的子接口上并不拥有独立的MAC 地址。所有共享父接口 MAC 地址的子接口拥有各自独立的 IP。
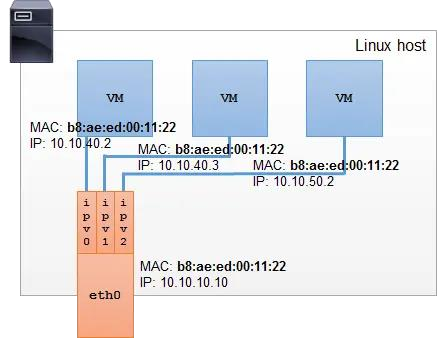
共享 MAC 地址会影响 DHCP 相关的操作。如果虚拟机、容器需通过 DHCP 获取网络配置,请确保它们在 DHCP 请求中使用各自独立的 ClientID; DHCP 服务器会根据请求中的 ClientID 而非 MAC 地址来分配 IP 地址。某些设备不支持分配多个 ip 地址所以IPVlan 也没有实际大规模推广。
三.docker网络
3.1docker网络分类
之前我们已经认识过bridge,container,host与none网络,但是并没有对overlay网络进行更进一步的认识,通过上面的底层原理部分,我们再来重新认识下overlay网络:
overlay网络
Overlay 驱动创建一个支持多主机网络的覆盖网络。
在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在 IP 报文之上的新的数据格式。
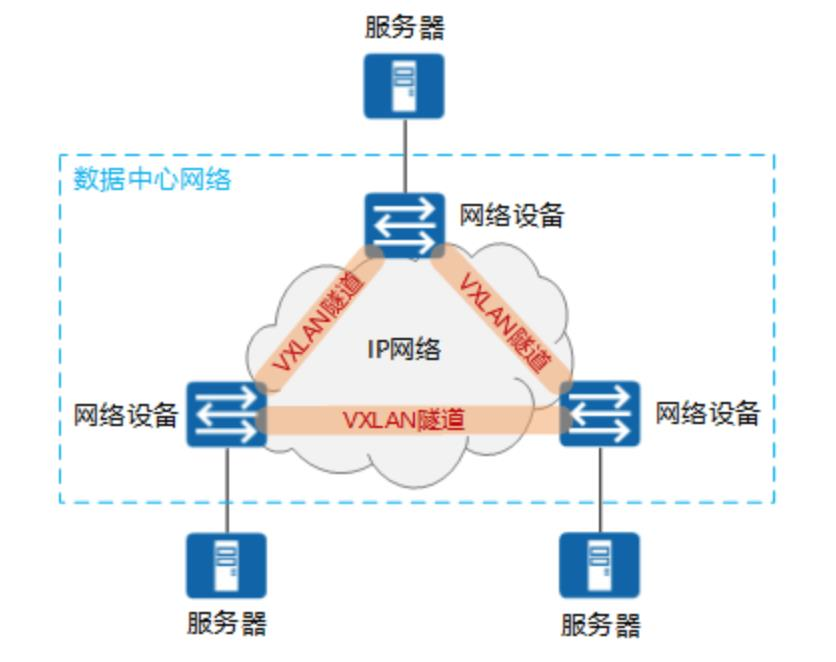
Overlay 网络实际上是目前最主流的容器跨节点数据传输和路由方案,底层原理VXLAN.Overlay 网络将多个 Docker 守护进程连接在一起,允许不同机器上相互通讯,同时支持对消息进行加密,实现跨主机的 docker 容器之间的通信, Overlay 网络将多个Docker 守护进程连接在一起,使 swarm 服务能够相互通信。这种策略消除了在这些容器之间进行操作系统级路由的需要。下图是个典型的 overlay 网络。
创建命令:
bash
docker network create -d overlay ovnet1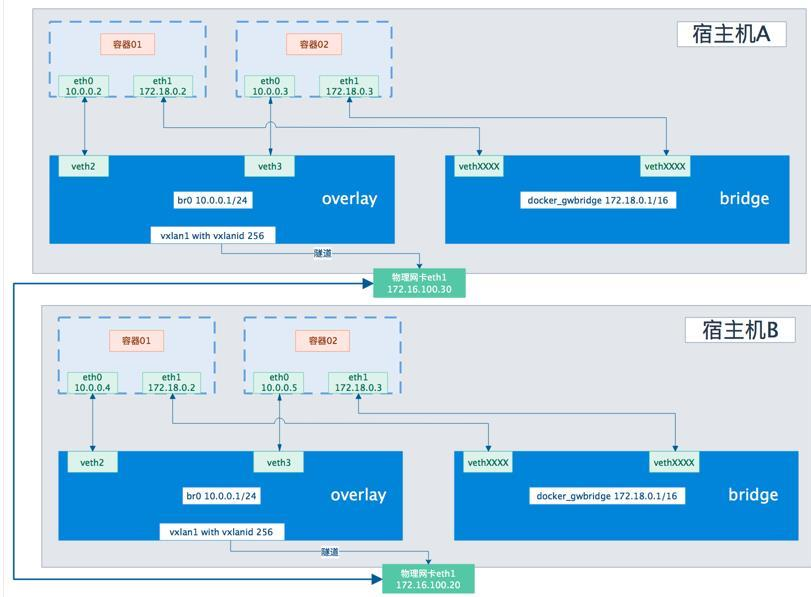
MacVlan网络
为每个容器的虚拟网络接口分配一个 MAC 地址,使其看起来是直接连接到物理网络的物理网络接口。在这种情况下,您需要在 Docker 主机上指定一个物理接口以用于 .macvlan 以及 子网和网关 macvlan。您甚至可以 macvlan 使用不同的物理网络接口隔离您的网络。注意要把对应的网卡开启混杂模式命令为 ifconfig 网卡名称(如 eth0)promisc
macvlan 典型的拓扑如下:
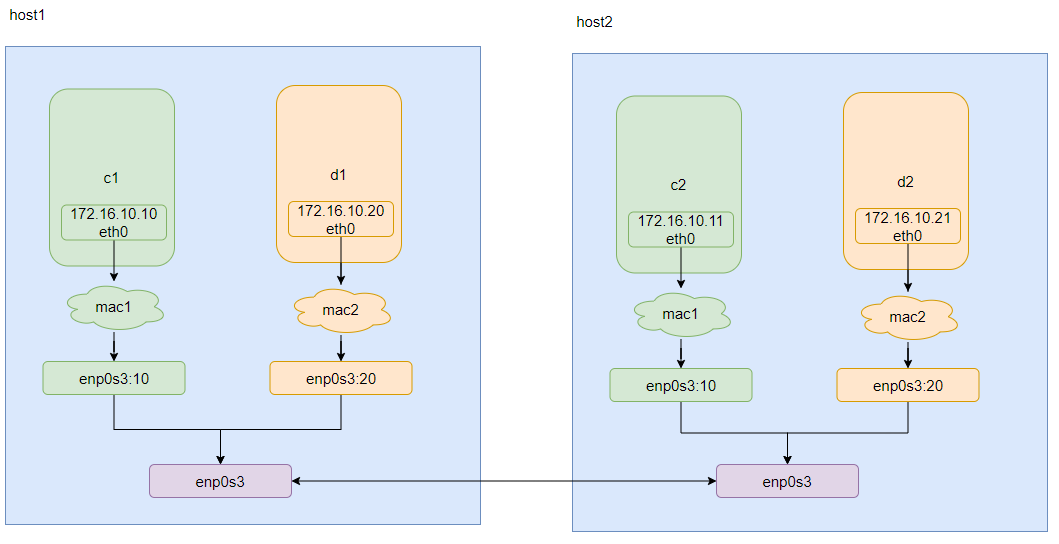
创建命令:
bash
docker network create -d macvlan --subnet=172.16.10.0/24 --gateway=172.16.10.1 -o parent=eth0 mac1IpVlan
ipvlan 和 overlay 都可以实现不同主机上的容器之间的通讯,但是 ipvlan 是所有容器都在一个网段,相当于在一个 vlan 里面,然后可以通过不同的子接口对应不同网段,实现不同容器之间的通讯。而 overlay 可以实现不同网段之间的通讯。 ipvlan 的 l2 网络
示例如下:
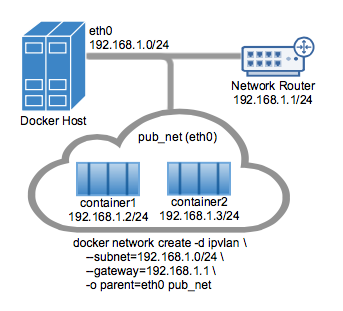
bash
docker network create -d ipvlan --subnet=192.168.1.0/24 --gateway=192.168.1.1 -o ipvlan_mode=l2 -o parent=eth0 pub_net3.2对docker bridge网络的进一步理解
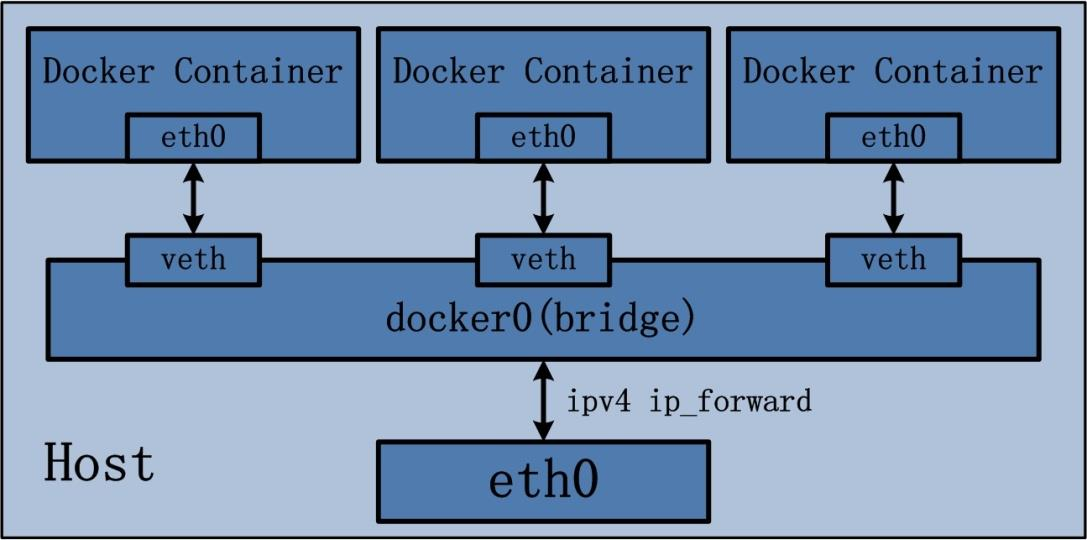
之前我们不是说bridge的时候,仅仅只是去使用了下但并没有实际在操作系统上看到他们的对应部分。这里我们来启动一个容器让其连接我们默认docker创建的docker0网络,然后看看是否能够查到对应的网桥与虚拟网卡:
bash
knd@NightCode:~$ sudo docker run --name busybox -d busybox:latest ping www.qq.com先来在容器内部找下其虚拟网卡:
bash
knd@NightCode:~$ sudo docker exec -it busybox sh
/ # ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if21: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 42:8b:0b:c5:be:74 brd ff:ff:ff:ff:ff:ff
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 42:8B:0B:C5:BE:74
inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:40 errors:0 dropped:0 overruns:0 frame:0
TX packets:33 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:3832 (3.7 KiB) TX bytes:2898 (2.8 KiB)我们再从宿主机上去找下:
bash
knd@NightCode:~$ ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:1b:f7:65 brd ff:ff:ff:ff:ff:ff
altname enp0s5
altname ens5
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:8a:07:f9:1e:df brd ff:ff:ff:ff:ff:ff
4: br-114be5f93480: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether de:c7:cb:9b:cf:f5 brd ff:ff:ff:ff:ff:ff
15: testbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/ether c6:03:f0:f3:ef:6f brd ff:ff:ff:ff:ff:ff
21: vethbe2391a@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 4e:18:79:a7:74:6d brd ff:ff:ff:ff:ff:ff link-netnsid 021与宿主机中的连接序号对上了,宿主机中的对应eth0的连接号为2,说明他们是一对veth pair。
容器与宿主机的通信原理
Bridge 桥接模式,从原理上实现了 Docker Container 到宿主机乃至其他机器的网络连通性。然而,由于宿主机的 IP 地址与 veth pair 的 IP 地址均不在同一个网段,故仅仅依靠 veth pair 和 namespace 的技术,还不足以是宿主机以外的网络主动发现 DockerContainer 的存在。为了使得 Docker Container 可以让宿主机以外的世界感知到容器内部暴露的服务, Docker 采用 NAT(Network Address Translation,网络地址转换)的方式,让宿主机以外的世界可以主动将网络报文发送至容器内部。
具体来讲,当 Docker Container 需要暴露服务时,内部服务必须监听容器 IP 和端口号port_0,以便外界主动发起访问请求。由于宿主机以外的世界,只知道宿主机 eth0 的网络地址,而并不知道 Docker Container 的 IP 地址,哪怕就算知道 Docker Container的 IP 地址,从二层网络的角度来讲,外界也无法直接通过 Docker Container 的 IP 地址访问容器内部应用。因此, Docker 使用 NAT 方法,将容器内部的服务监听的端口与宿主机的某一个端口 port_1 进行"绑定"。
如此一来,外界访问 Docker Container 内部服务的流程为:
- 外界访问宿主机的 IP 以及宿主机的端口 port_1;
- 当宿主机接收到这样的请求之后,由于 DNAT 规则的存在,会将该请求的目的 IP(宿主机 eth0 的 IP)和目的端口 port_1 进行转换,转换为容器 IP 和容器的端口port_0;
- 由于宿主机认识容器 IP,故可以将请求发送给 veth pair;
- veth pair 的 veth0 将请求发送至容器内部的 eth0,最终交给内部服务进行处理。使用 DNAT 方法,可以使得 Docker 宿主机以外的世界主动访问 Docker Container 内部服务。那么 Docker Container 如何访问宿主机以外的世界呢。
以下简要分析 DockerContainer 访问宿主机以外世界的流程:
- Docker Container 内部进程获悉宿主机以外服务的 IP 地址和端口 port_2,于是Docker Container 发起请求。容器的独立网络环境保证了请求中报文的源 IP 地址为容器 IP(即容器内部 eth0),另外 Linux 内核会自动为进程分配一个可用源端口(假设为 port_3) ;
- 请求通过容器内部 eth0 发送至 veth pair 的另一端,到达 veth0,也就是到达了网桥(docker0)处;
- docker0 网桥开启了数据报转发功能(/proc/sys/net/ipv4/ip_forward),故将请求发送至宿主机的 eth0 处;
- 宿主机处理请求时,使用 SNAT 对请求进行源地址 IP 转换,即将请求中源地址 IP(容器 IP 地址)转换为宿主机 eth0 的 IP 地址;
- 宿主机将经过 SNAT 转换后的报文通过请求的目的 IP 地址(宿主机以外世界的 IP地址)发送至外界。
在这里,很多人肯定会问:对于 Docker Container 内部主动发起对外的网络请求,当请求到达宿主机进行 SNAT 处理后发给外界,当外界响应请求时,响应报文中的目的IP 地址肯定是 Docker 宿主机的 IP 地址,那响应报文回到宿主机的时候,宿主机又是如何转给 Docker Container 的呢?关于这样的响应,由于 port_3 端口并没有在宿主机上做相应的 DNAT 转换,原则上不会被发送至容器内部。为什么说对于这样的响应,不会做 DNAT 转换呢。原因很简单, DNAT 转换是针对容器内部服务监听的特定端口做的,该端口是供服务监听使用,而容器内部发起的请求报文中,源端口号肯定不会占用服务监听的端口,故容器内部发起请求的响应不会在宿主机上经过 DNAT 处理。其实,这一环节的内容是由 iptables 规则来完成,具体的 iptables 规则如下:
bash
iptables -I FORWARD -o docker0 -m conntrack --ctstate
RELATED,ESTABLISHED -j ACCEPT这条规则的意思是,在宿主机上发往 docker0 网桥的网络数据报文,如果是该数据报文所处的连接已经建立的话,则无条件接受,并由 Linux 内核将其发送到原来的连接上,即回到 Docker Container 内部。
IP-Forwarding IP 转发。 一种路由协议。 IP 转发是操作系统的一种选项,支持主机起到路由器的功能。在一个系统中含有两块以上的网卡,并将 IP 转发选项打开,这样该系统就可以作为路由器进行使用了。
对于这个流程的图示如下:
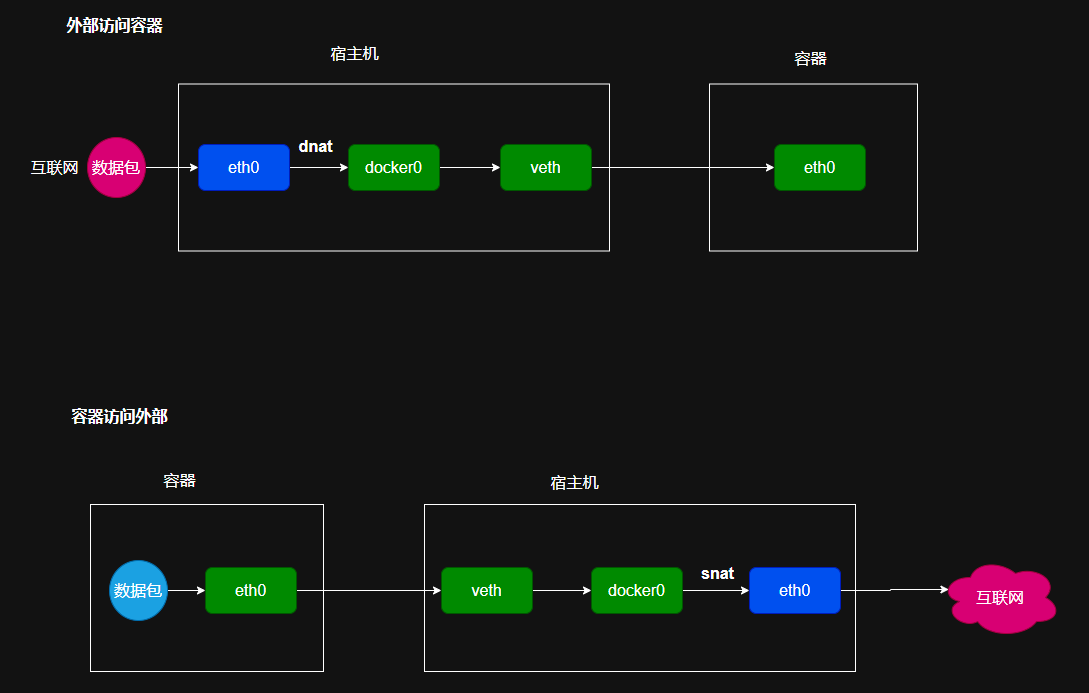
实际上是NAT转换,容器访问宿主机时经过了snat的转换,而宿主机与容器进行通信时则是经过了dnat的转换。
iptables 组成 Linux 平台下的包过滤防火墙,与大多数的 Linux 软件一样,这个包过滤防火墙是免费的,它可以代替昂贵的商业防火墙解决方案,完成封包过滤、封包重定向和网络地址转换等功能。
-t 指定表名,在 iptables 中,有四张表: filter:这里面的链条,规则,可以决定
一个数据包是否可以到达目标进程端口; mangle: 这里面的链条,规则,可以修改数据包的内容,比如 ttl; nat:这里面的链条,规则,可以修改源和目标的 ip 地址,从而进行包路由; raw:这里面的链条,规则,能基于数据包的状态进行规则设定
- -n 使用数字形式(numeric)显示输出结果
- -v 查看规则表详细信息(verbose)的信息
- -L 列出(list)指定链中所有的规则进行查看
下面我们可以通过 iptables 命令来查看 NAT 转换表,先启动一个nginx服务,然后查看NAT转换:
bash
knd@NightCode:~$ sudo docker run -d --name nginx -p 8080:80 mynginx:1.2
knd@NightCode:~$ sudo iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 733K packets, 39M bytes)
pkts bytes target prot opt in out source destination
734K 39M DOCKER 0 -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 190K packets, 12M bytes)
pkts bytes target prot opt in out source destination
1 84 DOCKER 0 -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 192K packets, 12M bytes)
pkts bytes target prot opt in out source destination
4 280 MASQUERADE 0 -- * !docker0 172.17.0.0/16 0.0.0.0/0
0 0 MASQUERADE 0 -- * !br-114be5f93480 172.18.0.0/16 0.0.0.0/0
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 DNAT 6 -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:80可以看到最底部有一个DNAT的规则,用于容器与外界进行通信。
容器的网络命名空间查找
前面我们不是展示过了,可以通过ip netns exec在对应的网络空间中进行对应命令的执行,而且不需要我容器安装此时直接用宿主机已经安装好的工具。但是这样终归还是太麻烦,我们再介绍一个更好用的命令:
nsenter 命令是一个可以在指定进程的命名空间下运行指定程序的命令。它位于 utillinux 包中。一最典型的用途就是进入容器的网络命令空间。相当多的容器为了轻量级,是不包含较为基础的命令的,比如说 ip address, ping, telnet, ss, tcpdump 等等命令,这就给调试容器网络带来相当大的困扰:只能通过 docker inspectContainerID 命令获取到容器 IP,以及无法测试和其他网络的连通性。这时就可以用 nsenter 命令仅进入该容器的网络命名空间,使用宿主机的命令调试容器网络。
语法:
bash
nsenter [options] <program> [<argument>...]常见参数
| 参数 | 含义 |
|---|---|
-t, --target <pid> |
进入目标进程的命名空间 |
-i, --ipc[=<file>] |
进入 IPC 空间 |
-m, --mount[=<file>] |
进入 Mount 空间 |
-n, --net[=<file>] |
进入 Net 空间 |
-p, --pid[=<file>] |
进入 Pid 空间 |
-u, --uts[=<file>] |
进入 UTS 空间 |
-U, --user[=<file>] |
进入用户空间 |
-V, --version |
版本查看 |
这里我们就只展示网络命名空间的案例了,有兴趣的读者可以自行进行查阅其他参数的使用方式。注意到后面他是需要跟目录的[=<file>],实际上ip netns 默认是去检查/var/run/netns 目录的。而 Docker 容器对应的 ns 信息记录到了/var/run/docker/netns 目录(防止误删)。所以 ip netns 查出来就是空的:
bash
knd@NightCode:~$ ip netns list
knd@NightCode:~$ sudo ls /var/run/docker/netns
082bbfd0a5fa那在docker这里查到的这玩意有什么用,因为nginx要对外通信,那么他会经过一个snat转换,可以查看容器详情中的下面展示出来的部分信息:
bash
"NetworkSettings": {
"SandboxID": "082bbfd0a5faff89e9bc0b60ba2a4e4e96fa35b7b3a820e1285e16ec4ff8a89a",
"SandboxKey": "/var/run/docker/netns/082bbfd0a5fa",我们可以看到SandboxKey后跟着的目录是对应上的。然后我们使用nsenter通过此文件进入nginx容器网络命名空间:
bash
knd@NightCode:~$ sudo nsenter --net=/var/run/docker/netns/082bbfd0a5fa sh
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether aa:c3:3c:88:30:9d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever然后我们在通过容器进入看看:
bash
knd@NightCode:~$ sudo docker exec -it nginx sh
# ip a
sh: 1: ip: not found可以看到容器内是没有这个命令的。那我们怎么验证这个是不是我们nginx的网络命名空间呢,iptables:
bash
knd@NightCode:~$ sudo iptables -t nat -nvL
...
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
2 104 DNAT 6 -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:80172.17.0.2,与我们上面用nsenter查到的ip地址是一样的。