
🎬 个人主页 :Vect个人主页
🎬 GitHub :Vect的代码仓库
🔥 个人专栏 : 《数据结构与算法》《C++学习之旅》《计算机基础》
⛺️Per aspera ad astra.
文章目录
- [1. 初始化方式](#1. 初始化方式)
-
- [1.1. `{}`初始化](#1.1.
{}初始化) - [1.2. `std::initializer_list`](#1.2.
std::initializer_list)
- [1.1. `{}`初始化](#1.1.
- [2. 声明方式](#2. 声明方式)
-
- [2.1. `auto`](#2.1.
auto) - [2.2. `decltype`](#2.2.
decltype)
- [2.1. `auto`](#2.1.
- [3. 右值引用和移动语义](#3. 右值引用和移动语义)
-
- [3.1. 左值引用和右值引用](#3.1. 左值引用和右值引用)
- [3.2. 左值引用和右值引用的区别](#3.2. 左值引用和右值引用的区别)
- [3.3. 右值引用的使用场景](#3.3. 右值引用的使用场景)
-
- [3.3.1. 用一个`buffer`观察返回值的拷贝和移动](#3.3.1. 用一个
buffer观察返回值的拷贝和移动)
- [3.3.1. 用一个`buffer`观察返回值的拷贝和移动](#3.3.1. 用一个
- [3.4. 升级版`buffer`+日志再次理解右值引用](#3.4. 升级版
buffer+日志再次理解右值引用) - [3.5. 完美转发](#3.5. 完美转发)
- 4.完美转发的应用------容器的`emplace`系列
-
- [4.1. **核心意义:原地构造+完美转发**](#4.1. 核心意义:原地构造+完美转发)
- [4.2. 使用场景](#4.2. 使用场景)
-
- [4.2.1. 场景一:`vector::emplace_back`VS`push_back`](#4.2.1. 场景一:
vector::emplace_backVSpush_back) - [4.2.2. 场景二:`map::emplace`VS `insert`](#4.2.2. 场景二:
map::emplaceVSinsert)
- [4.2.1. 场景一:`vector::emplace_back`VS`push_back`](#4.2.1. 场景一:
- [4.3. 底层机制](#4.3. 底层机制)
- [5. 可变参数模板](#5. 可变参数模板)
-
- [5.1. 是什么?](#5.1. 是什么?)
- [5.2. 怎么用?](#5.2. 怎么用?)
-
- [5.2.1. 参数包只能展开,不能索引](#5.2.1. 参数包只能展开,不能索引)
- [5.2.2. 搭配右值引用](#5.2.2. 搭配右值引用)
- [6. `lambda`表达式](#6.
lambda表达式) -
- [6.1. 基本语法和用法](#6.1. 基本语法和用法)
- [6.2. 底层原理](#6.2. 底层原理)
- [6.3. 捕获](#6.3. 捕获)
-
- [6.3.1. 按值捕获`=/x`](#6.3.1. 按值捕获
[=]/[x]) - [6.3.2. 按引用捕获`\&/\&X`](#6.3.2. 按引用捕获
[&]/[&X]) - [6.3.3. 混合捕获](#6.3.3. 混合捕获)
- [6.3.1. 按值捕获`=/x`](#6.3.1. 按值捕获
- [6.4. `mutable` 和`const`](#6.4.
mutable和const) - [6.5. `lambda`和函数对象](#6.5.
lambda和函数对象)
- [7. 包装器](#7. 包装器)
-
- [7.0. 什么是可调用对象?](#7.0. 什么是可调用对象?)
- [7.1. 模板函数的问题](#7.1. 模板函数的问题)
- [7.2. 包装器](#7.2. 包装器)
- [7.3. 用包装器改造`useF`](#7.3. 用包装器改造
useF) - [7.4. 迷你包装器实现](#7.4. 迷你包装器实现)
1. 初始化方式
1.1. {}初始化
在C++98中,{}对数组或结构体元素进行统一的列表初始化,例如:
cpp
// C++98 用{}对数组和结构体进行统一的列表初始化
int arr[] = { 10,20,34,2,2 };
struct showEG {
double x;
double y;
double z;
};
struct showEG pos = { 0.1,0.8 ,1.8};C++11扩大了{}适用范围,适用于所有的内置类型和自定义类型,使用初始化列表时,也可以省略=
cpp
// C++11 对所有内置类型和自定义类型 {}进行初始化 =可以省略
struct Point {
double x;
double y;
double z;
};
struct Point pos{1.1,1.1,1.1};
int num{ 10 };
long long len{ 1024 };
int arr[]{ 1,2,3,4,6,7 };创建对象时也可以采用这种方式:
cpp
class Date {
private:
int _year = 1;
int _month = 1;
int _day = 1;
public:
Date(int year,int month, int day)
:_year(year)
,_month(month)
,_day(day)
{ }
};
// 之前的初始化方式
Date d(2020, 1, 1);
// C++11引入的初始化方式
Date d1{ 2025,11,11 };1.2. std::initializer_list
std::initializer_list让 {} 这个"初始化列表"成为一种正式的类型,从而:
- 你可以写
vector<int> v = {1,2,3}; - 甚至可以写
v = {10,20,30}; - 自己的类也能像 STL 一样支持
{}初始化/赋值。
这是std::initializer_list的类型
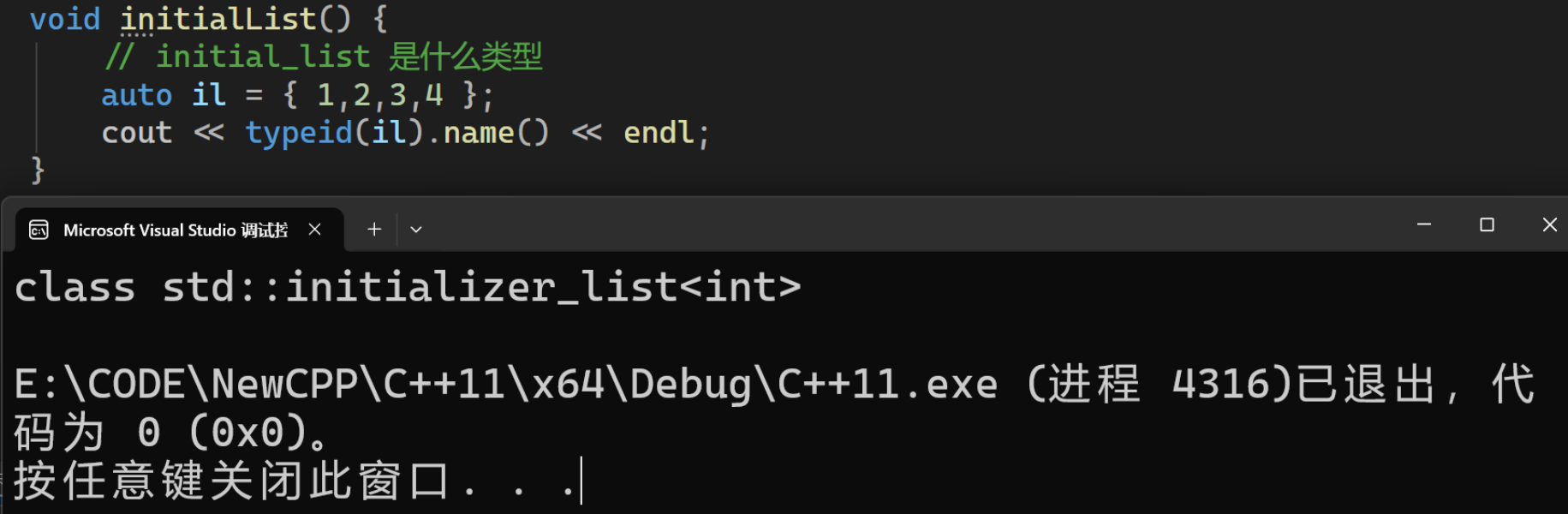
它的底层是一个数组,当写到:
cpp
std::vector<int> = {1,2,3};编译器会有下列行为:
- 在某个连续内存中放好{1,2,3}这个只读数组
- 构造一个
std::initializer_list<int>对象ilil.begin():指向临时数组的首元素il.end():指向临时数组最后元素的下一个
- 调用
vector(initializer_list<int> il)构造函数
以下是std::initializer_list的使用:
cpp
// 要和Date d1{ 2025,11,11 }区分开
// {}里的元素个数取决于Date类中成员变量个数
// 而以下{}里元素个数不限
vector<int> v = { 1,2,3,4 };
map<string, string> dict = { {"书","book"},{"排序","sort"} };2. 声明方式
2.1. auto
C++11中,auto用于实现类型的自动推断,这就要求必须显式初始化,让编译器将定义的对象类型设置为初始化值的类型
cpp
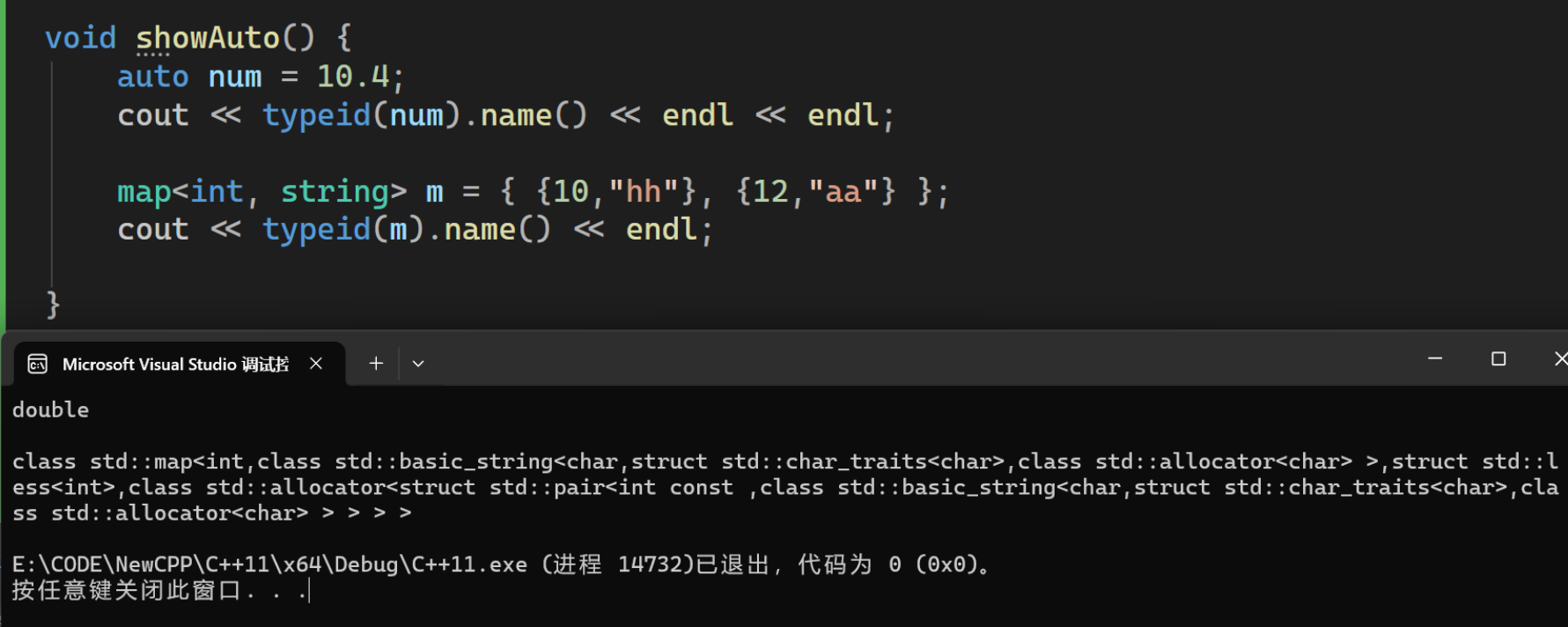
void showAuto() {
auto num = 10.4;
cout << typeid(num).name() << endl << endl;
map<int, string> m = { {10,"hh"}, {12,"aa"} };
cout << typeid(m).name() << endl;
}
2.2. decltype
将类型声明为表达式指定的类型,并计算表达式的结果
cpp
template<class T1, class T2>
void Func(T1 num1, T2 num2) {
decltype(num1 * num2) ret;
cout << typeid(ret).name() << endl;
}
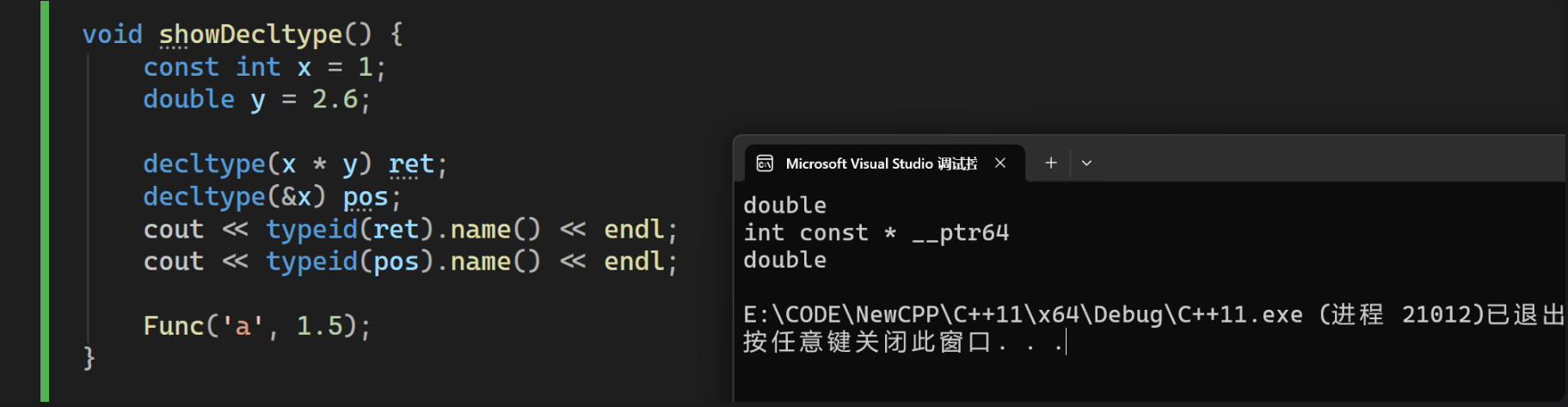
void showDecltype() {
const int x = 1;
double y = 2.6;
decltype(x * y) ret;
decltype(&x) pos;
cout << typeid(ret).name() << endl;
cout << typeid(pos).name() << endl;
Func('a', 1.5);
}
3. 右值引用和移动语义
3.1. 左值引用和右值引用
不论是左值引用还是右值引用,都是取别名
什么是左值?什么是左值引用?
左值:可以获取地址 的表示数据的表达式,可以对左值赋值,左值可以出现在=两边 ,而定义时有const修饰后的左值,不能给他赋值,但可以取地址
cpp
void showLeftValue() {
// num dnum *pnum 都是左值
int num = 10;
double dnum = 1.5;
const int* pnum = #
// rnum rdnum rpnum 都是左值引用
int& rnum = num; // 引用int类型变量
double& rdnum = dnum; // 引用double类型变量
const int*& rpnum = pnum; // 引用const指针类型变量
// 可以给左值赋值
num = 20;
// 左值可以出现在=右侧
dnum = (double)num;
}什么是右值?什么是右值引用?
右值:不能获取地址 的表示数据的表达式,通常有字面常量,表达式返回值,函数返回值 ,右值只能出现在=的右侧。
cpp
void showRightValue() {
// "13245" 1.1 2.2 Fmin('a', 'c') (x + y)都是右值
string s = "13245";
double x = 1.1, y = 2.2;
Fmin('a', 'c');
double plus = x + y;
// 以下都是右值引用
int&& rrnum = 10;
double&& rrplus = x + y;
char&& ret = Fmin('a', 'c');
// 右值不能出现在=左边
// error C2106: "=": 左操作数必须为左值
//10 = x;
//x + y = 2.0;
//Fmin('a', 'b') = 0;
}这里需要注意,不能给右值取地址,但是引用右值之后,会把右值存到特定位置,可以取到这个地址,也就是说不能取字面常量10的地址,但是rrnum饮用后,可以对rrnum取地址,也可以修改rrnum
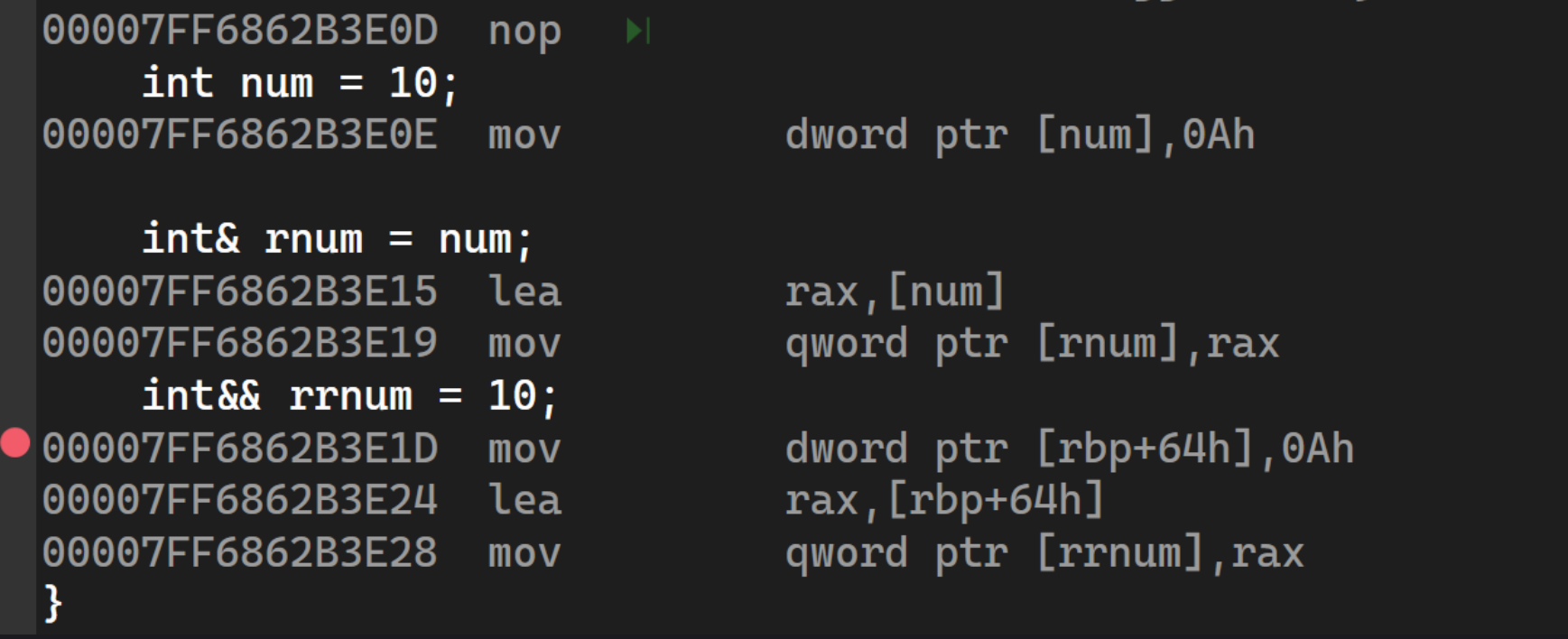
我们转到汇编层,会发现并没有引用的概念,都是有详细的地址的
3.2. 左值引用和右值引用的区别
左值引用:
- 左值引用只能引用左值,不能引用右值
const左值引用既可以引用左值,也能引用右值-->右值有临时属性,相当于是临时变量,而临时变量有常性,只读
cpp
// 左值引用只能引用左值
int val = 10;
int& rval1 = val;
// C2440: "初始化": 无法从"int"转换为"int &" 非常量引用只能绑定到左值
//int& rval2 = 10;
// const左值引用可以引用右值
const int&& rrval = 10;右值引用:
- 右值引用只能引用右值,不能引用左值
- 右值引用可以引用
move后的值
cpp
// 右值引用只能引用右值
double num = 1.1;
double&& rrnum1 = 1.1;
// C2440: "初始化": 无法从"double"转换为"double &&" 无法将左值绑定到右值引用
//double&& rrnum2 = num;
// 右值引用可以引用move后的左值
double&& rrnum = move(num);需要注意的是move并不改变num的左值属性,经过move(num)的返回值类型是右值
3.3. 右值引用的使用场景
3.3.1. 用一个buffer观察返回值的拷贝和移动
写一个简单的动态数组类:
cpp
class buffer {
public:
// 普通构造 开一块空间
buffer(size_t n)
:_data(new int[n])
, _size(n)
{
cout << "构造buffer(" << n << ")" << endl;
}
// 拷贝构造 深拷贝
buffer(const buffer& other)
:_data(new int[other._size])
, _size(other._size)
{
cout << "拷贝构造 buffer" << endl;
for (size_t i = 0; i < _size; i++)
{
_data[i] = other._data[i];
}
}
// 析构
~buffer() {
cout << "析构buffer" << endl;
delete[] _data;
}
private:
int* _data;
size_t _size;
};1. 没有移动构造:函数返回会发生什么?
没有移动构造的情况下,大致流程:
MakeBuffer()里构造buf→ 调用普通构造return buf;时:- 需要把
buf的内容拷贝给"返回值临时对象" → 调用拷贝构造
- 需要把
main里Buffer b = MakeBuffer();- 再把"返回值临时对象"拷贝给
b→ 又一次拷贝构造
- 再把"返回值临时对象"拷贝给
- 最后局部对象/临时对象依次析构 → 对应多次"释放内存"
也就是说,可能会发生 2 次深拷贝(新申请内存 + 复制数据)。
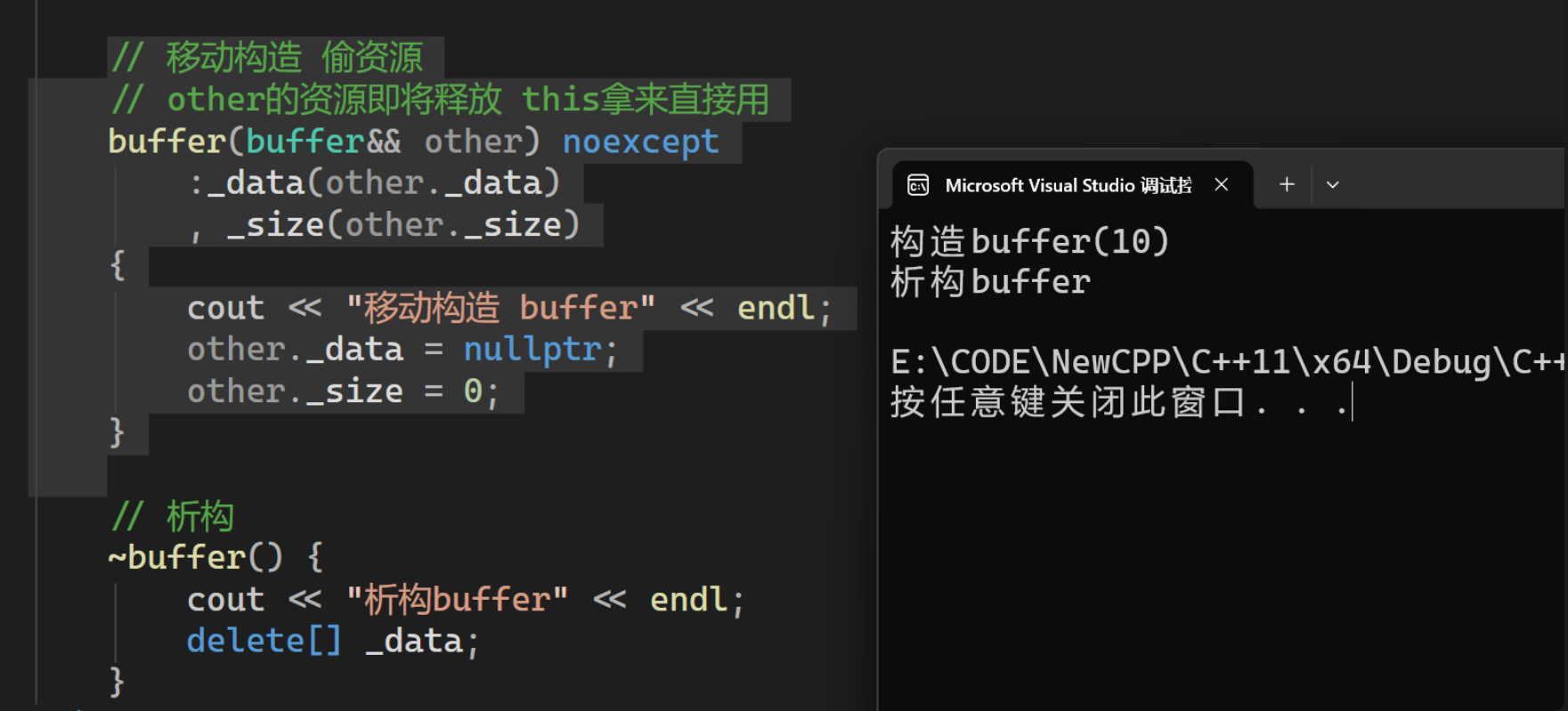
2. 加上移动构造之后的现象:
移动构造的本质是讲参数右值的资源窃取过来,占为己有,就不用深拷贝了
现在添加一个移动构造函数:
cpp
// 移动构造 偷资源
// other的资源即将释放 this拿来直接用
buffer(buffer&& other) noexcept
:_data(other._data)
, _size(other._size)
{
cout << "移动构造 buffer" << endl;
other._data = nullptr;
other._size = 0;
}
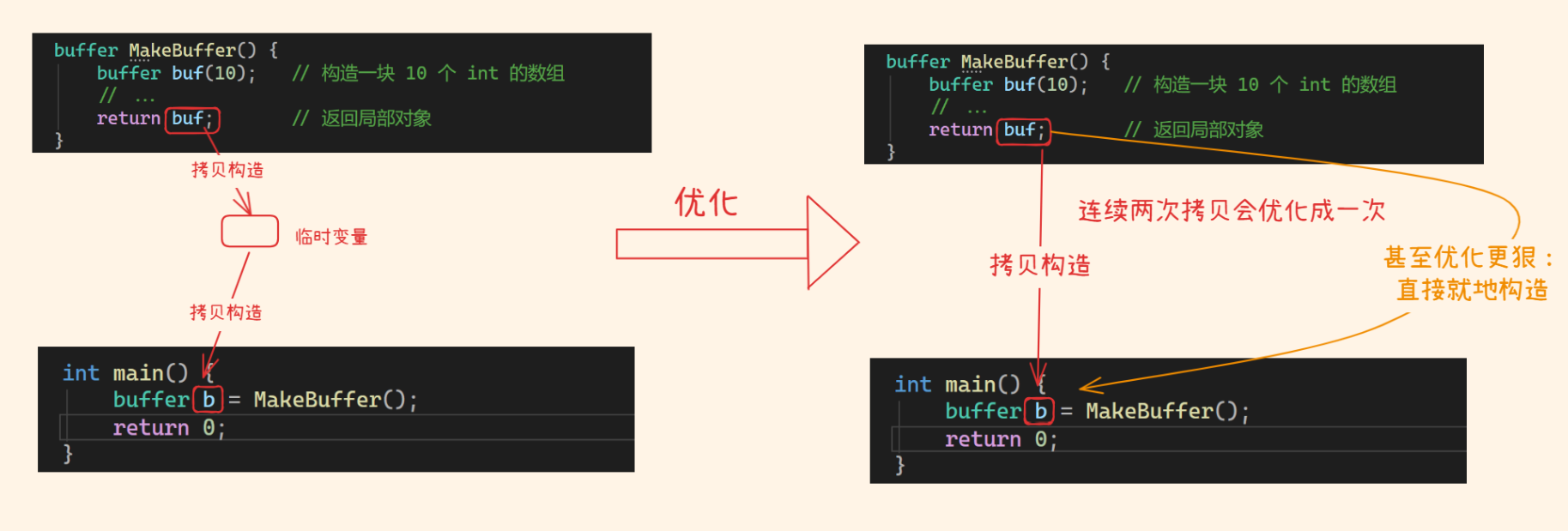
但是我们发现,只有一次构造,这是编译器优化的太厉害了:
编译器发现我的逻辑是先构造一个局部对象,再拷贝/移动一份给外面的人用
而编译器说:我干嘛要先构造再搬?
我直接再外面那块内存上"就地构造"不就完了
这是编译器的行为:

3. 总结一下:
我们现在遇到两个现象:
return buf:只打印"构造buffer(10)"和析构buffer,没有看到移动构造return (move)buf:VS2026给出警告,一次构造,一次移动,两次析构
先搞清楚三个概念:拷贝、移动、拷贝消除(RVO/NRVO)
- 拷贝构造 :开辟新空间,把别人的数据一份一份拷贝过来(深拷贝)
- 移动构造 : 直接偷指针,把别人的
_data指针接管过来,把对方置空- 拷贝消除 : 省略掉拷贝/移动,直接在对应空间就地构造
所以,对于return buf; 和buffer b = MakeBuffer();,既然buf最终要传给b,那么干脆在b的空间上直接构造buf,这是常见的RVO(Return Value Optimization)
而对于返回的是一个函数内的局部自动对象,类型与返回值相同,就符合NRVO(Named RVO)
而对于return (move)buf,表达式变为一个将亡值,不再是一个局部变量的名字,不符合NRVO,语义变为:
从
buf调用移动构造,构造一个"返回值临时对象 rv"
buf资源被搬到 rv 上退出函数,把这个 rv 返回给
main在
main里用 rv 再移动构造b而VS这里的警告是:用了
move会限制优化
3.4. 升级版buffer+日志再次理解右值引用
添加移动赋值和拷贝赋值
cpp
class buffer {
public:
// 普通构造 开一块空间
buffer(size_t n)
:_data(new int[n])
, _size(n)
{
cout << "构造buffer(" << n << ")" << endl;
}
// 拷贝构造 深拷贝
buffer(const buffer& other)
:_data(new int[other._size])
, _size(other._size)
{
cout << "拷贝构造 buffer" << endl;
for (size_t i = 0; i < _size; i++)
{
_data[i] = other._data[i];
}
}
// 移动构造 偷资源
// other的资源即将释放 this拿来直接用
buffer(buffer&& other) noexcept
:_data(other._data)
, _size(other._size)
{
cout << "移动构造 buffer" << endl;
other._data = nullptr;
other._size = 0;
}
// 拷贝赋值:深拷贝+释放旧资源
buffer& operator=(const buffer& other) {
cout << "拷贝赋值 buffer" << endl;
if (this != &other) {
// 先备份旧数据 避免自拷贝
int* newData = other._size ? new int[other._size] : nullptr;
for (size_t i = 0; i < other._size; i++)
{
newData[i] = other._data[i];
}
delete[] _data;
_data = newData;
_size = other._size;
}
return *this;
}
// 移动赋值
buffer& operator=(buffer&& other) noexcept {
cout << "移动赋值 buffer" << endl;
if (this != &other) {
delete[] _data; // 先释放旧资源
_data = other._data; // 直接接管对方资源
_size = other._size;
other._data = nullptr;
other._size = 0;
}
return *this;
}
// 析构
~buffer() {
cout << "析构buffer" << endl;
delete[] _data;
}
size_t size() const { return _size; }
private:
int* _data;
size_t _size;
};
void testNoExpand() {
cout << "=== 不扩容场景: push_back 左值/右值 ===" << endl;
vector<buffer> v;
v.reserve(3);
cout << "\n---插入左值---\n";
buffer b1(10);
v.push_back(b1);
cout << "\n---插入右值---\n";
v.push_back(buffer(20));
cout << "\n---插入move(b1)---\n";
v.push_back(move(b1));
cout << "=== 析构 ===" << endl;
}
int main() {
testNoExpand();
return 0;分析一下详细过程:
v.push_back(b1);------ 左值插入
buffer b1(10);
- 调用普通构造:
构造 buffer(10)
v.push_back(b1);
b1是左值,匹配push_back(const T&)版本vector 在它预留的空间里原地构造一个元素 :调用 拷贝构造
输出:
拷贝构造 buffer此时:
b1拥有一块 size=10 的数组
v[0]也有一块 size=10 的数组,独立深拷贝
v.push_back(buffer(20));------ 使用右值插入
buffer(20)先在语句求值时生成一个临时对象:
- 输出:
构造 buffer(20)
push_back接收到的是一个右值,匹配push_back(T&&)版本
vector 在自己的存储中构造元素时 优先调用移动构造
输出:
移动构造 buffer那个临时
buffer(20)用完后会析构:
- 输出:
析构 buffer(因为资源已经被偷走,_size 已变 0)
v.push_back(std::move(b1));------ 把已有对象资源挪进去
std::move(b1)把b1从左值修饰成右值匹配
push_back(T&&),内部调用 移动构造:
输出:
移动构造 buffer新元素接管 b1 的
_data/_size
b1变成_data=nullptr, _size=0最后
main结束:
依次析构
v[2]、v[1]、v[0]、b1b1 已经是空壳,所以不会析构两次
结论:
- 传左值 → 只能拷贝构造(深拷贝 O(n) )
- 传右值 /
std::move→ 优先移动构造(偷指针 O(1) )
再来看下扩容版本:
cpp
void testExpand() {
cout << "=== 扩容场景: vector 重新分配 ===" << endl;
vector<buffer> v;
v.reserve(2);
cout << "\n push_back(b1) \n";
buffer b1(10);
v.push_back(b1);
cout << "\n push_back(b1) \n";
buffer b2(20);
v.push_back(b2);
cout << "\n 第三次 触发扩容机制 \n";
buffer b3(30);
v.push_back(b3);
cout << "=== 析构 ===" << endl;
}当 v 从容量 2 增长到 3 时,典型流程是:
- vector 申请一块更大的新空间(例如容量变成 4)
- 把旧空间中的元素一个个搬到新空间:
- 如果 T 有移动构造 → 调用移动构造(我们会看到"移动构造 buffer")
- 如果 T 只有拷贝构造 → 调用拷贝构造
- 析构旧空间中的对象
- 插入新的那个元素
因为我们给 buffer 提供了移动构造,大部分标准库实现都会优先用移动构造来搬元素,性能更好。
这就是右值引用 / 移动构造在容器内部的一个重要使用场景:
让容器扩容时不用对每个元素做深拷贝,而是快速"挪指针"。
3.5. 完美转发
3.5.1.写一个"转发函数"会丢掉左右值的信息
想象有一个需求:
写一个函数
void F(...),然后写一个函数Relay(...)记录日志后再把参数原样转发给F`
cpp
void F(int& x) { cout << "F(int& 左值)" << endl; }
void F(const int& x) { cout << "F(const int& 左值)" << endl; }
void F(int&& x) { cout << "F(int&& 右值)" << endl; }
void F(const int&& x) { cout << "F(const int&& 右值)" << endl; }
// 错误写法:
template<class T>
void Relay(T t) {
cout << "Relay\n";
F(t); // 会发生什么?
}
int main() {
int a = 10;
Relay(a); // 传左值
Relay(10); // 传右值
return 0;
}可能以为是:
- Relay(a) -> F(int&)
- Relay(10) -> F(int&&)
实际上:
-
模板参数推导:
-
Relay(a)时:T = int&, 参数类型按值传递,变成T t -> int t -
Relay(10)时:T = int, T t -> int t
-
-
在
Relay里面,t是变量名,一定是一个左值
所以:
F(t)永远只能匹配到左值版本,右值属性丢失了!
3.5.2.解决方案:万能引用+完美转发
万能引用
写成这样:
cpp
template <class T>
void Relay(T&& t){ F(t);}T&&在模板参数推导的场景下是万能引用,既能接收左值,也能接收右值:
- 传左值:T推导为
int&,形参类型由int&&折叠为int& - 传右值:T推导为
int,形参类型就是int&&
现在还有个问题:F(t)里面t还是左值
完美转发:根据T恢复原本的类型
std::forward做的事情是:根据模板参数T,判断传进来的是左值还是右值,然后把t转成对应的值类型
可以这样写:
cpp
template <class T>
void Relay(T&& t){
F(std::forward<T>(t));
}完整测试
cpp
// 正确写法:万能引用+完美转发
void F(int& x) { cout << "F(int& 左值)" << endl; }
void F(const int& x) { cout << "F(const int& 左值)" << endl; }
void F(int&& x) { cout << "F(int&& 右值)" << endl; }
void F(const int&& x) { cout << "F(const int&& 右值)" << endl; }
// 错误示范:丢失右值
template<class T>
void BadForward(T&& t) {
cout << "BadForward(T&& t):" ;
F(t); // t永远是左值
}
// 完美转发
template<class T>
void PerfectForward(T&& t) {
cout << "PerfectForward(T&& t):";
F(forward<T>(t));
}
int main() {
int a = 10;
const int ca = 20;
cout << "=== 传左值a ===\n";
BadForward(a);
PerfectForward(a);
cout << "\n=== 传const左值ca ===\n";
BadForward(ca);
PerfectForward(ca);
cout << "\n=== 传右值10 ===\n";
BadForward(10);
PerfectForward(10);
cout << "\n=== 传const右值10 ===\n";
BadForward(10);
PerfectForward(10);
return 0;
}最后的输出结果:
css
=== 传左值a ===
BadForward(T&& t):F(int& 左值)
PerfectForward(T&& t):F(int& 左值)
=== 传const左值ca ===
BadForward(T&& t):F(const int& 左值)
PerfectForward(T&& t):F(const int& 左值)
=== 传右值10 ===
BadForward(T&& t):F(int& 左值)
PerfectForward(T&& t):F(int&& 右值)
=== 传const右值10 ===
BadForward(T&& t):F(int& 左值)
PerfectForward(T&& t):F(int&& 右值)4.完美转发的应用------容器的emplace系列
4.1. 核心意义:原地构造+完美转发
而对于push_back/insert:先把传进来的参数变成一个临时对象,再拷贝/移动进容器
例如:
cpp
vector<string> v;
// push_back
v.push_back(string("111")); // 构造临时string 再移动进vector
// emplace
v.emplace_back("111"); // 直接在vector的内存里构造string("111")从语义上讲:
push_back:给我一个 已经构造好的 T 对象,我把它(拷贝/移动)到容器里emplace_back:给我一堆 构造 T 所需的参数 ,我在容器那块内存直接 new 一个 T(args...)
这就是"少了一次临时对象"的差别。
所以:真正的使用场景如下:
- 传的是构造参数如字面常量,多个内置类型,而不是已经构造好的对象
- 容器元素需要深拷贝的对象,如
string、自定义类、map的value等
底层模板模式:
cpp
template <class... Args>
void emplace_back(Args&&... args){
::new (end()) T(std::forward<Args>(args)...);
}Args&&...:万能引用std::forward<Args>(args)...:完美转发::new (end()):原地构造
4.2. 使用场景
4.2.1. 场景一:vector::emplace_backVSpush_back
cpp
struct Widget {
Widget(int x, int y) {
cout << "构造Widget(" << x << "," << y << ")\n";
}
Widget(const Widget&) {
cout << "拷贝构造Widget\n";
}
Widget(Widget&&) noexcept {
cout << "移动构造Widget\n";
}
};
int main() {
vector<Widget> v;
v.reserve(2);
cout << "push_back\n";
v.push_back(Widget(1, 2));
cout << "emplace_back\n";
v.emplace_back(1, 2);
return 0;
}逻辑执行:
push_back(Widget(1,2)):- 构造一个临时
Widget(1,2)→ 打印"构造 Widget(1,2)" push_back把这个临时对象移动构造进 vector → 打印"移动构造 Widget"- 临时对象析构
- 构造一个临时
emplace_back(1,2):- 在 vector 尾部的那块内存上直接调用
Widget(1,2)→ 只打印"构造 Widget(1,2)"
- 在 vector 尾部的那块内存上直接调用
差别:
push_back:构造 + 移动emplace_back:只构造一次
对大对象/复杂对象来说,少一次构造 + 移动,C++11 下是有价值的。
什么时候emplace_back没优势?
cpp
Widget w(1, 2);
v.push_back(w); // 左值:拷贝构造
v.emplace_back(w); // 拷贝构造
v.push_back(move(w)); // 右值:移动构造
v.emplace_back(move(w)); // 移动构造当已经存在了一个Widget对象,再使用emplace_back,本质上还是拷贝/移动构造,真正有意义的是:不先构造对象,直接给参数: v.emplace_back(1,2);
4.2.2. 场景二:map::emplaceVS insert
使用方式:
cpp
map<int, string> m;
// 写法一: 传pair所需的参数
m.emplace(2, "hh");
// 写法二: make_pair
m.emplace(make_pair(2, "hh"));
m.insert(make_pair(2,"hh"));对于m.emplace(2,"hh"),底层大概发生如下:
cpp
node* newnode = allocate_node();
::new (&newnode->value) std::pair<const int, std::string>(2, "hh"); // 原地构造
link_to_tree(newnode);对于m.insert(std::make_pair(2, "world")); 大概是:
- 先构造一个临时
std::pair<int, std::string>(2, "world") - 再用它拷贝/移动构造节点内部的
std::pair<const int, std::string>
所以:
- 用
emplace(key, value_args...)→ 少一次临时 pair - 用
emplace(make_pair(...))→ 和 insert 差不多,优势变小
4.3. 底层机制
所有容器的 emplace(C++11)基本遵循同一个模式:
cpp
template<class... Args>
iterator emplace(Args&&... args) {
// 1. 申请 / 找到一块原始内存(vector 尾部、list 节点、map 节点等)
void* p = allocate_raw_memory_for_one_T();
// 2. 在这块内存上原地构造对象(placement new + 完美转发)
::new (p) T(std::forward<Args>(args)...);
// 3. 把这个节点/元素挂到容器结构里(尾部、链表、红黑树、哈希表)
link_to_container(p);
return iterator_to(p);
}要意识到:
Args&&...:万能引用std::forward<Args>(args)...:完美转发,保证右值参数保持右值、左值保持左值::new (p) T(...):placement new,在已有内存上构造对象,不再 malloc
emplace 就是把这套模板模式应用到"插入元素"这个场景里。
那么在使用时就可以注意到:
-
有构造参数时 → 用 emplace
cppvector<std::string> v; v.emplace_back("hello"); // 优于 push_back(std::string("hello")); map<int, std::string> m; m.emplace(1, "hello"); // 优于 insert(std::make_pair(1,"hello")); -
已经有对象时 → push / emplace 都行
cppstd::string s = "hi"; v.push_back(s); // 拷贝 v.emplace_back(s); // 也是拷贝 -
对 node-based 容器(list/map/unordered_map)
- emplace 优势更纯粹一些(节点本来就分配,新元素原地构造,旧元素不动)
- 但仍然遵守上面两条规则
5. 可变参数模板
5.1. 是什么?
可变参数模板 = 模板参数可以是"0~N个"的一包东西,编译器会根据传入的实参个数和类型进行推导和展开
最基本的模板长这样:
c++
template <class... Args>
void Func(Args... args);class... Args:类型包Args... args:参数包(函数形参包)- 调用时,每个实参推导出一个类型,按照顺序装进
Args...
c++
template <class... Args>
void Debug(Args... args) {
// 这个写法很怪 sizeof...() 而其他是跟在class Args后面
cout << "参数个数: " << sizeof...(Args) << endl;
}
int main() {
Debug(1, 3.5, "hi", 'a');
return 0;
}对于Debug(1,3.5,"hi",'a');,编译器会做如下处理:
- 看到模板
Debug(Args... args)和调用了4个实参->Args...里面就必须有四个类型 - 对每个实参做普通模板的推导:
1->int3.5->double"hi"->const char*'a'->char
- 得到:
Args... = <int, double, const char*, char> - 实例化出具体版本:
c++
void Debug<int, double, const char*,char>(int, double, const char*,char);每个实参 → 一个类型 T_i → 按顺序排进 Args...,长度 = 实参数量。
5.2. 怎么用?
5.2.1. 参数包只能展开,不能索引
不能写args[0],只能用...拆包
一次性展开到一个函数里
c++
// 一次性展开到一个函数里
template <class... Args>
void call(void(*f)(Args...), Args... args) {
f(args...); // 展开成f(a,b,c...)
}用initial_list展开打印
c++
// 用initial_list展开打印
template<class... Args>
void Print(Args... args) {
int arr[] = { (cout << args << " ",0)... };
(void)arr;
// 数组只是为了展开参数包,并不会使用,这里明确告诉编译器,arr是故意不用的,别报警告
cout << endl;
}
int main() {
Print(1, 3.5, "hh", 'a');
return 0;
}详细拆解一下这段代码:
这段代码的核心是用一个临时数组arr来展开参数包
-
参数包
Args... args是多个参数的集合,必须用...展开 -
展开需要上下文,这里用到的是初始化列表
{...} -
{ (cout << args << " ",0)... }会将每一个args展开为一个表达式:c++(cout<<参数1)<<" ",0), (cout<<参数2)<<" ",0), (cout<<参数3)<<" ",0), (cout<<参数4)<<" ",0),然后将这四个值放入数组
arr中 -
为什么表达式要加", 0"?
因为初始化列表的元素必须要是同一类型,这里用了逗号表达式,返回最右边值的类型,将每项强制转成``int`类型,并且保留打印的功能
- 为什么用数组?
因为数组初始化列表会按照顺序执行每个元素的初始化,利用"顺序执行"特性,让cout打印顺序正确
arr数组本身并不重要,他的唯一目的是:让每个(cout<<args<<...)被依次执行
5.2.2. 搭配右值引用
这是模板:
cpp
// 搭配右值引用
template <class... Args>
void ForwardTo(FuncType f, Args&&... args) {
// 这个...又tm写到外面去了
f(forward<Args>(args)...);
}Args&&...: 万能引用,既能接收左值也能接收右值
forward<Args>(args)...:对每个参数恢复它原来的左值/右值属性->完美转发
配合容器的emplace:
c++
#include <vector>
template<class... Args>
void vector<T>::emplace_back(Args&&... args) {
::new ((void*)_finish) T(std::forward<Args>(args)...);
++_finish;
}可变参数模板 +
Args&&+std::forward就是emplace的逻辑:支持任意个构造参数,并保持每个参数原本的左值/右值属性,在容器内部原地构造对象
6. lambda表达式
6.1. 基本语法和用法
基本形式:
cpp
[capture_list](parameter_list) mutable ->return_type{
body;
};[capture_list]:捕获列表,编译器根据[]来判断接下来的代码是否为lambda函数,捕获列表可以捕获上下文中的变量供lambda使用(parameter_list):参数列表,和普通函数的参数列表一直,如果不传参,可以连同()一起省略mutable:默认情况,lambda是一个const函数,mutable可以取消常性。使用这个修饰符的时候,参数列表不能省略-> return_type:返回值类型{body;}:函数体,可以使用参数列表和捕获到的变量
最常见的:
cpp
auto f = [](int x) {return x * 2 };
int y = f(10);
// 算法里典型用法:
vector<int> v = {1,12,37,4,3};
sort(v.begin(),v.end(),[](int a, int b){ return a < b; });这里的[](int a, int b){...0}就是一个比较函数对象
6.2. 底层原理
lambda本质是一个编译器帮忙生成的匿名函数对象类 ,[]捕获的东西变成这个类的成员,函数体变成仿函数operator()
比如说:
cpp
int factor = 10;
auto f = [factor](int x){return x * factor;};编译器大致会生成一个类似这样的东西(伪代码):
cpp
struct __Lambda_1 {
int factor; // 捕获的变量变成成员
__Lambda_1(int f) : factor(f) {}
int operator()(int x) const { // 函数体变成 operator()
return x * factor;
}
};
int factor = 10;
__Lambda_1 f(factor); // 捕获时拷贝 factor
int y = f(3); // 调用 operator()(3)6.3. 捕获
6.3.1. 按值捕获[=]/[x]
cpp
void captureValue() {
int a = 10;
// a 是复制进来的,lambda 里面访问的是那份拷贝
auto f = [a]() { cout << a << endl; };
a = 20;
f();
int x = 1, y = 2, z = 3;
auto g = [=] {cout << x << ":" << y << ":" << z << endl; };
g();
}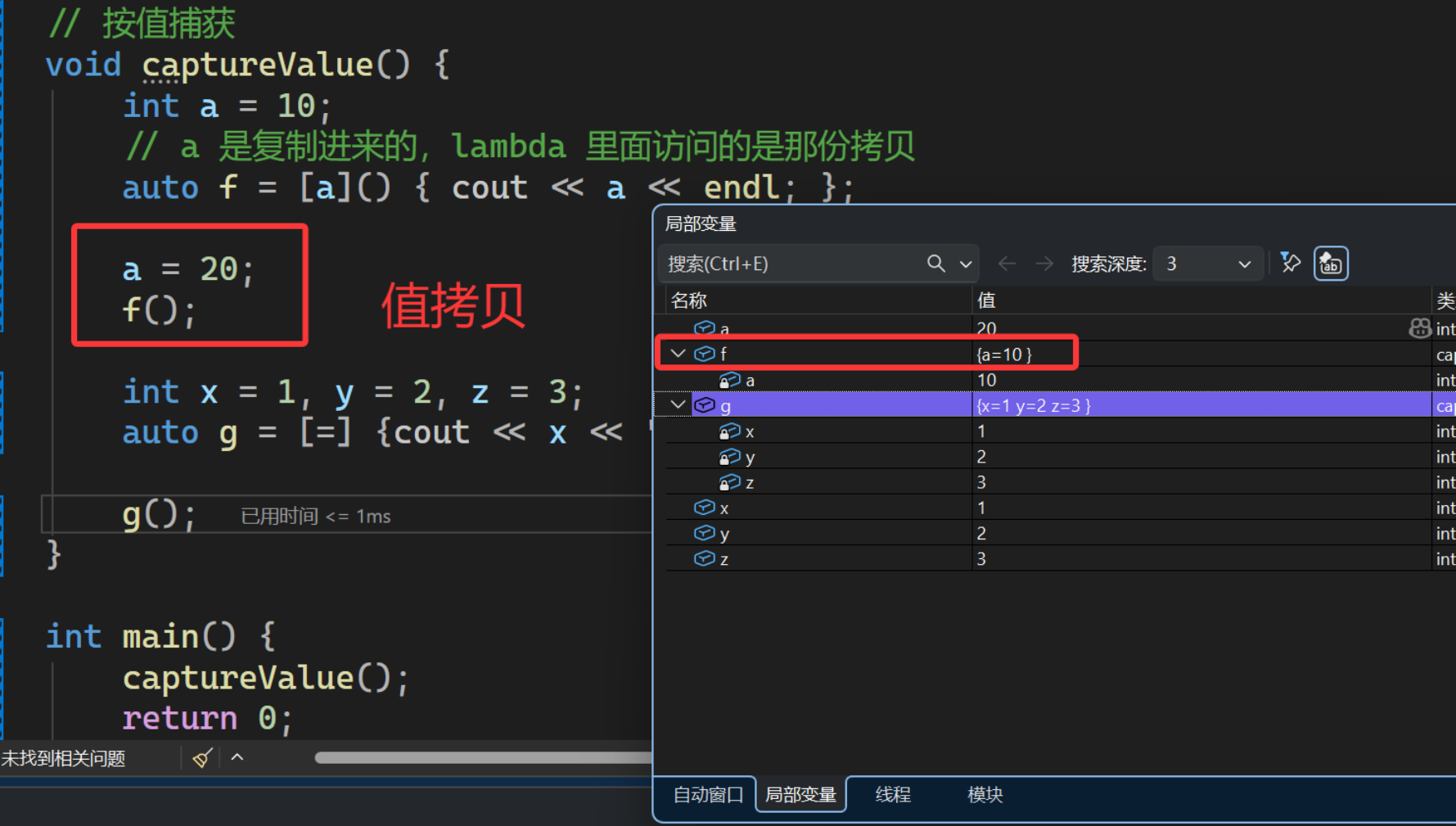
按值捕获会 拷贝一份当前的值 到 lambda 对象里,后面原变量变了,不影响 lambda已经拷贝的那份
6.3.2. 按引用捕获[&]/[&X]
cpp
// 按引用捕获
void captureRef() {
int a = 10;
// lambda 里面访问的是a的别名
auto f = [&a] {cout << a << endl; };
a = 20;
f();
int x = 1, y = 2, z = 3;
auto g = [&] {cout << x << ":" << y << ":" << z << endl; };
g();
}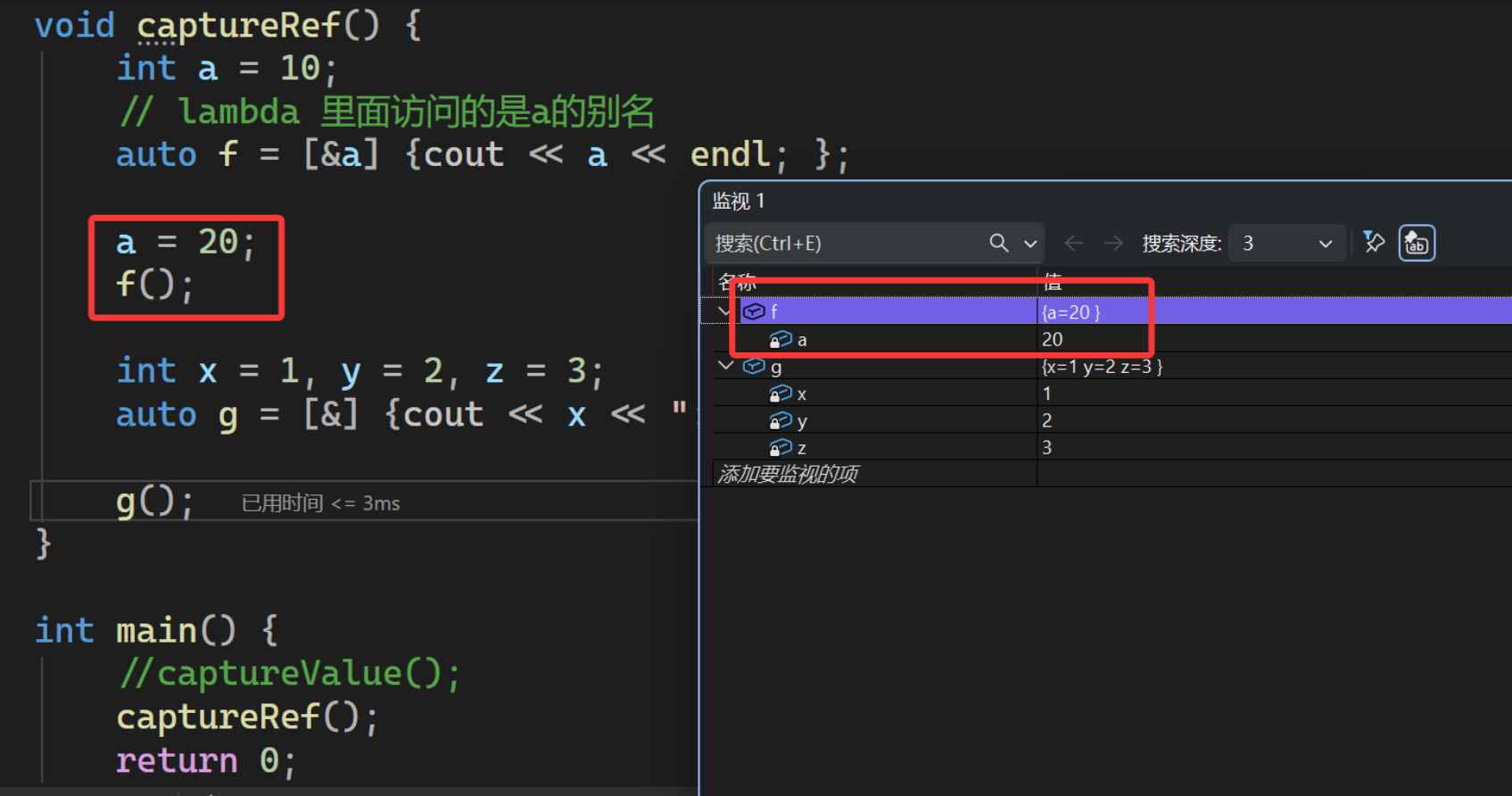
按引用捕获的是别名,对外部变量的修改、外部对变量的修改,都互相可见
危险点:如果外部变量已经被销毁了引用就悬空了
6.3.3. 混合捕获
cpp
// 混合捕获
void captureMixing() {
int a = 10, b = 20;
double c = 0.6;
// 错误写法 C++要求 默认方式捕获必须放到最前面,之后的特殊捕获随意
//auto f = [&b,=] {cout << a << ":" << b << ":" << c << endl; };
auto f = [=,&b] {cout << a << ":" << b << ":" << c << endl; };
f();
}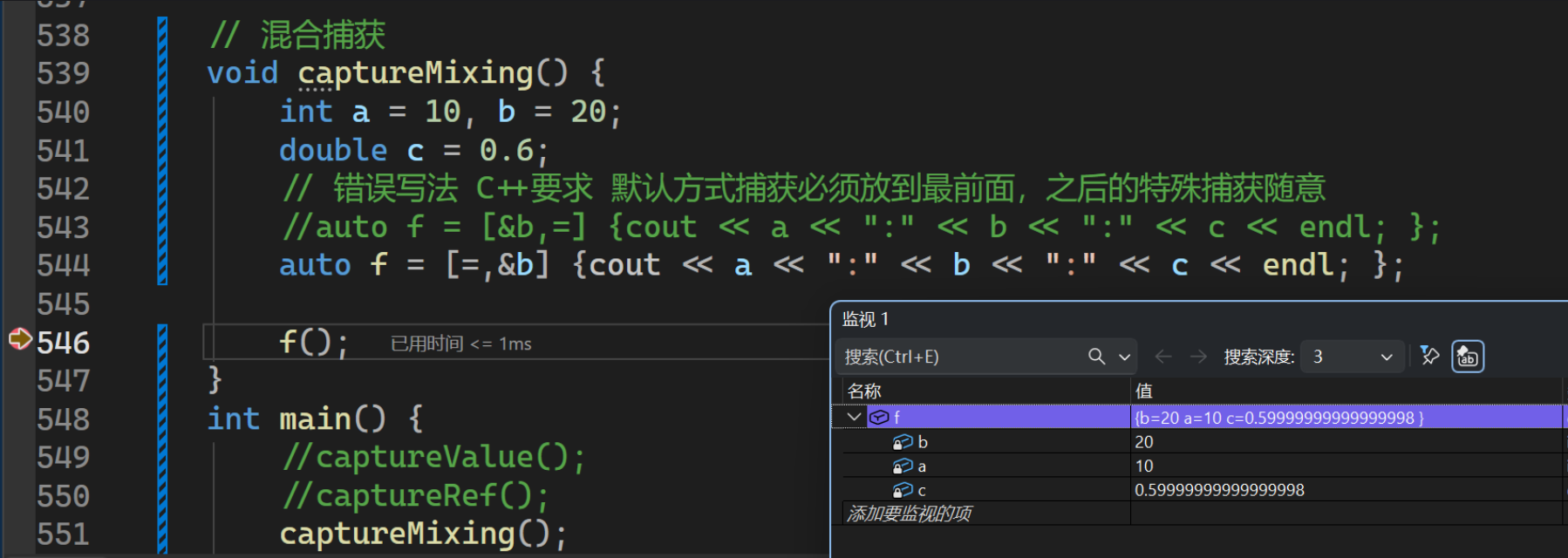
这里需要注意:默认捕获 要放到[]的最前面,之后个性化的捕获放后面
6.4. mutable 和const
默认情况下,按值捕获的lambda的operator()是const的:
cpp
void test() {
// 按值捕获的lambda是const的
int a = 10;
// error C3491: "a": 无法在非可变 lambda 中修改通过复制捕获
auto f = [a]() {a++; };
}如果想在lambda内部修改按值捕获的拷贝,要加mutable
cpp
int a = 10;
auto f = [a]()mutable {
// 改的是拷贝 不是外面的a
a++; cout << a << endl;
};
f(); // 11
f(); // 12
cout << a << endl; // 10重点:
mutable允许在lambda里修改"捕获的副本",而不是原变量- 不加
mutable,lambda的operator()是const成员函数,不能改成员(也就不能改按值捕获的变量)
6.5. lambda和函数对象
lambda = 仿函数 + 捕获能力 + 更好写法。
对于仿函数:
cpp
struct Rate{
double operator()(double money,int year) const{
return money * pow(1.05,year);
}
}
Rate r;
r(100,3);对于lambda:
cpp
auto r2 = [](double money, int year){
return money * pow(1.05,year);
}
r2(100,3);
底层都是一个对象调用了operator[]
总结:lambda 和仿函数有什么区别?
lambda本质上是编译器自动为生成的"匿名仿函数对象",内部是一个结构体 +operator()。和手写仿函数相比,
lambda` 更简洁、支持捕获上下文变量、默认 `operator()是const、更容易内联优化。两者本质相同,都是"可调用对象",但
lambda更适用于一次性的闭包场景,而仿函数更适用于需要反复复用的策略对象。
7. 包装器
7.0. 什么是可调用对象?
对于这段代码:
cpp
ret = func(x);func可能是什么?在C++中,能写成func(...)的,都可以叫可调用对象,包括了:
- 普通函数
- 函数指针
- 仿函数对象
lambda表达式对象
而包装器,就是用一个统一的类型装下这些可调用对象
7.1. 模板函数的问题
先看一段代码:
cpp
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
std::cout << "count:" << ++count << std::endl;
std::cout << "count:" << &count << std::endl;
return f(x);
}
double f(double i) { return i / 2; }
struct Functor {
double operator()(double d) { return d / 3; }
};
// 用三种方式调用
int main() {
// 函数名
std::cout << useF(f, 11.11) << std::endl;
// 函数对象(仿函数)
std::cout << useF(Functor(), 11.11) << std::endl;
// lambda 表达式
std::cout << useF([](double d)->double { return d / 4; }, 11.11) << std::endl;
}虽然useF看起来只有一个模板
但是:
-
第一次调用:
F = double(*)(double) -
第二次调用:
F = Functor -
第三次调用:
F =(某个 lambda 的匿名类型)
编译器实例化出了3个不同版本的useF
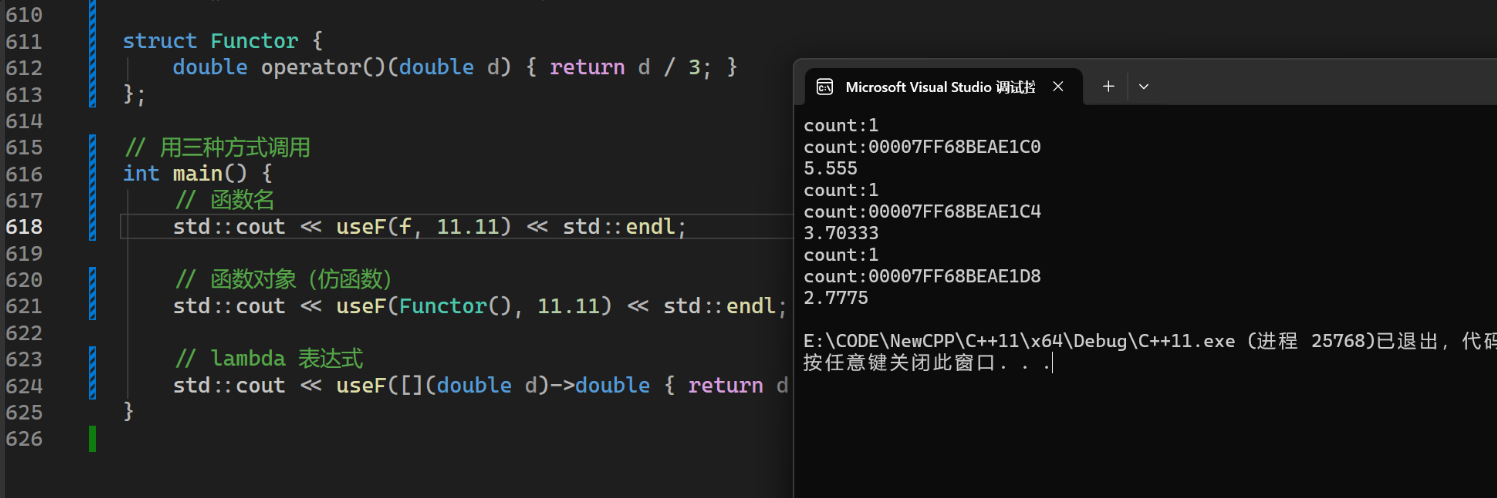
全局变量count有三个不同的地址,这种模式到处都是,在一个项目里,模板实例化会将项目变得很大,能不能有一种方式,把这些调用统一成一种类型?
7.2. 包装器
包装器的原型是:

cpp
template <class Ret, class... Args>
class function<Ret(Args...)>;std::function<Ret(Args...)> 就是一个"函数包装器类",能包装任何可以被当成 Ret(Args...) 来调用的东西。
cpp
#include <functional>
int f(int a, int b) { return a + b; }
struct Func {
int operator()(int a, int b) { return a + b; }
};
class Plus {
public:
static int plusi(int a, int b) { return a + b; }
double plusd(double a, double b) { return a + b; }
};
int main() {
// 1. 包普通函数/函数指针
function<int(int, int)> func1 = f;
cout << func1(1, 2) << endl;
// 2. 包仿函数
function<int(int, int)> func2 = Func();
cout << func2(1, 2) << endl;
// 3.包lambda
function<int(int, int)> func3 =
[](int a, int b) {return a + b; };
cout << func3(1, 2) << endl;
// 4. 包静态成员函数
function<int(int, int)> func4 = &Plus::plusi;
cout << func4(1, 2) << endl;
// 5. 包普通成员函数 需要把类也当参数传进去
function<double(Plus,double, double)> func5 = &Plus::plusd;
cout << func5(Plus(),1.0, 2.0) << endl;
return 0;
}同一个
std::function<int(int,int)>,
可以装 函数 / 函数指针 / 仿函数 / lambda / 成员函数指针。这就是它叫"包装器(适配器)"的原因:它帮你把不同种类的可调用对象适配成统一的类型。
7.3. 用包装器改造useF
cpp
#include <functional>
using namespace std;
// --------------------------------------------------------------------------
// 包装器版 useF:统一要求 "f 是一个能 T(T) 调的可调用对象"
// --------------------------------------------------------------------------
template <class T>
T useF(function<T(T)> f, T x) {
static int count = 0; // 静态变量:整个模板只实例化一次,只存在一份
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
// 调用包装器 f,它里面可能存着函数、lambda、仿函数
return f(x);
}
// --------------------------------------------------------------------------
// 一个普通函数 ------ 能被当成 double(double) 调用
// --------------------------------------------------------------------------
double f(double i) {
return i / 2;
}
// --------------------------------------------------------------------------
// 一个仿函数(函数对象) ------ 重载 operator(),可以 f(d) 调用
// --------------------------------------------------------------------------
struct Functor {
double operator()(double d) {
return d / 3;
}
};
int main()
{
// ----------------------------------------------------------------------
// 把不同类型的可调用对象"包装"成同一种类型
// function<double(double)> 就是一个固定类型的"可调用对象包装器"
// ----------------------------------------------------------------------
function<double(double)> func1 = f; // 包普通函数:f(double)
function<double(double)> func2 = Functor(); // 包仿函数对象 Functor()
function<double(double)> func3 = [](double d) {
return d / 4; // 包 lambda(匿名函数)
};
// ----------------------------------------------------------------------
// 三次 useF 调用,参数类型完全一样:
// useF<double>(function<double(double)>, double)
//
// 所以模板 useF 只实例化一份,静态变量 count 只有一个。
// ----------------------------------------------------------------------
cout << useF(func1, 11.11) << endl; // f(11.11) = 5.555
cout << useF(func2, 11.11) << endl; // Functor::operator()(11.11) = 3.7033
cout << useF(func3, 11.11) << endl; // lambda 的结果
return 0;
}useF 的参数类型固定为 std::function<double(double)>
- 不管传的是函数 / 仿函数 / lambda
- 对编译器来说,模板只实例化一次(T = double)
模板版本:编译期多态 ,性能最好,但容易导致模板膨胀
std::function版本:统一成一个类型,只实例化一次
7.4. 迷你包装器实现
cpp
template<class R, class... Args>
class MiniFunction {
void* obj; // 存真实对象
R (*caller)(void*, Args&&...); // 怎么调用
public:
template<class F> MiniFunction(F&& f) // 构造:存对象 + 存调用器
: obj(new F(std::forward<F>(f)))
, caller([](void* p, Args&&... as) -> R { // lambda 作为"调用器"
return (*static_cast<F*>(p))(std::forward<Args>(as)...);
}) {}
R operator()(Args... as) { // 对外调用统一接口
return caller(obj, std::forward<Args>(as)...);
}
};