【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(一)
分析了 Python 中 http.server 模块的一些内容,下面继续
Python http.server
上篇 blog 分析到了 http.server 的 head 方法,里面提到该方法只返回响应头,不返回响应主体内容 ,下面举几个会用到 head 方法的场景:
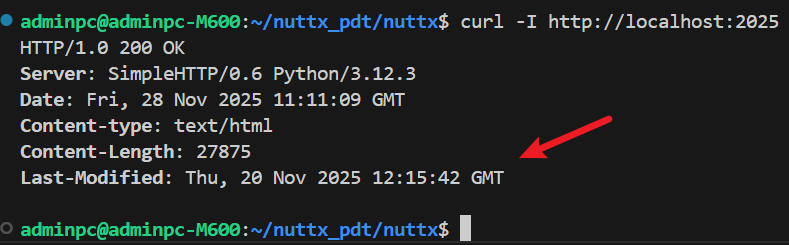
- 检查文件是否已更新(缓存验证) :比如浏览器之前加载过网页根目录
index.html,现在再次访问该页面,如果index.html比较大,那么浏览器肯定不想直接重新下载整个页面的,会浪费流量和时间 ,那这个时候浏览器就可以发一个head请求问 Web 服务器这个文件最近的修改时间如何,然后 Web 服务器返回响应头,浏览器就可以检查Last-Modified信息,如果Last-Modified没变,浏览器就可以继续使用本地缓存,而不用下载新文件
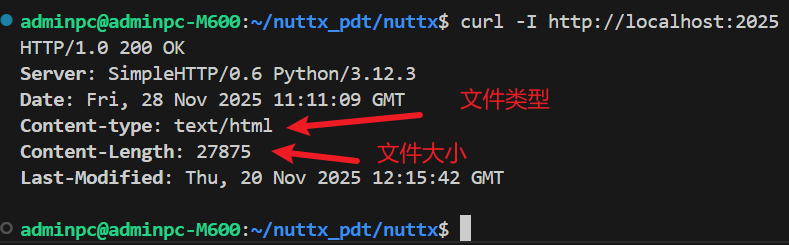
- 预检文件大小或类型 :比如浏览器上有某个
*.js脚本,当用户访问某在线视频播放器网站时,点击播放,该脚本可能先发HEAD请求检查,如果视频太大(比如>500MB),就提示该视频较大,建议在 Wi-Fi 下观看,或者如果类型不是video/mp4,就提示格式不支持等,从响应头中可以读取Content-Length(文件大小),Content-Type(文件类型)等信息 ,这样就可以不用下载整个视频,就能知道基本信息
- 爬虫或快速探测资源工具 :比如搜索引擎爬虫 想确认某个 URL 是否还有效(是返回
2xx还是4xx),那这时候发HEAD而不是GET,可以节省带宽和服务器压力,如果返回200 OK,才可能后续真正抓取内容
关于第一点使用场景 ,现代浏览器一般不会主动发纯 HEAD 请求,浏览器会更倾向于用带条件的 GET 请求做缓存,比如带 If-Modified-Since 的 GET 请求,但开发者,脚本,工具,爬虫,代理等会大量使用 HEAD 请求获取基本信息,而且几乎所有符合标准的 HTTP 服务器(包括 Python 自带的 http.server)也都会正确支持 HEAD 请求,不然会被认为不规范
关于带条件的 GET 请求,比如 If-Modified-Since,RFC 9110: HTTP Semantics 的 13. Conditional Requests 章节已有相关描述

OK,最后是 post 方法,HTTP 的 post 方法,是用来让客户端(比如浏览器)向 Web 服务器提交数据的,post 和 get 的最大区别是 get 是要东西,比如浏览器要首页,要涂片,要视频等,而 post 是给东西,比如浏览器要输入登录信息,或者写评论上传到 Web 服务器,关于 post 方法的典型使用场景如下:
- 表单提交 :用户填写注册,登录信息等后,点击提交或登录,浏览器将发送
post请求 - 上传文件:比如选择涂片,文档上传到 Web 服务器
- API 请求 :比如前端
*.js脚本向后端发送 json 数据
所有这些操作都有一个共同点,就是客户端主动发送数据给服务器,服务器要接收,处理,存储或响应这些请求 ,不过需要注意的是,对于 Python 的 http.server 模块,只有在 CGI 模式下,才支持 post 方法
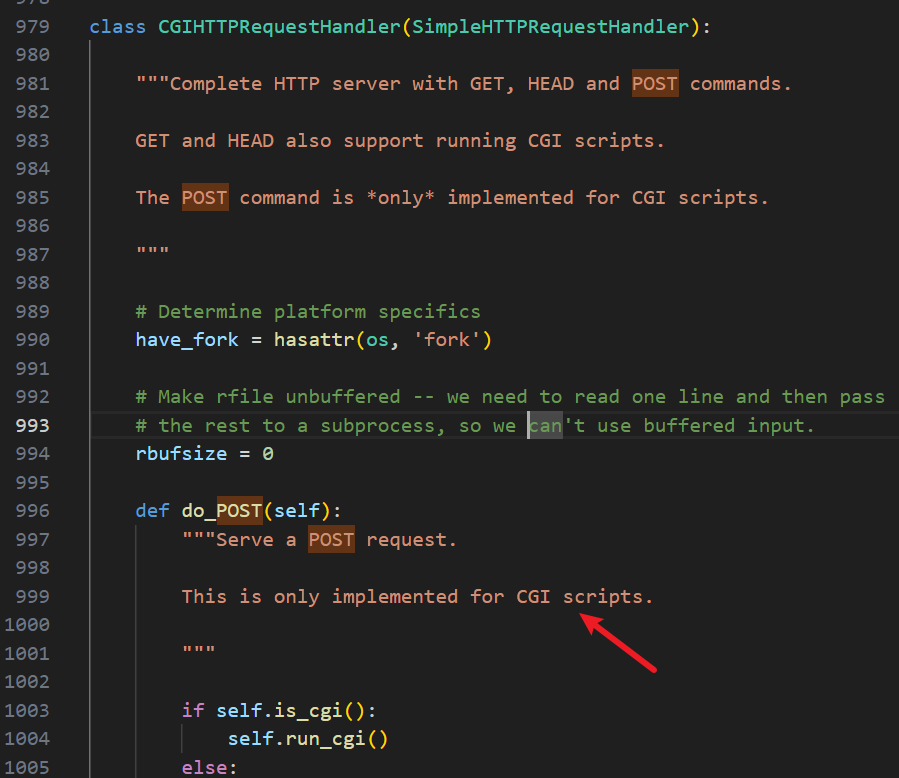
所以从这里也可以看出,Python 的 http.server 模块其设计目标主要还是作为一个静态文件服务器,把本地的 HTML,CSS,JS 等文件发给浏览器看,其内部没有逻辑要去处理浏览器提交的数据(主要依靠 CGI 脚本),既不会验证密码,也不会存评论,更不会返回动态结果
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog