这学期参加了同研究科的田中研的读书会,所选的是近年出的较新的书《Learning Theory from First Principles》[1]:

作者Francis Bach是COLT2025的keynote speaker[2]。我主动承担了4.1-4.4部分(这周做了分享),该部分和我目前的科研方向比较相关。下面是我结合自己的科研的一些心得和笔记。
1 导引
给定\(\mathcal{X}\times\mathcal{Y}\)上的联合概率分布\(p(x, y)\),以及损失函数\(L:\mathcal{Y}\times \mathcal{Y}\rightarrow \mathbb{R}\),定义预测函数\(h:\mathcal{X}\rightarrow \mathcal{Y}\)的期望风险(expected risk)(也称泛化误差(generalization error)或测试误差(testing error)):
\R(h)=\\mathbb{E}_{x, y}\[L(y, h(x)) = \int_{\mathcal{X}\times \mathcal{Y}}L(y, h(x))\mathrm{d} p \]
对于贝叶斯线性回归这类输出的是一个预测分布\(\hat{p}(t\mid x)\)的任务,其预测函数\(h(x)\)可以由条件期望\(h(x) = \mathbb{E}_tt\\mid x = \int t\mathrm{d}\hat{p}\)表示,于是其期望风险可以写为
\R(h) = \\int\\int_{\\mathcal{X}\\times \\mathcal{Y}}L(y, t)\\mathrm{d} p \\mathrm{d}\\hat{p} \\
注 当从数据中进行学习时,\(h\)依赖于随机训练数据而非测试数据,因此尽管\(R(h)\)的表达式中关于测试数据取了期望,但在通常情况下它仍然是随机的。然而,\(R(h)\)做为关于\(h\)的泛函是确定性的。
接下来考虑学习问题,给定从概率分布\(p(x, y)\)中i.i.d.采样的大小为\(n\)的随机样本,目标为学习一个预测函数\(h:\mathcal{X}\rightarrow \mathcal{Y}\)使得期望风险\(R(h)\)最小化,或等价地,使得下列超额风险(excess risk)(或称超额误差(excess error))最小:
\R(h) - R\^\* = R(h) - \\inf_{h \\space \\text{measurable}}R(h) \\
其中\(\inf_{h \space \text{measurable}}\)中的\(h\)为可测函数。在这篇博客中我们关注基于经验风险最小化方法的统计分析。
然而,以二分类问题为例,预测函数\(h\)是个布尔函数,在其假设空间中的经验风险最小化是难以处理的(intractable)组合优化问题。此外,分析这种布尔函数假设空间的复杂度可能需要进一步引入诸如VC维的工具。然而,可以通过凸代理损失的框架来学习一个实值函数\(f\)以将该问题凸化从而克服之。此时,我们就可以使用拉德马赫复杂度来对经验风险最小化的渐进收敛进行分析。
考虑二分类场景,做为直接学习\(h: \mathcal{X}\rightarrow \left\{-1, +1\right\}\)的替代,我们采用学习实值函数\(f: \mathcal{X}\rightarrow\mathbb{R}\)(其对应的函数族为\(\mathcal{F}\))的方法,并定义\(h(x) = \mathrm{sign}(f(x))\),其中
\h(x) = \\left\\{\\begin{aligned} +1 \\quad f(x) \\geqslant 0\\\\ -1 \\quad f(x) \< 0 \\end{aligned} \\right. \\
我们将关于函数\(h = \text{sign}\circ f\)的的0-1风险直接记为\(R_{\text{0-1}}(f)\),它可以表示为:
\R_{\\text{0-1}}(f) = \\mathbb{E}_{x, y}\\left\[\\underbrace{\\mathbb{I}\\left(yf(x)\\leqslant 0\\right)}_{\\mathclap{\\Phi_{\\text{0-1}}\\left(yf(x)\\right)}}\\right \]
注意,这里出于简洁,未严格讨论\(f(x)=0\)的情形。记\(\mathbb{I}\left(yf(x)\leqslant 0\right):= \Phi_{\text{0-1}}\left(yf(x)\right)\),其中\(\Phi_{\text{0-1}}\left(\cdot\right)\)称为"基于间隔的"0-1损失函数(注意与满足定义\(L_{\text{0-1}}(h(x), y) = \mathbb{I}\left(h(x)\neq y\right)\)的0-1损失函数\(L_{\text{0-1}}(\cdot, \cdot)\)相区分)。
2 凸代理
优化上述\(R(f)\)的经验版本\(\frac{1}{m}\sum_{i=1}^m\mathbb{I}\left(y_if(x_i)\leqslant 0\right)\)是NP-hard的(由于\(\mathbb{I}\left(yf(x)\leqslant 0\right)\)非凸不连续),因此我们可以考虑使用凸代理(convex surrogates) 技术对目标函数\(\Phi_{\text{0-1}} = \mathbb{I}\left(yf(x)\leqslant 0\right)\)进行凸放松,其中我们使用具有更好的数值属性的函数\(\Phi\)(主要是凸性)对\(\Phi_{\text{0-1}}\)进行替代。下面是一些凸代理损失函数的例子[3]:
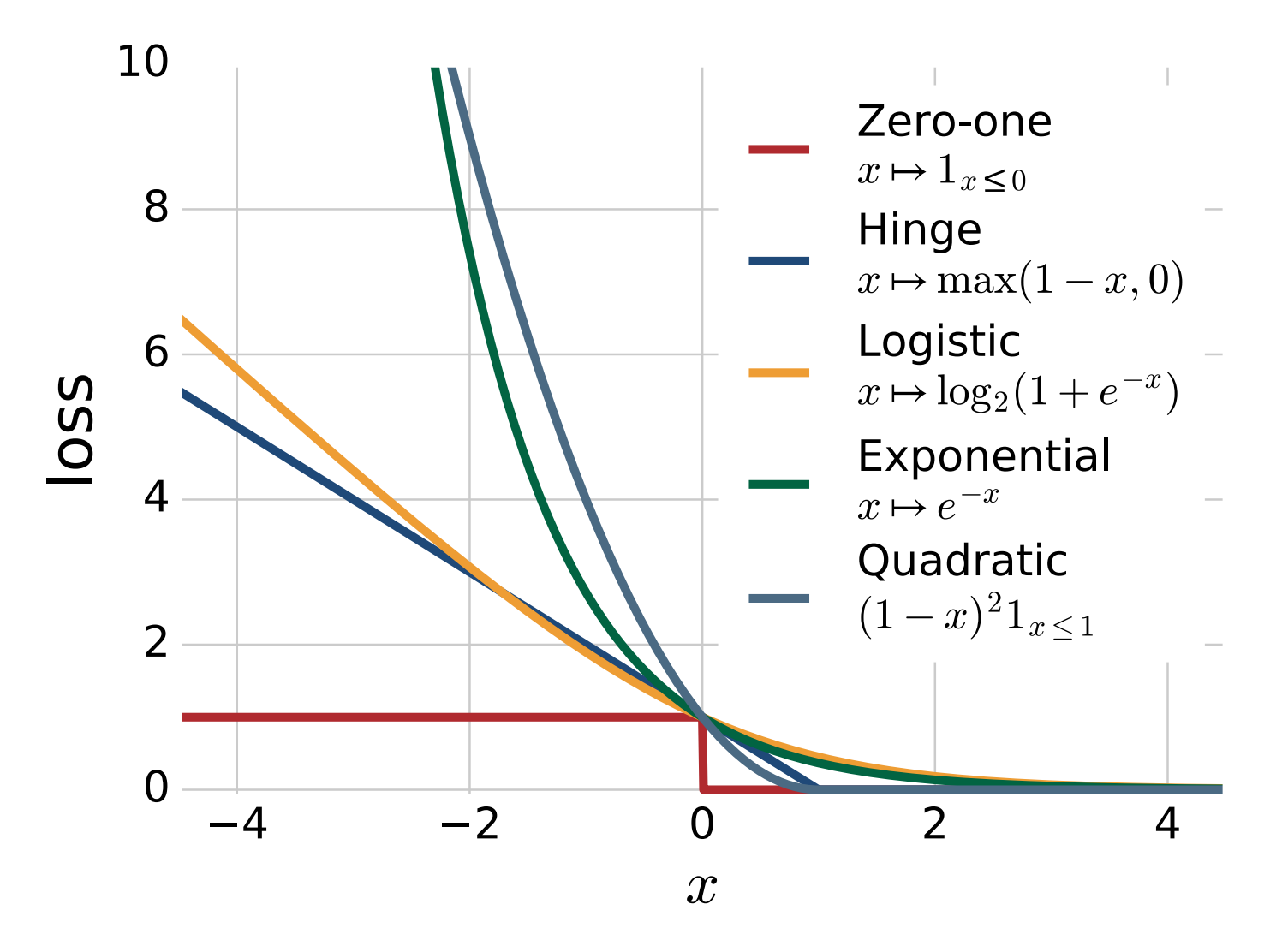
注 深度学习中的sigmoid函数\(\Phi(t) = 1 / (1 + e^{-t})\)也可以看做一种针对\(\frac{1}{2}\mathbb{I}(t\geqslant 0)\)的光滑连续的非凸替代函数[5]。
于是,做为对直接优化0-1风险\(R_{\text{0-1}}(f)\)(或其经验版本)的替代,我们转而优化下列的代理风险\(R_{\Phi}(f)\)(及其经验版本):
\R_{\\Phi}(f) = \\mathbb{E}_{x, y}\\left\[\\Phi(yf(x))\\right \]
3 校准与条件风险
理想的代理损失函数\(\Phi\)应该满足代理风险一致性(Surrogate risk consistency) [4][5]:在总体层面上对\(\Phi\)-风险的优化能够确保优化对0-1风险的优化:
代理风险一致性 (Surrogate risk consistency) 若对优化代理经验风险得到的任意函数序列\(\hat{f}_1, \hat{f}_2, \cdots, \hat{f}_m, \cdots\),以及任意分布\(p(x, y)\)满足:
\R_{\\Phi}(f_m)\\xrightarrow{m\\rightarrow \\infty} R_{\\Phi}\^\* \\Longrightarrow R_{\\text{0-1}}(f_m)\\xrightarrow{m\\rightarrow \\infty} R\^\*_{\\text{0-1}} \\
则称损失\(\Phi\)对原目标损失\(\mathcal{\Phi}_{\text{0-1}}\)是代理风险一致 的,或Bayes一致 的/Fisher一致 的,有时也称代理损失函数\(\Phi\)是校准 (calibrated) 的。直观地理解可以参见下图[6]:

直观理解地,代理风险一致性也就意味着能够最小化\(R_{\Phi}(f)\)的输出函数也能够最小化\(R_{\text{0-1}}(f)\) 。那么我们接下来先来考虑最小化\(R_{\text{0-1}}(f)\)的问题。
\R_{\\text{0-1}}(f) = \\mathbb{E}_{x, y}\\left\[\\Phi_{\\text{0-1}}\\left(yf(x)\\right)\\right \]
为了进一步简化后续的分析,我们根据条件期望以及其相关的全期望定理,将\(R_{\text{0-1}}(f)\)写为:
\\\begin{aligned} R_{\\text{0-1}}(f) \&=\\mathbb{E}_{x}\\left\[\\mathbb{E}_{y}\\left\[\\Phi_{\\text{0-1}}\\left(yf(x)\\right)\\mid x\\right\right] \\ &= \mathbb{E}{x}\underbrace{\left\\eta(x)\\Phi_{\\text{0-1}}\\left(f(x)\\right) + (1 - \\eta(x))\\Phi_{\\text{0-1}}\\left(-f(x)\\right)\\right}{\text{conditional risk }C_{\text{0-1}}} \end{aligned} \]
其中\(\eta(x) = p(y=+1\mid x)\),我们有\(\mathbb{E}y\\mid x = 2\eta(x) - 1\)。我们称其中内层的条件期望项为0-1间隔损失\(\Phi_{\text{0-1}}\)的条件风险(conditional risk) (也称为pointwise风险[2]),由于在其计算过程中\(y\)取期望取掉了,因此该项只和\(f(x)\)相关,因此我们将其记为\(C_{\text{0-1}}(f)\):
\\\begin{aligned} C_{\\text{0-1}}(f) \&= \\mathbb{E}_{y}\\left\[\\Phi_{\\text{0-1}}\\left(yf(x)\\right)\\mid x\\right \\ & = \eta(x)\Phi_{\text{0-1}}\left(f(x)\right) + (1 - \eta(x))\Phi_{\text{0-1}}\left(-f(x)\right) \end{aligned} \]
我们用\(C^*{\text{0-1}} = \inf{f} C_{\text{0-1}}(f)\)来表示最优的\(\Phi_{\text{0-1}}\)的条件风险,可得
\ C\^\*_{\\text{0-1}} = \\min\\left\\{\\eta(x), 1 - \\eta(x)\\right\\} \\
而最优\(0-1\)风险(也称贝叶斯风险(Bayes risk))可以表示为:
\ R_{\\text{0-1}}\^\* = \\mathbb{E}_{x}\\left\[\\min\\left\\{\\eta(x), 1 - \\eta(x)\\right\\}\\right \]
上式也可进一步写为 R_{\\text{0-1}}\^\* = \\mathbb{E}_{x}\\left\[\\frac{1}{2} - \\frac{1}{2}\\left\|\\mathbb{E}\[y\\mid x\]\\right\|\\right\]。
此时最优实值函数(也称贝叶斯实值函数(Bayes real-valued function) )\(f^*{\text{0-1}}\)需要满足当\(\eta(x) < \frac{1}{2}\)时,\(f^*{\text{0-1}}(x) < 0\),当\(\eta(x) > \frac{1}{2}\)时,\(f^*{\text{0-1}}(x) > 0\),当\(\eta(x)=\frac{1}{2}\)时,\(f^*{\text{0-1}}(x)\)可以是任意实数。于是,\(f^*_{\text{0-1}}\)满足:
\f\^\*_{\\text{0-1}}\\in \\mathcal{F}\^\* = \\left\\{f: \\begin{aligned} \&\\text{当} \\eta(x) = \\frac{1}{2} \\text{时} f(x) \\text{可以是任意的实数;}\\\\ \&\\text{当} \\eta(x) \\neq \\frac{1}{2} \\text{时} \\underbrace{f(x)(\\eta(x) - \\frac{1}{2}) \> 0}_{f(x) \\text{与} 2\\eta(x) - 1 (=\\mathbb{E}\[y\|x)\text{同号}} \end{aligned}\right\} \]
我们称满足\(h^* = \mathrm{sign}(2\eta - 1)\)(\(=\mathrm{sign}\left(\mathbb{E}y\|x\right)\))的分类器为贝叶斯最优分类器,或直接简称为贝叶斯分类器(Bayes's classifier) 。这里可以与在线性回归问题中得到的最优预测器\(h^* = \mathbb{E}y\|x\)进行对照。
我们用\(C_{\Phi}\)来表示代理损失\(\Phi\)的条件风险,并用\(C^*{\Phi}\)来表示其对应的最优条件风险,用\(R^*{\Phi}\)来表示其对应的最优期望风险。
由上述内容可知,对于代理损失\(\Phi\)而言,如果也能确保其对应的最优实值输出函数\(f_{\Phi}^*\)在\(\eta(x) \neq \frac{1}{2}\)时与\(2\eta(x) - 1\)同号,那么它就是校准的。
可以证明,当\(\Phi\)为凸函数时,存在一个可用的校准充要条件,如下述命题所示:
命题 [8] 设\(\Phi: \mathbb{R}\rightarrow \mathbb{R}\) 为凸函数。代理函数\(\Phi\)是校准的当且仅当\(\Phi\)在\(0\)处可微且\(\Phi^{\prime}(0) < 0\)。
证明 由于\(\Phi\)是凸的,则\(C_{\Phi}\)也是凸的,因此可以考虑\(\eta(x)\neq \frac{1}{2}\)时, \(C_{\Phi}(f)\)在0处的左和右导数以对关于最小值的位置进行分类讨论,有如下所示的\((a)\)和\((b)\)两种可能(最优点 f\^*(x)\> 0\\(当且仅当在0点的右导数严格为负, 最优点\\) f\^*(x) \< 0当且仅当在0点的左导数严格为正):
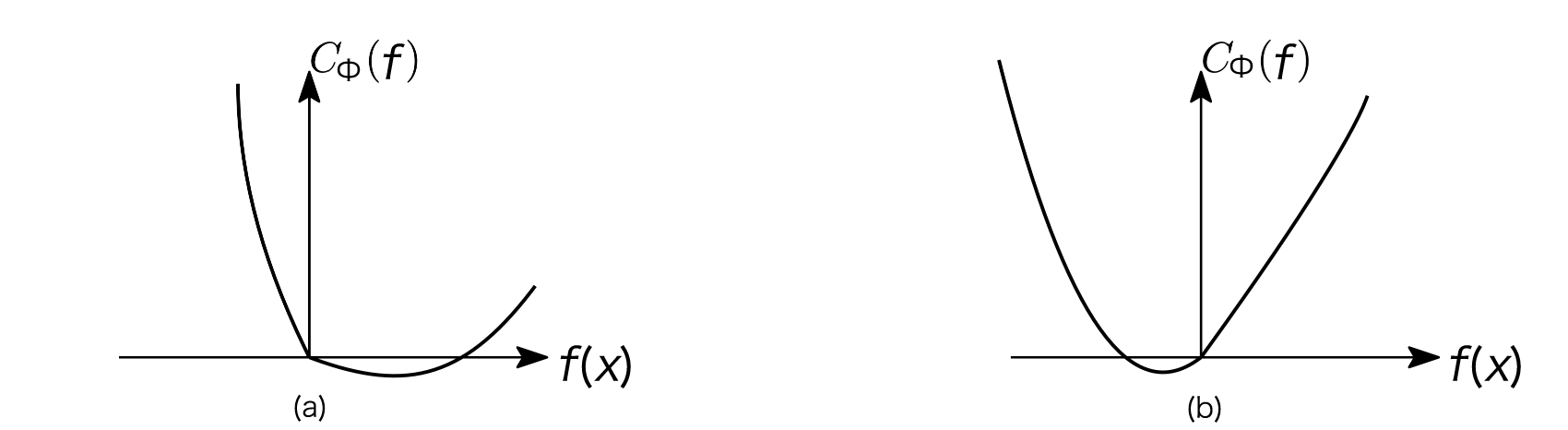
(a) \(f^*{\Phi}(x) > 0 \Leftrightarrow C{\Phi}^{\prime}(0_{+}) = \eta(x)\Phi^{\prime}\left(0_{+}\right) - (1 - \eta(x))\Phi^{\prime}\left(0_{-}\right) < 0\)
(b) \(f^*{\Phi}(x) < 0 \Leftrightarrow C{\Phi}^{\prime}(0_{-}) = \eta(x)\Phi^{\prime}\left(0_{-}\right) - (1 - \eta(x))\Phi^{\prime}\left(0_{+}\right) > 0\)
先证明充分性。假设\(\Phi\)是校正的。如令上述等式\((a)\)中的\(\eta\rightarrow {\frac{1}{2}}{+}\),这将导致\(C{\Phi}^{\prime}(0_{+}) = \frac{1}{2} \left\\Phi\^{\\prime}\\left(0_{+}\\right) - \\Phi\^{\\prime}\\left(0_{-}\\right)\\right\leqslant 0\)。由于\(\Phi\)是凸的,等式\(\Phi^{\prime}\left(0_{+}\right) - \Phi^{\prime}\left(0_{-}\right)\geqslant 0\)恒成立。因此,\(\Phi^{\prime}\left(0_{+}\right) = \Phi^{\prime}\left(0_{-}\right)\),这意味着\(\Phi\)在\(0\)处是可微的。由\((a), (b)\)与之前提到的同号条件可得,\(\Phi^{\prime}(0) < 0\)。
再证明必要性。假设\(\Phi\)在0点是可微的且\(\Phi^{\prime}(0) < 0\),则\(C_{\Phi}^{\prime}(0) = (2\eta - 1)\Phi^{\prime}(0)\),则由\((a), (b)\)可得之前提到的同号条件。于是原命题得证。
注意上述命题排除了凸代理\(\Phi(f) = (1-f)+ = \max\left\{1-f, 0\right\}\),该函数在0点处不可微。此外,之前我们在第2部分提到的所有代理损失函数的例子都是校准的。
注 在使用概率模型进行分类的情况下,若学习\(p(y=1\mid x)\)的模型,则校准也可能指关于这个概率的估计的准确度。
4 代理损失函数的超额风险界
由前文叙述可知,任意\(x\in \mathcal{X}\),若代理损失函数\(\Phi\)是校准的,则最小化条件代理风险\(C_{\Phi}(f)\)可以得到最优预测函数\(h^* = \text{sign}(f^*)\)。这个结果是当样本数量\(m\rightarrow \infty\)时的渐近(asymptotic)结果。
接下来,我们要更进一步,得到一个非渐进(non-asymptotic)的结果:如果能够控制代理超额风险(可以通过经验风险最小化达到),就能够控制目标超额风险。形式化地说,我们需要证明如下所示的代理损失函数的超额风险界:
\ R_{\\text{0-1}}(f) - R\^\*_{\\text{0-1}}\\leqslant \\Gamma\\left(R_{\\Phi}(f) - R_{\\Phi}\^\*\\right) \\
对\(\forall f(x)\in \mathbb{R}\)成立,其中\(\Gamma: \mathbb{R}{+}\rightarrow \mathbb{R}{+}\)为满足属性\(\lim_{t\rightarrow 0^{+}}\Gamma (t) = 0\)的非递减函数。
函数\(\Gamma(t)\)有时被称为校准函数(calibration function) 或 超额风险率(excess risk rate) 。这里我们关注当\(t\rightarrow 0^{+}\)时,函数\(\Gamma(t)\)的表现。后面我们会证明hinge损失的校准函数是\(\mathcal{O}(t)\)的,而诸如平方和logistic损失的光滑凸代理则可能会导致\(\mathcal{O}(\sqrt{t})\)的校准函数。
注 由于这里我们关注的是\(t\rightarrow 0^{+}\)时的情况,所以\(\mathcal{O}(t)\)是比\(\mathcal{O}(\sqrt{t})\)更紧的结果。因此,尽管hinge损失在光滑的性质上没平方和logistic损失那么好,但它所导出的校准函数结果更好,这也是一种"权衡"的体现。
现在我们考虑将期望风险转换为我们之前提到的条件风险以简化分析。由条件风险的定义可得,对\(\forall f(x)\in \mathbb{R}\),有
\\\begin{aligned} \\mathbb{E}_x\\left\[C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\*\\right\leqslant \Gamma\left(\mathbb{E}_x\leftC_{\\Phi}(f) - C_{\\Phi}\^\*\\right\right) \end{aligned} \]
若函数\(\Gamma\)是凹函数,则可利用Jensen不等式得到
\\\mathbb{E}_x\\left\[C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\*\\right\leqslant \mathbb{E}_x\left\\Gamma\\left(C_{\\Phi}(f) - C_{\\Phi}\^\*\\right)\\right \]
于是,若能证明\(C_{\text{0-1}}(f) - C_{\text{0-1}}^*\leqslant \Gamma(C_{\Phi}(f) - C_{\Phi}^*)\)对\(\forall f(x)\in \mathbb{R}\)成立,则代理损失函数的超额风险界得证。
超额条件0-1风险的表达式
接下来我们考虑对\(C_{\text{0-1}}(f) - C_{\text{0-1}}^*\)进行表示。由前面提到的知识可知:
\C_{\\text{0-1}}(f) - C\^\*_{\\text{0-1}} = \\eta\\Phi_{\\text{0-1}}\\left(f\\right) + (1 - \\eta)\\Phi_{\\text{0-1}}\\left(-f\\right) - \\min\\left\\{\\eta, 1 - \\eta\\right\\} \\
接下来我们需要对\(\eta(x)\)和\(f(x)\)的取值情况进行分类讨论:
-
\(\eta(x) = \frac{1}{2}\):
\(C_{\text{0-1}}(f) = \eta\Phi_{\text{0-1}}\left(f\right) + (1 - \eta)\Phi_{\text{0-1}}\left(-f\right) = \frac{1}{2}\)为常值函数,故\(C_{\text{0-1}}(f) - C_{\text{0-1}}^* = 0\)。
-
\(\eta(x) > \frac{1}{2}\):
此时\(C^*_{\text{0-1}} = 1 - \eta\)(在 f(x) \> 0时取得)。
a. 当\(f(x) \leqslant 0\)时,\(C_{\text{0-1}}(f) - C_{\text{0-1}}^* = 2\eta - 1\);
b. 当\(f(x) > 0\)时,\(C_{\text{0-1}}(f) - C_{\text{0-1}}^* = 0\)。
于是可以得到
\ \\forall f(x)\\in \\mathbb{R}, C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\* = \\left(2\\eta - 1\\right)\\Phi_{\\text{0-1}}\\left(f\\right) \\
-
\(\eta < \frac{1}{2}\):
同理可得\(C_{\text{0-1}}(f) - C_{\text{0-1}}^* = \left(1 - 2\eta(x)\right)\Phi_{\text{0-1}}(-f(x))\)。
综上所述,对任意\(\eta(x)\in 0, 1\):
\ \\forall f(x)\\in \\mathbb{R}, C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\* = \|2\\eta - 1\|\\Phi_{\\text{0-1}}\\left((2\\eta - 1)f\\right) \\
我们也可以对其进行放松,以得到一个更加实用的结果:
\\\begin{aligned} \\forall f(x)\\in \\mathbb{R}, C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\* \&\\leqslant \|2\\eta - 1 - b(f)\|\\Phi_{\\text{0-1}}\\left((2\\eta - 1)f\\right)\\\\ \&\\leqslant \|2\\eta - 1 - b\\left(f\\right)\| \\end{aligned} \\
其中\(b(f)\)为不改变\(f(x)\)符号的保号函数。
平方代理损失 对平方代理损失\(\Phi(f) = (f - 1)^2\),我们有
\\\begin{aligned} C_{\\Phi}(f) = \\eta(f - 1)\^2 + (1 - \\eta)(-f - 1)\^2 \\end{aligned} \\
\(C_{\Phi}^{\prime}(f) = 0\)当且仅当\(f^{*}{\Phi} = 2\eta - 1\)时满足,此时有\(C{\Phi}^* = 4\eta(1 - \eta)\),故
\\\begin{aligned} C_{\\Phi}(f) - C_{\\Phi}\^\* \&= f\^2 - 2\\left(2\\eta - 1\\right)f + (2\\eta - 1)\^2\\\\ \&= \\left(f - \\left(2\\eta - 1\\right)\\right)\^2\\\\ \&= (2\\eta - 1 - f)\^2 \\\\ \&\\geqslant \\left(C_{\\text{0-1}}(f) - C\^\*_{\\text{0-1}}\\right)\^2 \\quad (b(f) = f) \\end{aligned} \\
于是就能得到\(\Gamma(t) = \mathcal{O}(\sqrt{t})\)的平方代理损失的超额风险界;
\R_{\\text{0-1}}(f) - R_{\\text{0-1}}\^\*\\leqslant (R_{\\Phi}(f) - R\^\*_{\\Phi})\^{\\frac{1}{2}} \\
我们接下来会扩展到更一般的光滑代理的校准结果。
光滑代理损失 我们考虑形式为\(\Phi(f) = F(f) - f\)的光滑代理损失(可加上任意乘性常数缩放及加性常数平移),其中对平方代理损失而言\(F(f) = \frac{1}{2}f^2\),可验证此时
\ \\Phi(f) = \\frac{1}{2}f\^2 - f = \\frac{1}{2}(f - 1)\^2 - \\frac{1}{2} \\
对logistic代理损失而言\(F(f) = 2\log (e^{f/2} + e^{-f/2})\),可验证此时
\\\begin{aligned} \\Phi(f) \&= 2\\log(e\^{f/2} + e\^{-f/2}) - f\\\\ \&= 2\\log(e\^{f/2} + e\^{-f/2}) - 2\\log e\^{f/2}\\\\ \&= 2\\log(\\frac{e\^{f/2} + e\^{-f/2}}{e\^{f/2}})\\\\ \&= 2\\log(1 + e\^{-f}) \\end{aligned} \\
我们假设\(F\)为偶函数且\(\beta-\)光滑(\(\beta > 0\))这意味着对于所有的\(f \in \mathcal{F}\)和\(\alpha \in \mathbb{R}\),有
\F(f) - \\alpha f(x) - \\inf_{f\\in \\mathcal{F}}\\left\\{F(f) - \\alpha f\\right\\}\\geqslant \\frac{1}{2\\beta}\|\\alpha - F\^{\\prime}(f)\|\^2 \\
注 这里的一种证明方法是使用Fenchel共轭[7]\(F^*: \mathcal{F}\rightarrow\mathbb{R}\),它是\((1/\beta)\)-强凸的。我们有
\\\begin{aligned} \&F(f) - \\alpha f(x) - \\inf_{f\\in \\mathcal{F}}\\left\\{F(f) - \\alpha f\\right\\}\\\\ \&= \\underbrace{F(f) }_{\\sup_{\\alpha\\in \\mathbb{R}}\\left\\{f\\alpha - F\^\*(\\alpha)\\right\\}}- \\alpha f(x) + \\underbrace{\\sup_{f\\in \\mathcal{F}}\\left\\{\\alpha f - F(f)\\right\\}}_{F\^\*(\\alpha)}\\\\ \&= F\^\*(\\alpha) - f(x)\\alpha + \\sup_{\\alpha\\in \\mathbb{R}}\\left\\{f(x)\\alpha - F\^\*(\\alpha)\\right\\}\\\\ \&= F\^\*(\\alpha) - f(x)\\alpha - \\inf_{\\alpha\\in \\mathbb{R}}\\left\\{F\^\*(\\alpha) - f(x)\\alpha \\right\\}\\\\ \&\\geqslant \\frac{1}{2\\beta}\\lVert \\alpha - F\^{\\prime}(f)\\rVert\^2 \\end{aligned} \\
其中\(F^{\prime}(f) = \inf_{\alpha\in \mathbb{R}}\left\{F^*(\alpha) - f(x)\alpha\right\}\)。
由\(\Phi(f) = F(f) - f\)且\(F(f)\)为偶函数,代入可得\(C_{\Phi}(f) = \eta\Phi(f) + (1 - \eta)\Phi (-f) = F(f) - (2\eta - 1)f(x)\),因此
\\\begin{aligned} C_{\\Phi}(f) - C_{\\Phi}\^\* \&= F(f) - (2\\eta - 1)f - \\inf_f\\left\\{F(f) - (2\\eta - 1)f\\right\\}\\\\ \&\\geqslant \\frac{1}{2\\beta}(2\\eta - 1 - F\^{\\prime}(f))\^2 \\\\ \&\\geqslant \\frac{1}{2\\beta}\\left\[C_{\\text{0-1}}(f) - C_{\\text{0-1}}\^\*\\right^2 \end{aligned} \]
这将得出\(\Gamma(t) = \sqrt{2\beta t} = \mathcal{O}(\sqrt{t})\)的代理损失函数的超额风险界:
\R_{\\text{0-1}}(f) - R\^\*_{\\text{0-1}}\\leqslant \\sqrt{2\\beta}(R_{\\Phi}(f) - R\^\*_{\\Phi})\^{\\frac{1}{2}} \\
hinge损失[5]
对hinge损失\(\Phi(f) = (1-f)+ = \max\left\{1-f, 0\right\}\),我们有
\\\begin{aligned} C_{\\Phi}(f) = \\eta\\max\\left\\{1-f, 0\\right\\} + (1 - \\eta)\\max\\left\\{1+f, 0\\right\\} \\end{aligned} \\
接下来我们来表示\(C^*_{\phi}\),而这需要对\(\eta(x)\)的取值情况进行分类讨论:
-
\(\eta(x) = \frac{1}{2}\): \(f^*{\Phi}(x) = c \in -1, 1\),\(C^*{\Phi} = \frac{1}{2}(1-f) + \frac{1}{2}(1+f) = 1\)。
-
\(\eta(x) > \frac{1}{2}\): \(f^*(x) = 1\),\(C^*_{\Phi} = 2(1 - \eta)\)。
-
\(\eta(x) < \frac{1}{2}\): \(f^*(x) = -1\),\(C^*_{\Phi} = 2\eta\)。
综上所述,\(C^*_{\Phi} = 2\min\left\{\eta, 1 - \eta\right\}\)。
于是
\C_{\\Phi}(f) - C\^\*_{\\Phi} = \\eta\\max\\left\\{1-f, 0\\right\\} + (1 - \\eta)\\max\\left\\{1+f, 0\\right\\} - 2\\min\\left\\{\\eta, 1 - \\eta\\right\\} \\
接下来我们需要对\(\eta(x)\)和\(f(x)\)的取值情况进行分类讨论:
-
\(\eta(x) = \frac{1}{2}\):
此时\(C_{\text{0-1}}(f) - C^*{\text{0-1}} = 0\),故必有\(C{\Phi}(f) - C^*{\Phi} \geqslant C{\text{0-1}}(f) - C^*_{\text{0-1}}\)。
-
\(\eta(x) > \frac{1}{2}\):
此时\(C^*{\Phi} = 2( 1- \eta)\),\(C{\text{0-1}}(f) - C^*{\text{0-1}} = \left(2\eta - 1\right)\Phi{\text{0-1}}\left(f\right)\)。
a. 当\(f(x) < -1\)时,
\\\begin{aligned} C_{\\Phi}(f) - C\^\*_{\\Phi} \&= \\eta(1 - f) - 2(1 - \\eta) \\\\ \&= 2\\eta - 1 - \\underbrace{\\left(1 - \\eta(1 - f)\\right)}_{\<0}\\\\ \&\\geqslant 2\\eta - 1\\\\ \&= C_{\\text{0-1}}(f) - C\^\*_{\\text{0-1}} \\end{aligned} \\
b. 当\(-1 \leqslant f(x) \leqslant 1\)时,
\\\begin{aligned} C_{\\Phi}(f) - C\^\*_{\\Phi} \&= 1 + (1 - 2\\eta) f - 2(1 - \\eta) \\\\ \&= 2\\eta - 1 - \\underbrace{(2\\eta - 1)f}_{b(f)}\\\\ \&= \|2\\eta - 1 - b(f)\|\\\\ \&\\geqslant C_{\\text{0-1}}(f) - C\^\*_{\\text{0-1}} \\end{aligned} \\
c. 当\(f(x) > 1\)时,此时\(C_{\text{0-1}}(f) - C^*{\text{0-1}} = 0\)。故必有\(C{\Phi}(f) - C^*{\Phi} \geqslant C{\text{0-1}}(f) - C^*_{\text{0-1}}\)。
-
\(\eta < \frac{1}{2}\): 类似地,有\(C_{\Phi}(f) - C^*{\Phi} \geqslant C{\text{0-1}}(f) - C^*_{\text{0-1}}\)。
综上所述,代理损失函数的超额风险界对于\(\Gamma\)为恒等函数时成立(也即\(\Gamma(t) = t = \mathcal{O}(t)\))。换句话说,对于hinge损失,我们有
\R_{\\text{0-1}}(f) - R\^\*_{\\text{0-1}} \\leqslant R_{\\Phi}(f) - R\^\*_{\\Phi} \\
也就意味着超额\(\Phi\)-风险直接控制超额0-1风险。
对于同样的二分类问题,可以使用不同的凸代理。尽管贝叶斯分类器总是相同的(即\(h^* = \mathrm{sign}(2\eta - 1)\)),但大部分代理风险的最小点\(f^*\)是不同的。例如,对于hinge损失,\(f^*\)正好为\(\mathrm{sign}(2\eta - 1)\),然而对于诸如形式为\(\Phi(f) = F(f) - f\)的损失,我们有\(F^{\prime}(f) = 2\eta - 1\),因此对于平方损失,\(f^* = 2\eta - 1\);对于logistic损失,可以验证\(f^* = 2 \text{atanh}(2\eta - 1)\)(其中\(\text{atanh}\)表示双曲反正切)。
注 当函数空间\(\mathcal{F}\)足够灵活以致\(f\in\mathcal{F}\)可以达到代理风险\(R_{\Phi}\)的最小点时,例如核方法或带有足够多神经元的神经网络,最小的0-1风险\(R^*_{\text{0-1}}\)是可达的。
然而在实践中,尤其在高维的情况下,使用受限的模型类,尤其是线性模型,达到最小代理风险将不再可能。在这种情况下,我们可以定义基于模型类的一致性[8](关于这个可以参见我的博客《学习理论:预测器-拒绝器多分类弃权学习 》)。
5 超额风险的分解
考虑最小化代理损失函数的超额风险\(R_{\Phi}(\hat{f}) - R_{\Phi}^{*}\),这里\(\hat{f}\)做为\(f^*\)的估计值,是最小化如下所示的经验误差(泛化误差的近似)[9]来获得的:
\\\hat{f} = \\inf_{f\\in \\mathcal{F}}\\widehat{R}_{\\Phi}(f) = \\inf_{f\\in \\mathcal{F}}\\left\\{ \\frac{1}{m}\\sum_{i=1}\^m \\Phi(y_if(x_i))\\right\\} \\
而这里的超额风险可以进一步做如下分解[5]:
\R_{\\Phi}(\\hat{f}) - R_{\\Phi}\^{\*} = \\underbrace{\\left(R_{\\Phi}(\\hat{f}) - \\inf_{f\\in\\mathcal{F}}R_{\\Phi}(f)\\right)}_{\\text{estimation error}\\geqslant 0} + \\underbrace{\\left(\\inf_{f\\in\\mathcal{F}}R_{\\Phi}(f) - R_{\\Phi}\^{\*}\\right)}_{\\text{approximation error}\\geqslant 0} \\
其中\(\inf_{f\in\mathcal{F}}R_{\Phi}(f)\)为假设类最优(best-in-class)误差,对应的假设类最优假设记为\(f^{\circ}\),假设类最优误差也可以记为\(R_{\Phi}(f^{\circ})\)
-
第一项差值被称为估计误差(estimation error),它衡量了一个模型和假设类最优的模型之间的差距。
-
第二项差值是逼近误差(approximation error) ,代表了假设类\(\mathcal{F}\)在多大程度上涵盖了最优实值输出函数\(f^*\),刻画了模型的表达能力。
接下来我们分别来看逼近误差和估计误差。
6 逼近误差
逼近误差\(\inf_{f\in\mathcal{F}}R_{\Phi}(f) - R_{\Phi}^{*}\)是确定性的,它依赖于潜在的分布及函数类\(\mathcal{F}\):函数类越"大",逼近误差越小。
界定逼近误差需要贝叶斯预测器\(f^*\)的假设,因此也需要在测试分布上的假设。
在本部分,我们关注\(\mathcal{F}=\left\{f_{\theta}, \theta\in \Theta\right\}(\Theta\subset \mathbb{R}^d)\),以及凸Lipschitz连续的代理损失\(\Phi(\cdot)\),并假设\(\theta^*\)是\(R_{\Phi}(f_{\theta})\)在\(\theta \in \mathbb{R}^d\)的最小点,假设该最小点存在(\(\theta^*\)常常并不属于\(\Theta\))。这也就意味着逼近误差可以被分解为
\\\inf_{\\theta\\in\\mathcal{\\Theta}}R_{\\Phi}(f_{\\theta}) - R_{\\Phi}\^\* = \\left(\\inf_{\\theta\\in\\mathcal{\\Theta}}R_{\\Phi}(f_{\\theta}) - \\inf_{\\theta\\in\\mathbb{R}\^d}R_{\\Phi}(f_{\\theta})\\right) + \\left(\\inf_{\\theta\\in\\mathbb{R}\^d}R_{\\Phi}(f_{\\theta}) - R_{\\Phi}\^{\*}\\right) \\
-
第二项\(\inf_{\theta\in\mathbb{R}^d}R_{\Phi}(f_{\theta}) - R_{\Phi}^{*}\)是由所选择的模型\(f_{\theta}\)的集合产生的不可压缩近似误差。对于诸如核方法或神经网络的灵活模型,这个不可压缩误差可以根据需要变小。
-
函数\(\theta\mapsto R_{\Phi}(f_{\theta}) - \inf_{\theta\in\mathbb{R}^d}R_{\Phi}(f_{\theta})\)在\(\mathbb{R}^d\)上非负,且通常可以被特定的范数\(\Omega(\theta - \theta^*)\)(或其平方)界定,因此我们可以将上述的第一项\(\inf_{\theta\in\mathcal{\Theta}}R_{\Phi}(f_{\theta}) - \inf_{\theta\in\mathbb{R}^d}R_{\Phi}(f_{\theta})\)看做是\(\theta^*\)和\(\Theta\)之间某种"距离"的体现。
如果代理损失函数是\(G\)-Lipschitz连续的,即存在常数\(G > 0\),对任意\(u_1, u_2 \in \mathbb{R}\),都有\(\left|\Phi(u_1) - \Phi(u_2)\right| \leqslant G\left|u_1 - u_2\right|\)成立(参见我的博客《数值优化:算法分类及收敛性分析基础》), 我们有
\\\begin{aligned} R_{\\Phi}(f_{\\theta_1}) - R_{\\Phi}(f_{\\theta_2}) \&= \\mathbb{E}_{x, y}\\left\[{\\Phi}(yf_{\\theta_1}(x)) - \\Phi(yf_{\\theta_2}(x))\\right\\ &\leqslant \mathbb{E}{x, y}\leftG\\left\|yf_{\\theta_1}(x) - yf_{\\theta_2}(x)\\right\|\\right\\ &=G\mathbb{E}{x, y}\left\|f_{\\theta_1}(x) - f_{\\theta_2}(x)\|\\right \quad (y\in \left\{-1, +1\right\}) \end{aligned} \]
因此,逼近误差的第一部分被\(G\)和\(f_{\theta^{*}}\)和\(\mathcal{F}=\left\{f_{\theta}, \theta\in \Theta\right\}\)之间的某种"距离"之积所界定,这里是指某种伪距离\((\theta_1, \theta_2)\mapsto \mathbb{E}\left\|f_{\\theta_1}(x) - f_{\\theta_2}(x)\|\\right\)(忽略当且仅当\(\theta = \theta^{\prime}\)时该式为0这一性质)。
7 估计误差
机器学习理论的一大目标是最小化估计误差\(R_{\Phi}(\hat{f}) - \underset{f\in\mathcal{F}}{\inf} R_{\Phi}(f)\),然而我们前面提到过,\(\hat{f}\)做为\(f^*\)的估计值,是最小化经验误差来获得的,即\(\hat{f} = \underset{f\in \mathcal{F}}{\inf}\widehat{R}{\Phi}(f)\)。这也就意味着\(\hat{f}\)并不能保证最小化泛化误差\(R{\Phi}(\hat{f})\),自然也就无法保证最小化估计误差了。
于是,考虑对估计误差进行进一步的分解[5]与界定:
\\\begin{aligned} \& R_{\\Phi}(\\hat{f}) - \\inf_{f\\in\\mathcal{F}}R_{\\Phi}(f) \\\\ \&= R_{\\Phi}(\\hat{f}) - R_{\\Phi}(f\^{\\circ}) \\quad (f\^{\\circ} = \\underset{f\\in \\mathcal{F}}{\\mathrm{arg min }}R_{\\Phi}(f))\\\\ \&= \\underbrace{\\left(R_{\\Phi}(\\hat{f}) - \\widehat{R}_{\\Phi}(\\hat{f})\\right)}_{\\text{generalization gap}\\geqslant 0} + \\underbrace{\\left(\\widehat{R}_{\\Phi}(\\hat{f}) - \\widehat{R}_{\\Phi}(f\^{\\circ})\\right)}_{\\text{training error} \\leqslant 0 \\text{ or } \\geqslant 0} + \\underbrace{\\left(\\widehat{R}_{\\Phi}(f\^{\\circ}) - R_{\\Phi}(f\^{\\circ})\\right)}_{\\text{small term} \\geqslant 0} \\\\ \&\\leqslant \\sup_{f\\in \\mathcal{F}} \\left(R_{\\Phi}(f) - \\widehat{R}_{\\Phi}(f)\\right) + \\left(\\widehat{R}_{\\Phi}(\\hat{f}) - \\widehat{R}_{\\Phi}(f\^{\\circ})\\right) + \\sup_{f\\in \\mathcal{F}} \\left(\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right) \\\\ \&\\leqslant \\sup_{f\\in \\mathcal{F}} \\left(R_{\\Phi}(f) - \\widehat{R}_{\\Phi}(f)\\right) + 0 + \\sup_{f\\in \\mathcal{F}} \\left(\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right)\\\\ \&\\leqslant 2\\sup_{f\\in \\mathcal{F}} \\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\end{aligned} \\
观察上式,我们可以发现:
- 移除\(\widehat{R}{\Phi}\)和\(\hat{f}\)之间统计依赖性的关键工具是取一致界(uniform bound) ,也即上式中的\(\sup{f\in \mathcal{F}}\left(\cdot\right)\)操作。
- 当\(\hat{f}\)并非\(\widehat{R}{\Phi}\)的全局最优点但满足\(\widehat{R}{\Phi}(\hat{f})\leqslant \inf_{f\in\mathcal{F}}\widehat{R}_{\Phi}(f) + \epsilon\)时,则优化误差\(\epsilon\)需要被加入本部分所提到的估计误差中。
- 渐进偏差(uniform deviation) 随着\(\mathcal{F}\)的"大小"而增长,它是一个随机量(由于其依赖于数据),并常随着样本数量\(m\)衰减。
- 这里的关键问题是我们需要对所有\(f\in \mathcal{F}\)的一致控制:正如我们后面会涉及的,对于单个\(f\),可以对随机变量\(\Phi(yf(x))\)应用集中不等式(如Hoeffding不等式)以得到\(\mathcal{O}(1 / \sqrt{m})\)的界。然而,当控制在多个\(f\)上的最大偏差时,会存在其中某个偏差变大的可能。因此,我们需要显式控制这种现象。
8 估计误差界
8.1 经验过程与McDiarmid 不等式的应用
由于估计误差是一个随机量,我们需要使用概率工具来界定它,这时界可以以某个高概率成立。而\(\sup_{f\in \mathcal{F}}\lvert \widehat{R}{\Phi}(f) - R{\Phi}(f)\lvert\)可以视为函数\(f\in \mathcal{F}\)做为下标索引的随机过程的量纲(magnitude),这种随机过程称为经验过程(参见我的博客(《学习理论:代理损失函数的泛化界与Rademacher复杂度》)))。于是证明估计误差有界的问题可转化为证明经验过程有界的问题。
设\(A(z_1, \cdots, z_m) = \sup_{f\in \mathcal{F}}\left(\widehat{R}{\Phi}(f) - R{\Phi}(f)\right)\),其中随机变量\(z_i = (x_i, y_i)\)独立同分布。假设对于所有的在数据生成分布的支撑集(support)里的\((x, y)\),以及\(f\in \mathcal{F}\),代理损失函数都位于0和某个\(M_{\Phi}\)之间(对于大部分代理损失函数而言,这是当函数\(f\)有界时的直接结果)。
注 直观地理解,概率分布\(p\)的支撑集定义为那些概率大于0的点,对于离散概率分布而言为\(\left\{x: p(X=x) > 0\right\}\),对于连续概率分布而言为\(\left\{x: p(x) > 0\right\}\)[9]。
对于单个函数\(f\in \mathcal{F}\),我们可以通过Hoeffding不等式控制\(\widehat{R}{\Phi}(f)\)与\(R{\Phi}(f)\)之间的偏差(这是一个有界独立随机变量的经验均值,与其期望之间的偏差):对于任意\(\delta\in (0, 1)\),至少以\(1 - \delta\)的概率有
\\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\leqslant \\frac{M_{\\Phi}}{\\sqrt{2m}}\\sqrt{\\log \\frac{1}{\\delta}} \\
Hoeffding不等式: [1][5][10] 若\(X_1, \cdots, X_m\)为独立随机变量且\(X_i\in a, b\),则有
\P\\left(\\frac{1}{m}\\sum_{i=1}\^m X_i - \\frac{1}{m}\\sum_{i=1}\^m\\mathbb{E}\[X \geqslant \epsilon\right) \leqslant \exp\left(-\frac{2m\epsilon^2}{(b - a)^2}\right) \]
有时也会用到Hoeffding不等式的另一种表达形式,令\(\delta = \exp\left(-\frac{2m\epsilon^2}{(b - a)^2}\right)\)(\(\Rightarrow \epsilon = \frac{(b - a)}{\sqrt{2m}}\sqrt{\log\frac{1}{\delta}}\)),则至少以\(1 - \delta\)的概率有
\\\frac{1}{m}\\sum_{i=1}\^m X_i - \\frac{1}{m}\\sum_{i=1}\^m\\mathbb{E}\[X \leqslant \frac{(b - a)}{\sqrt{2m}}\sqrt{\log\frac{1}{\delta}} \]
这个控制可以扩展到多个函数\(f\)。这里需要用到McDiarmid不等式,而该不等式的应用以有界变差条件为前提,在这里即当将单个变量\(z_i\in \mathcal{X}\times\mathcal{Y}\)替换为与训练集独立同分布的\(z_i^{\prime}\in \mathcal{X}\times\mathcal{Y}\)后,偏差最多为\(\frac{1}{m}M_{\Phi}\)(也即\(\left|A(z_1, \cdots, z_m) - A(z_1, \cdots, z_i^{'}, \cdots, z_m)\right|\leqslant \frac{1}{m}M_{\Phi}\)成立,类似的证明可以参见我的博客《学习理论:代理损失函数的泛化界与Rademacher复杂度》)。于是,应用McDiarmid不等式 可以得到:至少以\(1 - \delta\)的概率有
\ A(z_1, \\cdots, z_m) \\leqslant \\mathbb{E}_{z}\\left\[A(z_1, \\cdots, z_m)\\right + \frac{M_{\Phi}}{\sqrt{2m}}\sqrt{\log \frac{1}{\delta}} \]
因此,要证明经验过程有界,可以先界定\(\sup_{f\in \mathcal{F}} \left(\widehat{R}{\Phi}(f) - R{\Phi}(f)\right)\)的期望(或相似的量\(\sup_{f\in \mathcal{F}} \left(R_{\Phi}(f) - \widehat{R}_{\Phi}(f)\right)\)的期望,它们通常具有同样的界),然后将单侧界转换为带\(\left|\cdot\right|\)的双侧界即可。而这个期望的界定可以使用模型类的Rademacher复杂度(参见我之前的博客)。
8.2 简化情形: 有限数量的模型
对于有限数量的模型,可以直接将对多个函数的处理转换为单个函数\(f\)的处理。在这部分我们假设代理损失函数被界定在0和\(M_{\Phi}\)之间。我们可以使用 联合界(union bound) 将一致偏差界定:
\\\mathbb{P}\\left(\\sup_{f\\in \\mathcal{F}} \\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\geqslant \\epsilon\\right) \\leqslant \\sum_{f\\in \\mathcal{F}} \\mathbb{P}\\left(\\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\geqslant \\epsilon\\right) \\
因此,对于固定的\(f\in \mathcal{F}\),\(\widehat{R}{\Phi}(f)\),可以应用双侧Hoeffding's不等式来界定每一个\(\mathbb{P}\left(\left|\widehat{R}{\Phi}(f) - R_{\Phi}(f)\right| \geqslant \epsilon\right)\)以得到
\\\begin{aligned} \\mathbb{P}\\left(\\sup_{f\\in \\mathcal{F}} \\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\geqslant \\epsilon\\right) \&\\leqslant \\sum_{f\\in \\mathcal{F}}2\\exp(-2mt\^2 / M_{\\Phi}\^2)\\\\ \&= 2\\left\|\\mathcal{F}\\right\|\\exp(-2mt\^2 / M_{\\Phi}\^2) \\end{aligned} \\
双侧Hoeffding不等式: [11] 若\(X_1, \cdots, X_m\)为独立随机变量且\(X_i\in a, b\),则有
\P\\left(\\left\|\\frac{1}{m}\\sum_{i=1}\^m X_i - \\frac{1}{m}\\sum_{i=1}\^m\\mathbb{E}\[X\right| \geqslant \epsilon\right) \leqslant 2\exp\left(-\frac{2m\epsilon^2}{(b - a)^2}\right) \]
因此,令\(\delta = 2\left|\mathcal{F}\right|\exp(-2mt^2 / M_{\Phi}^2)\)(\(\Rightarrow \epsilon = \frac{M_{\Phi}}{\sqrt{2m}}\sqrt{\log \frac{2\left|\mathcal{F}\right|}{\delta}}\)),得到至少以\(1 - \delta\)的概率有:
\\\begin{aligned} \\sup_{f\\in \\mathcal{F}} \\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \&\\leqslant \\epsilon = \\frac{M_{\\Phi}}{\\sqrt{2m}}\\sqrt{\\log \\frac{2\\left\|\\mathcal{F}\\right\|}{\\delta}}\\\\ \&= \\frac{M_{\\Phi}}{\\sqrt{2m}}\\sqrt{\\log(2\\left\|F\\right\|) + \\log\\frac{1}{\\delta}}\\\\ \&\\leqslant M_{\\Phi}\\sqrt{\\frac{\\log(2\\left\|F\\right\|)}{2m}} + \\frac{M_{\\Phi}}{\\sqrt{2m}}\\sqrt{\\log \\frac{1}{\\delta}}\\quad \\left(\\sqrt{a + b}\\leqslant \\sqrt{a} + \\sqrt{b}\\right) \\end{aligned} \\
其中最后一行不等式我们使用了平方根函数的次可加性(sub-additivity)[13]。这是一个一致偏差的上界。根据上述界,当模型类"大小"的对数\(\log(\left|\mathcal{F}\right|)\)显著小于\(m\)时,学习是可能的。这是一个对一致偏差的通用控制方法。
注 这个上界对于有限的模型类成立。
8.3 通过覆盖数超越有限多的模型
简单地说,覆盖数(covering number) [1][11]背后的思想是通过无限多的元素来处理函数空间,而这是通过使用有限多的元素来对其进行近似而达到的。这也常被称为"\(\epsilon\)-网论证"。
这里我们假设代理损失函数是\(G\)-Lipschitz连续的。因此,正像在第6部分提到过的,对任意\(f_1, f_2\in \mathcal{F}\),我们有
\\\left\|R_{\\Phi}(f_1) - R_{\\Phi}(f_2)\\right\| \\leqslant G\\cdot \\mathbb{E}\\left\[\|f_1(x) - f_2(x)\|\\right = G\cdot \Delta(f_1, f_2) \]
定义 (覆盖数) 我们假设有\(N\)个元素\(f_1, \cdots, f_N\)使得对任意\(f\in \mathcal{F}\),存在\(i\in \left\{1, \cdots, N\right\}\),使得\(\Delta(f, f_i)\leqslant \epsilon\)(\(d\)按上式定义)。最小的\(N\)的可能值是\(\mathcal{F}\)在精度为\(\epsilon\)时的覆盖数(Cover number) ,记为\(\mathcal{N}(\mathcal{F}, \Delta, \epsilon)\)。下面展示了在二维的情况下使用欧几里得球的覆盖:
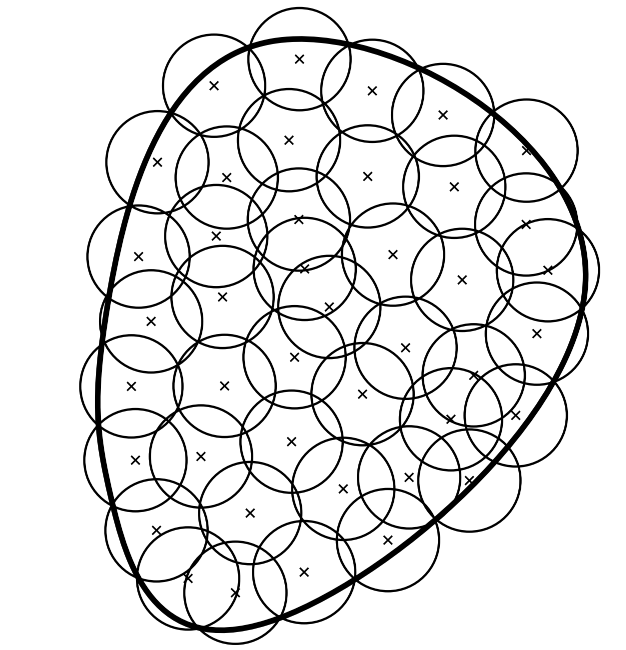
覆盖数\(\mathcal{N}(\mathcal{F}, \Delta, \epsilon)\)可视为\(\epsilon\)的非增函数。通常情况下,当\(\epsilon\rightarrow 0\)时,\(\mathcal{N}(\mathcal{F}, \Delta, \epsilon)\)随着\(\epsilon\)以指数\(\epsilon^{-d}\)变化,这里\(d\)是潜在维度。实际上,对于\(f\)关于\(M_{\Phi}\)的有界条件而言,如果\(\mathcal{F}\)(在某种特定的参数化下)被包含在维度为\(d\)的\(M_{\Phi}\)-球中的半径为\(c\)的球中,它可以被\((c/\epsilon)^d\)个长度为\(2\epsilon\)的立方体覆盖(若\(c \geqslant \epsilon\)),如下图所示:
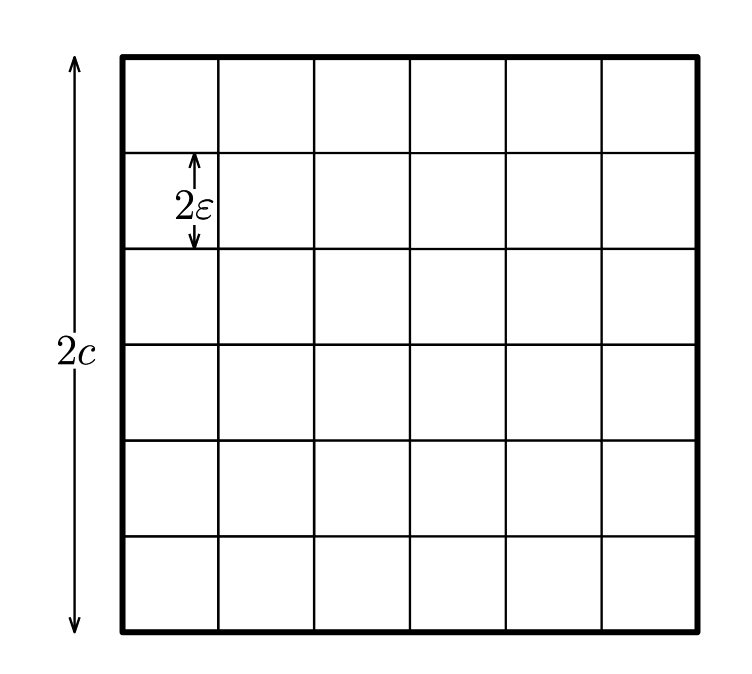
推广到所有在\(d\)维情况下等价的距离\(\Delta\),对于有限维向量空间的任意有界子集\(\mathcal{F}\),我们仍然有\(\mathcal{N}(\mathcal{F}, \Delta, \epsilon)\sim \epsilon^{-d}\),取对数可得\(\log \mathcal{N}(\mathcal{F}, \Delta, \epsilon)\sim d\log\frac{1}{\epsilon}\)。
对于某些集合\(\mathcal{F}\)(例如在\(d\)维情况下关于有界Lipschitz常量的Lipschitz连续函数),\(\log \mathcal{N}(\mathcal{F}, \Delta, \epsilon)\)增长得更快,例如以\(\epsilon^{-d}\)的阶增长。
\(\epsilon\)-网论证 给定\(\mathcal{F}\)的一个覆盖,对所有\(f\in \mathcal{F}\)和与之相关的覆盖元素\((f_i)_{i\in 1, \cdots, \mathcal{N}(\mathcal{F}, \Delta, \epsilon)}\),由\(\widehat{R}\)和\(R\)都关于距离\(\Delta\)满足\(G\)-Lipschitz连续,于是对任意\(i\in \left\{1, \cdots, \mathcal{N}(\mathcal{F}, \Delta, \epsilon)\right\}\),我们有
\\\begin{aligned} \\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \&\\leqslant \\left\|\\widehat{R}_{\\Phi}(f) - \\widehat{R}_{\\Phi}(f_i)\\right\| + \\left\|\\widehat{R}_{\\Phi}(f_i) - R_{\\Phi}(f_i)\\right\| + \\left\|R_{\\Phi}(f_i) - R_{\\Phi}(f)\\right\| \\\\ \&\\leqslant 2G\\cdot \\Delta(f, f_i) + \\left\|\\widehat{R}_{\\Phi}(f_i) - R_{\\Phi}(f_i)\\right\| \\\\ \&\\leqslant 2G\\cdot \\Delta(f, f_i) + \\sup_{j\\in \\left\\{1, \\cdots, \\mathcal{N}(\\mathcal{F}, \\Delta, \\epsilon)\\right\\}}\\left\|\\widehat{R}_{\\Phi}(f_j) - R_{\\Phi}(f_j)\\right\| \\\\ \\end{aligned} \\
由于\((f_i)_{i\in 1, \cdots, \mathcal{N}(\mathcal{F}, \Delta, \epsilon)}\)满足覆盖性质,于是我们可以用\(\epsilon\)将\(\Delta(f, f_i)\)界定:
\\\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\leqslant 2G\\epsilon + \\sup_{j\\in \\left\\{1, \\cdots, \\mathcal{N}(\\mathcal{F}, \\Delta, \\epsilon)\\right\\}}\\left\|\\widehat{R}_{\\Phi}(f_j) - R_{\\Phi}(f_j)\\right\| \\
这也就意味着,若使用7.2部分的结论,则以大于\(1 - \delta\)的概率有
\\\sup_{f\\in \\mathcal{F}}\\left\|\\widehat{R}_{\\Phi}(f) - R_{\\Phi}(f)\\right\| \\leqslant 2G\\epsilon + M_{\\Phi}\\sqrt{\\frac{\\log\\left(2\\mathcal{N}(\\mathcal{F}, \\Delta, \\epsilon)\\right)}{2m}} + \\frac{M_{\\Phi}}{\\sqrt{2m}}\\sqrt{\\log\\frac{1}{\\delta}} \\
因此,若\(\mathcal{N}(\mathcal{F}, \Delta, \epsilon)\sim \epsilon^{-d}\),忽略常数的话,我们还需要界定\(\epsilon + \sqrt{d\log(1 / \epsilon) / m}\)。取\(\epsilon \propto 1 / \sqrt{m}\)可以得到\(\mathcal{O}\left(\sqrt{(d/m)\log (m)}\right)\)的率。和7.2部分有限模型类的情况有点像,这里和\(m\)的关系也接近于\(1 / \sqrt{m}\)。然而,除非重新定义覆盖数的计算或者使用更高级的工具(比如链(chaining)),这通常会导致非最优的维度项与/或样本数量项的出现。
有两个有力的工具可以以合理的代价导出更好的界,它们是Rademacher复杂度 和Gaussian复杂度 。其中Rademacher复杂度可以参见我的博客《学习理论:代理损失函数的泛化界与Rademacher复杂度》。
参考
- 1 Bach, Francis. Learning theory from first principles. MIT press, 2024.
- 2 【COLT 2025】Conference on Learning Theory
- 3 Mohri M, Rostamizadeh A, Talwalkar A. Foundations of machine learningM. MIT press, 2018.
- 4 John Duchi: Statistics and Information Theory
- 5 周志华, 王魏, 高尉, 张利军. 机器学习理论导引M. 机械工业出版社, 2020.
- 6 Han Bao: Learning Theory Bridges Loss Functions
- 7 Boyd, Stephen, and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
- 8 Long, Phil, and Rocco Servedio. "Consistency versus realizable H-consistency for multiclass classification." International conference on machine learning. PMLR, 2013.
- 9 Ni C, Charoenphakdee N, Honda J, et al. On the calibration of multiclass classification with rejectionJ. Advances in Neural Information Processing Systems, 2019, 32.
- 10 Wikipedia: Support (mathematics)
- 11 Vershynin R. High-dimensional probability: An introduction with applications in data scienceM. Cambridge university press, 2018.
- 12 Wikipedia: Subadditivity