1. 概述
根据DAOS的架构设计可以知道,用户写入的数据最终会由相应的target负责写入到磁盘。数据的写入操作会先转化成对DAOS object的操作,然后再转化成对target的操作。实际上,object在DAOS中并非是操作的最小单元。DAOS支持更细粒度的操作,比如精确到对字节的操作。本文会从dfs层元数据的insert_entry操作出发,理清object IO与target IO之间的逻辑转换。
2. IO逻辑分析
在创建新文件时,文件的元数据信息会封装到entry中,然后调用insert_entry函数将文件的元数据插入到父目录object中。insert_entry函数会调用daos_obj_update函数,该函数是DAOS的API函数,它会借助任务调度机制进入DAOS层实现对DAOS object的一系列操作。因此,通过daos_obj_update函数,insert_entry函数便可以将对entry的操作转换成对父目录object的更新操作。
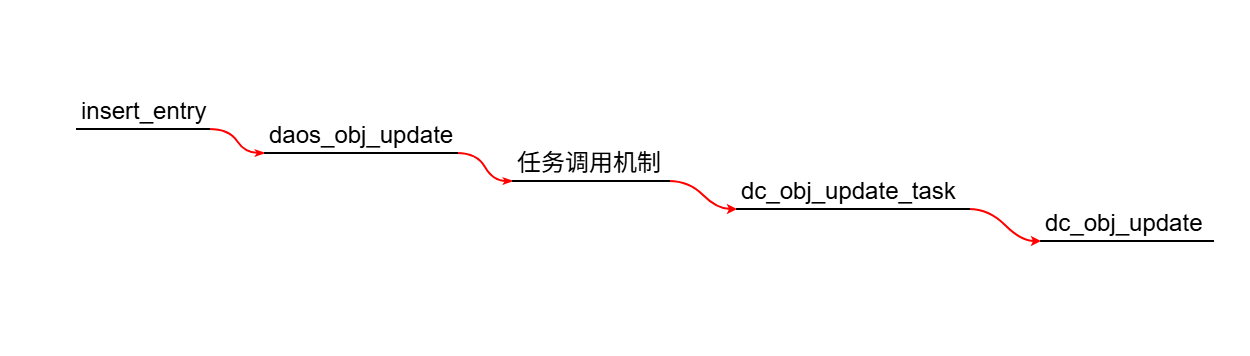
进入DAOS层后,如果是对于元数据的insert操作,最终会进入dc_obj_update函数内。该函数是object update的入口函数。在讲解该函数之前,有必要先介绍obj_auxi_args这个数据结构,它在接下来的流程中起到非常关键的作用。
obj_auxi_args是专为object IO设计的数据结构,该结构中封装了一个object IO相关的所有的参数信息。其中,object相关的有:obj,th;object shard相关的有:shard_rw_args;dkey相关的有:dkey_hash;value相关的有:sgls_dup;target相关的有:req_tgts;IO相关的有:IO task flag,request flags。
dc_obj_update函数的整体逻辑基本上是围绕obj_auxi_args这个数据结构展开的。其主要思想是通过各种手段填充obj_auxi_args中的参数值,然后调用obj_req_fanout函数进入IO准备阶段。最关键的,也最难理清的是obj_update_shards_get函数和obj_shards_2_fwtgts函数。obj_update_shards_get函数主要是获取出object的shard counts和start shard index。obj_shards_2_fwtgts函数会利用上面获取到的shard counts和start shard index,找到object shard与target之间的映射关系。因此,object便与target之间建立起关联关系。
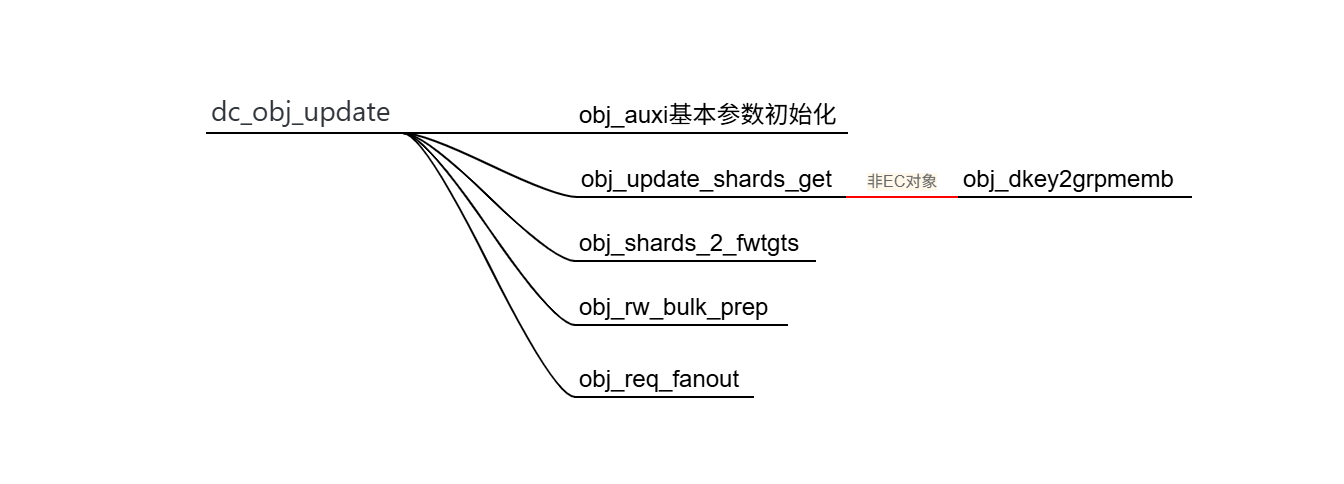
obj_update_shards_get函数会根据object的数据保护方式做不同的处理。如果是EC类型的,处理逻辑相对于RP类型的要复杂一些,此处为了简化分析,只分析RP类型的处理逻辑。对于RP类型的object,会直接调用obj_dkey2grpmemb函数获取要更新的shard counts和start shard index。该函数会利用jump hash算法并结合传入的dkey hash的值计算出对应的group idx,start shard index的值等于group idx乘以group size。group size是直接从object的成员cob_grp_size获取出来的。但是这里有点琢磨不透,代码中直接将shard counts与group size画等号。正常情况下,对于RP类型的object而言,一个group就是一组互为副本的object shards的集合,group size就是副本数量,group counts就是shard counts(不包含副本)。
c
static int obj_dkey2grpmemb(struct dc_object *obj, uint64_t hash, uint32_t map_ver,
uint32_t *start_shard, uint32_t *grp_size)
{
int grp_idx;
grp_idx = obj_dkey2grpidx(obj, hash, map_ver);
if (grp_idx < 0)
return grp_idx;
*grp_size = obj_get_grp_size(obj);
*start_shard = grp_idx * *grp_size;
return 0;
}然而,在计算group idx时,obj_dkey2grpidx函数内部会调用obj_pl_grp_idx函数,该函数的传入参数group counts是通过group counts = shard counts / group size方式计算的。如果按照这种计算方式,该表达式中的shard counts应该理解为包含了副本的所有object shard的数量,与我的理解正好符合。
经过与DAOS社区开发人员深入沟通了解,我才发现我对shard counts的理解是错误的。实际上
shard counts应该理解为包含了所有冗余的object shard的数量,而不是等于group counts。所以shard counts = group counts * group size是正确的。所以上文提到的更新的shard counts直接等于group size的逻辑可以这样理解:一个目录object中有很多dkey,当目录object按照给定的分片策略进行分片时,每个leader分片和每个group之间是一对一的映射关系。因为dkey是存在于分片中,每个leader分片中可能包含多个dkey,所以dkey与leader分片之间是多对一的映射关系,依次类推可知dkey与group之间是多对一的映射关系。所以想要更新某个dkey的信息,一定能知道要更新哪个group。而所定位到的group中的group size就是最终要更新的object shard的数量。
由此可见,上述obj_update_shards_get函数真正的思想是获取与待更新的dkey相关的object shard信息,而不是object的所有shard信息,以达到精准定位的目的。
接下来,obj_shards_2_fwtgts函数会根据获取出来的shard counts和start shard index,找到对应的target。该函数核心思想是围绕ort_shard_tgts这个数组展开,它是daos_shard_tgt *类型的,该数据结构是关于object shard与target之间的映射关系。该函数中使用循环嵌套逻辑,外for循环是遍历groups,内while循环是遍历每个group中的object shards。在内循环中调用obj_shard_tgts_query函数来获取到对应的target信息。
c
static int obj_shards_2_fwtgts(...) {
...
req_tgts->ort_grp_nr = grp_nr;
req_tgts->ort_grp_size = grp_size;
shard_idx = start_shard;
for (i = 0; i < grp_nr; i++) {
cur_grp_size = req_tgts->ort_grp_size;
head = tgt = req_tgts->ort_shard_tgts + i * grp_size;
grp_idx = shard_idx / obj_get_grp_size(obj);
grp_start = grp_idx * obj_get_grp_size(obj);
....
while (cur_grp_size > 0) {
shard_idx = grp_start + tgt_idx;
rc = obj_shard_tgts_query(obj, map_ver, shard_idx, tgt, obj_auxi, bit_map);
...
cur_grp_size--;
tgt++;
}
shard_idx = grp_start + obj_get_grp_size(obj);
}
}obj_shards_2_fwtgts函数实际上不是很复杂,只要理清各种index之间的关系,就能够理解该函数的逻辑。上述逻辑中最关键是group index与shard index之间的计算,如下图所示:
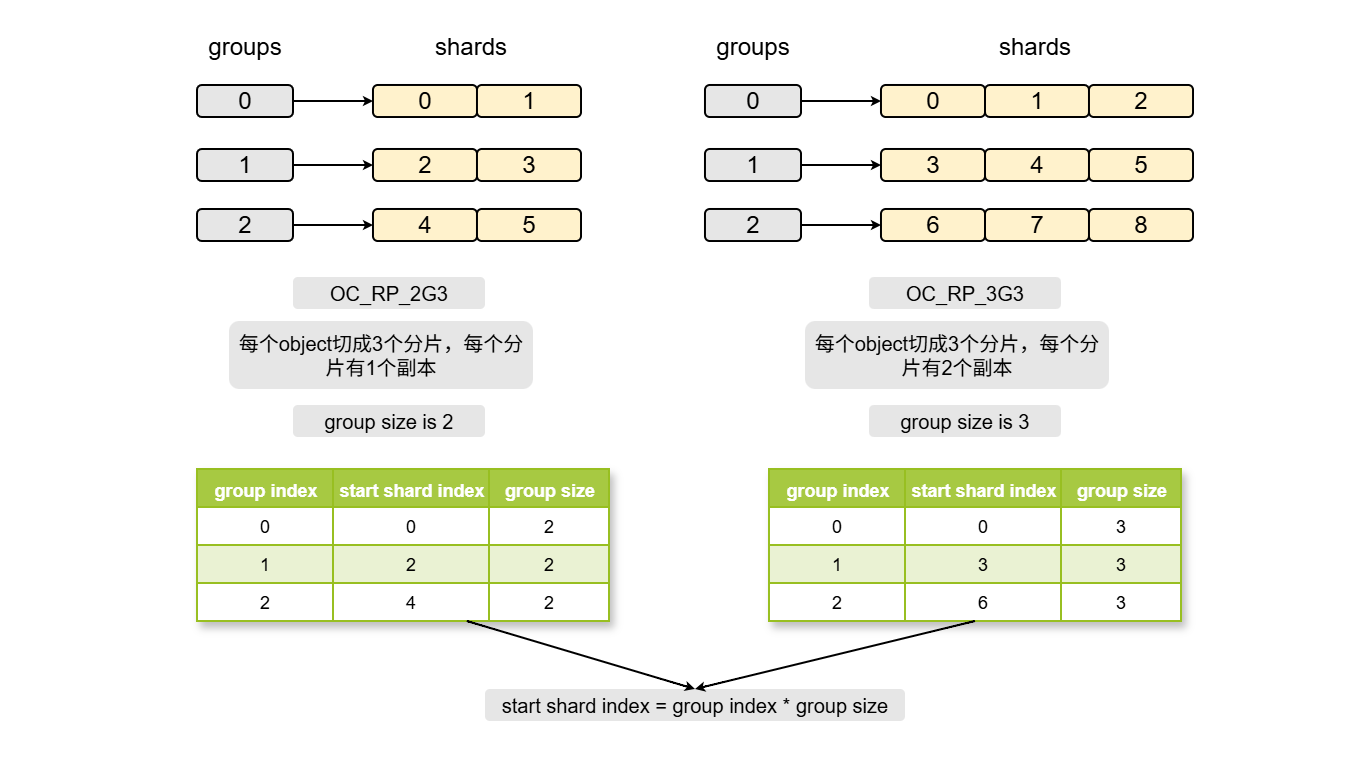
上图中展示了2副本和3副本的情况,从中可以看出,只要知道group index、shard index与group size中的任意2个值,都可以根据start shard index = group index * group size公式计算出最后一个值。
obj_shard_tgts_query函数逻辑很简单,主要是通过obj_shard_open函数打开一个object shard,它是dc_obj_shard类型的。这个结构中正好包含了所需要的target信息,所以直接从该结构中获取即可。
由此,IO中所需的各种信息都已经准备就绪,dc_obj_update函数中的IO流程最终会进入obj_req_fanout函数中,实现IO真正的扭转。该函数主要思想是遍历每一个target,执行shard io操作。详细逻辑,后续再展开介绍。