一 人工智能AI的大框架
从水平角度看,仍然可以通过软硬件分层来理解,类似传统软件系统框架,如下图:
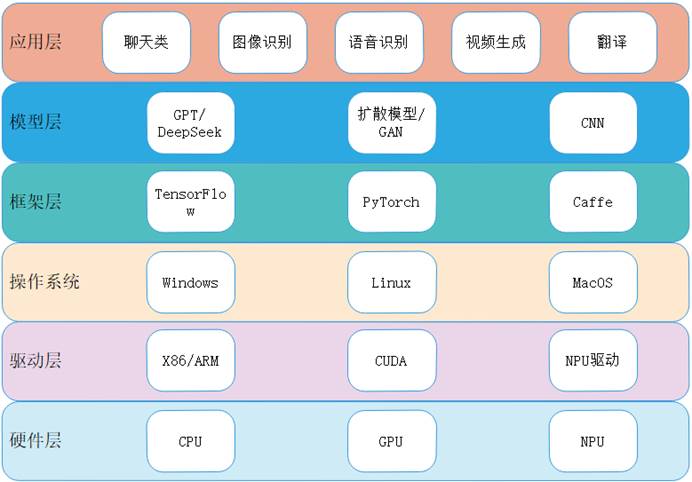
二 硬件层
最底层:硬件。进一步的,以GPU、NPU为代表。
GPU为通用算力代表,NPU为专用算力代表。
GPU早期为图像渲染芯片,是专用算力(图形渲染)代表。慢慢的,因为并行计算需求的旺盛,逐渐发展为通用并行算力代表。英伟达也据此推出以CUDA为代表的统一计算设备架构,打通软硬件通路,从更高的抽象层次简化并行计算。从图形渲染到并行计算到AI的矩阵运算,这类处理都有一个共同点:单指令多数据且运算量大,大量数据可以以同一种算式进行并行计算。这也是为啥需要专门的算力芯片以及为啥这样做行得通。
NPU为神经网络处理单元,主要用于神经网络模型的高效运行,有点GPU早期针对图形渲染的味道。目前这类处理单元主要与嵌入式端侧平台结合,用于端边侧的人工智能推理。它并没有形成一个计算平台,而是在无GPU的端边侧嵌入式设备为了高效运行大模型而推出的专用计算网络。注意,NPU主要用于模型的推理,或者说是运行,而非模型的训练。模型的训练仍然在GPU端。从本质上来讲,NPU可以说是一个专门进行高效矩阵运算的芯片。
GPU和NPU的区别:GPU更为通用,底层是更为基础的乘-加运算,组合方式多样,可以编程满足不同类型运算的需求,不单单是图形渲染,AI矩阵运算等。而NPU则更为专用,主要进行模型推理运算,其底层基础将GPU的乘-加分类小算子合并为乘加大算子,减少运算过程中数据、指令的内部搬运,其运算过程更体现一步到位的特点。简而言之,一个保留了更基础的算子,以保持灵活性,一个针对特定场景和需求,整合出了公共大算子,牺牲一定的灵活性,从而追求更加极致的速度。
举例来讲,CPU最灵活,可以执行的指令种类丰富,但是完成AI推理运算,则每一中间步骤都需要先运算存储,再取存储结果进行下一轮计算。GPU则可以提取矩阵的乘、加运算,进行并行计算,同时可以编程对运算过程进行组合处理。而NPU则基本只能执行固定的乘加运算,需要CPU先将数据按内部格式要求,提前准备好,然后批量喂给NPU,NPU内部一气呵成,不需要提交中间运算结果。总结起来,追求速度,就需要牺牲灵活性,通过将原来的多步骤运算合并到一步中,并且由硬件内部自动串接实现来完成,从而达到运算速度的提升。
三 驱动与操作系统层
硬件之上就是驱动层。驱动的宿主是操作系统。所有硬件设备都需要驱动来管理。CPU本身其实也需要驱动,只不过因为CPU往往承担了主人的身份,我们不将这部分称呼为驱动,而是架构。操作系统的架构层包括了各种架构的CPU芯片,比如X86架构,ARM架构等。而附着在CPU周边的硬件设备,其管理软件则被正式称呼为驱动。GPU也需要驱动,只不过在人工智能时代,GPU的驱动已远远超出常规的图形驱动范围,不再简单是操作系统图形架构的末端死板执行者,而是转变为一种计算设备。我们可以在CPU端编写计算逻辑,然后通过这个特殊驱动提交给GPU执行。英伟达将其称为CUDA。不同的芯片厂家,其提供的计算框架不同。有了这一层封装,GPU就可以按自己的节奏进行升级换代,从而实现与CPU的解耦。NPU也是类似,虽然其不如GPU那样灵活通用,但是要工作起来,仍然需要相关的驱动,这一点是不变的。
通过操作系统、驱动、设备的组合,人工智能底层计算的环境就准备好了。操作系统仍然是管理这些硬件的基础软件。
四 框架层
同其他特定场景或领域的应用类似,人工智能也有自身的特点,针对这些特点,为了提升效率,人们创造了应用于这些场景的框架软件。就像我们要进行图形开发,就有图形框架软件,这类软件帮我们封装好了一些基础元素,比如怎么画点线面,更进一步,还提供更加复杂的一些控件。这样再去开发图形界面,就方便多了。比如游戏开发,就有游戏引擎。对于人物的移动以及关联的光影变化效果等,都有通用的一些封装。还有像电路图的设计、建筑物的设计等等。人工智能领域也有自身的专用框架,比如Tensorflow,Pytorch等,这些框架也封装了一些基础算子,比如向量的各种运算和组合,一些通用的库等等,方便我们进行模型的开发和设计。这样一来,大家都可以基于这些基础组件进行二次开发丰富,同时也不断完善扩展已有的库,避免重复造轮子的情况,从而提升了总体的效率,减少了资源浪费。
五 模型层
框架只是一个基础,就像一个数控机床,怎么用,用它做出什么,仍然是使用者决定的。对于人工智能而言,框架之上就是模型。模型可以说是算法的载体,模型定了,算法的能力上限也就定了。关于模型,我们平常会听到很多相关的概念,这些概念的差异是什么,这里做一个简单的介绍。在介绍模型的概念前,我们需要先了解人工智能中的各种学习,具体可以参考博主之前的一篇博文:https://blog.csdn.net/wwwyue1985/article/details/124233741。有了这篇参考博文做基础,我们这里说的模型可以说是以深度学习为基础,更基础一些是以深度神经网络为基础。学习是一个通用概念,机器学习仍然是一个通用概念,讲述的是一个比较笼统的学习的概念。而各种不同学习体现的是学习的特点,好比说某个人擅长记忆,某个人擅长推理,某个人擅长心算等等。这些都是从特点出发,而非一个具体的可触摸可感知的东西。但是到模型这一块就不同了,这里面既有通用的含义,也有具体的含义。我们从具体到一般来看,这样比较好理解。以大家比较熟悉的Chat-GPT为例,这是一个具体的模型,是由一大堆数据组合训练构成的一些列权重系数的表达按特定格式构成的一个文件。我们可以以一个视频文件来对比说明。对于Chat-GPT这个大模型,更具体的说是大语言模型而言,最终训练结果是以一个模型文件体现的。这个文件有其自身的格式。DeepSeek训练的结果也是以一个模型文件体现的,这两个模型可能体现为同一种格式的文件,好比同一种格式的视频文件。同样的格式说明文件的开始部分是什么,中间部分是什么,结尾部分是什么,这些含义是明确的。对于某种格式的视频文件而言,开始可能是该视频文件的说明,比如名字,时长,编解码格式,帧率等等,中间可能是具体的一帧一帧的视频画面数据,结尾可能是字幕或其他辅助信息。而对某一种模型文件而言,开始也大概率是模型的说明,包括模型的参数大小、token长度、底层算法类型(神经网络)、层数等,中间是各个层的权重系数文件,结尾是辅助信息等。两个模型文件虽然格式一致,但不同内容所最终表达的功能是不同的。这就好比两个视频文件,文件格式一样,但是包含的视频帧内容可能不一样,播放出来的画面也就不一样。不仅内容可能不一样,播放的时长、画面大小、清晰度也可能是不一样的。模型即便文本格式一样,其训练参数、层数、内部算法也完全可能不一样。即便一样,因为训练数据不同,导致权重系数不同,最终功能的表达也是有差异的。以上,我们通过类比视频文件,介绍了具体的模型和模型文件。这里的模型文件就可以放到框架层之上了。
同样作为大语言模型,同样作为同一种格式的模型文件,Chat-GPT和DeepSeek内部的算法却是不一样的。GPT是生成式-预训练TRANSFORMER模型,而DeepSeek用到了强化学习。推而广之,就GPT而言,其本质上也是属于深度学习的深度神经网络模型,每一层就是一个Transformer自注意力编解码层。同样是神经网络,处理图像识别的CNN卷积神经网络和GPT就完全不一样。还有其他的一些神经网络模型,用于处理其他特定领域的问题,比如音频、视频等。这里,识别和生成又是不同角度的分类。此时,我们将具体的模型推广到了一般的模型。所以,我们说模型这个概念时,可能是指具体的某一个模型,也可能是指具有某种特点的一类模型。就以GPT为例,层数不同,token长度不同,即便是同样的算法,训练的结果也是不一样的。就好比同样的编码算法,分辨率不同,帧率不同,最终播放的视频效果也是不同的。而且即便是同一个模型文件,通过提示词工程,通过RAG,通过微调优化,最终应用效果也可能是不一样的。这就引入了模型最上层,应用层。
六 应用层
应用层是模型的最终应用。前面提过了,有识别类应用和分类类应用。有自然语言交互类应用,也有图像音频等多媒体处理类应用,还有语言翻译等等。这些具体的应用场景是我们切入人工智能的好入口。所有这类人工智能应用的底层基础就是模型文件。先有模型,再通过封装,二次处理,得到人工智能应用。没有应用落地,再好的模型也是空中楼阁。但是,同一个模型,其潜力也是待挖掘的,同样的模型文件,不同的厂家做出的应用效果可能是不一样的。
前面我们从底层到应用分层了解了人工智能整体框架,下面我们再从应用到底层,梳理整个体系。应用层是最好理解的。大量的应用都需要底层模型的支撑。模型则需要大量数据来训练,同时也需要好的算法引导。为了方便开发训练,人们开发了框架,构建了算子库,还提供了各种工具库,以此加快模型的训练和验证。这些训练工作需要大量算力保障,这就最终依赖底层的GPU支撑。训练完成后,为了方便模型的使用,训练结果会按特定格式生成模型文件。拿到模型文件后,各个厂家就可以基于GPU或NPU进行推理,实现模型的实际应用。如此,我们从工程角度梳理了从模型应用到底层硬件的整个过程。
七 其他:
到这里,我们还有几个问题需要额外说明:
1 理论与工程实际的鸿沟
前面我们介绍整个框架构成时,大多时候都是基于工程实际来展开的,特别是关于算法和模型。但是,一个算法从理论想法到工程实际落地,还需要经过大量的验证、调整、优化等工作,如何在理论和实际之间搭建一个桥梁,让天堑变通途,往往是比较难的。这个过程中,很多算法往往因为得不到理想结果而早早夭折。不过,也有一些算法,经受了实践的考验,而留了下来,这就是前面提到过的一些神经网络模型。这些模型已经是具备一般概念的模型了。也就是说,这类模型具有一定的特点,通过二次加工,就可以用于特定的场景。再一般化一下,这类网络又是深度学习的子集,而深度学习又是神经网络和机器学习的子集。机器学习又根据学习的特点分为有监督学习和无监督学习,以及强化学习。所以,梳理这些概念,区分理论和工程实际,将有利于我们更好的掌握人工智能领域的相关知识。从前面的介绍我们也可以感受到,相对于通用的理论概念,工程实际的东西还是更好理解一些。
2 语言模型与世界模型
GPT的大火,带动人工智能的发展冲上了又一个高峰。前一个峰点,还是打败李世石的阿尔法狗。再往前,可能是辛顿团队基于深度神经网络开发的图像识别模型。每一个引爆点都带来了新的认知和期待。站在当前峰点,有人已经认为大语言模型会带来真正的智能,超越人类自身的智能,因为语言就是人类本身创造的交流符号,通过语言,机器就可以学会人类的所有知识,从而涌现智能。当然,也有另外一种观点,认为语言是人类自身创造的东西,并不是真正原始智能的来源,动物没有语言,但是却具有明显的智能属性。所以,这类观点认为,语言模型是有其局限的,要想获取真正的智能,需要的是世界模型,就是让机器在自然世界中学习,而非仅仅通过语言。比如,对于自动驾驶来讲,仅仅通过语言并不能学会驾驶,而是需要在实际世界中学习,机器人类的应用也是如此。通过构建物理世界模型,让机器在该世界中学习,才能获得真正的智能。当然,那条路是正确的,时间会给出答案,但是,无论如何,都不能否认人工智能已经融入我们的日常生活了,而且随着时间的推移,这种交融只会越来越密,越来越深。下一个全新的时代,也就真的就是人工智能创造的或者是人工智能带来的。