前言
上篇分享《LangChain1.0实战之多模态RAG系统(二)------多模态RAG系统图片分析与语音转写功能实现》中,笔者系统探讨了如何基于 Qwen3-Omni 多模态大模型实现图片分析与音频处理的能力。作为多模态 RAG 系统的核心组成部分,对 PDF 文档的解析回答与引用溯源同样至关重要。
本文将重点介绍如何实现对上传 PDF 的结构化解析,构建具备引用溯源能力的问答系统。系统不仅能够依据文档内容进行准确回答,还将在回复中实时标注原始出处,方便用户进行信息追溯与验证。
学习前置要求:本文是系列的第三篇,强烈建议大家先掌握第一、二篇中介绍的项目架构、环境配置和基础代码实现,这将有助于大家更好地理解本文的内容。
本系列内容适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。当然,如果大家已经学习过我的专栏《深入浅出LangChain&LangGraph AI Agent 智能体开发》,相信可以更快上手。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 29讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
一、多模态PDF处理流程解析
1.1 标准处理流程
多模态PDF文档的处理通常遵循一套标准化的流程,下面笔者将逐步解析各个环节的关键技术与实现思路:
1.1.1 文档内容提取
根据PDF文档类型的不同,可以采用差异化的提取策略:
- 非影印版文档:使用PyMuPDF、PyPDF2等工具直接提取文本、图片和表格内容。图片在提取后通过URL占位符进行标记,保持文档结构的完整性。
- 影印版/扫描版文档:借助DeepSeek-OCR、Paddle-OCR等OCR引擎将图像内容转换为可读的Markdown格式。特别值得注意的是,对于跨页表格的识别难题,推荐尝试OCRFlux-3b模型,其在复杂版面分析方面表现出色。
1.1.2 文档检索优化策略
直接将完整文档内容嵌入提示词(Prompt)虽然实现简单,但存在明显缺陷:
- 引入大量无关信息,干扰模型推理过程
- 受限于大模型的Token输入上限,无法处理大规模文档
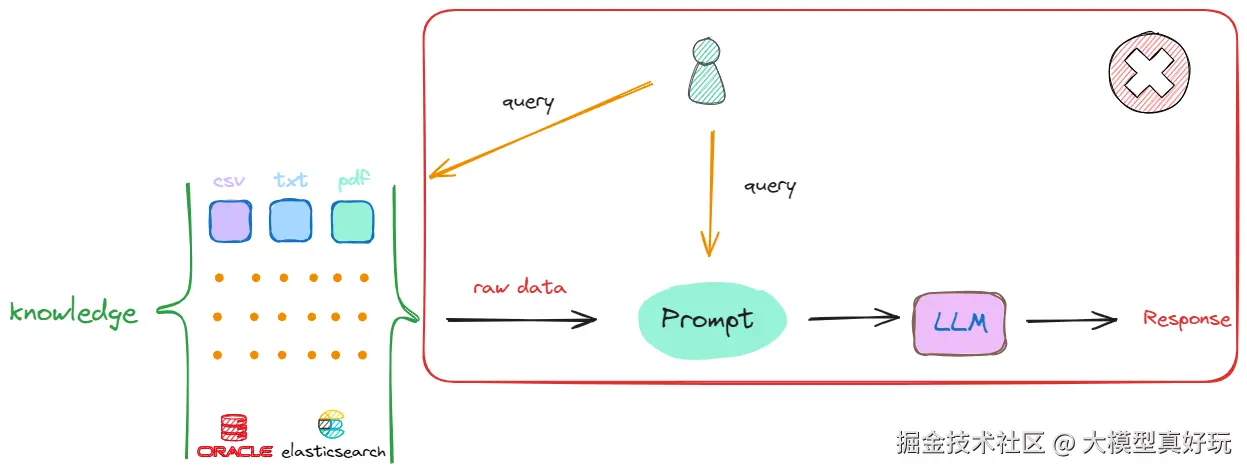
1.1.3 文档分块处理
为解决上述问题,通常采用文档分块策略:
- 将原始文档按段落或固定长度(有很多精细的文档切分策略,这里只列举了两种比较简单的)切分为多个语义完整的片段
- 如图示,原始数据1被分割为chunk1至chunk4
- 所有文档经过相同处理后,形成统一的知识库存储
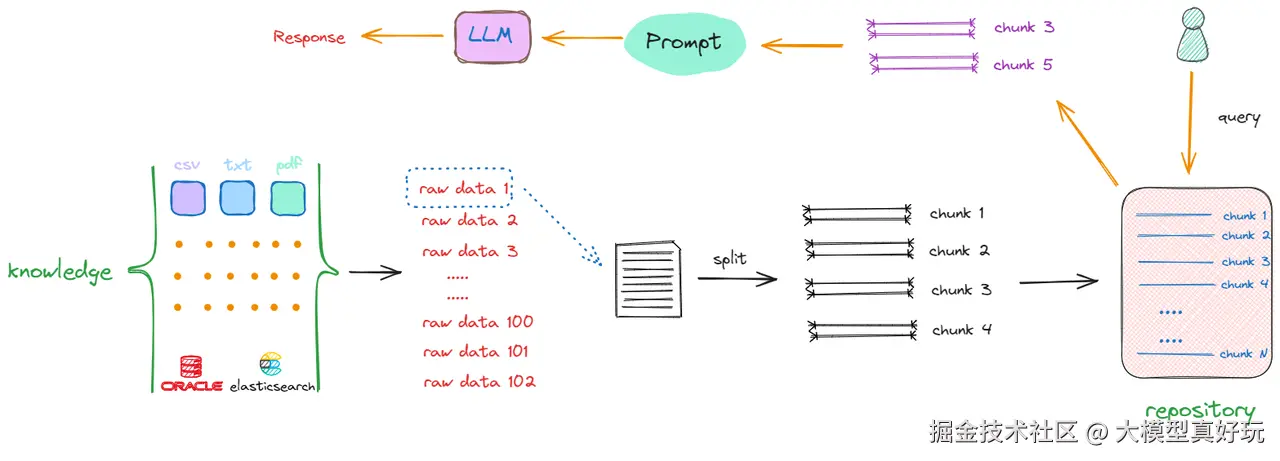
1.1.4 语义检索机制
当用户发起查询时,系统执行以下操作:
- 在分块知识库中进行语义搜索
- 返回相关性最高的多个文本片段
- 将这些片段作为上下文信息与用户原始查询组合,输入大模型生成最终答案
1.1.5 向量化与语义理解
文本分块后仍面临语义理解挑战:
- 单纯的字词匹配无法准确衡量文本相似度
- 需要挖掘文本深层的语义信息
解决方案是引入Embedding技术:
- 将所有文本块转换为高维向量表示
- 通过向量相似度计算实现精准的语义匹配
向量数据库在这个过程中扮演关键角色,专门用于存储:
- 每个文本块的语义向量
- 对应的原始文本内容
- 通过语义向量匹配实现高效的检索
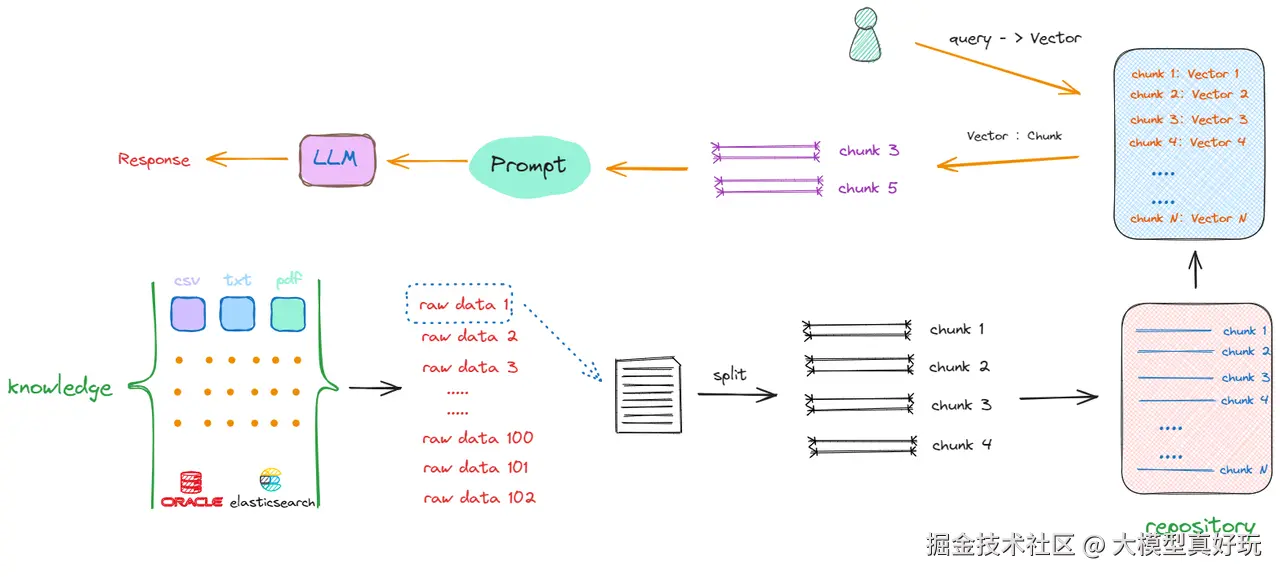
如上所示解决搜索效率和计算相似度优化算法的答案就是向量数据库,主要用于保存每个块的语义向量及其原始文字内容。通过语义向量匹配,原始文字与Query拼接。
1.1.6 溯源引用实现
实现答案溯源的技术要点:
数据存储层面:
-
向量数据库存储语义向量和原始文本
-
关联结构化数据库存储块的元信息:
- 原始文档标识
- 页码位置
- 段落位置等详细信息
提示词设计:
- 在系统提示词中明确要求:引用内容必须标注来源索引
- 确保生成答案具备完整的可追溯性
1.2 可溯源RAG系统核心工作流
笔者这里将上述过程进行了总结:
- OCR识别 - 提取原始文档内容
- 内容分块 - 将文档转化为语义块,记录原始内容和溯源元信息
- 向量化存储 - 将文本块转换为向量,分别存储在向量数据库和关联数据库中
- 提示词构建 - 组合系统提示词、相关文本块和用户查询,生成可溯源的回答
对于以上流程,LangChain提供了非常完美的支持,大家可以看笔者下面这张图迅速找到相关技术的langchain工具库:
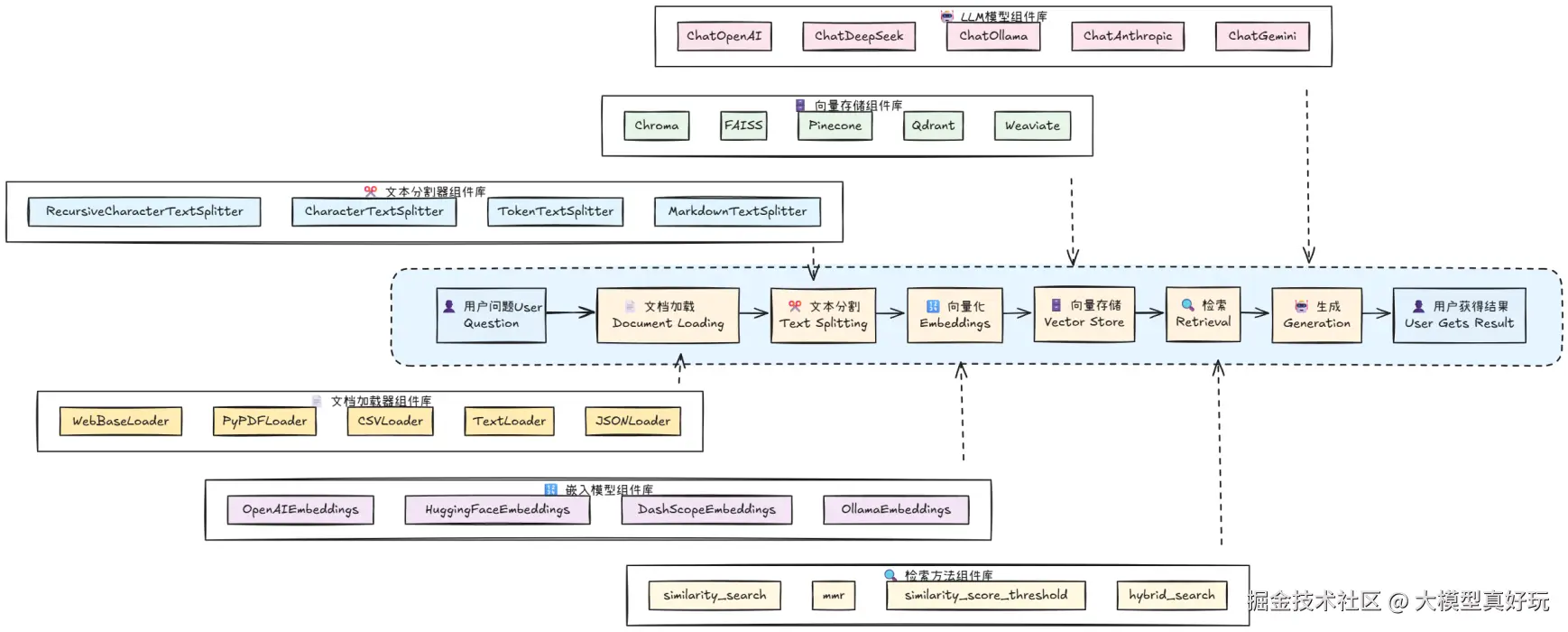
理论介绍就到这里啦,想了解更完整的RAG原理知识大家可以参考笔者文章一文带你了解RAG核心原理!不再只是文档的搬运工, 接下来让笔者通过具体的代码实例来深入分享整个实现过程。
二、多模态PDF处理代码实现
2.1 多模态PDF处理代码编写
-
环境配置与依赖安装: 在开始编写代码前,需要安装必要的依赖包。根据搜索结果,PyMuPDF是处理PDF文档的推荐工具,具有处理速度快、功能全面的优势。
pip install PyMuPDF langchain_text_splitters
- PDF处理工具类实现: 创建
pdf_utils.py文件,实现PDF处理的核心逻辑。本示例主要展示基于文本的PDF处理流程,OCR相关功能可作为扩展练习。
python
import base64
import io
import fitz # PyMuPDF
from PIL import Image
from typing import List, Dict, Any, Iterator
from langchain_text_splitters import RecursiveCharacterTextSplitter
import os
class PDFProcessor:
def __init__(self):
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", " ", ""]
)
@staticmethod
async def extract_pdf_pages_as_images(self, file_content: bytes, max_pages: int = 5) -> List[str]:
"""
因为上传的pdf有时候会是扫描件,无法直接读取文字,通常需要将文档的每页作为图片提取出来并作OCR处理
"""
try:
pdf_document = fitz.open(stream=file_content, filetype="pdf")
total_pages = len(pdf_document)
pages_to_extract = min(max_pages, total_pages)
images = []
for page_num in range(pages_to_extract):
page = pdf_document.load_page(page_num)
pix = page.get_pixmap()
img = Image.frombytes("RGB", (pix.width, pix.height), pix.samples)
buffer = io.BytesIO()
img.save(buffer, format="PNG")
base64_image = base64.b64encode(buffer.getvalue()).decode("utf-8")
images.append(base64_image)
pdf_document.close()
return images
except Exception as e:
raise
@staticmethod
def read_pdf_pages(pdf_path):
# 检查文件是否存在
if not os.path.exists(pdf_path):
print(f"错误:文件 '{pdf_path}' 不存在")
return {}
async def process_pdf(self, file_content: bytes, filename: str):
"""
流式处理PDF文档
返回处理进度和结果
"""
try:
# Step 1: 保存临时文件
print('保存临时文件')
# 创建临时文件
tmp_file_path = r'temp\' + filename
with open(tmp_file_path, 'wb') as f:
f.write(file_content)
full_text = ""
doc = fitz.open(tmp_file_path)
# 存储每页内容
pages_content = {}
# 逐页读取内容
for page_num in range(len(doc)):
page = doc[page_num]
# 提取文本
text = page.get_text()
full_text += text
# 存储页面内容
pages_content[page_num + 1] = text
print(f"合并后文本长度: {len(full_text)} 字符")
# 调试:输出前200个字符看看提取到了什么
preview = full_text[:200] if full_text else "空内容"
print(f"文本预览: {repr(preview)}")
# 使用RecursiveCharacterTextSplitter进行智能分块
text_chunks = self.text_splitter.split_text(full_text)
print(f"文本分块完成,共 {len(text_chunks)} 个块")
# Step 4: 构建文档块
print(f"正在构建 {len(text_chunks)} 个文档块...")
# 构建带元数据的文档块(包含页码信息)
document_chunks = []
for i, chunk in enumerate(text_chunks):
if chunk.strip(): # 过滤空块
# 尝试从原始文档块中获取页码信息
page_number = 1 # 默认页码
sorted_keys = sorted(pages_content.keys())
for page_number in sorted_keys:
if chunk.strip()[:50] in pages_content[page_number]:
break
doc_chunk = {
"id": f"{filename}_{i}",
"content": chunk.strip(),
"metadata": {
"source": filename,
"chunk_id": i,
"chunk_size": len(chunk),
"total_chunks": len(text_chunks),
"page_number": page_number,
"reference_id": f"[{i + 1}]",
"source_info": f"{filename} - 第{page_number}页"
}
}
document_chunks.append(doc_chunk)
print(document_chunks)
# Step 5: 完成处理
print(f"处理完成!共生成 {len(document_chunks)} 个文档块")
# 返回处理结果
return document_chunks
except Exception as e:
print(f"PDF处理失败: {str(e)}")
return {
"type": "error",
"error": f"PDF处理失败: {str(e)}"
}- 数据结构扩展: 回顾笔者在LangChain1.0实战之多模态RAG系统(二)------多模态RAG系统图片分析与语音转写功能实现中定义的核心数据结构,在
MessageRequest中添加pdf_chunks用于存储切分后的文档块:
python
class ContentBlock(BaseModel):
type: str = Field(description="内容类型: text, image, audio")
content: Optional[str] = Field(description="内容数据")
class MessageRequest(BaseModel):
content_blocks: List[ContentBlock] = Field(default=[], description="内容块")
history: List[Dict[str, Any]] = Field(default=[], description="对话历史")
pdf_chunks: List[Dict[str, Any]] = Field(default=[], description="PDF文档块信息,用于引用溯源")
class MessageResponse(BaseModel):
content: str
timestamp: str
role: str
references: List[Dict[str, Any]] # PDF的引用- 多模态消息构建增强: 在
create_multimodal_message函数中添加PDF文档块处理逻辑。 在这篇文章中笔者限于时间问题并没有将切分后的文本块存储在向量库中,还是一股脑增加到提示词中。这块也是给读者留一个小练习,大家可以参考笔者文章深入浅出LangChain AI Agent智能体开发教程(九)---LangChain从0到1搭建知识库自定义向量库和结构化数据库存储文档块的向量和索引元信息对系统进行优化。这样就不需要把切分块一股脑放到用户消息提示词中,只需要根据用户提问检索出相应块,将相应块的内容和索引元信息放入提示词中即可。
python
def create_multimodal_message(request: MessageRequest, image_file: UploadFile | None, audio_file:UploadFile | None) -> HumanMessage:
"""创建多模态消息"""
message_content = []
# 如果有图片
if image_file:
processor = ImageProcessor()
mime_type = processor.get_image_mime_type(image_file.filename)
base64_image = processor.image_to_base64(image_file)
message_content.append({
"type": "image_url",
"image_url": {
"url": f"data:{mime_type};base64,{base64_image}"
},
})
if audio_file:
processor = AudioProcessor()
mime_type = processor.get_audio_mime_type(audio_file.filename)
base64_audio = processor.audio_to_base64(audio_file)
message_content.append({
"type": "audio_url",
"audio_url": {
"url": f"data:{mime_type};base64,{base64_audio}"
},
})
# 处理内容块
for i, block in enumerate(request.content_blocks):
if block.type == "text":
message_content.append({
"type": "text",
"text": block.content
})
elif block.type == "image":
# 只有base64格式的消息才会被接入
if block.content.startswith("data:image"):
message_content.append({
"type": "image_url",
"image_url": {
"url": block.content
},
})
elif block.type == "audio":
if block.content.startswith("data:audio"):
message_content.append({
"type": "audio_url",
"audio_url": {
"url": block.content
},
})
if request.pdf_chunks:
pdf_content = "\n\n=== 参考文档内容 ===\n"
for i, chunk in enumerate(request.pdf_chunks):
content = chunk.get("content", "")
source_info = chunk.get("metadata", {}).get(
"source_info", f"文档块 {i}")
pdf_content += f"\n[{i}] {content}\n来源: {source_info}\n"
pdf_content += "\n请在回答时引用相关内容,使用格式如 [1]、[2] 等。\n"
for i in range(len(message_content) - 1, -1, -1):
item = message_content[i]
if item['type'] == 'text':
item['text'] += pdf_content
break
return HumanMessage(content=message_content)- 系统提示词优化: 在
convert_history_to_messages函数中增强系统提示词,明确引用要求:
python
def convert_history_to_messages(history: List[Dict[str, Any]]) -> List[BaseMessage]:
"""将历史记录转换为 LangChain 消息格式,支持多模态内容"""
messages = []
# 添加系统消息
system_prompt = """
你是一个专业的多模态 RAG 助手,具备如下能:
1. 与用户对话的能力。
2. 图像内容识别和分析能力(OCR, 对象检测, 场景理解)
3. 音频转写与分析
4. 知识检索与问答
重要指导原则:
- 当用户上传图片并提出问题时,请结合图片内容和用户的具体问题来回答
- 仔细分析图片中的文字、图表、对象、场景等所有可见信息
- 根据用户的问题重点,有针对性地分析图片相关部分
- 如果图片包含文字,请准确识别并在回答中引用
- 如果用户只上传图片没有问题,则提供图片的全面分析
引用格式要求(重要):
- 当回答基于提供的参考文档内容时,必须在相关信息后添加引用标记,格式为[1]、[2]等
- 引用标记应紧跟在相关内容后面,如:"这是重要信息[1]"
- 每个不同的文档块使用对应的引用编号
- 如果用户消息中包含"=== 参考文档内容 ==="部分,必须使用其中的内容来回答问题并添加引用
- 只需要在正文中使用角标引用,不需要在最后列出"参考来源"
请以专业、准确、友好的方式回答,并严格遵循引用格式。当有参考文档时,优先使用文档内容回答。
"""
messages.append(SystemMessage(content=system_prompt))
# 转换历史消息
for i, msg in enumerate(history):
content = msg.get("content", "")
content_blocks = msg.get("content_blocks", [])
message_content = []
if msg["role"] == "user":
for block in content_blocks:
if block.get("type") == "text":
message_content.append({
"type": "text",
"text": block.get("content", "")
})
elif block.get("type") == "image":
image_data = block.get("content", "")
if image_data.startswith("data:image"):
message_content.append({
"type": "image_url",
"image_url" : {
"url": image_data
}
})
elif block.get("type") == "audio":
audio_data = block.get("content", "")
if audio_data.startswith("data:audio"):
message_content.append({
"type": "audio_url",
"image_url": {
"url": audio_data
}
})
messages.append(HumanMessage(content=message_content))
elif msg["role"] == "assistant":
messages.append(AIMessage(content=content))
return messages- 引用提取功能: 新增
extract_references_from_content函数,从模型回答中提取引用信息:
python
def extract_references_from_content(content: str, pdf_chunks: list = None) -> list:
print('模型输出内容:',content)
references = []
reference_pattern = r'[(\d+)]'
matches = re.findall(reference_pattern, content)
print(matches)
if matches and pdf_chunks:
for match in matches:
ref_num = int(match)
if ref_num <= len(pdf_chunks):
chunk = pdf_chunks[ref_num] # 索引从0开始
reference = {
"id": ref_num,
"text": chunk.get("content", "")[:200] + "..." if len(
chunk.get("content", "")) > 200 else chunk.get("content", ""),
"source": chunk.get("metadata", {}).get("source", "未知来源"),
"page": chunk.get("metadata", {}).get("page_number", 1),
"chunk_id": chunk.get("metadata", {}).get("chunk_id", 0),
"source_info": chunk.get("metadata", {}).get("source_info", "未知来源")
}
references.append(reference)
return references- 流式响应生成增强: 在
generate_streaming_response函数中集成引用提取功能:
python
async def generate_streaming_response(
messages: List[BaseMessage],
pdf_chunks: List[Dict[str, Any]] = None
) -> AsyncGenerator[str, None]:
"""生成流式响应"""
try:
model = get_chat_model()
# 创建流式响应
full_response = ""
chunk_count = 0
async for chunk in model.astream(messages):
chunk_count += 1
if hasattr(chunk, 'content') and chunk.content:
content = chunk.content
full_response += content
# 直接发送每个chunk的内容,避免重复
data = {
"type": "content_delta",
"content": content,
"timestamp": datetime.now().isoformat()
}
yield f"data: {json.dumps(data, ensure_ascii=False)}\n\n"
# 提取引用信息
references = extract_references_from_content(full_response, pdf_chunks) if pdf_chunks else []
# 发送完成信号
final_data = {
"type": "message_complete",
"full_content": full_response,
"timestamp": datetime.now().isoformat(),
"references": references
}
yield f"data: {json.dumps(final_data, ensure_ascii=False)}\n\n"
except Exception as e:
error_data = {
"type": "error",
"error": str(e),
"timestamp": datetime.now().isoformat()
}
yield f"data: {json.dumps(error_data, ensure_ascii=False)}\n\n"- API接口集成: 在FastAPI接口中集成PDF处理功能
python
@app.post("/api/chat/stream")
async def chat_stream(
image_file: UploadFile | None = File(None),
content_blocks: str = Form(default="[]"),
history: str = Form(default="[]"),
audio_file: UploadFile | None = File(None),
pdf_file: UploadFile | None = File(None)
):
"""流式聊天接口(支持多模态)"""
try:
# 解析 JSON 字符串
try:
content_blocks_data = json.loads(content_blocks)
history_data = json.loads(history)
except json.JSONDecodeError as e:
raise HTTPException(status_code=400, detail=f"JSON 解析错误: {str(e)}")
if pdf_file:
pdf_processor = PDFProcessor()
pdf_content = await pdf_file.read()
pdf_chunks = await pdf_processor.process_pdf(file_content=pdf_content, filename=pdf_file.filename)
request_data = MessageRequest(content_blocks=content_blocks_data, history=history_data, pdf_chunks=pdf_chunks)
else:
# 创建请求对象(用于传递给其他函数)
request_data = MessageRequest(content_blocks=content_blocks_data, history=history_data)
# 转换消息历史
messages = convert_history_to_messages(request_data.history)
# 添加当前用户消息(支持多模态)
current_message = create_multimodal_message(request_data, image_file=image_file, audio_file=audio_file)
messages.append(current_message)
print(messages)
# 返回流式响应
return StreamingResponse(
generate_streaming_response(messages, pdf_chunks if pdf_file is not None else None),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Type": "text/event-stream",
}
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))完成以上代码开发工作就基本完成~ 本文提供的完整源代码可通过关注笔者的同名微信公众号大模型真好玩 ,并私信LangChain智能体开发免费获取。
2.2 PDF知识库功能测试
测试配置
使用Postman进行接口测试,配置参数如下:
- content_blocks :
[{"type": "text", "content": "请依据参考文档描述关羽的相关情况"}] - history :
[] - pdf_file: 上传包含关羽介绍的自定义PDF文档
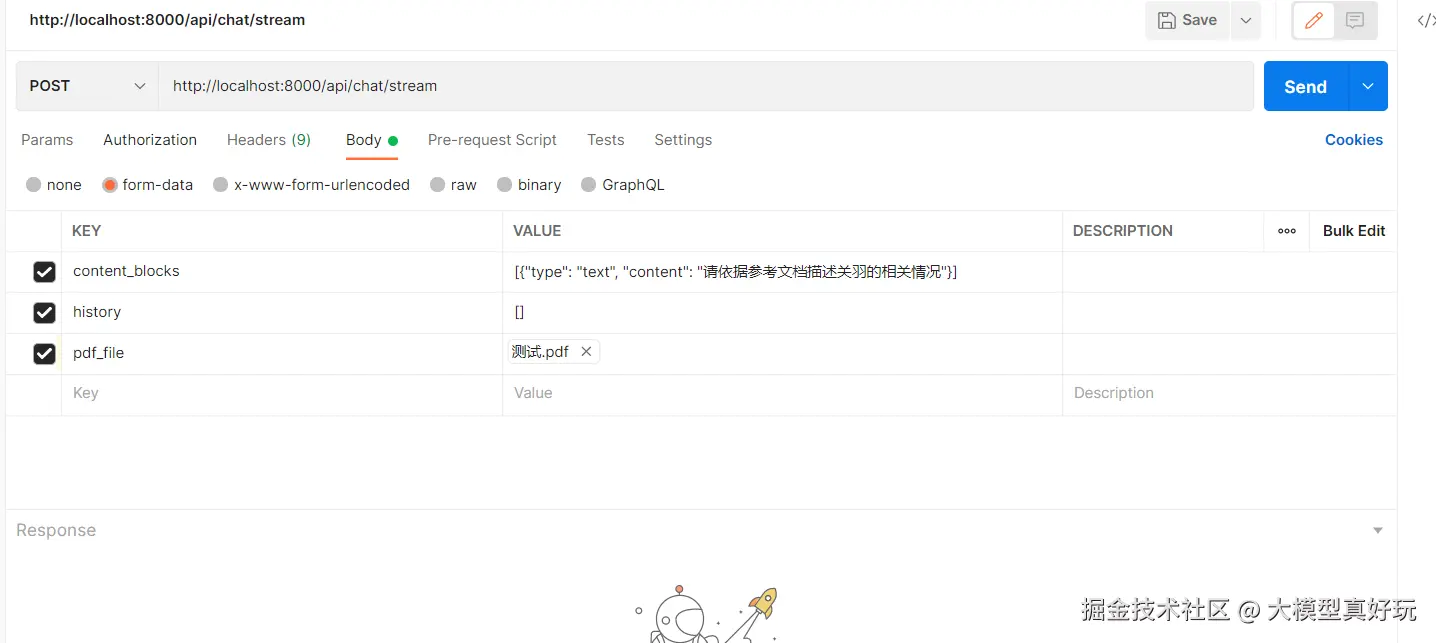
测试结果分析
系统正确识别了PDF文档中关于关羽的内容,回答中准确使用了引用标记[0]指向对应的文档块(块0也就是我们上传文档的第一页,第一页是关羽的相关介绍),返回的引用信息包含了完整的溯源元数据。


2.3 系统优化方向
大家注意当前实现只是作为基础版本,还有很多的优化空间:
1. 向量数据库集成
使用向量数据库存储文档嵌入向量,实现基于语义的相似度检索,替代当前的全文本匹配方式
2. 多文档知识库管理
扩展系统支持多个PDF文档的管理,建立完整的知识库体系。
3. OCR功能增强
集成OCR模型(如PaddleOCR、DeepSeek-OCR)处理扫描版PDF文档
大家可参考笔者的文章《深入浅出LangChain AI Agent智能体开发教程(九)---LangChain从0到1搭建知识库》进一步完善系统功能,这里就将以上的优化点作为一个大的课后练习吧~
三、总结
本文详细分享了基于LangChain的多模态RAG系统中PDF文档处理的全流程,涵盖PDF解析、文本分块、引用溯源等核心技术,并通过完整代码示例展示了如何实现具备文档引用功能的问答系统,为构建实用化多模态RAG应用提供实践指导。作为一个完整的系统项目,我们完成了后端的基础功能,当然也需要有用户友好的前端匹配才行呀,下期内容笔者将分享相关项目前端构建流程,大家敬请期待~
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前已更新29讲,正在更新实战篇和LangChain1.0实战项目多模态RAG系统开发,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。