cut
切割提取指定列\字符\字节的数据,文本处理工具
语法
cut options filename
|-----------|---------------------------------|
| 选项参数 | 功能 |
| -f 提取范围 | 列号,获取第几列 |
| -d 自定义分隔符 | 默认为制表符 |
| -c 提取范围 | 以字节为单位进行分割 |
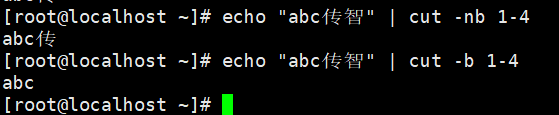
| -b 提取范围 | 以字节为单位进行分割,忽略多字节字符边界,除非指定了-n 标志 |
| -n | 与"-b" 连用,不分割多字节字符 |
提取范围
|-------|--------------------------------------|
| 范围 | 说明 |
| n- | 提取指定第 n 列或字符或字节后面所有数据 |
| n-m | 提取指定第n列或字符或字节到 第m列 或 字符 或 字节中间 的所有数据 |
| -m | 提取指定第m列或字符或字节前面所有数据 |
| n1,n2 | 提前指定枚举 列 的所有数据 |
示例:
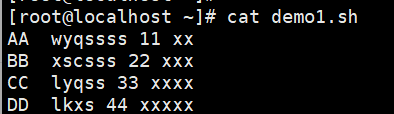
#脚本文件
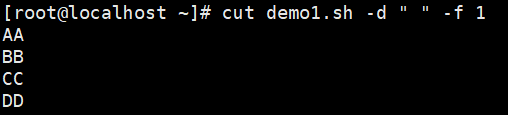
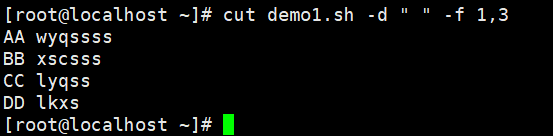
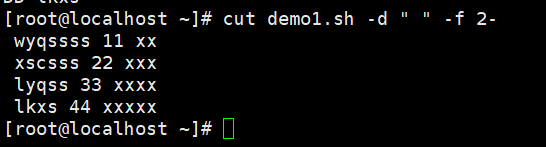
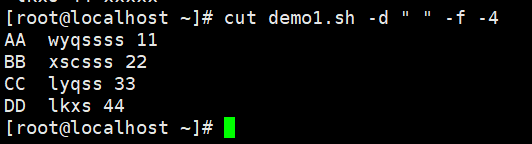
#以空格为分割,AA:第1列 ;空格:第2列;wyqssss:第3列;11:第4列;xx:第5列#提取第一列
#提取1和3列
#第2列以后的数据
#第4列以前的数据
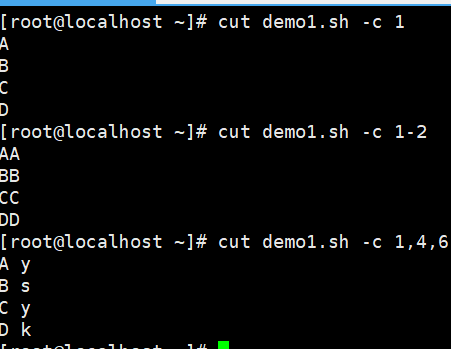
#按字符提取
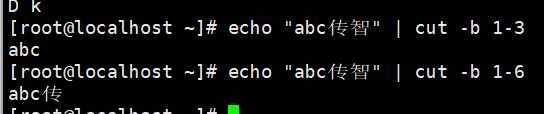
#按字节提取
#多字节会被阻断,-n可以避免
示例:切割指定单词数据
#先用 cat 获取指定的单词
#再 cut 进行切割

示例:切割提取bash进程PID号
查看指定的 bash 的pid号
只查看第一行
截取第9列



示例:切割提取ip地址
查看ip地址
截取出指定行
切割第10列


sed
sed (stream editor)是一个非交互式的流式文本编辑器(vim是交互式文本编辑器),可以对文本进行增删改查,非常适合大文件的编辑
sed一次处理一行数据,将这行放入缓存(存取空间称:模式空间),然后进行处理,最后将缓存区的内容发送到终端
语法
sed 选项参数 模式匹配/sed程序命令 文件名
|------------|------------------------------------------------------|
| 选项参数 | 说明 |
| -e | 直接在指令列模式进行sed编辑,当命令行给出多个sed指令才需要使用-e选项,一行命令可以执行多条sed |
| -i | 直接对内容进行修改,不加-i默认只是预览,不会对文件做实际修改 |
| -f | 后保存了sed指令的文件 |
| -n | 取消默认输出,sed默认会输出所有文本内容,使用-n参数后只显示处理过的行 |
| -r ruguler | 使用扩展正则表达式,默认情况sed只识别基本的正则表达式* |
sed程序命令功能描述
|----|---------------------------|
| 命令 | 功能描述 |
| a | add新增,a后,1可以接字串,在下一行出现 |
| c | change更改,更改匹配行的内容 |
| d | delete删除,删除匹配内容 |
| i | insert插入,向匹配行前插入内容 |
| p | print打印,打印出匹配内容,通常与-n选项和用 |
| s | substitute替换,替换掉匹配的内容 |
| = | 用来打印被匹配的行的行号 |
| n | 读取下一行,遇到n时会自动跳入下一行 |
特殊符号
|-----------------|-------------|
| 命令 | 描述 |
| ! | |
| {sed命令1;sed命令2} | 多个命令操作同一个的行 |
示例
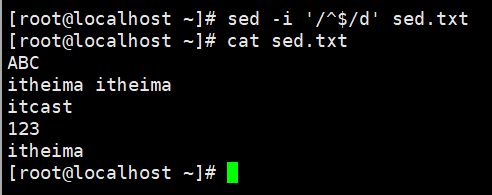
sed.txt文件内容
ABC
itheima itheima
itcast
123
itheima
示例:向文件中添加数据
演示1:指定行号的前或后添加数据
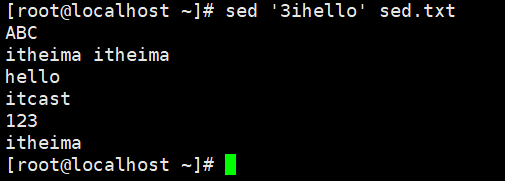
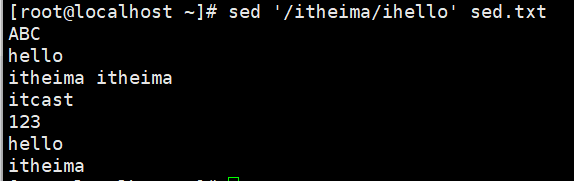
演示2:指定内容前/后添加数据
#前面
#后面
#最后一行
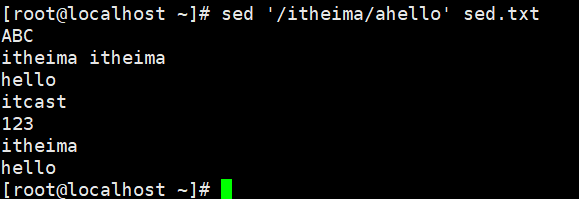
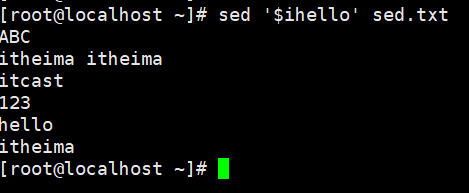
示例:删除文件中的数据
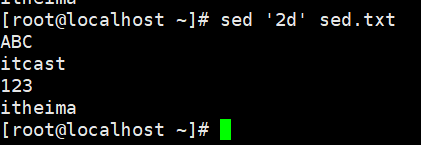
示例:删除第2行
sed '2d' sed.txt
d 表示删除
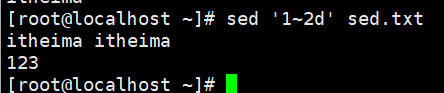
示例:删除奇数行
#从第1行开始,每隔2行删除
示例:删除指定范围的多行数据
删除 1到3行的数据
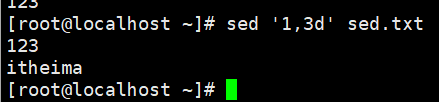
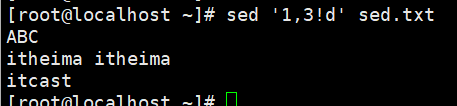
演示3:删除指定范围取反的多行数据
删除从第1行到第3行取反的数据
sed '1,3!d' sed.txt
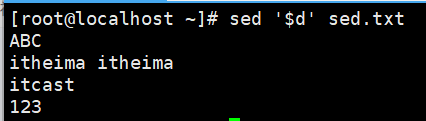
演示4:删除最后一行
演示5:删除匹配itheima的行

演示6:删除匹配行到最后一行

演示7:删除匹配行及后面一行
删除itheima 以及后面一行

演示8:删除不匹配的行
删除不匹配 itheima 或 itcast 的行

示例:更改文件中数据
演示1:将文件第1行修改为hello
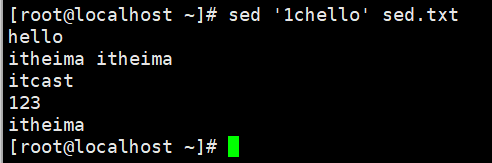
演示2:将包含itheima的行修改为hello
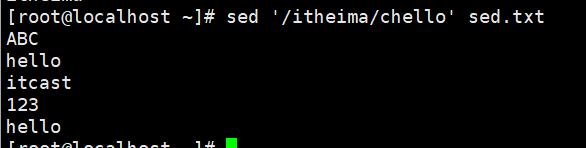
演示3:将最后一行修改为hello
#最后一行就是 $
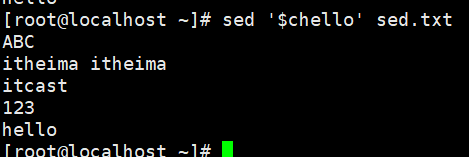
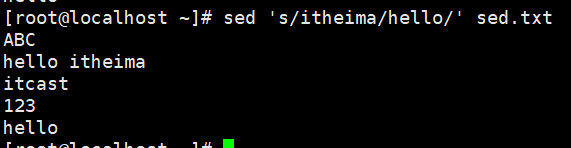
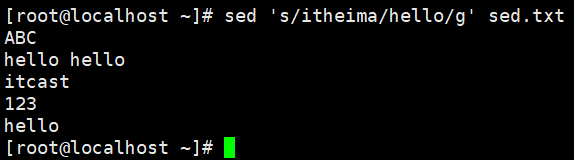
演示4:将文件中的itheima替换为hello
#将文件每行的第一个itheima替换为hello
#将所有的itheima都替换为hello,用 g
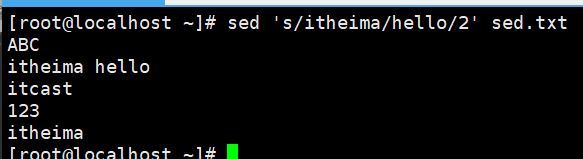
演示5:将每行中的第二个匹配替换
将每行第二个itheima替换为hello
演示6:替换后的内容写入文件
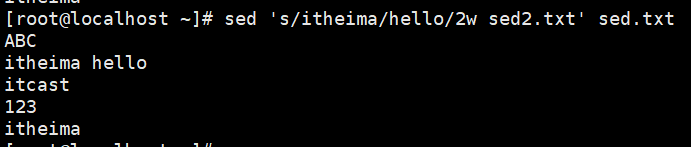
只打印你自己修改的行
-n获取匹配的行,p与n一块用,打印

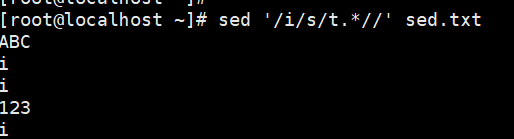
演示7:正则表达式匹配替换
匹配有i的行,替换匹配行 t 后的所有内容为空
只显示匹配的行

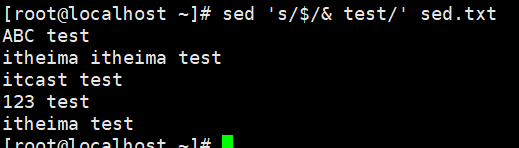
演示8:每行末尾拼接一个 test
s替换,$末尾,&拼接,最后 / 为终止符
演示9:每行行首添加注释
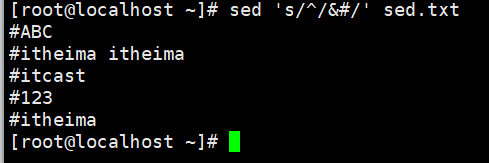
示例:查询文件或管道中的数据
需求1:查询含有 itcast 的行数据

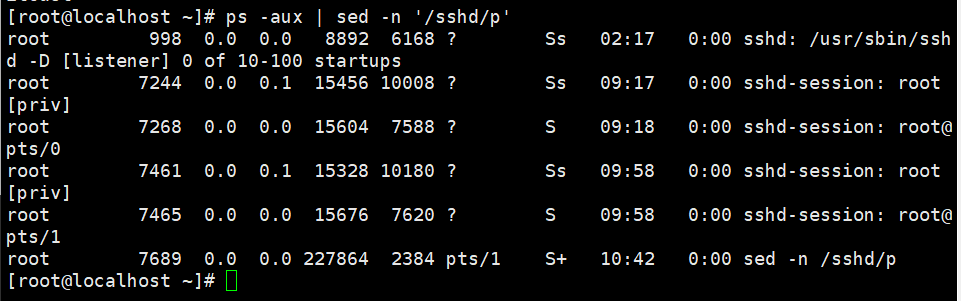
需求2:管道过滤查询
查询进程中含有sshd的进程信息命令(推荐grep)
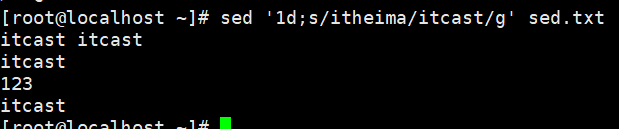
示例:多个sed命令执行
将文件第1行删除并把 itheima 替换为 itcast

sed高级用法:缓存区数据交换
模式空间与暂存空间介绍
- sed处理命令是一行一行处理的
- sed把文件读出来每一行存放的空间叫模式空间,会在该空间对读到的内容做处理
- sed的一个额外空间即暂存空间,刚开始只有一个空行
- sed可以用命令从模式空间往暂存空间放入内容或从暂存空间放入模式空间
关于缓存区sed程度命令
|----|------------------|
| 命令 | 含义 |
| h | 从模式空间内容复制到暂存(覆盖) |
| H | 模式-->暂存(追加) |
| g | 暂存 --> 模式(覆盖) |
| G | 暂存 --> 模式(追加) |
| x | 交换 |
示例:缓存空间数据交换
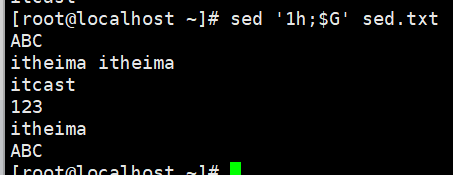
演示1:第1行粘贴到最后1行
将模式第一行复制到暂存(覆盖),将暂存复制到模式的最后一行(追加)
sed '1h;$G' sed.txt
#1h 模式第一行复制到暂存(覆盖)
$G 将暂存复制到模式的最后一行(追加)
演示2:第1行删除后粘贴到最后1行
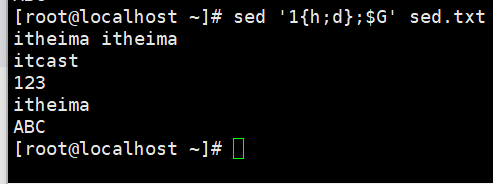
演示3:第1行数据复制粘贴替换其他行数据
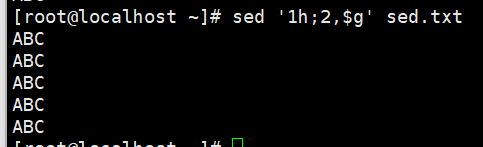
演示4:将前3行数据复制粘贴到最后1行
将前3行数据复制到暂存(追加),再将暂存所有复制到模式的最后一行(追加)
暂存空间默认有个空行
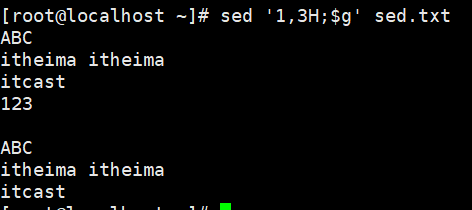
示例:给每一行添加空行
通过暂存空间本身默认存在一个空行
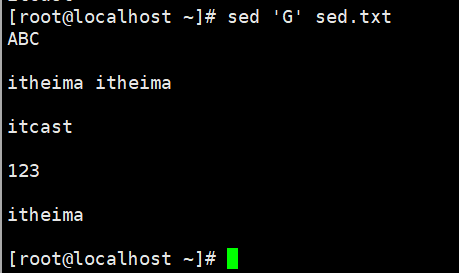
示例:删除所有的空行
awk
主要对数据分析并生成报告时,显得非常强大,简单来说就是把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理
语法
awk 'pattern{action}' {filenames}
pattern :在数据中查找的内容,就是匹配模式
|----|-------------|
| 参数 | 功能 |
| -F | 指定输入文件拆分分隔符 |
| -v | 赋值一个用户定义变量 |
awk内置变量
|----------|-------------------------------------------|
| 参数 | 功能 |
| FS | 设置输入域分隔符,等价于命令行 -F |
| NF | 浏览记录的域的个数,根据分隔符分割后的列数 |
| FILENAME | awk浏览的文件名 |
| NR | 已读的记录数,也是行号 |
| n | 0指整条记录,1 指当前行第一个域,2 指当前行的第二个域 |
| NF | NF number finally指最后一列信息,区分,NF统计的是每行列的个数 |
数据准备
cp /etc/passwd ./
示例:默认每行空格切割
"&" :拼接字符串

示例:打印含有匹配信息的行
搜索passwd文件中有root关键字的所有行
$0:这一行所有数据

示例:打印匹配行中第7列数据
搜索passwd文件有root关键字的所有行,以:拆分并打印输出第7列
-F :自定义分隔符

示例:打印文件每行属性信息
统计passwd:文件名,每行的行号,每行的列数,对应的完整行内容
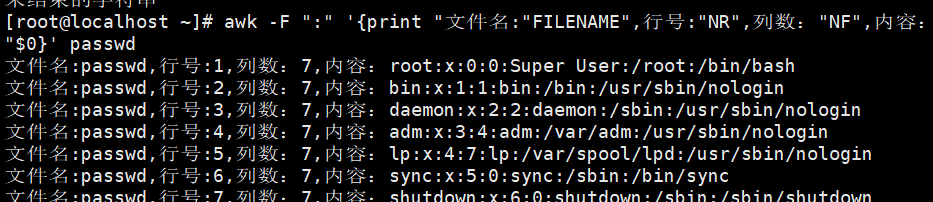


示例:打印第二行信息

示例:查找以a开头的资源

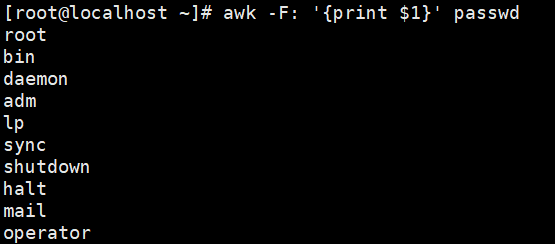
示例:打印第一列
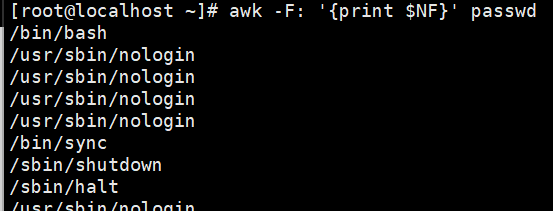
示例:打印最后一列
示例:打印倒数第二行
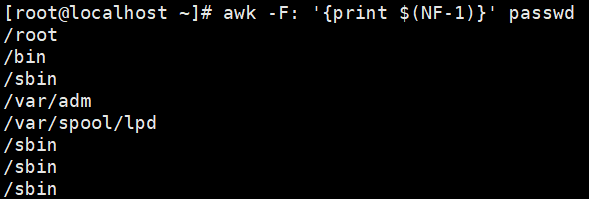
示例:打印10-20行的第一列
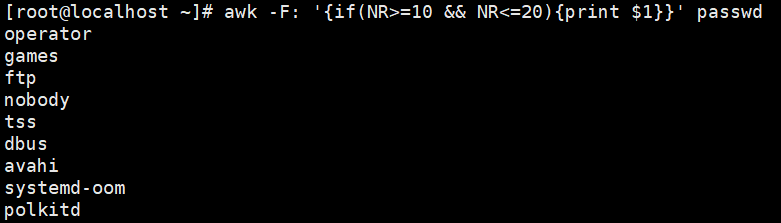
示例:多分隔符的使用

示例:添加开始和结束内容

示例:使用循环拼接分割后的字符串

示例:操作指定数字运算

示例:切割ip
默认分隔符为空格

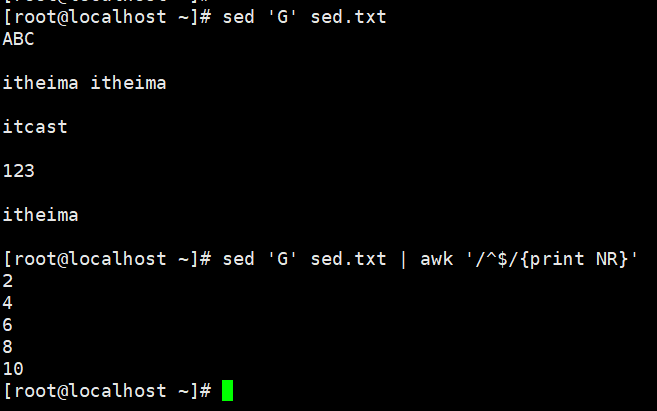
示例:显示空行行号
小结
grep,sed,awk,cut文本字符串操作四剑客的区别
grep:用于查找匹配的行
cut:截取数据,截取某个文件中的字符,按照列的分隔,不适合截取文件中有很多空格字符的字段
sed:增删改查数据,用于在文件中以行来截取数据进行增\删\改\查
awk:截取分析数据,可以在某个文件中是以竖列来截取分析数据,字段有很多空格也可以获取到
sort
对文件进行排序
语法
sort (options) 参数
|---------|-----------------|
| 选项 | 说明 |
| -n | number,按数值的大小排序 |
| -r | reverse,反转 |
| -t 分隔字符 | 默认为空格 |
| -k | 指定需要排序的列 |
| -o 输出文件 | 将排序后的结果存入指定文件 |
数据准备
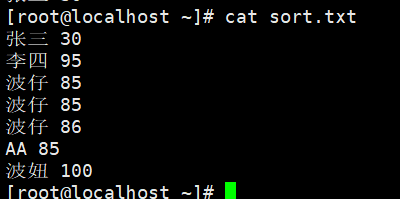
sort.txt 文本代码
示例1:数字升序
按照""空格分割后的第2列数字升序排序
sort -t " " -k2n,2 sort.txt
-t " " 代表使用空格分隔符拆分列
-k 2n,2 代表从第2列开始到第2列结束进行数字升序,仅对第2列排序
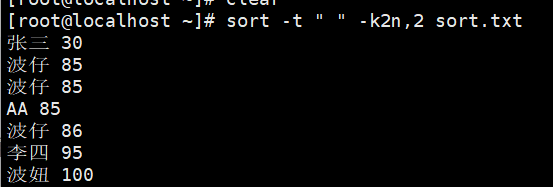
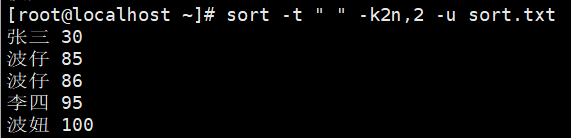
示例2:数字升序去重
-u 去重
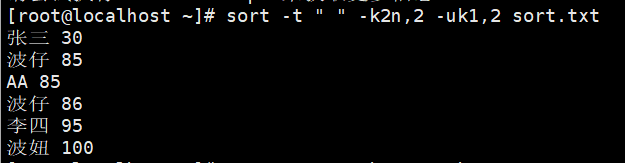
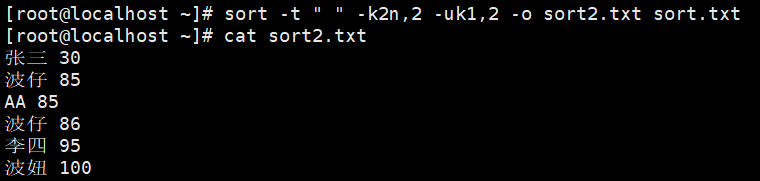
示例3:数字升序去重,结果保存到文件
示例4:数字降序去重
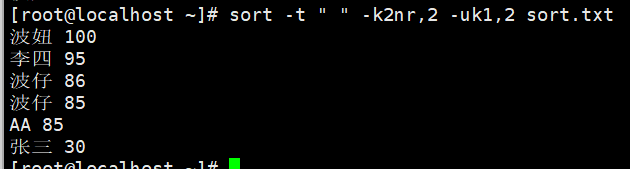
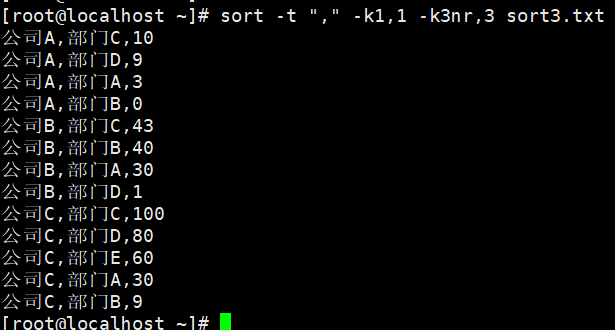
示例5:多列排序
数据准备
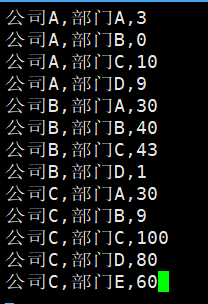
要求:以","分割先对第1列字符串升序,再对第3列数字降序