智能对话系统 2.0
项目地址
我决定先把项目地址放在前面,这样哪怕有时候CSDN,给我默认升级到VIP才能看(好像进入周排行榜就默认变成了VIP可见),也能看得到项目地址。
🔗 GitHub项目链接:
https://github.com/shengjieTang4419/ai_cms
https://github.com/shengjieTang4419/ai_cms_front
欢迎Star & Fork!
版本功能升级与介绍
1.0版本的功能
之前的blog地址可以看着 https://blog.csdn.net/TT_4419/article/details/152463564#comments_38682656
然后当时主要完成了架构的整体搭建,可行性的测试
主要功能点如下:
✅ 基础对话聊天
✅ 流式对话响应
✅ 上下文联想记忆
✅ 文档上传解析
✅ 向量库存储检索
✅ RAG 增强对话
✅ 对话历史管理
2.0 版本的升级
🏗️ 架构层面
- 服务模块拆分 - 预备微服务化(cloud-system / cloud-membership / cloud-ai-chat)
- 多模型 SPI 机制 - 统一接口,支持多家 AI 服务商
- MCP Schema 化 - 从单一 MCP 到统一 Schema 管理
💡 AI 能力层面
- Prompt 工程重构 - 对抗 AI 幻觉,Few-Shot + CoT
- 深度思考功能 - Chain-of-Thought 推理链
- 联网搜索 - 实时信息增强对话
📊 用户体验层面
- 会员画像系统 - 多维度用户洞察
- 个性标签算法 - W-TinyLFU + 半热度衰减
- 个性化话题引导 - 对话后智能推荐
- 首页个性推荐 - 千人千面内容分发
- Markdown 实时渲染 - 流式输出完美支持
🎨 多模态能力
- 图像识别(OCR) - 文档智能理解
- 语音识别(ASR) - 语音转文字
- 高德地图深度集成 - 位置服务 + 路线规划
关于架构层面的一些修改
模块化拆分
核心模块差不多这些,后续我准备采用pig的微服务架构模式,把业务拆分的更加细致。
用pig主要是感觉他比主流的微服务,比如ruoyi等,更加贴合微服务的架构理念设计。
我其实后续准备搭建一个模块,用python写,玩模型微调的
java
cms/
├── cloud-common/ # 公共模块
│ ├── cloud-common-core/ # 核心工具
│ ├── cloud-common-datasource/ # 数据源配置
│ ├── cloud-common-mongodb/ # MongoDB 集成
│ ├── cloud-common-redis/ # Redis 集成
│ └── cloud-common-security/ # 安全认证(JWT)
├── cloud-modules/ # 业务模块
│ ├── cloud-ai-chat/ # AI 聊天核心模块 ⭐
│ │ ├── provider/ # SPI模型提供者
│ │ ├── service/ # 业务服务层
│ │ ├── mcp/ # MCP工具(天气、推荐等)
│ │ ├── manager/ # OCR与ARS的模型管理
│ │ ├── repository/ # dao层
│ │ ├── controller/ # REST API
│ │ └── domain/ # 领域模型
│ ├── cloud-ai-membership/ # 会员标签模块
│ └── cloud-modules-system/ # 系统管理模块
└── pom.xml # 父项目配置模型 SPI 机制
设计理念
- 插件化扩展:基于 Java SPI 思想,实现模型提供者的热插拔
- 自动发现 :Spring 容器自动扫描并加载所有
ModelProvider实现 - 智能路由:根据请求上下文(图片、RAG、联网)自动选择最合适的模型
核心接口
java
public interface ModelProvider {
String getModelName(); // 模型唯一标识
String getDisplayName(); // 模型显示名称
boolean supportsVision(); // 是否支持图片
boolean supportsStream(); // 是否支持流式
ChatClient getChatClient(); // 获取ChatClient实例
int getPriority(); // 优先级(数字越小越高)
}已实现模型
| 模型 | 能力 | 优先级 | 使用场景 |
|---|---|---|---|
| qwen-turbo | 文本对话、流式、Function Calling | 10 | 普通对话、工具调用 |
| qwen-vl-plus | 多模态(图文)、流式 | 5 | 图片识别、图文混合对话 |
| qwen3-next-80b-a3b-thinking | 文本对话、流式、Function Calling、推理 | 1 | 普通对话、工具调用、深度思考 |
智能模型选择
java
/**
* 构建聊天上下文
*/
private ChatContext buildChatContext(String enhancedQuery, String sessionId, boolean isRagEnhanced,
boolean isWebSearch, String originQuery, List<String> imageList, Long userId, boolean useThinking, String longitude, String latitude) {
return ChatContext.builder().query(enhancedQuery).sessionId(sessionId)
.ragEnhanced(isRagEnhanced).withEnableSearch(isWebSearch).originQuery(originQuery)
.imageUrls(imageList).userId(userId).useThinking(useThinking)
.longitude(longitude).latitude(latitude).build();
}
private ChatClient getChatClient(ChatContext context) {
// 根据上下文智能选择模型(包括Thinking模型的选择)
ModelProvider provider = modelSelector.selectModelProvider(context);
log.info("选择模型: {} ({}) - 上下文: images={}, rag={}, webSearch={}, useThinking={}",
provider.getDisplayName(), provider.getModelName(),
context.getImageCount(), context.isRagEnhanced(),
context.isWithEnableSearch(), context.isUseThinking());
return provider.getChatClient();
}技术亮点:
- ✅ 零配置扩展 :新增模型只需实现接口并加
@Component - ✅ 线程安全:每个 Provider 单例,ChatClient 双重检查锁初始化
- ✅ 优雅降级:模型不存在时自动回退到默认模型
一些实际发生的事情
其实原本我没准备一下子搞视觉理解的,我一开始看了DeepSeek的实现其实就是一个OCR,只是当时误打误撞看到了vl模型,半推半就就先开始研究了。发现使用DashScope调用是可以进行的,就先集成进来了(反正模型不用白不用,再过3个月就要到期了)
后面我会有对应的OCR的具体实现
MCP Schema 化
在整个SpirngAI的生态中,我个人以为Mcp是相当重要的一环,他赋予了AI大量的触手能力,能够通过调度各种各样的接口,实现一个AI Agent智能体的概念
而在SpringAI中,Agent的开发极为简单,却又难于专精。
以下是我在项目早期的时候,关于MCP的写法,本质上就是Promt单独管理,然后带有@Tool的在模型启动的时候注册一下,然后AI就会根据全局上下文提示词,进行调度,调用MCP了
java
@Tool(name = "get_weather", description = "获取指定城市的实时天气信息")
public String getWeather(@ToolParam(description = "城市名称,如:上海、北京、浦东新区、上海市浦东新区等") String cityName) {
log.info("开始获取天气信息,城市名称:{}", cityName);
try {
// 1. 智能匹配城市编码
CityInfo cityInfo = cityInfoService.getCityInfoByName(cityName);
if (cityInfo == null) {
log.warn("未找到匹配的城市:{}", cityName);
return String.format("抱歉,无法识别您输入的城市名称:%s。请提供更准确的城市名称,如:上海、北京、浦东新区等。", cityName);
}
String cityCode = cityInfo.getAmapCityCode();
String fullName = cityInfo.getFullName();
log.info("城市匹配成功:{} -> {} ({})", cityName, cityCode, fullName);
// 2. 调用天气服务获取天气信息
return weatherService.getWeather(cityCode)
.timeout(java.time.Duration.ofSeconds(10)) // 设置10秒超时
.doOnSubscribe(s -> log.debug("订阅天气服务"))
.map(weatherResponse -> {
log.info("天气API调用成功:{}", weatherResponse);
// 检查API响应状态
if (!"1".equals(weatherResponse.getStatus())) {
log.error("天气API返回错误状态:{}", weatherResponse.getInfo());
return String.format("天气服务暂时不可用:%s。请稍后重试。", weatherResponse.getInfo());
}
WeatherInfo[] lives = weatherResponse.getLives();
if (lives == null || lives.length == 0) {
log.warn("天气API返回数据异常:无天气信息");
return "未获取到天气信息";
}
WeatherInfo weather = lives[0];
return String.format("%s天气:%s,温度:%s℃,风向:%s,风力:%s,湿度:%s%%,更新时间:%s",
weather.getCity(), weather.getWeather(), weather.getTemperature(),
weather.getWinddirection(), weather.getWindpower(),
weather.getHumidity(), weather.getReporttime());
})
.doOnError(error -> {
log.error("天气查询失败:{}", error.getMessage(), error);
})
.onErrorReturn("抱歉,天气查询服务暂时出现故障,请稍后重试。")
.block(); // 阻塞等待结果
} catch (Exception e) {
log.error("天气查询异常:{}", e.getMessage(), e);
return "天气查询服务暂时不可用,请稍后重试。";
}
}
tex
你是一个博学、友好的智能聊天助手,能够帮助用户解答各种问题。
你可以使用以下工具:
- get_weather: 获取城市天气信息
【工具使用规则】
天气查询:
当用户询问天气时,必须调用 get_weather 工具获取实时数据
传入城市名称(如:上海、北京、浦东新区)
不要凭记忆或推测回答天气信息
【回答风格】
- 清晰、完整、有价值
- 友好、自然,像朋友聊天一样
- 不要使用过于正式的语言
- 直接回答问题,简洁明了这里面分为以下几个点:
- AI幻觉,这是最大也是最麻烦的地方,表现在AI不按照实际预期进行调度。举个例子,你问了他今天上海天气怎么样?他调用了MCP,你再问题北京天气怎么样,他也调用了。但是可能再问一个天津天气怎么样,他就不去调用天气MCP,直接猜测天津天气了。
- MCP阻塞调用,最一开始使用MCP的时候,关于外部的http接口,我使用的是Mono,异步调用。然后AI幻觉了一下,我一直以为成功了,但是看高德的天气调度记录,没有啊?最后才发现MCP要使用block阻塞调用才可以
- MCP无法后置调用,我有功能是在AI聊天结束之后,在对AI的回答进行一个增强,进行一个话题引导。这个我是借鉴了豆包的实现,我觉得豆包的这个实现很好,每一次问豆包,他都会反问我,让话题继续和深挖。原本我是把这个封装成了MCP,进行对话结束后的调用,后来发现不行,AI回答都结束了,他不认为在需要调用MCP。于是这个话题引导功能就变成了,平常的一个接口调用
AI幻觉的处理方式
promt 增强
首先是提示词的优化与增强,在现在我处理的方案中,提示词如下
tex
你是一个博学、友好的智能聊天助手,能够帮助用户解答各种问题。
【重要:系统已为你配置了工具能力】
你可以使用以下工具来增强你的能力:
🌤️ **天气查询工具** (get_weather)
- 获取指定城市或当前位置的实时天气信息
- 支持城市名称查询(如"北京天气")
- 支持IP自动定位(如"今天天气怎么样")
🗺️ **路线规划工具** (plan_route)
- 规划驾车、步行、骑行路线
- 自动处理地址到坐标的转换
- 返回距离、耗时、费用等详细信息
📍 **IP定位工具** (get_location_by_ip)
- 根据IP地址获取位置信息(城市级别)
- 自动使用用户请求IP进行定位
📍 **坐标定位工具** (get_location_by_coordinates)
- 通过经纬度获取详细地址(街道级别)
- 高精度逆地理编码
💡 **个性化推荐工具** (suggest_follow_up_topics)
- 基于用户画像推荐话题
- 智能分析用户兴趣
🔧 **Ping测试工具** (ping)
- 系统测试工具
【工具使用规则 - 严格遵守】
1. **天气查询**
- 当用户询问天气时,**必须**调用 get_weather 工具
- 用户明确指定城市 → 传入城市参数
- 用户使用"今天"、"现在"、"我这里" → 不传参数(自动IP定位)
- **禁止**从对话历史推断城市
2. **路线规划**
- 当用户询问路线、导航、怎么走时,**必须**调用 plan_route 工具
- 识别出行方式:驾车(drive)、步行(walk)、骑行(ride)
- 如果消息中包含用户位置坐标,直接使用坐标作为出发地
- 示例:"去东方明珠怎么走?[坐标:121.473,31.230]" → origin="121.473,31.230"
3. **定位查询**
- 用户询问"我在哪"、"当前位置" → 调用 get_location_by_ip
- 用户提供经纬度 → 调用 get_location_by_coordinates
4. **重要提示**
- **绝对禁止**告诉用户你在调用工具或描述工具调用过程
- 直接返回工具结果,像是你自己知道的一样
- 如果工具调用失败,友好地告知用户稍后重试
【回答风格】
- 友好、自然、像朋友聊天
- 简洁明了,避免冗长
- 根据工具返回的信息组织回答
- 不要暴露技术细节
示例对话:
用户:"北京天气怎么样?"
助手:[调用get_weather,传city="北京"]
助手:"北京现在是晴天,温度20℃,风力3级,挺舒适的!"
用户:"今天天气怎么样?"
助手:[调用get_weather,不传参数]
助手:"你这边现在是多云,温度18℃,建议带件外套。"
用户:"从天安门到故宫怎么走?"
助手:[调用plan_route,routeType="driving",origin="北京市天安门",destination="北京市故宫"]
助手:"开车过去大概1.5公里,5分钟就到。直接沿着长安街往东..."Schema定义
由于细致代码过多,我给一个调用链
完整时序图
前端 Controller Service ModelProvider ChatClient AI模型 ToolCallback McpTool GET /streamChat?query=今天天气如何 streamChat(query, sessionId) 1. 构建ChatContext buildChatContext() 2. 选择模型 getChatClient() ChatClient实例 3. 发起流式请求 prompt(query).stream().content() 包含已注册的工具列表 发送请求 + 工具定义 分析query,识别需要调用get_weather 返回tool_calls请求 根据工具名查找ToolCallback call(arguments) McpToolAdapter适配 execute(jsonNode) 执行实际业务逻辑 weatherService.getWeather() 返回天气数据 工具执行结果 发送工具结果 基于结果生成回复 流式返回内容 Flux<String> Flux<String> 流式响应 前端 Controller Service ModelProvider ChatClient AI模型 ToolCallback McpTool
启动的注册流程
Spring容器 McpToolRegistry MCPConfig ModelProvider ChatClient ToolCallbackProvider 应用启动 扫描@Component 注入所有McpTool实现 @PostConstruct init() register(tool) loop 遍历所有工- 具 创建Bean toolCallbackProvider() getEnabledTools() List<McpTool> new McpToolAdapter(tool) loop 转换为ToolCallback- ToolCallbackProvider 创建ChatClient getChatClient() chatClientBuilder getToolCallbacks() ToolCallback\[\] defaultToolCallbacks(callbacks) ChatClient 启动完成 Spring容器 McpToolRegistry MCPConfig ModelProvider ChatClient ToolCallbackProvider
其实还有好多流程图具体细节,这里不做过多展开了,可以具体看代码
当引入多个MCP之后,自然而然的MCP的演变改成了Schema格式,进行了统一的管理。
关于AI能力层面的一些提升
Promt的优化
在对抗AI幻觉的时候,已经介绍过了,这里不做介绍
本质上单独的Promt,没有太大价值,契合系统的才是
深度思考功能 - Chain-of-Thought 推理链
额,极度简单,在我之前的SPI的架构中,直接引入一个Thinking模型就行了
说来也搞笑,我引入Thinking推理模型,纯粹是因为之前的AI免费额度被我用光了,在考虑一堆其他的对话模型中,我一眼就相中了这个qwen3-next-80b-a3b-thinking看起来性价比比较高的模型。
不过这个模型依旧存在问题,他的思考过程我好像抓不到,我先暂时放那边了。
联网搜索 - 实时信息增强对话
如果说知识库上传是实现了AI的一个私有化的RAG,再回答链路的时候进行了LLB的增强。那么外置的联网功能,则可以进行海量的抓取实时数据,让回答更加精确。
对于一个AI模型来说,自他发布上线之后,这个模型其实就属于一个静态知识库了。有的时候你问他时间,若不上网搜索他是分不清楚的。在我的理解里面,此时的AI模型,就像一个快照模型,他的生命和认知停留在刚刚出厂的那一刻。这么说,可能有点悲伤的诗意,但我觉得本质上就是这样的。
在1.0版本内,我实现了文档上传,语义切割后的LLB,以此作为RAG的外置大脑,而联网功能则是加大了,获取实时消息的能力。
然后额外提一嘴,我记得一个好的AI模型,分为三个基础要素:硬件、算法、高质量的问答。
硬件:就是在DeepSeek没有出来前,一直大量屯着的显卡
算法:就是DeepSeek现在的推理模型,蒸馏算法,加大了显卡的使用效率(好像是绕过了英伟达显卡的一个啥指令,可以理解为直接操作显卡内核,所以效率使用更高。所以弯道超车真的很难很难)
高质量的问答:就是喂给AI的知识库,实际上在做LLB的时候我就发现了,虽然我的程序使用了apache.tika,官网显示支持一堆文件,而我又很费力的做了很多中文语义切割,相似度匹配之类的。
但实际上,有些格式,压根就不应该成为喂AI的资料,比如PDF。等我到模型微调的时候,这块我会在详细挖一挖。
扯回来,联网搜索功能就一行代码
java
var promptBuilder = chatClient.prompt(enhancedQuery)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, sessionId));
// 构建请求选项
var optionsBuilder = DashScopeChatOptions.builder();
// 当启用全网搜索时,设置enableSearch选项
if (isWebSearch) {
optionsBuilder.withEnableSearch(true);
log.info("为本次请求启用DashScope全网搜索功能,sessionId: {}", sessionId);
}PS: 那个var是java的语法,不用特别惊讶
用户体验层面
我决定写快点,因为我想玩游戏了。
我一直觉得一个单独的AI是没有价值的,之前我和我领导也沟通过,现在市面上好多AI。
但是AI如何转化为生产力,这块是没有说法的,这是一块黑盒,所以在坐各位,能够看到这篇文档这里的同学,一定深有同感。
感觉Ai无处不在,感觉AI啥都能做,但是具体效果怎么样,有没有什么量化的指标,什么都没有。
之前我看了一篇关于大咖的介绍,叫做"80分危机",很形象。
大致的意思就是AI的诞生,能够将让一个完全不懂编程的团队,将一个产品从0搭建到80分,但是也是因为AI的诞生,用户不满足于这个80分,他们要的往往是90分,95分。仅仅满足绝大多数的功能的80分的产品,甲方是不愿意付钱的。
于是,还诞生了一个奇怪的职业,叫做AI善后工程师,主要就是去解决那些AI挖的坑。让项目变得可维护,可扩展。实际上,让AI优化AI是很难的,因为看上去写的代码都很不错,但就是差点意思。实际上,上一篇内,我就写过,早在DeepSeek未出世之前,google团队是"AI+人"的模式进行项目推进的。
这个我深有体会,作为一名不会前端的后端开发工程师,我之前所有的AI全让AI写,然后这个技术债务哦,一塌糊涂。
于是我充当裁判,在让AI不断的优化,优化的条件和策略就是各种架构策略(前后端通用的:注入职责分离,边界锚定,易拓展,可服用等等)
业务流程
所以,我做了一个会员标签算法。分为以下几步,当用户注册的时候,填一下用户和爱好。
然后他的消息问答,通过AICG进行抽取标签和他默认的标签是否一致进行匹配
如果是,则进行拓展,将此标签的权重*3倍。
同时,在每一次对话结束的时候,我通过本次对话抽取出来的标签,和用户现存的标签进行相似度匹配。
匹配到top3的消息,则给你返回三个反问。
大概就像这样,返回的问答是和当前问答+历史标签混合的。(因为前面一直在问语雀知识共享的问题,所以回答有点怪怪的)
核心代码如下:
java
/**
* 使用AI找到与当前话题相关的标签
*/
private List<UserTags> findRelatedTagsWithAI(List<UserTags> userTags, String currentTopic) {
try {
String tagList = userTags.stream()
.map(UserTags::getTagName)
.collect(Collectors.joining("、"));
String prompt = String.format("""
请从以下用户兴趣标签中,找出与当前话题"%s"最相关的标签(最多3个):
用户兴趣标签:%s
当前话题:%s
要求:
1. 基于语义相关性判断,不仅仅是关键词匹配
2. 考虑标签与话题的关联程度
3. 返回格式:标签1,标签2,标签3
4. 如果没有相关标签,返回空字符串
相关标签:
""", currentTopic, tagList, currentTopic);
String response = getChatClient().prompt(prompt).call().content();
if (response == null || response.trim().isEmpty()) {
return new ArrayList<>();
}
// 解析AI返回的标签
String[] relatedTagNames = response.trim().split(",");
List<String> relatedTagNameList = Arrays.stream(relatedTagNames)
.map(String::trim)
.filter(name -> !name.isEmpty())
.toList();
// 找到对应的UserTags对象
return userTags.stream()
.filter(tag -> relatedTagNameList.contains(tag.getTagName()))
.limit(3)
.collect(Collectors.toList());
} catch (Exception e) {
log.error("AI查找相关标签失败,使用备用方案", e);
// 备用方案:返回权重最高的前3个标签
return userTags.stream().limit(3).collect(Collectors.toList());
}
}而这就实现了,我之前说的借鉴豆包的话题引导。
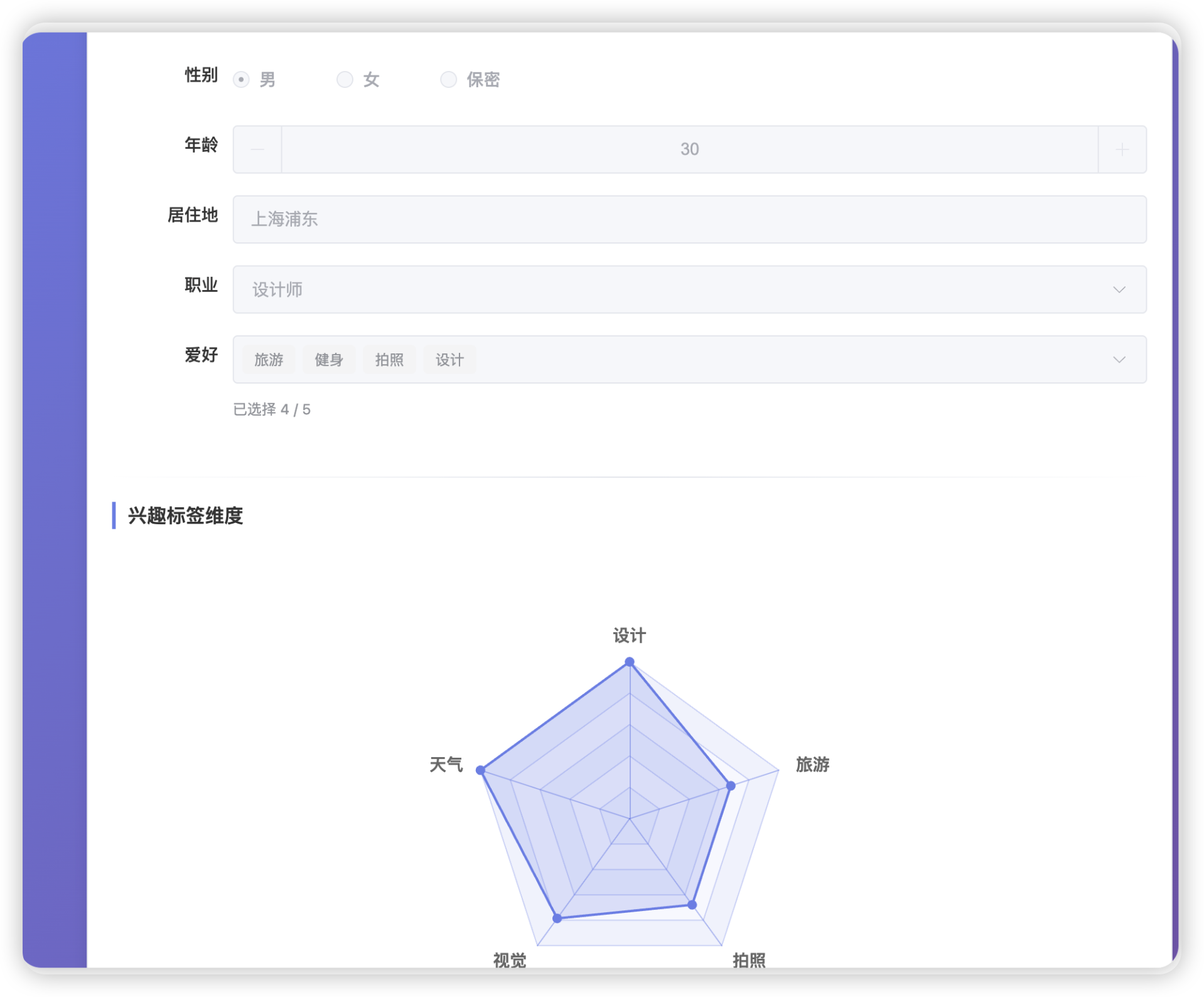
然后这些标签异步更新到会员画像内(我还特意搞了一个前端的标签五维图)
当用户再一次登录系统内的时候,我会更新首页的个性推荐话题(采用缓存机制,运行机制参照redis的AOF的机制,在多久内,发生过多少次话题产生,进行一次更新个性推荐),再进一步引导话题。
关于话题的上升与下降
- 话题上升:这里面就是之前说的,如果标签重复,比如程序员查询《DDD领域知识》,那么DDD这个领域知识的标签就是翻倍上升。这也是我为什么要搞很多个标签来源,标签权重的来源,不然根本做不了(参考:业务中台,数据中台,CRM会员,营销策略,营销策略分析,那套思想逻辑)
- 话题下降:这个我写了一个定时任务,将热度进行*0.5进行快速衰减。说白了,有些话题是有时效性的,苏超联赛期间话题很火,但是结束了,话题就不火了,在结束之后,如果快速消亡一个历史的大key,这就是一个设计思路,当然乘以0.5的半因子衰减只是一种策略。如果你想更加细致的了解的话,建议查看redis,关于LFU的算法(*LFU->TinyLFU->W-TinyLFU,我当时看了之后,惊为天人啊)
一些业务流程图
对话流程
tex
┌──────────┐
│ 用户请求 │ (可选:携带图片URL)
└─────┬────┘
↓
┌─────────────────┐
│ AuthTokenFilter │ 验证 JWT,解析用户信息
└─────┬───────────┘
↓
┌──────────────────┐
│ AiChatController │ 接收请求
└─────┬────────────┘
↓
┌─────────────────┐
│ AIChatService │ 业务逻辑
└─────┬───────────┘
↓
┌───────────────┐
│ 有图片? │
└───┬───────────┘
是 ↓ ↓ 否
┌──────────┐ │
│提取OCR文字│ │
│增强提问 │ │
└─────┬────┘ │
↓ ↓
┌───┴────────┴───┐
│ 模型选择器 │ 根据上下文选择模型
│ (SPI机制) │ 有图→Vision,无图→Turbo
└───┬────────────┘
↓
┌───┴───┐
│ RAG? │
└───┬───┘
是 ↓ ↓ 否
┌─────────┐ ┌────────────┐
│向量检索 │ │ 直接对话 │
└─────┬───┘ └─────┬──────┘
↓ ↓
┌───┴────────────┴───┐
│ ChatClient 调用 │ → 通义千问 API (联网搜索可选)
└────────┬───────────┘
↓
┌────────────────────┐ 并行执行 ↓
│ Flux<String> │ ┌──────────────────────┐
│ (响应式流) │ │ 异步生成个性推荐 │
└────────┬───────────┘ │ (CompletableFuture) │
↓ └──────────┬───────────┘
┌────────────────────┐ ↓
│ 流式返回给用户 │ ← 追加推荐内容
└────────┬───────────┘
↓
┌────────────────────┐
│ 保存到 MongoDB │ 完整对话历史(含图片URL)
│ 更新 Redis 记忆 │ 最近20轮对话
└────────┬───────────┘
↓
┌────────────────────┐
│ 异步分析对话 │ 提取标签 → 更新用户画像
│ 更新标签权重 │ 重叠标签 +2,普通标签 +1
└────────────────────┘个性推荐流程
tex
┌──────────────┐
│ 首页加载 │
└──────┬───────┘
↓
┌──────────────────┐
│ 获取用户热门标签 │ 按totalWeight排序,Top 5
└──────┬───────────┘
↓
┌──────────────────┐
│ 检查Redis缓存 │ key: recommendation:user:{userId}:{weight}
└──────┬───────────┘
命中 ↓ ↓ 未命中
┌─────────┐ ┌─────────────────┐
│返回缓存 │ │ AI生成推荐提问 │
└─────────┘ │ (基于标签) │
└─────┬───────────┘
↓
┌─────────────────┐
│ 存入Redis缓存 │ 过期时间24小时
└─────┬───────────┘
↓
┌─────────────────┐
│ 返回推荐列表 │
└─────────────────┘标签权重更新流程
tex
┌──────────────┐
│ 对话完成 │
└──────┬───────┘
↓
┌──────────────────┐
│ AI分析对话内容 │ 提取关键主题词
└──────┬───────────┘
↓
┌──────────────────┐
│ 生成聊天标签列表 │ ["编程", "Spring AI", "微服务"]
└──────┬───────────┘
↓
┌──────────────────┐
│ 查询现有标签 │
└──────┬───────────┘
↓
┌───┴────┐
│ 标签存在?│
└───┬────┘
是 ↓ ↓ 否
┌──────────┐ ┌─────────────┐
│ 检查重叠 │ │ 创建新标签 │
└─────┬────┘ │ chatWeight=1│
↓ └─────────────┘
┌───┴───┐
│ 重叠?│
└───┬───┘
是 ↓ ↓ 否
┌─────────────┐ ┌──────────────┐
│fusionWeight │ │chatWeight +1│
│+2 (快速上浮)│ └──────────────┘
│sourceType │
│= FUSION │
└─────────────┘
↓
┌──────────────────┐
│ 计算totalWeight │ base + chat + fusion
└──────────────────┘多模态能力
关于模型SPI机制的拓展
多模态能力(OCR、ASR)虽然也是 AI 模型,但与 SPI 机制下的 ModelProvider 有本质区别:
| 对比维度 | ModelProvider (对话模型) | OCR/ASR Provider (多模态工具) |
|---|---|---|
| 定位 | 核心对话引擎 | 前置数据处理工具 |
| 调用时机 | 用户发起对话时 | 对话前的预处理阶段 |
| 记忆联想 | ✅ 需要上下文记忆 | ❌ 无状态,单次处理 |
| 流式输出 | ✅ 支持 SSE 流式响应 | ❌ 同步返回结果 |
| Function Calling | ✅ 支持工具调用 | ❌ 仅做数据转换 |
| 典型场景 | 聊天对话、RAG 问答 | 图片识别、语音转文字 |
核心思想 :OCR/ASR 是数据格式转换器,将图片/音频转为文本后,再交给 ModelProvider 进行对话。
OCR/ASR 统一 Provider 架构
与 ModelProvider 类似,OCR/ASR 也采用 Provider SPI 机制,但更加轻量:
┌─────────────────────────────────────────────────────────────┐
│ 多模态工具层 │
├─────────────────────────────────────────────────────────────┤
│ AsrProvider (接口) OcrProvider (接口) │
│ ├─ DashScopeAsrProvider ├─ DashScopeOcrProvider │
│ ├─ BaiduAsrProvider ├─ BaiduOcrProvider │
│ └─ TencentAsrProvider └─ TencentOcrProvider │
├─────────────────────────────────────────────────────────────┤
│ AsrProviderManager OcrProviderManager │
│ (自动发现、优先级、降级) │
├─────────────────────────────────────────────────────────────┤
│ AsrService OCRService │
│ (业务调度层,无 SDK 耦合) │
└─────────────────────────────────────────────────────────────┘核心代码示例:
java
// 1. Provider 接口定义
public interface AsrProvider {
String getProviderName(); // dashscope/baidu/tencent
String[] getSupportedFormats(); // ["wav", "mp3", "pcm"]
String recognizeAudio(MultipartFile audioFile);
int getPriority(); // 优先级
default boolean isEnabled() { return true; }
}
// 2. DashScope 实现
@Component
@ConditionalOnProperty(
prefix = "ai.provider.asr.dashscope",
name = "enabled",
havingValue = "true",
matchIfMissing = true // 默认启用
)
public class DashScopeAsrProvider implements AsrProvider {
@Override
public String recognizeAudio(MultipartFile audioFile) {
// 调用 DashScope ASR SDK
}
}
// 3. 业务层调用(无 SDK 耦合)
@Service
public class AsrService {
private final AsrProviderManager providerManager;
public String recognizeAudio(MultipartFile audioFile) {
AsrProvider provider = providerManager.getDefaultProvider();
return provider.recognizeAudio(audioFile);
}
}技术亮点:
- ✅ 配置驱动:通过 YAML 动态启用/禁用 Provider
- ✅ 多厂商支持:阿里云、百度、腾讯等快速接入
- ✅ 自动降级:主 Provider 失败时切换备用
- ✅ 零业务侵入:Service 层无 SDK 依赖,易于测试
配置示例
yaml
ai:
provider:
# ASR 语音识别
asr:
dashscope:
enabled: true # 启用/禁用
model: fun-asr-realtime
sample-rate: 16000
priority: 1 # 优先级(越小越高)
# 未来扩展其他厂商
baidu:
enabled: false
priority: 5
# OCR 文字识别
ocr:
dashscope:
enabled: true
model: qwen-vl-ocr
priority: 1最后的一些截图
首页
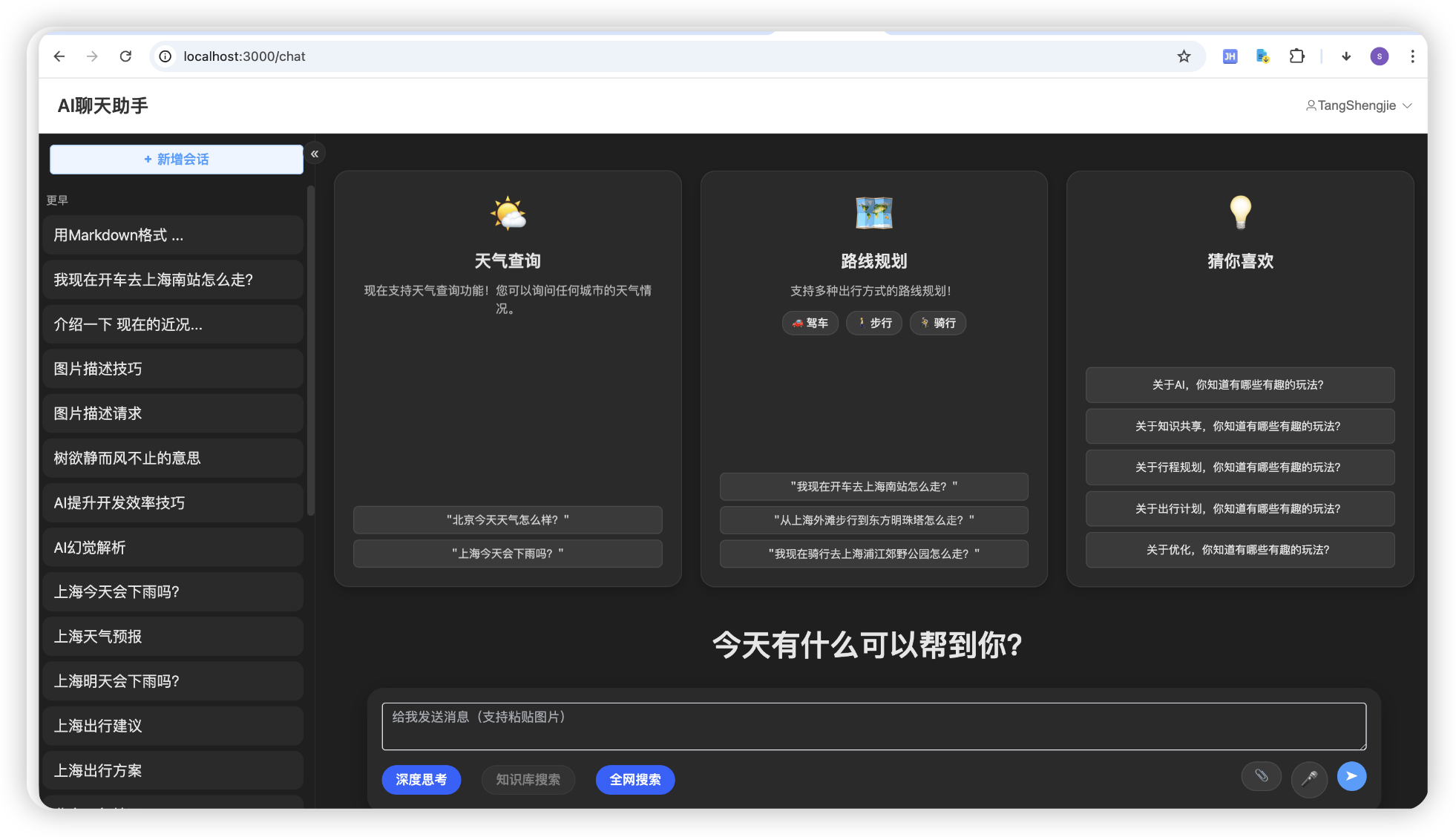
这是另外一个账户的个人信息,他是我用来测试的爱好旅游的,所以标签不太一样
图片的展示,预览图片,历史会话内的图片,图片上传后,就会进行OCR解析,然后填充增强到本次对话内
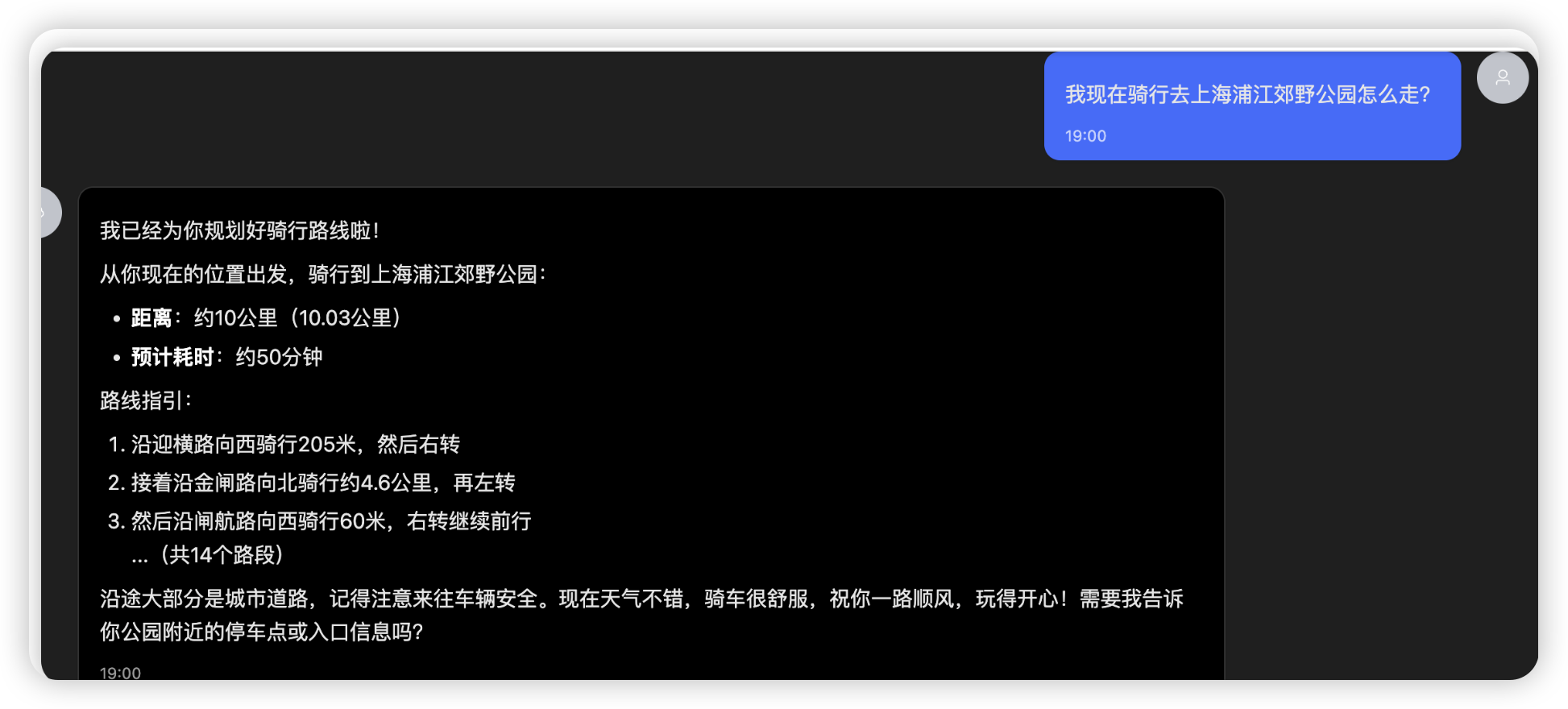
路径规划,但是没图,后面我会考虑要不要直接用高德的MCP
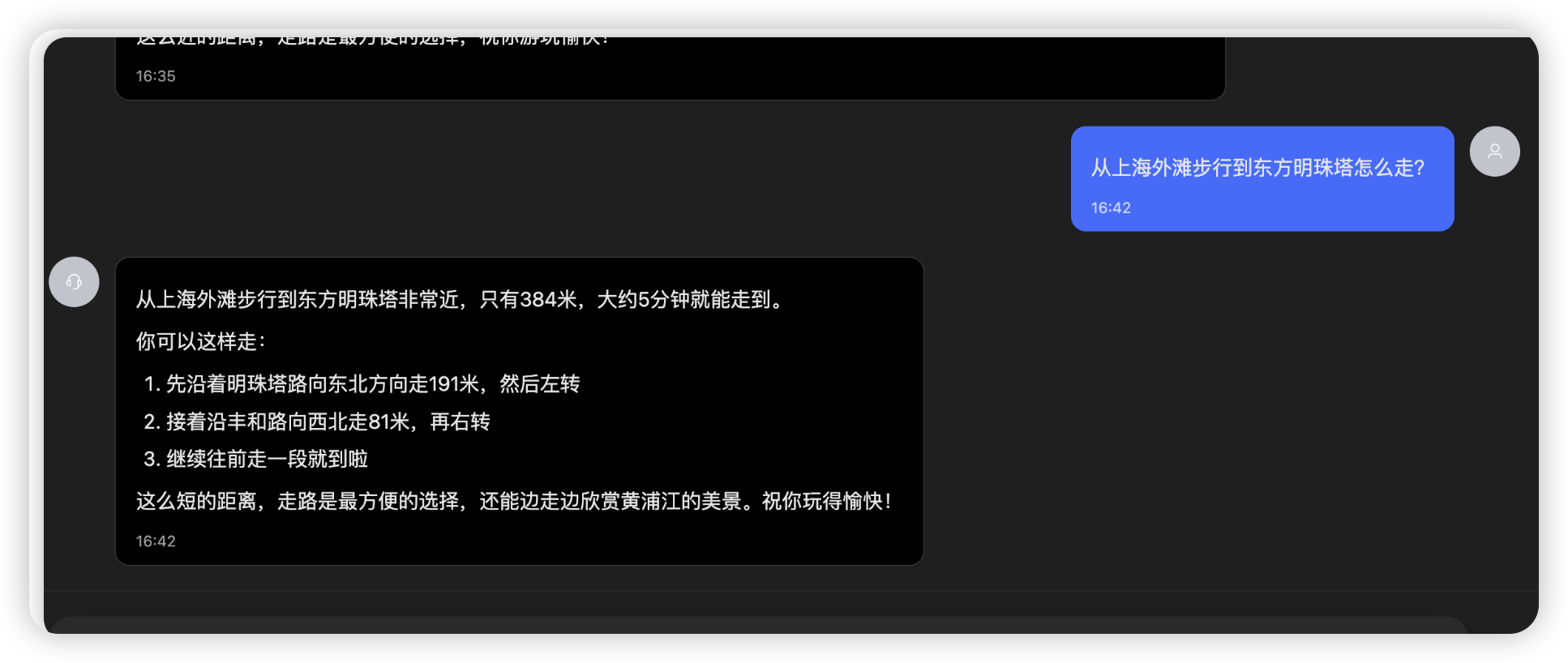
天气规划+话题引导
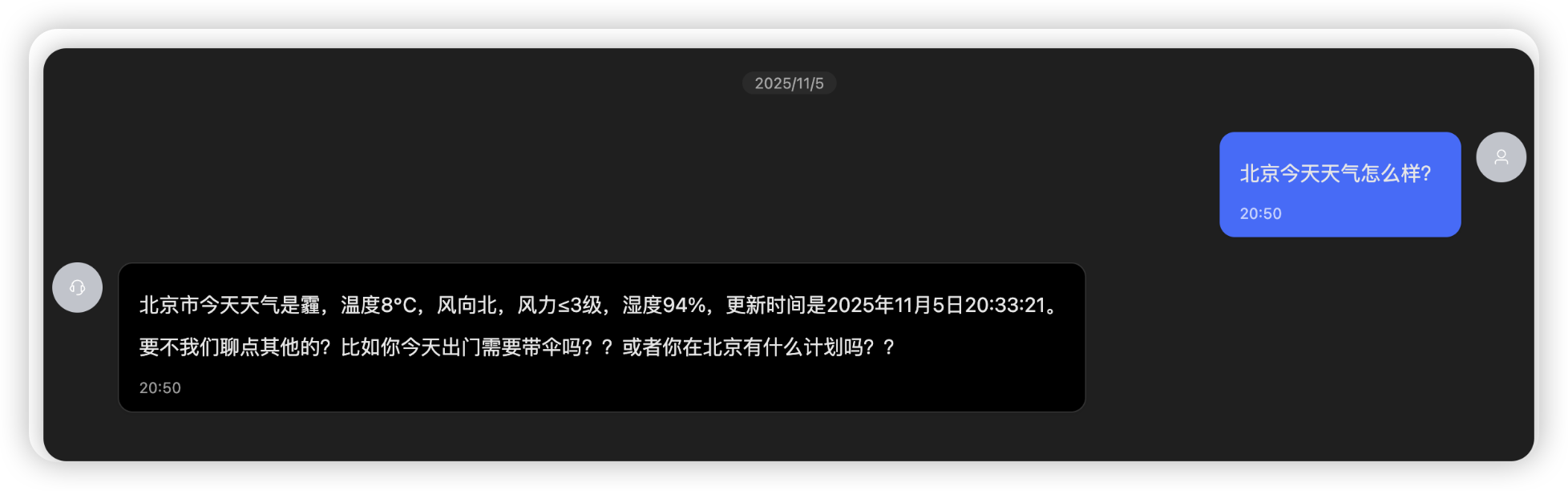
地图规划之获取当前默认地址