小模型微调过程记录
背景
在智能客服在做知识问答和增值服务时,需要根据用户语义判断用户意图,根据用户意图对走不同的分支。传统做法是Prompt+LLM,写提示词就可以完成意图的识别。也可以对模型进行微调,输入一批数据集,对小模型进行训练。现在模型更新迭代越来越快,能力越来越强。模型微调的成本比较高,效果不一定到位(对于没有微调经验的我来讲)
工具
ModelScope
国内模型和数据集开源平台,也提供了免费的云环境实例
LLaMA-Factory
LLaMA-Factory 是一个开源的大语言模型训练框架,专门用于简化和优化大语言模型的微调过程。
https://github.com/hiyouga/LLaMA-Factory
https://blog.llamafactory.net/posts/mca-quickstart/
Jan
Jan应用程序可以直接运行Llama.app的模型,在本机运行模型
制作数据集
数据集的格式和要求参考官方文档:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
本次调试的数据集是Alpaca 格式的指令监督微调数据集,主要有两个数据集文件,一个是身份的改变,另一个是意图识别的意图集。格式及本分样例如下:
json
[
{
"instruction": "请告诉我你的名字",
"input": "",
"output": "我的名字是 xxx-小助手,我的使命是为尽可能多的人提供知识与帮助,让更多人受益于人工智能技术。"
},
{
"instruction": "你好,你可以做什么",
"input": "",
"output": "我是 xxx-小助手,一个由 xxx开发团队 制作的 AI 助手,可以帮您回答问题、提供建议、进行聊天、翻译文字等等。"
}
...
]
json
[
{
"instruction": "导出本月的数据",
"input": "",
"output": "下载场景"
},
{
"instruction": "会员消费情况",
"input": "",
"output": "用户会员相关分析"
}
...
]实践过程
下载训练框架
打开魔塔免费的GPU实例,打开终端
bash
# 源码安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 下载依赖
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation下载模型
可以在魔塔中找到适合自己的模型,我这里使用的是Qwen3-4B的小模型
bash
# 回到项目目录
cd /mnt/workspace/
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen3-4B.git配置模型训练文件
bash
# LLaMA-Factory 目录下
cd examples/train_qlora/
cp llama3_lora_sft_awq.yaml qwen3_lora_sft.yaml编辑配置文件
yaml
### model
### 模型目录
model_name_or_path: /mnt/workspace/model/Qwen3-4B
### method
### 监督微调阶段
stage: sft
### 启用训练模型
do_train: true
### 使用LoRA(Low-Rank Adaptation)进行参数高效微调
finetuning_type: lora
lora_target: all
### dataset 数据集配置下章节说明
dataset: identity,intent
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
### 训练模型输出
output_dir: saves/qwen3-4b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 2.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
# ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500配置数据集文件
bash
# LLaMA-Factory 目录下
cd data
# 备份
cp dataset.json dataset_backup.josn将制作数据章节的数据放在data目录下,dataset.json是数据集配置文件,
bash
{
"identity": {
"file_name": "identity.json"
},
"intent": {
"file_name": "intent.json"
}
}模型训练
bash
llamafactory-cli train examples/train_qlora/qwen3_lora_sft.yaml漫长的等待,中间如果执行有错误,可以移步到chatgpt和claude...
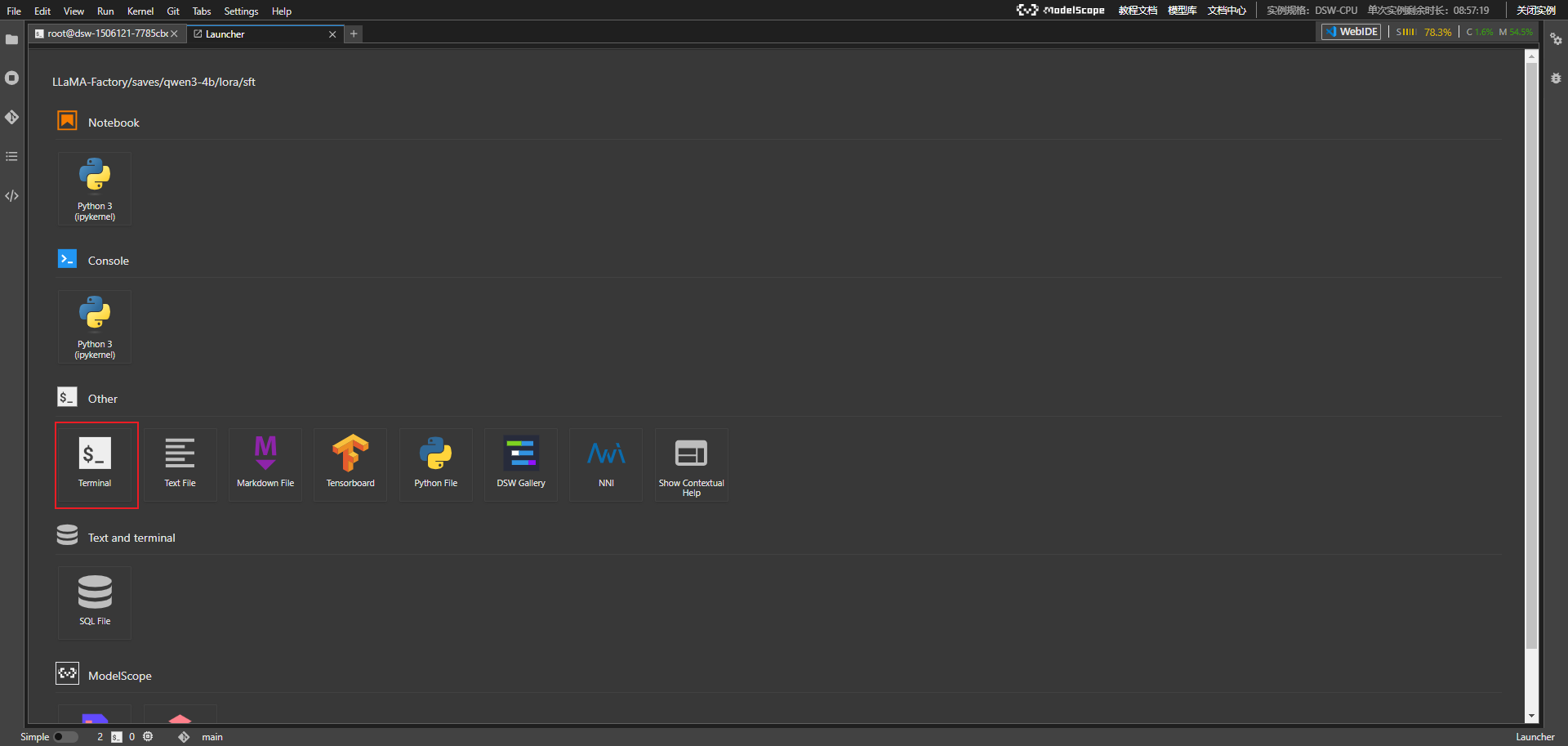
测试推理
bash
llamafactory-cli chat \
--model_name_or_path /mnt/workspace/model/Qwen3-4B \
--adapter_name_or_path saves/qwen3-4b/lora/sft \
--template qwen3然后可以开始和训练后的模型进行对话测试
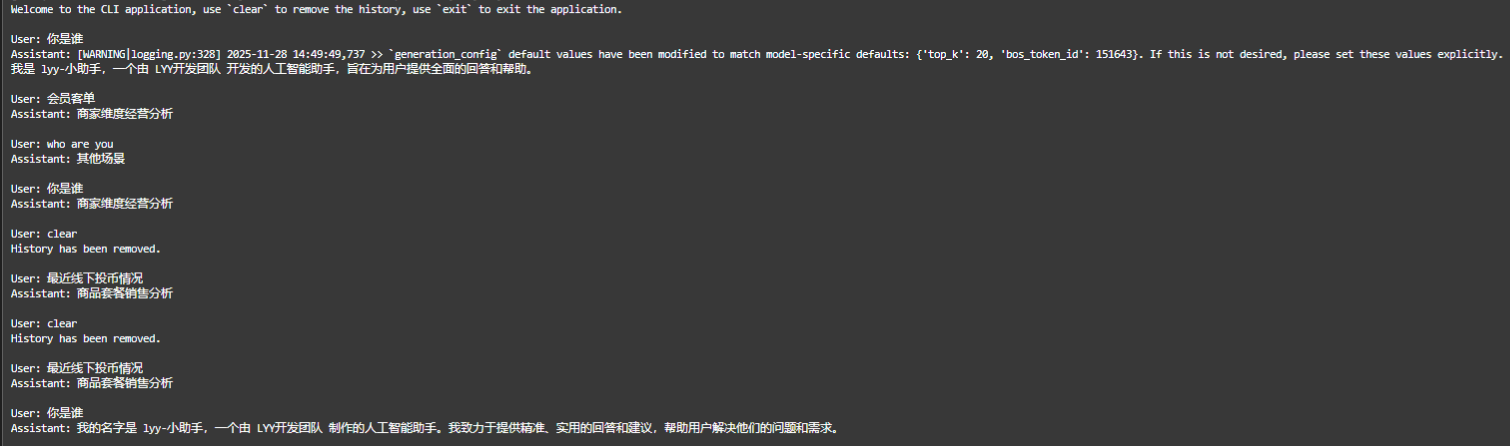
效果感觉呆呆的,一定一定是我没有用好...
LoRA模型合并导出
把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件。合并后的模型可以自由地像使用原始的模型一样应用到其他下游环节,当然也可以递归地继续用于训练。
bash
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /mnt/workspace/model/Qwen3-4B \
--adapter_name_or_path saves/qwen3-4b/lora/sft \
--template qwen3 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False导出GGUF
GGUF 是 lllama.cpp 设计的大模型存储格式,可以对模型进行高效的压缩,减少模型的大小与内存占用,从而提升模型的推理速度和效率。
bash
cd /mnt/workspace/
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp/gguf-py
pip install --editable .
cd ..
python convert_hf_to_gguf.py /mnt/workspace/LLaMA-Factory/megred-model-path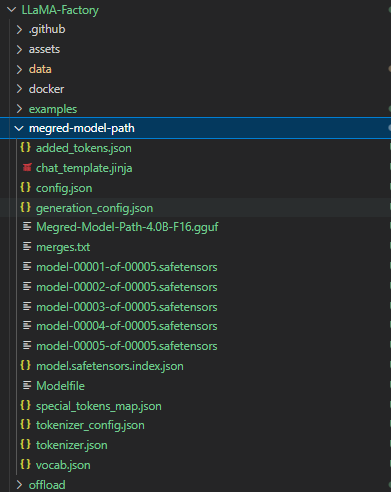
可以把Megred-Model-Path-4.0B-F16.gguf文件导出,在**Ollama**中进行部署
Jan加载模型
点击开始,你就可以在本机电脑运行你微调的模型。然后然后然后电脑就卡机了...die
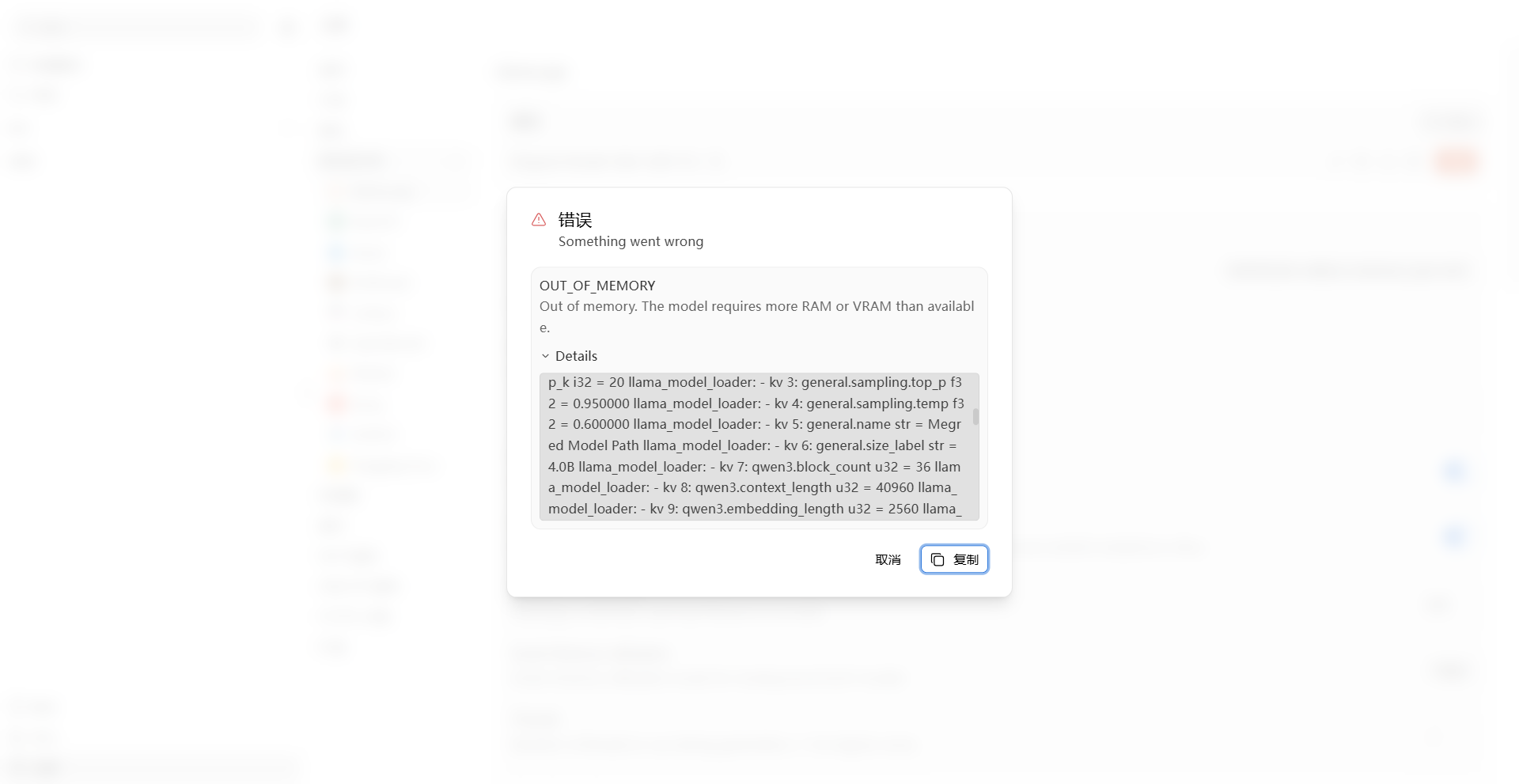
整体实践下来,能够发现模型微调确实在某些领域中有不少的提升,运维实践的成本都会比较大,对于真正的应用起来门槛还是比较高的...