Flink CDC系列之:Kafka JSON 序列化器JsonSerializationSchema
这是一个 JSON 序列化器,负责将 Flink CDC 事件转换为 JSON 格式的数据。
类概述
java
public class JsonSerializationSchema implements SerializationSchema<Event>这个类实现了 Flink 的 SerializationSchema 接口,专门用于将 CDC 事件序列化为 JSON 格式的字节数组。
核心属性
java
private static final long serialVersionUID = 1L;
/**
* A map of {@link TableId} and its {@link SerializationSchema} to serialize Debezium JSON data.
*/
private final Map<TableId, TableSchemaInfo> jsonSerializers; // 表结构缓存
// JSON 格式配置参数
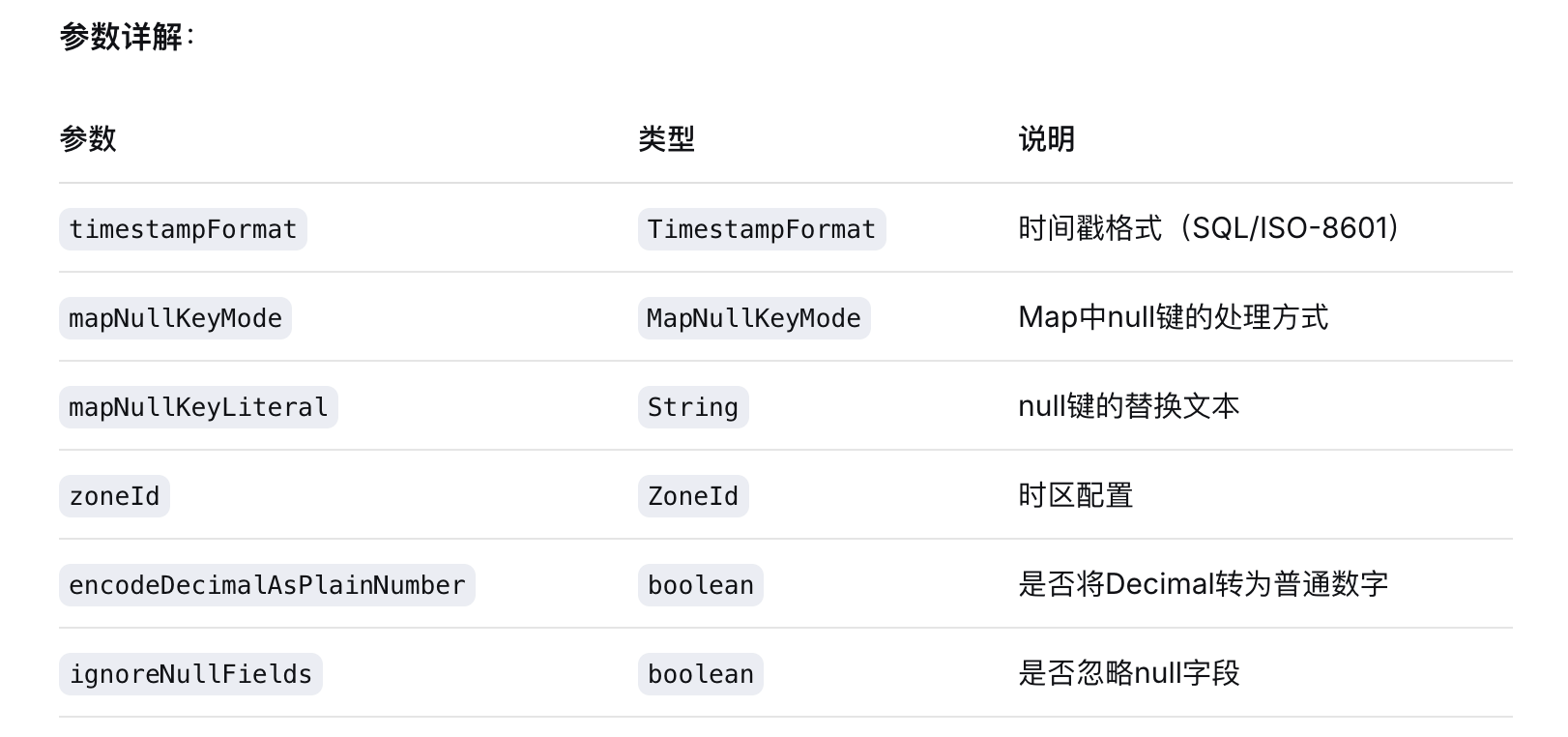
private final TimestampFormat timestampFormat; // 时间戳格式
private final JsonFormatOptions.MapNullKeyMode mapNullKeyMode; // Map中null键处理模式
private final String mapNullKeyLiteral; // null键替换文本
private final boolean encodeDecimalAsPlainNumber; // Decimal是否编码为普通数字
private final boolean ignoreNullFields; // 是否忽略null字段
private final ZoneId zoneId; // 时区配置
private InitializationContext context; // Flink 初始化上下文构造函数
java
public JsonSerializationSchema(
TimestampFormat timestampFormat,
JsonFormatOptions.MapNullKeyMode mapNullKeyMode,
String mapNullKeyLiteral,
ZoneId zoneId,
boolean encodeDecimalAsPlainNumber,
boolean ignoreNullFields) {
this.timestampFormat = timestampFormat;
this.mapNullKeyMode = mapNullKeyMode;
this.mapNullKeyLiteral = mapNullKeyLiteral;
this.encodeDecimalAsPlainNumber = encodeDecimalAsPlainNumber;
this.zoneId = zoneId;
jsonSerializers = new HashMap<>();
this.ignoreNullFields = ignoreNullFields;
}
核心方法详解
open() - 初始化方法
java
@Override
public void open(InitializationContext context) {
this.context = context;
}作用:Flink 在启动序列化器时调用,用于传递运行时上下文。
serialize() - 主序列化方法
java
@Override
public byte[] serialize(Event event) {
if (event instanceof SchemaChangeEvent) {
handleSchemaChangeEvent((SchemaChangeEvent) event); // 处理Schema变更
return null;
}
DataChangeEvent dataChangeEvent = (DataChangeEvent) event;
return serializeDataChangeEvent(dataChangeEvent); // 处理数据变更
}Schema 变更事件处理
java
private void handleSchemaChangeEvent(SchemaChangeEvent schemaChangeEvent) {
Schema schema;
if (event instanceof CreateTableEvent) {
// 新建表:获取完整表结构
CreateTableEvent createTableEvent = (CreateTableEvent) event;
schema = createTableEvent.getSchema();
} else {
// 更新表结构:应用Schema变更
schema = SchemaUtils.applySchemaChangeEvent(
jsonSerializers.get(schemaChangeEvent.tableId()).getSchema(),
schemaChangeEvent);
}
// 构建JSON序列化器
JsonRowDataSerializationSchema jsonSerializer = buildSerializationForPrimaryKey(schema);
try {
jsonSerializer.open(context); // 初始化序列化器
} catch (Exception e) {
throw new RuntimeException(e);
}
// 缓存表结构信息
jsonSerializers.put(
schemaChangeEvent.tableId(),
new TableSchemaInfo(
schemaChangeEvent.tableId(), schema, jsonSerializer, zoneId));
}buildSerializationForPrimaryKey() - 构建JSON序列化器
java
private JsonRowDataSerializationSchema buildSerializationForPrimaryKey(Schema schema) {
// 构建包含表名和主键的字段数组
DataField[] fields = new DataField[schema.primaryKeys().size() + 1];
fields[0] = DataTypes.FIELD("TableId", DataTypes.STRING()); // 表标识字段
// 添加所有主键字段
for (int i = 0; i < schema.primaryKeys().size(); i++) {
Column column = schema.getColumn(schema.primaryKeys().get(i)).get();
fields[i + 1] = DataTypes.FIELD(column.getName(), column.getType());
}
// 构建数据类型
DataType dataType = DataTypes.ROW(fields).notNull();
LogicalType rowType = DataTypeUtils.toFlinkDataType(dataType).getLogicalType();
// 使用兼容性工具类创建JSON序列化器
return JsonRowDataSerializationSchemaUtils.createSerializationSchema(
(RowType) rowType,
timestampFormat,
mapNullKeyMode,
mapNullKeyLiteral,
encodeDecimalAsPlainNumber,
ignoreNullFields);
}生成的 JSON 格式
数据结构
JSON 输出包含以下字段:
- TableId:表标识
- 主键字段:所有主键列的值
示例输出
源表结构
java
CREATE TABLE users (
user_id BIGINT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
created_at TIMESTAMP
);
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id BIGINT,
amount DECIMAL(10,2),
order_date DATE
);JSON 输出示例
java
// users 表数据
{
"TableId": "users",
"user_id": 1001
}
{
"TableId": "users",
"user_id": 1002
}
// orders 表数据
{
"TableId": "orders",
"order_id": 5001
}
{
"TableId": "orders",
"order_id": 5002
}JSON 格式配置详解
时间戳格式 (TimestampFormat)
java
TimestampFormat.SQL // "2023-11-24 15:30:00"
TimestampFormat.ISO_8601 // "2023-11-24T15:30:00Z"Map中null键处理 (MapNullKeyMode)
java
JsonFormatOptions.MapNullKeyMode.DROP // 丢弃null键
JsonFormatOptions.MapNullKeyMode.FAIL // 抛出异常
JsonFormatOptions.MapNullKeyMode.LITERAL // 使用指定文本替换Decimal编码方式
java
encodeDecimalAsPlainNumber = true // 123.45 编码为 123.45
encodeDecimalAsPlainNumber = false // 123.45 编码为 "123.45"Null字段处理
java
ignoreNullFields = true // 忽略null字段,不输出到JSON
ignoreNullFields = false // 包含null字段,输出为 null扩展为完整数据序列化
如果要序列化完整数据,可以修改 buildSerializationForPrimaryKey 方法:
java
private JsonRowDataSerializationSchema buildSerializationForAllColumns(Schema schema) {
// 包含所有字段
DataField[] fields = new DataField[schema.getColumns().size() + 1];
fields[0] = DataTypes.FIELD("TableId", DataTypes.STRING());
for (int i = 0; i < schema.getColumns().size(); i++) {
Column column = schema.getColumns().get(i);
fields[i + 1] = DataTypes.FIELD(column.getName(), column.getType());
}
DataType dataType = DataTypes.ROW(fields).notNull();
LogicalType rowType = DataTypeUtils.toFlinkDataType(dataType).getLogicalType();
return JsonRowDataSerializationSchemaUtils.createSerializationSchema(
(RowType) rowType,
timestampFormat,
mapNullKeyMode,
mapNullKeyLiteral,
encodeDecimalAsPlainNumber,
ignoreNullFields);
}配置示例
Flink CDC Pipeline 配置
java
mysql-sync-database \
--database source_db \
--sink-conf connector=kafka \
--sink-conf format=json \
--sink-conf json.timestamp-format=ISO-8601 \
--sink-conf json.map-null-key.mode=LITERAL \
--sink-conf json.map-null-key.literal=NULL \
--sink-conf json.encode-decimal-as-plain-number=true \
--sink-conf json.ignore-null-fields=trueFlink SQL 配置
java
CREATE TABLE kafka_sink (
-- 字段定义
) WITH (
'connector' = 'kafka',
'format' = 'json',
'json.timestamp-format' = 'SQL',
'json.map-null-key.mode' = 'LITERAL',
'json.map-null-key.literal' = 'null',
'json.encode-decimal-as-plain-number' = 'false',
'json.ignore-null-fields' = 'true'
);总结:这个 JsonSerializationSchema 是一个专门用于将 CDC 事件序列化为 JSON 格式的组件,它通过维护表结构缓存和动态处理 Schema 变更,实现了高效的数据序列化。虽然当前实现只序列化表名和主键信息,但其设计支持轻松扩展为完整数据序列化。