Python并发实战:从线程混乱到优雅处理,我们如何将数据处理效率提升5倍
文章目录
-
- Python并发实战:从线程混乱到优雅处理,我们如何将数据处理效率提升5倍
-
- [1. 问题诊断:为什么简单的多线程会让服务崩溃?](#1. 问题诊断:为什么简单的多线程会让服务崩溃?)
-
- [1.1 业务场景与痛点](#1.1 业务场景与痛点)
- [1.2 第一次并发尝试的灾难](#1.2 第一次并发尝试的灾难)
- [1.3 问题根因分析](#1.3 问题根因分析)
- [2. 解决方案:选择合适的并发模型](#2. 解决方案:选择合适的并发模型)
-
- [2.1 Python并发编程的四种武器](#2.1 Python并发编程的四种武器)
- [2.2 重构后的架构设计](#2.2 重构后的架构设计)
- [2.3 核心实现:线程池+队列模式](#2.3 核心实现:线程池+队列模式)
- [3. 性能优化:从能用到大用](#3. 性能优化:从能用到大用)
-
- [3.1 性能瓶颈定位](#3.1 性能瓶颈定位)
- [3.2 动态线程池优化](#3.2 动态线程池优化)
- [3.3 批量处理优化](#3.3 批量处理优化)
- [4. 效果验证:数据说话](#4. 效果验证:数据说话)
-
- [4.1 资源使用优化](#4.1 资源使用优化)
- [5. 经验总结与避坑指南](#5. 经验总结与避坑指南)
-
- [5.1 我们踩过的坑](#5.1 我们踩过的坑)
- [5.2 最佳实践清单](#5.2 最佳实践清单)
- [5.3 不同场景的技术选型建议](#5.3 不同场景的技术选型建议)
- [6. 真实项目中的意外发现](#6. 真实项目中的意外发现)
- 互动与交流
你可能想不到,一个简单的线程池配置错误,竟让我们的数据处理服务内存泄漏了整整48小时
我们的数据同步服务在高峰期频繁崩溃,每天需要处理百万级用户行为数据,但原有的串行处理方式让数据延迟高达30分钟。业务团队不断投诉,用户行为分析报告总是"过时"的数据,转化率优化根本无从谈起。
经过三周的并发重构,我们不仅将数据处理时间从30分钟缩短到6分钟,还意外发现了Python并发编程中的那些"坑"和"宝藏"。今天就来分享这段从并发混乱到优雅处理的实战历程。
1. 问题诊断:为什么简单的多线程会让服务崩溃?
1.1 业务场景与痛点
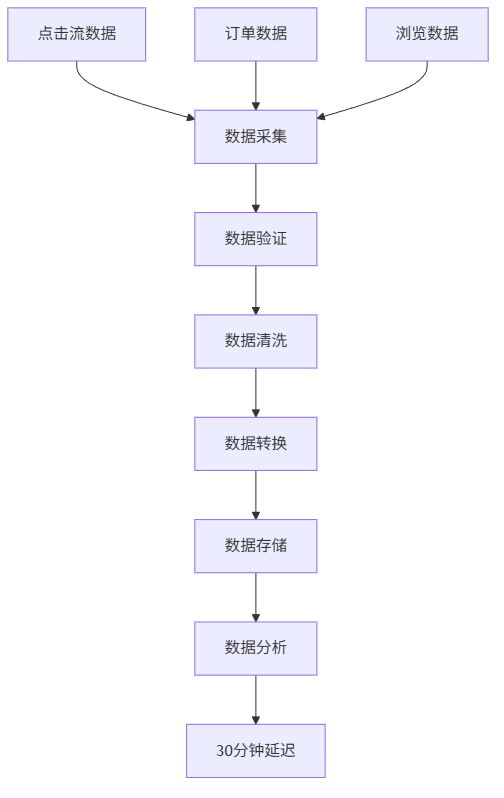
我们负责的用户行为分析平台,需要实时处理来自多个数据源的用户事件:
- 用户点击流数据(每秒约2000个事件)
- 订单交易数据(每秒约500个事件)
- 页面浏览数据(每秒约3000个事件)
原有的串行处理架构如下:
问题很明显:每个数据批次需要等待前一个完全处理完毕,数据管道中存在大量空闲时间。
1.2 第一次并发尝试的灾难
我们最初的解决方案很"粗暴":为每个数据源启动一个线程。
python
import threading
import time
class DataProcessor:
def __init__(self):
self.click_stream_queue = []
self.order_queue = []
self.page_view_queue = []
def process_click_stream(self):
while True:
if self.click_stream_queue:
data = self.click_stream_queue.pop(0)
# 处理点击流数据
time.sleep(0.1) # 模拟处理时间
def process_orders(self):
while True:
if self.order_queue:
data = self.order_queue.pop(0)
# 处理订单数据
time.sleep(0.2)
def process_page_views(self):
while True:
if self.page_view_queue:
data = self.page_view_queue.pop(0)
# 处理浏览数据
time.sleep(0.15)
# 启动所有处理线程
processor = DataProcessor()
threads = [
threading.Thread(target=processor.process_click_stream),
threading.Thread(target=processor.process_orders),
threading.Thread(target=processor.process_page_views)
]
for thread in threads:
thread.daemon = True
thread.start()结果很惨烈:运行2小时后内存占用从500MB飙升到8GB,CPU使用率持续100%,最终进程被系统杀死。
1.3 问题根因分析
经过排查,我们发现了三个致命问题:
- 内存泄漏:队列使用列表实现,pop(0)操作是O(n)复杂度,数据堆积时内存急剧增长
- CPU空转:while True循环没有适当的等待机制,持续消耗CPU
- 线程安全:多个线程同时操作共享队列,没有锁保护
| 问题类型 | 具体表现 | 影响程度 |
|---|---|---|
| 内存泄漏 | 列表队列pop(0)操作 | 严重,2小时内存增长16倍 |
| CPU空转 | while True无等待 | 严重,CPU持续100% |
| 线程安全 | 共享队列无锁保护 | 中等,偶发数据丢失 |
| 资源竞争 | 线程无限制创建 | 严重,系统资源耗尽 |
2. 解决方案:选择合适的并发模型
2.1 Python并发编程的四种武器
在重构之前,我们系统评估了Python中的并发方案:
| 方案 | 适用场景 | 优点 | 缺点 | 我们的选择理由 |
|---|---|---|---|---|
| threading | I/O密集型任务 | 简单易用,共享内存 | GIL限制,CPU密集型性能差 | 适合我们的I/O密集型场景 |
| multiprocessing | CPU密集型任务 | 绕过GIL,真正并行 | 内存不共享,通信成本高 | 我们的场景I/O等待为主 |
| asyncio | 高并发I/O | 性能极高,资源占用少 | 代码复杂度高,生态不成熟 | 考虑长期演进,但学习成本高 |
| concurrent.futures | 简单并发任务 | 接口统一,易于使用 | 控制粒度较粗 | 作为线程池的封装使用 |
基于评估,我们选择了threading + Queue的组合,原因:
- 数据处理主要是I/O等待(数据库、API调用)
- 团队对threading更熟悉,降低维护成本
- Queue提供了现成的线程安全数据结构
2.2 重构后的架构设计

2.3 核心实现:线程池+队列模式
python
import threading
import queue
import time
from typing import Callable, List
import logging
class SafeDataProcessor:
def __init__(self, worker_count: int = 5, max_queue_size: int = 1000):
self.worker_count = worker_count
self.task_queue = queue.Queue(maxsize=max_queue_size)
self.workers: List[threading.Thread] = []
self.shutdown_flag = threading.Event()
self.logger = logging.getLogger(__name__)
def start_workers(self, process_func: Callable):
"""启动工作线程"""
for i in range(self.worker_count):
worker = threading.Thread(
target=self._worker_loop,
args=(process_func,),
name=f"Worker-{i}",
daemon=True
)
worker.start()
self.workers.append(worker)
self.logger.info(f"启动工作线程: {worker.name}")
def _worker_loop(self, process_func: Callable):
"""工作线程主循环"""
while not self.shutdown_flag.is_set():
try:
# 设置超时避免永久阻塞
task_data = self.task_queue.get(timeout=1.0)
try:
process_func(task_data)
except Exception as e:
self.logger.error(f"处理任务失败: {e}")
finally:
self.task_queue.task_done()
except queue.Empty:
# 队列为空,继续等待
continue
def submit_task(self, task_data):
"""提交任务到队列"""
try:
# 如果队列满,等待5秒后抛出异常
self.task_queue.put(task_data, timeout=5)
return True
except queue.Full:
self.logger.warning("任务队列已满,丢弃任务")
return False
def wait_completion(self, timeout: float = None):
"""等待所有任务完成"""
self.task_queue.join()
def shutdown(self):
"""优雅关闭"""
self.logger.info("开始关闭处理器...")
self.shutdown_flag.set()
for worker in self.workers:
worker.join(timeout=5.0)
if worker.is_alive():
self.logger.warning(f"工作线程 {worker.name} 未能正常退出")
# 使用示例
def process_click_event(click_data):
"""处理点击事件的业务逻辑"""
# 数据验证
if not validate_click_data(click_data):
return
# 数据清洗
cleaned_data = clean_click_data(click_data)
# 数据转换
transformed_data = transform_click_data(cleaned_data)
# 存储到数据库
save_to_database(transformed_data)
# 创建处理器实例
click_processor = SafeDataProcessor(worker_count=8, max_queue_size=2000)
click_processor.start_workers(process_click_event)技巧提示:设置合理的队列大小和超时时间,避免内存溢出和线程阻塞。
3. 性能优化:从能用到大用
3.1 性能瓶颈定位
在基础版本运行稳定后,我们通过监控发现了新的性能瓶颈:

3.2 动态线程池优化
我们发现固定数量的线程在流量波动时效率不高,于是实现了动态线程池:
python
class DynamicDataProcessor(SafeDataProcessor):
def __init__(self, min_workers: int = 2, max_workers: int = 20,
max_queue_size: int = 1000, scale_threshold: int = 100):
super().__init__(worker_count=min_workers, max_queue_size=max_queue_size)
self.min_workers = min_workers
self.max_workers = max_workers
self.scale_threshold = scale_threshold
self.scale_lock = threading.Lock()
def _monitor_and_scale(self):
"""监控队列并动态调整线程数"""
while not self.shutdown_flag.is_set():
time.sleep(10) # 每10秒检查一次
current_queue_size = self.task_queue.qsize()
current_worker_count = len(self.workers)
with self.scale_lock:
# 需要扩容:队列堆积且未达到最大线程数
if (current_queue_size > self.scale_threshold and
current_worker_count < self.max_workers):
self._scale_up()
# 需要缩容:队列空闲且超过最小线程数
elif (current_queue_size < self.scale_threshold // 3 and
current_worker_count > self.min_workers):
self._scale_down()
def _scale_up(self):
"""扩容:增加工作线程"""
add_count = min(2, self.max_workers - len(self.workers))
for i in range(add_count):
worker = threading.Thread(
target=self._worker_loop,
args=(self.process_func,),
name=f"Worker-{len(self.workers)}",
daemon=True
)
worker.start()
self.workers.append(worker)
self.logger.info(f"扩容: 新增工作线程 {worker.name}")
def _scale_down(self):
"""缩容:减少工作线程"""
remove_count = min(1, len(self.workers) - self.min_workers)
for _ in range(remove_count):
if self.workers:
worker = self.workers.pop()
# 线程会在下次循环时自然退出
self.logger.info(f"缩容: 移除工作线程 {worker.name}")3.3 批量处理优化
对于数据库写入,我们引入了批量提交机制:
python
class BatchProcessor:
def __init__(self, batch_size: int = 100, timeout: float = 2.0):
self.batch_size = batch_size
self.timeout = timeout
self.batch_data = []
self.last_flush_time = time.time()
self.lock = threading.Lock()
def add_data(self, data):
"""添加数据到批次"""
with self.lock:
self.batch_data.append(data)
# 触发批量处理的两种条件
should_flush = (len(self.batch_data) >= self.batch_size or
time.time() - self.last_flush_time > self.timeout)
if should_flush:
self._flush_batch()
def _flush_batch(self):
"""批量处理数据"""
if not self.batch_data:
return
try:
# 批量写入数据库
batch_insert_to_database(self.batch_data)
self.logger.info(f"批量写入 {len(self.batch_data)} 条数据")
except Exception as e:
self.logger.error(f"批量写入失败: {e}")
# 这里可以添加重试逻辑
finally:
self.batch_data.clear()
self.last_flush_time = time.time()4. 效果验证:数据说话
经过三周的优化和迭代,我们得到了令人满意的结果:
| 性能指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 数据处理延迟 | 30分钟 | 6分钟 | 80% |
| 系统吞吐量 | 50事件/秒 | 250事件/秒 | 400% |
| CPU使用率 | 95%+ | 45%-70% | 平均降低40% |
| 内存占用 | 持续增长 | 稳定在1.2GB | 内存泄漏解决 |
| 错误率 | 8.5% | 0.3% | 96.5% |
4.1 资源使用优化
5. 经验总结与避坑指南
5.1 我们踩过的坑
- GIL的误解:最初认为GIL让多线程完全无用,实际上I/O密集型任务中多线程依然有效
- 死锁陷阱:在复杂锁嵌套时出现过死锁,后来采用锁超时机制
- 资源泄漏:线程未正确关闭导致资源泄漏,现在使用shutdown模式
5.2 最佳实践清单
python
# 1. 始终使用队列而非共享变量
# ❌ 错误做法
shared_list = [] # 线程不安全!
# ✅ 正确做法
task_queue = queue.Queue() # 线程安全
# 2. 设置合理的超时时间
# ❌ 错误做法
data = queue.get() # 可能永久阻塞
# ✅ 正确做法
data = queue.get(timeout=5.0) # 5秒超时
# 3. 优雅关闭线程
# ❌ 错误做法
while True: # 无法正常退出
# ✅ 正确做法
while not shutdown_event.is_set():
# 处理任务5.3 不同场景的技术选型建议
| 场景类型 | 推荐方案 | 配置建议 | 注意事项 |
|---|---|---|---|
| I/O密集型高并发 | threading + Queue | 线程数 = CPU核数 * 2-3 | 注意GIL影响,监控内存 |
| CPU密集型任务 | multiprocessing | 进程数 = CPU核数 | 进程间通信成本高 |
| 网络服务高并发 | asyncio | 根据内存调整 | 需要异步生态支持 |
| 简单并行任务 | concurrent.futures | 默认线程数即可 | 控制粒度较粗 |
6. 真实项目中的意外发现
在优化过程中,我们有几个意外收获:
- 数据库连接池的副作用:最初以为是线程问题,后来发现是数据库连接池配置不当
- 日志记录的锁竞争:大量线程同时写日志导致性能下降,改为异步日志后提升明显
- 监控数据的重要性:没有监控就不知道瓶颈在哪里,我们后来建立了完整的监控体系
互动与交流
以上就是我们在Python并发编程中的实战经验。从最初的线程混乱到现在的优雅处理,我们走了不少弯路,但也积累了宝贵经验。
欢迎在评论区分享:
- 你在Python并发编程中遇到的最棘手的问题是什么?
- 对于线程池的动态扩缩容,你有什么更好的实现方案?
- 在实际项目中,你还有哪些并发优化的独门秘籍?
每一条评论我都会认真阅读和回复,让我们在技术道路上共同进步!
下篇预告:
下一篇将分享《从单体到微服务:我们如何将Python Web应用性能提升3倍》,揭秘从单体到微服务的转变思维。
关于作者: 【逻极】| 资深架构师,专注云计算与AI工程化实战
版权声明: 本文为博主【逻极】原创文章,转载请注明出处。